brief introduction
Official documents: https://www.elastic.co/guide/en/elasticsearch/reference/7.x/analysis.html
A tokenizer receives a character stream, divides it into independent tokens (word elements, usually independent words), and then outputs the tokens stream.
For example: whitespace tokenizer splits text when it encounters white space characters. It will put the text "Quick brown fox!" Split into [Quick,brown,fox!].
The tokenizer is also responsible for recording the order or position position position of each term (for phrase and word proximity query), and the character offsets of the start and end of the original word represented by term (for highlighting the content of the search).
elasticsearch provides many built-in word splitters that can be used to build custom analyzers.
POST _analyze
{
"analyzer": "standard",
"text": "The 2 QUICK Brown-Foxes jumped over the lazy dog's bone."
}
The default word splitter is generally for English. For Chinese, we need to install additional word splitter for word segmentation.
Install IK word breaker
Preparation in advance:
IK word splitter belongs to Elasticsearch plug-in, so the installation directory of IK word splitter is Elasticsearch plugins directory. When we start Elasticsearch with Docker, this directory has been mounted to / mydata/elasticsearch/plugins directory of the host.
The version of IK word splitter needs to correspond to the version of Elasticsearch. The currently selected version is 7.4.2, and the download address is: Github Release Or visit: Mirror Address
1. Download
# Enter the installed plug-in directory / mydata/elasticsearch/plugins cd /mydata/elasticsearch/plugins # Install wget download tool (if installed, skip) yum install -y wget # Download the corresponding version of IK word breaker (here is 7.4.2) wget https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.4.2/elasticsearch-analysis-ik-7.4.2.zip
The IK word breaker has been installed in the plugins directory of the mount. Now let's go inside the es container and check whether the installation is successful
# Enter the inside of the container docker exec -it elasticsearch /bin/bash # View es plug-in directory ls /usr/share/elasticsearch/plugins # You can see elastic search-analysis-ik-7.4.2 zip
Therefore, we only need to operate in the mounted directory / mydata/elasticsearch/plugins.
2. Decompression
# Enter the plug-in directory of es cd /mydata/elasticsearch/plugins # Unzip it to the ik directory under the plugins directory unzip elasticsearch-analysis-ik-7.4.2.zip -d ik # Delete downloaded packages rm -f elasticsearch-analysis-ik-7.4.2.zip # Modify folder access chmod -R 777 ik/
3. Check the installed ik plug-ins
# Enter es container docker exec -it elasticsearch /bin/bash # Enter the es bin directory cd /usr/share/elasticsearch/bin # Execute the view command to display ik elasticsearch-plugin list # Exit container exit # Restart Elasticsearch docker restart elasticsearch
4. Test ik word splitter
Intelligent word segmentation
GET _analyze
{
"analyzer": "ik_smart",
"text": "I am Chinese,"
}

Maximum participle
GET _analyze
{
"analyzer": "ik_max_word",
"text": "I am Chinese,"
}

Custom extended Thesaurus
For some relatively new words, ik word segmentation is not supported, so we need to customize the thesaurus
We customize the word segmentation file in nginx and remotely call the word segmentation file in nginx by configuring the ik configuration file of es to realize the custom extended thesaurus.
Note: by default, nginx requests the html static directory of the data directory
nginx installation reference: docker installation nginx
1. Custom word segmentation file in nginx
echo "Shang Silicon Valley" > /mydata/nginx/html/fenci.txt
The default request address of nginx is IP: port / fenci txt;
If you want to add a new word, just add a new line to the file and save the new word.
2. Configure custom thesaurus for es
# 1. Open and edit the ik plug-in configuration file vim /mydata/elasticsearch/plugins/ik/config/IKAnalyzer.cfg.xml
Open the comments on this line and configure your own word segmentation dictionary
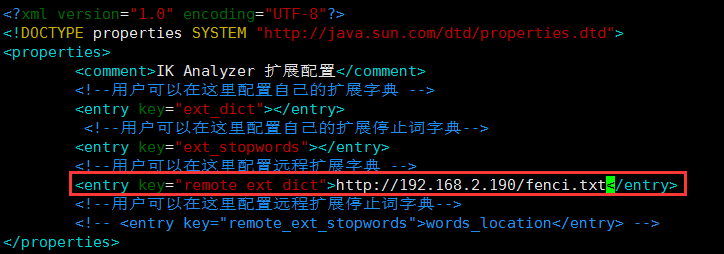
3. Restart the elasticsearch container
docker restart elasticsearch
4. Test custom Thesaurus
GET _analyze
{
"analyzer": "ik_smart",
"text": "Shang Silicon Valley"
}
result:

Docker installation Nginx
Here is how to install nginx using docker. First, we start a temporary nginx, copy its configuration to the local nginx configuration directory we will mount, and then create a new nginx container we want to use.
1. Create configuration directory
mkdir -p /mydata/nginx
2. Start the temporary nginx container
docker run -p 80:80 --name nginx -d nginx:1.10
3. Copy the configuration of the Nginx container
# Enter the mounted nginx directory cd /mydata/nginx # Copy the configuration file in the container to the nginx directory # The structure after modification is as follows: / mydata/nginx/nginx / Other documents docker container cp nginx:/etc/nginx . # Rename the copied nginx folder conf # Final effect: / mydata/nginx/conf / Other documents mv nginx conf
4. Delete temporary nginx container
# Stop running nginx container docker stop nginx # Delete nginx container docker rm nginx
5. Start nginx container
docker run -p 80:80 --name nginx \ -v /mydata/nginx/html:/usr/share/nginx/html \ -v /mydata/nginx/logs:/var/log/nginx \ -v /mydata/nginx/conf/:/etc/nginx \ -d nginx:1.10
6. Set nginx to start with Docker
docker update nginx --restart=always
7. Test nginx
echo '<h1><a target="_blank" href="https://gitee.com/UnityAlvin/gulimall">gulimall</a></h1>' \ >/mydata/nginx/html/index.html
Visit: your virtual machine ip can see the following content, indicating that the installation is successful