IK word splitter is a word splitter about Chinese. If there is IK word splitter, naturally there are other word splitters. For example, pinyin word splitter is for pinyin word segmentation, and letter word segmentation is for letter word segmentation. A good way for ES is to expand these functions in the form of plug-ins.
Download and installation of an IK word splitter
In fact, the installation is very convenient. First, you should know what version your ELK is, and then search the corresponding version on the github address of the IK word splitter.
IK word splitter github address
The rest is how to download the corresponding version of IK word splitter. Quite simply, unzip the corresponding package to the plugins folder under the installation path of ElasticSearch. As shown in the figure:
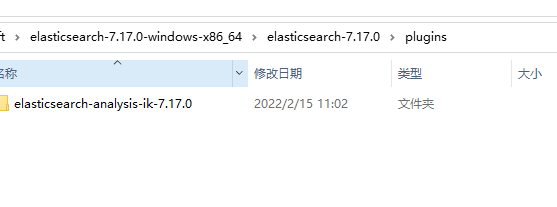
The last step is to restart ES, just like you install a new plug-in in idea. Generally, you will be prompted to restart idea. After successful restart, you can use the word splitter.
Check whether the word splitter is loaded. In addition to es startup, you can also check the loaded plug-ins through the elasticsearch plugin list under the bin directory.
II. Use and experience of IK word splitter
We have now installed kibana. Kibana itself can be used as a good visual plug-in. Our subsequent operations can be tested on kibana.
Open kibana's development tool
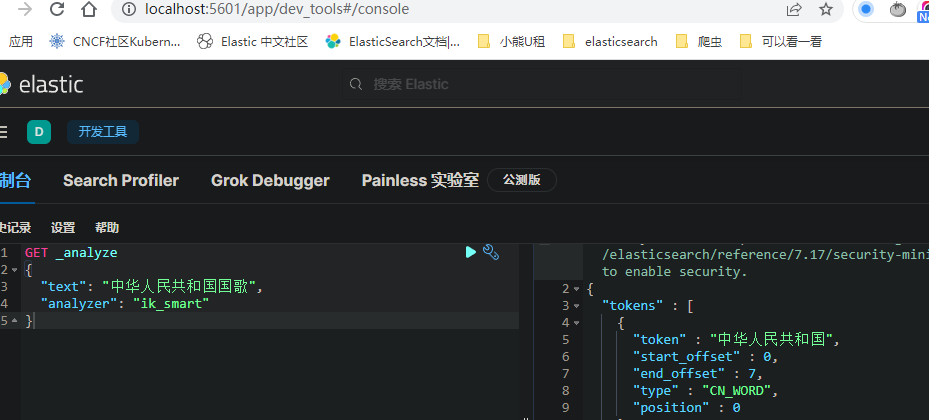
Here are two analyzers of ik word splitter: max is the most fine-grained, smart is the coarsest
ik_max_word will do the most fine-grained text
- For example, the "National Anthem of the people's Republic of China" will be divided into: the people's Republic of China, the people's Republic of China, the Chinese, the Chinese, the people's Republic, the people, the people, the Republic, the Republic, and the national anthem, and all possible combinations will be exhausted;
ik_ The coarsest granularity splitting of smart
- For example, the National Anthem of the people's Republic of China will be divided into: the National Anthem of the people's Republic of China and the national anthem.
Simple request
max maximizes the thinnest
GET _analyze
{
"text": "National Anthem of the people's Republic of China",
"analyzer": "ik_max_word"
}
return
{
"tokens" : [
{
"token" : "The People's Republic of China",
"start_offset" : 0,
"end_offset" : 7,
"type" : "CN_WORD",
"position" : 0
},
{
"token" : "Chinese people",
"start_offset" : 0,
"end_offset" : 4,
"type" : "CN_WORD",
"position" : 1
},
{
"token" : "the chinese people",
"start_offset" : 0,
"end_offset" : 2,
"type" : "CN_WORD",
"position" : 2
},
{
"token" : "Chinese",
"start_offset" : 1,
"end_offset" : 3,
"type" : "CN_WORD",
"position" : 3
},
{
"token" : "People's Republic of China",
"start_offset" : 2,
"end_offset" : 7,
"type" : "CN_WORD",
"position" : 4
},
{
"token" : "the people",
"start_offset" : 2,
"end_offset" : 4,
"type" : "CN_WORD",
"position" : 5
},
{
"token" : "republic",
"start_offset" : 4,
"end_offset" : 7,
"type" : "CN_WORD",
"position" : 6
},
{
"token" : "republic",
"start_offset" : 4,
"end_offset" : 6,
"type" : "CN_WORD",
"position" : 7
},
{
"token" : "country",
"start_offset" : 6,
"end_offset" : 7,
"type" : "CN_CHAR",
"position" : 8
},
{
"token" : "national anthem",
"start_offset" : 7,
"end_offset" : 9,
"type" : "CN_WORD",
"position" : 9
}
]
}
smart
GET _analyze
{
"text": "National Anthem of the people's Republic of China",
"analyzer": "ik_smart"
}
{
"tokens" : [
{
"token" : "The People's Republic of China",
"start_offset" : 0,
"end_offset" : 7,
"type" : "CN_WORD",
"position" : 0
},
{
"token" : "national anthem",
"start_offset" : 7,
"end_offset" : 9,
"type" : "CN_WORD",
"position" : 1
}
]
}
Sometimes the word splitter may not contain what we want. For example, I have a nickname. ZP is very handsome. I think these words should be a whole, but the word splitter is now disassembled and we need to add word segmentation settings ourselves.
For example, the configuration of IK word splitter is added as follows:
Find the configuration file of the word splitter first
IKAnalyzer.cfg.xml, and then add a Thesaurus (ext_dict is the added participle. I hope it can be used. ext_stopwords doesn't think it's necessary to separate the participle. For example, it's a modal particle that can't appear by waving others.)
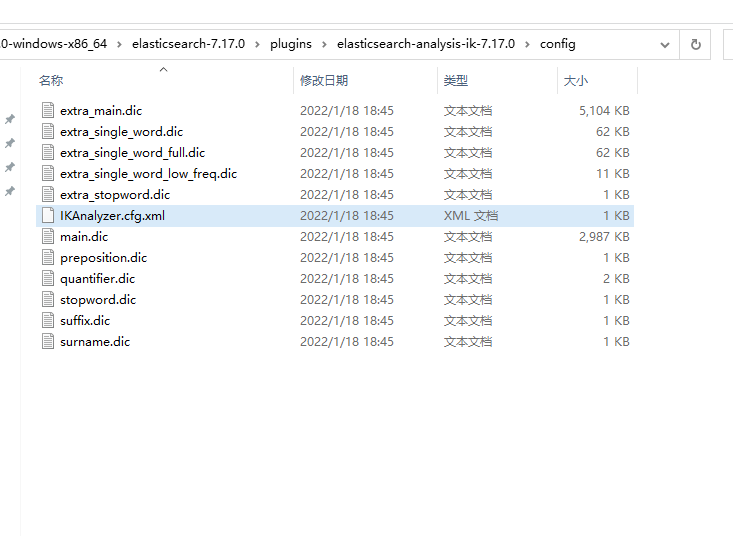
<?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd"> <properties> <comment>IK Analyzer Extended configuration</comment> <!--Users can configure their own extended dictionary here --> <entry key="ext_dict">zp.dic</entry> <!--Users can configure their own extended stop word dictionary here--> <entry key="ext_stopwords"></entry> <!--Users can configure the remote extension dictionary here --> <!-- <entry key="remote_ext_dict">words_location</entry> --> <!--Users can configure the remote extended stop word dictionary here--> <!-- <entry key="remote_ext_stopwords">words_location</entry> --> </properties>
Word segmentation practice
We need to build our own index and insert the experimental data
(1) Indexing
I build an index of zp
(2) Import data
PUT /zp
{
"mappings": {
"my_type": {
"properties": {
"text": {
"type": "text",
"analyzer": "ik_max_word"
}
}
}
}
}
POST /zp/my_type/_bulk
{ "index": { "_id": "1"} }
{ "text": "The man was still single when he was caught stealing tens of thousands of yuan red packets to make a girlfriend" }
{ "index": { "_id": "2"} }
{ "text": "16 The 22-year-old girl "changed" for marriage. After seven years, she wanted to divorce and was rejected by the court" }
{ "index": { "_id": "3"} }
{ "text": "Shenzhen girl was scared to cry when she was claimed for riding against Mercedes Benz(chart)" }
{ "index": { "_id": "4"} }
{ "text": "Women are better at skin care products than men's tickets? Netizen Shenjie" }
{ "index": { "_id": "5"} }
{ "text": "Why do domestic street signs use red and yellow matching?" }
GET /zp/my_type/_search
{
"query": {
"match": {
"text": "16 Is it better for a 20-year-old girl to get married or single?"
}
}
}
query
GET /zp/my_type/_search
{
"query": {
"match": {
"text": "16 Is it better for a 20-year-old girl to get married or single?"
}
}
}
Hit result:
{
"took" : 646,
"timed_out" : false,
"_shards" : {
"total" : 5,
"successful" : 5,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 5,
"relation" : "eq"
},
"max_score" : 1.941854,
"hits" : [
{
"_index" : "zp",
"_type" : "my_type",
"_id" : "2",
"_score" : 1.941854,
"_source" : {
"text" : "16 The 22-year-old girl "changed" for marriage. After seven years, she wanted to divorce and was rejected by the court"
}
},
{
"_index" : "zp",
"_type" : "my_type",
"_id" : "4",
"_score" : 0.8630463,
"_source" : {
"text" : "Women are better at skin care products than men's tickets? Netizen Shenjie"
}
},
{
"_index" : "zp",
"_type" : "my_type",
"_id" : "1",
"_score" : 0.8630463,
"_source" : {
"text" : "The man was still single when he was caught stealing tens of thousands of yuan red packets to make a girlfriend"
}
},
{
"_index" : "zp",
"_type" : "my_type",
"_id" : "5",
"_score" : 0.70134467,
"_source" : {
"text" : "Why do domestic street signs use red and yellow matching?"
}
},
{
"_index" : "zp",
"_type" : "my_type",
"_id" : "3",
"_score" : 0.685139,
"_source" : {
"text" : "Shenzhen girl was scared to cry when she was claimed for riding against Mercedes Benz(chart)"
}
}
]
}
}