Basic concepts
-
An index is similar to a table in a traditional relational database. It is a place to store relational documents
-
Document type [removed after version 7.0]
-
Document (doc)
A doc represents a piece of data in the index, like a record in the database table. Doc stores data in json format
es architecture design
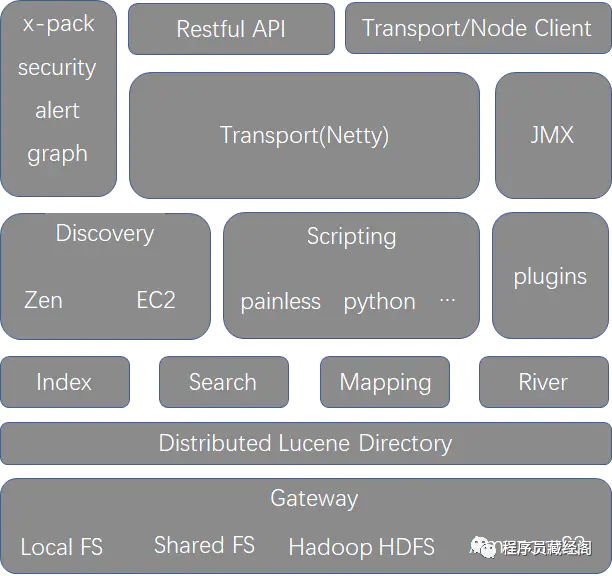
Simple definition of each component of the architecture:
-
The underlying storage system of gateway is generally a file system, which supports multiple types.
-
distributed lucence directory is based on lucence's distributed framework and encapsulates the implementation of inverted index, data storage, translog, segment and so on.
-
The module layer is the main module of ES, including index module, search module and mapping module.
-
The Discovery cluster node Discovery module is used for communication between cluster nodes, elects coordinate node operations, and supports a variety of Discovery mechanisms, such as zen, ec2, etc.
-
Script script parsing module is used to support scripts written in query statements, such as painless, groovy, python, etc.
-
plugins third-party plug-ins. Various advanced functions can be provided by plug-ins and support customization.
-
transport/jmx communication module, data transmission, netty framework is used at the bottom
-
restful/node provides an interface for accessing Elasticsearch cluster
-
An expansion package of x-pack elasticsearch, which integrates security, warning, monitoring, graphics and reporting functions, with seamless access and pluggable design.
Photo source: Nuggets
Request logic diagram
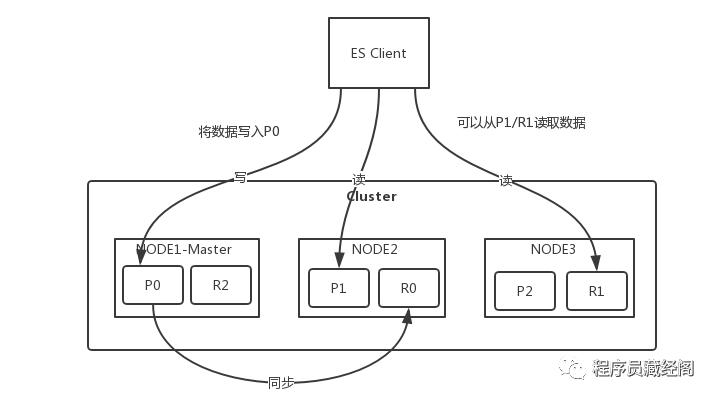
Source: Architect training
Create, delete and change operations
Create index
PUT /<index>
PUT /report_index_1
{
"settings": {
"number_of_shards": 3,
"number_of_replicas": 1
},
"mappings": {
"properties": {
"action_cost": {
"type": "double"
},
"activation": {
"type": "long"
},
"advertiser_name": {
"type": "text",
"fields":{
"keyword":{
"type":"keyword"
}
}
},
"cover_url": {
"type": "keyword"
},
"created_at": {
"type": "date",
"format": "yyyy-MM-dd HH:mm:ss || yyyy-MM-dd HH:mm:ss.SSS ||yyyy-MM-dd || epoch_millis || strict_date_optional_time || yyyy-MM-dd'T'HH:mm:ss'+'08:00"
}
}
}
}
Create doc
#Specify id
PUT /<index>/_doc/<_id>
PUT /report_index_1/_doc/1
{
"cover_url":"test2",
"activation":100
}
#Do not specify id
POST /<index>/_doc
POST /report_index_1/_doc/
{
"cover_url":"test2",
"activation":200
}
#If doc already exists during creation, an exception will be reported
PUT /report_index_1/_doc/10/_create
{
"cover_url": "test10",
"activation": 1000
}
Batch creation and operation
POST _bulk
{"index":{"_index":"report_index_1","_id":"1"}}
{"cover_url":"test1","activation":100, "advertiser_name":"Zhang San, Today is Monday"}
{"index":{"_index":"report_index_1","_id":"2"}}
{"cover_url":"test2","activation":200,"advertiser_name":"Thursday, today is Tuesday"}
{"index":{"_index":"report_index_1","_id":"3"}}
{"cover_url":"test3","activation":300,"advertiser_name":"Wang Wu is today Wednesday"}
{"index":{"_index":"report_index_1","_id":"4"}}
{"cover_url":"test4","activation":400, "advertiser_name":"Ma Saturday today is Thursday"}
{"create":{"_index":"report_index_1","_id":"5"}}
{"cover_url":"test5","activation":500, "advertiser_name": "Advertiser"}
{"delete":{"_index":"report_index_1","_id":"5"}}
{"update":{"_id":"1","_index":"report_index_1"}}
{"doc":{"cover_url":"test11"}}
Update index field
es does not support changing the type of existing fields. If you need to change, you need to reindex
PUT /<index>/_mapping
PUT /report_index_1/_mapping
{
"properties": {
"creative_create_time": {
"type": "date",
"format": "yyyy-MM-dd HH:mm:ss"
}
}
}
Update doc
#Update by id
PUT /<index>/_doc/<_id>
PUT /report_index_1/_doc/227
{
"advertiser_name" : "Hi Sushi-Lee"
}
#Update by condition
POST /report_index_1/_update_by_query
{
"query": {
"term": {
"advertiser_name": "Hi Sushi-Lee"
}
} ,
"script": {
"source": "ctx._source['advertiser_name'] = 'Hi Sushi'"
}
}
Delete index
DELETE /<index> DELETE /report_index_1
Delete doc
DELETE /<index>/_doc/<_id> DELETE /report_index_1/_doc/137
Empty doc
POST /report_index_1/_delete_by_query
{
"query": {
"match_all": {}
}
}
Common query types
General query
- Query all data of index
GET /report_index_1/_search
{
"query": {
"match_all": {}
}
}
- Specify id query
GET /report_index_1/_doc/1
- Fuzzy query
GET /report_index_1/_search
{
"query": {
"wildcard": {
"cover_url": {
"value": "*4*"
}
}
}
}
- Exist query
GET /report_index_1/_search
{
"query": {
"exists": {
"field": "cover_url"
}
}
}
- Range query
GET /report_index_1/_search
{
"query":{
"range": {
"activation": {
"gt": 1,
"lte": 200
}
}
}
}
- Accurate query
GET /report_index_1/_search
{
"query":{
"term": {
"_id": {
"value": "1"
}
}
}
}
- Regular query
GET /report_index_1/_search
{
"query": {
"regexp": {
"advertiser_name":"Zhang*"
}
}
}
- Compound query (bool query)
bool query can be used to merge query results of multiple filter criteria. It includes the following operators:
Must: the query must appear in the matching document
filter: for must, the score of the query will be ignored. Cache query
must_not: queries must not appear in matching documents
Should: the query should appear in the matching document. (do not force matching. If matching is found, the score is larger. If there is no must, at least one should query matching)
All {must} statements must match, and all} must_not , statements must not match, but how many , should , statements should match? By default, no 'should' statements must match, with one exception: when there is no 'must' statement, at least one 'should' statement must match. Just like we can control the accuracy of [match query]( https://www.elastic.co/guide/cn/elasticsearch/guide/current/match-multi-word.html#match -Like precision, we can use minimum_ should_ The match , parameter controls the number of , should , statements to match. It can be either an absolute number or a percentage
GET /report_index_1/_search
{
"query": {
"bool": {
"must": [
{
"terms": {
"_id": [
"1",
"2"
]
}
}
],
"must_not": [
{
"term": {
"cover_url": {
"value": "test2"
}
}
}
],
"should": [
{
"term": {
"cover_url": {
"value": "test1"
}
}
}
]
}
}
}
Text query
At present, the online es text word segmentation uses IK word segmentation
Official word splitter:
Fingerprint,Keyword,Language,Pattern,Simple,**Standard,**Stop,Whitespace
IK word segmentation (Chinese):
IK analyzer: ik_smart, ik_max_word
- math
GET /report_index_1/_search
{
"query": {
"match": {
"advertiser_name": {
"query": "Ma Liu today",
"analyzer": "standard"
}
}
}
}
- math_phrase
GET /report_index_1/_search
{
"query": {
"match_phrase": {
"advertiser_name": {
"query": "Ma Liu today",
"analyzer": "standard"
}
}
}
}
- View analysis results
POST /_analyze?pretty=true
{
"text":"Zhang San, Today is Monday",
"tokenizer":"ik_max_word"
}
Aggregation query
- bucket aggregation
group by equivalent to db
Fractional polymerization
GET /report_index_1/_search
{
"query":{
"range":{
"activation":{
"gte":300
}
}
},
"size": 0,
"aggs": {
"my-agg-name": {
"terms": {
"field": "advertiser_name.keyword"
}
}
}
}
- metric aggregation
Aggregate function equivalent to db; max,avg
GET /report_index_1/_search
{
"query":{
"range":{
"activation":{
"gte":300
}
}
},
"size": 0,
"aggs": {
"my-agg-name-avg":{
"avg": {
"field": "activation"
}
}
}
}
- bucket and metric combined query
GET /report_index_1/_search?pretty
{
"size":0,
"aggs": {
"my-agg-name": {
"terms": {
"field": "advertiser_name.keyword"
},
"aggs": {
"my-sub-agg-name": {
"avg": {
"field": "activation"
}
}
}
}
}
}
- pipe line aggregation
The object of pipeline aggregation is the output of other aggregations (bucket or some weight of bucket), rather than directly targeting the document.
The function of pipeline aggregation is to add some useful information to the output.
buckets_path: the weight path used to calculate the mean value
{
"aggs" : {
"sales_per_month" : {
"date_histogram" : {
"field" : "date",
"interval" : "month"
},
"aggs": {
"sales": {
"sum": {
"field": "price"
}
}
}
},
"avg_monthly_sales": {
"avg_bucket": { //Average the total sales of all months
"buckets_path": "sales_per_month>sales"
}
}
}
}
Cluster basic information query
- View basic cluster information
GET /
- View cluster node information
GET /_cluster/health?pretty
- View all index es of the cluster
GET /_cat/indices
- View index mapping information
GET /report_index_1/_mapping
example
Report condition query
POST /report_index_1/_search
{
"aggregations":{
"count":{
"cardinality":{
"field":"unit_id"
}
},
"group":{
"aggregations":{
"bucket_sort":{
"bucket_sort":{
"size":20
}
},
"lately_top_hit":{
"top_hits":{
"size":1,
"sort":[
{
"unit_create_time":{
"order":"desc"
}
}
]
}
},
"max_create_time":{
"max":{
"field":"unit_create_time"
}
},
"sum_aclick":{
"sum":{
"field":"aclick"
}
},
"sum_bclick":{
"sum":{
"field":"bclick"
}
},
"sum_charge":{
"sum":{
"field":"charge"
}
},
"sum_photo_click":{
"sum":{
"field":"photo_click"
}
},
"sum_show":{
"sum":{
"field":"show"
}
}
},
"terms":{
"field":"unit_id",
"order":[
{
"max_create_time":"desc"
}
],
"size":20
}
},
"sum_aclick":{
"sum":{
"field":"aclick"
}
},
"sum_bclick":{
"sum":{
"field":"bclick"
}
},
"sum_charge":{
"sum":{
"field":"charge"
}
},
"sum_photo_click":{
"sum":{
"field":"photo_click"
}
},
"sum_show":{
"sum":{
"field":"show"
}
}
},
"from":0,
"query":{
"bool":{
"filter":[
{
"range":{
"stat_date":{
"format":"yyyy-MM-dd",
"from":"2021-06-08",
"include_lower":true,
"include_upper":true,
"to":"2021-06-08"
}
}
},
{
"term":{
"campaign_id":62935142
}
}
]
}
},
"size":0
}