There is a feature in OC language called protocol. Because OC does not support multiple inheritance, we define a series of methods that a class should implement in the protocol. The protocol can well describe the interface.
**Category * * is also an important feature of OC. Using classification, you can directly add methods to the current class without inheriting subclasses, which is in line with OC language runtime. The system is highly dynamic.
23: inter object communication through delegation and data source protocol
Objects often need to communicate with each other, and there are many ways of communication. Objective-C developers widely use a programming design pattern called "Delegate pattern" to realize the communication between objects. The main purpose of this pattern is to define a set of interfaces. If an object wants to accept the delegation of another object, it needs to follow this interface to become its "delegate object". This "another object" can return some information to its delegate object, or notify the delegate object when relevant events occur.
This pattern decouples data from business logic. For example, if there is a view used to display a series of data in the user interface, this view should only contain the logic code required to display the data, and should not decide what data to display and how to interact between the data. The properties of the view object need to include the object responsible for data and event processing. These two objects are called data source and delegate, respectively.
Let's take the following example: suppose we want to carry a class that obtains data from the Internet. If the network request takes too long, it will block the application, which is very bad, so we will adopt the delegate mode
Delegation mode
The class used first contains a * * delegate object * *. After requesting data, it will call back this object. The following is the process of calling back the delegate object:
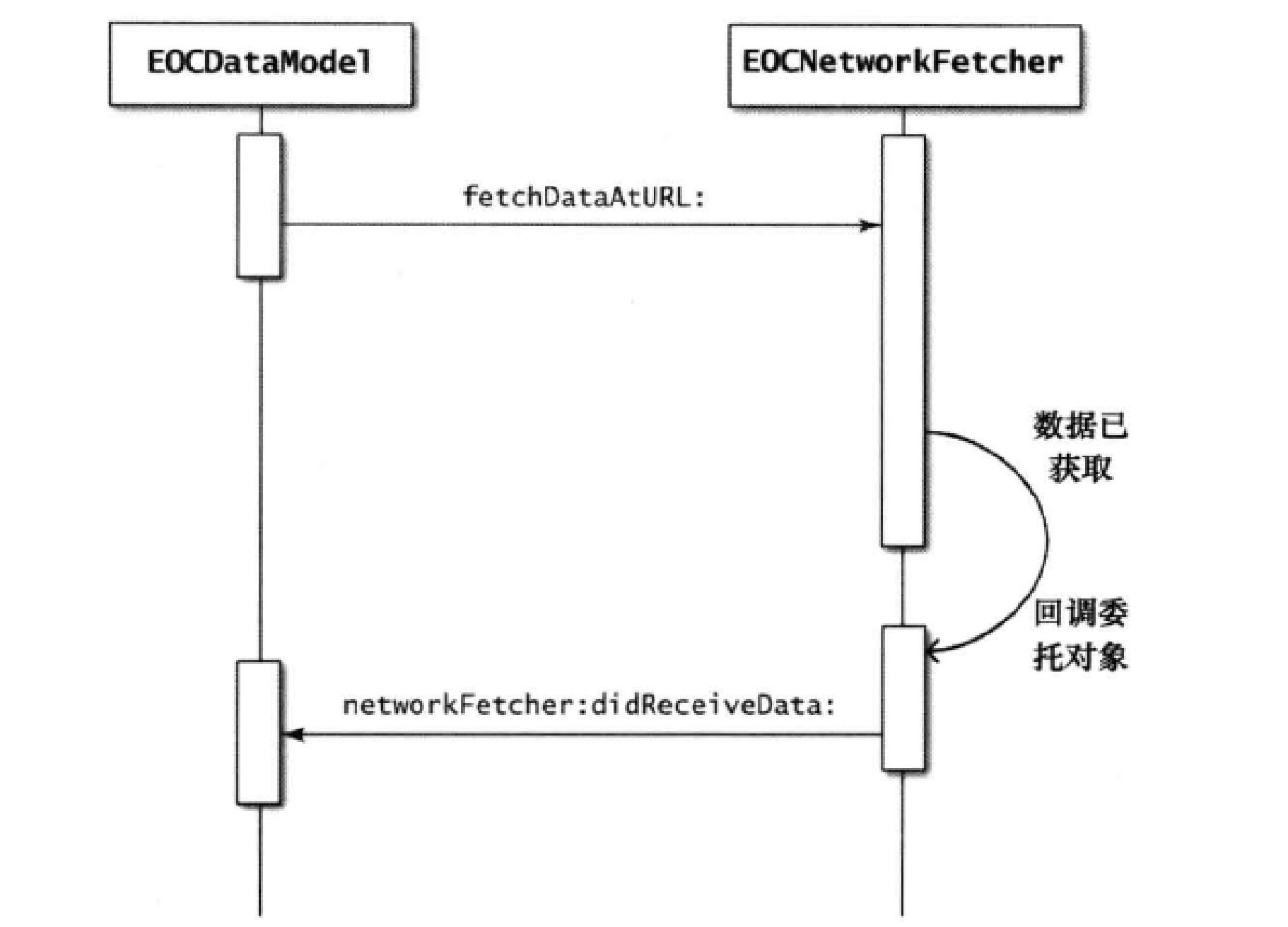
EOCNetworkFetcher object is the class that we complete the network request.
The EOCDataModel object is the delegate object of the EOCNetworkFetcher. EOCDataModel requests the EOCNetworkFetcher to perform a task asynchronously. After the EOCNetworkFetcher completes the task, it will notify its delegate object, that is, EOCDataModel.
The so-called asynchronous mode here: that is, a method of adding tasks in GCD: after adding, you don't have to wait for the task to end, and the function will return immediately. It is recommended to use this method first because it will not block the execution of other tasks.
Let's look at the code:
@protocol EOCNetworkFetcherDelegate - (void)networkFetcher:(EOCNetworkFetcher*) fetcher didReceiveData:(NSData*)data; - (void)networkFetcher:(EOCNetworkFetcher*)fetcher didFailWithError:(NSError*)error; @end
The protocol name is usually the name of the relevant class followed by Delegate. With the agreement, the class can use a property to store the Delegate object.
@property (nonatomic, weak) id <EOCNetworkFetcherDelegate> delegate;
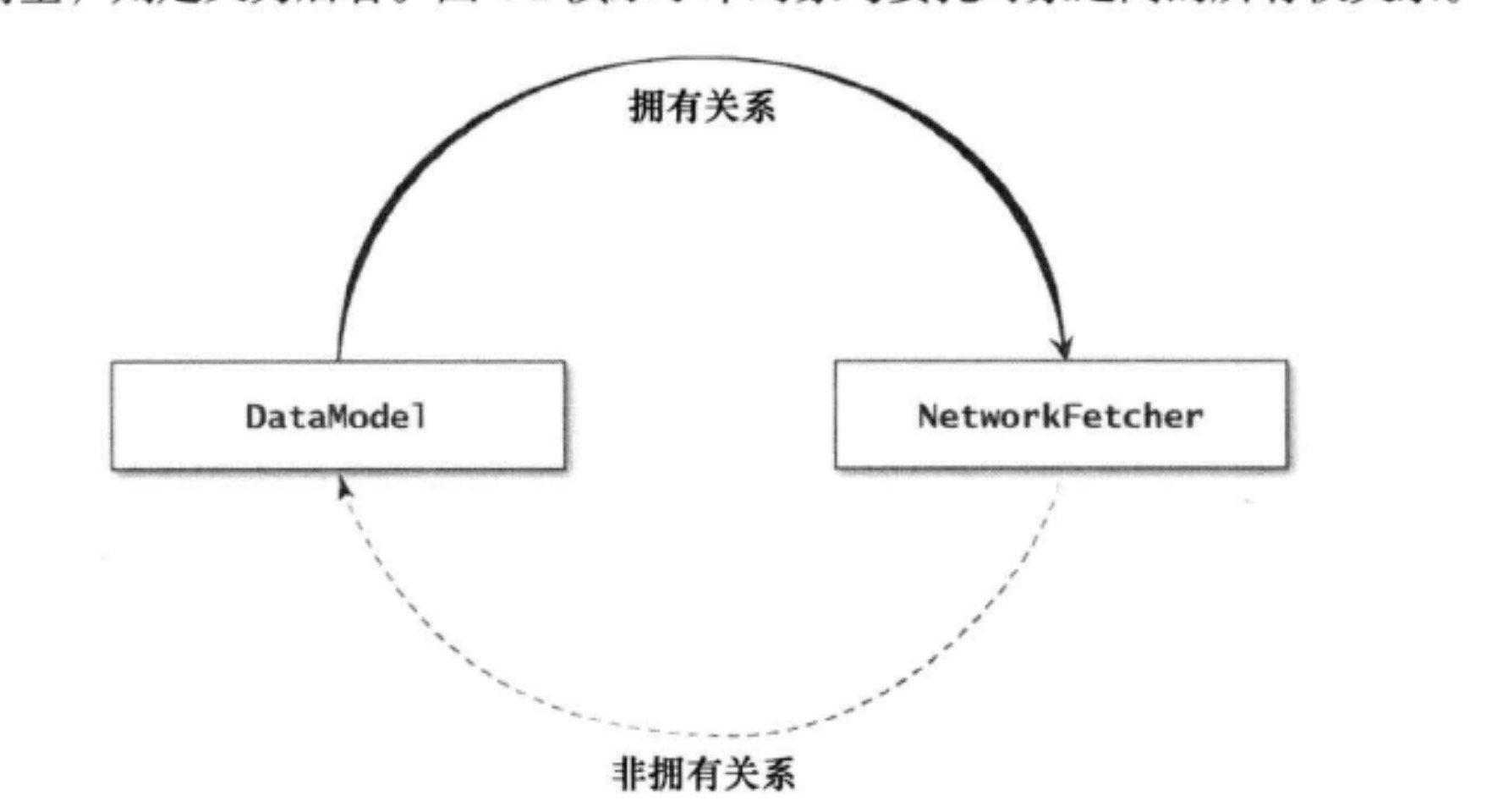
It must be noted that this attribute needs to be defined as weak, not strong, because there must be a "non owning relationship" between the two. Usually, the object that plays delegate also holds this object. For example, in this case, the object that wants to use the EOCNetworkFetcher will hold the object and will not be released until it is used up. If strongis used to define the ownership relationship between this object and the delegate object when declaring the attribute, a "retention cycle" will be introduced. Therefore, the attribute storing the delegate object in this class is defined as either weak or unsafe unretained. If it is necessary to automatically empty the relevant object when it is destroyed, it is defined as the former. If it is not necessary to automatically empty, it is defined as the latter.
The figure below illustrates their ownership relationship.
The way to implement the delegate object is to declare that a class complies with the delegate protocol, and then implement those methods in the protocol in the class. If a class wants to comply with the delegation protocol, it can be declared in its interface or classified in "class continuation". If it wants to announce that this class implements a protocol to the outside world, it should be declared in the interface. If this protocol is a delegation protocol, it will usually be used only inside the class. Therefore, this situation is generally declared in the "class continuation classification":
@implementation EOCDataModel () <EOCNetworkFetcherDelegate>
@end
@implementation EOCDataModel
- (void)networkFetcher:(EOCNetworkFetcher*)fetcher
didReceiveData:(NSData*)data {
/* Handle data */
}
-
(void)networkFetcher:(EOCNetworkFetcher*)fetcher didFailWithError:(NSError*)error {
/* Handle error */
}
@end
The methods in the protocol are generally "optional". In order to indicate the optional method, delegation agreements often use the @ optional keyword.
@protocol EOCNetworkFetcherDelegate @optional - (void)networkFetcher:(EOCNetworkFetcher*)fetcher didReceiveData:(NSData*)data; - (void)networkFetcher:(EOCNetworkFetcher*)fetcher didFailWithError:(NSError*)error; @end
If you call an optional method on a delegate object, you must use the type information query method in advance to determine whether the delegate object can respond to the relevant selectors, as follows:
NSData *data = /*data obtained from network*/;
if ([_delegate respondToSelector:@selector(networkFetcher:didReceiveData:)]) {
[_delegate networkFetcher:self didReceiveData:data];
}
If the "toresponse:", the "toresponse": "method will not be called to determine whether there is any relevant operation.
The method name in the delegate object must also be appropriate. The method name should accurately describe the current event and why the delegate object should know about it. In addition, when calling the method in the delegate object, the instance that initiates the delegation should always be passed into the method. In this way, when the delegate object implements the relevant method, it can execute different codes according to the passed in instance.
- (void)networkFetcher:(EOCNetworkFetcher*)fetcher didReceiveData:(NSData*)data {
if (fetcher == _myFetcherA) {
/*Handel data*/
} else {
/*Handel data*/
}
}
This parameter can be used to determine which instance object gets the data.
The method in delegate can also be used to get information from the delegate object. For example, the MyNetworkFetcher class may want to provide a mechanism: if a "redirect" is encountered when retrieving data, it will ask its delegate object whether it should be redirected. The relevant methods in the delegate object can be written as follows:
Redirection: it's like that we find an advertising company a to design business cards. A clearly tells us that they won't design, so let's find company B. as a result, company B has designed it for me, so we will announce that it is the business card designed by company B for us. (so we send two requests, and the URL address bar changes from company a to company B)
- (BOOL)networkFetcher:(EOCNetworkFetcher*)fetcher shouldFollowRedirectToURL:(NSURL*)url;
Through this example, it should be easy to understand why this mode is called "delegation mode": because the object delegates the responsibility for a certain behavior to another class.
Protocol definition interface
Define a set of interfaces with protocol: make a Class obtain the data it needs through the interface. This method of Delegate pattern aims to provide data to classes, so it is also called "Data Source Pattern". In this mode, information flows from the Data Source to the Class; In the conventional delegation mode, the information flows from the Class to the Delegate.
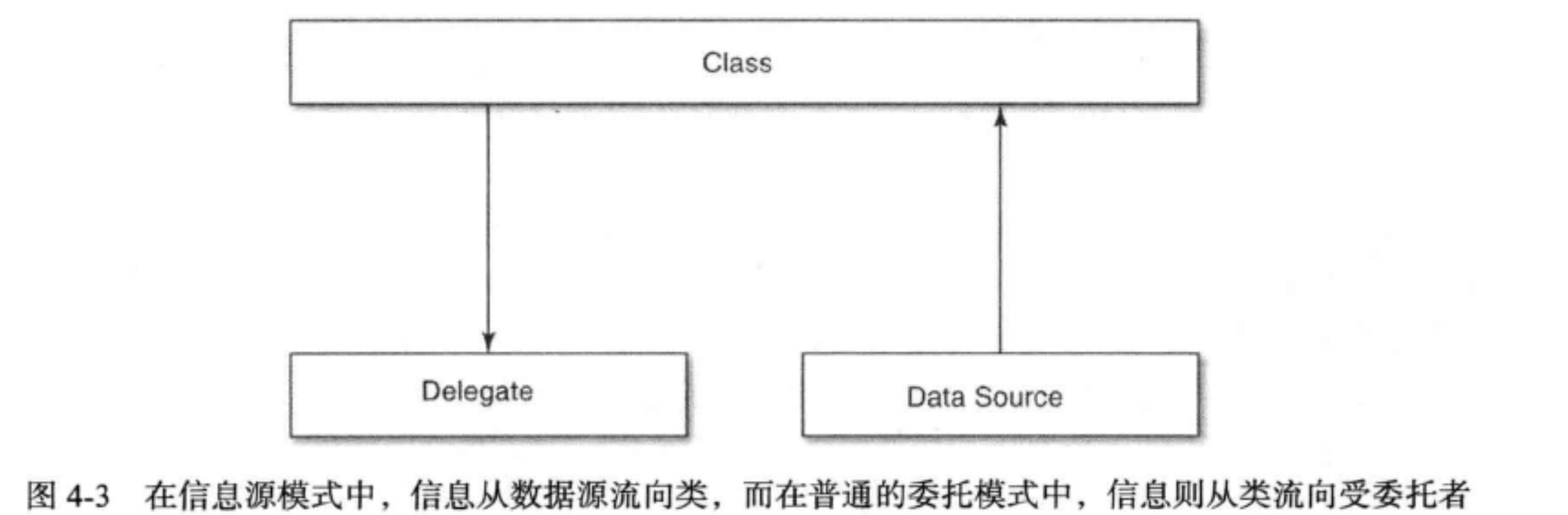
For example, the "list view" object in the user interface framework may obtain the data to be displayed in the list through the data source protocol. In addition to the data source, the list view has a delegate to handle the user's interaction with the list. Separating the data source protocol from the delegation protocol can make the interface clearer, because the logical codes of the two parts are also separated. In addition, data source and trustee can be two different objects. However, in general, the same object is used to play these two roles.
When implementing delegate mode and data source mode, if the method in the protocol is optional, a large number of codes similar to the following will be written:
if ([_delegate respondToSelector:@selector(someClassDidSomething)]) {
[_delegate someClassDidSomething];
}
Using this method, it is easy to find out whether a delegate object can respond to a specific selector, but in addition to the results of the first detection, the subsequent detection may be redundant. In view of this, we usually save the information of whether the delegate agreement can respond to it to optimize the performance of the program.
Suppose that in the "network data collector" example, the protocol followed by the delegate object has a callback method representing the progress of data acquisition, which will be called many times in the life cycle of the network data collector. After adding the selector just mentioned, the delegation protocol to be implemented by the delegate object will be extended to:
@protocol EOCNetworkFetcherDelegate @optional - (void)networkFetcher:(EOCNetworkFetcher*)fetcher didReceiveData:(NSData*)data; - (void)networkFetcher:(EOCNetworkFetcher*)fetcher didFailWithError:(NSError*)error; - (void)networkFetcher:(EOCNetworkFetcher*)fetcher didUpdateProgressTo:(float)progress; @end
After the expansion, a method networkFetcher:didUpdateProgressTo:: is added. The best way to cache the response ability of the method is to use the "bit field" data type. This is a C language feature that few people pay attention to, but it is right here. We can set the binary single digits occupied by a field in the structure to a specific value,
For details, please refer to Bit segment
For example:
struct data {
unsigned int fieldA : 8;
unsigned int fieldB : 4;
unsigned int fieldC : 2;
unsigned int fieldD : 1;
};
The integer after the above member defines how many bits the member occupies, and fieldD occupies one bit, which can only represent 0 and 1. We can cache whether to implement the method like this, as follows:
@interface EOCNetworkFetcher() {
struct {
unsigned int didReceiveData : 1;
unsigned int didFailWithError : 1;
unsigned int didUpdateProgressTo : 1;
} _delegateFlags;
}
@end
We created a structure with only a few bit segments, which can store many bool values. This structure is used to cache whether the delegate object can respond to a specific selector. The code to implement the cache function is written in the setting method corresponding to the delegate attribute:
- (void)setDelegate:(id<EOCNetworkFetcher>)delegate {
_delegate = delegate;
_delegateFlags.didReceiveData = [delegate respondToSelector:@selector(didReceiveData:)];
_delegateFlags.didFailWithError = [delegate respondToSelector:@selector(didFailWithError:)];
_delegateFlags.didUpProgressTo = [delegate respondToSelector:@selector(didUpProgressTo:)];
}
It is worth this optimization when the relevant methods need to be called many times. For example, multiple independent data are obtained from the data source through the data source protocol for many times.
24: disperse the implementation code of the class into several categories that are easy to manage
Classes are often easy to fill with various methods, and the code of these methods is all piled in a huge implementation file. Sometimes it is reasonable to do so, because even if the class is broken up through refactoring, the effect will not be better. In this case, the class code can be logically divided into several partitions through the "classification" mechanism.
For example, if we model personal information as a class, there may be the following methods:
#import <Foundation/Foundation.h> @interface EOCPerson : NSObject @property (nonatomic, copy, readonly) NSString *firstName; @property (nonatomic, copy, readonly) NSString *lastName; @property (nonatomic, strong, readonly) NSSet *friends; - (id)initWithFirstName:(NSString*)name andLastName:(NSString*)lastName; //Friendship - (void)addFriend:(EOCPerson*)person; - (void)removeFriend:(EOCPerson*)person; - (BOOL)isFriendWith:(EOCPerson*)person; //Work - (void)performDaysWork; - (void)takeVacationFromWork; //Play - (void)goToTheCinema; - (void)goToSportsGame; @end
If all methods are placed in one class, the source code file will become larger and larger and difficult to manage. We can use the classification mechanism to rewrite the above code:
#import <Foundation/Foundation.h> @interface EOCPerson : NSObject <NSCopying> @property (nonatomic, copy, readonly) NSString *firstName; @property (nonatomic, copy, readonly) NSString *lastName; @property (nonatomic, strong, readonly) NSSet *friends; - (id)initWithFirstName:(NSString*)name andLastName:(NSString*)lastName; @end @interface EOCPerson (Friendship) - (void)addFriend:(EOCPerson*)person; - (void)removeFriend:(EOCPerson*)person; - (BOOL)isFriendWith:(EOCPerson*)person; @end @interface EOCPerson (Work) - (void)performDaysWork; - (void)takeVacationFromWork; @end @interface EOCPerson (Play) - (void)goToTheCinema; - (void)goToSportsGame; @end
Now the method is divided into several parts through the method feature, so this feature is called classification. In principle, the basic elements are declared in the "main implementation", and the rest belong to other classifications.
After using the classification mechanism, you can still define the whole class in an interface file and write its code in an implementation file** However, with the increase of the number of categories, the current implementation document soon expanded beyond management** At this time, each classification can be extracted into its own file. Take EOCPerson as an example. It can be divided into the following documents according to its classification:
//EOCPerson+Friendship.h
#import "EOCPerson.h"
@interface EOCPerson (Friendship)
- (void)addFriend:(EOCPerson*)person;
- (void)removeFriend:(EOCPerson*)person;
- (BOOL)isFriendWith:(EOCPerson*)person;
@end
//EOCPerson+Friendship.m
#import "EOCPerson+Friendship.h"
@implementation EOCPerson (Friendship)
- (void)addFriend:(EOCPerson*)person {
//...
}
- (void)removeFriend:(EOCPerson*)person {
//...
}
- (BOOL)isFriendWith:(EOCPerson*)person {
//...
}
@end
Through the classification mechanism, the class code can be divided into many manageable small blocks for separate viewing. If you want to use the classification method in the primary file, you should not only use the classification mechanism, but also use the classification method in the primary file.
Even if the class itself is not too large, we can use the classification mechanism to cut it into several pieces and classify the corresponding code into different "functional area s".
Another reason to break up the class code into the classification is to facilitate debugging: for all methods in a classification, the classification name will appear in its symbol. For example, the "symbol name" of the "addFriend:" method is as follows:
-[EOCPerson(Friendship) addFriend:]
According to the category name of backtracking, it is easy to locate the functional area to which the class method belongs. For example, our private method. Users can find the word private in the backtracking information and do not call this method directly. This can be regarded as a way to write "self documenting code".
25: always prefix the classification names of third-party classes
Classification mechanisms are often used to add functionality to existing classes without source code. This feature is extremely powerful. The methods in classification are directly added to the class. They are just like the inherent methods in this class. Adding a classification method to a class is done when the runtime system loads the classification. The runtime system will add each method implemented in the classification to the method list of the class. If this method exists in the class and the classification is implemented again, the method in the classification will overwrite the original implementation code. In fact, there may be many overrides. For example, the method in one classification overrides the relevant method in the "main implementation", while the method in another classification overrides the method in this classification. The result of multiple coverage shall be subject to the last classification.
therefore, we can add a common prefix to the relevant names:
@interface NSString(ABC_HTTP) - (NSString*)abc_urlEncodedString; - (NSString*)abc_urlDecodedString; @end
■ when adding a category to a third-party category, always prefix its name with your own prefix.
■ when adding a classification to a third-party class, always prefix the method name with your own prefix.
26: do not declare attributes in the classification
Attributes are the way to encapsulate data. Although technically speaking, attributes can also be declared in the classification, this practice should be avoided as much as possible. The reason is that except for the "class continuation classification", other classifications cannot add instance variables to the class. Therefore, they cannot synthesize the instance variables required to implement the attributes.
For example, write the previous attribute friends into the category:
@interface EOCPerson (Friendship) @property (nonatomic, strong) NSArray *friends; - (void)addFriend:(EOCPerson*)person; - (void)removeFriend:(EOCPerson*)person; - (BOOL)isFriendWith:(EOCPerson*)person; @end
At this time, the compiler will give a warning message, warning: property ‘friends’ requires method’friends’ to be defined - use @dynamic or provide a method implementation in this category [-Wobjc-property-implementation ]
warning: property ‘friends’ requires method’setFriends:'to be defined - use @dynamic or provide a method implementation in this category [-Wobjc-property-implementation].
The general meaning of this paragraph is that this classification cannot synthesize instance variables related to the friends attribute, so developers need to implement access methods for this attribute in the classification. At this time, you can declare the access methods as @ dynamic, that is, these methods will be provided at runtime, which is invisible to the compiler at present. If you decide to use the message forwarding mechanism to intercept method calls at run time and provide their implementation, you may be able to do so.
associated objects can solve the problem that instance variables cannot be synthesized in classification. For example. We can use the following code to implement the access method in classification:
#import<objc/runtime.h>
static const char *kFriendsPropertyKey = "kFriendsPropertyKey";
@implementation EOCPerson (Friendship)
- (NSArray*)friends {
return objc getAssociatedObject(self,kFriendsPropertyKey);
}
- (void)setFriends:(NSArray*) friends {
objc_setAssociatedObject(self,
kFriendsPropertyKey, friends,
OBJC_ASSOCIATION_RETAIN_NONATOMIC);
}
@end
It's not ideal, but it's not ideal. Write similar code many times. However, it is easy to make mistakes in memory management. Because we often forget to follow its memory management semantics when implementing access methods for attributes
The correct approach is to define all attributes in the main interface. All data encapsulated by the class should be defined in the main interface. This is the only place where instance variables (that is, data) can be defined. Attributes are just "syntax sugar" used to define instance variables and related access methods, so they should also follow the same rules as instance variables. As for the classification mechanism, it should be understood as a means to extend the functions of classes, not to encapsulate data.
Finally, sometimes read-only attributes can be used in classification.
27: use classification to hide implementation details
Classes often contain methods and instance variables that do not need to be published. The working mode of OC dynamic message system determines that it is impossible to implement real private methods or private instance variables. However, we'd better only disclose the part that really needs to be published. So, how should I write the method and instance variables that do not need to be published but should have? At this time, this special "class continuation classification" comes in handy.
This classification is different from the general classification. It must be defined in the implementation file of the class to which it is connected. At this time, the only classification that can declare instance variables, and this classification has no specific implementation file. All methods should be defined in the main implementation file of the class, and this class has no name.
@interface EOCPerson () //... @end
Why is this classification needed? Because methods and instance variables can be defined. Why can you define methods and instance variables in it? Just because of the mechanism of "stable ABI", we can use it without knowing the size of the object. Since users of classes do not necessarily need to know the memory layout of instance variables, they do not need to be defined in the public interface. For the above reasons, we can add instance variables to the class in the "class continuation classification" as in the class implementation file. We only need to add a few parentheses in the appropriate position and add instance variables:
@interface EOCPerson () {
NSString *_anInstanceVariable;
}
@end
@implementation EOCPerson {
int _anotherInstanceVariable;
}
The advantage of this method: it is only used for this class, because even if the public interface is marked as private, the implementation details will be leaked, which can be hidden by this method.
==Instance variables can also be defined in the implementation block. Grammatically, this is equivalent to adding directly to the "class continuation classification", but it depends on personal preferences== It is recommended to add it to the "class continuation classification" to put all data definitions in one place.
Since some attributes can be defined in the "class continuation classification", it is also appropriate to declare some additional instance variables here. These instance variables are not really private because some methods can always be called at run time to bypass this restriction, but in a general sense, they are private. In addition, because it is not declared in the public header file, the code is better hidden when it is distributed as part of the library.
The "class continuation classification" is also particularly useful when writing Objective-C + + code. Objective-C + + is a mixture of Objective-C and C + +, and its code can be written in these two languages. For compatibility reasons, the game back-end is generally written in C + +. In addition, sometimes the third-party library to be used may only have C + + binding, and C + + must also be used for coding at this time. In these cases, it is convenient to use the "class continuation classification".
Another reasonable use of "class continuation classification" is to extend the attribute declared as "read-only" in the public interface to "read-write" in order to set its value inside the class. We usually do not directly access instance variables, but by setting access methods, because this can trigger KVO notification, and other objects may be listening to this event. The attributes appearing in the "class continuation category" or other categories must have the same characteristics as those in the same interface. However, its "read-only" status can be extended to "read-write". For example, there is a class that describes personal information, and its public interface is as follows:
@interface EOCPerson : NSObject @property (nonatomic, copy, readonly) NSString *firstName; @property (nonatomic, copy, readonly) NSString *lastName; @end
We can extend these two attributes in the class- continuation category:
@interface EOCPerson () @property (nonatomic, copy, readwrite) NSString *firstName; @property (nonatomic, copy, readwrite) NSString *lastName; @end
Now, the implementation code of EOCPerson can call the two setting methods of "setFirstName:" or "setLastName:" at will, or set the attribute using point syntax. In this way, the data encapsulated in the class is controlled by the instance itself, and its value cannot be modified by external code. Note that if the observer is reading the attribute value and the internal code is writing the attribute, a "race condition" may be raised. Rational use of synchronization mechanism can alleviate this problem.
Methods that can only be used in the class implementation code can also be declared in the "class continuation classification", which is more appropriate. Here, you can make a forward declaration. You can uniformly describe the relevant methods contained in the class.
Finally, there is another usage: if the protocol followed by the object should only be regarded as private, it can be declared in "class continuation". For example, a protocol in a private API:
#import "EOCPerson.h" #import "EOCSecretDelegate.h" @interface EOCPerson () <EOCSecretDelegate> @end @implementation EOCPerson /* .·.*/ @end
In this way, it can not be known to the outside world.
28: provide anonymous objects using the protocol
We can use the protocol to hide the implementation details in our API, and design the returned object as the id type conforming to this protocol. In this way, you can hide the class name. If there are many different classes behind the interface and you don't want to indicate which class to use, you can use this method. This concept is often referred to as a hidden object, such as the "trustee" in our previous entrustment agreement:
@property (nonatomic, weak) id <EOCDelegate> delegate;
The object of any class can act as this attribute, which mainly follows the EOCDelegate protocol. If you need to check the class, you can find it during the operation period.
NSDictionary can also actually illustrate this point: in the dictionary, the standard memory management semantics of keys are "copy when setting", while the semantics of values are "keep when setting". Therefore, in the variable dictionary, the signature of the method corresponding to the set key value is:
- (void)setObject:(id)object forKey:(id<NSCopying>)key
The parameter type representing the key is ID < NSCopying >, which can be any type. As long as the NSCopying protocol is followed, the copy information can be sent to the object. This key parameter can be regarded as an anonymous object. Like the delegate attribute, the dictionary does not care about the specific class to which the key object belongs. And it should never rely on it. As long as the dictionary object can determine that it can send copy information to this instance.
The program library dealing with database connection also uses this idea to represent the objects returned from another library with anonymous objects. You may not want to let outsiders know the name of the class used to process the connection, because different databases may need to process different classes. If you can't make them inherit from the same base class, you have to return something of type id. However, we can put those methods that all database connections have into the protocol to make the returned objects comply with the protocol. The agreement can be written as follows:
@protocol EOCDatabaseConnection - (void)connect; - (void)disconnect; - (BOOL)isConnected; - (NSArray*)performQuery:(NSString*)query; @end
You can then use the database handler singleton to provide database connections. The interface of this singleton can be written as:
#import <Foundation/Foundation.h> @protocol EOCDatabaseConnection; @interface EOCDatabaseManager : NSObject + (id)sharedInstance; - (id<EOCDatabaseConnection>)connectionWithIdentifier:(NSString*)identifier; @end
In this way, the name of the link class will not be disclosed. People who use this API only require that the returned object can be used to connect, disconnect and query the database.
Sometimes the object type is not important. What is important is that the object can respond to specific methods defined in the protocol. In this case, these "anonymous types" can also be used to express this concept. Even if the implementation code always uses a fixed class, you may still write it as an anonymous type that complies with a protocol to indicate that the type is not important here.