ElasticJob ‐ Lite: simple & dataflow job
The following introduction to ElasticJob comes from Official documents:
ElasticJob is a distributed scheduling solution for Internet Ecology and massive tasks. It is composed of two independent subprojects ElasticJob Lite and ElasticJob Cloud. It creates a distributed scheduling solution suitable for Internet scenarios through the functions of flexible scheduling, resource control and job governance, and provides diversified job ecology through open architecture design. Its products use a unified job API, and developers can deploy them at will with only one development. ElasticJob became a subproject of Apache ShardingSphere on May 28, 2020.
Elastic job can make development engineers no longer worry about non functional requirements such as linear throughput improvement of tasks, so that they can focus more on business oriented coding design; At the same time, it can also liberate the operation and maintenance engineers, so that they no longer have to worry about the availability of tasks and related management requirements, and can achieve the purpose of automatic operation and maintenance only by easily adding service nodes.
Environmental requirements:
- Java 8 and above.
- Maven 3.5.0 and above.
- ZooKeeper 3.6.0 and above.
Here, the use of the subproject ElasticJob Lite is introduced. The architecture of ElasticJob Lite is shown in the following figure:
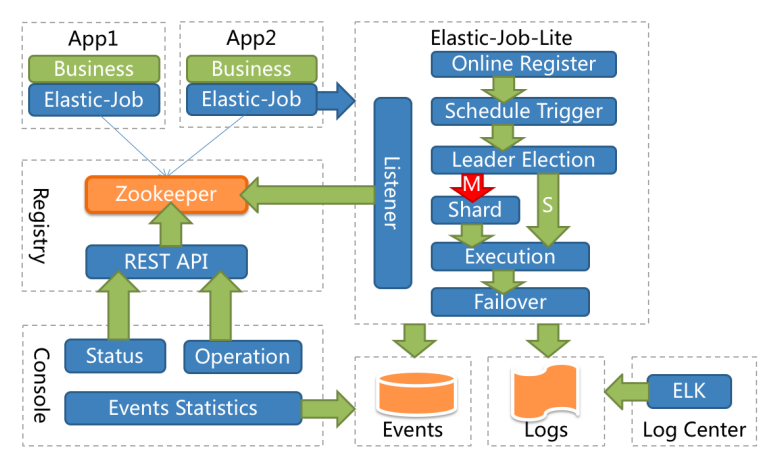
ElasticJob ‐ Lite will register the job on ZooKeeper and create a job name node under the defined namespace to distinguish different jobs. Therefore, once a job is created, the job name cannot be modified. If the job name is modified, it will be regarded as a new job.
Add dependency (3.0.1 is the latest release version):
<dependency>
<groupId>org.apache.shardingsphere.elasticjob</groupId>
<artifactId>elasticjob-lite-core</artifactId>
<version>3.0.1</version>
</dependency>
The job classification of ElasticJob is based on class and type. Class based jobs require developers to weave business logic by implementing interfaces; Type based jobs do not need coding, but only need to provide corresponding configuration. The method parameter shardingContext of class based job interface contains job configuration, slice and runtime information. The total number of fragments and the fragment serial number running on the job server can be obtained through getShardingTotalCount(), getShardingItem(), etc.
ElasticJob currently provides two class based job types: Simple and Dataflow, and two type based job types: Script and HTTP. Users can expand job types by implementing SPI interface.
This blog will only introduce Simple and Dataflow jobs. Other job types and extended job types will also be introduced by bloggers in the future.
Simple job
To define a Simple job, you need to implement the SimpleJob interface, which defines only one method and inherits the ElasticJob interface (this interface is obviously the SPI interface provided by ElasticJob to extend the job type, and the interfaces of other types of jobs also inherit this interface).
public interface SimpleJob extends ElasticJob {
void execute(ShardingContext shardingContext);
}
Define a Simple job. The task is divided into three parallel subtasks, and each subtask only outputs the current time and the task fragments executed by each subtask.
package com.kaven.job;
import org.apache.shardingsphere.elasticjob.api.ShardingContext;
import org.apache.shardingsphere.elasticjob.simple.job.SimpleJob;
import java.text.SimpleDateFormat;
import java.util.Date;
/**
* @Author: ITKaven
* @Date: 2021/11/20 17:02
* @Blog: https://kaven.blog.csdn.net
* @Leetcode: https://leetcode-cn.com/u/kavenit
* @Notes:
*/
public class MyJob implements SimpleJob {
private static final SimpleDateFormat formatter =new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
@Override
public void execute(ShardingContext shardingContext) {
switch (shardingContext.getShardingItem()) {
case 0:
System.out.println(formatter.format(new Date()) + " : ShardingItem[0]");
break;
case 1:
System.out.println(formatter.format(new Date()) + " : ShardingItem[1]");
break;
case 2:
System.out.println(formatter.format(new Date()) + " : ShardingItem[2]");
break;
default:
System.out.println(formatter.format(new Date()) + " : Unknown ShardingItem");
}
}
}
Jobs are defined, and jobs need to be configured, such as job name, number of slices, cron time expression and whether failure transfer is required. These configurations are mainly completed through JobConfiguration class, which provides builder style API s, such as the following job configuration. The job name is MySimpleJob and the number of job slices is 3, The task is executed at the 30th second of each minute, and the overwrite method is called to set whether the local configuration is overwritten to the registry when the job is started (it is not overwritten by default, for example, if the cron time expression is modified locally, it will not work). If it needs to be overwritten (the method is passed in true), the local configuration will be used every time it is started (that is, the local job configuration is the main one, otherwise the local modification of the job configuration will not work). The failover method is called to set whether to enable failure transfer (only applicable to the case where monitorExecution is enabled. monitorExecution is enabled by default, but failure transfer is not enabled by default). ElasticJob will not be re segmented during this execution (assign job fragmentation to the job node), but wait until the next scheduling before starting the re fragmentation process. When the server goes down during job execution, failure transfer allows the uncompleted task to be compensated and executed on another job node. Turn on the failure transfer function,
ElasticJob will monitor the execution status of each job slice and write it to the registry for other nodes to perceive. In a job scenario with long running time and long interval, failure transfer is an effective means to improve the real-time performance of job operation; for jobs with short interval, there will be a lot of network communication with the registry, which will affect the performance of the cluster Short interval operations do not pay attention to the real-time performance of a single operation. All fragments can be executed correctly through the re fragmentation of the next operation. Therefore, it is not recommended to start failure transfer for short interval operations. In addition, it should be noted that the idempotence of the operation itself is the premise to ensure the correctness of failure transfer.
private static JobConfiguration createJobConfiguration() {
return JobConfiguration.newBuilder("MySimpleJob", 3)
.cron("30 * * * * ?")
.overwrite(true)
.failover(true)
.build();
}
Job node 1:
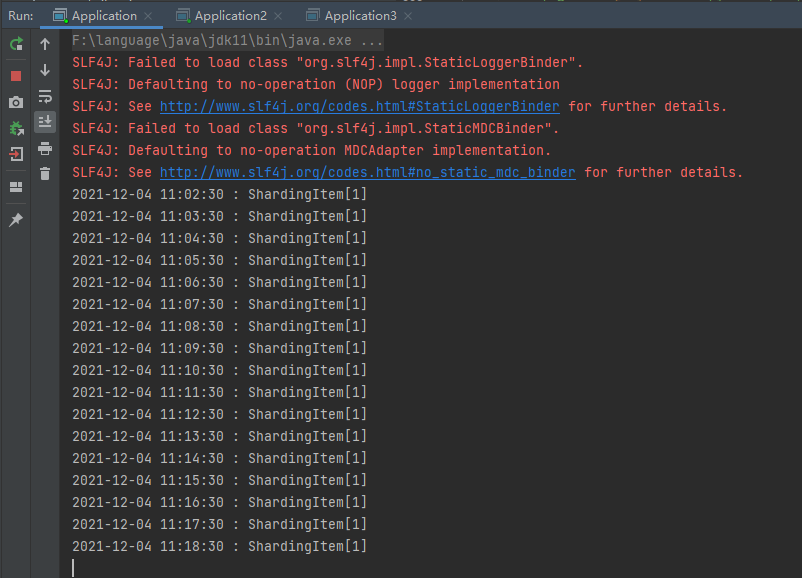
Job node 2 (when job node 3 goes down, it will compensate for the fragmentation of jobs not executed by job node 3):
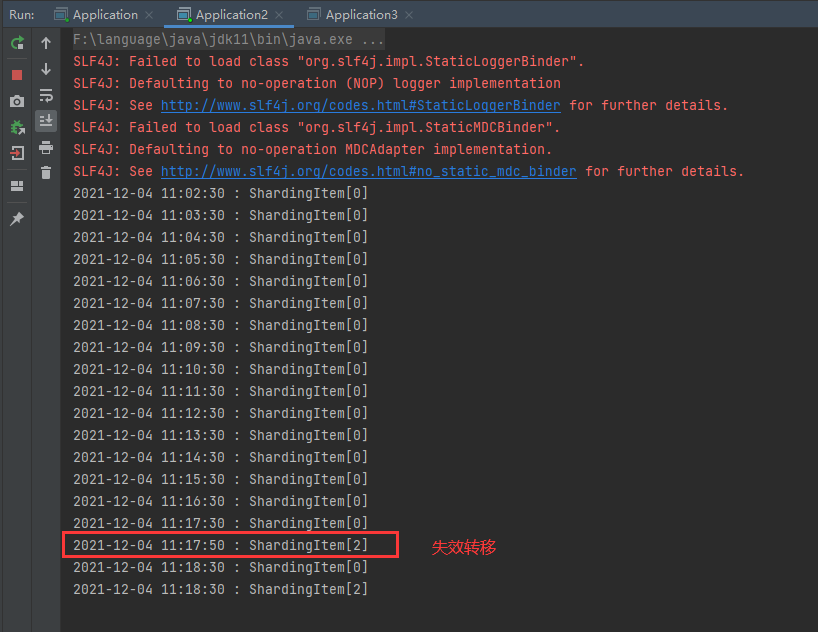
Job node 3 (simulated downtime):
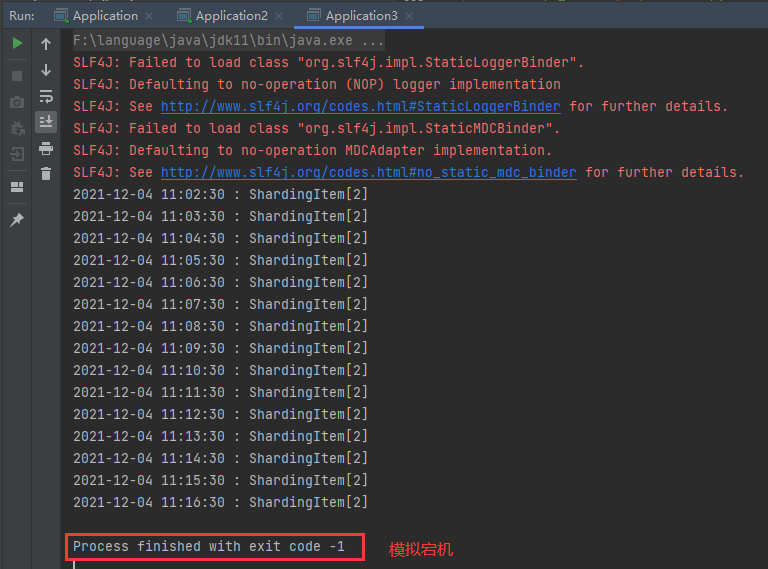
Next, you need to connect to the registration center (using ZooKeeper). At present, only ZooKeeper is supported as the registration center by default (the CoordinatorRegistryCenter interface has only one implementation class of ZookeeperRegistryCenter), so it can also be extended.
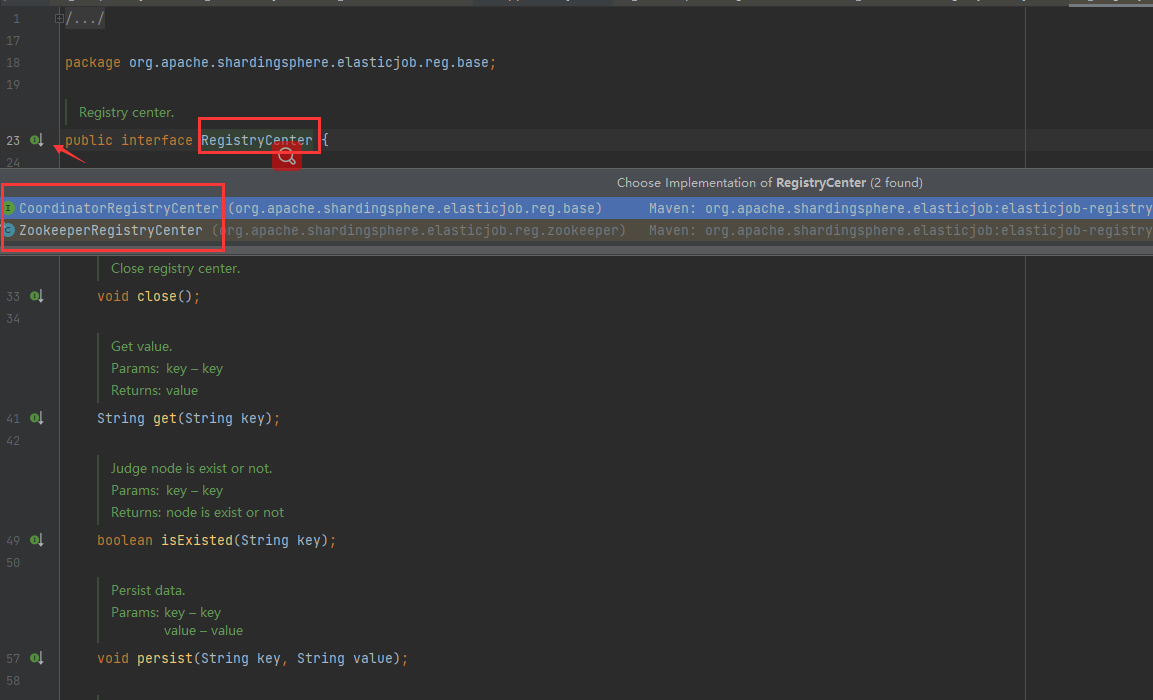
192.168.1.184:9000 is the client connection socket provided by ZooKeeper server, and my job is the namespace of the job.
private static CoordinatorRegistryCenter createRegistryCenter() {
ZookeeperConfiguration zc = new ZookeeperConfiguration("192.168.1.184:9000", "my-job");
zc.setConnectionTimeoutMilliseconds(40000);
zc.setMaxRetries(5);
CoordinatorRegistryCenter regCenter = new ZookeeperRegistryCenter(zc);
regCenter.init();
return regCenter;
}
After the various configurations and connection registries of the job are ready, the job can be started. It is implemented through the ScheduleJobBootstrap class, which mainly introduces the registry, job definition and job configuration into the instance of starting the job.
public static void main(String[] args) {
new ScheduleJobBootstrap(createRegistryCenter(), new MySimpleJob(),
createJobConfiguration()).schedule();
}
Summarize to Application class:
package com.kaven.job;
import org.apache.shardingsphere.elasticjob.api.JobConfiguration;
import org.apache.shardingsphere.elasticjob.lite.api.bootstrap.impl.ScheduleJobBootstrap;
import org.apache.shardingsphere.elasticjob.reg.base.CoordinatorRegistryCenter;
import org.apache.shardingsphere.elasticjob.reg.zookeeper.ZookeeperConfiguration;
import org.apache.shardingsphere.elasticjob.reg.zookeeper.ZookeeperRegistryCenter;
/**
* @Author: ITKaven
* @Date: 2021/11/20 17:05
* @Blog: https://kaven.blog.csdn.net
* @Leetcode: https://leetcode-cn.com/u/kavenit
* @Notes:
*/
public class Application {
public static void main(String[] args) {
new ScheduleJobBootstrap(createRegistryCenter(), new MySimpleJob(),
createJobConfiguration()).schedule();
}
private static CoordinatorRegistryCenter createRegistryCenter() {
ZookeeperConfiguration zc = new ZookeeperConfiguration("192.168.1.184:9000", "my-job");
zc.setConnectionTimeoutMilliseconds(40000);
zc.setMaxRetries(5);
CoordinatorRegistryCenter regCenter = new ZookeeperRegistryCenter(zc);
regCenter.init();
return regCenter;
}
private static JobConfiguration createJobConfiguration() {
return JobConfiguration.newBuilder("MySimpleJob", 3)
.cron("30 * * * * ?")
.overwrite(true)
.failover(true)
.build();
}
}
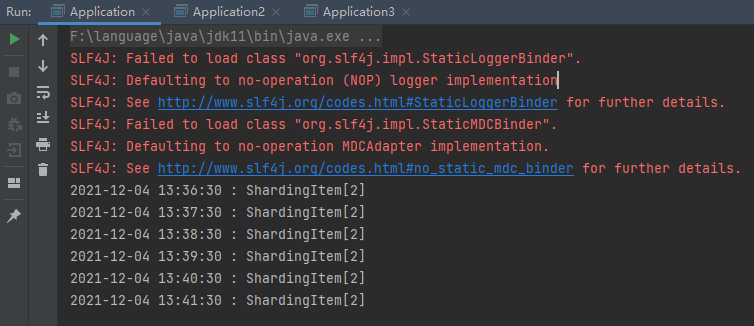
The results are shown in the figure below:
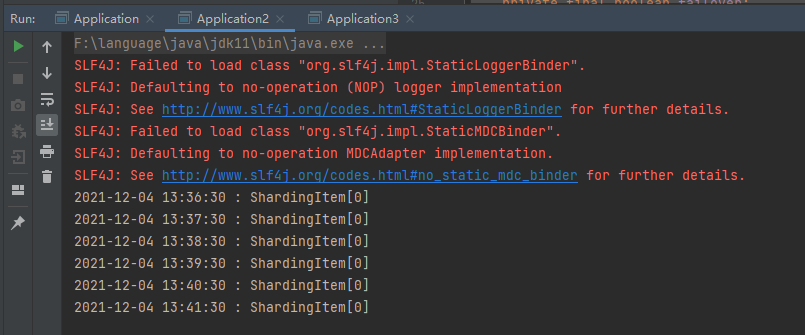
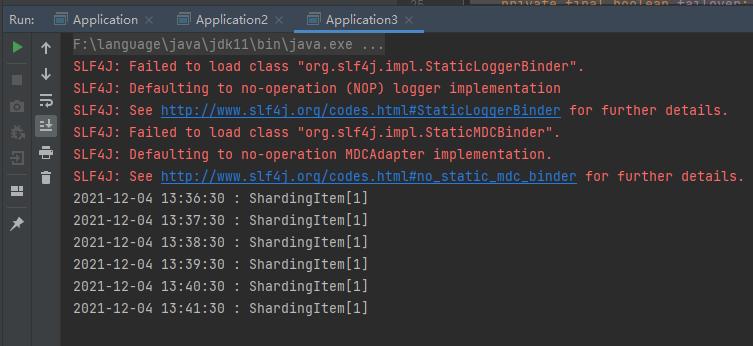
For the introduction of cron time expression, please refer to the following blog:
Dataflow job
Dataflow job is used to process data flow. It needs to implement DataflowJob interface. This interface provides two methods, which are used to fetch data and process data respectively.
package com.kaven.job;
import org.apache.shardingsphere.elasticjob.api.ShardingContext;
import org.apache.shardingsphere.elasticjob.dataflow.job.DataflowJob;
import reactor.core.publisher.Flux;
import java.text.SimpleDateFormat;
import java.util.*;
/**
* @Author: ITKaven
* @Date: 2021/11/20 17:02
* @Blog: https://kaven.blog.csdn.net
* @Leetcode: https://leetcode-cn.com/u/kavenit
* @Notes:
*/
public class MyDataflowJob implements DataflowJob<Flux<String>> {
private static final SimpleDateFormat formatter =new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
private static final String[][] message = {
{"java", "c", "c++", "python", "go"},
{"docker", "k8s"},
{"elastic-job", "elasticsearch", "zookeeper", "spring cloud alibaba"}
};
@Override
public List<Flux<String>> fetchData(ShardingContext shardingContext) {
int item = shardingContext.getShardingItem();
return Collections.singletonList(Flux.fromArray(message[item]));
}
@Override
public void processData(ShardingContext shardingContext, List<Flux<String>> list) {
System.out.println("-------------------------------------------------------------");
System.out.println(formatter.format(new Date()));
System.out.println(shardingContext.getShardingParameter());
list.forEach(MyDataflowJob::printData);
}
private static void printData(Flux<String> data) {
data.sort().toStream().forEach(System.out::println);
}
}
The Flux abstract class is provided by the reactor project. Spring's responsive programming is based on the reactor project. Responsive programming is a declarative programming paradigm based on data flow and change transmission. It will not be introduced in detail here. The code should be easy to understand. It is to obtain the corresponding string array according to the fragment item, and then print the string array. getShardingParameter method Used to obtain the corresponding slice parameters.
<dependency>
<groupId>io.projectreactor</groupId>
<artifactId>reactor-core</artifactId>
<version>3.3.8.RELEASE</version>
</dependency>
package com.kaven.job;
import org.apache.shardingsphere.elasticjob.api.JobConfiguration;
import org.apache.shardingsphere.elasticjob.lite.api.bootstrap.impl.ScheduleJobBootstrap;
import org.apache.shardingsphere.elasticjob.reg.base.CoordinatorRegistryCenter;
import org.apache.shardingsphere.elasticjob.reg.zookeeper.ZookeeperConfiguration;
import org.apache.shardingsphere.elasticjob.reg.zookeeper.ZookeeperRegistryCenter;
/**
* @Author: ITKaven
* @Date: 2021/11/20 17:05
* @Blog: https://kaven.blog.csdn.net
* @Leetcode: https://leetcode-cn.com/u/kavenit
* @Notes:
*/
public class Application {
public static void main(String[] args) {
new ScheduleJobBootstrap(createRegistryCenter(), new MyDataflowJob(),
createJobConfiguration()).schedule();
}
private static CoordinatorRegistryCenter createRegistryCenter() {
ZookeeperConfiguration zc = new ZookeeperConfiguration("192.168.1.184:9000", "my-job");
zc.setConnectionTimeoutMilliseconds(40000);
zc.setMaxRetries(5);
CoordinatorRegistryCenter regCenter = new ZookeeperRegistryCenter(zc);
regCenter.init();
return regCenter;
}
private static JobConfiguration createJobConfiguration() {
return JobConfiguration.newBuilder("MyDataflowJob", 3)
.shardingItemParameters("0=programming language,1=Container technology,2=frame")
.description("Data flow job")
.cron("30 * * * * ?")
.overwrite(true)
.monitorExecution(false)
.misfire(true)
.build();
}
}
shardingItemParameters method is used to set the mapping of partition items and partition parameters. Partition items and partition parameters are separated by equal sign, multiple partition items and partition parameters are separated by comma, and partition items start from zero, as also mentioned above. The monitorExecution method is used to set whether to start monitorExecution (it is started by default, and the default value is true). For short interval jobs, it is best to disable monitorExecution to improve performance (it will increase the pressure on ZooKeeper and reduce the performance of ZooKeeper, because data will be written to ZooKeeper every cron interval to ensure that data is obtained only once). If monitorExecution is disabled, it cannot guarantee duplicate data acquisition and cannot fail over, so the job needs to maintain idempotency. For long interval jobs, it is best to enable monitorExecution to ensure that data is obtained only once. The misfire method is used to set whether to start missed task re execution (enabled by default and true by default). ElasticJob does not allow jobs to be superimposed and executed at the same time. When the execution time of a job exceeds its running interval (for some reason), missing task re execution can ensure that the job continues to execute overdue jobs after completing the last task.
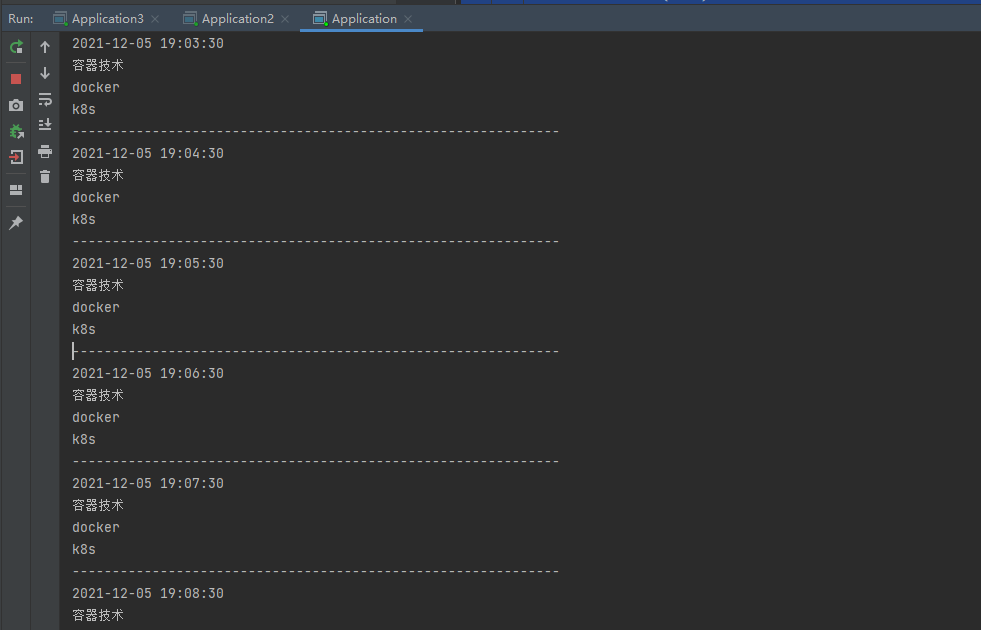
The results are shown in the figure below:
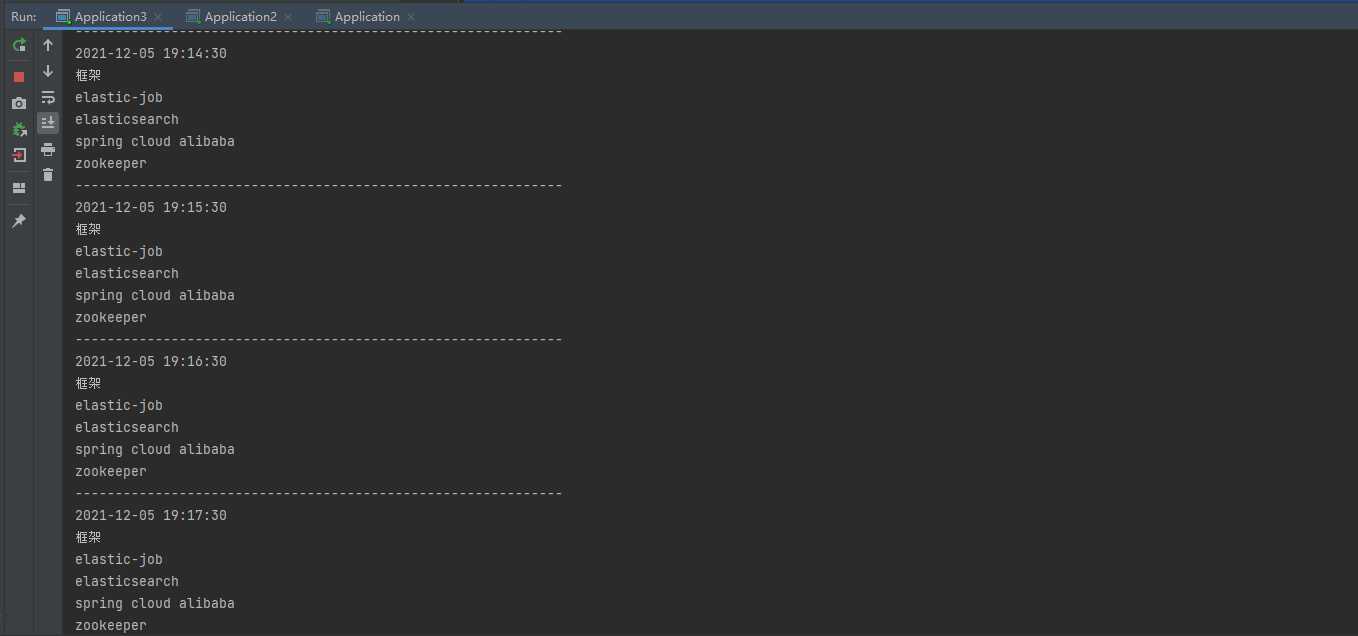
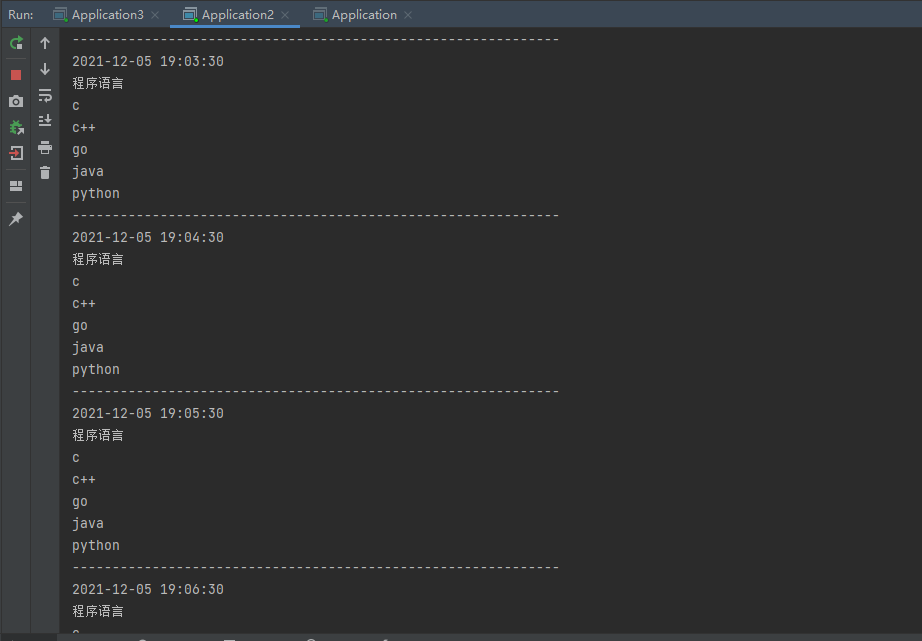
Originally, the blogger also planned to introduce the UI project of ElasticJob (other blogs are relatively simple), but he felt that there were bugs in the project (or the blogger's improper operation), and the blogger was discouraged (after adding the event tracking data source successfully, the database has not been written into the data. Due to the recent modification of the small paper, the blogger did not look at the source code), Interested friends can step on the pit( Official website,Github).
That's all for the Simple and Dataflow assignments. If the blogger is wrong or you have different opinions, you are welcome to comment and supplement.