One of the main purposes of DVC repository is version control of data and model files. DVC also supports the reuse of these data artifacts across projects. This means that your project can rely on data from other DVC repositories, just like a package management system for data science.
We can build a DVC project dedicated to version control of data sets (or data features, ML models, etc.).
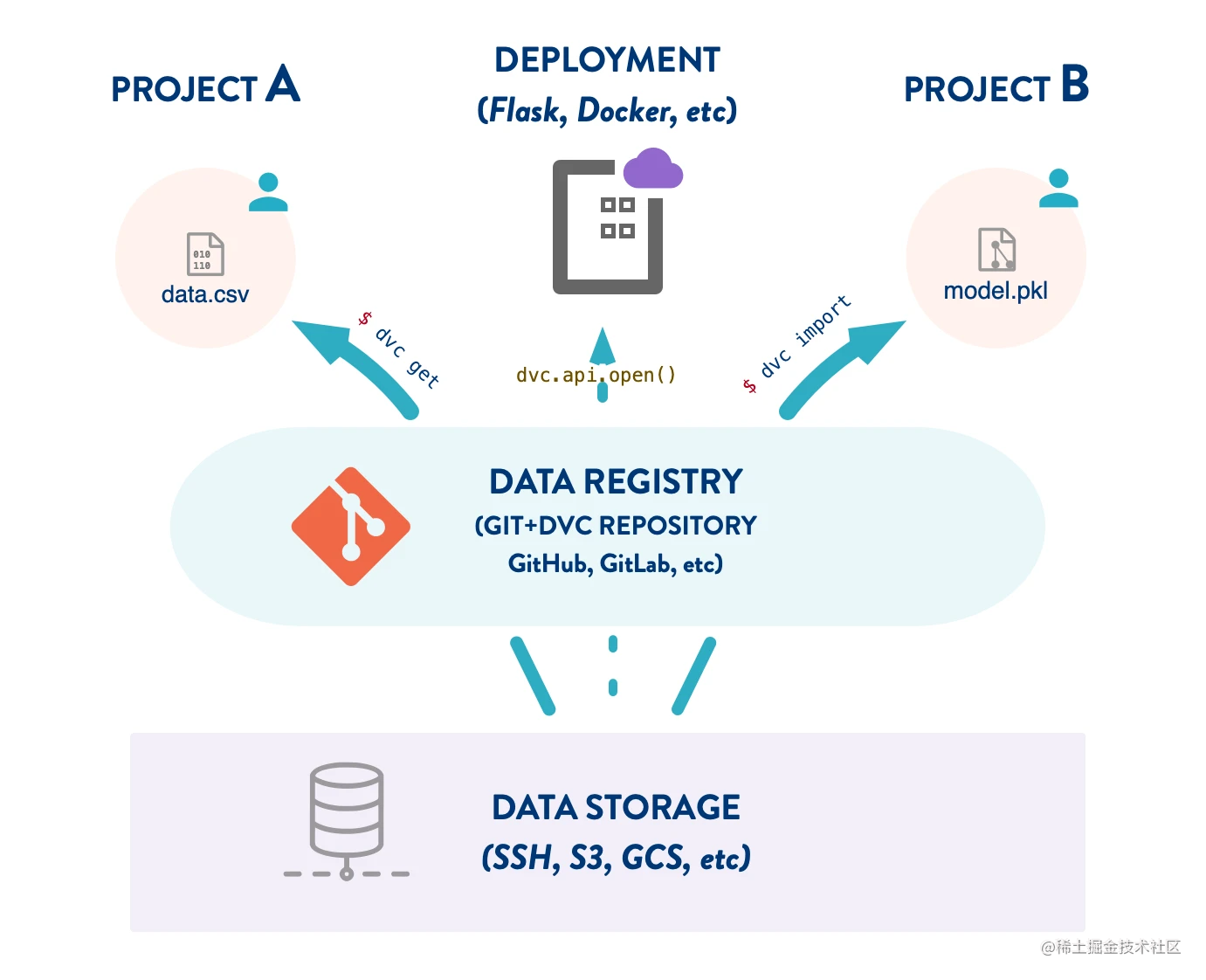
GIT has all metadata and change history of the data it tracks in the remote warehouse. We can see who changed what when, and use the pull request to update the data, just as we use code. This is what we call the data registry - the data management middleware between machine learning project and cloud storage.
Advantages of data registry:
- Reusability: use simple CLI (dvc get and dvc import commands, similar to pip and other software package management systems) to reproduce and organize the Feature Store.
- Persistence: remote storage tracked by the DVC Registry (e.g. S3 bucket) improves data security. For example, someone is less likely to delete or rewrite an ML model.
- Storage optimization: centralize the data shared by multiple projects in one location. This simplifies data management and optimizes space requirements.
- Data is code (managing data is like managing code): leverage Git workflows for your data and model lifecycle, such as commit, branch, pull request, review, and even CI/CD.
- You can use remote registry security (for example: HTTP server read only).
Establish data registry
Adding a dataset to the registry is very simple. Just put the data file or directory in the workspace and use dvc add to track it. You can replace the actual data with The dvc file (for example, the following music/songs.dvc file) follows the normal Git workflow. This allows the team to collaborate on data at the same level as the source code:
this Sample data set If it does exist, please download it in advance. After downloading, perform the following operations:
$ mkdir -p music/songs $ cp ~/Downloads/millionsongsubset_full music/songs $ dvc add music/songs/ $ git add music/songs.dvc music/.gitignore $ git commit -m "Track 1.8 GB 10,000 song dataset in music/"
The actual data is stored in the cache of the project and can be pushed to one or more remote storage locations so that others can access the registry from other locations.
$ dvc remote add -d myremote s3://mybucket/dvcstore $ dvc push
A good way to organize a DVC repository into a data registry is to use directories to group similar data, such as images /, natural language /
For example, our Dataset registry It has directories such as get started / and use cases / The website Match part of the content.
Use data registry
The main ways to use artifacts in the data registry are the dvc import and dvc get commands, and the python API DVC api. First, we may want to explore its content.
List data
To explore the contents of the DVC repository to search for appropriate data, use the dvc list command (similar to the ls command and third-party tools such as aws s3 ls):
$ dvc list -R https://github.com/iterative/dataset-registry .gitignore README.md get-started/.gitignore get-started/data.xml get-started/data.xml.dvc images/.gitignore images/dvc-logo-outlines.png ...
The above command lists the files tracked by Git and the data (or models, etc.) tracked by DVC.
Download data to working directory
dvc get is similar to using wget (HTTP), aws s3 cp (S3) and other direct download tools. To get a dataset from the DVC repository, we can run the following command:
$ dvc get https://github.com/example/registry music/songs
This will download music/songs from the project's default remote data repository and place it in the current working directory.
Import data into workflow
dvc import uses the same syntax as dvc get:
$ dvc import https://github.com/example/registry images/faces
In addition to downloading data, this command also saves information about the dependency of the local project on the data source (registry repository). This is done by generating a special import dvc file (including metadata information).
Whenever the data set in the registry changes, we can use dvc update to update the data:
dvc update faces.dvc
This will download new and changed files according to the latest submission in the source code base, and delete the deleted files; At the same time, it will be updated accordingly dvc file.
be careful:
dvc get, dvc import, and dvc update have a -- rev parameter option for downloading data from a specific submission in the source repository.
Downloading DVC data using Python code
Our Python API is included in the DVC package installed with DVC, including open functions to load and stream data directly from external DVC projects:
import dvc.api.open
model_path = 'model.pkl'
repo_url = 'https://github.com/example/registry'
with dvc.api.open(model_path, repo_url) as fd:
model = pickle.load(fd)
# ... Use the model!
This will change the model Pkl opens as a file descriptor. This example demonstrates a simple ML model deployment method, but it can be extended to more advanced scenarios, such as a model zoo.
In addition, you can also refer to DVC api. Read() and DVC api. get_ URL () function.
Update data registry
The data set is constantly updated, and DVC can easily deal with it. Just change the data in the registry. Apply the update by running dvc add again.
$ cp 1000/more/images/* music/songs/ $ dvc add music/songs/
dvc modifies the corresponding dvc file to reflect the changes, which will be collected by Git:
$ git status
...
modified: music/songs.dvc
$ git commit -am "Add 1,000 more songs to music/ dataset."
Repeating this process for multiple data sets can form a robust registry. The result is basically a library versioning a set of metafiles.
Let's take an example:
$ tree --filelimit=10 . ├── images │ ├── .gitignore │ ├── cats-dogs [2800 entries] # Listed in .gitignore │ ├── faces [10000 entries] # Listed in .gitignore │ ├── cats-dogs.dvc │ └── faces.dvc ├── music │ ├── .gitignore │ ├── songs [11000 entries] # Listed in .gitignore │ └── songs.dvc ├── text ...
Don't forget to use it dvc push Push data changes to Remote storage , so that others can get these changes!
$ dvc push