RestClient query document
Video directions 👉 Station B dark horse micro service Super recommended!!
1. Quick start
We use match_ Take all query as an example:
1.1 initiate query request
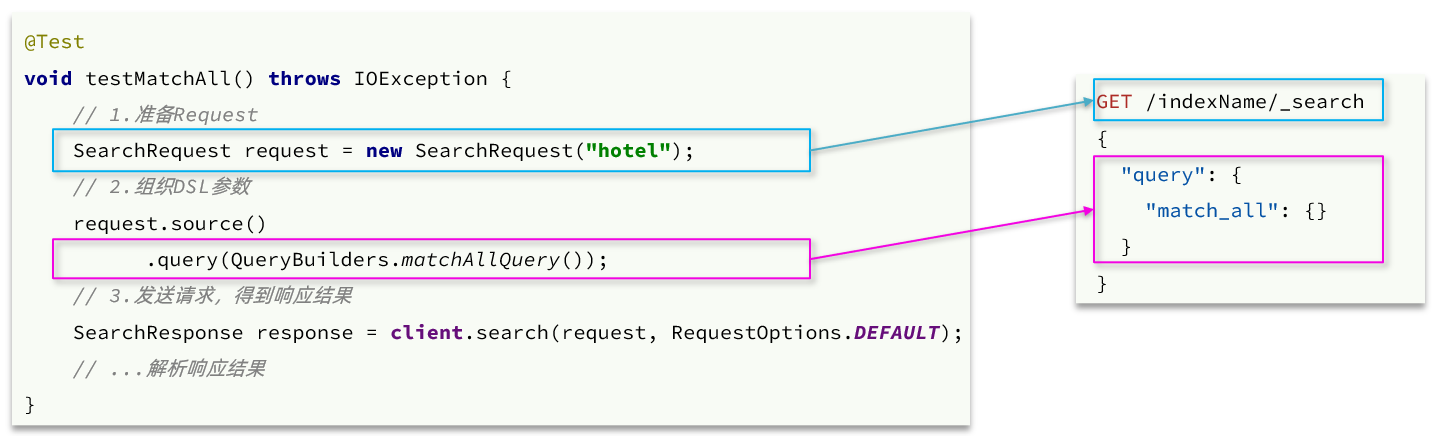
There are three steps:
- Create a SearchRequest object and specify the index library name
- Use request.source() to build DSL, which can include query, paging, sorting, highlighting, etc
- query(): represents the query criteria, and uses QueryBuilders.matchAllQuery() to build a match_ DSL for all queries
- Use client.search() to send the request and get the response
There are two key API s:
-
One is request.source(), which contains all functions such as query, sorting, paging and highlighting:
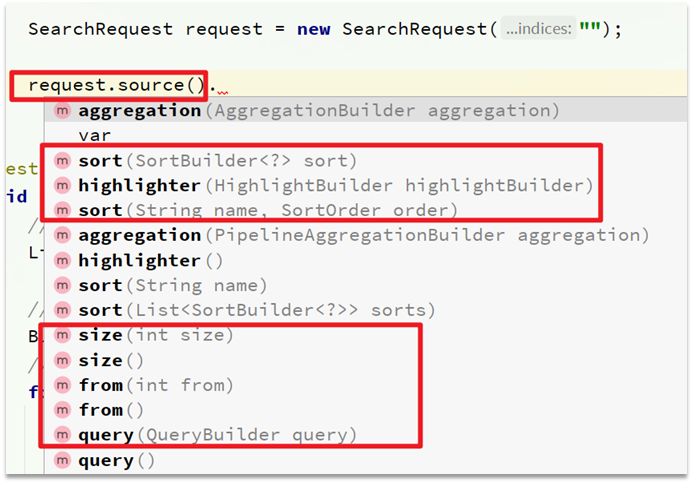
-
The other is QueryBuilders, which contains match, term and function_score, bool and other queries:

The code is as follows:
@Test
void testMatchAll() throws IOException {
// 1. Prepare Request
SearchRequest request = new SearchRequest("hotel");
// 2. Prepare DSL
request.source()
.query(QueryBuilders.matchAllQuery());
// 3. Send request
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
// 4. Parse response
handleResponse(response);
}
1.2 analytical response
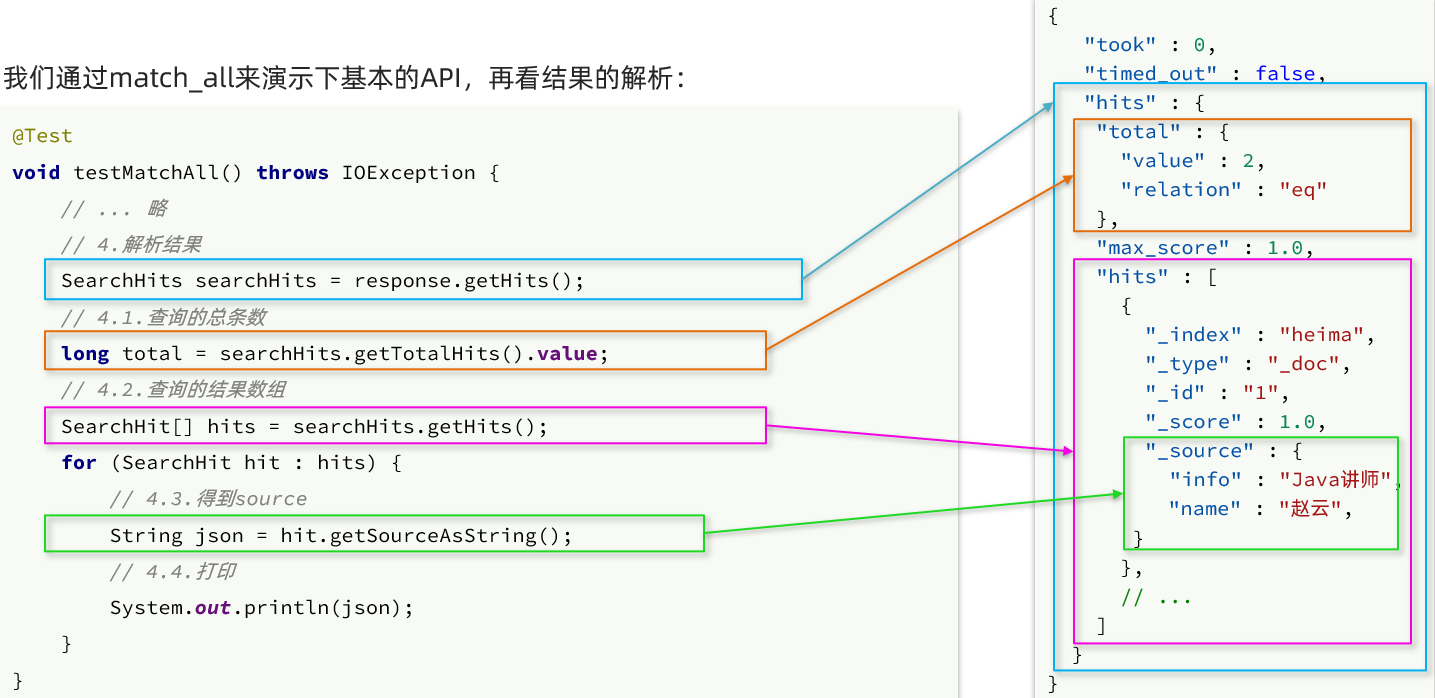
The result returned by Elasticsearch is a JSON string with the following structure:
- hits: hit results
- Total: total number of entries, where value is the specific total number of entries
- max_score: score the relevance of the document with the highest score in all results
- hits: an array of documents in search results, each of which is a json object
- _ source: the original data in the document, which is also a json object
Therefore, when we parse the response result, we parse the JSON string layer by layer. The process is as follows:
- SearchHits: obtained through response.getHits(), which is the outermost hits in json, representing the hit result
- SearchHits.getTotalHits().value: get the total number information
- SearchHits.getHits(): get the SearchHit array, that is, the document array
- SearchHit.getSourceAsString(): get the result in the document_ source, that is, the original json document data
The code is as follows:
private void handleResponse(SearchResponse response) {
// 4. Parse response
SearchHits searchHits = response.getHits();
// 4.1. Get the total number of entries
long total = searchHits.getTotalHits().value;
System.out.println("Total searched" + total + "Data bar");
// 4.2. Document array
SearchHit[] hits = searchHits.getHits();
// 4.3. Traversal
for (SearchHit hit : hits) {
// Get document source
String json = hit.getSourceAsString();
// Deserialization
HotelDoc hotelDoc = JSON.parseObject(json, HotelDoc.class);
System.out.println("hotelDoc = " + hotelDoc);
}
}
2.match query
Match and multi in full-text retrieval_ Match query and match_ The API of all is basically the same. The difference is the query criteria, that is, the query part:


The code is as follows:
@Test
void testMatch() throws IOException {
// 1. Prepare Request
SearchRequest request = new SearchRequest("hotel");
// 2. Prepare DSL
request.source()
.query(QueryBuilders.matchQuery("all", "Like home"));
// 3. Send request
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
// 4. Parse response
handleResponse(response);
}
3. Accurate query
Precise query mainly includes two aspects:
- Term: exact term matching
- Range: range query

4. Boolean query
Boolean query uses must, must_ Other queries are combined by not, filter, etc. the code example is as follows:
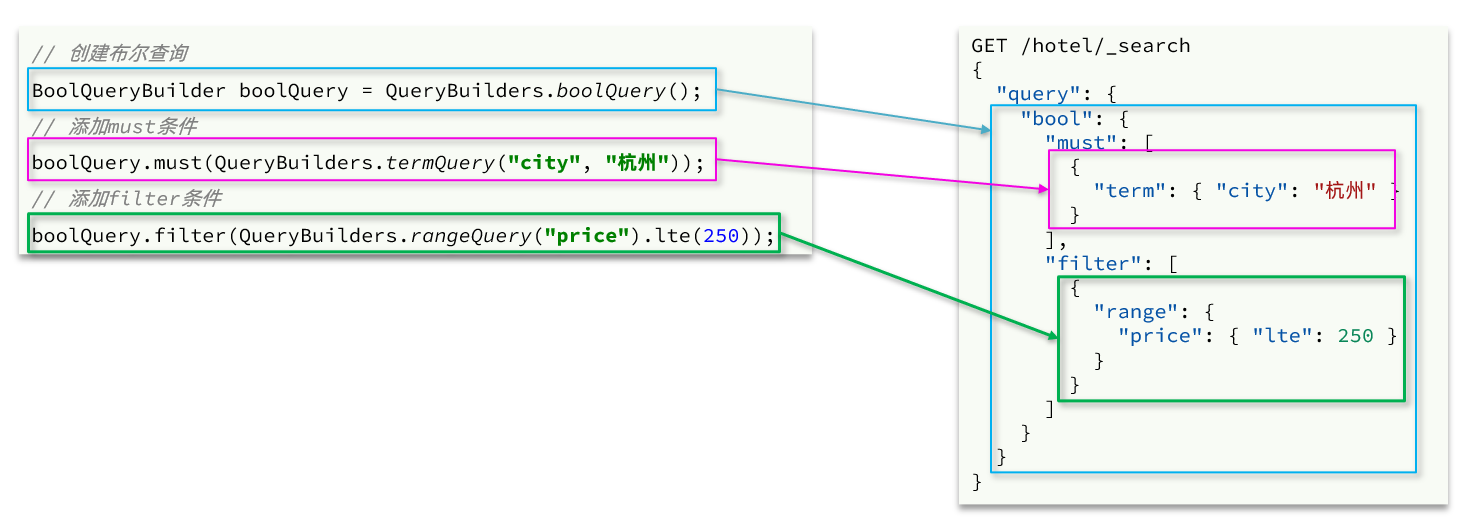
The code is as follows:
@Test
void testBool() throws IOException {
// 1. Prepare Request
SearchRequest request = new SearchRequest("hotel");
// 2. Prepare DSL
// 2.1. Prepare Boolean query
BoolQueryBuilder boolQuery = QueryBuilders.boolQuery();
// 2.2. Add term
boolQuery.must(QueryBuilders.termQuery("city", "Hangzhou"));
// 2.3. Add range
boolQuery.filter(QueryBuilders.rangeQuery("price").lte(250));
request.source().query(boolQuery);
// 3. Send request
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
// 4. Parse response
handleResponse(response);
}
5. Sorting and pagination
The sorting and paging of search results are parameters at the same level as query, so request.source() is also used to set.
The corresponding API is as follows:

The code is as follows:
@Test
void testPageAndSort() throws IOException {
// Page number, size of each page
int page = 1, size = 5;
// 1. Prepare Request
SearchRequest request = new SearchRequest("hotel");
// 2. Prepare DSL
// 2.1.query
request.source().query(QueryBuilders.matchAllQuery());
// 2.2. sort
request.source().sort("price", SortOrder.ASC);
// 2.3. Paging from, size
request.source().from((page - 1) * size).size(5);
// 3. Send request
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
// 4. Parse response
handleResponse(response);
}
6. Highlight
The highlighted code is quite different from the previous code, with two points:
- DSL of query: in addition to query criteria, highlight criteria also need to be added, which is the same level as query.
- Result parsing: the result should be parsed_ source document data, and analyze the highlighted results
6.1 highlight request build
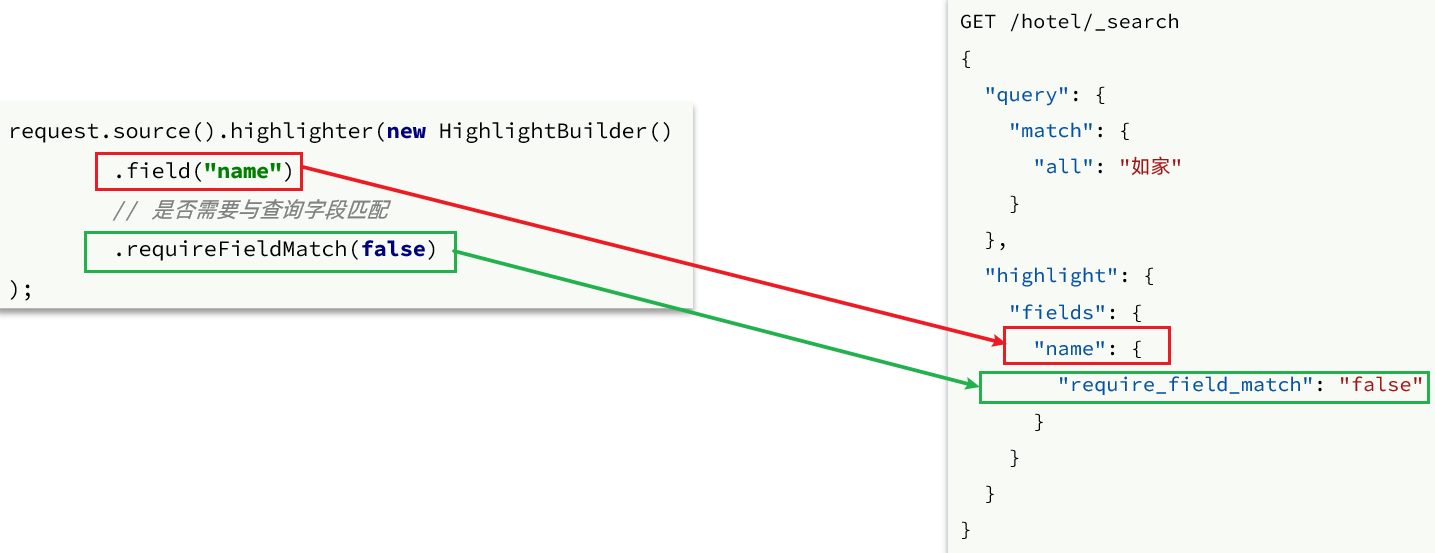
The above code omits the query criteria, but don't forget: the highlighted query must use full-text search query, and there must be search keywords, so that the keywords can be highlighted in the future.
The code is as follows:
@Test
void testHighlight() throws IOException {
// 1. Prepare Request
SearchRequest request = new SearchRequest("hotel");
// 2. Prepare DSL
// 2.1.query
request.source().query(QueryBuilders.matchQuery("all", "Like home"));
// 2.2. Highlight
request.source().highlighter(new HighlightBuilder().field("name").requireFieldMatch(false));
// 3. Send request
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
// 4. Parse response
handleResponse(response);
}
6.2 highlight result analysis
The highlighted results are separated from the query document results by default.
Therefore, parsing the highlighted code requires additional processing:

Code interpretation:
- Step 1: get the source from the result. hit.getSourceAsString(), which is a non highlighted result, json string. You also need to inverse sequence the HotelDoc object
- Step 2: get the highlight result. hit.getHighlightFields(), the return value is a Map, the key is the name of the highlighted field, and the value is the HighlightField object, representing the highlighted value
- Step 3: get the highlighted field value object HighlightField from the map according to the highlighted field name
- Step 4: get Fragments from the HighlightField and convert them into strings. This part is the real highlighted string
- Step 5: replace the non highlighted results in HotelDoc with the highlighted results
The code is as follows:
private void handleResponse(SearchResponse response) {
// 4. Parse response
SearchHits searchHits = response.getHits();
// 4.1. Get the total number of entries
long total = searchHits.getTotalHits().value;
System.out.println("Total searched" + total + "Data bar");
// 4.2. Document array
SearchHit[] hits = searchHits.getHits();
// 4.3. Traversal
for (SearchHit hit : hits) {
// Get document source
String json = hit.getSourceAsString();
// Deserialization
HotelDoc hotelDoc = JSON.parseObject(json, HotelDoc.class);
// Get highlighted results
Map<String, HighlightField> highlightFields = hit.getHighlightFields();
if (!CollectionUtils.isEmpty(highlightFields)) {
// Get highlighted results based on field names
HighlightField highlightField = highlightFields.get("name");
if (highlightField != null) {
// Get highlight value
String name = highlightField.getFragments()[0].string();
// Overwrite non highlighted results
hotelDoc.setName(name);
}
}
System.out.println("hotelDoc = " + hotelDoc);
}
}

Last favorite little partner, remember the third company! 😏🍭😘