Elasticsearch
- It is an open source and highly extended distributed full-text retrieval engine, which can store and retrieve data in near real time;
- It uses Java to develop and use Lucene as its core to realize all indexing and search functions, but its purpose is to hide the complexity of Lucene through a simple Restful API, so as to make full-text search simple.
SQL: like% query content%. If it is big data, even if there is an index, it is very slow
1. Installation
- Development tools: Postman, Curl, head, Google browser plug-ins
(the installation package can be downloaded by itself. If you can't find it, you can leave a message to get the installation software)
1. Install ElasticSearch
https://mirrors.huaweicloud.com/elasticsearch/?C=N&O=D
Download and unzip
bin: Startup file config: configuration file log4j2: Log profile jvm.options java Virtual machine related configuration elesticsearch.yml Configuration file! Default 9200 port plugins: plug-in unit
Start: click bin / elasticsearch Bat, and then visit the browser http://127.0.0.1:9200/ , the following appears
{
"name" : "DESKTOP-0U1AJ4S",
"cluster_name" : "elasticsearch",
"cluster_uuid" : "AzTUTxy6Sbq1-j-jU1A2rw",
"version" : {
"number" : "7.2.0",
"build_flavor" : "default",
"build_type" : "zip",
"build_hash" : "508c38a",
"build_date" : "2019-06-20T15:54:18.811730Z",
"build_snapshot" : false,
"lucene_version" : "8.0.0",
"minimum_wire_compatibility_version" : "6.8.0",
"minimum_index_compatibility_version" : "6.0.0-beta1"
},
"tagline" : "You Know, for Search"
}
2. Install visual interface (head plug-in)
Download address: https://github.com/mobz/elasticsearch-head/ (npm needs to be installed first)
- After decompression, open cmd in this directory,
#Installing dependencies using cnpm cnpm install perhaps npm install #start-up npm run start
- Solve cross domain problems
#Open C: \ tools \ es \ elasticsearch-7.2.0 \ config \ elasticsearch YML, append at the end http.cors.enabled: true http.cors.allow-origin: "*" #Save, restart ES service, access http://localhost:9100/ Click Connect to display the cluster health value: green (0 of 0)
- You can also use the Google plug-in
3. Install Kibana
The version shall be consistent https://mirrors.huaweicloud.com/kibana/7.2.0/?C=N&O=D
-
Unpack and open bin / kibana Bat, access http://localhost:5601
-
Sinicization
C:\tools\ES\kibana-7.2.0-windows-x86_64\config\kibana.yml Add in i18n.locale: "zh-CN"
4. Install ik word splitter
Consistent with ES version https://github.com/medcl/elasticsearch-analysis-ik/tree/v7.2.0
- Decompression: if the IK and ES versions do not correspond, an error will be reported when running es, saying that the two versions are wrong, resulting in failure to start. After downloading the IK word splitter, the surface is version 7.2.0, and the processed zip decompression is version 7.0.0. You only need to modify the POM under the path The version in XML can be changed to 7.2.0.
- Open the dos window in this directory and execute the command mvn clean package to package. Then go to \ target\releases and see the zip package
- Create the analysis IK folder under the plugins in the directory where you installed es, then copy the zip package typed above to the analysis IK folder and unzip the zip package here
- Then restart ES and you can see that ik word breaker is installed successfully
2.ES core concepts
- Elastic search is document oriented, compared with relational database: (everything is JSON)
| Relational DB | Elasticsearch |
|---|---|
| Database | Indexes (just like databases) |
| Tables | types (gradually discarded) |
| rows | documents |
| Fields (columns) | fields |
- Indexes
The index is a container of mapping type, and the index in es is a very large collection. The index stores the fields and other settings of the mapping type, which are then stored on each slice
- A cluster has at least one node, and a node is an es process. A node can have multiple default indexes. If an index is created, the index will be composed of five primary shards, and each primary shard will have a replica shard
- The primary partition and the corresponding replication partition will not be in the same node, which is conducive to the death of a node and the loss of data.
- In fact, a fragment is a Lucene index, a file directory containing inverted index. The inverted index structure enables ES to tell us which documents contain specific keywords without scanning all documents
- Inverted index
- ES uses a structure called inverted index, which uses Lucene inverted index as the bottom layer. This structure is suitable for fast full-text search.
- An index consists of all non duplicate lists in the document. For each word, there is a document list containing it
If you search blog posts through blog tags, the inverted index is such a structure
| Blog posts (raw data) | Index list (inverted index) | ||
|---|---|---|---|
| Blog post ID | label | label | Blog post ID |
| 1 | python | python | 1,2,3 |
| 2 | python | linux | 3,4 |
| 3 | linux,python | ||
| 4 | linux |
If you want to search for articles with puton tag, it will be much faster to find the data after inverted index than to find all the original data. You only need to check the tag column and obtain the relevant article ID, so as to completely filter out all irrelevant data and improve efficiency
Inverted index level document word segmentation into the mapping between keyword and document id
3.IK word splitter
Word segmentation: that is to divide a paragraph of Chinese or others into keywords. When searching for elements, we will segment our own information, segment the data in the database or index database, and then perform a matching operation. The default Chinese word segmentation is to treat each word as a word. For example, "good study" will be divided into "good", "good", "learn" and "learn", This obviously does not meet the requirements, so we need to install Chinese word splitter IK to solve the problem.
IK provides two word segmentation algorithms: ik_smart and ik_max_word, where ik_smart is the least segmentation, ik_max_word is the most fine-grained partition
Use kibana test to see different word segmentation effects
ik_smart
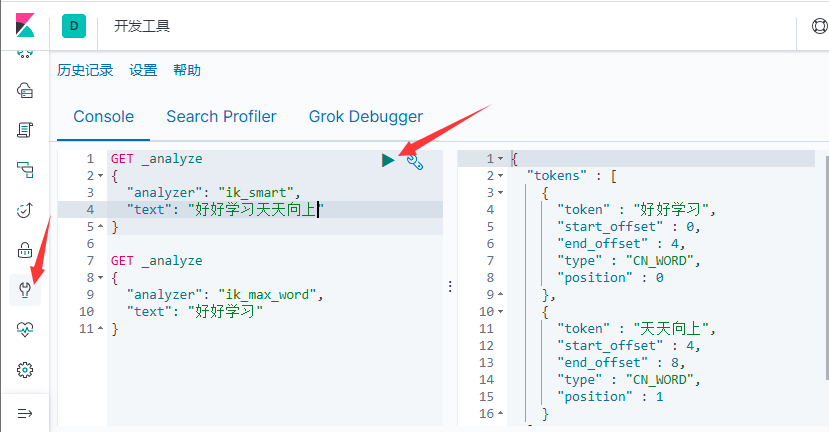
ik_max_word
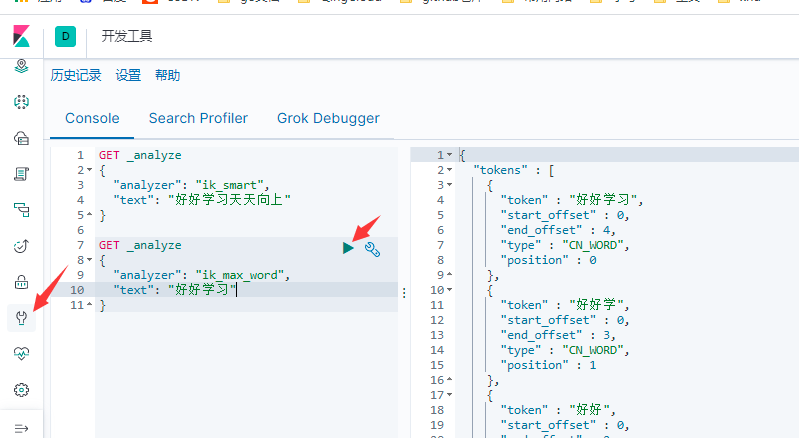
The words you need need need to be manually added to the dictionary of the word splitter
IK word splitter adds its own configuration
- Add my DIC configuration
<!-- C:\tools\ES\elasticsearch-7.2.0\plugins\analysis-ik\config\IKAnalyzer.cfg.xml --> <?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd"> <properties> <comment>IK Analyzer Extended configuration</comment> <!--Users can configure their own extended dictionary here --> <entry key="ext_dict">my.dic</entry> <!--Users can configure their own extended stop word dictionary here--> <entry key="ext_stopwords"></entry> <!--Users can configure the remote extension dictionary here --> <!-- <entry key="remote_ext_dict">words_location</entry> --> <!--Users can configure the remote extended stop word dictionary here--> <!-- <entry key="remote_ext_stopwords">words_location</entry> --> </properties>
- Create my. In the current directory DIC file, which writes the words you added
- Then restart ES
4.Rest style description
| method | url address | describe |
|---|---|---|
| PUT | localhost:9200 / index name / type name / document id | Create document (specify document id) |
| POST | localhost:9200 / index name / type name | Create document (random document id) |
| POST | localhost:9200 / index name / type name / document id/_update | Modify document |
| DELETE | localhost:9200 / index name / type name / document id | remove document |
| GET | localhost:9200 / index name / type name / document id | Query document by document id |
| POST | localhost:9200 / index name / type name / document id/_search | Query all data |
Basic test
1. Index operation
- 1. Create index
#Create and execute commands in kibana
PUT /Index name/Type name/id
{Request body}
#After execution, you can view the created index in the head plug-in
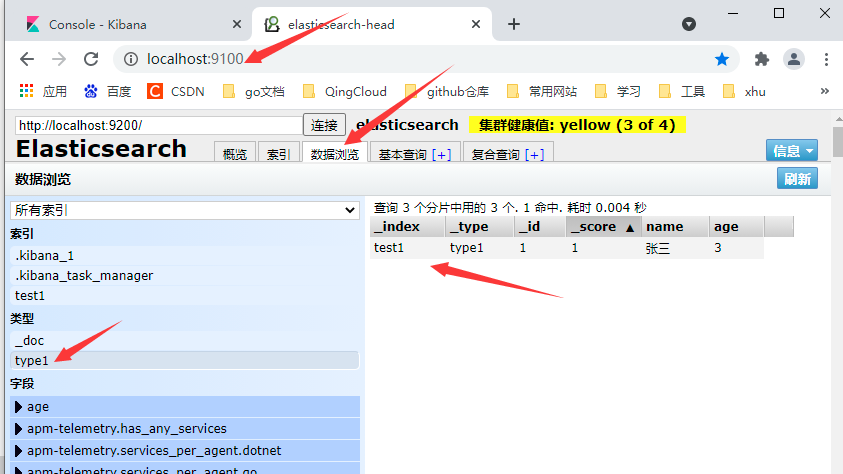
-
2. Type
- String: text, keyword
- Values: long, integer, short, byte, double, float, half float, scaled float
- date: date
- boolean: boolean
- Binary: binary
- ...
-
Specify type (create rule)
#Create index but no field, create rule
PUT /test2
{
"mappings": {
"properties": {
"name": {
"type": "text"
},
"age": {
"type": "long"
},
"birthday": {
"type": "date"
}
}
}
}
#Get, you can view specific information
GET test2
- View default information
#_ doc is the default type. The specific type will be discarded in the future
PUT /test3/_doc/1
{
"name": "Li Si",
"age": 3,
"birth": "1993-2-11"
}
GET test3
#If your own document does not specify, es will give us the default configuration field type
#Extension: use the elasticsearch command to index the situation
GET _cat/health
- 3. Modification
1. You can still use PUT, and then perform the overwrite (but if the data is lost, only the overwritten data will be available after the overwrite)
2. Use POST
- 4. Delete index
#DELETE is realized through the DELETE command. Judge whether to DELETE the index or DELETE the document record according to the request DELETE test1
2. Document operation
basic operation
#1. Add record
POST /test3/user/2
{
"name": "Li Si",
"age": 24,
"birth": "1993-2-11",
"tags": ["Straight man","Good grades"]
}
#2. Get, simple search (by id)
GET /test3/user/1
#Through search
GET test3/user/_search?q=name:Zhang San
#3. Modify (update is recommended)
PUT /test3/user/3
{
"name": "anan",
"age": 23,
"birth": "1999-2-11",
"tags": ["beautiful","Good grades"]
}
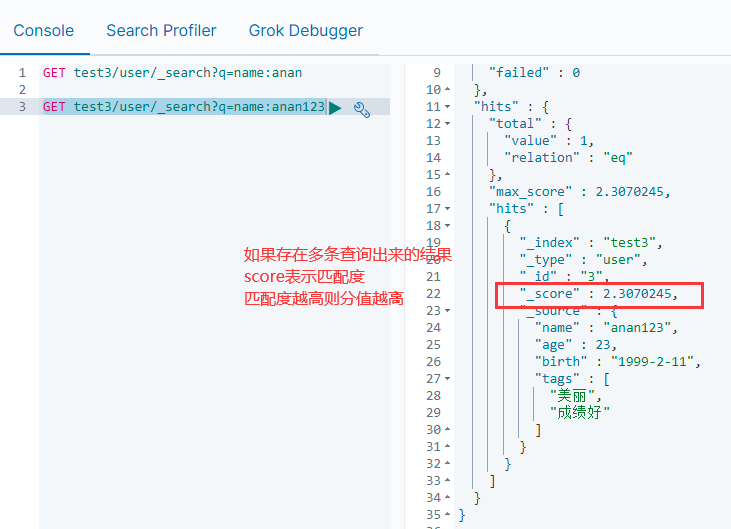
POST /test3/user/3/_update
{
"doc": {
"name": "anan123"
}
}
be careful:
3. Detailed query
Complex query search
#1. Default query all
GET test3/user/_search
{
"query": {
"match": {
"name": "Li Si"
}
}
}
#Multiple conditions are separated by spaces. You can find them as long as one of them is met. At this time, you can make basic judgment through score
GET test3/user/_search
{
"query": {
"match": {
"tags":"Male beauty"
}
}
}
#The hit queried represents the index and document information, the total number of query results, and then the specific document queried. The data in the data can be traversed
#2. Result filtering, query only name and age
GET test3/user/_search
{
"query": {
"match": {
"name": "Li Si"
}
}
, "_source": ["name","age"]
}
#3. Sort
#For example, reverse and page by age
GET test3/user/_search
{
"query": {
"match": {
"name": "Li Si"
}
},
"sort": [
{
"age": {
"order": "desc"
}
}
],
"from": 0,
"size": 2
}
#The general paging implementation is / search/{current}/{pagesize}
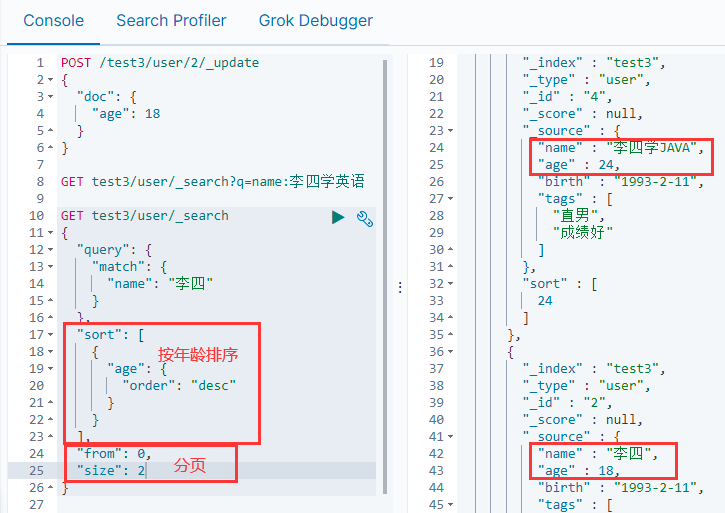
#4. Multi condition query
#must is equivalent to and and should is equivalent to or
GET test3/user/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"name": "Li Si"
}
},
{
"match": {
"age": 24
}
}
]
}
}
}
#5. Not query name is not Li Si's person
GET test3/user/_search
{
"query": {
"bool": {
"must_not": [
{
"match": {
"name": "Li Si"
}
}
]
}
}
}
#6. filter
gt greater than gte Greater than or equal to lt less than lte Less than or equal to
#Filter the query results according to the maximum age of 30 and the minimum age of 20
GET test3/user/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"name": "Li Si"
}
}
],
"filter": {
"range": {
"age": {
"gte": 20,
"lte": 30
}
}
}
}
}
}
Accurate query!
About participle
About participle*
- Term, which can be found directly through the term process specified by the inverted index
- match, which will be parsed using the word splitter (first analyze the document, and then query through the analyzed document)
Two types: text keyword
#1. Create index
PUT testdb
{
"mappings": {
"properties": {
"name": {
"type": "text"
},
"desc": {
"type": "keyword"
}
}
}
}
#2. put data
PUT testdb/_doc/2
{
"name": "Zhang San studies English name",
"desc": "Zhang San studies English desc2"
}
#3. text is not parsed by the word breaker, and keyword represents a whole
GET _analyze
{
"analyzer": "keyword",
"text": "Zhang San studies English name"
}
#Will be split
GET _analyze
{
"analyzer": "standard",
"text": "Zhang San studies English name"
}
#4. Precise query
#Fields of type keyword are not resolved by the word breaker
GET testdb/_search
{
"query": {
"term": {
"name": "three"
}
}
}
GET testdb/_search
{
"query": {
"term": {
"desc": "Zhang San studies English desc1"
}
}
}
#5. Accurately query multiple values
PUT testdb/_doc/3
{
"test1": "22",
"test2": "2021-5-19"
}
PUT testdb/_doc/4
{
"test1": "33",
"test2": "2021-5-20"
}
GET testdb/_search
{
"query": {
"bool": {
"should": [
{
"term": {
"test1": "22"
}
},
{
"term": {
"test1": "33"
}
}
]
}
}
}
Highlight query
[the external chain image transfer fails. The source station may have an anti-theft chain mechanism. It is recommended to save the image and upload it directly (img-1bpmter-1625021445261) (C: \ go \ notes \ images \ 16214048937. PNG)]
#Apply custom highlight conditions
GET test3/user/_search
{
"query": {
"match": {
"name": "Li Si"
}
},
"highlight": {
"pre_tags": "<p class='key' style='color:red'>",
"post_tags": "</p>",
"fields": {
"name": {}
}
}
}