*1 * ***** 0 * * * introduction
Why index?
In general application systems, the read-write ratio is about 10:1, and there are few performance problems in insert operations and general update operations. In the production environment, we encounter the most and most prone to problems, or some complex query operations. Therefore, the optimization of query statements is obviously the top priority. When it comes to accelerating query, we have to mention index.
What is an index?
Index is also called "key" or "key" (primary key, unique key and another index key) in MySQL. It is a data structure used by the storage engine to quickly find records. Index is very important for good performance, especially when the amount of data in the table is increasing, the impact of index on performance becomes more and more important, reducing io times and accelerating queries. (among them, the primary key and unique key not only have the effect of accelerating query, but also have the effect of constraint. The primary key is not empty and unique, and the unique key is unique, while the index key only has the effect of accelerating query and has no constraint effect.)
Index optimization should be the most effective means to optimize query performance. Indexing can easily improve query performance by several orders of magnitude.
The index is equivalent to the phonetic order table of the dictionary. If you want to look up a word, if you don't use the phonetic order table, you need to look up it page by page from hundreds of pages.
Emphasis: once the index is created for the table, it is better to check the index first in future queries, and then find the data according to the index positioning results
30
10 40
5 15 35 66
1 6 11 19 21 39 55 100
Do you misunderstand the index?
Indexing is an important aspect of application design and development. If there are too many indexes, application performance may be affected. Too few indexes will have an impact on query performance. To find a balance, it is very important to the performance of the application. Some developers always think of adding indexes after the fact -- I always think this is due to a wrong development model. If you know the use of data, you should add indexes where needed from the beginning. Developers often use the database at the application level, such as writing SQL statements and stored procedures. They may not even know the existence of the index, or think it's enough to add it to the relevant DBA afterwards. DBAs often do not understand the data flow of the business, and adding indexes requires monitoring a large number of SQL statements to find problems. The time required for this step must be much longer than that required for adding indexes initially, and some indexes may be omitted. Of course, the more indexes are not the better. I once encountered such a problem: iostat of a MySQL server shows that the disk utilization rate has been at 100%. After analysis, it is found that the developers add too many indexes. After deleting some unnecessary indexes, the disk utilization rate immediately drops to 20%. It can be seen that the addition of indexes is also very technical.
*Principle of 2 * ***** 0 * * * two index
I. indexing principle
The purpose of index is to improve query efficiency. It is the same as the directory we use to consult books: first locate the chapter, then locate a section under the chapter, and then find the number of pages. Similar examples include: look up the dictionary, train number, plane flight, etc. it doesn't matter if you can't understand the following contents. Just understand the truth of this directory. Do you think that the book directory accounts for the number of pages? Should this page also be stored in the hard disk and take up hard disk space. Think again, if you build an index or directory quickly without data, or if there is already a lot of data, then build an index. Which is fast must be fast when there is no data, because if you have a lot of data, do you want to traverse all the data and then build an index according to the data. If you think about it again, it is faster to add data after the index is established, or it is faster to add data when there is no index. What is the index used for? It is used to speed up the query. What impact will it have on your data writing? It must be slower, because whenever you add some new data, you need to make a new index or storytelling directory, Therefore, although the index will speed up the query, it will reduce the efficiency of writing.
Impact of index
1. If there is a large amount of data in the table, the speed of creating the index will be very slow
2. After the index is created, the query performance of the table will be greatly improved, but the write performance will be reduced
The essence is: filter out the final desired results by constantly narrowing the range of data you want to obtain, and turn random events into sequential events. In other words, with this indexing mechanism, we can always lock the data in the same way.
The database is the same, but it is obviously much more complex, because it is faced with not only equivalent query, but also range query (>, <, between, in), fuzzy query (like), union query (or), etc. How should the database deal with all the problems? Let's recall the example of a dictionary. Can we divide the data into segments and then query them in segments? In the simplest way, if 1000 pieces of data are divided into the first segment from 1 to 100, the second segment from 101 to 200, and the third segment from 201 to 300... In this way, you can find the third segment for the 250 pieces of data, and 90% of the invalid data is removed at once. But if it's a record of 10 million, how many paragraphs are better? Students with a little basic algorithm will think of the search tree. Its average complexity is lgN and has good query performance. But here we ignore a key problem. The complexity model is based on the same operation cost every time. The database implementation is complex. On the one hand, the data is stored on the disk. On the other hand, in order to improve the performance, part of the data can be read into the memory for calculation every time, because we know that the cost of accessing the disk is about 100000 times that of accessing the memory, so a simple search tree is difficu lt to meet complex application scenarios.
II. Disk IO and read ahead
As mentioned earlier, disk IO and pre reading are briefly introduced here. Disk data reading depends on mechanical movement. The time spent reading data each time can be divided into three parts: seek time, rotation delay and transmission time. Seek time refers to the time required for the magnetic arm to move to the specified track. Mainstream disks are generally less than 5ms; The rotation delay is the disk speed we often hear about. For example, a disk 7200 RPM means that it can rotate 7200 times per min ute, that is, 120 times per second. The rotation delay is 1/120/2 = 4.17ms, That's half a lap (there are two times here: the average seek time, which is limited by the current physical level, is about 5ms. When you find the track, you also need to find the point where your data exists, the seek time. An average value of the seek time is the half turn time. This half turn time is called the average delay time. Then the average delay time plus the average seek time is what you find The average time consumed by a data is about 9ms. In fact, the mechanical hard disk is mainly slow in these two times. When finding the data and copying the data to the memory, the time is very short, which is about the same as the speed of light); Transmission time refers to the time to read or write data from or to the disk, generally in a few tenths of a millisecond, which can be ignored relative to the first two times. So the time to access a disk, that is, the time to perform an IO on a disk is about 5+4.17 = 9ms, which sounds good, but you should know that a 500 MIPS (Millennium instructions per second) machine can execute 500 Million Instructions Per Second, because the instructions rely on the nature of electricity. In other words, the cpu can execute about 4.5 million instructions during the time consumed to perform an IO, The database often has 100000 or even tens of millions of data, and the time of 9 milliseconds each time is obviously a disaster, so we should find ways to reduce the number of Io. The following figure is a comparison diagram of computer hardware delay for your reference:

Considering that disk IO is a very expensive operation, the computer operating system has made some optimization. During an IO, not only the data of the current disk address, but also the adjacent data are read into the memory buffer, because the principle of local pre reading tells us that when the computer accesses the data of an address, the adjacent data will also be accessed soon. The data read by each IO is called a page. The specific data size of a page is related to the operating system, generally 4k or 8k, that is, when we read the data in a page, there is actually only one io. This theory is very helpful for the data structure design of the index.
*Data structure of 3 * ***** 0 * * * three indexes
We talked about the basic principle of index, the complexity of database and the relevant knowledge of operating system. The purpose is to let you know. Now let's see how index can reduce IO and speed up query. Any data structure is not created out of thin air. It must have its background and usage scenarios. Let's summarize what we need this data structure to do. In fact, it is very simple, that is, control the disk IO times in a small order of magnitude, preferably a constant order of magnitude, every time we look for data. So we think if a highly controllable multi-channel search tree can meet the demand? In this way, B + tree came into being (B + tree is evolved from balanced binary tree and B tree through binary search tree. Wait until the algorithm is discussed later. At this stage, you can probably understand it. Don't go deep ~ ~).

As shown in the figure above, it is a b + tree. The top layer is the root, the middle is the branch, and the bottom is the leaf node. For the definition of b + tree, see B + tree , here are just some key points. Light blue blocks are called a disk block or a block block. This is what the operating system reads into memory at an IO. A block corresponds to four sectors, You can see that each disk block contains several data items (shown in dark blue, how much data is contained in a disk block, and a dark blue block represents a data, but it is not data, which is explained later) and pointers (shown in yellow, look at the top one. P1 indicates the position of the data smaller than the dark blue 17 above. Look at the left block pointed to by its pointer. The data in it is smaller than 17, and P2 points to the disk block larger than 17 and smaller than 35). For example, disk block 1 contains data items 17 and 35, including pointers P1, P2 and P3. P1 indicates the disk block smaller than 17, P2 represents a disk block between 17 and 35, and P3 represents a disk block greater than 35. Real data exists in leaf nodes, i.e. 3, 5, 9, 10, 13, 15, 28, 29, 36, 60, 75, 79, 90 and 99. Non leaf nodes only store real data, and only store data items that guide the search direction. For example, 17 and 35 do not really exist in the data table.
###Search process of b + tree
As shown in the figure, if you want to find the data item 29, first load the disk block 1 from the disk into the memory. At this time, an IO occurs. Use the binary search in the memory to determine that the 29 is between 17 and 35, lock the P2 pointer of disk block 1, and the memory time is negligible because it is very short (compared with the IO of the disk), Load disk block 3 from disk to memory through the disk address of P2 pointer of disk block 1, and the second IO occurs. 29 is between 26 and 30. Lock the P2 pointer of disk block 3, load disk block 8 to memory through the pointer, and the third IO occurs. At the same time, do a binary search in memory to find 29, and end the query. There are three IOS in total. The real situation is that the three-tier b + tree can represent millions of data. If millions of data searches only need three IO, the performance improvement will be huge. If there is no index and each data item needs one IO, a total of millions of IO are required. Obviously, the cost is very high. In addition to leaf nodes, other tree roots and branches store data indexes. They exist for you to establish the relationship between such data.
###b + tree properties
1**. The index field should be as small as possible * *: through the above analysis, we know that the IO times depend on the height h or level of the b + number. This height or level is the IO times you query the data every time. Assuming that the data in the current data table is N and the number of data items in each disk block is m, there is h = ㏒ (m+1)N. when the amount of data N is certain, the larger m, the smaller h; M = size of disk block / size of data item. The size of disk block, that is, the size of a data page, is fixed. If the space occupied by data items is smaller, the number of data items is more, and the height of the tree is lower. This is why each data item, that is, the index field, should be as small as possible. For example, int occupies 4 bytes, which is half less than bigint 8 bytes. This is why the b + tree requires that the real data be placed in the leaf node instead of the inner node. Once placed in the inner node, the data items of the disk block will decrease significantly, resulting in the increase of the tree. When the data item is equal to 1, it will degenerate into a linear table.
For example, if you only store two data in each leaf node, what do you do if you want to add two more data

Therefore, we need to build the tree as low as possible, because the size of each disk block is certain, which means that the larger the size of the single data in our single database, the better or the smaller the better. Think about it, the disk blocks of your leaf node are full of two data. If your data is larger, you can only put one data in each disk block, In this way, with the increase of your data volume, your tree will be higher. We should find ways to reduce the number of layers of the tree and improve the efficiency. Therefore, we should make the size of each data as small as possible, which means that the more data you store in each disk block, the fewer levels of your tree, and the lower the tree, right. And the larger the amount of data, the more disk blocks you need, and the higher the tree level you need, so we should use fewer disk blocks to load more data items as much as possible, so that the height of the tree can be reduced. How can we load more data items? Of course, the smaller your data items, the more data your disk blocks hold, So if there are many fields in a table, what field should we use to build the index? If you have id field, name field, description information field, etc., which field should you use to build the index? Of course, it's id field. Think about it, right? Because id is a number and takes up the least space.
2. The leftmost matching feature of the index: in short, after your data comes, start matching from the left of the data block, and those on the right of the matching will know this sentence ~ ~ ~ ~ ~. Let's continue to learn the following content. When the data item of the b + tree is a composite data structure, such as (name,age,sex), the b + number establishes the search tree from left to right. For example, when data such as (Zhang San, 20,F) is retrieved, the b + tree will give priority to comparing the name to determine the search direction in the next step. If the name is the same, then compare age and sex in turn to get the retrieved data; However, when there is no name data like (20,F), the b + tree does not know which node to query next, because name is the first comparison factor when establishing the search tree. You must search according to name first to know where to query next. For example, when retrieving data such as (Zhang San, F), the b + tree can use name to specify the search direction, but the next field age is missing, so we can only find the data whose name is equal to Zhang San, and then match the data whose gender is F. this is a very important property, that is, the leftmost matching feature of the index.
*4 * ***** 0 * * * four clustered indexes and auxiliary indexes
What is a clustered index? In fact, it is the primary key we are talking about. Before, we said that the tables of the Innodb storage engine must have a primary key. Remember why? We said... I don't remember. See below
**Remember what files the MyISAM storage engine generates on the hard disk when creating tables? Are there three frm. MYD. For the three files at the end of MYI, frm ends with a table structure, MyD ends with a data file, and MYI ends with an index file, that is, the index also exists on the hard disk. For InnoDB engine, create a table and generate it on the hard disk frm. For the two files at the end of the idb, what about the index? Can't InnoDB use the index? How is that possible? Have we ever created an index before? Are the primary key and unique key all called indexes? But where is the index file? The index cannot be in the table structure In the frm (what fields and types of these things) file, there is only one left The data file at the end of the idb contains the index. The index and data of the table of the InnoDB engine are in the same file. Therefore, I have always stressed that when using the InnoDB storage engine, each table needs to be given a primary key because the primary key is owned by the InnoDB storage engine idb files are used to organize the basis or method of storing data, that is, the InnoDB storage engine stores data for you according to the tree structure of the index by default. This kind of index is called clustered index, which is used when aggregating data and organizing data. InnoDB does this to speed up the query efficiency, because you often query data based on the primary key, and usually we use the ID field as the primary key. First, because the ID takes up little data space, and second, you often use the ID to query data. If your table has two fields, one ID and one name, and the ID is the primary key, when you query, if the condition behind where is name = how much, you will not use the effect of accelerating query brought by the primary key (auxiliary indexes other than the primary key are required). If you use where id = how much, It will find data for you according to the tree structure we just mentioned (of course, it is not only the data structure type of this tree structure), which can quickly help you locate the data block. The feature of this clustered index is that it will establish a tree structure based on the ID field, but the leaf node stores a complete record and a complete data in your table. Keep this in mind. I will talk about the concept of back to table when I introduce the auxiliary index later.
**
In the database, the height of the B + tree is generally at level 24, which means that it only needs 2 to 4 IO at most to find the row record of a key value, which is good. At present, the general mechanical hard disk can do at least 100 IOS per second. 24 IOS means that the query time is only 0.02 ~ 0.04 seconds.
The B + tree index in the database can be divided into clustered index and secondary index,
The same thing about clustered index and auxiliary index is that both clustered index and auxiliary index are in the form of B + tree, that is, the height is balanced, and the leaf node stores all data.
The difference between a clustered index and an auxiliary index is whether a leaf node stores an entire row of information
1. Clustered index
#The InnoDB storage engine represents the index organization table, that is, the data in the table is stored according to the primary key order. The clustered index is to construct a B + tree according to the primary key of each table. At the same time, the leaf node stores the row record data of the whole table, and the leaf node of the clustered index is also called the data page. This feature of clustered index determines that the data in the index organization table is also a part of the index. Like the B + tree data structure, each data page is linked through a two-way linked list.
#If no primary key is defined, MySQL takes the first unique index (unique) and only contains a non null column (NOT NULL) as the primary key. InnoDB uses it as the cluster index.
#If there is no such column, InnoDB will generate an ID value of six bytes, which is hidden and used as a cluster index.
#Since the actual data pages can only be sorted by one B + tree, each table can only have one clustered index. In how many cases does the query optimizer prefer clustered indexes. Because the clustered index can find data directly on the leaf node of the B + tree index. In addition, because the logical order of data is defined, clustered indexes can access queries for range values particularly quickly.

One of the advantages of clustered index: it is very fast in sorting and range searching of primary keys. The data of leaf nodes is the data that users want to query. If the user needs to find a table and query the last 10 user information, because the B + tree index is a two-way linked list, the user can quickly find the last data page and take out 10 records

#Referring to the sixth summary, the preparation stage of the test index is used to create table s1 mysql> desc s1; #There was no primary key at first +--------+-------------+------+-----+---------+-------+ | Field | Type | Null | Key | Default | Extra | +--------+-------------+------+-----+---------+-------+ | id | int(11) | NO | | NULL | | | name | varchar(20) | YES | | NULL | | | gender | char(6) | YES | | NULL | | | email | varchar(50) | YES | | NULL | | +--------+-------------+------+-----+---------+-------+ 4 rows in set (0.00 sec) mysql> explain select * from s1 order by id desc limit 10; #Using filesort, secondary sorting is required +----+-------------+-------+------------+------+---------------+------+---------+------+---------+----------+----------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-------+------------+------+---------------+------+---------+------+---------+----------+----------------+ | 1 | SIMPLE | s1 | NULL | ALL | NULL | NULL | NULL | NULL | 2633472 | 100.00 | Using filesort | +----+-------------+-------+------------+------+---------------+------+---------+------+---------+----------+----------------+ 1 row in set, 1 warning (0.11 sec) mysql> alter table s1 add primary key(id); #Add primary key Query OK, 0 rows affected (13.37 sec) Records: 0 Duplicates: 0 Warnings: 0 mysql> explain select * from s1 order by id desc limit 10; #After the primary key based clustered index is created, it has been sorted without secondary sorting +----+-------------+-------+------------+-------+---------------+---------+---------+------+------+----------+-------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-------+------------+-------+---------------+---------+---------+------+------+----------+-------+ | 1 | SIMPLE | s1 | NULL | index | NULL | PRIMARY | 4 | NULL | 10 | 100.00 | NULL | +----+-------------+-------+------------+-------+---------------+---------+---------+------+------+----------+-------+ 1 row in set, 1 warning (0.04 sec)
The second advantage of clustered index: range query, that is, if you want to find data within a certain range of the primary key, you can get the page range through the upper intermediate node of the leaf node, and then directly read the data page
mysql> alter table s1 drop primary key; Query OK, 2699998 rows affected (24.23 sec) Records: 2699998 Duplicates: 0 Warnings: 0 mysql> desc s1; +--------+-------------+------+-----+---------+-------+ | Field | Type | Null | Key | Default | Extra | +--------+-------------+------+-----+---------+-------+ | id | int(11) | NO | | NULL | | | name | varchar(20) | YES | | NULL | | | gender | char(6) | YES | | NULL | | | email | varchar(50) | YES | | NULL | | +--------+-------------+------+-----+---------+-------+ 4 rows in set (0.12 sec) mysql> explain select * from s1 where id > 1 and id < 1000000; #There is no clustered index. The estimated number of rows to be retrieved is as follows. explain is to estimate the execution efficiency of your sql +----+-------------+-------+------------+------+---------------+------+---------+------+---------+----------+-------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-------+------------+------+---------------+------+---------+------+---------+----------+-------------+ | 1 | SIMPLE | s1 | NULL | ALL | NULL | NULL | NULL | NULL | 2690100 | 11.11 | Using where | +----+-------------+-------+------------+------+---------------+------+---------+------+---------+----------+-------------+ 1 row in set, 1 warning (0.00 sec) mysql> alter table s1 add primary key(id); Query OK, 0 rows affected (16.25 sec) Records: 0 Duplicates: 0 Warnings: 0 mysql> explain select * from s1 where id > 1 and id < 1000000; #With clustered indexes, the estimated number of rows to be retrieved is as follows +----+-------------+-------+------------+-------+---------------+---------+---------+------+---------+----------+-------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-------+------------+-------+---------------+---------+---------+------+---------+----------+-------------+ | 1 | SIMPLE | s1 | NULL | range | PRIMARY | PRIMARY | 4 | NULL | 1343355 | 100.00 | Using where | +----+-------------+-------+------------+-------+---------------+---------+---------+------+---------+----------+-------------+ 1 row in set, 1 warning (0.09 sec)
2. Secondary index
When we query, we need to write the names of other fields except id behind where to query. For example, where name=xx can't use the efficiency of the primary key index. What to do, we need to add an auxiliary index to name.
Except for clustered indexes, other indexes in the table are secondary indexes (also known as non clustered indexes) (unique key and index key). The difference from clustered indexes is that the leaf node of the Secondary Index does not contain all the data of row records.
The leaf node stores the value of the primary key field of the corresponding data. In addition to the key value, the index row in each leaf node also contains a bookmark. In fact, this bookmark can be understood as a data of {name field ', name value and primary key id value}. This bookmark is used to tell the InnoDB storage engine where to find the row data corresponding to the index. If we want name after select, we can directly find the corresponding name value in the leaf node of the auxiliary index, for example: select name from tb1 where name = 'xx'; This xx value can be found directly in the leaf node of the auxiliary index, which can also be called the overlay index. If the field after your select is not name, for example: select age from tb1 where name = 'xx'; In other words, I can't get the age value directly through the leaf node of the auxiliary index. I need to find a complete record through the aggregation index through the value of the primary key id saved in the leaf node of the auxiliary index, and then take out the age value from this record. This operation sometimes becomes a table back operation, that is, I go back and check it again from the beginning, This kind of query is also very efficient, but it is lower than the overlay index. Again, the leaf node of the secondary index can find the data you want, which can be called the overlay index. Let's look at the following explanation:
Because the InnoDB storage engine is an index organization table, the bookmark of the auxiliary index of the InnoDB storage engine is the clustered index key or the value called the primary key of the corresponding row data. As shown below

The existence of secondary indexes does not affect the organization of data in the clustered index. Therefore, there can be multiple secondary indexes on each table, but only one clustered index. When searching for data through the auxiliary index, the InnoDB storage engine will traverse the auxiliary index and obtain the primary key that only wants the primary key index through the leaf level pointer, and then find a complete row record through the primary key index. This search is also very efficient.
For example, if you search data in a secondary index tree with a height of 3, you need to traverse the secondary index tree three times to find the specified primary key. If the height of the clustered index tree is also 3, you need to search the clustered index tree three times to finally find the page where a complete row of data is located, Therefore, a total of 6 logical IO accesses are required to get the final data page.

The concept is basically finished. Let's do some practical operation and look at the following contents~~~~
*5 * ***** 0 * * * V MySQL index management
One function
#1. The function of index is to speed up search #2. The primary key, unique and unique indexes in MySQL are also indexes. These indexes not only speed up the search, but also have the function of constraints
II. Indexes commonly used in MySQL
General index INDEX: Accelerated search
Unique index:
-primary key PRIMARY KEY: Accelerated search+Constraint (not null and cannot be repeated)
-unique index UNIQUE:Accelerated search+Constraint (cannot be repeated)
Federated index:
-PRIMARY KEY(id,name):Federated primary key index
-UNIQUE(id,name):Federated unique index
-INDEX(id,name):Joint general index
Index operation:
Add primary key index: Add when creating: Pay attention when adding indexes,Add to the field with small data size in the field,Add to the field with high data discrimination in the field. How to add a clustered index Create is add Create table t1( Id int primary key, ) Create table t1( Id int, Primary key(id) ) Add after table creation Alter table Table name add primary key(id) Delete primary key index: Alter table Table name drop primary key; unique index: Create table t1( Id int unique, ) Create table t1( Id int, Unique key uni_name (id) ) Add a unique index after the table is created: alter table s1 add unique key u_name(id); delete: Alter table s1 drop index u_name; General index: establish: Create table t1( Id int, Index index_name(id) ) Alter table s1 add index index_name(id); Create index index_name on s1(id); delete: Alter table s1 drop index u_name; DROP INDEX Index name ON Table name;
Application scenarios of various indexes:
For example, you are making a membership card system for a shopping mall. The system has a membership table There are the following fields: Member number INT Member name VARCHAR(10) Membership ID number VARCHAR(18) Member telephone VARCHAR(10) Member Address VARCHAR(50) Member notes TEXT Then this member number is used as the primary key PRIMARY If the member name needs to be indexed, it is ordinary INDEX Membership ID number can be chosen if index is to be built. UNIQUE (Unique (duplicate is not allowed) #In addition, there is a full-text index, FULLTEXT If you need to build an index, you can choose full-text search. When used to search for a long article, the effect is the best. Used in relatively short text, if only one or two lines, ordinary INDEX it's fine too. But in fact, we will not use full-text search MySQL Instead of this index, third-party software will be selected, such as Sphinx,Dedicated to full-text search. #Others, such as SPATIAL, can be understood and hardly used
Two types of hash and btree for three indexes
#When creating the above index, we can specify the index type for it, which can be divided into two categories hash Type index: single query is fast and range query is slow btree Index of type: b+Tree, the more layers, the exponential growth of data volume (we use it because innodb (it is supported by default) #Different storage engines support different index types InnoDB Supports transaction, row level locking, and B-tree,Full-text Index, not supported Hash Indexes; MyISAM Transaction is not supported, table level locking is supported, and B-tree,Full-text Index, not supported Hash Indexes; Memory Transaction is not supported, table level locking is supported, and B-tree,Hash Index, not supported Full-text Indexes; NDB Supports transaction, row level locking, and Hash Index, not supported B-tree,Full-text Equal index; Archive Transaction and table level locking are not supported B-tree,Hash,Full-text Equal index;
IV. syntax for creating / deleting indexes
#Method 1: when creating a table
CREATE TABLE Table name (
Field name 1 data type [Integrity constraints],
Field name 2 data type [Integrity constraints],
[UNIQUE | FULLTEXT | SPATIAL ] INDEX | KEY
[Index name] (Field name[(length)] [ASC |DESC])
);
#Method 2: CREATE creates an index on an existing table
CREATE [UNIQUE | FULLTEXT | SPATIAL ] INDEX Index name
ON Table name (Field name[(length)] [ASC |DESC]) ;
#Method 3: ALTER TABLE creates an index on an existing table
ALTER TABLE Table name ADD [UNIQUE | FULLTEXT | SPATIAL ] INDEX
Index name (Field name[(length)] [ASC |DESC]) ;
#Delete index: DROP INDEX index name ON table name;
Look at the following demonstration:
#Mode 1
create table t1(
id int,
name char,
age int,
sex enum('male','female'),
unique key uni_id(id),
index ix_name(name) #index has no key
);
#Mode II
create index ix_age on t1(age);
#Mode III
alter table t1 add index ix_sex(sex);
#see
mysql> show create table t1;
| t1 | CREATE TABLE `t1` (
`id` int(11) DEFAULT NULL,
`name` char(1) DEFAULT NULL,
`age` int(11) DEFAULT NULL,
`sex` enum('male','female') DEFAULT NULL,
UNIQUE KEY `uni_id` (`id`),
KEY `ix_name` (`name`),
KEY `ix_age` (`age`),
KEY `ix_sex` (`sex`)
) ENGINE=InnoDB DEFAULT CHARSET=latin1
*6 * * * * * 0 * * * six test indexes
One preparation
#1. Preparation form
create table s1(
id int,
name varchar(20),
gender char(6),
email varchar(50)
);
#2. Create a stored procedure to insert records in batches
delimiter $$ #Declare that the end symbol of the stored procedure is$$
create procedure auto_insert1()
BEGIN
declare i int default 1;
while(i<3000000)do
insert into s1 values(i,'egon','male',concat('egon',i,'@oldboy'));
set i=i+1;
end while;
END$$ #$$end
delimiter ; #Redeclare semicolon as closing symbol
#3. View stored procedures
show create procedure auto_insert1\G
#4. Call stored procedure
call auto_insert1();
Second, test the query speed without index
#No index: mysql doesn't know whether there are records with ID equal to 333333, or whether there are several records with id = 333333. It can only scan the data table from beginning to end. At this time, how many disk blocks need to perform many IO operations, so the query speed is very slow mysql> select * from s1 where id=333333333; Empty set (0.33 sec)
3. When there is a large amount of data in the table, the speed of establishing an index for a field segment will be very slow

Or use alter table s1 add primary key(id); Adding a primary key and building an index is very slow.
4. After the index is established, when this field is used as the query condition, the query speed is significantly improved

PS:
1. mysql goes to the index table first. According to the search principle of b + tree, it quickly finds that the record with id equal to 333 does not exist, and the IO is greatly reduced, so the speed is significantly improved
2. We can find the table in the data directory of mysql. We can see that it takes up more hard disk space
3. It should be noted, as shown in the figure below

V. summary
#1. You must create an index for the fields of the search criteria, such as select * from s1 where id = 333; You need to index the ID #2. When there is already a large amount of data in the table, the index building will be very slow and occupy hard disk space, and the query speed will be accelerated after building such as create index idx on s1(id);All data in the table is scanned, and then id Create an index structure for data items and store them in a table on the hard disk. After the construction, the query will be very fast. #3. It should be noted that the index of innodb table will be stored in S1 In the IBD file, and the index of the myisam table will have a separate index file table1 MYI MySAM The index file and the data file are separated, and the index file only saves the address of the data record. And in innodb In, the table data file itself is based on B+Tree(BTree Namely Balance True)An index structure of the organization, the leaf node of the tree data The field holds a complete data record. Of this index key Is the primary key of the data table, so innodb The table data file itself is the primary index. because inndob The data files of are aggregated according to the primary key, so innodb The table must have a primary key( Myisam Yes, if not explicitly defined, then mysql The system will automatically select a column that can uniquely identify the data record as the primary key. If such a column does not exist, then mysql Will automatically innodb The table generates an implicit field as the primary key. The length of this field is 6 bytes and the type is long integer.
If you think about it, it must be good to add all the indexes. First, when we add the indexes, the query is fast, but the writing is slow. Remember, every time you insert a new record, your entire index structure will change. Therefore, if you add the indexes indiscriminately, you will find that even if few people on your website are registering, In other words, there are few operations to write data, your disk IO will remain high, and the disk is turning crazy, because every time you insert a piece of data, our index needs to be rebuilt, and the rebuilt index needs to be written into the hard disk. Remember the speed when we index the three million pieces of data? Every time you have to take out all the data, make a data structure, and then write it back to the hard disk. That is, you have to go through a lot of IO to achieve this. Therefore, a disadvantage of indiscriminately adding indexes is that your disk IO will be very high and lead to poor efficiency. Therefore, we need to learn how to correctly index.
*7 * ***** 0 * * * VII. Use index correctly
One index miss
****It doesn't mean that when we create an index, we will speed up the query speed. If * * * we want to use the index to achieve the desired effect of improving the query speed, we must follow the following questions when adding an index*
**
**1. The scope problem, or the condition is not clear, and these symbols or keywords appear in the condition: * * >, > =, <, < =,! = between…and…,*like,*
Greater than sign, less than sign

If you write where id > 1 and ID < 1000000; You will find that with the increase of your scope, the speed will be slower and slower, which will be multiplied.
Not equal to=
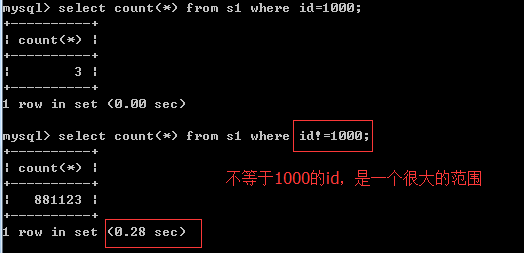
between ...and...

Like # when measuring like, you can first remove the primary key index of id, then measure like, then add index key, and then measure like. I know you forgot. Look at the statement: create index email_index on s1(email) ,email_index is the index name, on and S1 are the table name (field name). You will find that the time to build the index is also very slow, desc s1; Check whether the index has been created successfully. Check whether the key field has a mul. This indicates that the index has been created successfully.
like = if there are no special characters or wildcards, it will be an effect and an exact match.

#When using like, the wildcard is written in the front, which also needs to be fully matched, and then compare the second character of the string, the leftmost matching rule, remember.
2. Try to select the column with high discrimination as the index. The formula of discrimination is count(distinct col)/count(*), which indicates the proportion of fields that are not repeated. The larger the proportion, the fewer records we scan. The discrimination of the only key is 1, and the discrimination of some status and gender fields may be 0 in front of big data. Someone may ask, what is the empirical value of this proportion? It is also difficult to determine this value in different usage scenarios. Generally, the fields that need to be join ed are required to be more than 0.1, that is, an average of 1 scan 10 records
#First, delete all the indexes in the table. Let's concentrate on the problem of discrimination mysql> desc s1; +--------+-------------+------+-----+---------+-------+ | Field | Type | Null | Key | Default | Extra | +--------+-------------+------+-----+---------+-------+ | id | int(11) | YES | MUL | NULL | | | name | varchar(20) | YES | | NULL | | | gender | char(5) | YES | | NULL | | | email | varchar(50) | YES | MUL | NULL | | +--------+-------------+------+-----+---------+-------+ 4 rows in set (0.00 sec) mysql> drop index a on s1; Query OK, 0 rows affected (0.20 sec) Records: 0 Duplicates: 0 Warnings: 0 mysql> drop index d on s1; Query OK, 0 rows affected (0.18 sec) Records: 0 Duplicates: 0 Warnings: 0 mysql> desc s1; +--------+-------------+------+-----+---------+-------+ | Field | Type | Null | Key | Default | Extra | +--------+-------------+------+-----+---------+-------+ | id | int(11) | YES | | NULL | | | name | varchar(20) | YES | | NULL | | | gender | char(5) | YES | | NULL | | | email | varchar(50) | YES | | NULL | | +--------+-------------+------+-----+---------+-------+ 4 rows in set (0.00 sec)

We write stored procedures as tables s1 Batch add records, name Field values are egon,in other words name The discrimination of this field is very low( gender The field is the same, and we'll deal with it later) memory b+The tree structure and query speed are inversely proportional to the height of the tree. To control the height of the tree very low, you need to ensure that the data items in a certain layer are arranged in order from left to right and from small to large, that is, 1 on the left<Left 2<Left 3<... For fields with low discrimination, the size relationship cannot be found because the values are equal. There is no doubt that you want to use b+When the tree stores these equivalent data, it can only increase the height of the tree. The lower the field discrimination, the higher the height of the tree. In extreme cases, the values of the index fields are the same, then b+The tree almost became a stick. This is the extreme case in this case, name All field values are'egon' #Now we come to a conclusion: when indexing fields with low discrimination, the height of the index tree will be very high. However, what is the impact of this experience??? #1: If the condition is name='xxxx ', it must be possible to judge that' XXXX 'is not in the index tree at the first time (because all values in the tree are' egon ', you will know that you are not in the index tree when you look at the first entry), so the query speed is very fast #2: If the condition is just name='egon ', when querying, we can never get a clear range from a certain position in the tree. We can only look down, look down, look down... This is not much different from the IO times of full table scanning, so the speed is very slow
3 = and in can be out of order. For example, a = 1 and b = 2 and c = 3 can establish (a,b,c) indexes in any order. The mysql query optimizer will help you optimize them into a form that can be recognized by the index
4. The index column cannot participate in the calculation. Keep the column "clean", such as from_unixtime(create_time) = '2014-05-29' can't use the index. The reason is very simple. All the field values in the data table are stored in the b + tree, but when retrieving, you need to apply functions to all elements to compare. Obviously, the cost is too high. So the statement should be written as create_time = unix_timestamp(’2014-05-29’)
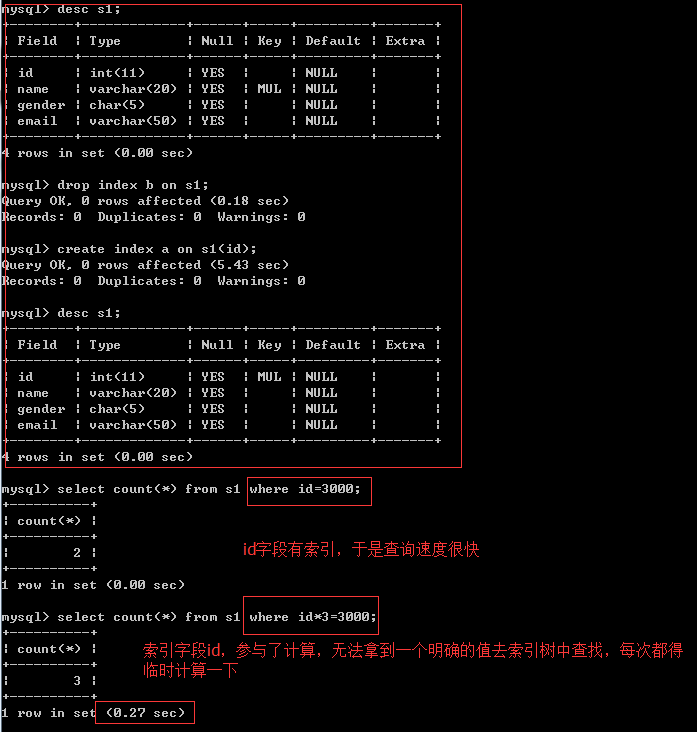
Write the above conditions as where id = 3000/3; You will find that the speed becomes very fast, because the number after the equals sign is calculated before comparison. You don't need to calculate it every time. It's the same as directly equal to a constant, so it's very fast. The conclusion is not to involve your index fields in the calculation.
5 and/or
#1. Logic of and and or
Condition 1 and Condition 2:All conditions are true, but if one condition is not true, the final result is not true
Condition 1 or Condition 2:As long as one condition holds, the final result holds
#2. How and works
Conditions:
a = 10 and b = 'xxx' and c > 3 and d =4
Indexes:
Make joint index(d,a,b,c)
working principle: #If you are looking for it, how will you find it? Do you compare it one by one from left to right? First of all, you can't be sure whether the field a has an index. Even if there is an index, you may not be able to ensure that the index is hit (the so-called hit index means that the index is applied). mysql won't be so stupid. See how mysql finds it below:
The essential principle of index is to continuously reduce the search range, and then process it. For continuous multiple indexes and: mysql An index field with high discrimination will be found from left to right according to the joint index(This allows you to quickly lock a small range),Speed up query by d—>a->b->c Order of
#3. How or works
Conditions:
a = 10 or b = 'xxx' or c > 3 or d =4
Indexes:
Make joint index(d,a,b,c)
working principle:
As long as one match is successful, so for consecutive multiple matches or: mysql It will judge from left to right according to the order of conditions, i.e a->b->c->d
The index should be added to the field with high data discrimination

When the conditions on the left are true but the discrimination of the index field is low (this is the case for name and gender), an index field with high discrimination will be found to the right to speed up the query

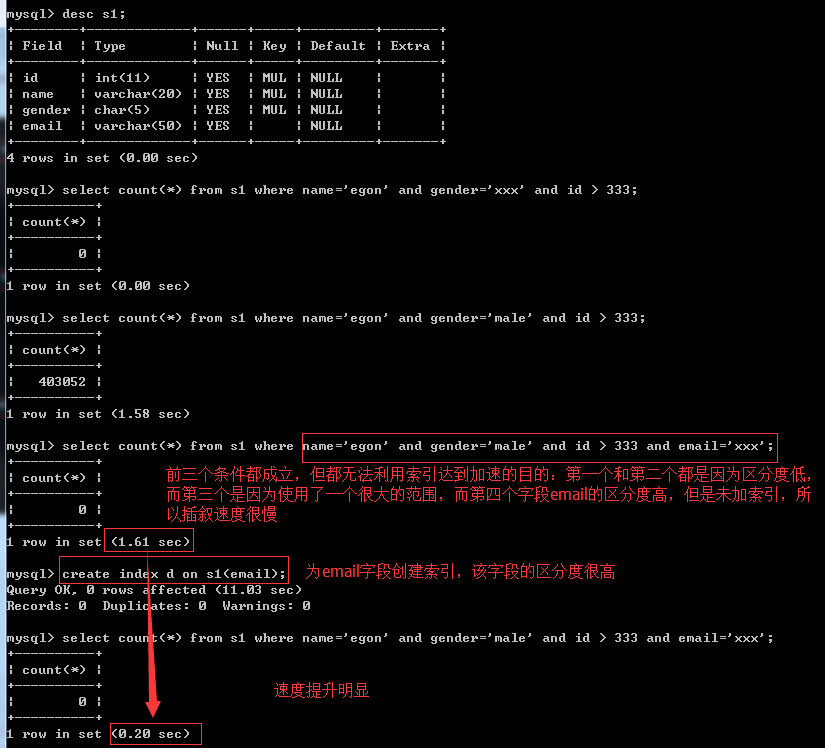
After analysis, when the conditions are name = 'egon' and gender = 'male' and ID > 333 and email ='xxx ', we don't need to quote the fields of the first three conditions at all, because we can only use the indexes of email fields, and the indexes of the first three fields will reduce our query efficiency

If you are still interested, you can study the log of slow sql query of mysql and learn how to filter the operation and configuration of slow sql. The way to optimize slow sql is to modify the logic of your query statement, and a more effective way is indexing or joint indexing.
6. The leftmost prefix matching principle (see Section 8 for details). It is a very important principle. For the combined index, mysql will match to the right until it meets the range query (>, <, between and like) (it means that the range is large and the indexing speed is slow). For example, a = 1 and B = 2 and C > 3 and d = 4 if the index in (a,b,c,d) order is established, D does not use the index, If the index of (a,b,d,c) is established, it can be used. The order of a,b,d can be adjusted arbitrarily.

7. Other conditions
- Use function
select * from tb1 where reverse(email) = 'egon';
- Inconsistent type
If the column is of string type, the incoming condition must be enclosed in quotation marks, otherwise...
select * from tb1 where email = 999;
#If the sorting condition is index, the select field must also be an index field, otherwise it cannot be hit
- order by
select name from s1 order by email desc;
When sorting by index, select If the field of the query is not an index, the speed is still very slow
select email from s1 order by email desc;
Special: if the primary key is sorted, it is still very fast:
select * from tb1 order by nid desc;
- Composite index leftmost prefix
If the combined index is:(name,email)
name and email -- Hit index
name -- Hit index
email -- Missed index
- count(1)or count(column)replace count(*)stay mysql There is no difference
- create index xxxx on tb(title(19)) #text type, length must be specified
II. Other precautions
- Avoid using select * - count(1)or count(column) replace count(*) - When creating tables char replace varchar - The field order of the table is fixed, and the field with fixed length takes precedence - Composite index replaces multiple single column indexes (when multiple conditional queries are often used) - Try to use short indexes - Use connection( JOIN)Instead of subquery(Sub-Queries) - When connecting tables, pay attention to the consistency of condition types - Index hash value (less repetition) is not suitable for indexing, for example, gender is not suitable
*8 * ***** 0 * * * eight joint indexes and overlay indexes
I. joint index
Joint index refers to the combination of multiple columns on the table to make an index. When you query, the condition fields behind where keep changing, and you want to give each field an embarrassing problem. The creation method of a joint index is the same as that of a single index, except that there are multiple index columns, as shown below
mysql> create table t(
-> a int,
-> b int,
-> primary key(a),
-> key idx_a_b(a,b)
-> );
Query OK, 0 rows affected (0.11 sec)

So when do I need to use a federated index? Before discussing this issue, let's look at the results within the federated index. In essence, a joint index is a b + tree. The difference is that the number of key values of the joint index is not 1, but > = 2. Next, let's discuss the joint index composed of two integer columns. Assume that the names of the two key values are a and b respectively, as shown in the figure

It can be seen that this is not different from the B + tree of a single key we saw before. The key values are sorted. All data can be read out logically through the leaf node. For the above example, that is, (1,1), (1,2), (2,1), (2,4), (3,1), (3,2), the data are stored in the order of (a,b).
Therefore, for the query select * from table where a=xxx and b=xxx, the joint index (a,b) can obviously be used. For the query select * from table where a=xxx of a single column a, the index (a,b) can also be used.
However, for the query of column B, select * from table where b=xxx, the (a,b) index cannot be used. In fact, it is not difficult to find the reason. The values of B on the leaf node are 1, 2, 1, 4, 1 and 2, which are obviously not sorted. Therefore, the (a,b) index cannot be used for the query of column B
**Note one principle of creating a joint index: * * the index has a leftmost matching principle, so when creating a joint index, place the highly differentiated index on the leftmost side and rank it down in turn, and put the range query conditions back as far as possible.
The second advantage of the joint index is that when the first key is the same, the second key has been sorted. For example, in many cases, the application needs to query the shopping situation of a user, sort by time, and finally take out the last three purchase records. At this time, using the joint index can help us avoid one more sorting operation, Because the index itself has been sorted in the leaf node, as follows
#===========Preparation table==============
create table buy_log(
userid int unsigned not null,
buy_date date
);
insert into buy_log values
(1,'2009-01-01'),
(2,'2009-01-01'),
(3,'2009-01-01'),
(1,'2009-02-01'),
(3,'2009-02-01'),
(1,'2009-03-01'),
(1,'2009-04-01');
alter table buy_log add key(userid);
alter table buy_log add key(userid,buy_date);
#===========Verify==============
mysql> show create table buy_log;
| buy_log | CREATE TABLE `buy_log` (
`userid` int(10) unsigned NOT NULL,
`buy_date` date DEFAULT NULL,
KEY `userid` (`userid`),
KEY `userid_2` (`userid`,`buy_date`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 |
#You can see that it is possible_keys has two indexes available here: the single index userid and the joint index userid_2. However, the optimizer finally chose to use userid as the key. Because the leaf node of the index contains a single key value, theoretically, a page should store more records
mysql> explain select * from buy_log where userid=2;
+----+-------------+---------+------+-----------------+--------+---------+-------+------+-------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+---------+------+-----------------+--------+---------+-------+------+-------+
| 1 | SIMPLE | buy_log | ref | userid,userid_2 | userid | 4 | const | 1 | |
+----+-------------+---------+------+-----------------+--------+---------+-------+------+-------+
1 row in set (0.00 sec)
#Next, suppose you want to retrieve the last three purchase records with userid 1, using the joint index userid_2, because in this index, when userid=1, buy_ The dates have been sorted
mysql> explain select * from buy_log where userid=1 order by buy_date desc limit 3;
+----+-------------+---------+------+-----------------+----------+---------+-------+------+--------------------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+---------+------+-----------------+----------+---------+-------+------+--------------------------+
| 1 | SIMPLE | buy_log | ref | userid,userid_2 | userid_2 | 4 | const | 4 | Using where; Using index |
+----+-------------+---------+------+-----------------+----------+---------+-------+------+--------------------------+
1 row in set (0.00 sec)
#ps: if the sorting of extra shows Using filesort, it means that secondary sorting is required after finding the data (the following query statement does not first locate the range with where userid=3, so it is useless even if the index is hit, and secondary sorting is required)
mysql> explain select * from buy_log order by buy_date desc limit 3;
+----+-------------+---------+-------+---------------+----------+---------+------+------+-----------------------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+---------+-------+---------------+----------+---------+------+------+-----------------------------+
| 1 | SIMPLE | buy_log | index | NULL | userid_2 | 8 | NULL | 7 | Using index; Using filesort |
+----+-------------+---------+-------+---------------+----------+---------+------+------+-----------------------------+
#For joint indexes (a,b), the following statements can directly use the index without secondary sorting
select ... from table where a=xxx order by b;
#Then, for the joint index (a,b,c), the following statements can also get the results directly through the index
select ... from table where a=xxx order by b;
select ... from table where a=xxx and b=xxx order by c;
#However, for the joint index (a,b,c), the following statements cannot get the results directly through the index. You also need to perform a filesort operation by yourself, because the index (a, c) is not sorted
select ... from table where a=xxx order by c;
Second coverage index
The InnoDB storage engine supports covering index (or index covering), that is, query records can be obtained from the secondary index without querying the records in the clustered index.
One advantage of using an overlay index is that the auxiliary index does not contain all the information of the whole row of records, so its size is much smaller than the clustered index, so it can reduce a lot of IO operations
Note: the overlay index technology was first completed and implemented in the InnoDB Plugin, which means that the InnoDB storage engine does not support the overlay index feature for those whose InnoDB version is less than 1.0 or MySQL database version is less than 5.0
For the secondary index of the InnoDB storage engine, because it contains the primary key information, the data stored in its leaf node is (primary key1, primary key2,..., key1, key2,...). for example
select age from s1 where id=123 and name = 'egon'; #The id field has an index, but the name field has no index. The sql hit the index but did not overwrite it. You need to find the details in the clustered index. The best case is that the index field covers all, so it is easy to speed up the query and obtain the results through indexing ok Yes mysql> desc s1; +--------+-------------+------+-----+---------+-------+ | Field | Type | Null | Key | Default | Extra | +--------+-------------+------+-----+---------+-------+ | id | int(11) | NO | | NULL | | | name | varchar(20) | YES | | NULL | | | gender | char(6) | YES | | NULL | | | email | varchar(50) | YES | | NULL | | +--------+-------------+------+-----+---------+-------+ 4 rows in set (0.21 sec) mysql> explain select name from s1 where id=1000; #No index +----+-------------+-------+------------+------+---------------+------+---------+------+---------+----------+-------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-------+------------+------+---------------+------+---------+------+---------+----------+-------------+ | 1 | SIMPLE | s1 | NULL | ALL | NULL | NULL | NULL | NULL | 2688336 | 10.00 | Using where | +----+-------------+-------+------------+------+---------------+------+---------+------+---------+----------+-------------+ 1 row in set, 1 warning (0.00 sec) mysql> create index idx_id on s1(id); #Create index Query OK, 0 rows affected (4.16 sec) Records: 0 Duplicates: 0 Warnings: 0 mysql> explain select name from s1 where id=1000; #If the secondary index is hit but the index is not overwritten, you also need to find name from the clustered index +----+-------------+-------+------------+------+---------------+--------+---------+-------+------+----------+-------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-------+------------+------+---------------+--------+---------+-------+------+----------+-------+ | 1 | SIMPLE | s1 | NULL | ref | idx_id | idx_id | 4 | const | 1 | 100.00 | NULL | +----+-------------+-------+------------+------+---------------+--------+---------+-------+------+----------+-------+ 1 row in set, 1 warning (0.08 sec) mysql> explain select id from s1 where id=1000; #All the information is found in the secondary index. Using index stands for overwriting the index +----+-------------+-------+------------+------+---------------+--------+---------+-------+------+----------+-------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-------+------------+------+---------------+--------+---------+-------+------+----------+-------------+ | 1 | SIMPLE | s1 | NULL | ref | idx_id | idx_id | 4 | const | 1 | 100.00 | Using index | +----+-------------+-------+------------+------+---------------+--------+---------+-------+------+----------+-------------+ 1 row in set, 1 warning (0.03 sec)
Another benefit of overriding indexes is for some statistical problems. Table buy created based on the previous summary_ Log, the query plan is as follows
mysql> explain select count(*) from buy_log; +----+-------------+---------+-------+---------------+--------+---------+------+------+-------------+ | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | +----+-------------+---------+-------+---------------+--------+---------+------+------+-------------+ | 1 | SIMPLE | buy_log | index | NULL | userid | 4 | NULL | 7 | Using index | +----+-------------+---------+-------+---------------+--------+---------+------+------+-------------+ 1 row in set (0.00 sec)
The innodb storage engine does not choose to query the clustered index for statistics. Due to buy_ The log table has an auxiliary index, which is much smaller than the clustered index. Selecting an auxiliary index can reduce IO operations. Therefore, the optimizer selects the above key as the userid auxiliary index
For the joint index in the form of (a,b), the so-called query criteria in B can not be selected. However, if it is a statistical operation and the index is overwritten, the optimizer will still choose to use the index, as shown below
#Federated index userid_2 (userid,buy_date). Generally, we follow buy_ The index cannot be used on date, but in special cases: if the query statement is a statistical operation and the index is overwritten, it is based on buy_ This union index can also be used when date is used as the query condition mysql> explain select count(*) from buy_log where buy_date >= '2011-01-01' and buy_date < '2011-02-01'; +----+-------------+---------+-------+---------------+----------+---------+------+------+--------------------------+ | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | +----+-------------+---------+-------+---------------+----------+---------+------+------+--------------------------+ | 1 | SIMPLE | buy_log | index | NULL | userid_2 | 8 | NULL | 7 | Using where; Using index | +----+-------------+---------+-------+---------------+----------+---------+------+------+--------------------------+ 1 row in set (0.00 sec)
*9 * ***** 0 * * * nine query optimization artifact - explain
I believe you are not unfamiliar with the explain command. For specific usage and field meaning, please refer to the official website explain-output Here, we need to emphasize that rows is the core indicator, and most of the small rows statements must execute very quickly (with exceptions, which will be discussed below). Therefore, the optimization statements are basically optimizing rows.
*About explain, if you are interested, you can take a look at this blog. His summary is very good: http://www.cnblogs.com/yycc/p/7338894.html *
Execution plan: let mysql Estimated execution operations(Generally correct)
all < index < range < index_merge < ref_or_null < ref < eq_ref < system/const
id,email
Slow:
select * from userinfo3 where name='alex'
explain select * from userinfo3 where name='alex'
type: ALL(Full table scan)
select * from userinfo3 limit 1;
Fast:
select * from userinfo3 where email='alex'
type: const(Walk index)
http://blog.itpub.net/29773961/viewspace-1767044/
*10 * ***** 0 * * * basic steps of ten slow query optimization
0.Run it first to see if it is really slow. Pay attention to the settings SQL_NO_CACHE 1.where Query the condition sheet table and lock the minimum return record table. This sentence means that the query statement where Apply to the table with the smallest number of records returned in the table. Query each field in a single table to see which field has the highest discrimination 2.explain Check whether the execution plan is consistent with 1 expectations (query from the table with few locked records) 3.order by limit Formal sql Statement gives priority to sorted tables 4.Understand the usage scenarios of the business party 5.Several principles of building indexes when adding indexes 6.The observation results do not meet the expectations. Continue to analyze from 0
*11 * * * * * 0 * * * eleven slow log management
Slow log
- execution time > 10
- Missed index
- log file path
to configure:
- Memory
show variables like '%query%';
show variables like '%queries%';
set global Variable name = value
- configuration file
mysqld --defaults-file='E:\wupeiqi\mysql-5.7.16-winx64\mysql-5.7.16-winx64\my-default.ini'
my.conf Content:
slow_query_log = ON
slow_query_log_file = D:/....
Note: after modifying the configuration file, you need to restart the service
MySQL Log management ======================================================== Error log: record MySQL Server startup, shutdown and operation errors Binary log: also called binlog Log, which records the data in the database in the form of binary file SELECT Operations other than Query log: Record query information Slow query log: Records actions that took longer than the specified time Relay log: the standby database copies the binary log of the primary database to its own relay log for local playback General log: which account, time period and events are audited Transaction log redo Logs: logging Innodb Transaction related, such as transaction execution time, checkpoint, etc ======================================================== I bin-log 1. Enable # vim /etc/my.cnf [mysqld] log-bin[=dir\[filename]] # service mysqld restart 2. suspend //Current session only SET SQL_LOG_BIN=0; SET SQL_LOG_BIN=1; 3. see View all: # mysqlbinlog mysql.000002 By time: # mysqlbinlog mysql.000002 --start-datetime="2012-12-05 10:02:56" # mysqlbinlog mysql.000002 --stop-datetime="2012-12-05 11:02:54" # mysqlbinlog mysql.000002 --start-datetime="2012-12-05 10:02:56" --stop-datetime="2012-12-05 11:02:54" By bytes: # mysqlbinlog mysql.000002 --start-position=260 # mysqlbinlog mysql.000002 --stop-position=260 # mysqlbinlog mysql.000002 --start-position=260 --stop-position=930 4. truncation bin-log(Generate new bin-log (file) a. restart mysql The server b. # mysql -uroot -p123 -e 'flush logs' 5. delete bin-log file # mysql -uroot -p123 -e 'reset master' 2, Query log Enable general query log # vim /etc/my.cnf [mysqld] log[=dir\[filename]] # service mysqld restart 3, Slow query log Enable slow query log # vim /etc/my.cnf [mysqld] log-slow-queries[=dir\[filename]] long_query_time=n # service mysqld restart MySQL 5.6: slow-query-log=1 slow-query-log-file=slow.log long_query_time=3 View slow query log test:BENCHMARK(count,expr) SELECT BENCHMARK(50000000,2*3);