1, Foreword
1. What is RestFul?
-
REST: representational state transfer. If an architecture conforms to the REST principle, it is called RESTful architecture style.
-
Resource: the so-called "resource" is an entity on the network, or a specific information on the network.
-
Presentation layer: the form in which we present "resources" is called its "Representation".
-
State transfer: if the client wants to operate the server, it must use some means to make the server "state transfer". This transformation is based on the presentation layer, so it is "presentation layer state transformation".
-
REST principles:
1. A URL represents a unique resource. Traditional URLs, such as: http://localhost:8989/user/findOne?id=21 , here? Id = 21 is not a part of the URL, but a parameter carried. ahead http://localhost:8989/user/findOne Does not represent a unique resource.
2. The four verbs in the HTTP protocol: GET, POST, PUT and DELETE correspond to four basic server-side operations: GET is used to query resources, POST is used to add resources (or update resources), PUT is used to update or add resources, and DELETE is used to DELETE resources.
2. What is full-text retrieval?
Full text retrieval is a computer program that scans each word in the article and establishes an index for each word to indicate the number and location of the word in the article. When the user queries, it is searched according to the established index, which is similar to the process of looking up words through the dictionary search word table.
Search: Search (establish index) check: (search index)
Full text retrieval takes the text as the search object to find the text containing the specified vocabulary. Comprehensive, accurate and fast is the key index to measure the full-text retrieval system.
For full-text retrieval, we should know:
- Only text is processed.
- Do not process semantics.
- English is not case sensitive when searching.
- The result list has relevance ranking.
3. What is ElasticSearch?
(1) Concept
ElasticSearch (es for short) is an open source search engine based on Apache Lucene. It is a popular enterprise search engine. Lucene itself can be regarded as an open source search engine toolkit with the best performance so far, but Lucene's API is relatively complex and requires deep search theory. It is difficult to integrate into practical applications. However, ES is written in java language and provides a simple and easy-to-use RestFul API. Developers can use its simple RestFul API to develop relevant search functions, so as to avoid the complexity of Lucene.
(2) Application scenario of ES
ES mainly uses lightweight JSON as the data storage format, which is somewhat similar to MongoDB, but it is better than MongoDB in read-write performance. At the same time, it also supports geographic location query and facilitates geographic location and text hybrid query. And is a leader in statistics, log data storage, analysis and visualization.
Abroad: Wikipedia uses ES to provide full-text search and highlight keywords, StackOverflow(IT Q & a website) combines full-text search and geographic location query, and Github uses Elasticsearch to retrieve 130 billion lines of code.
Domestic: Baidu (applies ES to cloud analysis, online alliance, prediction, library, wallet, risk control and other businesses. A single cluster imports 30TB + data every day, a total of 60TB + every day), Sina, Alibaba, Tencent and other companies all use ES.
ELK(ElasticSearch, Logstash, Kibana) is a widely used platform.
2, ElasticSearch installation [centos7 environment]
1. Installation
Environment required for this installation
centos7 +
java 8 +
elasticserch 6.8.0 +
(1)JDK installation:
For detailed installation steps, refer to: Installing JDK for Linux
(2)ElasticSearch installation
Note: ES cannot be installed as root user, and ordinary user must be created
# a. Create a new group in linux system groupadd es # b. Create a new user es and put the ES user into the ES group useradd es -g es # c. Modify es user password passwd es
Then log in to the virtual machine as es user to view the current user identity:
who am i
Now we officially enter the installation phase.
1. Unzip elasticsearch
tar -zxvf elasticsearch-6.8.0.tar.gz
2. Enter the bin directory and start the ES service
./elasticsearch
The following figure shows a red log indicating successful startup:

3. Test
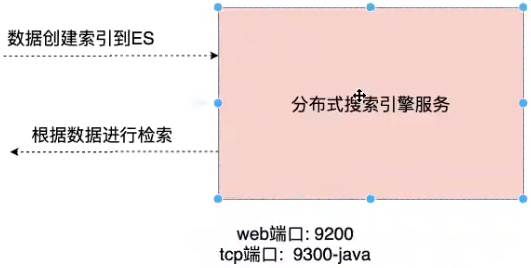
es provides two interfaces, one is the port directly accessed by the web, and the other is the interface that can be called by java and other programs. Here, we use 9200 interface for testing.
Q: Why can't I access it with a browser?
A: After es is started, no remote connection is provided and only local access is available.
Q: Why do I start es on only one machine and display cluster related information?
A: In es, a machine is also a cluster.
curl is a command used in Linux to simulate a browser sending a request
curl http://localhost:9200
If the following figure appears, it indicates success.
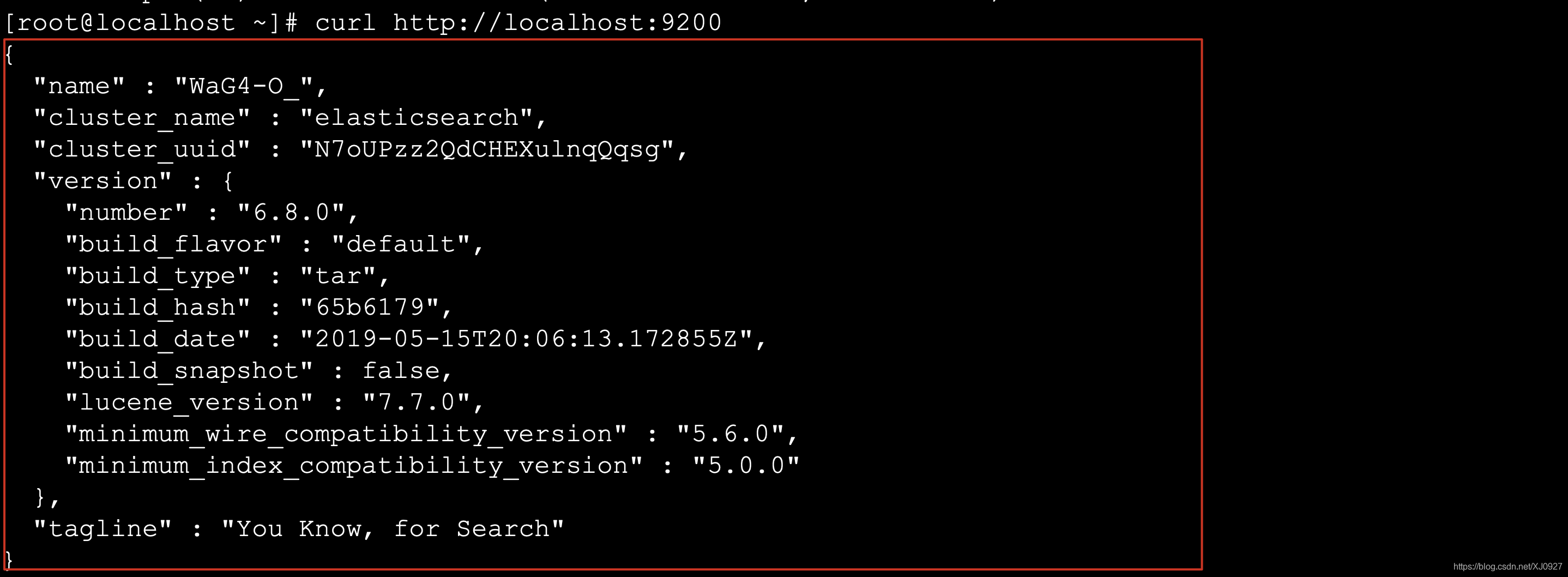
At this point, ElasticSearch installation is basically completed!
2. Enable remote connection permission
Note: the ES service is protected by default. Only local clients are allowed to connect. If you want to access through remote clients, you must open the remote connection
(1) Enable ES remote access
vim elasticsearch.yml network.host: 0.0.0.0 #Modify the original network to this configuration
(2) Restart ES service
./elasticsearch
The following error occurred when restarting es:

(3) Resolve errors
Error 1 resolution:
Use the root user to modify the system configuration
vim /etc/security/limits.conf
Add the following content on the last side (note that the asterisk should be written in the top box)
* soft nofile 65536 * hard nofile 65536 * soft nproc 4096 * hard nproc 4096
Check whether the configuration is effective after logging in again
ulimit -Hn ulimit -Sn ulimit -Hu ulimit -Su
Error 2 resolution:
Use the root user to modify the system configuration
vim /etc/security/limits.d/20-nproc.conf
Change the red circle name to the normal user name for starting es.

Error 3 resolution:
Use the root user to modify the system configuration
vim /etc/sysctl.conf # Add at the end vm.max_map_count=655360 # Execute the following command to check whether it is effective sysctl -p
(4) Reconnect and start the service
It is found that es can start normally
./elasticsearch
(5) Test remote access
It can be accessed using a browser

3, ElasticSearch basic concepts
(1) Near real time (NRT)
Elasticsearch is a near real-time search platform. This means that there is a slight delay (usually within 1 second) from indexing a document until the document can be searched
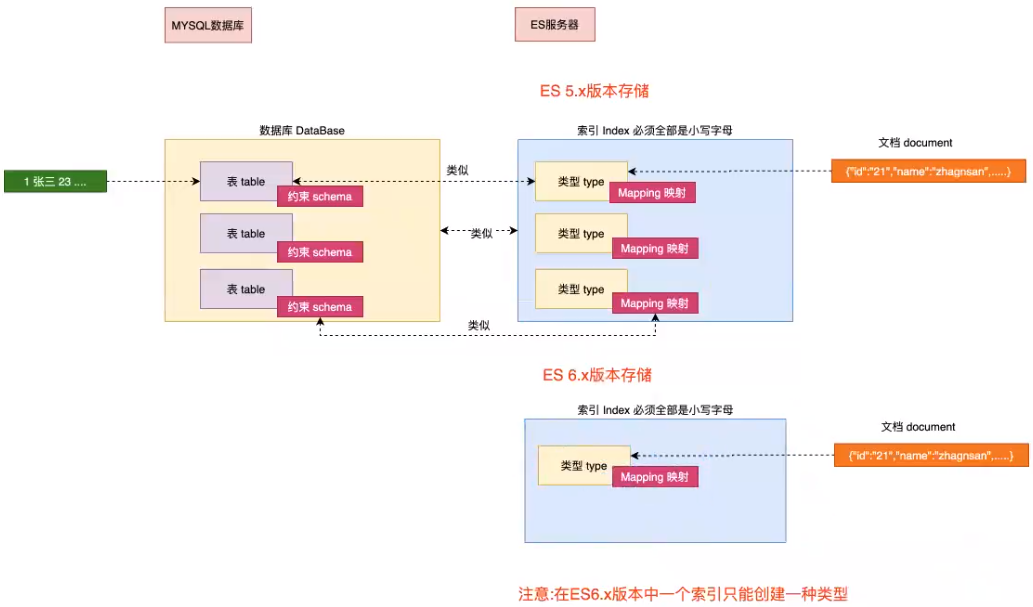
(2) Index
An index is a collection of documents with somewhat similar characteristics. For example, you can have an index of customer data, another index of product catalog, and an index of order data. An index is identified by a name (which must be all lowercase letters), and we should use this name when we want to index, search, update and delete the documents in this index. Index is similar to the concept of Database in relational Database. In a cluster, you can define as many indexes as you want.
(3) Type
In an index, you can define one or more types. A type is a logical classification / partition of your index, and its semantics is entirely up to you. Typically, a type is defined for a document that has a common set of fields. For example, let's say you run a blog platform and store all your data in an index. In this index, you can define one type for user data, another type for blog data, and of course, another type for comment data. Type is similar to the concept of Table in relational database.
NOTE: in 5 Before version x, multiple types can be defined in one index, 6 Versions after X can also be used, but it is not recommended. It is in 7 ~ 8 X version completely removes the creation of multiple types in an index
(4) Mapping
Mapping is a very important content in ES. It is similar to the schema of table in traditional relational data. It is used to define the structure of type data in an index. In ES, we can manually create type (equivalent to table) and mapping (related to schema), or use the default creation method. In the default configuration, ES can automatically create types and their mapping based on the inserted data. Mapping mainly includes field name, field data type and field index type.
(5) Document
A document is a basic unit of information that can be indexed, similar to a record in a table. For example, you can have a document of an employee or a document of a product. The document is represented by JSON(Javascript Object Notation), a lightweight data exchange format.
(6) Conceptual diagram
4, Kibana installation [centos7 environment]
1. What is kibana?
Kibana is an open source analysis and visualization platform for Elasticsearch. Kibana can query, view and interact with the data stored in ES index. Kibana can perform advanced data analysis and view data in the form of charts, tables and maps.
2. Install Kibana
The version of kibana must correspond to the version of ElasticSearch!
Official website download address: https://www.elastic.co/cn/downloads/kibana
(1) After downloading Kibana successfully, install it
rpm -ivh kibana-6.8.0-x86_64.rpm
(2) Edit profile
cd kibana-6.8.0-linux-x86_64/config vim kibana.yml
Modify to the following configuration:
# Find it and modify it to the following configuration server.host: "192.168.40.151" # ES server host address elasticsearch.hosts: ["http://192.168.40.151:9200 "] # es server address
(3) Start kibana
If you installed through rpm as in this article, enter the following code to start.
systemctl start kibana
(4) Visit kibana
5601 is the default port of kibana, which can be accessed by browser http://192.168.40.151:5601 You can view the kibana interface.
5, Index, type mapping, document operation
In the last step, we installed kibana. We can directly operate ElasticSearch using kibana client.
1. Index operation
# Create index PUT /dangdang/ # Delete index DELETE /dangdang # Delete all indexes [caution: ElasticSearch will bring two indexes. If kibana is deleted, the client cannot use it. It can only be used after kibana is restarted] DELETE /* # View index information GET /_cat/indices # View index information and header information GET /_cat/indices?v
2. Type operation
Note: creating a type in this way requires that the index cannot exist
# Create / book index and create (musicbook) type
PUT /book
{
"mappings": {
"musicbook": {
"properties": {
"name":{
"type":"keyword"
},
"price":{
"type":"double"
},
"desc":{
"type":"text"
}
}
}
}
}
# grammar
GET /Index name/_mapping
# such as
GET /book/_mapping
/book: the name of the index we created
"mappimgs": mapping, fixed writing method, that is to restrict the data structure of types, so that there will be constraints when adding documents
"musicbook": that is, the type name. After ES6, it is recommended to create a type with an index
"properties": attribute, fixed writing method, which adds the attribute to be created by the type
"Name"... Etc.: attribute name
"Type": fixed writing method, constraint type. Different types can be written according to different attributes
Mapping Type: text , keyword , date ,integer, long , double , boolean or ip
3. Document operation
(1) Add, delete, modify and query
# Add document syntax: PUT / index / type / id
# If you do not specify an ID, ES generates one by default_ ID, which is used for subsequent operation documents_ id.
# This is why the id attribute is generally not added when adding an attribute to a type.
PUT /book/musicbook/1
{
"name":"Music book",
"price":"22.0",
"desc":"This is a music book"
}
Return result:
{
"_index" : "book",
"_type" : "musicBook",
"_id" : "1",
"_version" : 3,
"result" : "created",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 2,
"_primary_term" : 1
}
# Query document syntax: GET / index / type / id
GET /book/musicbook/1
Return result:
{
"_index" : "book",
"_type" : "musicBook",
"_id" : "1",
"_version" : 3,
"_seq_no" : 2,
"_primary_term" : 1,
"found" : true,
"_source" : {
"name" : "Music book",
"price" : "22.0",
"desc" : "This is a music book"
}
}
# DELETE document syntax: DELETE / index / type / id
DELETE /book/musicbook/1
Return result:
{
"_index" : "book",
"_type" : "musicBook",
"_id" : "1",
"_version" : 4,
"result" : "deleted",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 3,
"_primary_term" : 1
}
#Update document
# Wrong way
POST /book/musicbook/1
{
"name":"Zhang San"
}
# After viewing the document, it is found that the original attribute information is overwritten, and only the newly updated attribute information is available
{
"_index" : "book",
"_type" : "musicBook",
"_id" : "1",
"_version" : 2,
"_seq_no" : 5,
"_primary_term" : 1,
"found" : true,
"_source" : {
"name" : "Zhang San"
}
}
# Correct way: use keywords_ update
POST /Indexes/type/id/_update
{
"doc":{
"Attribute name":"value"
}
}
# Method 1: update based on the original data
POST /book/musicbook/1/_update
{
"doc": {
"price":"40"
}
}
# The second way: add new constraint data
In this way, type did not color Property, but when you add it, ES Will match you accordingly
POST /book/musicbook/1/_update
{
"doc": {
"color":"gules"
}
}
# The third method: update according to the script [understand]
POST /book/musicbook/1/_update
{
"script": "ctx._source.price += 5.0"
}
(2) Batch operation
Sometimes, you want to add documents, delete documents, modify documents and index documents at the same time, and use keywords_ bulk.
Note: the so-called batch operation simply means that if you want to delete, you use the keyword "delete". If you want to modify, you use the keyword "update". In batch operation, you will not fail all because of one failure, but continue to perform subsequent operations. When returning in batch, you will start to return according to the execution status.
# Index two documents simultaneously
PUT /book/musicbook/_bulk
{"index":{"_id": "3"}}
{ "name":"Fairy tale book", "price":"21","des":"This is a fairy tale book"}
{"index":{"_id": "4"}}
{"name":"Adventure Book","price":"24","desc":"This is an adventure book"}
# Modify and delete documents at the same time
PUT /book/musicbook/_bulk
{"update":{"_id":"3"}}
{"doc":{"name":"Revised fairy tale book"}}
{"delete":{"_id":"4"}}
6, Advanced retrieval in ES
Es officially provides two retrieval methods: one is to search through URL parameters, and the other is to search through DSL(Domain Specified Language). Officials prefer the second method. Because the second method is based on passing JSON as the request body format to interact with ES, this method is more powerful and concise.

Syntax:
URL query: GET / index / type/_ search? parameter
DSL query: GET / index / type/_ search {}
The first one is less used, so you can understand it!
test data
# 1. Delete index
DELETE /ems
# 2. Create an index and specify the type
PUT /ems
{
"mappings":{
"emp":{
"properties":{
"name":{
"type":"text"
},
"age":{
"type":"integer"
},
"bir":{
"type":"date"
},
"content":{
"type":"text"
},
"address":{
"type":"keyword"
}
}
}
}
}
# 3. Insert test data
PUT /ems/emp/_bulk
{"index":{}}
{"name":"Xiao Hei","age":23,"bir":"2012-12-12","content":"Choose an excellent model for the development team MVC The framework is difficult, and it requires a high level of experience and level to choose among many feasible schemes","address":"Beijing"}
{"index":{}}
{"name":"Wang Xiaohei","age":24,"bir":"2012-12-12","content":"Spring The framework is a layered architecture composed of seven well-defined modules. Spring The module is built on the core container, which defines creation, configuration and management bean The way","address":"Shanghai"}
{"index":{}}
{"name":"Xiao Wu Zhang","age":8,"bir":"2012-12-12","content":"Spring Cloud As Java Language microservice framework, which depends on Spring Boot,It has the characteristics of rapid development, continuous delivery and easy deployment. Spring Cloud There are many components, involving all aspects of micro services, well in the open source community Spring and Netflix ,Pivotal Driven by the two companies, it is becoming more and more perfect","address":"Wuxi"}
{"index":{}}
{"name":"win7","age":9,"bir":"2012-12-12","content":"Spring Our goal is to simplify everything Java development. This is bound to lead to more explanations, Spring How is it simplified Java Developed?","address":"Nanjing"}
{"index":{}}
{"name":"Mei Chaofeng","age":43,"bir":"2012-12-12","content":"Redis Is an open source use ANSI C Language, network support, memory based and persistent log type Key-Value Database, and provide multilingual API","address":"Hangzhou"}
{"index":{}}
{"name":"zhang wuji","age":59,"bir":"2012-12-12","content":"ElasticSearch Is based on Lucene Search server for. It provides a distributed multi-user capable full-text search engine based on RESTful web Interface","address":"Beijing"}
1.URL retrieval
NOTE: understanding is enough to help you better understand DSL
GET /ems/emp/_search?q=*&sort=age:desc&size=5&from=0&_source=name,age,bir
_ search: search API
q = *: match all documents
sort=age: sort by the specified field. The default is ascending and desc is descending
size: how many pieces of data are displayed
from: show page
_ source: which fields match only
2.DSL retrieval
(1) Query all (match_all)
match_all keyword: returns all documents in the index
GET /ems/emp/_search
{
"query": {
"match_all": {}
}
}
(2) Returns the specified number (size) in the query result
size keyword: Specifies the number of returned items in the query result. The default return value is 10, which is used to process the query results.
GET /ems/emp/_search
{
"query": {
"match_all": {}
},
"size": 5
}
(3) Paging query (from)
from keyword: used to specify the starting return position. It can be used in conjunction with the size keyword to achieve paging effect
GET /ems/emp/_search
{
"query": {
"match_all": {}
},
"size": 5,
"from": 0
}
(4) Returns the specified field (_source) in the query result
_ source keyword: an array used to specify which fields to display
# Show individual fields
GET /ems/emp/_search
{
"query": {
"match_all": {}
},
"_source": "name"
}
# Show multiple fields
GET /ems/emp/_search
{
"query": {
"match_all": {}
},
"_source": ["name","age"]
}
(5) Keyword query (term)
term keyword: used to query with keywords
# Name is a text type and word segmentation is performed, so any document with "Zhang" in name is OK
GET /ems/emp/_search
{
"query": {
"term": {
"name": {
"value": "Zhang"
}
}
}
}
# bir is of date type, and word segmentation is not performed. Therefore, according to the overall query, no data can be found
GET /ems/emp/_search
{
"query": {
"term": {
"bir": {
"value": "2012-12"
}
}
}
}
Summary:
NOTE1:
By using the term query, we know that the default word splitter in ES is standard analyzer, which is used for English word segmentation and Chinese single word segmentation.
NOTE2:
By using the term query, we know that in the Mapping Type of ES, keyword, date,integer, long,double, boolean or ip do not have word segmentation, but only text type word segmentation.