Author: xidianwangtao@gmail.com
Abstract: This article will discuss the problems faced by Hyperparameter tuning when landing, and how to use Kubernetes+Helm to solve these problems.
Problems Faced by Hyperparameter Sweep
In Hyperparameter Sweep, we need different training according to many different combinations of hyperparameters. It takes a lot of computing resources or time to train the same model many times.
- If training is carried out in parallel according to different hyperparameters, it requires a lot of computational resources.
- If all the different hyperparametric combinations are trained sequentially on fixed computing resources, it will take a lot of time to complete the corresponding training of all combinations.
Therefore, in landing, most people choose a relatively optimal combination by manually fine-tuning their hyperparameters a very limited number of times.
Kubernetes+Helm is a sharp weapon
With Kubernetes and Helm, you can easily explore very large hyperparametric spaces while maximizing cluster utilization to optimize costs.
Helm enables us to package applications into charts and easily parameterize them. In Hyperparameter Sweep, we can use the configuration of Helm chart values to generate the corresponding TFJobs in template for training deployment. At the same time, we can deploy a TensorBoard instance in chart to monitor all these TFJobs, so that we can quickly compare the results of all our superparametric combination training. For those superparametric combinations with poor training effect, we can also deploy a TensorBoard instance in chart to monitor all these TFJobs. The corresponding training tasks can be deleted as soon as possible, which will undoubtedly save the computing resources of the cluster, thus reducing the cost.
Using Kubernetes+Helm for Hyperparameter Sweep Demo
Helm Chart
We will pass Azure/kubeflow-labs/hyperparam-sweep The example in Demo.
Firstly, the following Dockerfile is used to make the training mirror:
FROM tensorflow/tensorflow:1.7.0-gpu COPY requirements.txt /app/requirements.txt WORKDIR /app RUN mkdir ./output RUN mkdir ./logs RUN mkdir ./checkpoints RUN pip install -r requirements.txt COPY ./* /app/ ENTRYPOINT [ "python", "/app/main.py" ]
The main.py training script is as follows:
import click import tensorflow as tf import numpy as np from skimage.data import astronaut from scipy.misc import imresize, imsave, imread img = imread('./starry.jpg') img = imresize(img, (100, 100)) save_dir = 'output' epochs = 2000 def linear_layer(X, layer_size, layer_name): with tf.variable_scope(layer_name): W = tf.Variable(tf.random_uniform([X.get_shape().as_list()[1], layer_size], dtype=tf.float32), name='W') b = tf.Variable(tf.zeros([layer_size]), name='b') return tf.nn.relu(tf.matmul(X, W) + b) @click.command() @click.option("--learning-rate", default=0.01) @click.option("--hidden-layers", default=7) @click.option("--logdir") def main(learning_rate, hidden_layers, logdir='./logs/1'): X = tf.placeholder(dtype=tf.float32, shape=(None, 2), name='X') y = tf.placeholder(dtype=tf.float32, shape=(None, 3), name='y') current_input = X for layer_id in range(hidden_layers): h = linear_layer(current_input, 20, 'layer{}'.format(layer_id)) current_input = h y_pred = linear_layer(current_input, 3, 'output') #loss will be distance between predicted and true RGB loss = tf.reduce_mean(tf.reduce_sum(tf.squared_difference(y, y_pred), 1)) tf.summary.scalar('loss', loss) train_op = tf.train.AdamOptimizer(learning_rate).minimize(loss) merged_summary_op = tf.summary.merge_all() res_img = tf.cast(tf.clip_by_value(tf.reshape(y_pred, (1,) + img.shape), 0, 255), tf.uint8) img_summary = tf.summary.image('out', res_img, max_outputs=1) xs, ys = get_data(img) with tf.Session() as sess: tf.global_variables_initializer().run() train_writer = tf.summary.FileWriter(logdir + '/train', sess.graph) test_writer = tf.summary.FileWriter(logdir + '/test') batch_size = 50 for i in range(epochs): # Get a random sampling of the dataset idxs = np.random.permutation(range(len(xs))) # The number of batches we have to iterate over n_batches = len(idxs) // batch_size # Now iterate over our stochastic minibatches: for batch_i in range(n_batches): batch_idxs = idxs[batch_i * batch_size: (batch_i + 1) * batch_size] sess.run([train_op, loss, merged_summary_op], feed_dict={X: xs[batch_idxs], y: ys[batch_idxs]}) if batch_i % 100 == 0: c, summary = sess.run([loss, merged_summary_op], feed_dict={X: xs[batch_idxs], y: ys[batch_idxs]}) train_writer.add_summary(summary, (i * n_batches * batch_size) + batch_i) print("epoch {}, (l2) loss {}".format(i, c)) if i % 10 == 0: img_summary_res = sess.run(img_summary, feed_dict={X: xs, y: ys}) test_writer.add_summary(img_summary_res, i * n_batches * batch_size) def get_data(img): xs = [] ys = [] for row_i in range(img.shape[0]): for col_i in range(img.shape[1]): xs.append([row_i, col_i]) ys.append(img[row_i, col_i]) xs = (xs - np.mean(xs)) / np.std(xs) return xs, np.array(ys) if __name__ == "__main__": main()
- When docker build s a mirror, the starry.jpg image in the root directory is packaged for main.py to read.
- main.py uses the Andrej Karpathy's Image painting demo The goal of this model is to draw a new picture as close as possible to the original, Vincent Van Gogh's Star Night.
Configuration in Helm chart values.yaml is as follows:
image: ritazh / tf-paint: gpu useGPU: true hyperParamValues: learningRate: - 0.001 - 0.01 - 0.1 hiddenLayers: - 5 - 6 - 7
- Image: Configure the docker image corresponding to the training task, which is the mirror you created earlier.
- useGPU: bool value, default true means that you will use gpu for training, if false, you need to use tensorflow/tensorflow:1.7.0 base image when you make the image.
- hyperParamValues: Configuration of hyperparameters, where we configure only learningRate and hidden Layers.
The definition of TFJob, Tensorboard's Deployment and Service are the main definitions in Helm chart.
# First we copy the values of values.yaml in variable to make it easier to access them {{- $lrlist := .Values.hyperParamValues.learningRate -}} {{- $nblayerslist := .Values.hyperParamValues.hiddenLayers -}} {{- $image := .Values.image -}} {{- $useGPU := .Values.useGPU -}} {{- $chartname := .Chart.Name -}} {{- $chartversion := .Chart.Version -}} # Then we loop over every value of $lrlist (learning rate) and $nblayerslist (hidden layer depth) # This will result in create 1 TFJob for every pair of learning rate and hidden layer depth {{- range $i, $lr := $lrlist }} {{- range $j, $nblayers := $nblayerslist }} apiVersion: kubeflow.org/v1alpha1 kind: TFJob # Each one of our trainings will be a separate TFJob metadata: name: module8-tf-paint-{{ $i }}-{{ $j }} # We give a unique name to each training labels: chart: "{{ $chartname }}-{{ $chartversion | replace "+" "_" }}" spec: replicaSpecs: - template: spec: restartPolicy: OnFailure containers: - name: tensorflow image: {{ $image }} env: - name: LC_ALL value: C.UTF-8 args: # Here we pass a unique learning rate and hidden layer count to each instance. # We also put the values between quotes to avoid potential formatting issues - --learning-rate - {{ $lr | quote }} - --hidden-layers - {{ $nblayers | quote }} - --logdir - /tmp/tensorflow/tf-paint-lr{{ $lr }}-d-{{ $nblayers }} # We save the summaries in a different directory {{ if $useGPU }} # We only want to request GPUs if we asked for it in values.yaml with useGPU resources: limits: nvidia.com/gpu: 1 {{ end }} volumeMounts: - mountPath: /tmp/tensorflow subPath: module8-tf-paint # As usual we want to save everything in a separate subdirectory name: azurefile volumes: - name: azurefile persistentVolumeClaim: claimName: azurefile --- {{- end }} {{- end }} # We only want one instance running for all our jobs, and not 1 per job. apiVersion: v1 kind: Service metadata: labels: app: tensorboard name: module8-tensorboard spec: ports: - port: 80 targetPort: 6006 selector: app: tensorboard type: LoadBalancer --- apiVersion: extensions/v1beta1 kind: Deployment metadata: labels: app: tensorboard name: module8-tensorboard spec: template: metadata: labels: app: tensorboard spec: volumes: - name: azurefile persistentVolumeClaim: claimName: azurefile containers: - name: tensorboard command: - /usr/local/bin/tensorboard - --logdir=/tmp/tensorflow - --host=0.0.0.0 image: tensorflow/tensorflow ports: - containerPort: 6006 volumeMounts: - mountPath: /tmp/tensorflow subPath: module8-tf-paint name: azurefile
According to the above superparametric configuration, nine superparametric combinations will generate nine TFJob s at helm install, corresponding to all combinations of three learning rates and three hidden Layers we specified.
The main.py training script has three parameters:
| argument | description | default value |
|---|---|---|
| --learning-rate | Learning rate value | 0.001 |
| --hidden-layers | Number of hidden layers in our network. | 4 |
| --log-dir | Path to save TensorFlow's summaries | None |
Helm Install
Executing helm install command can easily accomplish all the training deployment corresponding to different combinations of hyperparameters. Here we only use single-machine training, you can also use distributed training.
helm install . NAME: telling-buffalo LAST DEPLOYED: NAMESPACE: tfworkflow STATUS: DEPLOYED RESOURCES: ==> v1/Service NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE module8-tensorboard LoadBalancer 10.0.142.217 <pending> 80:30896/TCP 1s ==> v1beta1/Deployment NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE module8-tensorboard 1 1 1 0 1s ==> v1alpha1/TFJob NAME AGE module8-tf-paint-0-0 1s module8-tf-paint-1-0 1s module8-tf-paint-1-1 1s module8-tf-paint-2-1 1s module8-tf-paint-2-2 1s module8-tf-paint-0-1 1s module8-tf-paint-0-2 1s module8-tf-paint-1-2 1s module8-tf-paint-2-0 0s ==> v1/Pod(related) NAME READY STATUS RESTARTS AGE module8-tensorboard-7ccb598cdd-6vg7h 0/1 ContainerCreating 0 1s
After deploying chart s, look at the created pods, and you should see the corresponding columns of Pods, as well as a single TensorBoard instance that monitors all panes:
$ kubectl get pods NAME READY STATUS RESTARTS AGE module8-tensorboard-7ccb598cdd-6vg7h 1/1 Running 0 16s module8-tf-paint-0-0-master-juc5-0-hw5cm 0/1 Pending 0 4s module8-tf-paint-0-1-master-pu49-0-jp06r 1/1 Running 0 14s module8-tf-paint-0-2-master-awhs-0-gfra0 0/1 Pending 0 6s module8-tf-paint-1-0-master-5tfm-0-dhhhv 1/1 Running 0 16s module8-tf-paint-1-1-master-be91-0-zw4gk 1/1 Running 0 16s module8-tf-paint-1-2-master-r2nd-0-zhws1 0/1 Pending 0 7s module8-tf-paint-2-0-master-7w37-0-ff0w9 0/1 Pending 0 13s module8-tf-paint-2-1-master-260j-0-l4o7r 0/1 Pending 0 10s module8-tf-paint-2-2-master-jtjb-0-5l84q 0/1 Pending 0 9s
Note: Some pod s are waiting to be processed due to GPU resources available in the cluster. If there are three GPUs in the cluster, there can be at most three TFJobs (one GPU per TFJob) for parallel training at a given time.
Identifying the Optimal Superparametric Combination as Early as possible by Tensor Board
TensorBoard Service is also created automatically when Helm install executes, and you can connect to TensorBoard using External-IP of the Service.
$ kubectl get service NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE module8-tensorboard LoadBalancer 10.0.142.217 <PUBLIC IP> 80:30896/TCP 5m
Visit TensorBoard's Public IP address through a browser and you will see pages like this (TensorBoard takes a little time to display images.)
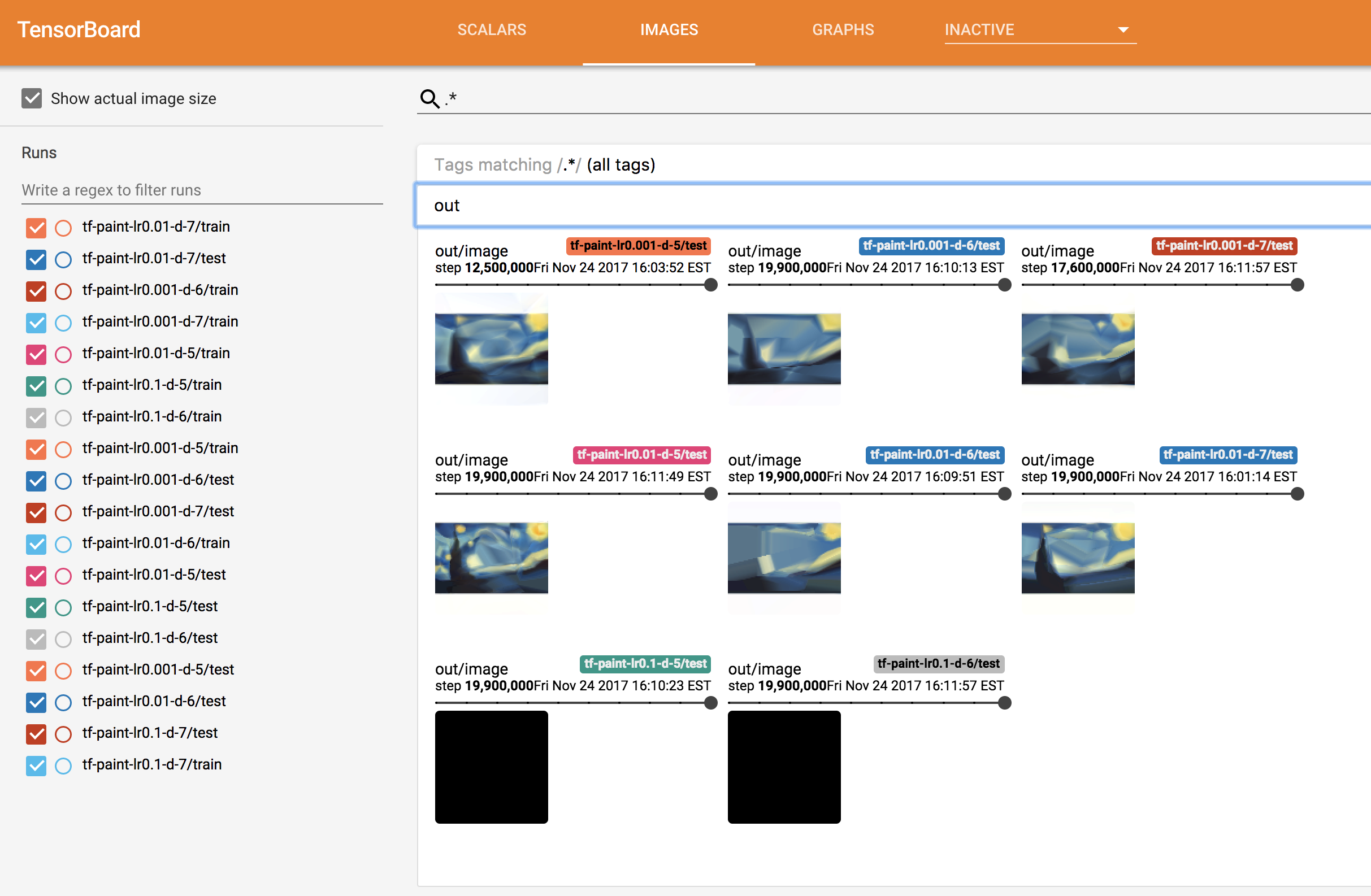
Here we can see that some hyperparametric models perform better than others. For example, all the models corresponding to learning rate of 0.1 generate all black images, and the effect of the models is very poor. In a few minutes, we can see that the two best-performing superparametric combinations are:
- hidden layers = 5,learning rate = 0.01
- hidden layers = 7,learning rate = 0.001
At this point, we can immediately Kill off other poor performance model training, release valuable gpu resources.
summary
In this paper, the use of Helm for Hyperparameter Sweep is briefly introduced, hoping to help you more efficient hyperparameter tuning.
Reference resources