This article is transferred from: Le byte
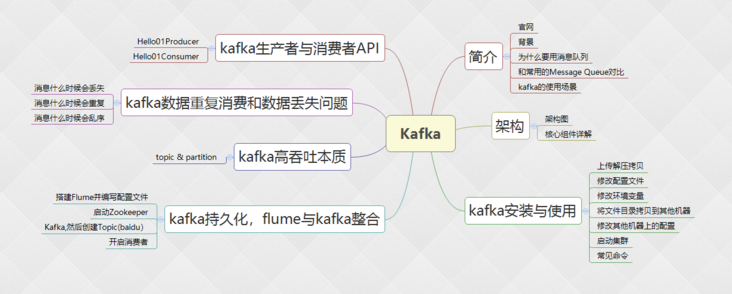
The article mainly explains: Kafka
For more Java related information, you can pay attention to the official account number: 999
Asynchronous communication principle
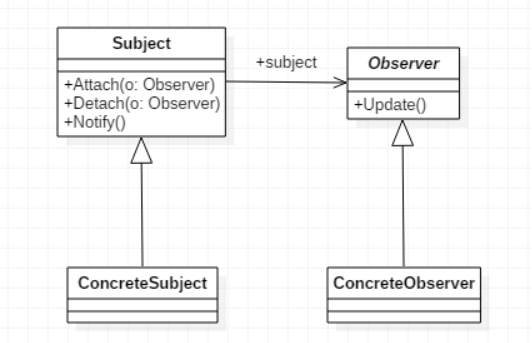
Observer mode
- Observer mode, also known as Publish/Subscribe mode
- Define a one to many dependency between objects, so that whenever an object changes state, all objects that depend on it will be notified and updated automatically.
- When the state of an object (target object) changes, all dependent objects (observer object) will be notified.
Application scenarios in real life
- JD arrival notice
- Chicken feather letter

Producer consumer model
Traditional mode
- The producer delivers the message directly to the specified consumer
- The coupling is particularly high. When producers or consumers change, they need to rewrite the business logic
Producer consumer model
- A container is used to solve the strong coupling problem between producers and consumers. Producers and consumers do not communicate directly with each other, but communicate through blocking queues

Data transfer process
- Producer consumer mode, that is, n threads produce and N threads consume at the same time. The two roles communicate through the memory buffer,
- The producer is responsible for adding data units to the buffer
The consumer is responsible for fetching data units from the buffer
- Generally, the principle of first in, first out is followed
buffer
decoupling
- Suppose that producers and consumers are two categories respectively. If the producer directly calls a method of the consumer, the producer will depend on the consumer
Support concurrency
- When the producer directly calls a method of the consumer, the function call is synchronous
- If consumers are slow to process data, producers will waste their good time
Support uneven free and busy
- Buffers have another benefit. If the speed of manufacturing data is fast and slow, the benefits of buffer are reflected.
- When data production is fast, consumers have no time to process, and unprocessed data can be temporarily stored in the buffer.
- When the manufacturing speed of producers slows down, consumers will deal with it slowly.
Data unit
Associate to business object
- The data unit must be associated with a business object
Integrity
- In the process of transmission, the integrity of the data unit shall be ensured
Independence
- That is, there is no interdependence between various data units
- The transmission failure of a data unit shall not affect the unit that has completed the transmission; Nor should it affect units that have not yet been transmitted.
Particle size
- The data unit needs to be associated with a business object. The relationship between the data unit and the business object (one to one? One to many)
- If the particle size is too small, it will increase the number of data transmission
- If the particles pass the assembly, the time of single data transmission will be increased, which will affect the later consumption
Message system principle
A message system is responsible for transferring data from one application to another. Applications only need to focus on data, not how data is transmitted between two or more applications.
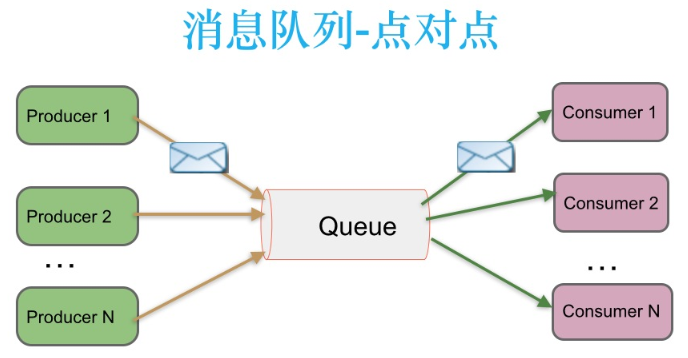
Peer to peer messaging
- In a peer-to-peer messaging system, messages are persisted to a queue. At this point, there will be one or more consumers consuming the data in the queue. But a message can only be consumed once.
- When a consumer consumes a piece of data in the queue, the data is deleted from the message queue.
- This mode can ensure the order of data processing even if multiple consumers consume data at the same time.
In the message system based on push model, the message agent records the consumption status.
- After the message agent pushes the message to the consumer, it marks the message as consumed, but this method can not guarantee the processing semantics of consumption.
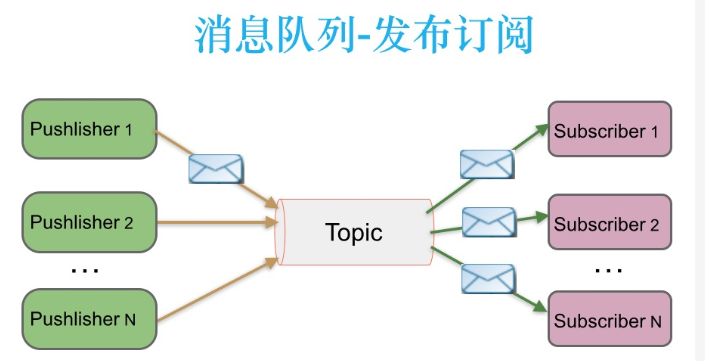
Publish subscribe messaging
- In the publish subscribe message system, messages are persisted into a topic.
- Consumers can subscribe to one or more topics. Consumers can consume all the data in the topic. The same data can be consumed by multiple consumers. The data will not be deleted immediately after consumption.
- In publish subscribe message system, the producer of message is called publisher, and the consumer is called subscriber.
- Kafka adopts the pull model (Poll), and controls the consumption speed and progress by itself. Consumers can consume according to any offset.
Introduction to Kafka
- Official website: http://kafka.apache.org/
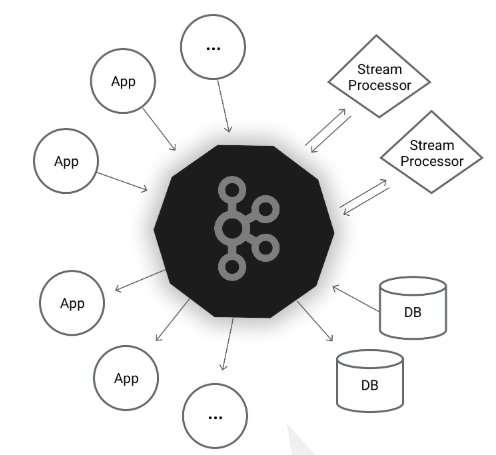
- Kafka is an open source stream processing platform developed by the Apache Software Foundation and written by Scala and Java. Kafka is a high-throughput distributed publish subscribe message system, which can process all the action flow data of consumers in the website.
design goal
- The message persistence capability is provided with a time complexity of O(1), and the constant time access performance can be guaranteed even for data above TB level.
- High throughput. Even on very cheap commercial machines, a single machine can support the transmission of 100K messages per second.
- Support message partition and distributed consumption between Kafka servers, and ensure the sequential transmission of messages in each partition.
- It also supports offline data processing and real-time data processing.
- Support online horizontal expansion
Advantages of Kafka
- Decoupling:
At the beginning of the project, it is extremely difficult to predict what needs the project will encounter in the future. The message system inserts an implicit and data-based interface layer in the middle of the processing process, and the processing processes on both sides should implement this interface. This allows you to independently extend or modify the processes on both sides, as long as you ensure that they comply with the same interface constraints.
- redundancy
In some cases, the process of processing data will fail. Unless the data is persisted, it will cause loss. Message queuing avoids the risk of data loss by persisting data until they have been completely processed. In the "insert get delete" paradigm adopted by many message queues, before deleting a message from the queue, your processing system needs to clearly indicate that the message has been processed, so as to ensure that your data is safely saved until you use it.
- Expansibility
Because message queuing decouples your processing process, it is easy to increase the frequency of message queuing and processing, as long as you add another processing process. There is no need to change the code and adjust the parameters. Expansion is as simple as turning up the power button.
- Flexibility & peak processing power
In the case of a sharp increase in traffic, applications still need to continue to play a role, but such burst traffic is not common; It would be a huge waste to put resources on standby to handle such peak visits. Using message queuing can make key components withstand the sudden access pressure without completely crashing due to sudden overloaded requests.
- Recoverability
Failure of some components of the system will not affect the whole system. Message queuing reduces the coupling between processes, so even if a process processing messages hangs, the messages added to the queue can still be processed after the system recovers.
- Sequence guarantee
In most usage scenarios, the order of data processing is very important. Most message queues are sorted and can ensure that the data will be processed in a specific order. Kafka guarantees the order of messages in a Partition.
- buffer
In any important system, there will be elements that require different processing times. For example, loading a picture takes less time than applying a filter. Message queuing helps the most efficient execution of tasks through a buffer layer -- the processing of writing to the queue will be as fast as possible. This buffer helps to control and optimize the speed of data flow through the system.
- asynchronous communication
Many times, users do not want or need to process messages immediately. Message queuing provides an asynchronous processing mechanism that allows users to put a message on the queue without processing it immediately. Put as many messages into the queue as you want, and then process them when needed.
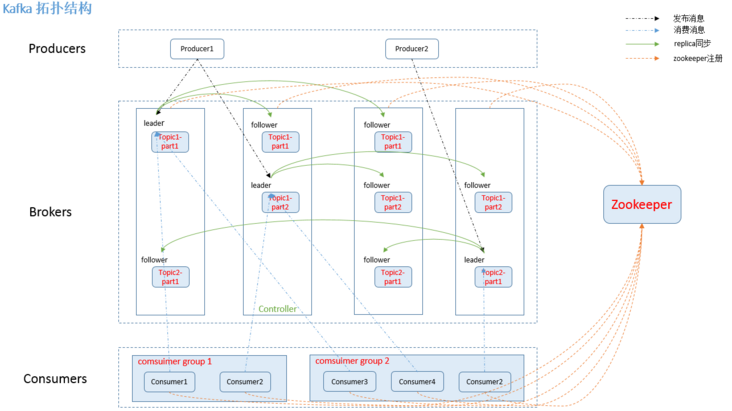
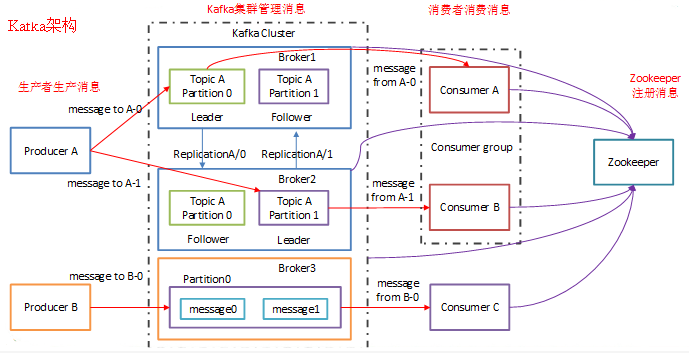
Kafka system architecture
Broker
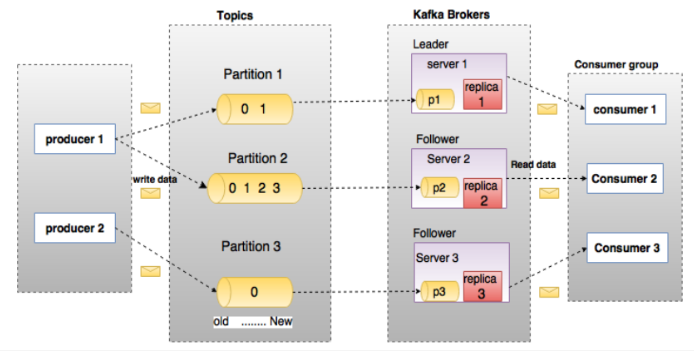
- The Kafka cluster contains one or more servers, and the server nodes are called broker s.
Topic
- Each message published to the Kafka cluster has a category called Topic.
- Similar to the database table name or ES Index
- Physically, messages of different topics are stored separately
- Logically, although the message of a Topic is saved in one or more broker s, users only need to specify the Topic of the message to produce or consume data without caring where the data is stored)
- Create process
1.controller stay ZooKeeper of/brokers/topics Register on node watcher,When topic Is created, then controller Will pass watch Get the topic of partition/replica Allocation. 2.controller from/brokers/ids Read all currently available broker List, for set_p Each of partition: 2.1 From assigned to the partition All of replica(be called AR)Select one of the available broker As new leader,And will AR Set as new ISR 2.2 New leader and ISR write in/brokers/topics/[topic]/partitions/[partition]/state 3.controller adopt RPC To the relevant broker send out LeaderAndISRRequest.- Delete process
1.controller stay zooKeeper of/brokers/topics Register on node watcher,When topic Deleted, then controller Will pass watch Get the topic of partition/replica Allocation. 2.if delete.topic.enable=false,end; otherwise controller Registered in/admin/delete_topics Upper watch cover fire,controller Send a callback to the corresponding broker send out StopReplicaRequest.
Partition
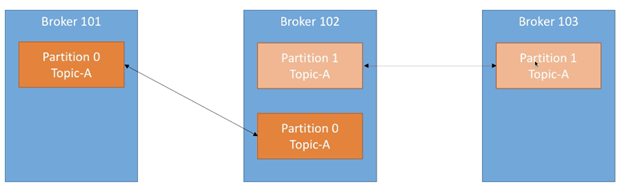
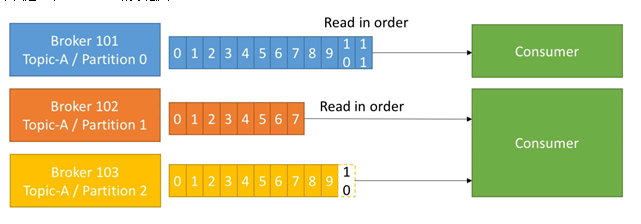
- The data in topic is divided into one or more partition s.
Each topic has at least one partition. When the producer generates data, select the partition according to the allocation policy, and then append the message to the end of the specified partition (queue)
## Partation data routing rules 1. Specified patition,Direct use; 2. Not specified patition But specify key,Pass on key of value conduct hash Choose one patition
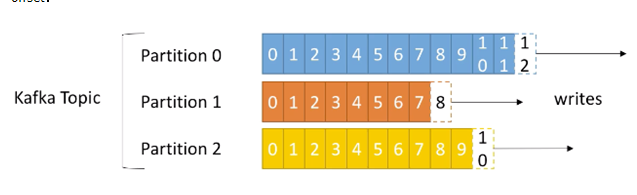
Each message will have a self incrementing number
- Identification sequence
- The offset used to identify the message
- The data in each partition is stored using multiple segment files.
- The data in the partition is orderly, and the data between different partitions loses the order of the data.
If the topic has multiple partitions, the order of data cannot be guaranteed when consuming data. In the scenario of strictly ensuring the consumption order of messages, the number of partitions needs to be set to 1.
Leader
- Each partition has multiple copies, including one and only one Leader, which is the partition currently responsible for reading and writing data.
1. producer First from zookeeper of "/brokers/.../state" The node found the partition of leader 2. producer Send a message to the leader 3. leader Write message to local log 4. followers from leader pull Message, write local log after leader send out ACK 5. leader All received ISR Medium replica of ACK After, increase HW(high watermark,last commit of offset) And to producer send out ACK
Follower
- The Follower follows the Leader. All write requests are routed through the Leader. Data changes will be broadcast to all followers. The Follower keeps data synchronization with the Leader.
- If the Leader fails, a new Leader is elected from the Follower.
- When a follower hangs, gets stuck, or the synchronization is too slow, the leader will delete the follower from the "in sync replicas" (ISR) list and recreate a follower.
replication
- The data will be stored in topic's partition, but the partition may be damaged
- We need to back up the partitioned data (how much you back up depends on how much you pay attention to the data)
We divide the partition into Leader(1) and Follower(N)
- The Leader is responsible for writing and reading data
- Follower is only responsible for backup
- The consistency of data is ensured
The number of backups is set to N, which means active + standby = n (refer to HDFS)
## Kafka's algorithm for assigning Replica is as follows 1. Will all broker(Hypothetical total n individual broker)And to be allocated partition sort 2. Will be the first i individual partition Assign to page( i mod n)individual broker upper
producer
- The producer is the publisher of data. This role publishes messages to Kafka's topic.
- After the broker receives the message sent by the producer, the broker appends the message to the segment file currently used to append data.
The messages sent by the producer are stored in a partition. The producer can also specify the partition of the data store.
consumer
- Consumers can read data from the broker. Consumers can consume data from multiple topic s.
kafka provides two sets of consumer API s:
1. The high-level Consumer API
- The high-level consumer API provides a high-level abstraction of consumption data from kafka, while the SimpleConsumer API requires developers to pay more attention to details.
Consumer Group
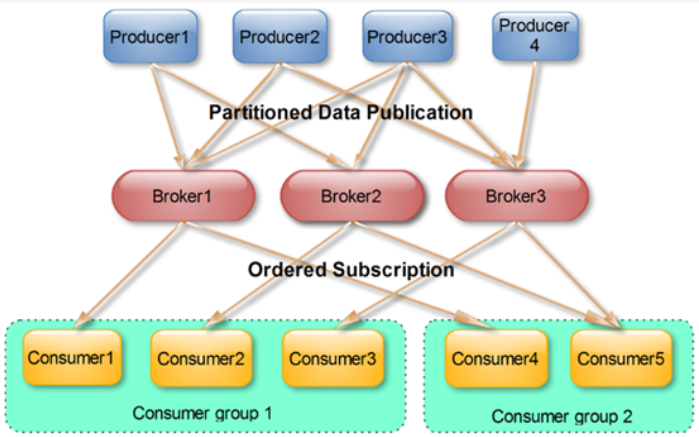
- Each Consumer belongs to a specific Consumer Group (you can specify a group name for each Consumer. If you do not specify a group name, it belongs to the default group).
- Bringing multiple consumers together to process the data of a Topic can quickly improve the data consumption power
- The entire consumer group shares a set of offsets (preventing data from being repeatedly read) because a Topic has multiple partitions
Offset offset
- A message can be uniquely identified
- The offset determines the location of the data to be read. There is no thread safety problem. Consumers use the offset to determine the message to be read next time
- Messages are not deleted immediately after they are consumed, so that multiple businesses can reuse kafka messages
- A service can also read the message again by modifying the offset, which is controlled by the user
- Messages will eventually be deleted. The default life cycle is 1 week (7 * 24 hours)
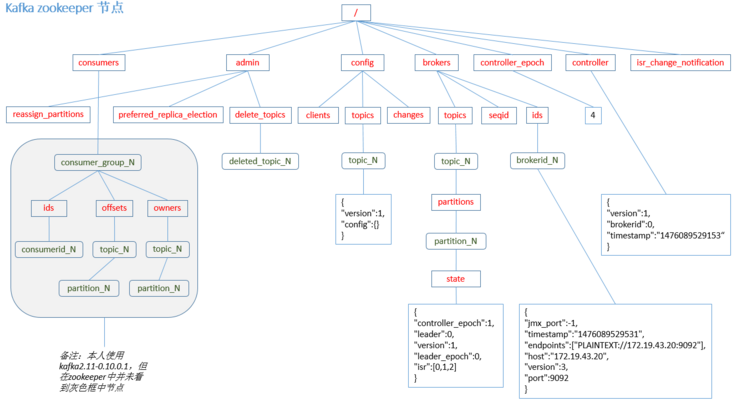
Zookeeper
- kafka stores the meta information of the cluster through zookeeper.
Kafka environment construction
Build and start based on Zookeeper
- Verify ZK availability
- [123]zkServer.sh start
Configure Kafka
basic operation
- Upload unzipped copy
Modify profile
## vim server.properties 20 broker.id=0 25 port=9092 58 log.dirs=/var/bdp/kafka-logs
Modify environment variables
## vim /etc/profile export KAFKA_HOME=/opt/lzj/kafka_2.11-0.8.2.1 export PATH=$KAFKA_HOME/bin:$PATH ## Profile validation
Copy files and directories to another machine
[1]scp -r kafka_2.11-0.8.2.1 root@node02:`pwd` [1]scp -r kafka_2.11-0.8.2.1 root@node03:`pwd` [1]scp /etc/profile root@node02:/etc/profile [1]scp /etc/profile root@node03:/etc/profile
Modify configuration on other machines
## vim server.properties [2]broker.id=1
Start cluster
- kafka-server-start.sh /opt/lzj/kafka_2.11-0.8.2.1/config/server.properties
Common commands
//create themes kafka-topics.sh --zookeeper node01:2181,node02:2181,node03:2181 --create --replication-factor 2 --partitions 3 --topic userlog kafka-topics.sh --zookeeper node01:2181 --create --replication-factor 2 --partitions 6 --topic studentlog
kafka-topics.sh --zookeeper node01:2181 --delete --replication-factor 2 --partitions 6 --topic baidu //View all topics kafka-topics.sh --zookeeper node01:2181,node02:2181,node03:2181 --list //View topics kafka-topics.sh --zookeeper node01:2181,node02:2181,node03:2181 --describe --topic userlog //Create producer kafka-console-producer.sh --broker-list node01:9092,node02:9092,node03:9092 --topic userlog //Create consumer kafka-console-consumer.sh --zookeeper node01:2181,node02:2181,node03:2181 --from-beginning --topic userlog ```

Kafka data retrieval mechanism

- Topics are grouped by partitions on the physical level. A topic can be divided into several partitions
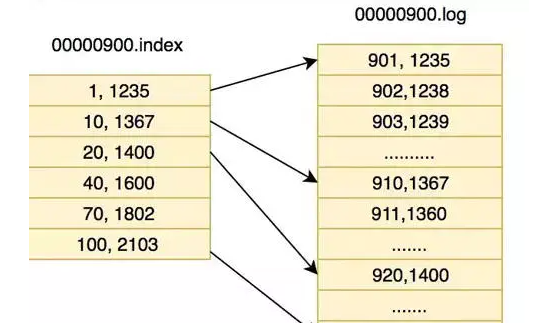
A partition can also be subdivided into segments. A partition is physically composed of multiple segments
segment has two parameters:
- log.segment.bytes: the maximum amount of data that can be accommodated by a single segment. The default is 1GB
- log.segment.ms: the time Kafka waits before commit ting an underfilled segment (7 days by default)
LogSegment file consists of two parts, namely ". Index" file and ". log" file, which are represented as Segment index file and data file respectively.
- The first segment of the partition global starts from 0, and each subsequent segment file name is the offset value of the last message of the previous segment file
- The value size is 64 bits, the length of 20 digital characters, and no numbers are filled with 0
first segment 00000000000000000000.index 00000000000000000000.log the second segment,The file is named after the first one segment Of the last message offset form 00000000000000170410.index 00000000000000170410.log Third segment,File named above segment Of the last message offset form 00000000000000239430.index
- Messages have fixed physical structures, including offset(8 Bytes), message body size (4 Bytes), crc32(4 Bytes), magic(1 Byte), attributes(1 Byte), key length(4 Bytes), key(K Bytes), payload(N Bytes) and other fields to determine the size of a message, that is, where to read.
Data security
producer delivery guarantee
0. At least one Messages are never lost, but may be transmitted repeatedly 1. At most once Messages may be lost, but they will never be transmitted repeatedly 2. Exactly once Each message must be transmitted once and only once
Producers can choose whether to receive acks for data writing. There are several options for acks: request.required.acks
acks=0:
- The Leader of Producer in ISR has successfully received the data and sent the next Message after confirmation.
acks=1:
- This means that the Producer does not have to wait for confirmation from the Broker to continue sending the next batch of messages.
acks=all:
- The Producer needs to wait until all followers in the ISR confirm the receipt of data before completing the transmission at one time, with the highest reliability.
ISR mechanism
key word
- Ar: assigned replicas is used to identify the complete set of replicas
- OSR: out -sync Replicas copies leaving the synchronization queue
- ISR: in -sync Replicas replicas replicas joined to the synchronization queue
- ISR = Leader + copy without falling too far behind; AR = OSR+ ISR.
We backup data to prevent data loss. When the primary node is down, we can enable the backup node
- producer--push-->leader
- leader--pull-->follower
- Follower pulls data from the Leader at regular intervals to ensure data synchronization
ISR(in-syncReplica)
- When the master node is hung, instead of selecting the master from the Follower, select the master from the ISR
Judgment criteria
No synchronization data for more than 10 seconds
- replica.lag.time.max.ms=10000
The primary and secondary nodes differ by 4000 pieces of data
- rerplica.lag.max.messages=4000
Dirty node election
- kafka adopts a degradation measure to deal with:
- Elect the first restored node to serve as a leader. Based on its data, this measure is called dirty leader election
Broker data storage mechanism
- kafka retains all messages regardless of whether they are consumed or not. There are two strategies to delete old data:
1. Time based: log.retention.hours=168 2. Based on size: log.retention.bytes=1073741824
consumer delivery guarantee
- If the consumer is set to autocommit, the consumer will automatically commit once it reads the data. If only this process of reading messages is discussed, Kafka ensures that it is Exactly once.
After reading the message, commit before processing the message.
- If the consumer crash es before it has time to process the message after the commit, it will not be able to read the unprocessed message that has just been submitted after the next restart
- This corresponds to most once
After reading the message, process it first and then commit.
- If the consumer crash es after processing the message and before the commit, the message that has not been committed will be processed the next time you restart the work. In fact, the message has been processed.
- This corresponds to At least once.
If you must do Exactly once, you need to coordinate the offset with the output of the actual operation.
- The classic approach is to introduce two-phase submission.
Kafka guarantees At least once by default, and allows At most once by setting producer asynchronous submission
Data consumption
- partiton_num=2, start a consumer process to subscribe to this topic, corresponding to stream_num is set to 2, which means that two threads are started to process message in parallel.
If auto.commit.enable=true,
- When the consumer fetch es some data but has not completely processed it,
- Just before the commit interval, the offset operation was submitted, and then the consumer crash dropped.
- At this time, the fetch ed data has not been processed, but has been commit ted, so there is no chance to be processed again, and the data is lost.
If auto.commit.enable=false,
- Suppose that the two fetcher s of the consumer each take a piece of data and are processed by two threads at the same time,
- At this time, thread t1 processes the data of partition1 and manually submits the offset. It should be emphasized here that when the commit is manually executed,
- In fact, it is committed to all partition s occupied by the consumer process. kafka has not provided a more fine-grained commit method yet,
- That is, even if t2 does not process the data of partition2, the offset is submitted by t1. If the consumer crash drops at this time, the data t2 is processing will be lost.
Method 1: (turn the multithreading problem into a single thread)
- Manually commit offset for partition_num starts the same number of consumer processes, which can ensure that a consumer process occupies a partition. When committing offset, it will not affect the offsets of other partitions. However, this method is limited because the number of partition and consumer processes must strictly correspond
Method 2: (refer to HDFS data writing process)
- Manually commit offset. In addition, all fetch ed data is cached in the queue at the consumer end. After all data in the queue is processed, the offset is submitted in batch, so that only the processed data can be committed.
JavaAPI
producer
Create a thread to repeatedly input data to kafka
Create producer thread class
public class Hello01Producer extends Thread {
//Create producers for Kafka
private Producer<String, String> producer;/**
- Create constructor
*/
public Hello01Producer(String pname) {
//Set the name of the thread super.setName(pname); //Create profile list Properties properties = new Properties(); // kafka address. Multiple addresses are separated by commas properties.put("metadata.broker.list", "192.168.58.161:9092,192.168.58.162:9092,192.168.58.163:9092"); //Format write out data properties.put("serializer.class", StringEncoder.class.getName()); //Written response mode properties.put("acks", 1); //Batch write properties.put("batch.size", 16384); //Create producer object producer = new Producer<String, String>(new kafka.producer.ProducerConfig(properties));}
@Override
public void run() {//Initialize a counter int count = 0; System.out.println("Hello01Producer.run--Start sending data"); //Send message iteratively while (count < 100000) { String key = String.valueOf(++count); String value = Thread.currentThread().getName() + "--" + count; //Encapsulating message objects KeyedMessage<String, String> message = new KeyedMessage<>("userlog", key, value); //Send message to server producer.send(message); //Print message System.out.println("Producer.run--" + key + "--" + value); //Send 1 every 1 second try { Thread.sleep(100); } catch (InterruptedException e) { e.printStackTrace(); } }}
public static void main(String[] args) {
Hello01Producer producer = new Hello01Producer("Shanghai shangxue school"); producer.start();}
}- Create constructor
consumer
Create a thread that repeatedly consumes data from kafka
//Create consumer object private ConsumerConnector consumer; /** * Create constructor */ public Hello01Consumer(String cname) { super.setName(cname); //Read configuration file Properties properties = new Properties(); //ZK address properties.put("zookeeper.connect", "192.168.58.161:2181,192.168.58.162:2181,192.168.58.163:2181"); //The name of the consumer's group properties.put("group.id", "shsxt-bigdata"); //ZK timeout properties.put("zookeeper.session.timeout.ms", "400"); //When consumers consume for the first time, they begin to consume from the lowest offset properties.put("auto.offset.reset", "smallest"); //Auto commit offset properties.put("auto.commit.enable", "true"); //The interval at which consumers automatically submit offsets properties.put("auto.commit.interval.ms", "1000"); //Create consumer object consumer = Consumer.createJavaConsumerConnector(new ConsumerConfig(properties)); } @Override public void run() { // Describe which topic to read and how many threads are required to read it Map<String, Integer> topicCountMap = new HashMap<String, Integer>(); topicCountMap.put("userlog", 1); //The consumer starts reading the message flow with the configuration information Map<String, List<KafkaStream<byte[], byte[]>>> consumerMap = consumer.createMessageStreams(topicCountMap); // Each thread corresponds to a KafkaStream List<KafkaStream<byte[], byte[]>> list = consumerMap.get("userlog"); // Get kafkastream stream KafkaStream stream0 = list.get(0); ConsumerIterator<byte[], byte[]> it = stream0.iterator(); //Start the iteration and get the data while (it.hasNext()) { // Get a message MessageAndMetadata<byte[], byte[]> value = it.next(); int partition = value.partition(); long offset = value.offset(); String data = new String(value.message()); System.out.println("start" + data + " partition:" + partition + " offset:" + offset); } } public static void main(String[] args) { Hello01Consumer consumer01 = new Hello01Consumer("Li Yi"); consumer01.start(); }}
Repeated consumption and data loss
It is possible that a consumer takes out a piece of data (offset=88), but the processing is not completed, but the consumer is closed
- It would be perfect if it could be reprocessed from 88 next time
- If the next data starts from 86, it belongs to repeated consumption of data
- If the data starts from 89 next time, it is related to the loss of data
//The time interval when the consumer automatically submits the offset props.put("auto.commit.interval.ms", "1010"); Submission interval: single execution time (repetition)
Kafka optimization
Number of partitions
Generally speaking, the throughput that each partition can handle is several MB/s (still based on the accurate indicators obtained after testing according to the local environment). Adding more partitions means:
- Higher parallelism and throughput
- More consumers (in the same consumer group) can be extended
- If there are more brokers in the cluster, idle brokers can be used to a greater extent
- But it will lead to more elections for Zookeeper
- More files will also be opened in Kafka
Adjustment criteria
- Generally speaking, if the cluster is small (less than 6 brokers), the partition number of 2 x broker s is configured. The main consideration here is the subsequent expansion. If the cluster is doubled (for example, 12), there is no need to worry about insufficient partition
- Generally speaking, if the cluster is large (more than 12), configure the number of partitions of 1 x the number of brokers. Because there is no need to consider the expansion of clusters here, the number of partitions with the same number of brokers is enough to cope with normal scenarios. If necessary, adjust it manually
- Consider the number of parallel consumers required for the peak throughput and adjust the number of partitions. If the application scenario requires 20 consumers (in the same consumer group) to consume in parallel, set it to 20 partitions accordingly
- Consider the throughput required by the producer and adjust the number of partitions (if the throughput of the producer is very high or high in the next two years, increase the number of partitions)
Replication factor
- This parameter determines the number of records to be copied. It is recommended to set it to at least 2, generally 3, and up to 4.
A higher replication factor (assuming a number of N) means:
- The system is more stable (N-1 broker s are allowed to go down)
- More copies (higher latency if acks=all)
- The system disk utilization will be higher (generally, if RF is 3, it will occupy 50% more disk space than when RF is 2)
Adjustment criteria:
- Start with 3 (of course, at least 3 brokers are required, and it is not recommended that the number of nodes in a Kafka cluster be less than 3)
- If the replication performance becomes a bottleneck or an issue, it is recommended to use a better broker instead of reducing the number of RF s
- Never set RF to 1 in a production environment
Batch write
- In order to greatly improve the write throughput of producer, it is necessary to write files in batches regularly
whenever producer Brush data to disk when writing 10000 messages log.flush.interval.messages=10000 Brush the data to the disk every 1 second log.flush.interval.ms=1000
Flume+Kafka integration
Build Flume and write configuration file
- vim /opt/lzj/flume-1.6.0/options/f2k.conf
#flume-ng agent -n a1 -f /opt/lzj/flume-1.6.0/options/f2k.conf - flume.root.logger=INFO,console # Name the components on this agent a1.sources = r1 a1.sinks = k1 a1.channels = c1 # Describe/configure the source a1.sources.r1.type = exec a1.sources.r1.command = tail -F /var/bdp/baidu.ping # Describe the sink a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink a1.sinks.k1.topic = baidu a1.sinks.k1.brokerList = node01:9092,node02:9092,node03:9092 a1.sinks.k1.requiredAcks = 1 a1.sinks.k1.batchSize = 10 a1.sinks.k1.channel = c1 # Use a channel which buffers events in memory a1.channels.c1.type = memory a1.channels.c1.capacity = 1000000 a1.channels.c1.transactionCapacity = 10000 # Bind the source and sink to the channel a1.sources.r1.channels = c1
Start Zookeeper, Kafka, and then create Topic(baidu) to start consumers
- [123]zkServer.sh start
[123]kafka-server-start.sh /opt/lzj/kafka_2.11/config/server.properties
[1]kafka-topics.sh --zookeeper node01:2181 --create --replication-factor 3 --partitions 3 --topic baidu
[1]kafka-console-consumer.sh --zookeeper node01:2181 --from-beginning --topic baidu
- [123]zkServer.sh start
Open Flume
- [1]flume-ng agent -n a1 -f /opt/lzj/apache-flume-1.6.0-bin/options/f2k.conf -Dflume.root.logger=INFO,console
Start ping Baidu script
- ping www.baidu.com >> /var/bdp/baidu.ping 2>&1 &
Thank you for your recognition and support. Xiaobian will continue to forward the high-quality articles of Le byte