1, Introduction
With the help of the official website
Introduction to Elasticsearch
You know, for search (and analysis)
Elasticsearch is the core distributed search and analysis engine of Elastic Stack. Logstash and Beats help collect, aggregate and enrich your data and store it in elasticsearch. With Kibana, you can interactively explore, visualize and share insights into data, and manage and monitor the stack. Elastic search is a place to index, search and analyze magic.
Elasticsearch provides real-time search and analysis for all types of data. Whether you are structured or unstructured text, digital data or geospatial data, elasticsearch can effectively store and index it in a way that supports fast search. You can not only perform simple data retrieval, but also aggregate information to find trends and patterns in the data. As data and queries grow, elasticsearch's distributed nature allows your deployment to grow seamlessly
Learning comprehension
ES generally exists as a search engine. Now the ELK protocol stack on the official website is taken as a whole, and there are other related tools. There has been practice and exploration in other directions
In production practice, it is mainly used for storage index analysis of big data. It can be integrated with neo4j to generate node graph. Integrate with hive as storage mapping, and integrate with deep learning as similarity search
2, Architecture and basic concepts
ES overview
Elasticsearch is document oriented, which means that it can store an entire object or document. However, it
Not only store, but also index the content of each document so that it can be searched. In elastic search, you can search documents (instead of rows and columns)
Index, search, sort and filter.
Elasticsearch is better than traditional relational databases as follows:
Relational DB ‐> Databases ‐> Tables ‐> Rows ‐> Columns
Elasticsearch ‐> Indices ‐> Types ‐> Documents ‐> Fields
Because people's understanding of Elasticsearch above is actually not in line with the true meaning (type is not the target meaning) in order to avoid confusion, type is no longer used as a type after ES7. It may disappear in ES7. Type is default and there is only one type in an index
framework
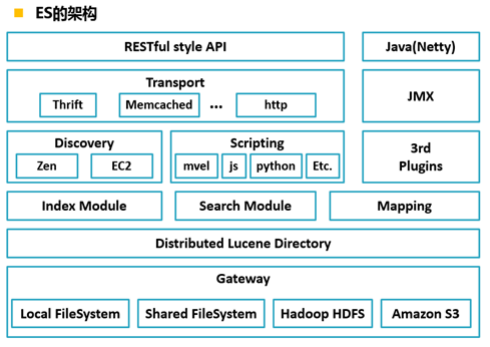
Gateway is a file system used by ES to store indexes, and supports many types.
The upper layer of Gateway is a distributed lucene framework.
Above Lucene are ES modules, including index module, search module, mapping and parsing module, etc
Above the ES module are Discovery, Scripting and third-party plug-ins.
Discovery is the node discovery module of ES. To form a cluster, ES nodes on different machines need message communication, and master nodes need to be elected in the cluster,
All this work is done by the Discovery module. Support multiple Discovery mechanisms, such as Zen, EC2, gce and Azure.
Scripting is used to support the insertion of javascript, python and other scripting languages into query statements. The scripting module is responsible for parsing these scripts and using scripts
Statement performance is slightly lower. ES also supports a variety of third-party plug-ins.
The upper layer is the ES transmission module and JMX The transport module supports a variety of transport protocols, such as Thrift, memecached and http. http is used by default. JMX is
java management framework for managing ES applications.
The top layer is the interface provided by es to users, which can interact with ES cluster through RESTful interface.
Core concept
Index index
An index is a collection of documents with somewhat similar characteristics.
Type type
There can be multiple types in an index, but there can only be one in ES6, and one cannot be changed by default in ES7
document
A document is a basic information unit that can be indexed. The document is represented in JSON (Javascript Object Notation), which is a ubiquitous Internet data interaction format.
Field field
Is multiple representations of a document. It can also be understood that a document is a row of data and a field is a field in a row. In practical use, an index data is generally used as a two-dimensional table
mapping
mapping makes some restrictions on data processing methods and rules, such as the data type, default value, analyzer, whether a field is indexed, etc. generally, ES will automatically infer the data type when writing index data. But the actual production is not recommended. mapping should be established first to determine the dimensions of the field.
Setting settings
settings
Cluster, node, fragmented replication
Cluster is a system composed of multiple servers equipped with ES to provide external services
The node is each server with ES
Piecemeal replication is a common concept in big data to improve storage and ensure data security. Fragmentation is the storage of each index, which can be divided into multiple parts and stored on different nodes. Replication is the backup of each part
3, Installation
Install Elasticsearch
In cluster mode, ES should be installed on each machine. The configuration file should be the same for each machine, except for some local configurations to form a cluster
Install one es head, kibana and tomcat
1. Create es ordinary users
ES cannot be started by root user, only ordinary users can be used
#Create user useradd es #Create a directory for es users mkdir ‐p /data/es chown ‐R es /data/es #Set password passwd es
2. Add sudo permission for es user
visudo
#Add content: es ALL=(ALL) ALL
Use es user login to complete the following steps
3. Download and upload the installation package and unzip it
Enter the official website to download https://www.elastic.co/cn/
It is better to download the ES and kibana together, and the relevant versions should be corresponding
I downloaded version 7.6.0
For the related installation of ES, I installed es, kibana, ES head, IK word breaker and tomcat
Relevant resources are in my network disk
Link: https://pan.baidu.com/s/1GQIXFP8xPW0mWisTZoZQXA
Extraction code: sf1g
I unzipped them to the / data/es directory
4. Modify the configuration file
Each cluster should be installed and configured
Enter es the configuration file directory:
vim elasticsearch.yml
# ======================== Elasticsearch Configuration ========================= # # NOTE: Elasticsearch comes with reasonable defaults for most settings. # Before you set out to tweak and tune the configuration, make sure you # understand what are you trying to accomplish and the consequences. # # The primary way of configuring a node is via this file. This template lists # the most important settings you may want to configure for a production cluster. # # Please consult the documentation for further information on configuration options: # https://www.elastic.co/guide/en/elasticsearch/reference/index.html # # ---------------------------------- Cluster ----------------------------------- # # Use a descriptive name for your cluster: #Cluster name cluster.name: my-es # # ------------------------------------ Node ------------------------------------ # # Use a descriptive name for the node: #Node name node.name: etl-oracle # # Add custom attributes to the node: # #node.attr.rack: r1 # # ----------------------------------- Paths ------------------------------------ # # Path to directory where to store the data (separate multiple locations by comma): #Data storage address path.data: /data/es/elasticsearch-7.6.0/datas # # Path to log files: #log file address path.logs: /data/es/elasticsearch-7.6.0/logs # # ----------------------------------- Memory ----------------------------------- # # Lock the memory on startup: #Memory configuration bootstrap.system_call_filter: false bootstrap.memory_lock: false # # Make sure that the heap size is set to about half the memory available # on the system and that the owner of the process is allowed to use this # limit. # # Elasticsearch performs poorly when the system is swapping the memory. # # ---------------------------------- Network ----------------------------------- # # Set the bind address to a specific IP (IPv4 or IPv6): #Native ip address network.host: ip # # Set a custom port for HTTP: # http.port: 9200 # # For more information, consult the network module documentation. #Allow cross domain http.cors.enabled: true http.cors.allow-origin: "*" # --------------------------------- Discovery ---------------------------------- #My is stand-alone. The type added here is stand-alone discovery.type: single-node # Pass an initial list of hosts to perform discovery when this node is started: # The default list of hosts is ["127.0.0.1", "[::1]"] #For the cluster type, you need to modify the following configuration to configure the ip address of each node in the cluster #If you want to form a cluster containing nodes on other hosts, you must use discovery seed_ The hosts setting provides a list of other nodes in the cluster #discovery.seed_hosts: ["host1", "host2"] # # Bootstrap the cluster using an initial set of master-eligible nodes: #For the cluster type, you need to modify the following configuration to configure the ip address of each node in the cluster #When you first start a brand new Elasticsearch When clustering, a cluster guidance step will appear, which determines the main candidates for counting votes in the first election#Lattice node set. In development mode, if the discovery setting is not configured, this step is automatically performed by the node itself. Because this auto boot is inherently unsafe#Therefore, when you start a new cluster in production mode, you must clearly list the names or names of the qualified nodes IP Address, the voting of these nodes shall be in the second page#Calculated in an election. Use cluster initial_ master_ Nodes sets this list. #cluster.initial_master_nodes: ["node-1", "node-2"] # # For more information, consult the discovery and cluster formation module documentation. # # ---------------------------------- Gateway ----------------------------------- # # Block initial recovery after a full cluster restart until N nodes are started: # #gateway.recover_after_nodes: 3 # # For more information, consult the gateway module documentation. # # ---------------------------------- Various ----------------------------------- # # Require explicit names when deleting indices: # #action.destructive_requires_name: true
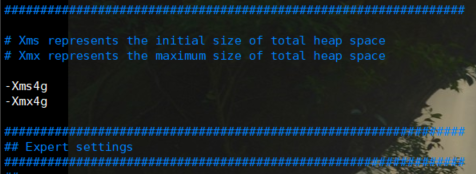
vim jvm.option
#Set the memory according to your server configuration -Xms4g -Xmx4g
5. Modify some configurations of the server to solve the startup error
Question 1: the maximum data limit for ordinary users to open files
Error message: max file descriptors [4096] for elasticsearch process like too low, increase to at least
[65536]
Error reason: ES needs to create a large number of index files and open a large number of system files, so we need to lift the limit on the maximum number of open files in linux system, otherwise es will throw an error when starting
sudo vim /etc/security/limits.conf
#Add the following: #es ordinary users created for you es soft nofile 65536 es hard nofile 131072 es soft nproc 2048 es hard nproc 4096
Problem 2: limit on the number of threads started by ordinary users
Error message: max number of threads [1024] for user [es] like too low, increase to at least [4096]
Error reason: the local thread cannot be created. The maximum number of threads that can be created by the user is too small
sudo vi /etc/security/limits.d/90‐nproc.conf
#es es soft nproc 4096
Problem 3: ordinary users increase virtual memory
Error message: Max virtual memory areas VM max_ map_ count [65530] likely too low, increase to at
least [262144]
Error reason: the maximum virtual memory is too small
sudo sysctl ‐w vm.max_map_count=262144 #Note: this command must be executed every time before starting es
Note: after the above three problems are solved, reconnecting secureCRT or reconnecting xshell takes effect. It can take effect only after saving, exiting and logging in again
Question 4
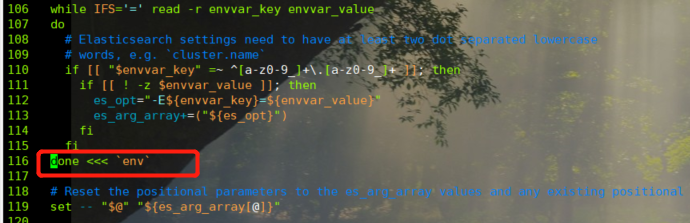
You may also report an error about the elasticsearch env file during startup. No errors were recorded at that time, but the modification scheme is shown below
#Modify about 116 lines to the following code 116 done <<< `env`
6. Start command
#Each cluster mode should be started nohup /data/es/elasticsearch-7.6.0/bin/elasticsearch 2>&1 &
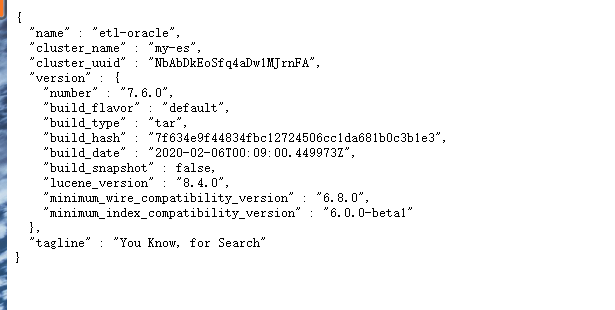
Access page:
http://ip:9200/?pretty Each can be viewed
If you want to view the log, go to the log address set in the configuration to find my es log
Install elasticsearch head
Because the es built-in page, that is, the above access page, is too ugly to see, elasticsearch head is installed
1. Install node js
node.js is a running environment used to run javascript language, which is equivalent to a jvm running java
You can find it in the shared resources above.
I installed node-v16 11.1-linux-x64. tar. gz
Decompression:

To create a soft connection:
sudo ln ‐s /data/node-v16.11.1-linux-x64/bin/node /usr/local/bin/node sudo ln ‐s /data/node-v16.11.1-linux-x64/bin/npm /usr/local/bin/npm
Check for success:
2. Install es head
You can download the source code and compile it yourself
You can also use the information in my resource bag
Various unexpected situations will occur during compilation. It is recommended to decompress the resource package directly
Upload and unzip:
To modify a profile:
vim Gruntfile.js
//The following code was found:
//Modify a line: hostname: 'ip',
connect: {
server: {
options: {
hostname: 'ip',
port: 9100,
base: '.',
keepalive: true
}
}
}
cd /data/es/elasticsearch-head/_site
vim app.js
//Change localhost to ip
this.base_uri = this.config.base_uri || this.prefs.get("app-base_uri") || "http://ip:9200";
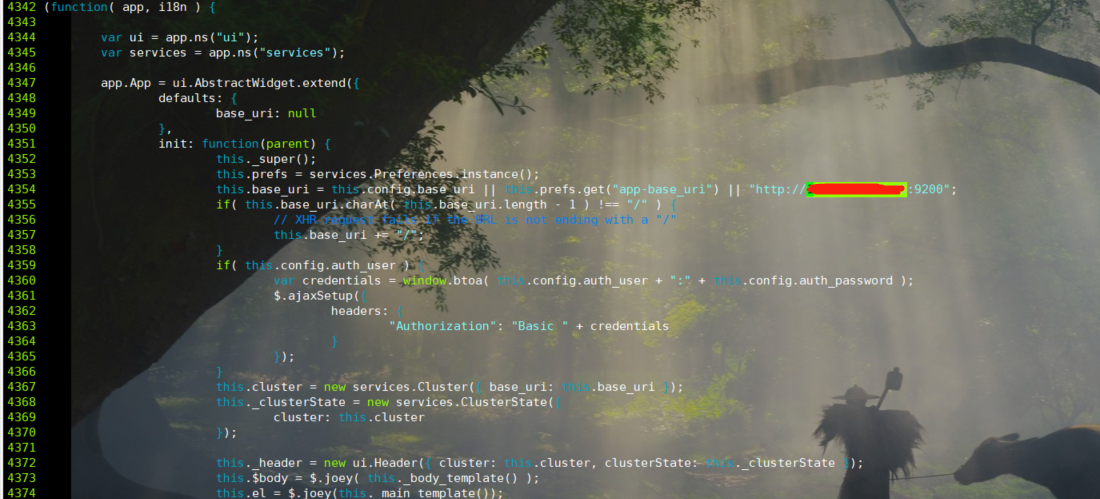
Start stop command
#Enter directory cd /data/es/elasticsearch-head/node_modules/grunt/bin #Attention should be paid to using the front desk to start/ An error may be reported when executing sh ./grunt server #The background startup starts with the background command and then exits the ssh connection. The background startup is true. The same is true for other front-end background startup nohup ./grunt server >/dev/null 2>&1 & exit #Kill netstat ‐nltp | grep 910 kill -9 pid
Access page:
http://ip:9100/
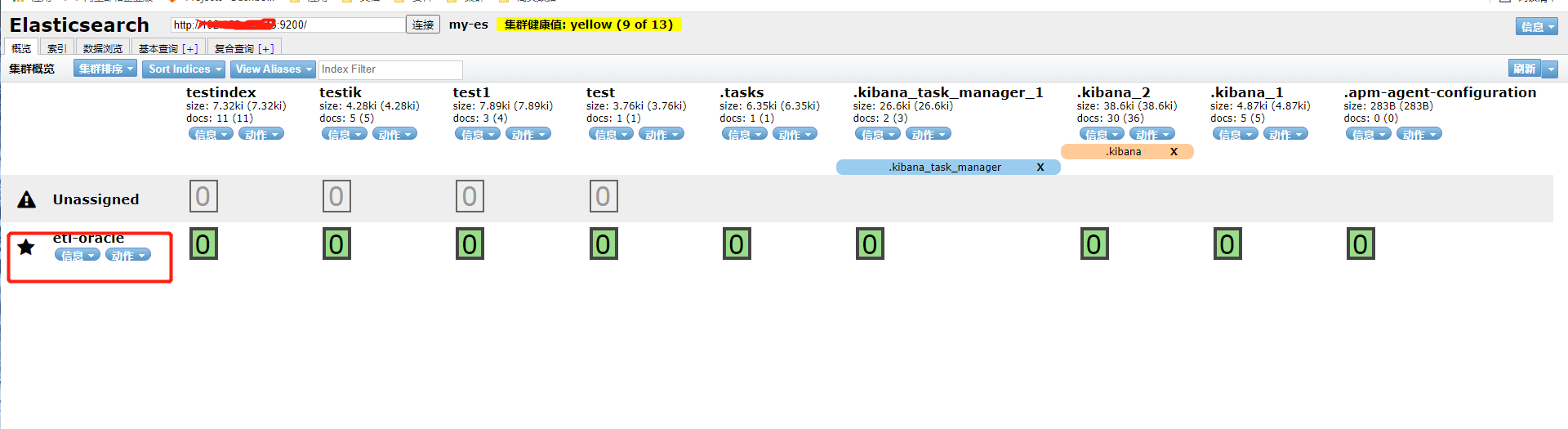
My is a single machine, so the health value of a normal cluster with yellow health value is green after startup
Install Kibana
1. Introduction
Kibana is an open source analysis and visualization platform designed to work with Elasticsearch. You use kibana to search, view, and interact with the data stored in the elastic search index. You can easily perform advanced data analysis and visualize data in the form of various icons, tables and maps.
2. Upload and unzip
To be consistent with the ES version, you can get it on the official website or in the resources I share
3. Modify the configuration file
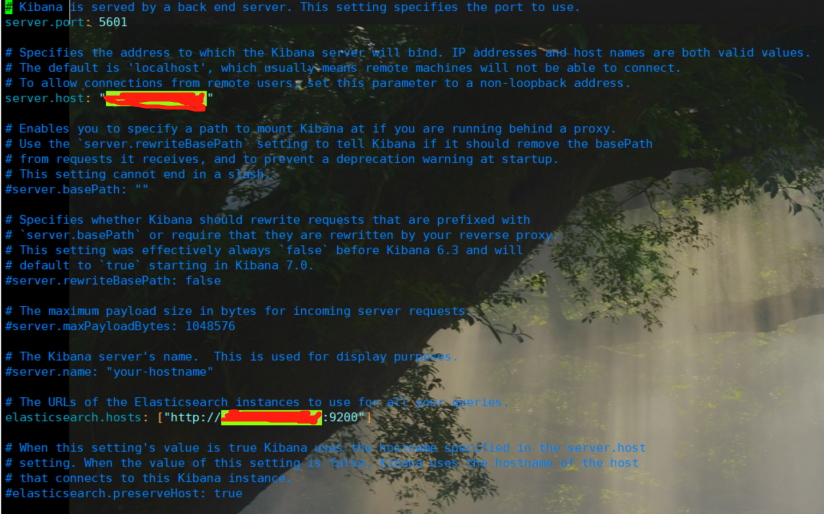
vim /data/es/kibana-7.6.0-linux-x86_64/config/kibana.yml
#Modify the following kibana.ymlserver.host: "ip" elasticsearch.hosts: ["http://ip:9200"]
4. Start command
#Enter the bin directory #start-up nohup sh kibana >/dev/null 2>&1 & #stop it ##View process number ps ‐ef | grep node ##Then kill the process with kill ‐ 9
5. Access page
http://192.168.101.45:5601/
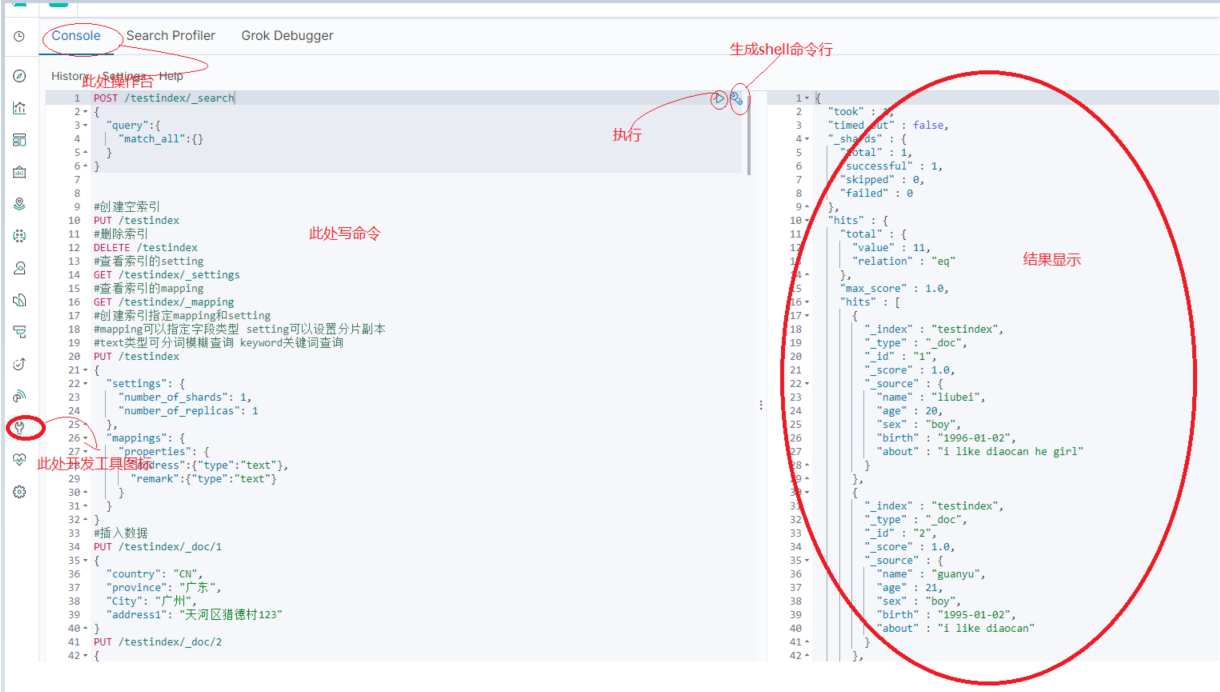
It is generally developed in the development tool shown in the figure above
Install ik word splitter
Note: each cluster mode needs to be installed
The core requirement of search is full-text retrieval. In short, full-text retrieval is to find the location of a word in a large number of documents. In the traditional relational database, data retrieval can only be realized through like, but in es, it is realized through word segmentation
An important function of ES for text search is word segmentation, which is to segment the data in the analyzable field in ES. Then an inverted index is established for Related words.
The inverted index is divided into two parts. One part is a word dictionary and the other part is an inverted list. The inverted index can be understood as follows: the storage unit in ES is a document. The document has a unique id. The inverted index uses word segmentation for the content, and takes the word as the search key and the document id as the value we want to obtain.
Correspondingly, the forward index is the forward index, which takes the document id as key and the document content as the value.
ES searches and extracts the id document from the inverted index according to the word separated, and then obtains the document content through the forward index of the document id.
For the word splitter in ES, there are the following types:
| Tokenizer | purpose |
|---|---|
| Standard Analyzer | Standard word splitter, suitable for English, etc |
| Simple Analyzer | Simple word splitter, word segmentation based on non alphabetic characters, words will be converted to lowercase letters |
| Whitespace Analyzer | Space word splitter, install space segmentation |
| Stop Analyzer | It is similar to the simple word separator, but the function of stop word is added |
| Keyword Analyzer | Keyword participle, input text is equal to output text |
| Pattern Analyzer | Use regular expressions to segment text and support stop words |
| Language Analyzer | Language specific word splitter |
| Fingerprint Analyzer | Fingerprint analysis word splitter, by creating markers for duplicate detection |
For ES text analysis, there are several built-in word splitters that are not friendly to Chinese word segmentation, so the IK word splitter plug-in is installed to support Chinese word segmentation
1. Download, install and unzip
You can download it from githup: https://github.com/medcl/elasticsearch-analysis-ik
Note: to download the corresponding version, mine is 7.6.0
You can also get it from the resources shared above
cd /data/es/elasticsearch-7.6.0/plugins mkdir ik #Unzip the compressed package to the ik directory
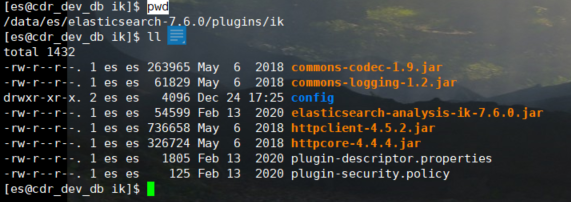
2. Restart es
#stop it
ps ‐ef|grep elasticsearch|grep bootstravelap |awk '{print $2}' |xargs kill ‐9
#start-up
nohup /data/es/elasticsearch-7.6.0/bin/elasticsearch 2>&1 &
Note: ik with two word splitters:
ikmaxword: the text will be split at the finest granularity; Split as many words as possible
Sentence: I love my motherland
Result: I love my ancestors and motherland
ik_smart: can do the coarsest granularity splitting; Words that have been separated will not be occupied by other words again
Sentence: I love my motherland
Result: I love my motherland
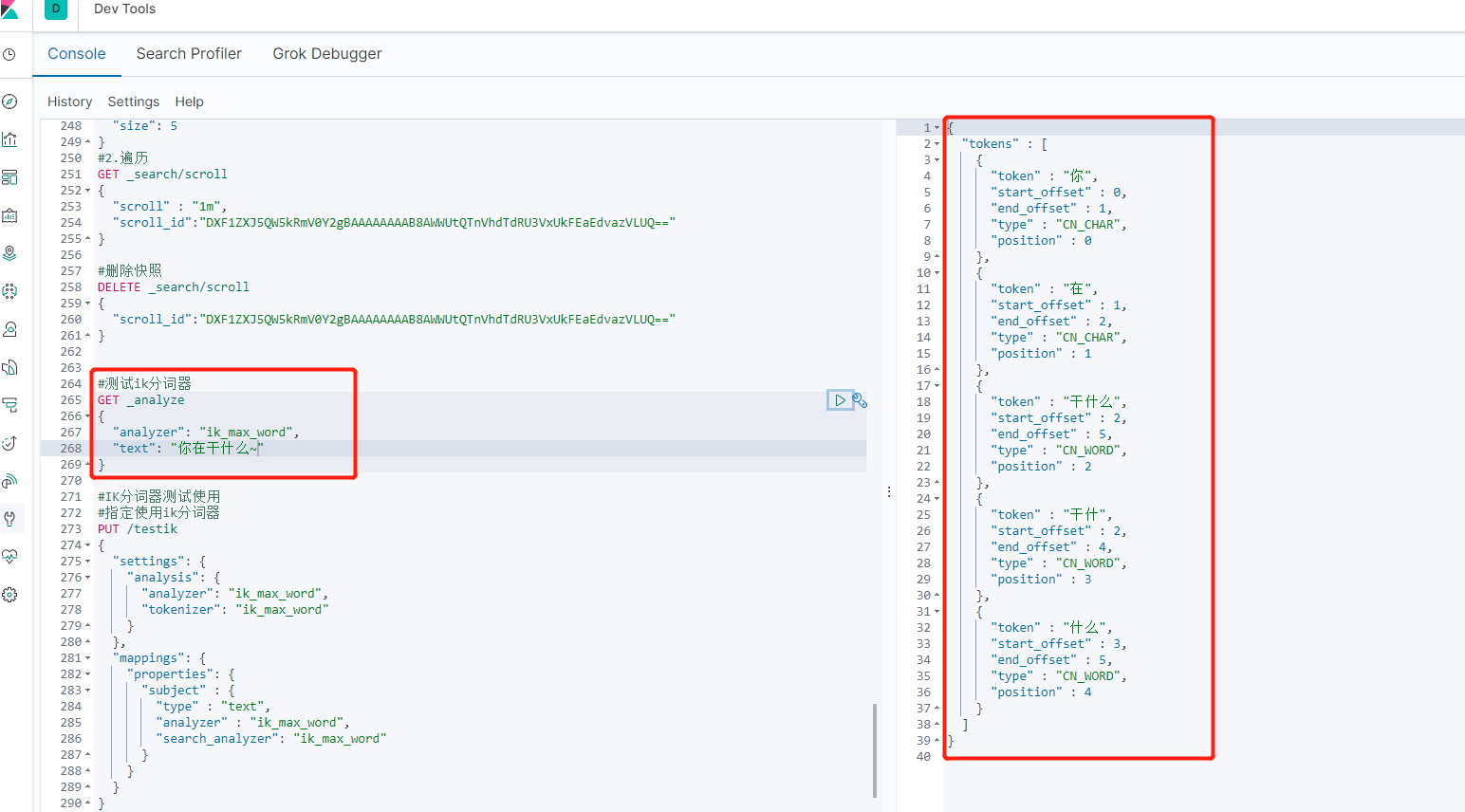
3. Test
#Test ik participle
GET _analyze
{
"analyzer": "ik_max_word",
"text": "what are you doing?~"
}
4. Hot word update
Note: only one server is required to configure the hot word service
For ik word segmentation, we use a thesaurus that has been divided. If you want to identify some hot words, hot stems or professional terms in some industries on the Internet, you need to update the thesaurus.
Update thesaurus and configure hot word update if you don't want to restart es
View ik your own Thesaurus:
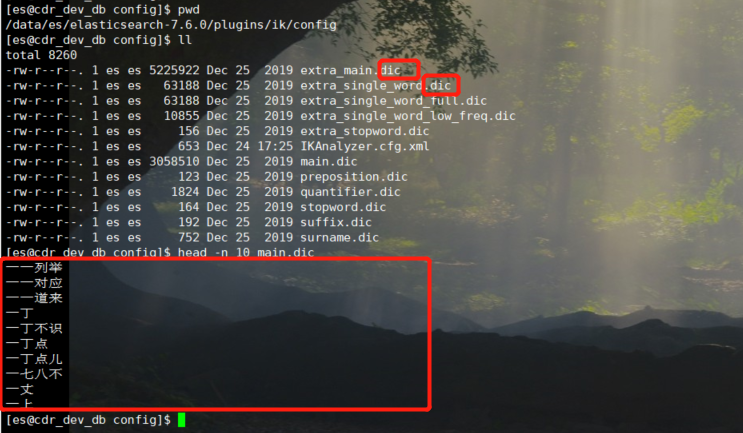
It can be seen that all dictionaries are dic format file, and each word is divided into one line
Configure hot word server:
#Enter directory
cd /data/es/elasticsearch-7.6.0/plugins/ik/config
#Modify profile
vim IKAnalyzer.cfg.xml
#Modify the following
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer Extended configuration</comment>
<!--Users can configure their own extended dictionary here -->
<entry key="ext_dict"></entry>
<!--Users can configure their own extended stop word dictionary here-->
<entry key="ext_stopwords"></entry>
<!--Users can configure the remote extension dictionary here -->
<entry key="remote_ext_dict">Own dictionary address</entry>
<!--Users can configure the remote extended stop word dictionary here-->
<entry key="remote_ext_stopwords">Own dictionary address</entry>
</properties>
Set hot word server:
Download, upload and unzip tomcat. You can download it yourself or use my resources
#Enter directory cd /data/es/apache-tomcat-9.0.56/webapps/ROOT #New dictionary file vim hot.dic #The contents of the file can be written by itself I feel awful. I want to cry Water of the Yellow River #Start tomcat cd /data/es/apache-tomcat-9.0.56/bin sh startup.sh
Access page:
http://ip:8080/hot.dic
It doesn't matter if it's garbled, just hot DIC is in utf8 format
take http://ip:8080/hot.dic Configure it into the ik configuration file above
Configure hot word server:
#Enter directory
cd /data/es/elasticsearch-7.6.0/plugins/ik/config
#Modify profile
vim IKAnalyzer.cfg.xml
#Modify the following
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer Extended configuration</comment>
<!--Users can configure their own extended dictionary here -->
<entry key="ext_dict"></entry>
<!--Users can configure their own extended stop word dictionary here-->
<entry key="ext_stopwords"></entry>
<!--Users can configure the remote extension dictionary here -->
<entry key="remote_ext_dict">http://ip:8080/hot.dic</entry>
<!--Users can configure the remote extended stop word dictionary here-->
<entry key="remote_ext_stopwords">http://ip:8080/hotstop.dic</entry>
</properties>
Restart es
#stop it
ps ‐ef|grep elasticsearch|grep bootstravelap |awk '{print $2}' |xargs kill ‐9
#start-up
nohup /data/es/elasticsearch-7.6.0/bin/elasticsearch 2>&1 &
In this way, ES will read our remote dictionary every 1 minute to update the thesaurus
View log:

Test word splitter:
#Test ik participle
GET _analyze
{
"analyzer": "ik_max_word",
"text": "The water of the Yellow River comes up from the sky~"
}
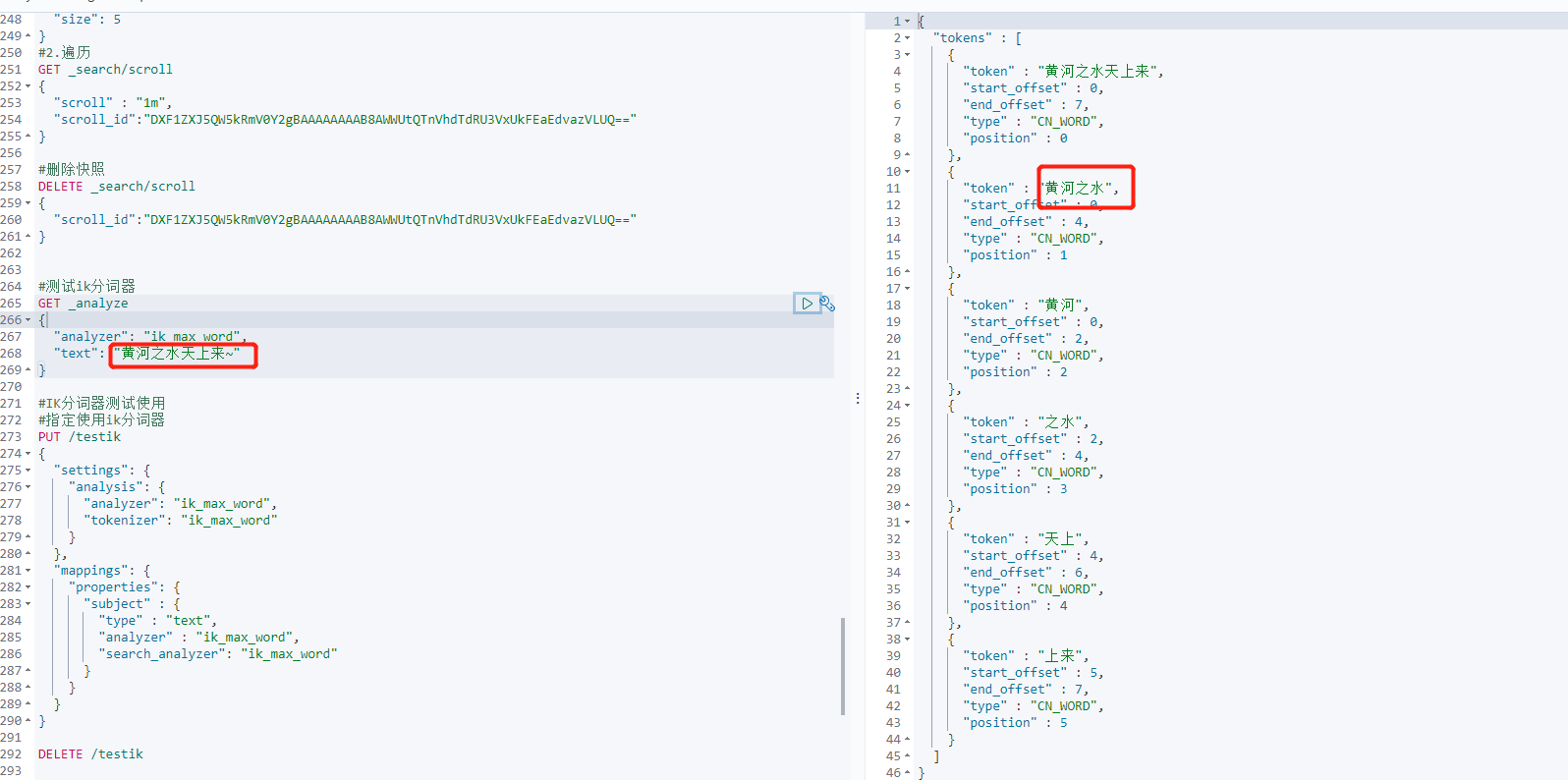
You can configure the stop dictionary. If you stop the dictionary configuration, you won't segment and stop the words in the dictionary
#######################################################
######################The installation is now complete######################
#######################################################
4, Use and syntax of ES
The following are implemented in kibana with ES7 syntax (other versions can add their own type):
One great advantage of ES is that it provides a rest api for users to manipulate data
| HTTP | purpose |
|---|---|
| PUT | Used to create |
| GET | For obtaining |
| POST | For updating, some queries can be used like GET |
| Delete | For deletion |
Basic statement
1. Cluster management
_ cat related view cluster
For example, aliases alias health status nodes indexes of nodes and so on
2. Index related operations
Index related operations specify that the first bit in the HTTP url is the index, such as PUT / index name
#Create empty index
PUT /testindex
#Create an index and specify mapping and setting
#mapping can specify the field type and setting can set the fragment copy
#text type separable word fuzzy query keyword keyword query
PUT /testindex
{
"settings": {
"number_of_shards": 1,
"number_of_replicas": 1
},
"mappings": {
"properties": {
"address":{"type":"text"},
"remark":{"type":"text"}
}
}
}
#Delete index
DELETE /testindex
#View index setting
GET /testindex/_settings
#Viewing mapping of indexes
GET /testindex/_mapping
3. Document data related operations
As the data format stored in ES, we add, delete, modify and query the document
Add a new document
#First create the index
PUT /testindex
#Insert a piece of data and specify the document id
PUT /testindex/_doc/1
{
"country": "China",
"province": "Beijing",
"City": "Beijing",
"address1": "East Chang'an Street"
}
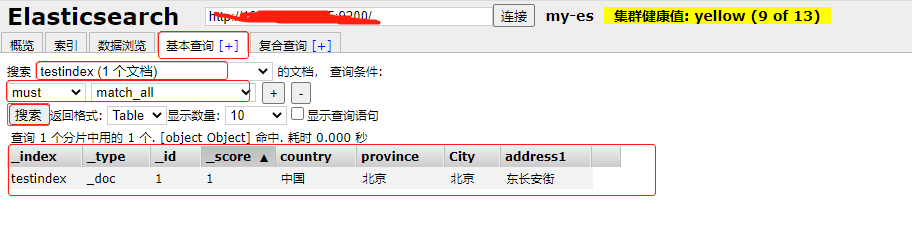
You can visually view the inserted data through the ES head plug-in
The process is: basic query - search the created document - select the method must match_ All (automatic) -- Search
The value is displayed as the index name and the unique id of the type document. After the score is the field we inserted
You can get all (must match_all) during testing, but not in production. This may cause GC
View the ES head plug-in
#Create document without specifying id
#At this time, you can only use POST to create
POST /testindex/_doc/
{
"country": "China",
"province": "Beijing",
"City": "Beijing",
"address1": "East Chang'an Street"
}
View the ES head plug-in
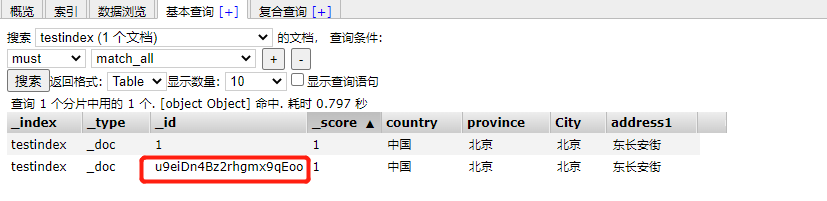
You can see that ES automatically generates a unique id
#What if the data inserted again is different from the previous field
#Delete the country field and add the address2 field
PUT /testindex/_doc/2
{
"province": "China",
"City": "Beijing",
"address1": "East Chang'an Street",
"address2": "West Chang'an Street"
}
View the ES head plug-in
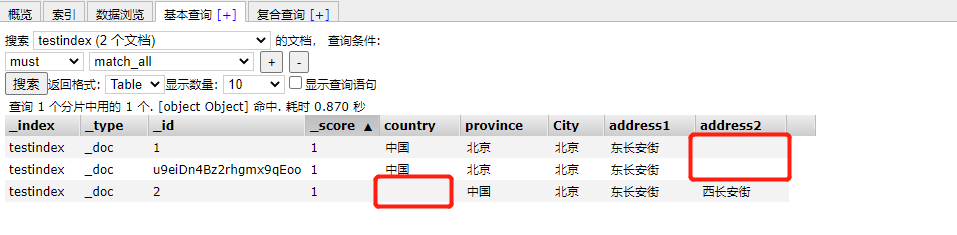
It can be seen that after the previous field is supplemented as empty, the data before creating a new field is supplemented as empty
Generally, fields and field types are specified before production
Delete a document
#Specifies the document id to delete DELETE /testindex/_doc/u9eiDn4Bz2rhgmx9qEoo
View the ES head plug-in
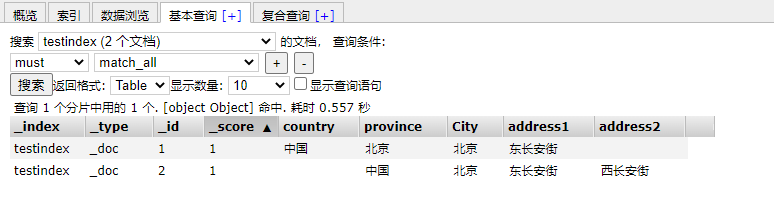
Deleting a document is only a logical deletion, not a direct deletion on disk
Modify one data in the document
#Modify the specified id in full
#You can also use post
PUT /testindex/_doc/1
{
"country": "China",
"province": "Tianjin",
"City": "Tianjin",
"address1": "area for development"
}
View the ES head plug-in
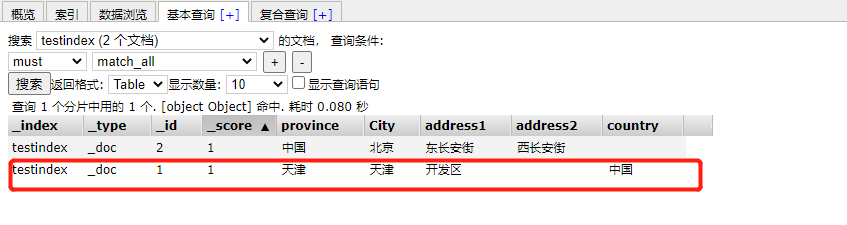
Writing the same id in ES will overwrite this document
#Partial modification
#Only post can be used
POST /testindex/_update/2
{
"doc": {
"City":"Haidian, Beijing"
}
}
View the ES head plug-in
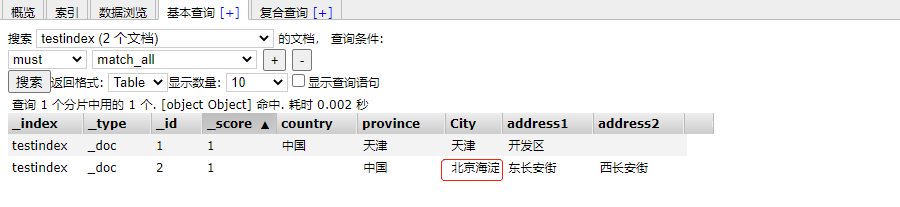
Batch insert
#Specify index
POST /testindex/_bulk
{"index":{"_id":3}}
{"country": "China","province": "Beijing","City": "Fengtai","address1": "Gymnasium"}
{"index":{"_id":4}}
{"country": "China","province": "Beijing","City": "Haidian","address1": "Wukesong"}
View the ES head plug-in
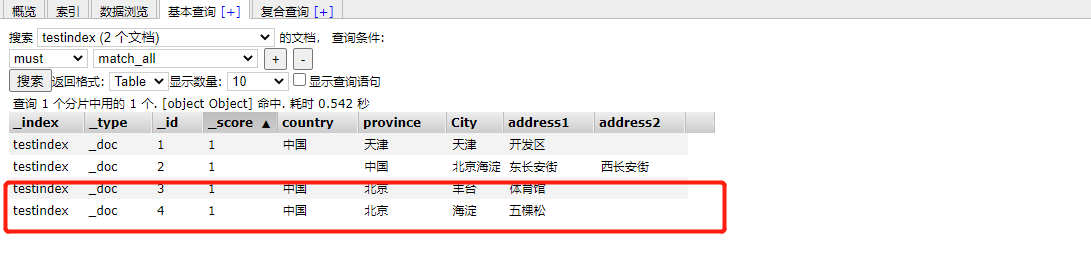
#Set index in request body
POST _bulk
{"create":{"_index":"testindex","_id":5}}
{"country": "China","province": "Beijing","City": "Changping","address1": "Ping Xifu"}
{"create":{"_index":"testindex","_id":6}}
{"country": "China","province": "Beijing","City": "Westlife ","address1": "Xidan"}
View the ES head plug-in
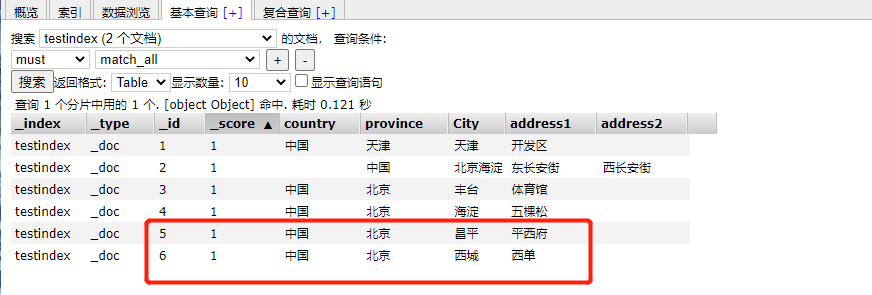
Query statement
Query return value
| Return value | explain |
|---|---|
| Hits | The most important part of the returned result is hits, which contains the total field to represent the total number of matched documents, and a hits array contains the first ten documents of the query result. In the hits array, each result contains the of the document_ index , _ type , _ ID, plus_ source field. This means that we can use the entire document directly from the returned search results. Unlike other search engines, which only return the document ID, you need to get the document alone. There is one for each result_ Score, which measures how well the document matches the query. By default, the most relevant document results are returned first, that is, the returned documents are based on_ Scores are in descending order. If we do not specify any query, then all documents have the same relevance, so 1 is neutral for all results_ score . max_ The score value is the number of documents that match the query_ Maximum value of score |
| took | The took value tells us how many milliseconds it took to execute the entire search request |
| Shard | _ The shards section tells us the total number of shards involved in the query, and how many of these shards succeeded and failed. Normally, we don't want fragmentation failure, but fragmentation failure can happen. If we encounter a disaster level failure in which the original data and copies of the same partition are lost, there will be no available copies for this partition to respond to the search request. If so, elastic search will report that the fragment failed, but will continue to return the results of the remaining fragments. |
| timeout | timed_ The out value tells us whether the query timed out. By default, search requests do not time out. If the low response time is more important than the completion result, you can specify the timeout as 10 or 10ms (10ms), or 1s (1s): get/_ search? Timeout = 10ms before the request times out, Elasticsearch will return the results successfully obtained from each partition. |
1. Basic query
Full query
#Full query get or post
GET /testindex/_search
{
"query":{
"match_all":{}
}
}
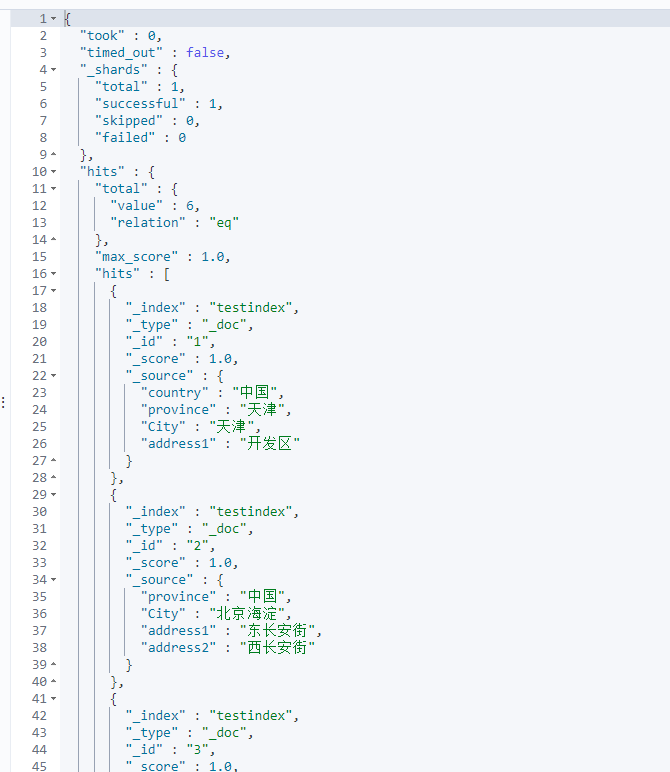
Primary key query
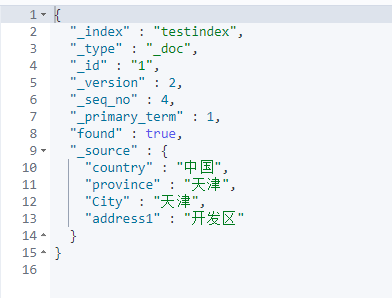
#Specify document id to query data GET /testindex/_doc/1
2. Fancy query
Test with a piece of data on the Internet
#Delete index
DELETE /testindex
#New index
PUT /testindex
#Batch insert data
POST /testindex/_bulk
{"index": { "_id": 1 }}
{ "name" : "liubei", "age" : 20 , "sex": "boy", "birth": "1996-01-02" , "about": "i like diaocan he girl"}
{ "index": { "_id": 2 }}
{ "name" : "guanyu", "age" : 21 , "sex": "boy", "birth": "1995-01-02" , "about": "i like diaocan" }
{ "index": { "_id": 3 }}
{ "name" : "zhangfei", "age" : 18 , "sex": "boy", "birth": "1998-01-02" , "about": "i like travel" }
{ "index": { "_id": 4 }}
{ "name" : "diaocan", "age" : 20 , "sex": "girl", "birth": "1992-01-02" , "about": "i like travel and sport"}
{ "index": { "_id": 5 }}
{ "name" : "panjinlian", "age" : 25 , "sex": "girl", "birth": "1991-01-02" , "about": "i like travel and wusong"}
{ "index": { "_id": 6 }}
{ "name" : "caocao", "age" : 30 , "sex": "boy", "birth": "1988-01-02" , "about": "i like xiaoqiao" }
{ "index": { "_id": 7 }}
{ "name" : "zhaoyun", "age" : 31 , "sex": "boy", "birth": "1997-01-02" , "about": "i like travel and music" }
{ "index": { "_id": 8 }}
{ "name" : "xiaoqiao", "age" : 18 , "sex": "girl", "birth": "1998-01-02" , "about": "i like caocao" }
{ "index": { "_id": 9 }}
{ "name" : "daqiao", "age" : 20 , "sex": "girl", "birth": "1996-01-02" , "about": "i like travel and history"}
{ "index": { "_id": 10 }}
{ "name" : "zhuge", "age" : 20 , "sex": "boy", "birth": "1996-01-02" , "about": "i like travel and history"}
{ "index": { "_id": 11 }}
{ "name" : "gaunyu", "age" : 20 , "sex": "boy", "birth": "1993-01-02" , "about": "i like travel and chunqiu"}
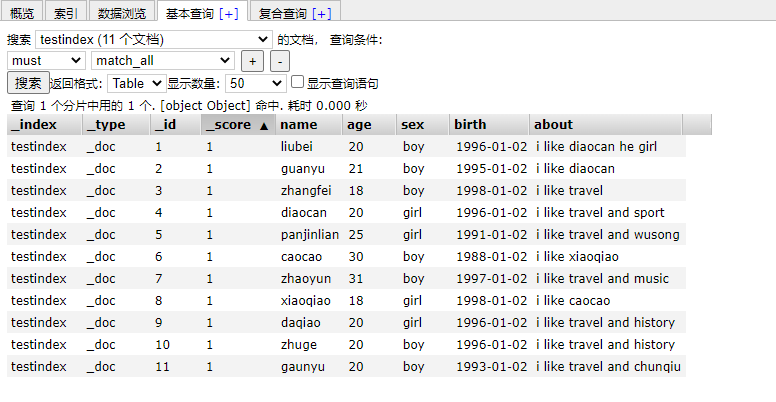
see:
Query by keyword
Match by match
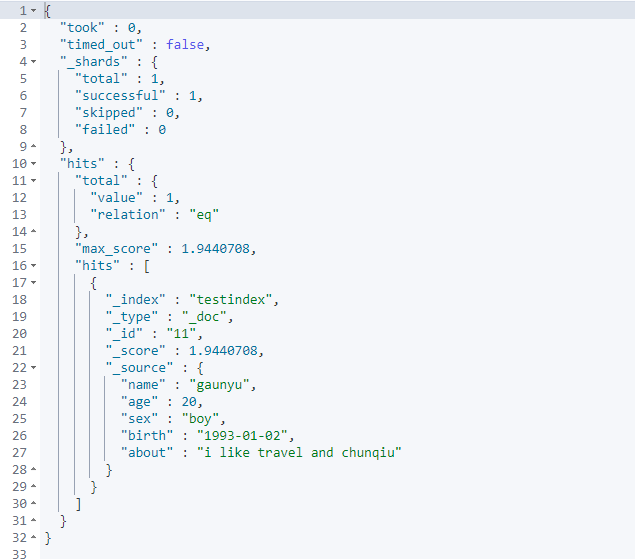
Query people who like reading spring and autumn at night
#match keyword search
GET /testindex/_search
{
"query": {
"match": {
"about": "chunqiu"
}
}
}
Compound query
When multiple query statements are combined, bool can be used to include them. Bool merge aggregate contains: must, must_not or should,
should means or
Inquire about people who like traveling and don't read spring and autumn
#bool compound query
## Must is required_ Not must be or should not be
GET /testindex/_search
{
"query": {
"bool": {
"must": [
{"match": {
"about": "travel"
}}
],
"must_not": [
{"match": {
"about": "chunqiu"
}}
]
}
}
}
Accurate matching
Matching through the above match is after word segmentation
Exact matching is used for accurate filtering
For example, enter "I love you"
Under match, matching can be parsers containing: I, love, you, I love, etc
Under the term syntax, it accurately matches: "I love you"
#Term exact matching term matching one term matches multiple terms
GET /testindex/_search
{
"query": {
"bool": {
"must": [
{"terms": {
"about": [
"travel",
"sport"
]
}}
]
}
}
}
Range matching
Range filtering allows us to find some data according to the specified range: operation range: gt:: greater than, gae:: greater than or equal to, lt:: less than, lte:: less than or equal to
Find out students older than 20 and younger than or equal to 25
#range filtering gt:: greater than, gte:: greater than or equal to, lt:: less than, lte:: less than or equal to
GET /testindex/_search
{
"query": {
"range": {
"age": {
"gt": 20,
"lte": 25
}
}
}
}
exists and missing filtering
exists and missing filters can find whether the document contains a field or does not have a field of data
#Exists and missing filter exists or missing does not exist. Here, it is determined whether the field exists or not rather than the value of the field
GET /testindex/_search
{
"query": {
"exists": {
"field": "age"
}
}
}
filter filtering
filter filters the value of a field
#filter filtering
GET /testindex/_search
{
"query": {
"bool": {
"must": [
{"match": {
"about": "travel"
}}
],
"filter": {"term": {
"age": "20"
}}
}
}
}
Paging query
Paging query is divided into size+from shallow paging and size+from shallow paging
#size+from shallow paging
#from defines the offset of the target data, and size defines the number of events currently returned
GET /testindex/_search
{
"query": {
"match_all": {}
},
"from": 5,
"size": 20
}
This shallow paging is only suitable for a small amount of data, because with the increase of from, the query time will be larger, and the larger the amount of data, the query efficiency index will decrease
#Scroll deep paging scroll maintains a snapshot information cache of the current index segment
#Two steps 1 Generate snapshot 2 Traversal snapshot
#? scroll=3m sets the expiration time of the cache
#1. Generate snapshot
GET /testindex/_search?scroll=3m
{
"query": {
"match_all": {}
},
"size": 5
}
#2. Traversal
GET _search/scroll
{
"scroll" : "1m",
"scroll_id":"DXF1ZXJ5QW5kRmV0Y2gBAAAAAAAAiPcWWUtQTnVhdTdRU3VxUkFEaEdvazVLUQ=="
}
#Delete snapshot
DELETE _search/scroll
{
"scroll_id":"DXF1ZXJ5QW5kRmV0Y2gBAAAAAAAAiPcWWUtQTnVhdTdRU3VxUkFEaEdvazVLUQ=="
}
Query sorting
The sort statement is equivalent to sql order by
#The multi condition query sort statement and query statement are equivalent to sorting the data found in sql
GET /testindex/_search
{
"query": {
"bool": {
"must": [
{"term": {
"about": {
"value": "travel"
}
}},
{"range": {
"age": {
"gte": 20,
"lte": 30
}
}}
]
}
},
"sort": [
{
"age": {
"order": "desc"
}
}
]
}
3. Aggregate query
Aggregation allows users to perform statistical analysis on es documents, similar to group by in relational databases. Of course, there are many other aggregations, such as taking the maximum value max, the average value avg, and so on.
The returned result will be accompanied by the original data. If you don't want results without raw data. You can use the size keyword.
Basic concepts
#Aggregate query
#The field of aggregate query in es should be of keyword type
#Aggregate query is the grouping aggregation equivalent to sql
#There are two concepts: bucket (group by) and indicator (aggregate indicator sum/count/max/min)
#Query in the following statement: you can query first and then aggregate functions
#aggs: aggregate command
#NAME: aggregate NAME user defined
#AGG_TYPE: aggregate type, which represents how we want statistics. There are two main types of aggregation: bucket aggregation and indicator aggregation
#AGG_TYPE {}: some parameters of aggregation can also be re aggregated within the aggregation function, such as aggs1 and aggs2 below
#You can also query multiple aggregations, such as NAME1 and NAME2 below
#size=0 means that you do not need to return query results, but only aggs statistical results
GET /testindex/_search
{
"query": {},
"aggs": {
"NAME": {
"AGG_TYPE": {}
,"aggs2": {
"NAME": {
"AGG_TYPE": {}
}
}},
"NAME2": {
"AGG_TYPE": {}
}
},
"size": 0
}
Index aggregation
#Index aggregation
#value count: total statistics;
#Cardinality: SQL like count(DISTINCT field)
#sum: sum
#max: maximum
#min: minimum
#avg: Average
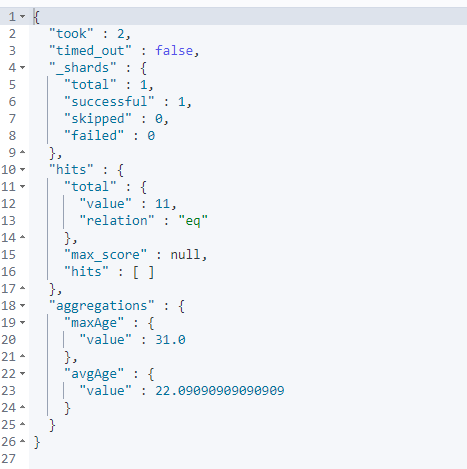
GET /testindex/_search
{
"aggs": {
"avgAge": {
"avg": {
"field": "age"
}
},
"maxAge": {
"max": {
"field": "age"
}
}
},
"size": 0
}
result:
Grouping aggregation
#Grouping aggregation
#terms: sql like group by;
#Histogram[ ˈ h ɪ st əɡ r æ m]) aggregation: grouping by array interval, such as price 100 interval grouping, 0100200, etc;
#Date histogram aggregation: grouping according to time interval, for example, grouping by month, day and hour;
#Range: according to the numerical range, for example, 0-150, 150-200 and 200-500.
#Bucket aggregation is generally not used alone, but together with indicator aggregation. After grouping the data, you must count the data in the bucket. If indicator aggregation is not explicitly specified in ES, the Value Count indicator aggregation is used by default to count the total number of documents in the bucket
GET /testindex/_search
{
"aggs": {
"termsTest": {
"terms": {
"field": "sex",
"size": 10
}
}
},
"size": 0
}
result:
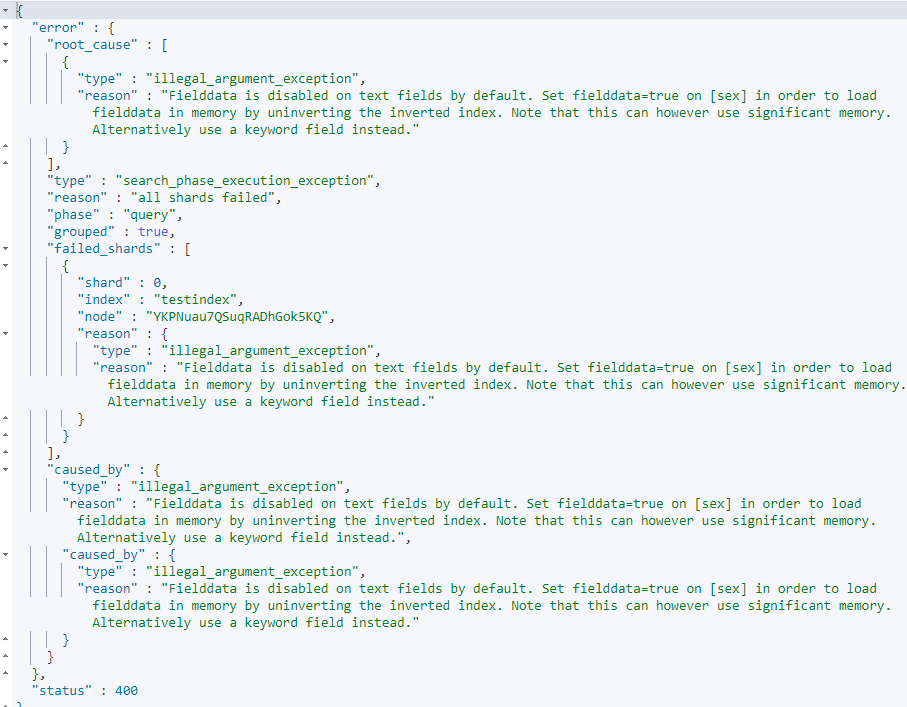
An error is generated because the ES that dynamically identifies the data type when writing the index recognizes the data as text
After the index is established in ES, the field type cannot be changed
One way: use sex Keyword or specify filedata, but filedata eats too many resources, so it is not considered
Another way: rebuild the index and specify the field as keyword to synchronize data
The second approach is used here:
Synchronous data
#New index
#Specify the time field and the keyword field
PUT /testindex2
{
"mappings" : {
"properties" : {
"about" : {
"type" : "text"
},
"age" : {
"type" : "long"
},
"birth" : {
"type" : "date",
"format": "yyyy-MM-dd"
},
"name" : {
"type" : "text"
},
"sex" : {
"type" : "keyword"
}
}
}
}
#View index
GET /testindex2/_mapping
#Synchronous data
POST _reindex
{
"source": {"index": "testindex"},
"dest": {"index": "testindex2"}
}
result:
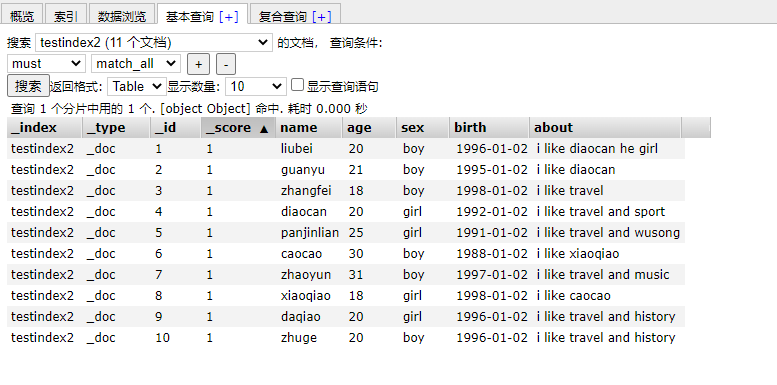
The data has been synchronized
Continue testing grouped aggregate data
terms
#terms
GET /testindex2/_search
{
"aggs": {
"termsTest": {
"terms": {
"field": "sex"
}
}
},
"size": 0
}
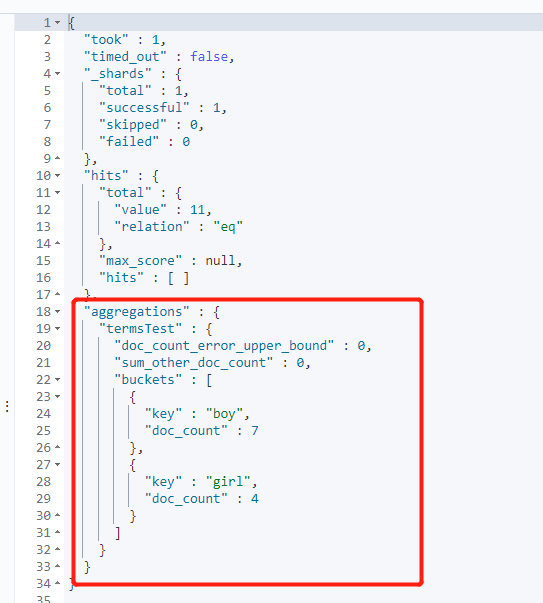
histogram
#Histogram
GET /testindex2/_search
{
"aggs": {
"histogramTest": {
"histogram": {
"field": "age",
"interval": 5
}
}
},
"size": 0
}
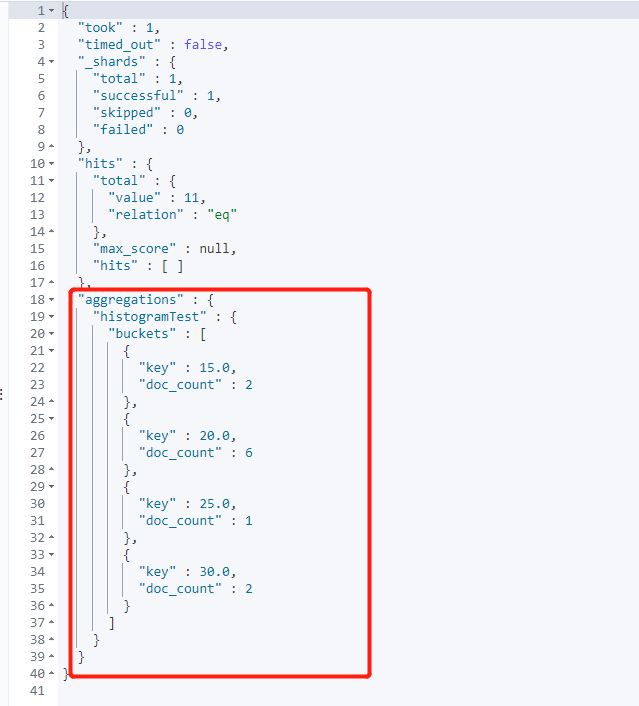
date_histogram
#Date Histogram
GET /testindex2/_search
{
"aggs": {
"dateHisTest": {
"date_histogram": {
"field": "birth",
"interval": "year"
}
}
},
"size": 0
}

Range
#Range
#The user-defined interval can be specified through the key value to facilitate subsequent search
GET /testindex2/_search
{
"aggs": {
"rangeTest": {
"range": {
"field": "age",
"ranges": [
{
"key": "18-20",
"from": 18,"to": 20
},
{
"key": "20-30",
"from": 20,"to": 30
}
]
}
}
},
"size": 0
}
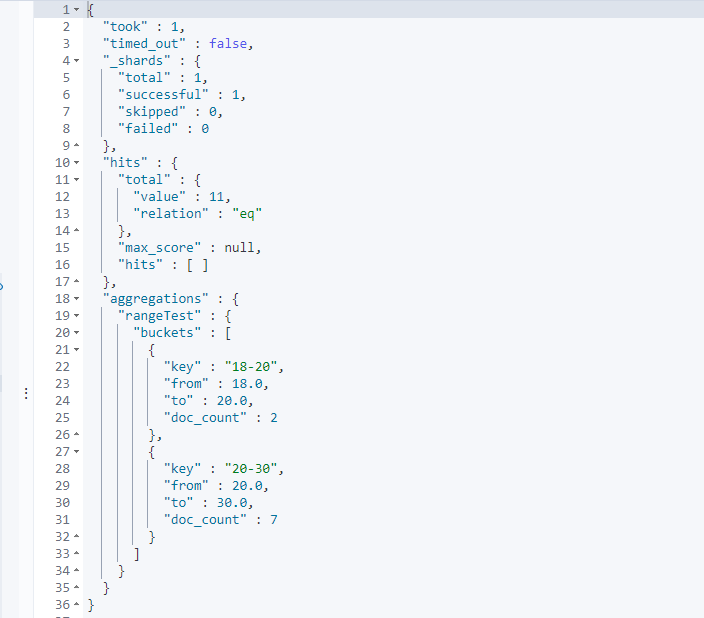
Combined use
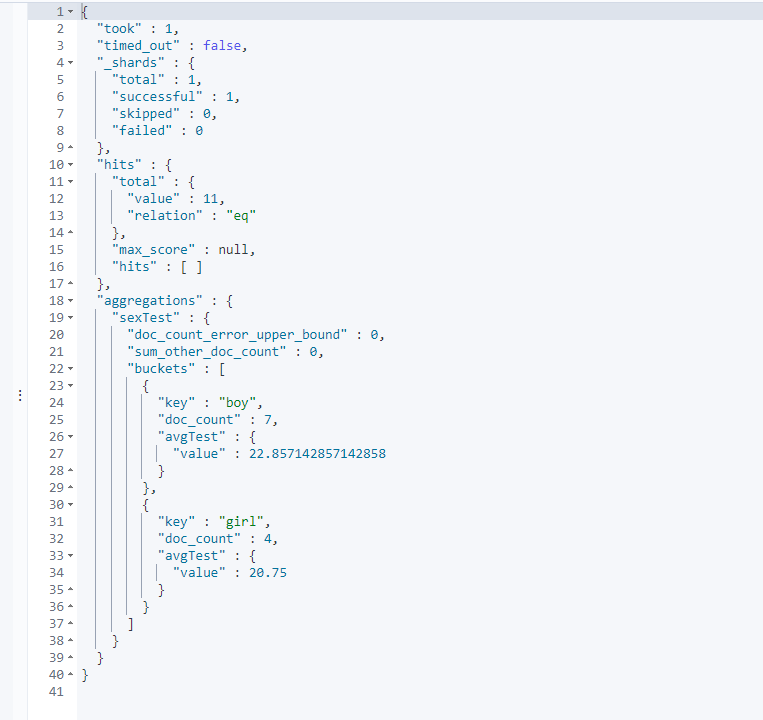
#test
#Query the average age in each group according to gender
GET /testindex2/_search
{
"size": 0,
"aggs": {
"sexTest": {
"terms": {
"field": "sex"
},
"aggs": {
"avgTest": {
"avg": {
"field": "age"
}
}
}
}
}
}
Full text retrieval, phrase matching and multi field matching
Data preparation
#New index
PUT /testindex3
#Delete index
DELETE /testindex3
#Batch insert
POST /testindex3/_bulk
{"index": { "_id": 1 }}
{"desc1":"a","desc2":"c"}
{"index": { "_id": 2 }}
{"desc1":"b","desc2":"a"}
{"index": { "_id": 3 }}
{"desc1":"c","desc2":"b"}
{"index": { "_id": 4 }}
{"desc1":"a b c","desc2":"a d"}
{"index": { "_id": 5 }}
{"desc1":"b c d","desc2":" a c"}
{"index": { "_id": 6 }}
{"desc1":"a c e","desc2":"d"}
{"index": { "_id": 7 }}
{"desc1":"d f g ","desc2":"a b c"}
{"index": { "_id": 8 }}
{"desc1":"c a","desc2":" c d"}
1.minimum_should_match
Minimum match
The meaning is the lowest matching words
Parameters passed in
Numbers positive integers or negative integers represent at least a few words that match. Negative numbers represent the maximum number of mismatches, such as 2, - 2
Percentage at least the percentage of matching words can be positive or negative as numbers, such as 50%, - 50%
It can also be mixed
Digital parameters
#number
GET /testindex2/_search
{
"query": {
"match": {
"about": {
"query": "i,like,and",
"minimum_should_match": 2
}
}
}
}
percentage
#percentage
GET /testindex2/_search
{
"query": {
"match": {
"about": {
"query": "i,like,and",
"minimum_should_match": "40%"
}
}
}
}
Combined use
#combination
#The format of the combination is number < percentage. The logic is to use number if the number of word segments given is less than or equal to number, otherwise use percentage
#It can also be understood as ternary expression format (given the number of query word segments < = the given numerical parameters)? Given parameter number: given percentage
#Multiple combined formats are executed in series
GET /testindex2/_search
{
"query": {
"match": {
"about": {
"query": "i,like,and",
"minimum_should_match": "3<40% 2<-10%"
}
}
}
}
2.match_phrase
match_ The data type of phrase search is text, which will segment the query criteria, but the documents to be matched need to contain the data after word segmentation. And the same order can be understood as the function of accurate matching of term
This search performance is not high because the location information of word segmentation needs to be calculated
GET /testindex2/_search
{
"query": {
"match_phrase": {
"about": {
"query": "i like aaa",
"slop": 0
}
}
}
}
3. Multi field matching
#Using multi_match can query the data of multiple fields, which is equivalent to writing multiple matches and using dis_max package or bool matching query. Both are tested in fancy queries. Now use the api for this single multi field query
The most important point is to set the weight for the score of the query field
The weight can be set by ^ weight. For example, about^3 means that the weight of the about field is 3 times
multi_ Common types of match are:
| type | explain |
|---|---|
| best_fields | (default) finds documents that match any field, using the weight of the best field |
| most_fields | Find documents that match any field and combine the weights for each field |
| cross_fields | Use the same analyzer to process fields as if they were a large field. Find each word in any field |
| phrase | Run match on each field_ Phrase query and merge the weights of each field are not recommended |
best_fields
best_ The fields type uses the score of a single best match field
If tie_ If the breaker specifies the score, the score is calculated as follows: score of a single best match field + (tie_breaker * score of all other matching fields)
operator specifies whether all participles match
#best_fields
GET /testindex3/_search
{
"query": {
"multi_match": {
"query": "c",
"fields": ["desc1","desc2"],
"type": "best_fields",
"tie_breaker": 0
}
}
}
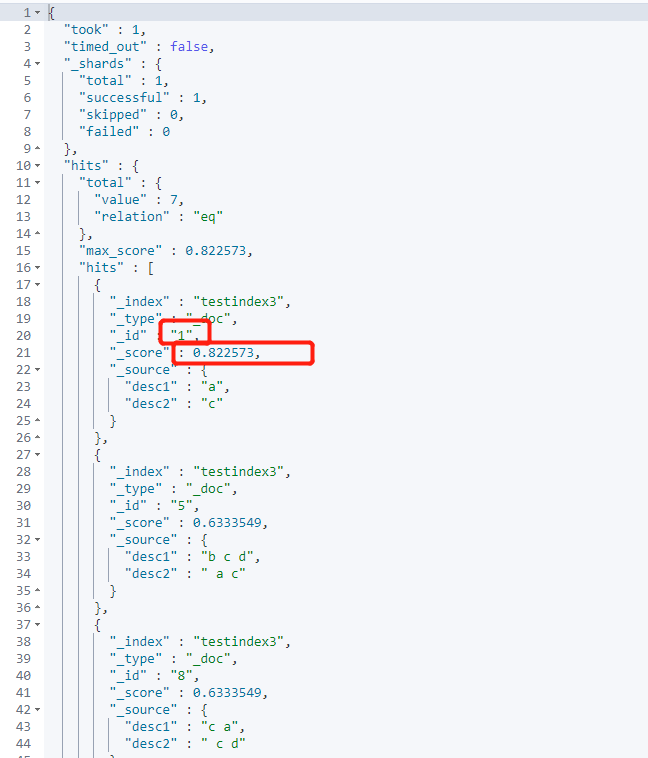
Lifting weight:
#best_fields
GET /testindex3/_search
{
"query": {
"multi_match": {
"query": "c",
"fields": ["desc1","desc2^3"],
"type": "best_fields",
"tie_breaker": 0
}
}
}
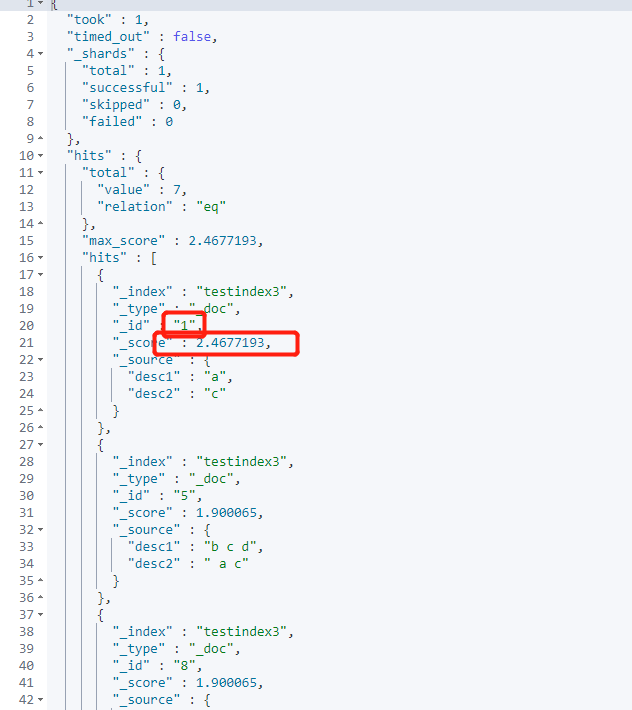
Visible scores have changed
most_fields
Find documents that match any field and combine the weights for each field
For best_ The file type is distinguished, and the comparison results of the two APIs are given
According to the ranking of the result score, two types can be distinguished. Because the designed data is imperfect, it is most_ Double the weight of desc2 in files to see the difference
If they are all best_ Even if you increase the weight of fields, the sorting result will not change, so increase most_ If the weight of fields changes, it can indicate the problem
#best_fields
GET /testindex3/_search
{
"query": {
"multi_match": {
"query": "c",
"fields": ["desc1","desc2"],
"type": "best_fields",
"tie_breaker": 0
}
}
}
#most_fields
GET /testindex3/_search
{
"query": {
"multi_match": {
"query": "c",
"fields": ["desc1","desc2^2"],
"type": "most_fields",
"tie_breaker": 0
}
}
}
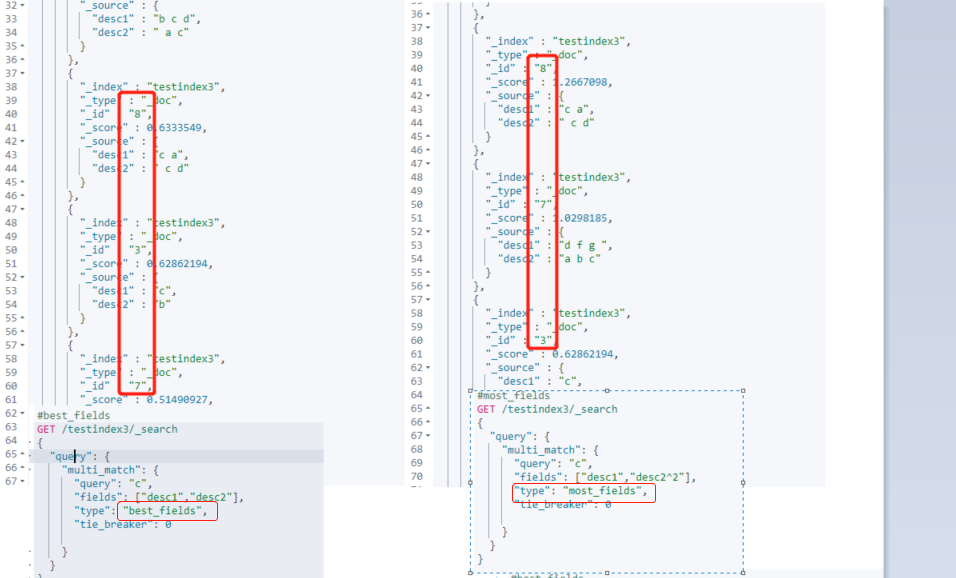
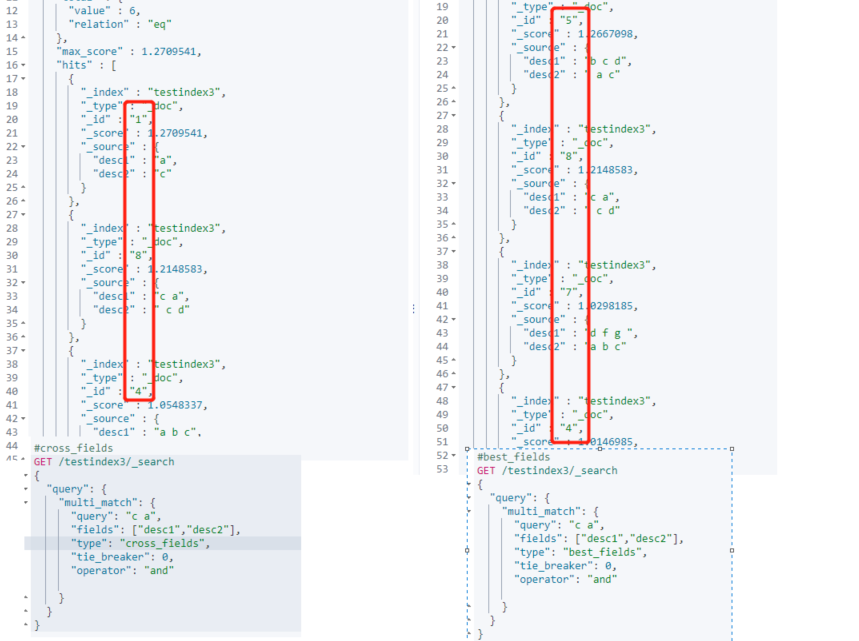
cross_fields
To make cross_fields queries work optimally. All fields must use the same analyzer. Fields with the same analyzer will be grouped together as mixed fields.
best_fields and most_fields is a field centric query
cross_fields is a word centric query
The obvious difference is that if opration is set to and, the two words in the field center must be in the field. The two words in the word center can be in any field
For comparison with field centric, use best_ Comparison of types of files with
#cross_fields
GET /testindex3/_search
{
"query": {
"multi_match": {
"query": "c a",
"fields": ["desc1","desc2"],
"type": "cross_fields",
"tie_breaker": 0,
"operator": "and"
}
}
}
#best_fields
GET /testindex3/_search
{
"query": {
"multi_match": {
"query": "c a",
"fields": ["desc1","desc2"],
"type": "best_fields",
"tie_breaker": 0,
"operator": "and"
}
}
}
5, Conclusion
Record the installation of ES and the basic syntax. For query and sharing
Specific practical functions need to be learned in production