
Redis has five basic data structures: string, list, hash, set and zset. They are the most frequently used and widely used data structures in daily development. If you understand these five data structures thoroughly, you will master half of redis application knowledge.
string

First, let's start with string. String represents a variable byte array. We can initialize the content of the string, get the length of the string, obtain the substring of the string, overwrite the substring content of the string, and append the substring.
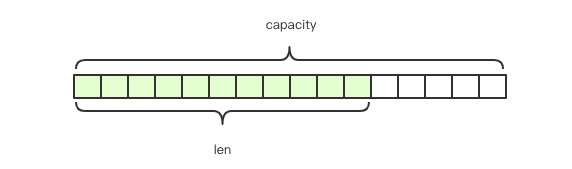
Redis's string is a dynamic string that can be modified. Its internal structure is similar to ArrayList in Java. It uses pre allocation of redundant space to reduce frequent memory allocation. As shown in the figure, the internal space capacity actually allocated for the current string is generally higher than the actual string length len. When the string length is less than 1M, the expansion is to double the existing space. If it exceeds 1M, only 1M more space will be expanded at a time. It should be noted that the maximum length of the string is 512M.
The initialization string needs to provide "variable name" and "variable content"
> set ireader beijing.zhangyue.keji.gufen.youxian.gongsi OK
Get the content of the string and provide "variable name"
> get ireader "beijing.zhangyue.keji.gufen.youxian.gongsi"
Get the length of the string and provide "variable name"
> strlen ireader (integer) 42
**Get the substring, provide the "variable name" * * and the start and end positions [start, end]
> getrange ireader 28 34 "youxian"
The override substring provides the "variable name" and the start position and target substring
> setrange ireader 28 wooxian (integer) 42 # Return length > get ireader "beijing.zhangyue.keji.gufen.wooxian.gongsi"
Append substring
> append ireader .hao (integer) 46 # Return length > get ireader "beijing.zhangyue.keji.gufen.wooxian.gongsi.hao"
Unfortunately, string insertion and substring deletion methods are not provided.
Counter if the content of the string is an integer, you can also use the string as a counter.
> set ireader 42 OK > get ireader "42" > incrby ireader 100 (integer) 142 > get ireader "142" > decrby ireader 100 (integer) 42 > get ireader "42" > incr ireader # Equivalent to incrby ireader 1 (integer) 43 > decr ireader # Equivalent to decrby ireader 1 (integer) 42
The counter has a range and cannot exceed long Max, not lower than long MIN
> set ireader 9223372036854775807 OK > incr ireader (error) ERR increment or decrement would overflow > set ireader -9223372036854775808 OK > decr ireader (error) ERR increment or decrement would overflow
Expired and deleted strings can be actively deleted by using del instruction, and the expiration time can be set by using expire instruction. They will be automatically deleted at the point of arrival, which belongs to passive deletion. You can use the ttl instruction to get the lifetime of a string.
> expire ireader 60 (integer) 1 # 1 indicates that the setting is successful, and 0 indicates that the variable ireader does not exist > ttl ireader (integer) 50 # There is still 50 seconds to live. Returning - 2 means the variable does not exist and - 1 means the expiration time is not set > del ireader (integer) 1 # 1 returned after deletion > get ireader (nil) # The variable ireader is gone
list

Redis names the list data structure as list instead of array because the storage structure of the list uses a linked list instead of an array, and the linked list is also a two-way linked list. Because it is a linked list, the random positioning performance is weak, and the head and tail insertion and deletion performance is better. If the list length of the list is very long, we must pay attention to the time complexity of linked list related operations.
The position of negative subscript linked list elements uses natural numbers 0,1,2 n-1 indicates that negative numbers - 1, - 2- n means, - 1 means "penultimate first" and - 2 means "penultimate second". Then - n means the first element, and the corresponding subscript is 0.
The queue / stack linked list can add and remove elements from the header and footer. Combined with the four instructions rpush/rpop/lpush/lpop, the linked list can be used as a queue or stack, from left to right
# Right in left out > rpush ireader go (integer) 1 > rpush ireader java python (integer) 3 > lpop ireader "go" > lpop ireader "java" > lpop ireader "python" # Left in right out > lpush ireader go java python (integer) 3 > rpop ireader "go" ... # Right in right out > rpush ireader go java python (integer) 3 > rpop ireader "python" ... # Left in and left out > lpush ireader go java python (integer) 3 > lpop ireader "python" ...
In daily applications, lists are often used as asynchronous queues.
Length use the len instruction to obtain the length of the linked list
> rpush ireader go java python (integer) 3 > llen ireader (integer) 3
Random reading can use the lindex instruction to access the elements at the specified location, and use the lrange instruction to obtain the list of linked list sub elements, providing start and end subscript parameters
> rpush ireader go java python (integer) 3 > lindex ireader 1 "java" > lrange ireader 0 2 1) "go" 2) "java" 3) "python" > lrange ireader 0 -1 # -1 means the penultimate 1) "go" 2) "java" 3) "python"
When using lrange to obtain all elements, you need to provide end_index, if there is no negative subscript, you need to obtain the length through the len instruction before you can get end_ The value of index, with a negative subscript, uses - 1 instead of end_index can achieve the same effect.
Modify an element use the lset instruction to modify an element at a specified location.
> rpush ireader go java python (integer) 3 > lset ireader 1 javascript OK > lrange ireader 0 -1 1) "go" 2) "javascript" 3) "python"
Insert elements use the linsert instruction to insert elements in the middle of the list. Experienced programmers know that when inserting elements, we often don't know whether to insert before or after the specified position, so antirez adds the direction parameter before/after to the linsert instruction to indicate the pre and post insertion. However, it is unexpected that the linsert instruction is not inserted by specifying a location, but by specifying a specific value. This is because in the distributed environment, the elements of the list always change frequently, which means that the element subscript calculated at the previous time may not be the subscript you expect at the next time.
> rpush ireader go java python (integer) 3 > linsert ireader before java ruby (integer) 4 > lrange ireader 0 -1 1) "go" 2) "ruby" 3) "java" 4) "python"
So far, I haven't found the application scenario of inserting specified elements in practical application.
The deletion operation of deleting the element list does not determine the element by specifying the subscript. You need to specify the maximum number of deleted elements and the value of elements
> rpush ireader go java python (integer) 3 > lrem ireader 1 java (integer) 1 > lrange ireader 0 -1 1) "go" 2) "python"
Fixed length list in practical application scenarios, we sometimes encounter the demand of "fixed length list". For example, the list of winning user names should be displayed in real time in the form of a walking lantern, because there are too many winning users, and the number that can be displayed generally does not exceed 100, then a fixed length list will be used here. The instruction to maintain the fixed length list is ltrim, which needs to provide two parameters: start and end, indicating that the subscript range of the list needs to be reserved, and all elements outside the range will be removed.
> rpush ireader go java python javascript ruby erlang rust cpp (integer) 8 > ltrim ireader -3 -1 OK > lrange ireader 0 -1 1) "erlang" 2) "rust" 3) "cpp"
If the real subscript corresponding to the end of the specified parameter is less than start, the effect is equivalent to the del instruction, because such a parameter indicates that the subscript range of the list element needs to be kept empty.
Quick list

If you go deeper, you will find that the underlying storage of Redis is not a simple linkedlist, but a structure called quicklist. First, when there are few list elements, a continuous memory storage will be used. This structure is ziplost, that is, compressed list. It stores all the elements next to each other and allocates a continuous piece of memory. When there is a large amount of data, it will be changed to quicklist. Because the additional pointer space required by ordinary linked lists is too large, it will waste space. For example, only int type data is stored in this list, and two additional pointers prev and next are required in the structure. Therefore, Redis combines the linked list and zipplist to form a quicklist. That is to string multiple ziplist s using bidirectional pointers. This not only meets the fast insertion and deletion performance, but also does not appear too much spatial redundancy.
hash
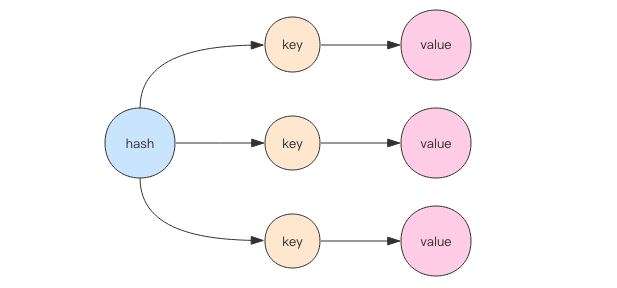
Hash is equivalent to HashMap of Java language or dict Of Python language. In terms of implementation structure, it uses two-dimensional structure. The first dimension is array, and the second dimension is linked list. The contents of hash, key and value are stored in linked list, and the header pointer of linked list is stored in array. When searching for elements through the key, first calculate the hashcode of the key, then use the hashcode to model the length of the array and locate it to the header of the linked list, and then traverse the linked list to obtain the corresponding value value. The function of the linked list is to string the elements with "hash collision". Java language developers will feel very familiar, because such a structure is no different from HashMap. The length of the first dimensional array of hash is also 2^n.
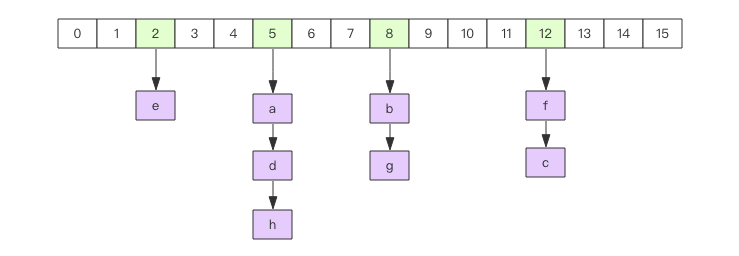
To add elements, you can use hset to add one key value pair at a time, or hmset to add multiple key value pairs at a time
> hset ireader go fast (integer) 1 > hmset ireader java fast python slow OK
The value corresponding to a specific key can be located through hget, the value corresponding to multiple keys can be obtained through hmget, all key value pairs can be obtained by hgetall, and all key list and value list can be obtained by hkeys and hvals respectively. These operations are similar to the Map interface of the Java language.
> hmset ireader go fast java fast python slow OK > hget ireader go "fast" > hmget ireader go python 1) "fast" 2) "slow" > hgetall ireader 1) "go" 2) "fast" 3) "java" 4) "fast" 5) "python" 6) "slow" > hkeys ireader 1) "go" 2) "java" 3) "python" > hvals ireader 1) "fast" 2) "fast" 3) "slow"
To delete an element, you can use hdel to delete the specified key. hdel supports deleting multiple keys at the same time
> hmset ireader go fast java fast python slow OK > hdel ireader go (integer) 1 > hdel ireader java python (integer) 2
To judge whether an element exists, we usually use hget to obtain whether the value corresponding to the key is empty until the corresponding element exists. However, if the string length of value is particularly large, it is a little wasteful to judge whether an element exists in this way. At this time, we can use the hexists instruction.
> hmset ireader go fast java fast python slow OK > hexists ireader go (integer) 1
The counter hash structure can also be used as a counter. Each internal key can be used as an independent counter. If the value value is not an integer, an error occurs when calling the hincrby instruction.
> hincrby ireader go 1 (integer) 1 > hincrby ireader python 4 (integer) 4 > hincrby ireader java 4 (integer) 4 > hgetall ireader 1) "go" 2) "1" 3) "python" 4) "4" 5) "java" 6) "4" > hset ireader rust good (integer) 1 > hincrby ireader rust 1 (error) ERR hash value is not an integer
Capacity expansion when the elements inside the hash are crowded (hash collisions are frequent), capacity expansion is required. For capacity expansion, you need to apply for a new array of twice the size, and then reassign all key value pairs to the linked list corresponding to the subscript of the new array (rehash). If the hash structure is large, for example, there are millions of key value pairs, the process of rehash will take a long time. This is a little stressful for single threaded Redis. Therefore, Redis adopts a progressive rehash scheme. It will retain two old and new hash structures at the same time, and gradually migrate the elements of the old structure to the new structure in the subsequent scheduled tasks and the read-write instructions of the hash structure. In this way, the thread jam caused by capacity expansion can be avoided.
Downsizing Redis's hash structure has not only capacity expansion but also capacity reduction. From this point of view, it is more powerful than Java's HashMap. Java's HashMap only has capacity expansion. The principle of capacity reduction is the same as that of capacity expansion, but the size of the new array is twice that of the old array.
set
Java programmers know that the internal implementation of HashSet uses HashMap, but all values point to the same object. Redis's set structure is the same. It also uses a hash structure internally. All values point to the same internal value.
Adding elements can add more than one element at a time
> sadd ireader go java python (integer) 3
Read elements, use smembers to list all elements, use scar to get the length of the collection, and use srandmember to get random count elements. If the count parameter is not provided, it is 1 by default
> sadd ireader go java python (integer) 3 > smembers ireader 1) "java" 2) "python" 3) "go" > scard ireader (integer) 3 > srandmember ireader "java"
Delete elements use srem to delete one or more elements and spop to delete a random element
> sadd ireader go java python rust erlang (integer) 5 > srem ireader go java (integer) 2 > spop ireader "erlang"
To judge whether an element exists, only a single element can be received using the sismember instruction
> sadd ireader go java python rust erlang (integer) 5 > sismember ireader rust (integer) 1 > sismember ireader javascript (integer) 0
sortedset
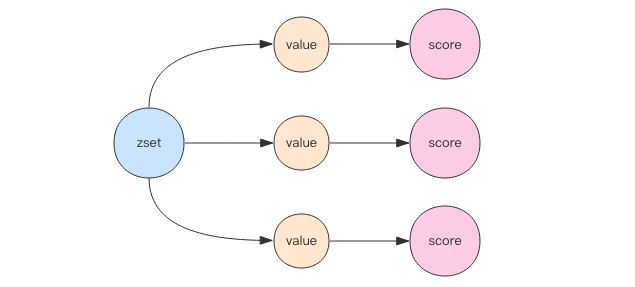
SortedSet(zset) is a very special data structure provided by Redis. On the one hand, it is equivalent to the Java data structure map < string, double >, which can give each element value a weight score. On the other hand, it is similar to TreeSet. The internal elements will be sorted according to the weight score to get the ranking of each element, You can also get the list of elements through the scope of score.
The underlying implementation of zset uses two data structures. The first is hash and the second is jump list. The function of hash is to associate the element value and weight score to ensure the uniqueness of the element value. The corresponding score value can be found through the element value. The purpose of jump list is to sort the element value and obtain the element list according to the range of score.
Add an element. One or more value/score pairs can be added through the zadd instruction, with score in the front
> zadd ireader 4.0 python (integer) 1 > zadd ireader 4.0 java 1.0 go (integer) 2
Length the number of elements of zset can be obtained through the instruction zcard
> zcard ireader (integer) 3
Delete element: the zrem instruction can delete elements in zset, and multiple elements can be deleted at one time
> zrem ireader go python (integer) 2
Like hash structure, zset can also be used as a counter.
> zadd ireader 4.0 python 4.0 java 1.0 go (integer) 3 > zincrby ireader 1.0 python "5"
Get the ranking and score, get the weight of the specified element through the zscore instruction, get the forward ranking of the specified element through the zrank instruction, and get the reverse ranking of the specified element [the last one] through the zrevrank instruction. The positive direction is from small to large, and the negative direction is from large to small.
> zscore ireader python "5" > zrank ireader go # Those with low scores are ranked before the examination, and the rank value is small (integer) 0 > zrank ireader java (integer) 1 > zrank ireader python (integer) 2 > zrevrank ireader python (integer) 0
Obtain the element list according to the ranking range, specify the ranking range parameter through the zrange instruction to obtain the corresponding element list, and carry the WithCores parameter to obtain the weight of the element together. The element list [reciprocal] is obtained by negative ranking through the zrevrange instruction. The positive direction is from small to large, and the negative direction is from large to small.
> zrange ireader 0 -1 # Get all elements 1) "go" 2) "java" 3) "python" > zrange ireader 0 -1 withscores 1) "go" 2) "1" 3) "java" 4) "4" 5) "python" 6) "5" > zrevrange ireader 0 -1 withscores 1) "python" 2) "5" 3) "java" 4) "4" 5) "go" 6) "1"
Obtain the list according to the score range, and specify the score range through the zrangebyscore instruction to obtain the corresponding element list. Obtain the inverted element list through the zrevrangebyscore instruction. The positive direction is from small to large, and the negative direction is from large to small. The parameter - inf indicates negative infinity and + inf indicates positive infinity.
> zrangebyscore ireader 0 5 1) "go" 2) "java" 3) "python" > zrangebyscore ireader -inf +inf withscores 1) "go" 2) "1" 3) "java" 4) "4" 5) "python" 6) "5" > zrevrangebyscore ireader +inf -inf withscores # Notice that the positive and negative are reversed 1) "python" 2) "5" 3) "java" 4) "4" 5) "go" 6) "1"
The element list can be removed according to the range. You can also remove multiple elements at one time through the ranking range or the score range
> zremrangebyrank ireader 0 1 (integer) 2 # Deleted 2 elements > zadd ireader 4.0 java 1.0 go (integer) 2 > zremrangebyscore ireader -inf 4 (integer) 2 > zrange ireader 0 -1 1) "python"
The internal sorting function of jump list zset is realized through the "jump list" data structure. Its structure is very special and complex. Readers should be prepared for the depth of content in this section.
Because zset needs to support random insertion and deletion, it is not easy to use arrays to represent it. Let's first look at an ordinary linked list structure.

We need this linked list to sort according to the score value. This means that when new elements need to be inserted, they need to locate the insertion point at a specific position, so as to continue to ensure that the linked list is orderly. Usually, we will find the insertion point through binary search, but the object of binary search must be an array. Only the array can support fast location, and the linked list can't do it. What should we do?
Think of a start-up company. At the beginning, there were only a few people. All team members were equal and were co founders. With the growth of the company, the number of people gradually increases, and the cost of team communication increases. At this time, the team leader system will be introduced to divide the team. Each team will have a team leader. The meeting is divided into teams, and multiple leaders will have their own meeting arrangements. To further expand the scale of the company, we need to add another level - Department. Each department will select a representative from the group leader list as the minister. Ministers will also have their own arrangements for high-level meetings.
The jump list is similar to this hierarchy. All the elements in the lowest layer will be connected. Then select a representative every few elements, and then string these representatives with another level of pointer. Then select secondary representatives from these representatives and string them together. Finally, a pyramid structure is formed.
Think about the location of your hometown in the world map: Asia - > China - > Anhui Province - > Anqing City - > Zongyang County - > Tanggou town - > Tiantian village - > XXXX. It is also such a similar structure.

The reason why the "jump list" is "jump" is that the internal elements may "have multiple roles". For example, the element in the middle of the above figure is at L0, L1 and L2 levels at the same time, so it can quickly "jump" between different levels.
When locating the insertion point, first locate it at the top level, then dive to the next level, dive all the way to the bottom level, find a suitable position and insert new elements. You may ask how the newly inserted element has the opportunity to "hold several positions"?
The jump list adopts a random strategy to determine which layer new elements can work part-time. First, L0 layer must be 100%, L1 layer has only 50%, L2 layer has only 25%, L3 layer has only 12.5%, and it is random to the top layer L31. Most elements can't pass through several layers, and only a few elements can go deep into the top layer. The more elements in the list, the deeper the level, and the greater the probability of entering the top level.
This is quite fair. Whether you can enter the central government depends not on your father, but on luck.