ElasticSearch Foundation: start with inverted index and quickly recognize ES
- 1 ElasticSearch cognition
- 2 SpringBoot integration ES
- 3 ElasticSearch installation
- ElasticSearch Part 2: ElasticSearch advanced: an overview of the implementation of various ES queries in Java
1 ElasticSearch cognition
What is elastic search (ES)? according to ElasticSearch official website Elasticsearch is a distributed, RESTful style search and data analysis engine.
It's official, but it's also obscure. So, let's try to describe it more bluntly.
1.1 about search
First, we need to understand the following questions:
- What is search?
- Why is the database not suitable for processing searches?
- What is full text retrieval and Lucene?
When it comes to search, people will immediately associate it with the scene of inputting keywords on Baidu and Google to obtain relevant content. However, search is not equal to Baidu. Most APP supported on-site search is more popular.
Database is a powerful tool for storing and querying data. Is database suitable for search? The answer is not appropriate. The first reason is that when a large amount of data is stored in the database, the query efficiency is greatly reduced.
In addition, the database does not support some search scenarios. For example, in the following table, we try to search the data through the keyword "Chinese football", and the database cannot query the corresponding content.
id | name |
|---|---|
1 | Chinese men's football team |
2 | Chinese men's track and field team |
3 | Chinese Women Volleyball Team |
4 | Chinese women's diving team |
1.2 inverted index
What is an inverted index? Inverted index is also called reverse index. We usually understand that the index is to find value through key. On the contrary, inverted index is to find key through value, so it is called reverse index.
Let's use a simple example to describe the action process of inverted index:
If there are three data documents, the contents are:
Doc 1:Java is the best programming language Doc 2:PHP is the best programming language Doc 3:Javascript is the best programming language
In order to create an index, the ES engine splits the contents of each document into separate words (called terms, or terms) through the word splitter, creates these terms into a sorted list without duplicate terms, and then lists which document each term appears in. The results are as follows:
term | Doc 1 | Doc 2 | Doc 3 |
|---|---|---|---|
Java | √ | ||
is | √ | √ | √ |
the | √ | √ | √ |
best | √ | √ | √ |
programming | √ | √ | √ |
language | √ | √ | √ |
PHP | √ | √ | |
Javascript | √ | √ |
This structure consists of a list of all non repeating words in the document, and at least one document is associated with each word. This structure in which the location of records is determined by attribute values is inverted index. Files with inverted index are called inverted files.
Turn the above table into a more intuitive picture to show the inverted index:
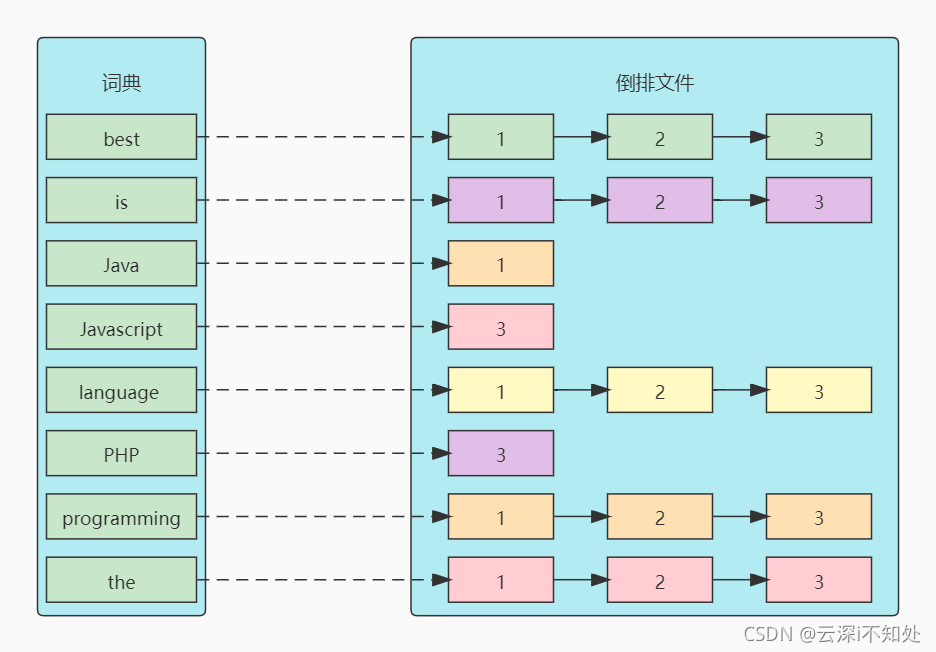
Among them, several core terms need to be understood:
- term: the smallest storage and query unit in the index. It is a word for English and a word after word segmentation for Chinese.
- Term Dictionary: also known as a dictionary, it is a combination of entries. The common index unit of search engine is word. Word dictionary is a string set composed of all words in the document set. Each index item in the word dictionary records some information of the word itself and pointers to all inverted words.
- Post list: a document is usually composed of multiple words. The inverted list records the occurrence and location of a word in which documents. Each record is called a Posting item. The inverted table records not only the document number, but also the word frequency and other information.
- Inverted File: the inverted list of all words is often sequentially stored in a file on the disk. This file is called an Inverted File. An Inverted File is a physical file that stores the inverted index.
Dictionary and inverted table are two very important data structures of Lucene, and they are important cornerstones for fast retrieval. Dictionaries and inverted files are stored in two parts. Dictionaries are stored in memory and inverted files are stored on disk.
1.3 Lucene
As for Lucene, to put it bluntly, it is a jar package that encapsulates various algorithms for establishing inverted indexes and matching indexes for search. We can introduce Lucene and develop based on its API.
ElasticSearch is implemented on the basis of Lucene. It encapsulates Lucene well, simplifies development, and provides many advanced functions.
ElasticSearch ecology
ElasticSearch was born to quickly retrieve and analyze big data. At present, it has formed a rich ecosystem.
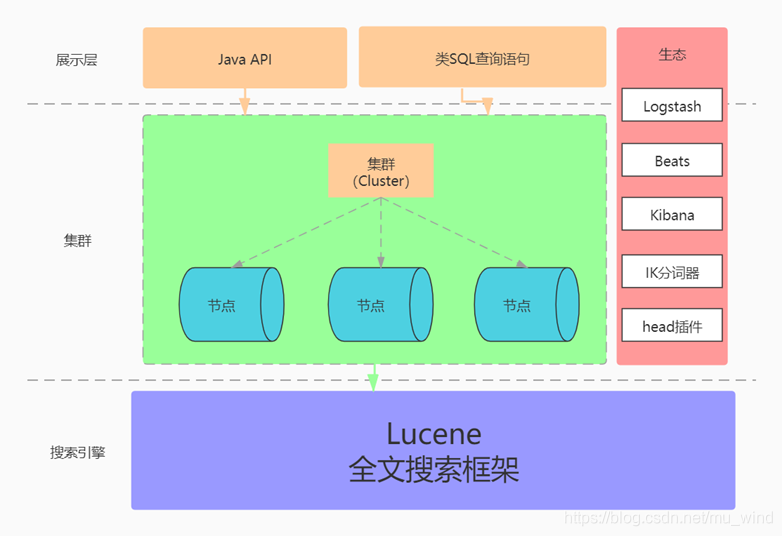
For example, the popular ELK system:
- Elasticsearch is a distributed search and analysis engine located at the core of the Elastic stack.
- Logstash and Beats help collect, aggregate, and enrich data and store it in Elasticsearch.
- Kibana enables you to interactively explore, visualize, and share insights into data, and manage and monitor the stack.
1.4 basic concept of ES
To understand elastic search, you must first understand the following proper nouns: index, type, document and mapping.
Since Elasticsearch can store and query data, we naturally want to compare it with the most famous database Mysql. A less rigorous analogy can be made between the two through the following table, mainly for convenience of understanding.
Mysql | Elasticsearch |
|---|---|
Index | Database |
Type | Table |
Document | Row |
Field | Column |
Mappings | Table structure (schema) |
- Index: index is equivalent to the database concept in relational database. It is a collection of data and a logical concept.
- Type: type, which is equivalent to the concept of table in the database. Before version 6.0, there can be multiple types in an Index. After version 7.0, multiple types are completely discarded. Each Index can only have one type, that is, "_doc". This concept doesn't need much attention.
- Document: document. The main entity stored in ES is called document, which can be understood as a row of data record in a table in a relational database. Each document consists of multiple fields. Different from relational database, ES is an unstructured database. Each document can have different fields and have a unique identification.
- Field: field, which exists in the document. A field is a key value pair containing data and can be understood as one of the columns of a row of Mysql data.
- Mapping: mapping defines the index fields and their data types in the index library, which is similar to the table structure in a relational database. ES dynamically creates indexes and mapping of index types by default.
Visual comparison between ES and Mysql:
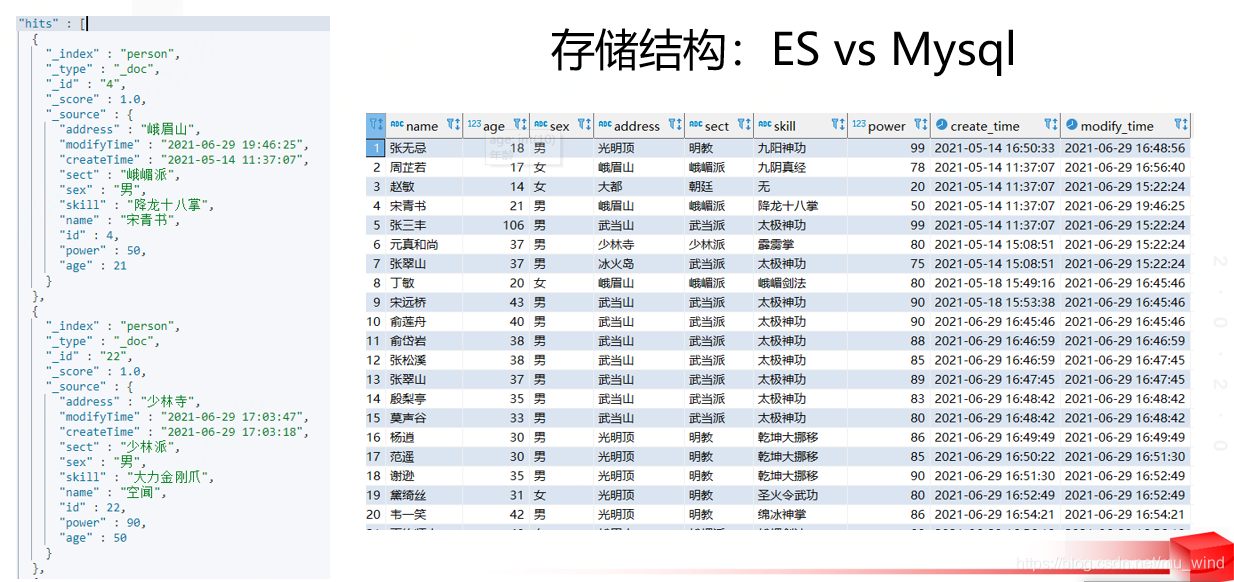
1.5 ES cluster concept
Elasticsearch is designed to support distribution naturally. Let's learn about the related concepts of cluster.
- Cluster: cluster. An ES cluster is composed of multiple node s. Each cluster has a common cluster name and is most identified.
- Node: node. An ES instance is a node. A machine can have multiple nodes.
- Shards: Shards. If an index contains so much data that one machine cannot store it, ES can divide the data in an index into multiple shards and store them on multiple servers. In this way, ES can scale horizontally, store more data, distribute search and analysis operations to multiple servers, and improve throughput and performance. Each shard is a minimum work unit, which carries part of the data, has a lucene instance and a complete ability to index and process requests.
- Replica: replica is the redundant backup of shard. It can prevent data loss and be responsible for fault tolerance and load balancing when shard is abnormal.
In actual production, ES is usually used in combination with Mysql and other storage systems, such as the following design:
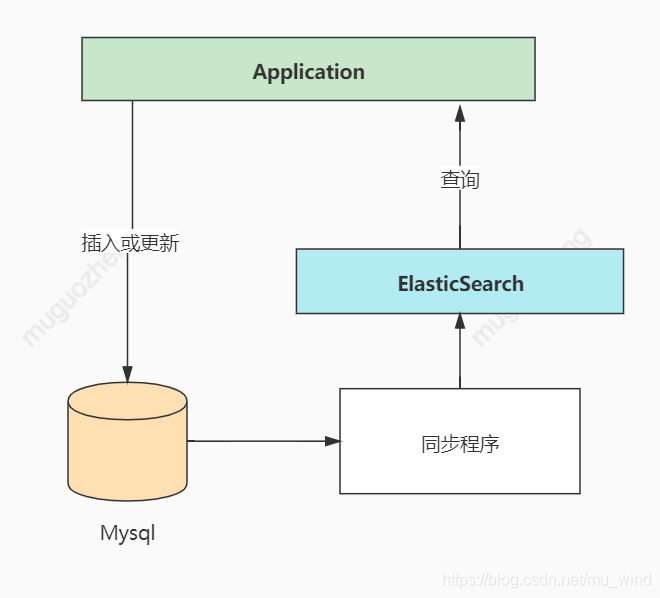
2 SpringBoot integration ES
Springboot integration with ES is very convenient. It only needs three steps:
1,pom. Add dependency to XML:
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-high-level-client</artifactId>
<version>7.8.0</version>
</dependency>
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-client</artifactId>
<version>7.8.0</version>
</dependency>
<dependency>
<groupId>org.elasticsearch</groupId>
<artifactId>elasticsearch</artifactId>
<version>7.8.0</version>
</dependency>2,application.yml add configuration:
elasticsearch: host: 11.50.36.97 port: 9200
3. New config class:
@Configuration
@ConfigurationProperties(prefix = "elasticsearch")
@Data
public class ESConfig {
private String host;
private Integer port;
@Bean(destroyMethod = "close")
public RestHighLevelClient client(){
return new RestHighLevelClient(RestClient.builder(new HttpHost(host, port)));
}
}Write a test method to test:
@RunWith(SpringJUnit4ClassRunner.class)
@SpringBootTest(classes = DemoApplication.class)
@Slf4j
public class BasicTest {
@Autowired
private RestHighLevelClient client;
/**
* Add index
*
* @throws IOException
*/
@Test
public void addIndex() throws IOException {
//1. Use the client to obtain the operation index object
IndicesClient indices = client.indices();
//2. Obtain the return value through specific operations
//2.1 set index name
CreateIndexRequest createIndexRequest = new CreateIndexRequest("person");
CreateIndexResponse createIndexResponse = indices.create(createIndexRequest, RequestOptions.DEFAULT);
//3. Judge the result according to the return value
System.out.println(createIndexResponse);
}
/**
* Query all indexes
*
* @throws IOException
*/
@Test
public void indexTest() throws IOException {
GetAliasesRequest request = new GetAliasesRequest();
GetAliasesResponse alias = client.indices().getAlias(request, RequestOptions.DEFAULT);
Map<String, Set<AliasMetadata>> map = alias.getAliases();
map.forEach((k, v) -> {
if (!k.startsWith(".")) {
System.out.println(k);
}
});
}
}3 ElasticSearch installation
3.1 download and installation
Download address: https://www.elastic.co/cn/downloads/elasticsearch
Installation:
1. Upload the compressed package to the linux server to a specific directory, such as / export/test 2. Unzip the compressed package: tar -zxvf elasticsearch-7.13.2-linux-x86_64.tar.gz
ES catalog introduction:
- bin: the executable file is in it, and the command to run es is in it, including some script files, etc
- config: configuration file directory
- JDK: java environment
- lib: dependent jar, class library
- logs: log file
- Modules: es related modules
- plugins: plug-ins that can be developed by yourself
- data: self built directory, which will be used later to place the index
3.2 modify configuration
First, we need to do some system configuration to use authorized users, such as root.
1. Configure user
Because the root user cannot directly run ES, a new user is added (if there is a non root user, it can also be used directly)
useradd es passwd es chown -R es elasticsearch
2. Set the maximum number of handles (nofile) and the maximum number of processes (nproc):
vim /etc/security/limits.conf
Add content at the end (ignore if existing):
* soft nofile 65536 * hard nofile 65536 * soft nproc 4096 * hard nproc 4096
3. Adjust VM max_ map_ Size of count
max_ map_ The count file contains a limit on the number of Vmas (virtual memory areas) a process can have
vim /etc/sysctl.conf
Add at the end of the text (ignore this step if it already exists):
vm.max_map_count=262144
Execute the following command for the configuration to take effect:
sysctl -p
Next, switch to the newly created user and modify the ES configuration file:
su es vim config/elasticsearch.yml
The following items are mainly modified:
# 1. Modify cluster name cluster.name: test-es # 2. Modify the current es node name node.name: node-1 # 3. Modify the data storage address (fill in according to your actual path) path.data: /export/test/elasticsearch-7.13.2/data # 4. Log data storage address (fill in according to your actual path) path.logs: /export/test/elasticsearch-7.13.2/logs # 5. Bind es network ip network.host: 0.0.0.0 # 6. Modify and initialize the master node cluster.initial_master_nodes: ["node-1"]
Start es service:
cd bin ./elasticsearch
visit http://192.168.1.13:9200/ , the following message appears, indicating that es is started successfully.
{
"name" : "node-1",
"cluster_name" : "elasticsearch",
"cluster_uuid" : "vMavXuuVTbmqykZpDEM0zQ",
"version" : {
"number" : "7.13.2",
"build_flavor" : "default",
"build_type" : "zip",
"build_hash" : "4d960a0733be83dd2543ca018aa4ddc42e956800",
"build_date" : "2021-06-10T21:01:55.251515791Z",
"build_snapshot" : false,
"lucene_version" : "8.8.2",
"minimum_wire_compatibility_version" : "6.8.0",
"minimum_index_compatibility_version" : "6.0.0-beta1"
},
"tagline" : "You Know, for Search"
}Set background startup:
./bin/elasticsearch -d
3.3 configuring Kibana
Download address: https://www.elastic.co/cn/downloads/kibana
Kibana is a Java application. Just unzip it. After decompression, enter the config directory of the file directory and edit kibana YML file, modify this item:
# Point to the ES service address we installed elasticsearch.hosts: ["http://11.50.36.97:9200/"]
Then, go to the bin directory and double-click kibana Bat to start.
The above is the basic content of ElasticSearch. More content will be added in the future. Please pay attention!