preface
This film blog is my notes recorded by watching the video of crazy God, which is convenient for reference when needed.
Video address: https://www.bilibili.com/video/BV17a4y1x7zq
1. Introduction to elasticsearch
Elastic search, ES for short. ES is an open source and highly extended distributed full-text retrieval engine, which can store and retrieve data in near real time; It has good scalability and can be extended to hundreds of servers to process BP (big data) level data. Es also uses Java to develop and use Lucene as its core to realize all epitome and search functions, but its purpose is to hide the complexity of Lucene through a simple RESTFul API, so as to make full-text search simple.
2.ElasticSearch installation and configuration
2.1. Installing ElasticSearch based on Docker
# Download the ElasticSearch image of version 7.6.1 docker pull elasticsearch:7.6.1 # Create and use containers through ElasticSearch images # ps: 9200 external access port, 9300 communication port docker run -d --name es -p 9200:9200 -p 9300:9300 -e "discovery.type=single-node" elasticsearch
2.2. to configure
# Enter the elasticsearch container docker exec -it es /bin/bash # Enter the config directory and find elasticsearch YML file cd config # Edit elasticsearch YML file vi elasticsearch.yml
The details are as follows:
cluster.name: user defined cluster name
network.host: the ip address bound to the current es node. The default is 127.0.0.1. If you need to open external access, this attribute must be set
The above two are default
http.cors.enabled: whether cross domain is supported. The default is false
http. cors. Allow origin: when the setting allows cross domain, the default is *, which means that all domain names are supported. If we only allow some websites to access, we can use regular expressions.
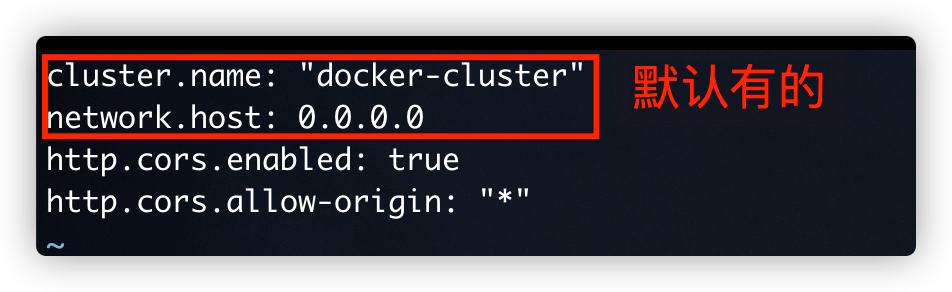
2.2.1.elasticsearch.yml profile
cluster.name: "docker-cluster" network.host: 0.0.0.0 http.cors.enabled: true http.cors.allow-origin: "*"
2.2.2. Configure the restart container
# Push out container exit # Restart container docker restart es
2.3. Browser access localhost:9200
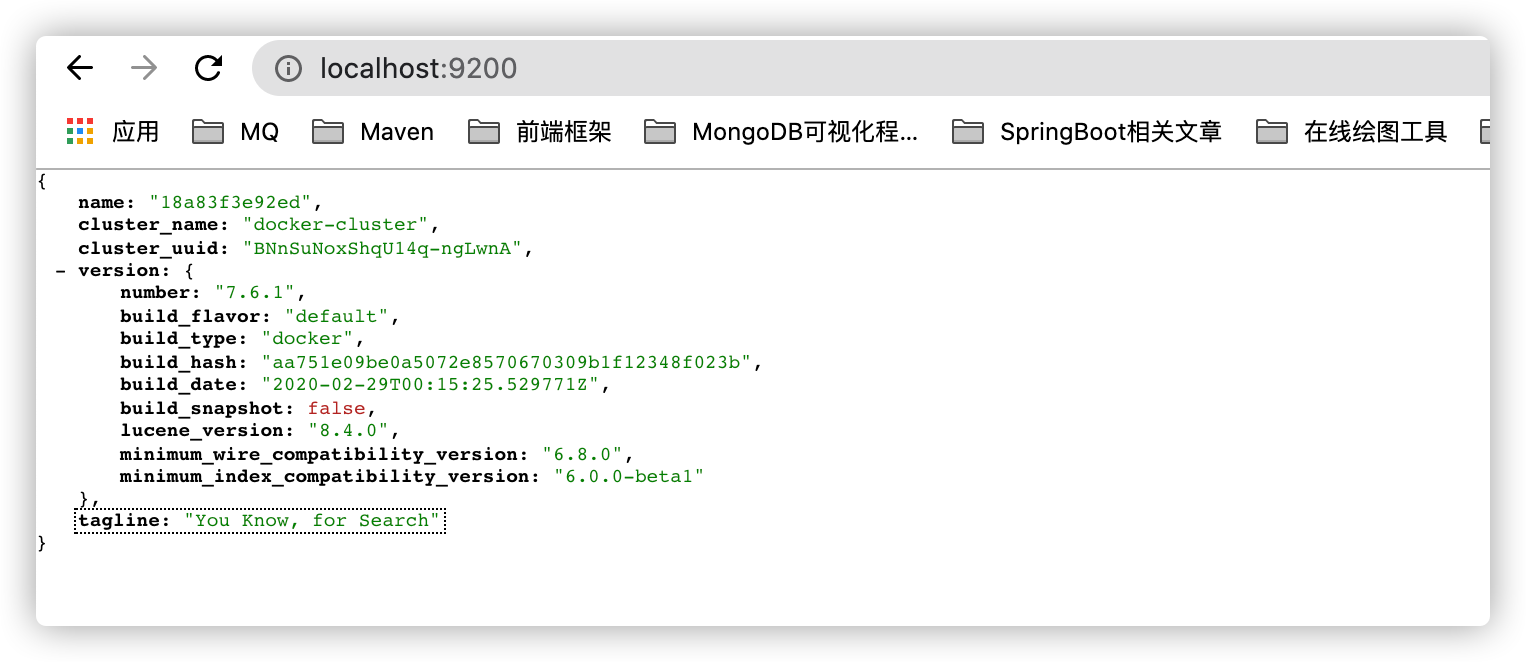
The above figure describes some basic information of ES. Including name, cluster name, cluster ID, version, opening method, and version information of dependent programs.
3. Description of elasticsearch directory structure
# Enter the container through the docker command docker exec -it es /bin/bash # View directory structure ls -ll
The details are shown in the figure below:
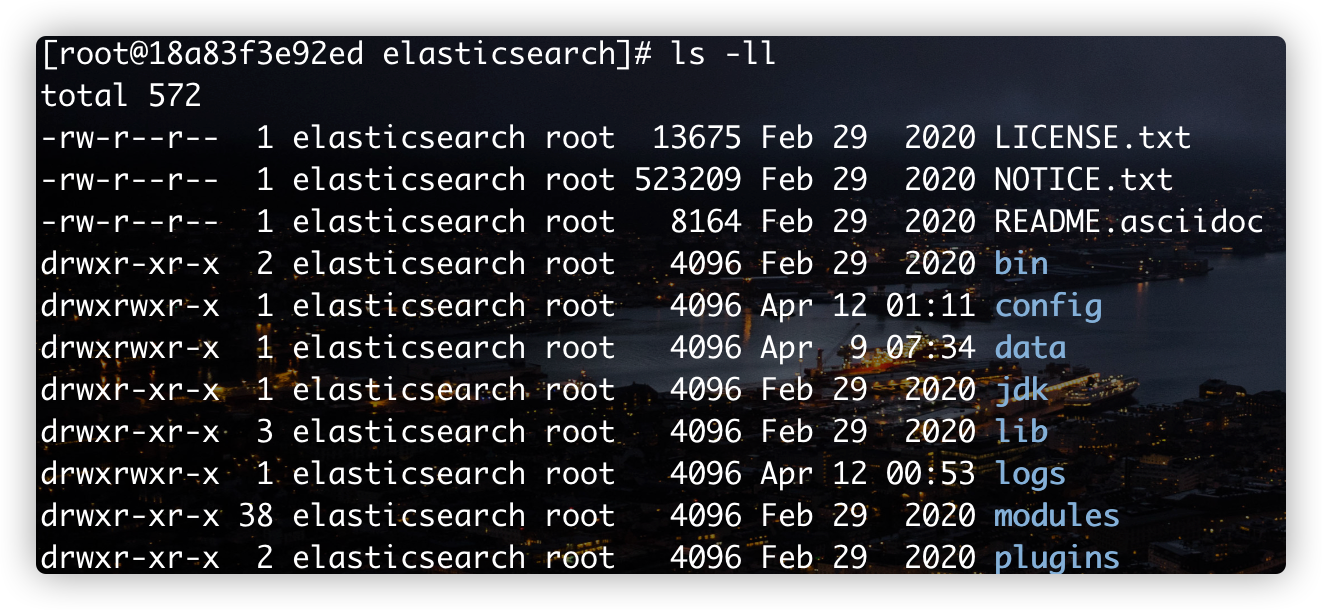
- LICENSE.txt: Certificate description file
- NOTICE.txt: precautions for product use
- README. ASCII doc: description or usage file
- bin: startup file
- config: configuration file
- log4j2: log configuration file
- jvm.options Java virtual machine related configuration
- elasticsearch. Configuration file of YML elasticsearch
- lib: related dependent packages
- Logs: logs
- Modules: function modules
- plugins: plug-ins
4. Use visualization tools to connect ElasticSearch
Installation: elasticsearch-head
Download address: https://github.com/mobz/elasticsearch-head
5. Install Kibana
5.1. Introduction to kibana
Kiibana is an open-source search platform for displaying and analyzing data, and kiibana can be used for interactive analysis of search data. Kibana makes massive data easier to understand. It is easy to operate and gives the browser a user interface. It can quickly create a dashboard and display the elasticsearch query dynamics in real time. Setting up kibana is very simple. Without coding or additional infrastructure, kibana installation can be completed and elasticsearch microcosm monitoring can be started in a few minutes
5.2.Docker installation Kibana
Note: the version of Kibana should be consistent with that of ElasticSearch
# Download Kibana image version 7.6.1
docker pull kibana:7.6.1
# When creating containers through Kibana images, it should be noted that ELASTICSEARCH_URL=http://IP:9200 The IP in is the IP of the server where elasticsearch is located
# You can first obtain the IP address of the server where elasticsearch is located through the following command
docker inspect --format '{{ .NetworkSettings.IPAddress }}' es
# The IP address I got here is 172.17.0.2
docker run --name kibana -d -p 5601:5601 --link es -e "ELASTICSEARCH_URL=http://172.17.0.2:9200" kibana:7.6.1
After the above operations are completed, access the address in the browser: localhost:5601. If you can see the following interface, Kibana has been installed
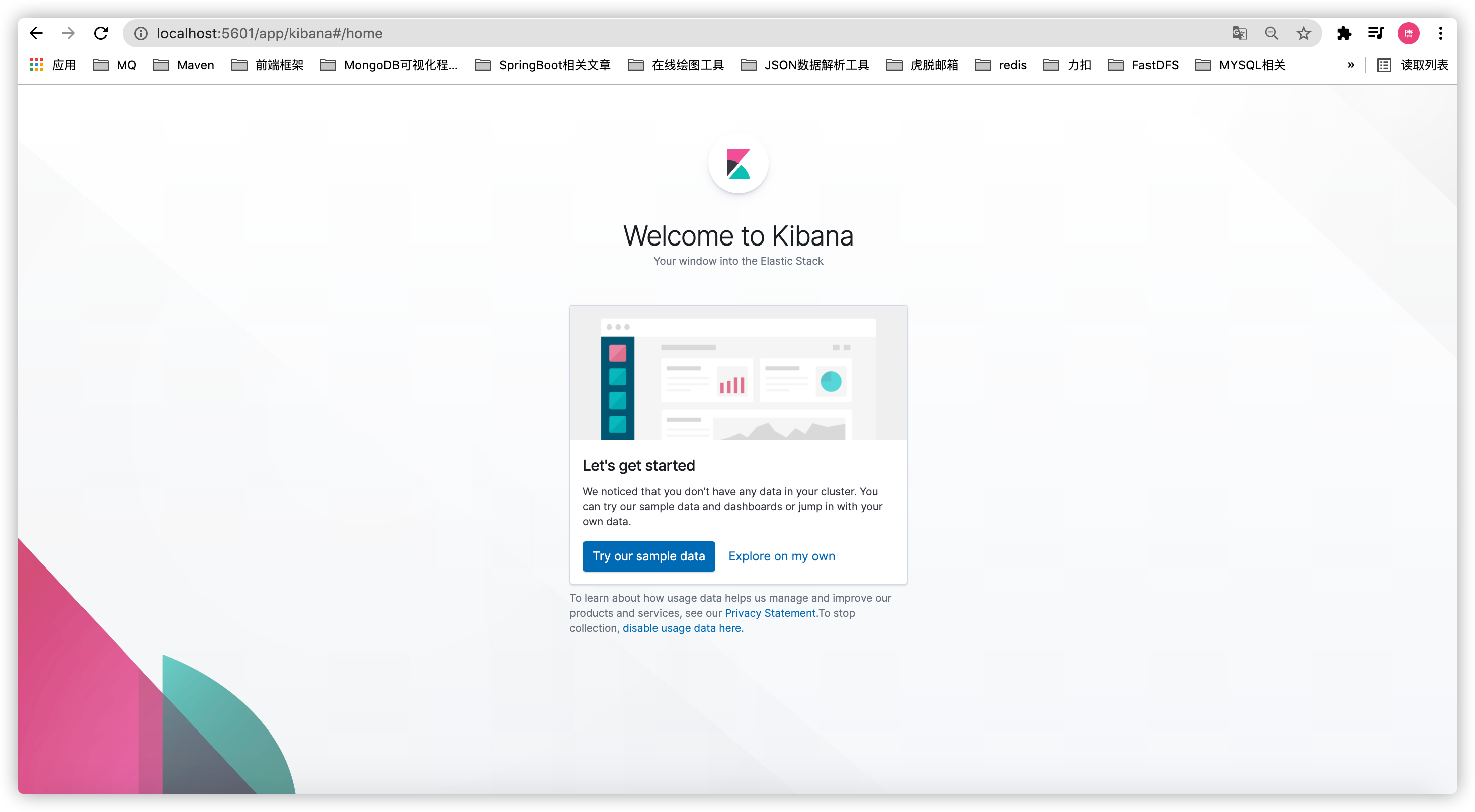
If you visit the address and see the following interface, it indicates that the IP pointing to the Kibana container created does not have the elasticsearch container IP.
At this point, we can solve this problem by modifying Kibana's configuration file
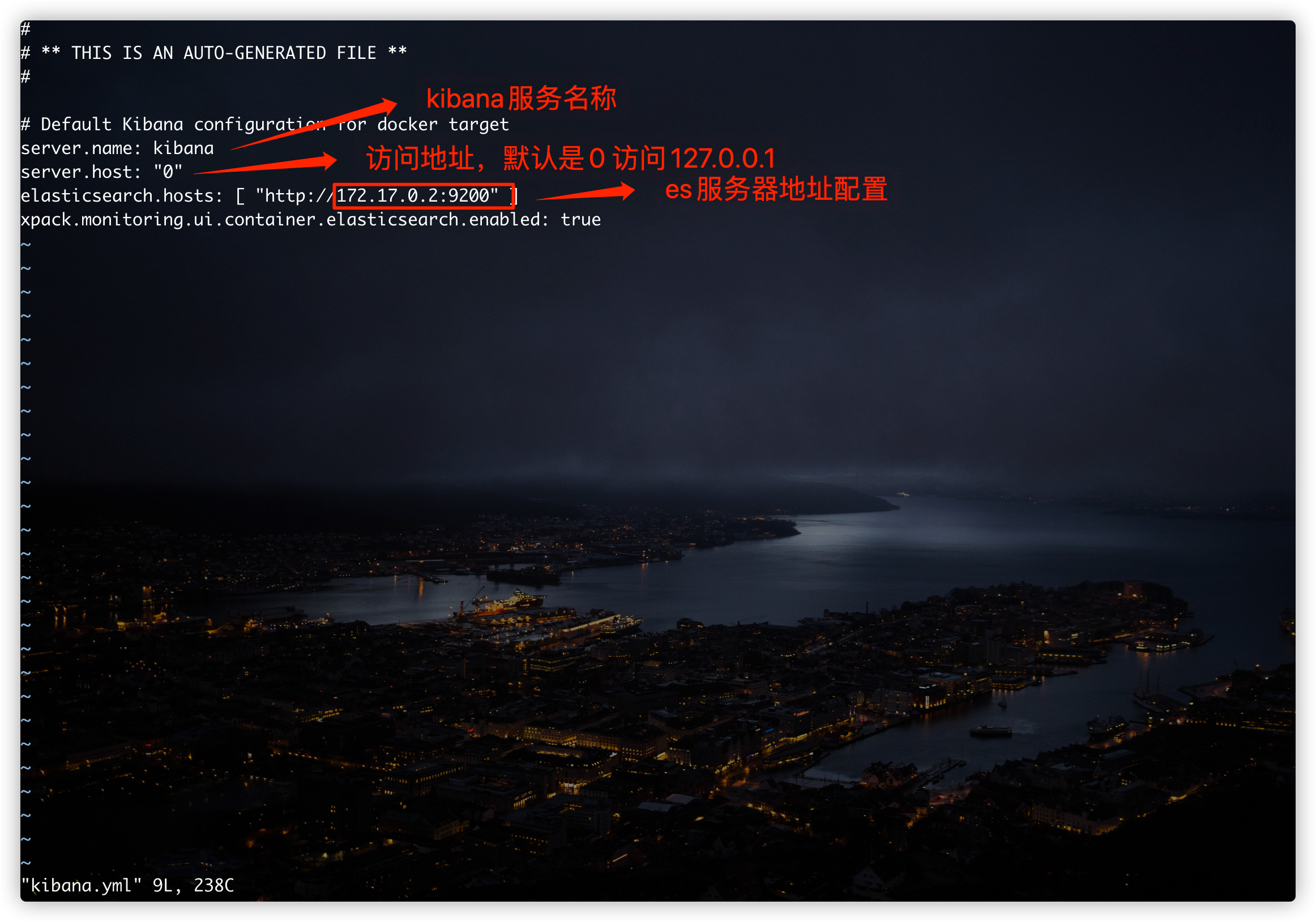
# Enter the inside of Kibana container docker exec -it kibana /bin/bash # Enter configuration folder cd config # Modify kibana YML profile vi kibana.yml
As shown in the following figure, elasticsearch. Needs to be modified With the configuration of hosts, change the access IP to the elastic search service address
5.3. use
6. Core concepts of elasticsearch
Elasticsearch is a document oriented non relational database.
The objective comparison between relational database and Elasticsearch is as follows:
| Relational database | Elasticsearch |
|---|---|
| database | Indexes (indexes) |
| table | Types (types, to be deprecated) |
| row data | documents |
| Fields (columns) | fields |
The elastic search (cluster) can contain multiple indexes (databases), each index can contain multiple types (tables), each type contains multiple documents (rows), and each document contains multiple fields (columns)
ES physical design
Elastic search divides each index into multiple slices in the background, and each slice can be migrated between different servers in the cluster
logic design
An index type contains multiple documents, such as document 1 and document 2 When we search a document, we can find it in this order:
Through this combination, we can retrieve a specific document.
Note: the ID does not have to be an integer, it is actually a string
6.1. file
Elasticserach is document oriented, which means that the smallest unit of indexing and searching data is the document. Elasticsearch, which has several important attributes:
- Self inclusion: a document contains both fields and corresponding values, that is, key:value at the same time
- It can be hierarchical. A document contains sub documents, which is the logical entity of scum
- Flexible structure, the document does not rely on pre mode. In a relational database, fields must be defined in advance before they can be used. In elastic search, fields are very flexible. Sometimes you can ignore some fields or add a new field dynamically
Although we can add or ignore a field at will, the type of each field is very important. For example, an age field type can be either a string or an integer. Because elasticsearch will save the mapping between fields and types and other settings. This mapping is specific to each type of each mapping, which is why the mapping between fields and types and other settings are saved in elastic search. This mapping is specific to each type of each mapping, which is why types sometimes become mapping types in elastic search.
6.2. type
A type is a logical container for documents. Just like a relational database, a table is a container for rows. The definition of a field in a type is called mapping. For example, name is mapped to a string type. We say that the document is modeless. It doesn't need to have all the fields defined in the mapping. For example, if you add a new field, elasticsearch will automatically add the new field to the mapping, but elasticsearch doesn't know what type this field is, so it will guess about it. If the value is 18, elasticsearch will consider it an integer type. But elastic search may also be wrong. The safest way is to define the required mapping with money in advance.
6.3. Indexes
The index is the container of mapping relationship. The index in elastic search is a very large collection of documents. The index stores the fields and other settings of the mapping type, which are then stored on each slice.
6.4. Physical design: how nodes and shards work
A cluster has at least one node, and a node is an elasticsearch process. A node can have multiple indexes (default). If you create an index, the index will be composed of five primary shards, and each primary shard will have a replica shard
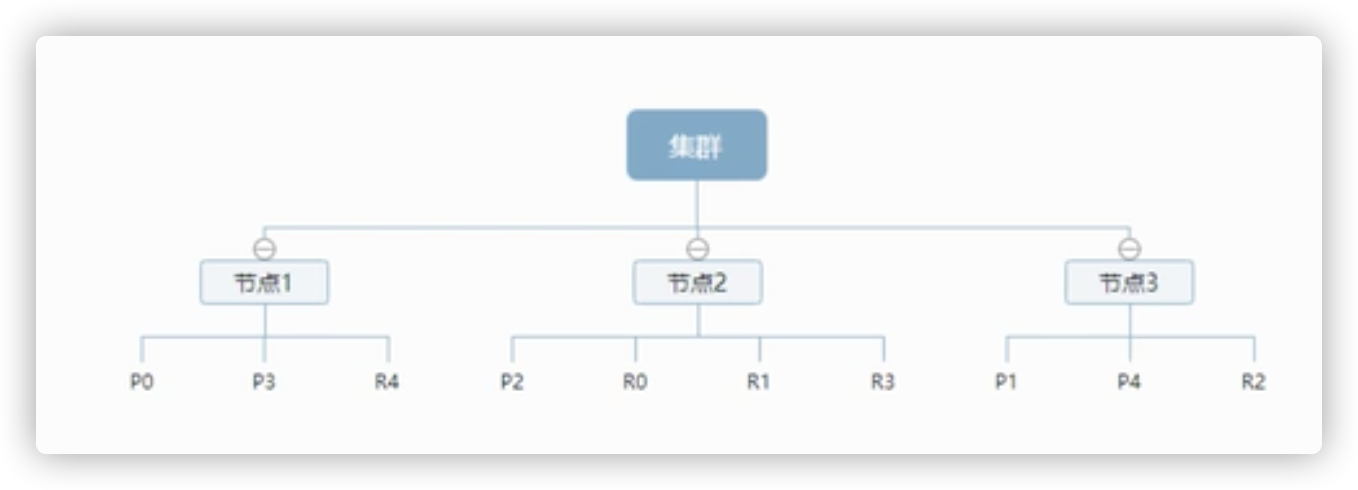
As the figure above shows a 3-node cluster, it can be seen that the primary partition and the replication partition will not be in the same node, which is conducive to an unexpected down of a node and no data loss. In fact, a fragment is a Lucene index, a file directory included in the index. The inverted index structure enables elastic search to tell you that those documents contain specific keywords without scanning all documents
6.5. Inverted index
Elasticsearch uses a structure called inverted index, which uses Lucene inverted index as the bottom layer. This structure is suitable for fast full-text search. An index consists of all non duplicate lists in the document. For each word, there is a document list. For example, there are now two documents, each containing the following:
study every day,good good up to forever # Contents of document 1 To forever,study every day,good good up # Content contained in document 2
In order to create an inverted index, we first split each document into independent words (or called entries or tokens), then create a sorted list containing all non repeated entries, and then list each entry in that document
| Term | doc_1 | doc_2 |
|---|---|---|
| study | V | X |
| To | X | V |
| every | V | V |
| forever | V | V |
| day | V | V |
| study | X | V |
| good | V | V |
| every | V | V |
| to | V | X |
| up | V | V |
Now, let's search for a to forever, just look at the document containing each entry
| Term | doc_1 | doc_2 |
|---|---|---|
| to | V | X |
| forever | V | V |
| total | 2 | 1 |
Both documents match, but the first document matches more than the second. If there are no other conditions, now the document containing both keywords will be returned
Example of inverted index understanding:
For example, we search blog posts through blog tags, as follows:
| Blog post ID | label |
|---|---|
| 1 | python |
| 2 | python |
| 3 | Linux python |
| 4 | Linux |
Then the inverted index list is such a structure
| label | Blog post ID |
|---|---|
| python | 1,2,3 |
| Linux | 3,4 |
If you want to search for articles with python tags, it will be much faster to find the inverted index data than to find all the original data. Just check the label column and get the relevant article ID to completely filter irrelevant documents.
Comparison between elasticsearch index and Lucene index
In elastic search, the word index is frequently used, which is the use of the term. In elastic search, the index is divided into multiple slices, each of which is an index of Lucene. Therefore, an elastic search index is composed of multiple Lucene indexes.
7.IK word splitter
What is an IK word breaker?
Word segmentation: that is to divide a paragraph of Chinese or others into keywords. When searching, we will segment our own information, segment the data in the database or index database, and then conduct a matching operation. The default Chinese word segmentation is to treat each word as a word.
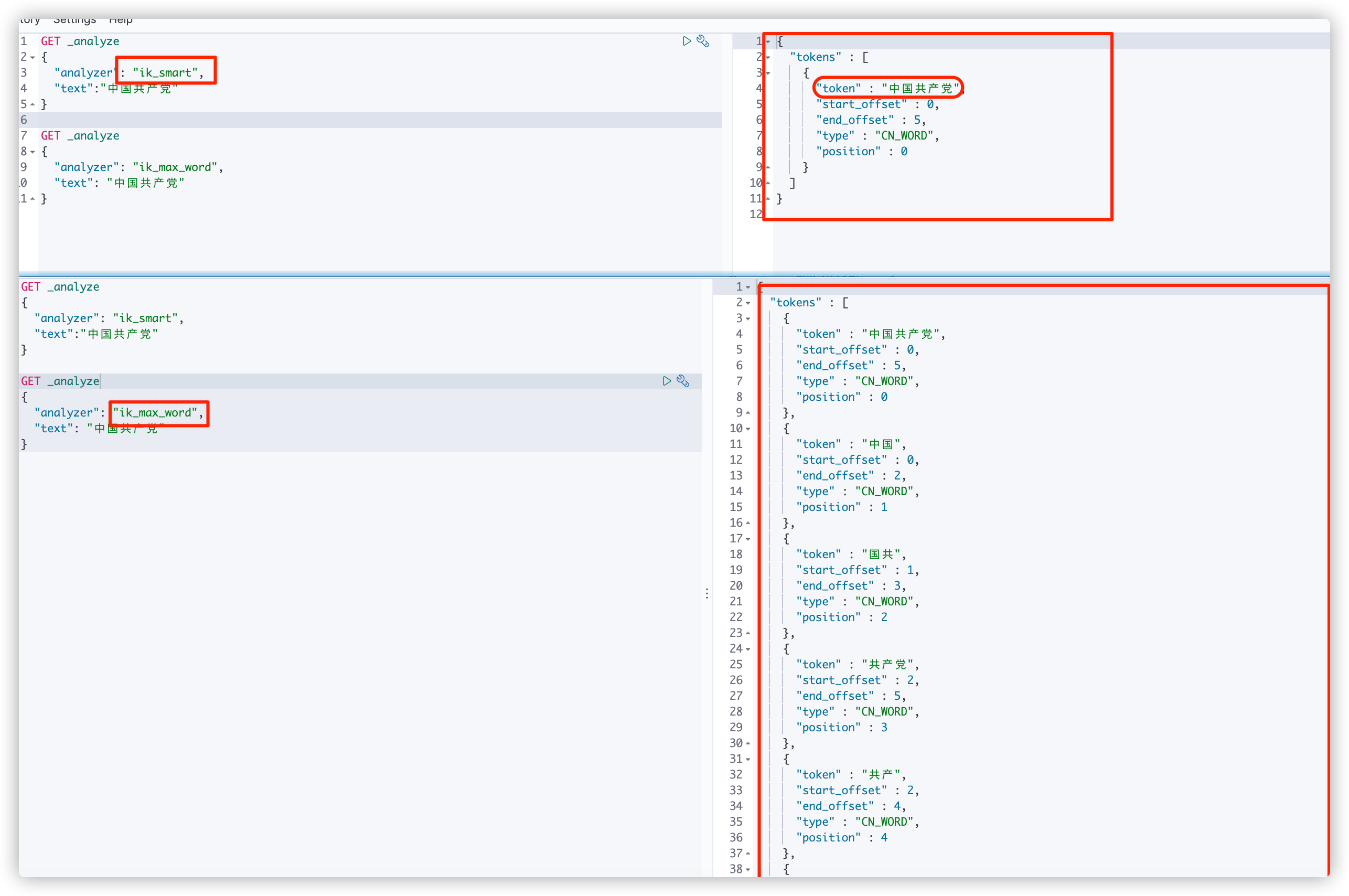
IK provides two word segmentation algorithms: ik_smart and ik_max_word, where ik_smart is the least segmentation, ik_max_word is the most fine-grained division!
7.1. Install IK word breaker
# Enter the elasticsearch container docker exec -it es /bin/bash # Enter the plug-in directory cd /usr/share/elasticsearch/plugins # Download the IK word splitter plug-in (my version here is the corresponding es version) elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.6.1/elasticsearch-analysis-ik-7.6.1.zip # After downloading, exit the es container and restart the es container
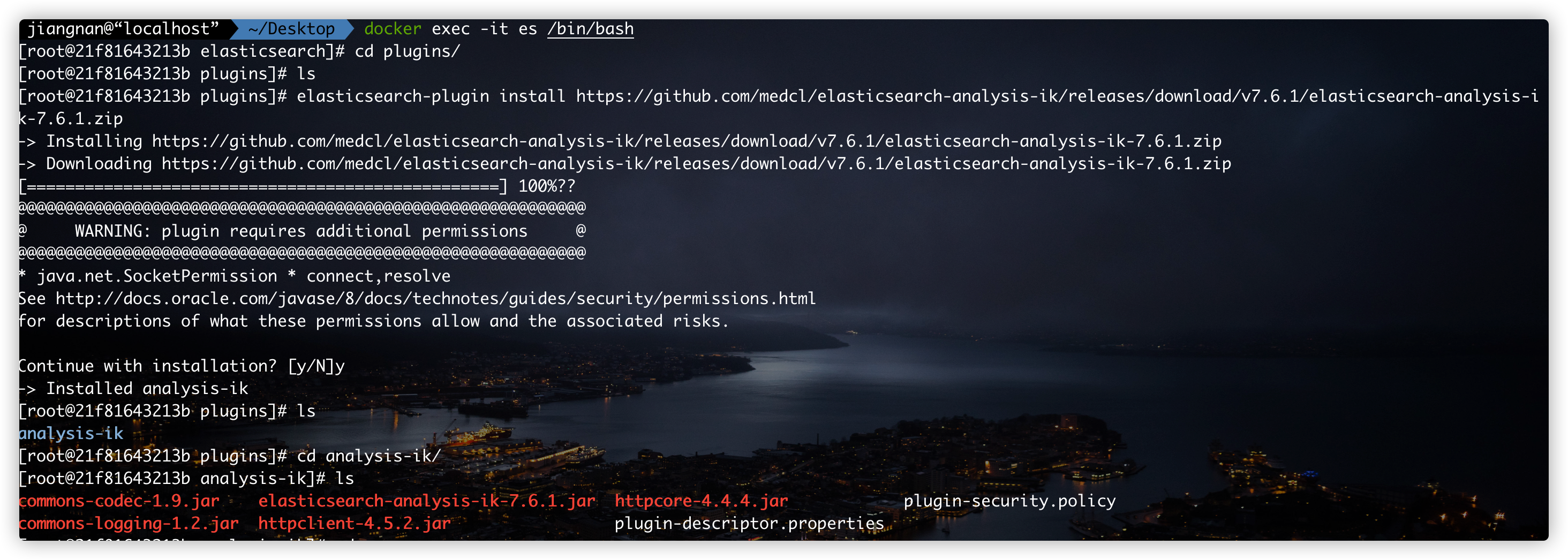
7.2.IK word breaker usage
Using Kibana test
7.3. Word splitter extended dictionary configuration
IK word splitter will split according to the algorithm, and the split is based on its default thesaurus. Maybe some words we want to connect can't meet the requirements of the default thesaurus. At this time, we can define some thesaurus dictionaries by ourselves.
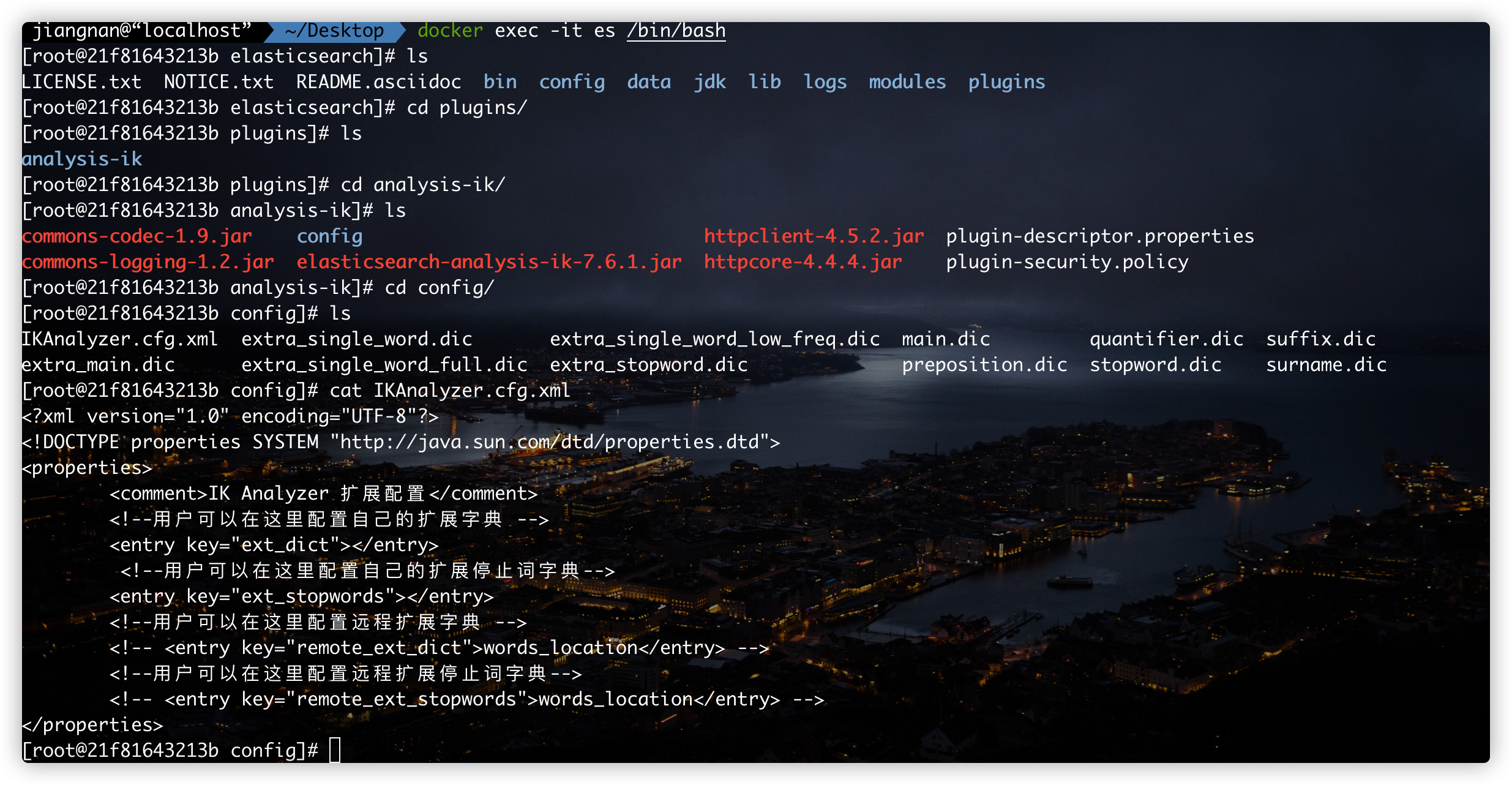
The first step is to find out where to configure:
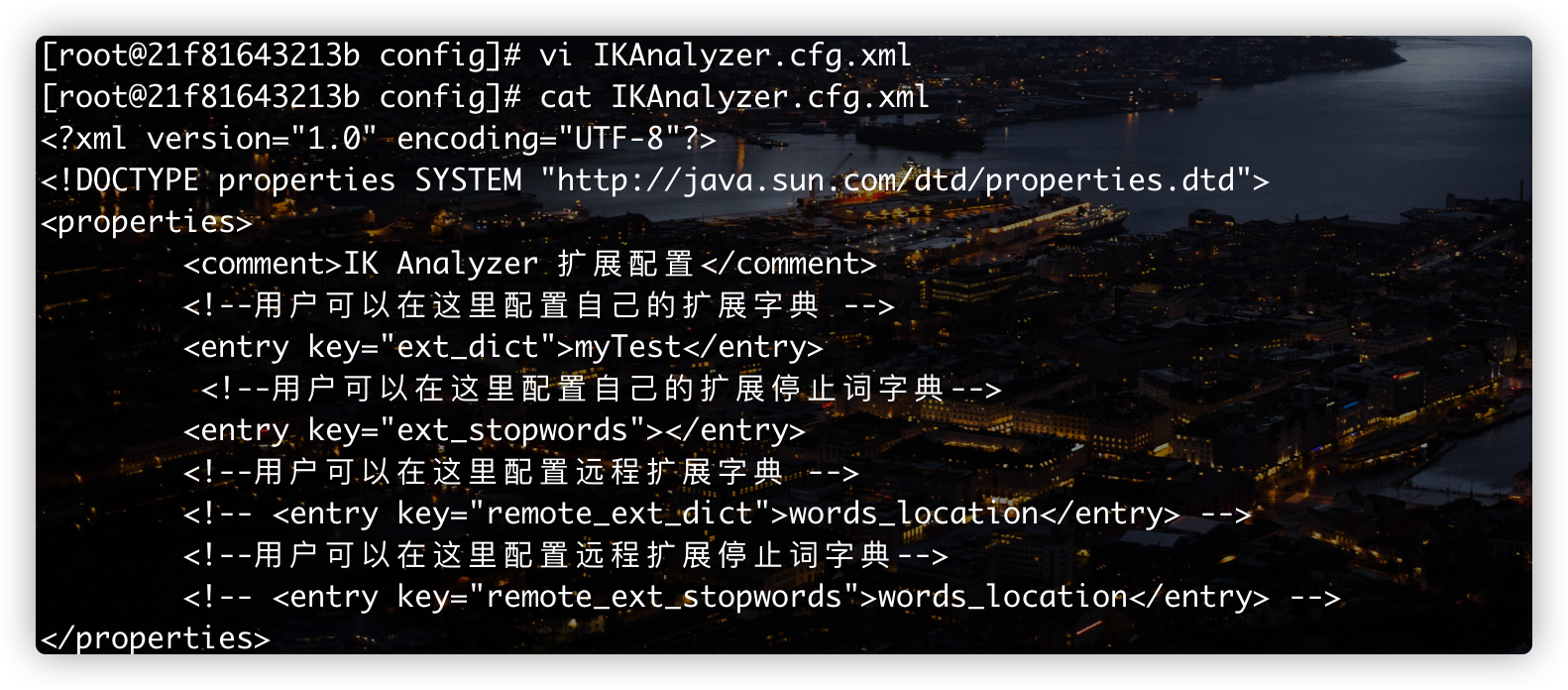
# Enter es container docker exec -it es /bin/bash # Enter the plug-in directory cd /usr/share/elasticsearch/plugins # Enter the IK word breaker plug-in cd analysis-ik/ # Enter the configuration directory of word splitter cd config/ # View word segmentation profile cat IKAnalyzer.cfg.xml
The detailed operation is shown in the figure below
Now we can create a dic dictionary ourselves
# Create a custom word segmentation dictionary file touch myTest.dic
Don't worry about writing content first. You can verify it through Kibana first.
In kibana, perform the default content splitting test for "text":"good man", as shown in the following figure:
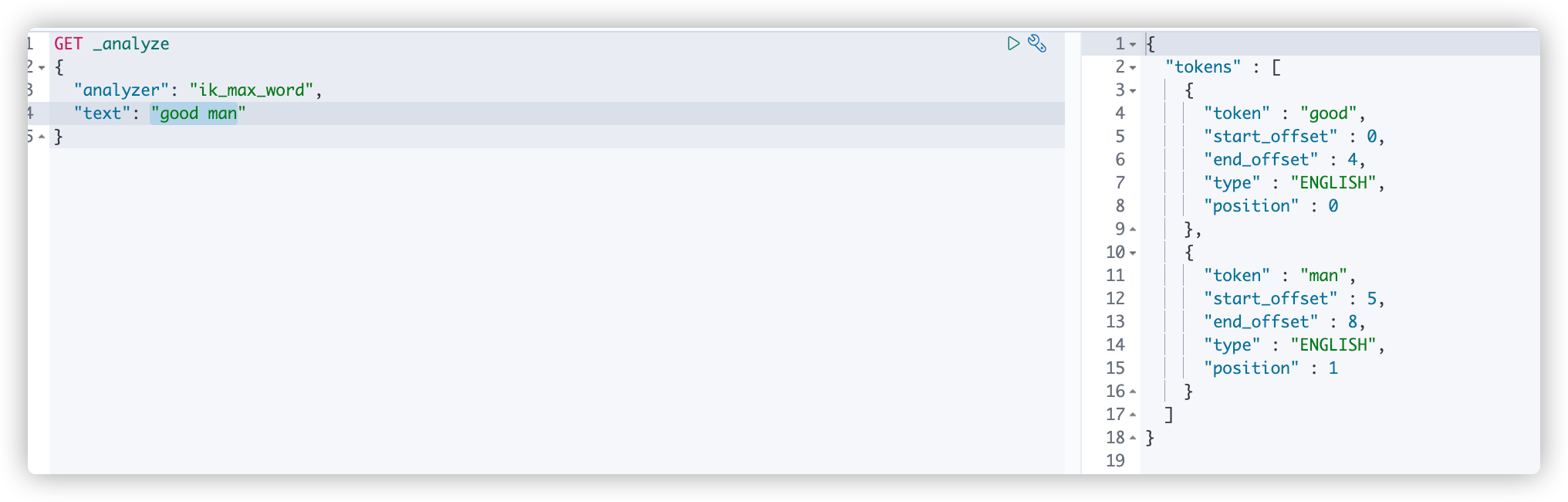
Now one of the participles I want to get is good ma. Now you can edit mytest DIC file input content in the file: Code ok
to configure:
Restart elasticsearch and kibana
8.Rest style description
8.1. Brief introduction
Rest is a software style, not a standard, index a set of design principles and constraints. It is mainly used for client and server interaction software. The software designed with this style can be more concise, more hierarchical and easier to implement caching and other mechanisms.
Basic Rest command description:
| Method | url address | describe |
|---|---|---|
| PUT | localhost:9200 / index name / type name / document ID | Create document (specify document ID) |
| POST | localhost:9200 / index name / type name | Create document (random document ID) |
| POST | localhost:9200 / index name / type name / document ID/_update | Modify document |
| DELETE | localhost:9200 / index name / type name / document ID | remove document |
| GET | localhost:9200 / index name / type name / document ID | Query document ID |
| POST | localhost:9200 / index name / type name/_ search | Query all data |
8.2. Demonstration case
8.2.1. Index related operations
Create index
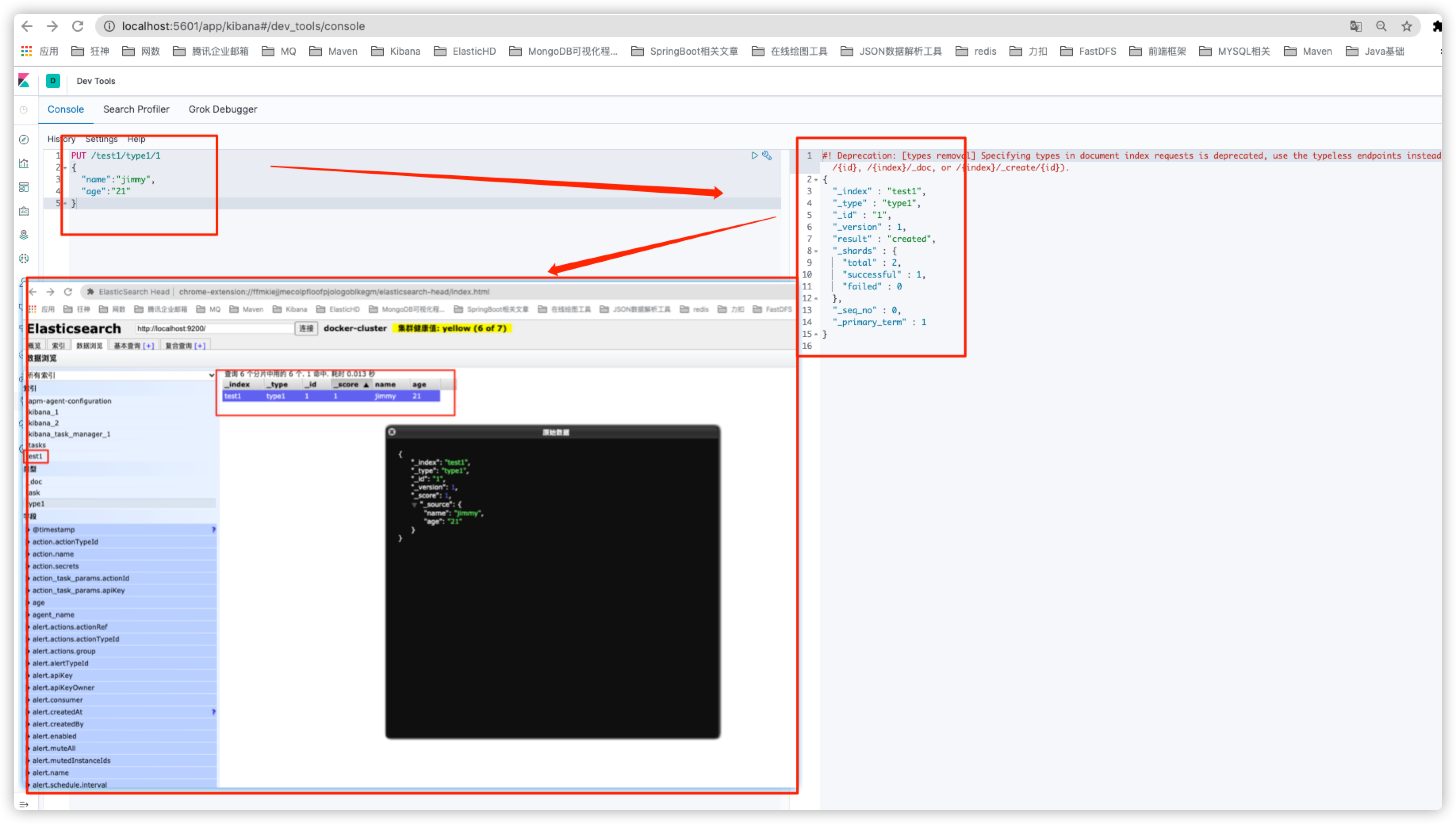
PUT /test1/type1/1
{
"name":"jimmy",
"age":"21"
}
Field types in ES
-
String type
text(text type will be parsed / split by the word splitter), keyword(keyword type will not be parsed by the word splitter)
-
value type
long,integer,short,byte,double,float,half,float,scaled,float
-
Date type
date
-
Boolean type
boolean
-
Binary type
binary
-
Wait
Create rule: Specifies the type of field when creating an index.
PUT /test2
{
"mappings": {
"properties": {
"name":{
"type":"text"
},
"age":{
"type":"integer"
}
}
}
}
GET the rule information of test2 index through GET request
GET /test2
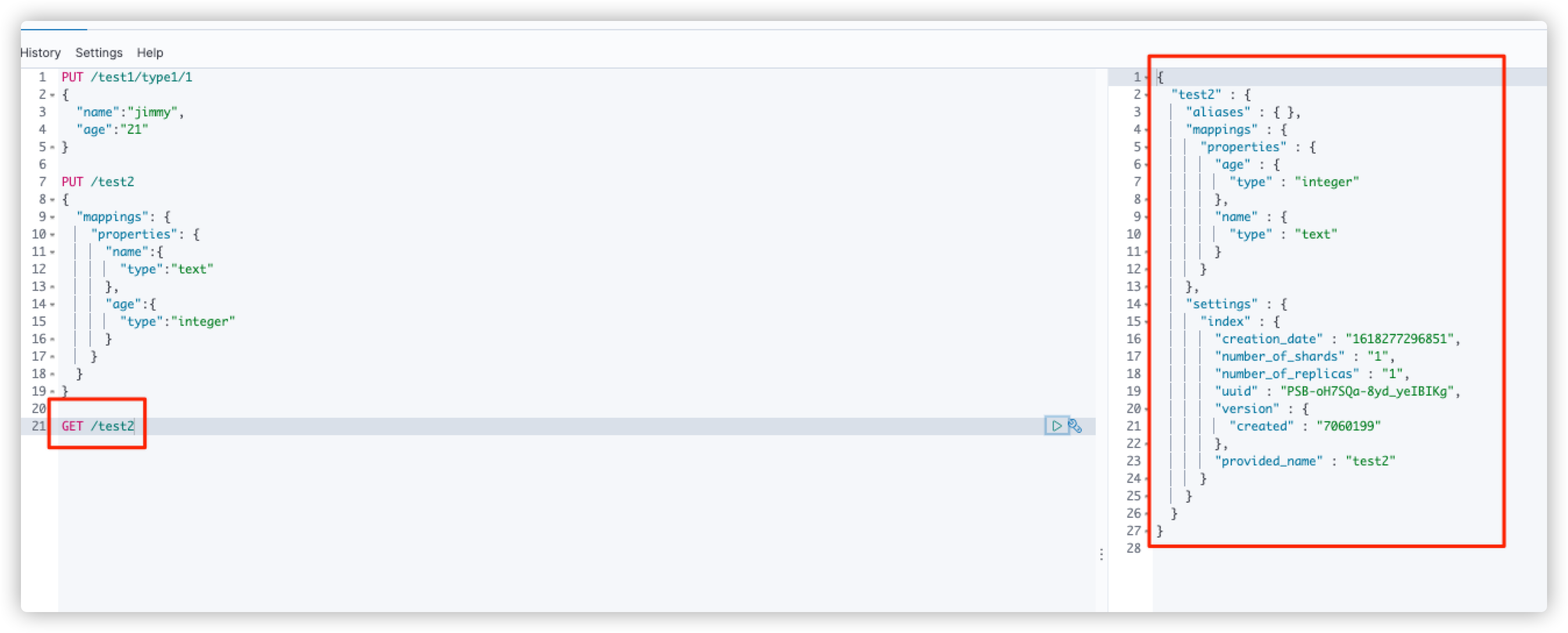
Get the rule information of test1 index (no field type rule is set when creating test1 index, es will help us configure it automatically)
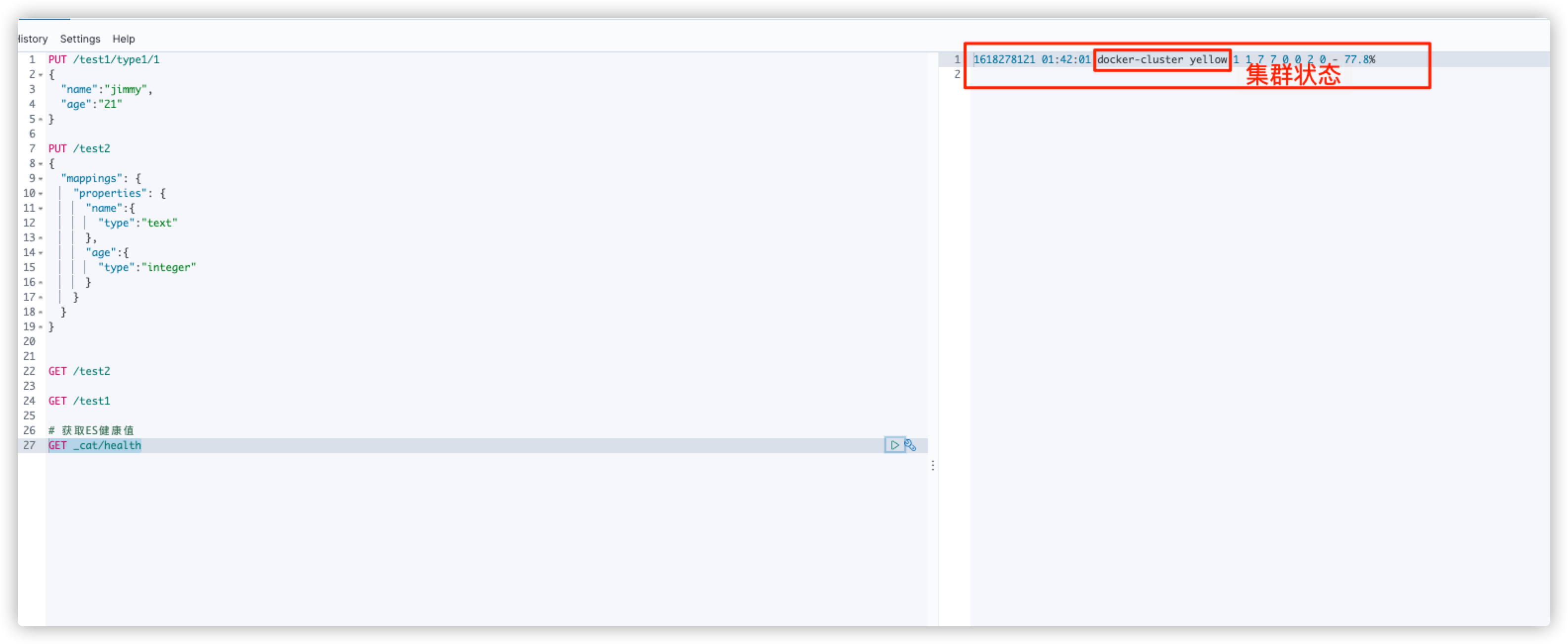
# Query index information GET /test1

Expand command
# Get ES health value GET _cat/health # View all information of ES GET _cat/indices?v
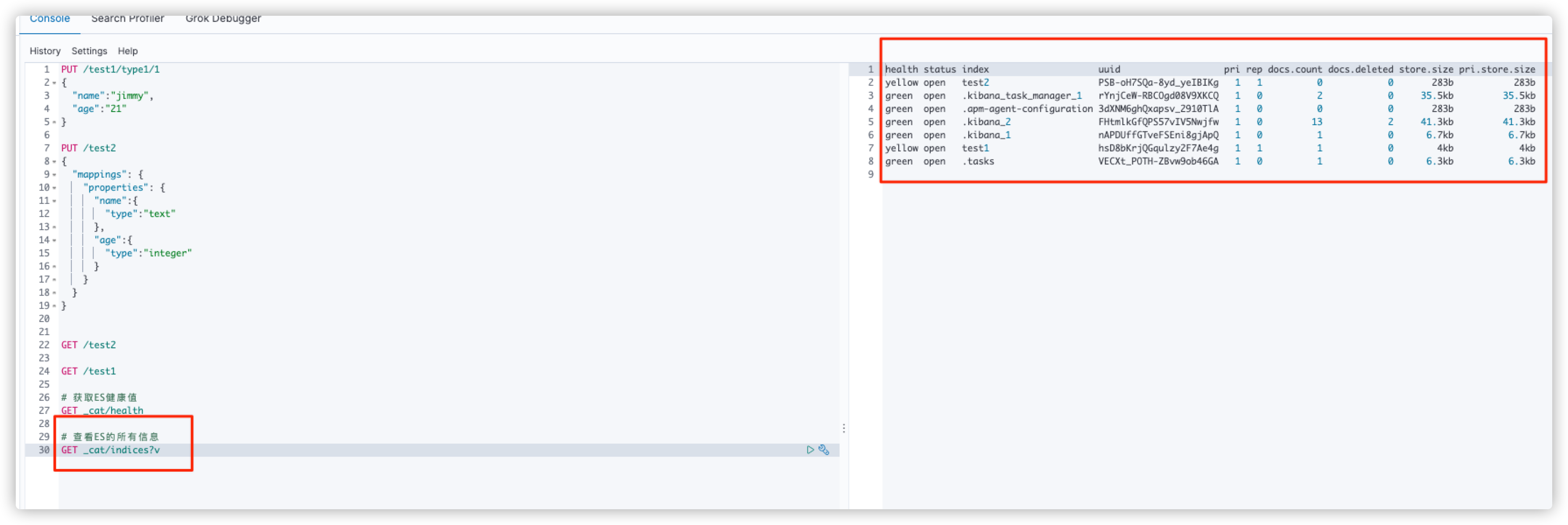
Modify document
There are two ways to modify a document:
- 1. Overwrite the original value by submitting again
PUT /test1/type1/1
{
"name":"Evil Zhang San",
"age":23
}

- 2. Via POST: localhost:9200 / index name / type name / document ID/_update to update the value of the specified field in the document. More flexibility
POST /test1/type1/1/_update
{
"doc":{
"name":"Good man Zhang San"
}
}

Delete index
DELETE test1
8.2.2. query
# Query preparation data
# 1. Create index and field mapping rules
PUT /search_data_list
{
"mappings": {
"properties": {
"name":{"type": "text"},
"age":{"type":"integer"},
"birthday":{"type":"date"},
"tags":{"type": "text"}
}
}
}
# 2. Add data
PUT /search_data_list/_doc/1
{
"name":"Zhang San",
"age":23,
"birthday":"2021-04-13",
"tags":["smoking","drink","Soup head"]
}
PUT /search_data_list/_doc/2
{
"name":"Li Si",
"age":24,
"birthday":"2021-04-13",
"tags":["smoking","drink","Soup head"]
}
PUT /search_data_list/_doc/3
{
"name":"Wang Wu",
"age":25,
"birthday":"2021-04-13",
"tags":["smoking","drink","Soup head"]
}
PUT /search_data_list/_doc/4
{
"name":"Wang Wujun",
"age":26,
"birthday":"2021-04-13",
"tags":["smoking","drink","Soup head"]
}
# Simple query
# 1. View index structure
GET search_data_list
# 2. View_ Data with document ID 2 under doc document
GET search_data_list/_doc/2
# 3. Query the data with name = Wang Wu, which is found on the right_ The score field indicates the data matching degree. The larger the value, the higher the matching degree
GET search_data_list/_doc/_search?q=name:Wang Wu
# Complex query
# query criteria result set
# match is equivalent to and in mysql
# _ source result filtering only takes the required fields
GET search_data_list/_doc/_search
{
"query":{
"match": {
"name": "Wang Wu"
}
},
"_source":["name","desc"]
}
# sort
GET search_data_list/_doc/_search
{
"query":{
"match": {
"name": "Wang Wu"
}
},
"sort":{
"age":{
"order":"asc"
}
}
}
# paging
# From starting value (starting from 0)
# size offset
GET search_data_list/_doc/_search
{
"query":{
"match": {
"name": "Wang Wu"
}
},
"sort":{
"age":{
"order":"asc"
}
},
"from":0,
"size":1
}
# Multi condition query
# match > and
# should > or
# must_not > !=
GET search_data_list/_doc/_search
{
"query":{
"bool":{
"must_not":[
{
"match":{"name":"Zhang San"}
},
{
"match":{"age":23}
}
]
}
}
}
# filter
# Use filter to filter data
# gt greater than gte greater than or equal to lt less than or equal to lte
GET search_data_list/_doc/_search
{
"query":{
"bool":{
"must":[
{
"match":{"name":"Wang Wu"}
}
],
"filter":{
"range":{
"age":{
"lt":26
}
}
}
}
}
}
# Accurate query, through the inverted index to find the specified terms accurately
# term directly queries the exact, and match will use the word splitter to parse (first analyze the document, and then query by analyzing the document)
GET search_data_list/_doc/_search
{
"query":{
"term":{
"name":"king"
}
}
}
# Multi condition exact query
GET search_data_list/_doc/_search
{
"query":{
"bool":{
"should":[
{
"term":{"age":13}
},
{
"term":{"age":25}
}
]
}
}
# Highlight query
GET search_data_list/_doc/_search
{
"query":{
"match":{
"name":"Zhang San"
}
},
"highlight":{
"fields":{
"name":{}
}
}
}
# Custom highlighting
GET search_data_list/_doc/_search
{
"query":{
"match":{
"name":"Zhang San"
}
},
"highlight":{
"pre_tags":"<p>",
"post_tags":"</p>",
"fields":{
"name":{}
}
}
}
9.SpringBoot integrates ElasticSearch to realize CRUD operation
9.1. Import dependency
When importing dependencies, it should be noted that the version of ES client should be consistent with that of local es service.
The ES integrated by SpringBoot uses the version of the parent project by default, so we need to take a look at the advanced Rest style es client version before writing code. The detailed operation is shown in the figure below:
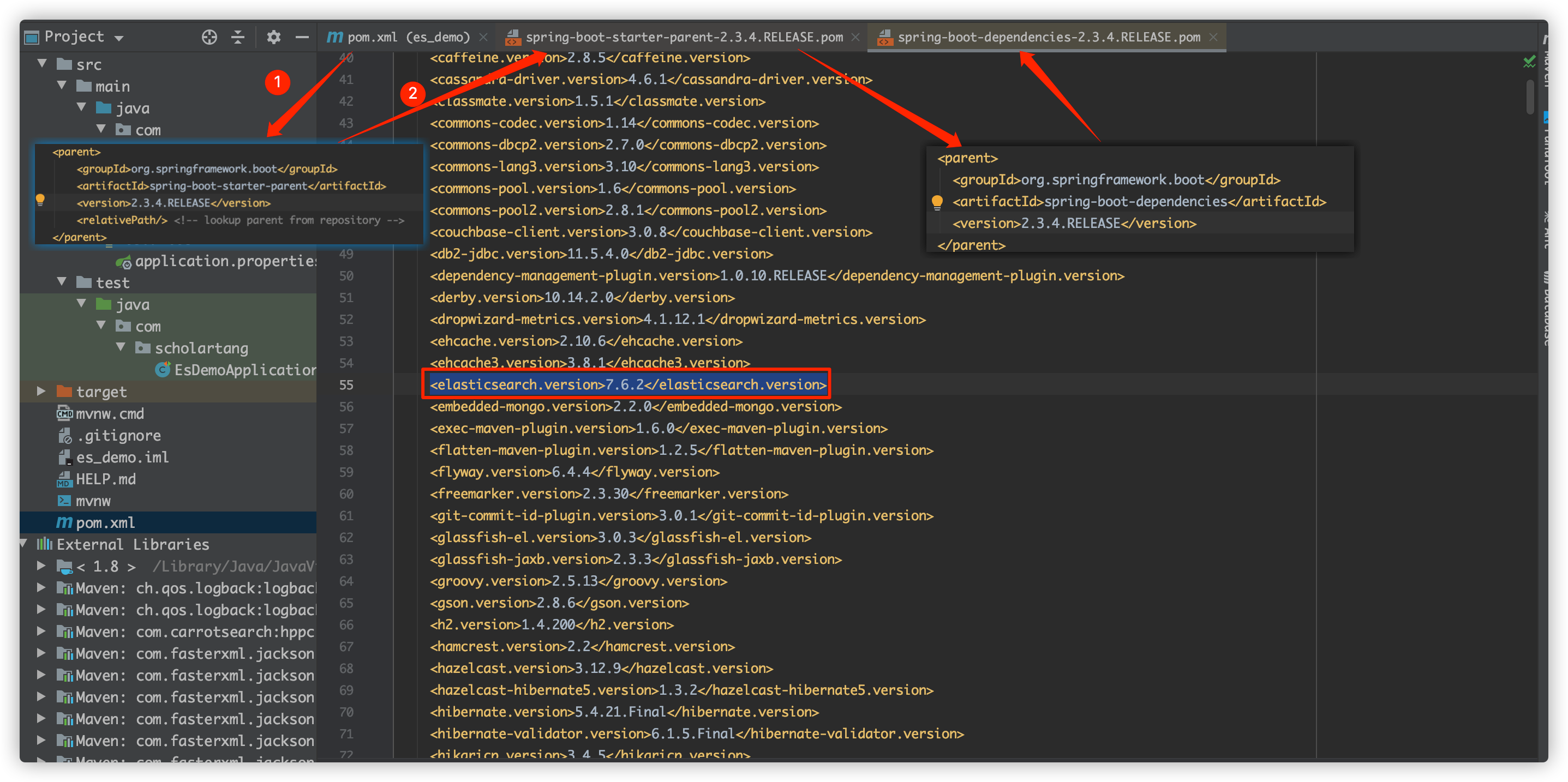
The version of my local es service is 7.6.1, and the version that relies on the parent project here is 7.6.2. I need to adjust the version of ES client
<properties> <java.version>1.8</java.version> <elasticsearch.version>7.6.1</elasticsearch.version> </properties> <!--EsClient The version should be the same as ES The version of is consistent--> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-data-elasticsearch</artifactId> </dependency>
At this point, you can start writing code
9.2. Build ES client instance
package com.scholartang.config;
import org.apache.http.HttpHost;
import org.elasticsearch.client.RestClient;
import org.elasticsearch.client.RestHighLevelClient;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
/**
* @Author ScholarTang
* @Date 2021/4/13 2:02 afternoon
* @Desc ES Configuration class
*/
@Configuration
public class ElasticSearchConfig {
/**
* Build an advanced Rest style es client instance
* A RestHighLevelClient instance needs a REST low-level client generator to build the following
* @return
*/
@Bean
public RestHighLevelClient restHighLevelClient(){
return new RestHighLevelClient(RestClient.builder(new HttpHost("localhost", 9200, "http")));
}
}
9.3. Index related operation API test
package com.scholartang;
import lombok.extern.slf4j.Slf4j;
import org.elasticsearch.action.admin.indices.delete.DeleteIndexRequest;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.client.indices.CreateIndexRequest;
import org.elasticsearch.client.indices.GetIndexRequest;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import java.io.IOException;
/**
* es 7.6.1 Advanced client test API (index related)
*/
@Slf4j
@SpringBootTest
class EsDemoApplicationTests {
@Autowired
private RestHighLevelClient restHighLevelClient;
/**
* Create index
*/
@Test
void testCreateIndex() throws IOException {
//Create index request
CreateIndexRequest createIndexRequest = new CreateIndexRequest("create_index_01");
//Client execution request
restHighLevelClient.indices().create(createIndexRequest, RequestOptions.DEFAULT);
}
/**
* Get index
*/
@Test
public void testGetIndex() throws IOException {
//Create get index request
GetIndexRequest getIndexRequest = new GetIndexRequest("create_index_01");
//Client execution request
boolean exists = restHighLevelClient.indices().exists(getIndexRequest, RequestOptions.DEFAULT);
log.info("Indexes" + (exists ? "existence" : "non-existent"));
}
/**
* Delete index
*/
@Test
public void testDeleteIndex() throws IOException {
//Create delete index request
DeleteIndexRequest deleteIndexRequest = new DeleteIndexRequest("create_index_01");
//Client execution request
restHighLevelClient.indices().delete(deleteIndexRequest, RequestOptions.DEFAULT);
}
}
9.4. API test of document first closing operation
package com.scholartang;
import lombok.extern.slf4j.Slf4j;
import org.elasticsearch.action.admin.indices.delete.DeleteIndexRequest;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.client.indices.CreateIndexRequest;
import org.elasticsearch.client.indices.GetIndexRequest;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import java.io.IOException;
/**
* es 7.6.1 Advanced client test API (document related)
*/
@Slf4j
@SpringBootTest
class EsDemoApplicationTests {
@Autowired
private RestHighLevelClient restHighLevelClient;
/** Add document */
@Test
public void testAddDocument() throws IOException {
// Create an index request
IndexRequest indexRequest = new IndexRequest("create_index_01");
// Document ID
indexRequest.id("1");
// Set request timeout
indexRequest.timeout(TimeValue.timeValueMillis(1));
// You can also write indexrequest timeout("60s");
// Set document data
indexRequest.source(JSON.toJSONString(new User(1, "Zhang San", "male", 23)), XContentType.JSON);
// The client sends a request to add a document
IndexResponse index = restHighLevelClient.index(indexRequest, RequestOptions.DEFAULT);
log.info("IndexResponse:{}", JSON.toJSONString(index));
}
/** Get document information */
@Test
public void testGetDocument() throws IOException {
// Create a get request get /index/_doc/documentId
GetRequest getRequest = new GetRequest("create_index_01", "5");
GetResponse getResponse = restHighLevelClient.get(getRequest, RequestOptions.DEFAULT);
if (getResponse.isExists()) {
String source = getResponse.getSourceAsString();
log.info("source:{}", source);
}
}
/** Update document information */
@Test
public void testUpdateDocument() throws IOException {
// Create an update request
UpdateRequest updateRequest = new UpdateRequest("create_index_01", "1");
updateRequest.timeout("60s");
updateRequest.doc(JSON.toJSONString(new User(2, "kuang", "female", 23)), XContentType.JSON);
UpdateResponse updateResponse =
restHighLevelClient.update(updateRequest, RequestOptions.DEFAULT);
log.info("updateStatus:{}", updateResponse.status());
}
/** remove document */
@Test
public void testDeleteDocument() throws IOException {
// Create a delete request
DeleteRequest deleteRequest = new DeleteRequest("create_index_01", "1");
deleteRequest.timeout("60s");
DeleteResponse deleteResponse =
restHighLevelClient.delete(deleteRequest, RequestOptions.DEFAULT);
log.info("deleteResponse:{}", deleteResponse.status());
}
/** Batch insert document */
@Test
public void testBathAddDocument() throws IOException {
BulkRequest bulkRequest = new BulkRequest();
bulkRequest.timeout("60s");
ArrayList<User> users = new ArrayList<>();
Collections.addAll(
users,
new User(1, "kuang1", "female", 23),
new User(2, "kuang2", "female", 23),
new User(3, "kuang3", "female", 23),
new User(4, "kuang4", "female", 23));
for (int i = 0; i < users.size(); i++) {
bulkRequest.add(
// For batch update and deletion operations, you can modify the request method here
new IndexRequest("create_index_01")
.id((i + 1) + "")
.source(JSON.toJSONString(users.get(i)), XContentType.JSON));
}
BulkResponse bulkResponse = restHighLevelClient.bulk(bulkRequest, RequestOptions.DEFAULT);
// Whether the operation failed. If false is returned, it is successful
log.info("bulkResponseStatus:{}", bulkResponse.isFragment());
}
/** Batch query operation */
@Test
public void testBathGetDocument() throws IOException {
// Create batch query request
SearchRequest searchRequest = new SearchRequest("create_index_01");
// Build query criteria
SearchSourceBuilder builder = new SearchSourceBuilder();
// QueryBuilders condition tool class
// termQuery exact query
TermQueryBuilder termQuery = QueryBuilders.termQuery("name", "kuang1");
// matchAllQuery matches all
// MatchAllQueryBuilder matchAllQueryBuilder = QueryBuilders.matchAllQuery();
// builder.query(termQuery);
// Batch query based on document ID
IdsQueryBuilder idsQueryBuilder = new IdsQueryBuilder().addIds("1", "2", "3", "100");
builder.query(idsQueryBuilder);
// Set request timeout
builder.timeout(new TimeValue(60, TimeUnit.SECONDS));
searchRequest.source(builder);
// Client initiated request
SearchResponse searchResponse =
restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
RestStatus status = searchResponse.status();
if ("ok".equalsIgnoreCase(status.toString())) {
// All the results are in SearchHits
List<Map> maps = new ArrayList<>();
SearchHits responseHits = searchResponse.getHits();
SearchHit[] hits = responseHits.getHits();
for (int i = 0; i < hits.length; i++) {
maps.add(hits[i].getSourceAsMap());
}
log.info(JSON.toJSONString(maps));
}
}
}