brief introduction
An open source search engine based on Apache Lucene(TM). Due to the complexity of using Lucene, ElasticSearch aims to make full-text search simple through RESTful API.
Basic concepts
1. Near real time NRT
When full-text search is not true, there is usually a delay. Different search engines have a core search delay time. The general delay time of ES is 1s.
2. Distributed cluster
-
Capacity expansion is improved by managing multiple nodes. Multiple nodes use one name, which is a cluster managed by ES.
-
A running ES instance is called a node. A cluster is composed of nodes with the same name (i.e. cluster.name) to jointly process data and load balance.
3. Documentation
-
Concretely speaking, a document is a JSON representation of a sequence of objects. Objects that are serialized into JSON can be called documents. Many documents form an index.
-
It refers to the topmost or root object. This root object is serialized into {JSON} and stored in {Elasticsearch} with a unique} ID specified.
-
ES is a distributed document storage. It actually serializes complex objects into JSON, then stores JSON documents and realizes real-time search.
4. Node
Store data (corresponding to a server). Each node is identified by a name. It is not specified that a random name will be given when the node is started. The node can be identified by configuring the cluster name cluster Name to join the cluster. If there is no cluster, the node will create a cluster named "elasticsearch" and join the default cluster.
5. Master node
-
It is responsible for managing changes in the cluster, adding and deleting indexes or adding and deleting nodes. The master node does not perform document level changes and searches.
-
The user can add the request to any node in the cluster. The node will forward the request to the node that actually needs the request, and finally put the data back to the user.
6. Index
-
An index is a collection of documents with similar characteristics. It is not required that the document structure under an index is the same, but the search efficiency will be improved when it is the same. For example, the waybill index must search, update and delete the waybill information through the index. Any number of indexes can be defined in a cluster.
-
The index points to the logical namespace of one or more physical partitions. Index is the abstraction of segmentation. In actual use, the program interacts directly with the index.
-
An index can also represent the process of storing documents so that they belong to an index (in the noun sense).
7. Type
-
An Index can define one or more types. A type is a logical classification of an Index and can be used for filtering. Data with different structures cannot be distinguished by type. Different indexes should be used, similar to the concept of table in mysql. Elastic 6. Version x , only allows each , Index , to contain one , type, 7 Version x , will completely remove the , type.
-
Two types of fields with the same name cannot be defined as two different attributes. Refer to Lucene processing documentation
8. Slice
-
Sharding is an underlying work unit that stores part of all data. A shard corresponds to a Lucene instance, and a shard itself is a complete search engine.
-
The data is stored and indexed into the partition table, and the partition is allocated to each node (server) in the cluster. When the cluster is expanded or deleted, ES automatically migrates the partition among nodes for load balancing
-
Primary partition: the data in the index belongs to a primary partition. The number of primary partitions determines the maximum amount of data that the index can save
-
Sub slice: the copy of the main slice, which can provide services for read operations in order to ensure that hardware failure data is not lost
-
The number of primary partitions is determined when the index is created, and the number of replica partitions can be modified at any time.
-
Adding replica shards can improve throughput, but secondary shards and primary shards cannot be on the same node
Explain in detail
Root object
The highest level of mapping is called following object, which mainly includes the following
1,_ source metadata
-
Just adding more replica shards to a cluster with the same number of nodes does not improve performance, because each shard will get less resources from the nodes. You need to add more hardware resources to improve throughput.
-
9. Fault recovery
When a node hangs, if it is the primary node, the primary node will be re elected. If the hung node includes the primary partition, and the corresponding secondary negative node is normal, the secondary partition will be upgraded to the primary partition. ES automatic management.
10. Mapping
Mapping is the process of defining how a document, and the fields it contains, are stored and indexed.
-
Mapping defines how a document and the fields it contains are stored and indexed (queried).
-
The mapping describes the fields or attributes that a document may have, the data type of each field, and how Lucene indexes and stores these fields.
-
A {properties} node that lists the mappings for each field that may be included in the document
-
Metadata fields are fields starting with an underscore. Besides the data contained in the document, there are metadata specifying its attributes. There are three essential metadata
-
_ Index: the document is used to store the index. The name must be lowercase, cannot start with an underscore, and cannot contain a comma
-
_ type = document object category, which logically distinguishes the data in the index. Different categories can have different fields.
-
It can contain uppercase characters, cannot have commas, cannot start with an underscore or a period, and is limited to 256 characters
-
_ id = document unique id
-
Set item to control how to dynamically process new fields, such as} analyzer and dynamic_date_formats and dynamic_templates
-
Other settings can be applied to the root object and other fields of type {object} at the same time, such as} enabled, dynamic} and} include_in_all
In_ The source field stores the JSON string representing the body of the document, that is, the original data. Like all stored fields_ The source # field is compressed before being written to disk.
Use_ Advantages of source
PUT /my_index
{
"mappings": {
"my_type": {
"_source": {
"enabled": false
}
}
}
}GET /_search
{
"query": { "match_all": {}},
"_source": [ "title", "created" ]
}-
The search results include the entire available document -- there is no need to retrieve the document from another data warehouse.
-
If not_ source field, some update requests will not take effect.
-
When your mapping changes, you need to re index your data_ The source field can be re indexed directly without retrieving all your documents from another (usually slower) data warehouse.
-
When you don't need to see the whole document, a single field can be selected from_ The source field is extracted and returned through a get or search request.
-
It is convenient for debugging. You can directly see the content contained in the document.
-
If you do not need the original data, you can disable source to save space.
-
Specify the fields to return
java api
SearchSourceBuilder builder = new SearchSourceBuilder();
List<String> fieldNameList = Lists.newArrayList("billCode");
String[] includes = fieldNameList.toArray();
builder.fetchSource(new FetchSourceContext(true, includes, null));
2,_ all metadata
_ The all field combines all other fields to form a large text field, query_ The string query clause (search? q=john) is used by default when no field is specified_ All field.
give an example
Index document content:
{
"tweet": "However did I manage before Elasticsearch?",
"date": "2014-09-14",
"name": "Mary Jones",
"user_id": 1
}_ all} field content
{
"_all" : "However did I manage before Elasticsearch? 2014-09-14 Mary Jones 1"
}Disable_ all
Disable_ all
PUT /my_index/_mapping/my_type
{
"my_type": {
"_all": { "enabled": false }
}
}Field setting whether to enter_ all
include_in_all setting to control whether fields are included in the_ In the all field, the default value is true.
3. Document identification
Document identification is related to four metadata fields:
_id
By default_ uid # fields are stored (retrievable) and indexed (searchable). _ The type field is indexed but not stored_ id} and_ The index field is neither indexed nor stored, which means that they do not really exist.
However, you can still query like real fields_ ID field. Elasticsearch , use_ uid} field_ id . Although you can modify the "index" and "store" settings of these fields, you basically don't need to do so.
Lucene processing documents
Lucene # does not have the concept of document type. The type name of each document is stored in a file called_ On the metadata field of the type. When we want to retrieve a certain type of document, Elasticsearch_ Use a filter on the type ¢ field to restrict the return of only documents of this type.
What happens if there are two different types, each type has a field with the same name, but the mapping is different (for example, one is a string and the other is a number)?
A: there will be errors because all types of ES at the bottom ultimately share the same mapping. For the whole index, the mapping is essentially flattened into a single and global schema. This is why two types cannot define conflicting fields: Lucene} does not know how to handle when the mapping is flattened. Types and mappings
Type mapping
Each document consists of a series of fields, each of which has its own data type. The mapping definition contains a series of definitions of document related fields (felds) and their types. The mapping definition also includes a metadata file, such as_ source et al. The metadata field defines the processing method of metadata related to a document.
1. Dynamic mapping
In order to enable users to quickly use {es}, users can directly add documents to} es}, and the corresponding fields, mappings and types of documents are automatically generated by dynamic mapping. Use dynamic mapping to determine the data type of the field and automatically add new fields to the type mapping.
Dynamic mapping is the mapping between fields and types added by default when users add some documents. Set different default mappings by setting the parameter dynamic.
The following are the default dynamic type mappings:
Setting 'dynamic' to 'false' will not change at all_ The field content of source. _ Source # still contains the entire JSON document being indexed. Only new fields are not added to the map and are not searchable
-
ID} string of the document
-
_type
-
Type name of the document
-
_index
-
The index where the document is located
-
_uid
-
_ Type , and_ ID #id is connected together to form # type #
-
A document is composed of a set of simple key value pairs, and each field can have # 1 # to multiple values.
-
A string can be converted into multiple values through the analysis process. Lucene doesn't care what the type of value is. For him, it is regarded as an opaque byte.
-
When a document is indexed in Lucene, the value of each field is added to the inverted index of related fields.
-
true dynamically adds new fields - default
-
false ignore new fields
-
strict throws an exception if a new field is encountered
| JSON} data type | "dynamic":"true" conversion | "dynamic":"runtime" conversion |
| null | No field added | No field added |
| true or false | boolean | boolean |
| double | float | double |
| integer | long | long |
| object1 | object | object |
| array | Depends on the first non-null value in the array | Depends on the first non-null value in the array |
| String in date format | date | date |
| A string that matches a number | float or long | double or long |
| Other strings are not supported |
The Object will be remapped into the {properties} field.
Dynamic mapping mainly includes two parts
PUT /my_index
{
"mappings": {
"my_type": {
//Dynamic template definition
"dynamic_templates": [
//Template name
{ "es": {
//Matching rules
"match": "*_es",
//Apply the template to a specific type of field
"match_mapping_type": "string",
//Match type and define word breaker
"mapping": {
"type": "string",
"analyzer": "spanish"
}
}},
{ "en": {
"match": "*",
"match_mapping_type": "string",
"mapping": {
"type": "string",
"analyzer": "english"
}
}}
]
}}}-
Dynamic attribute mapping
-
Dynamic field matching rules
-
Dynamic template
-
Custom rules for dynamic field attribute mapping
-
3. Custom dynamic mapping rules
date
-
The default rule value is dynamic_date_formats:
-
[ "strict_date_optional_time","yyyy/MM/dd HH:mm:ss Z||yyyy/MM/dd Z"]
-
Change default
-
es: in_ Field names ending in es , need to use the , spanish , participle.
-
en: all other fields use the english participle.
-
PUT my_index { "mappings": { "my_type": { "dynamic_date_formats": ["MM/dd/yyyy"] } } }4. Dynamic template
Use dynamic_templates is a dynamic template that controls the mapping of fields generated by new detection. Different mappings can also be applied by field name or data type.
Each template has a name, a mapping parameter to specify how the mapping should be used, and at least one parameter (such as match) to define which field the template applies to.
The templates are detected in sequence; The first matching template is enabled. For example, we define two templates for the {string} type field:
-
es: in_ Field names ending in es , need to use the , spanish , participle.
-
en: all other fields use the english participle.
-
The match} parameter only matches the field name,
-
path_ The match parameter matches the full path of the field on the object, address. * Name = matching object path
-
unmatch , and , path_unmatch will be used for unmatched fields.
-
5. Default mapping
Typically, all types in an index share the same fields and settings. _ default_ Mapping makes it easier to specify common settings rather than repeating them every time a new type is created. _ default_ Mapping is a new type of template. In settings_ default_ All types created after mapping will apply these default settings unless the type explicitly overrides these settings in its own mapping.
For example, we can use_ default_ Mapping is disabled for all types_ All , field, but only enabled in the , blog , type:
PUT /my_index { "mappings": { "_default_": { "_all": { "enabled": false } }, "blog": { "_all": { "enabled": true } } } }ES syntax usage
-
1. Create index
PUT # address / index name
PUT http://127.0.0.1:9200/commodity
By default, the number of index fragments created is , 5, and the number of replicas is , 1. If no cluster is specified, a new cluster named , elasticjob , will be created by default
When creating an index, you can specify the following parameters on both the partition and the mapping band for user-defined configuration:
{ "settings": { "number_of_shards": 3, "number_of_replicas": 2 }, "mapping": { "_doc": //Type { "properties": { "commodity_id": { "type": "long" }, "commodity_name": { "type": "text" }, "picture_url": { "type": "keyword" }, "price": { "type": "double" } } } } }field interpretation
-
The problem to be solved in search is "what are the documents containing query keywords?", Aggregation is just the opposite. The problem to be solved by aggregation is "what word items are included in the document". Doc is generated when most fields are re indexed_ Values, but the text field does not support doc_values. Instead, the text field will generate a data structure of fielddata during query. Fielddata will be generated when the field is aggregated, sorted or used in script for the first time. Elastic search regenerates the document term relationship by reading the inverted record table on the disk, and finally sorts it in the Java heap memory.
The fielddata property of the text field is off by default. Opening fielddata consumes a lot of memory. Before you open the text field, figure out why you want to aggregate and sort the text field. In most cases, it makes no sense to do so.
"New York" will be analyzed into "new" and "York". In the text type, the aggregation will be divided into "new" and "York". Maybe what you need is a "New York". This is a keyword field that can be added without analysis.
ignore_above field
Specify the maximum length of the field index and storage. Those exceeding the maximum value will be ignored and the index will be ignored.
2. Index addition
Original usage
-
Action / index name / type / custom id
-
Responder
-
PUT /{index}/{type}/{id} { "field": "value", ... }PUT /website/blog/123 { "title": "My first blog entry", "text": "Just trying this out...", "date": "2014/01/01" }
-
Responder
{
"_index": "website", //Index
"_type": "blog", //Type
"_id": "123", // id
"_version": 1, //Version number
"created": true //Is it new
}-
If you do not specify ID the system generated default ID is used
POST /website/blog/
{
"title": "My second blog entry",
"text": "Still trying this out...",
"date": "2014/01/01"
}-
response
{
"_index": "website",
"_type": "blog",
"_id": "AVFgSgVHUP18jI2wRx0w",//System generated default ID
"_version": 1,
"created": true
}In elastic search, each document has a version number. Every time a document is modified (including deletion)_ The value of version , is incremented. In Handling conflicts How to use it is discussed_ The version number ensures that changes made in one part of your application do not overwrite changes made in another part.
3. Simple query
GET /{index}/{type}/{id}parameter
| pretty | Readable return |
| _source=title,text | Return part of the data, and return the title and text fields in the data |
| _source | Return only_ The source data field does not require metadata |
Get the blog post with id 123 in the blog
GET /website/blog/123?pretty
{
"_index" : "website",
"_type" : "blog",
"_id" : "123",
"_version" : 1,
"found" : true,
"_source" : {
"title": "My first blog entry",
"text": "Just trying this out...",
"date": "2014/01/01"
}
}Query query
-
Match: match the specified conditions. The query string will be analyzed with the correct analyzer before executing the query
-
{ "match": { "age": 26 }}
-
match_all: match all documents
-
multi_match: multiple fields execute the same query
{
"multi_match": {
"query": "full text search",
"fields": [ "title", "body" ]
}
}-
term: accurate query. Input text is not analyzed, and accurate matching is performed based on the given value
-
{ "term": { "age": 26 }}
-
terms: multi value matching. As long as the document contains any value in the specified list, it can be recalled
-
{ "terms": { "tag": [ "search", "full_text", "nosql" ] }}
-
exists: the specified field has a value
-
missing: the specified field has no value
-
bool: Boolean query is used to merge query statements
-
Must: the condition that the document must contain
-
Must not: conditions that the document must not contain
-
Should: if the conditions are met, the document score (_score) will be increased. Otherwise, it will not be affected. Correct the correlation score of each document. When must or filer is used in combination with should, pay attention to the failure of the should condition.
-
Filter: filter, the conditions that need to be filtered. The filter is fast because it does not calculate the relevance of the document, filters according to whether it is satisfied or not, and the results can be easily cached.
-
Range: range
-
gt, gte: greater than or equal to
-
lt, lte: less than or equal to
{
"range": {
"age": {
"gte": 20,
"lt": 30
}
}
}-
minimum_should_match: the minimum number of conditions that should be satisfied. When must or fliter is used with should, the should condition may degenerate into plus or minus points, so use minimum_should_match can force the minimum satisfaction of the should condition, support percentage or specify a value
{
"bool": {
"must": { "match": { "email": "business opportunity" }},
"should": [
{ "match": { "starred": true }},
{ "bool": {
"must": { "match": { "folder": "inbox" }},
"must_not": { "match": { "spam": true }}
}}
],
"minimum_should_match": 1//match , and bool satisfy at least one , or relationship
}
}-
When the search is multiple keywords, the OR relationship is considered by default
GET //{index}/{type}/_search
{
"query":{
"match":{
"desc":"condition Second condition"}},//Multiple conditions separated by spaces
"from":2, //Specify displacement
"size":10 //Specifies the size returned
}-
Perform and searches for multiple keywords # use Boolean queries
{
"query": {
"bool": {
//Both software and system
"must": [
{ "match": { "desc": "Software" } },
{ "match": { "desc": "system" } }
]
}
}
}'The difference between query and filter
-
filter is a multiple-choice question, only yes or no
-
Query query is a short answer question. Different answers have different scores
-
Test the relevance of the document to this query, and assign this relevance to the fields representing the relevance_ score, and sort the matched documents according to their relevance
4. Renew
The document is immutable and needs to be modified, re indexed or replaced. When re indexed and put, the returned version will increase
PUT /{index}/{type}/{id}
{
"title": "My first blog entry",
"text": "I am starting to get the hang of this...",
"date": "2014/01/02"
}
return
{
"_index" : "website",
"_type" : "blog",
"_id" : "123",
"_version" : 2, //Version number
"created": false //Already exists
}5. Create a new document
Specify op_ The type parameter is create. Only new entries are accepted. The conflict returns 409
PUT /{index}/{type}/{id}?op_type=create6. Delete
Deletion will increase the value of version. It is only a logical deletion, even if there is no version
DELETE /{index}/{type}/{id}7. Cursor query scroll
The reason why deep paging is slow is that the larger the number of pages, the more data sets returned by each fragment, the larger the final sorted result set, and the greater the sorting cost. Cursor query is to take snapshot data at a certain point in time. Any change in the index after cursor query initialization will be ignored. Cursor query can be regarded as taking all data at a certain point and setting an effective time for this data. Within this effective time, paging results will be returned batch by batch, Moreover, the results of the next batch of pagination need to use the scroll returned by the previous batch of results_ ID query.
GET /your_index/_search?scroll=1m
{
"query":{"match_all":{}}, //Match all document} filters
"sort":["_doc"],
"size":1000
}-
Valid time of cursor window: 1} minute
-
Sort by:_ doc
-
Size: Specifies the number and size of each partition, so the maximum number of retrieved documents may be size * the number of your primary partitions
return:
GET /_search/scroll
{
"scroll": "1m",
"scroll_id" : "cXVlcnlUaGVuRmV0Y2g7NTsxMDk5NDpkUmpiR2FjOFNhNnlCM1ZDMWpWYnRROzEwOTk1OmRSamJHYWM4U2E2eUIzVkMxalZidFE7MTA5OTM6ZFJqYkdhYzhTYTZ5QjNWQzFqVmJ0UTsxMTE5MDpBVUtwN2lxc1FLZV8yRGVjWlI2QUVBOzEwOTk2OmRSamJHYWM4U2E2eUIzVkMxalZidFE7MDs="
}search
Structured search
term query - single exact value lookup
-
Scope of use: number, Boolean value, date, text
-
If the method of indexing data is analysis, the exact search through term will not be recalled, so set the field to not_analyzed for exact value lookup
Use example:
GET /claim_form/_search
{
"query": {
"term": {"id": "20395536"}
}
}terms - multiple exact value lookup
-
The recalled document id field contains the field of the content in the List. As long as the document id field is in the List, it can be recalled
The syntax is as follows:
GET /claim_form/_search
{
"query": {
"terms": {"id": ["1","2"]}
}
}
//result
//Recall two documents with id values of {1} and 2}-
When the field value of the recalled document contains multiple values, for example, the document value of the field [tags] is [["tag1","tag2"]]. When term (the same terms) {"term": {"tags": "tag1"}}, the document can be recalled. Is a concept of inclusion rather than equivalence.
-
Combined filter bool filter
Receive multiple other filters as parameters and combine these filters into Boolean logical combinations
structure
{ "bool" : { "must" : [],//All statements must match {and "should" : [], //At least one statement matches OR "must_not" : [],//All statements do NOT match {NOT} AND } }Boolean filters can also be nested inside. For complex usage, please refer to the following sql statement:
select * from claim_form where claimSource=3 or ( complaintOrgCode=1 &&toComplaintOrgCode1=2);
GET /claim_form/_search { "query": { "bool": { "filter": { "bool": { "should": [ { "term": { "claimSource": "3" } }, { "bool": { "must": [ { "term": { "complaintOrgCode": "1" } }, { "term": { "toComplaintOrgCode1": "2" } } ] } } ] } } } } }Case - share a pit encountered in using es
For the historical reasons of the project, es is the most basic method. Instead of encapsulating the query conditions of es, the query parameters are stuffed into a bool query each time. The project needs to query the list of the complained Party's province or the complainant's province is 000195 Province on September 1. There are at most three complained parties and at least one in each list. The query statements used at that time are as follows:
POST /form/_search { "query": { "bool": { "should": [ { "term": { "complaintZoneCode": "000195" } },{ "term": { "toComplaintZoneCode1": "000195" } }, { "term": { "toComplaintZoneCode2": "000195" } }, { "term": { "toComplaintZoneCode3": "000195" } } ], "filter": { "range": { "gmtCreate": { "gte": "2021-09-01 00:00:00", "lte": "2021-09-01 23:59:59" } } } } } }The statement is "bool", which is composed of "filter" and "should", that is, the ideal effect is to find a list whose time range is September 1 and the province of the complainant or the province of the respondent is 000195. The query result of this statement is 135924 in total. During paging query (adding the data that can jump directly to the deep page), it will be found that the data in the next few pages does not meet the requirements. The reason is that when the "should" statement is used simultaneously with the statements such as "filter" or "must", the "should" statement becomes a scoring item, that is, when the document meets the conditions in "should", the relevance score of the document increases and ranks higher in the recall, However, documents that do not meet the requirement of "should" will also be recalled, that is, they will be later than the recall order. The solution is to use {minimum_should_match, which will force the recalled document to meet one of the {should} conditions.
The modified sentence is as follows:
POST /form/_search { "query": { "bool": { "should": [ { "term": { "complaintZoneCode": "000195" } },{ "term": { "toComplaintZoneCode1": "000195" } }, { "term": { "toComplaintZoneCode2": "000195" } }, { "term": { "toComplaintZoneCode3": "000195" } } ], "minimum_should_match": 1, //Force , should , to meet at least one item "filter": { "range": { "gmtCreate": { "gte": "2021-09-01 00:00:00", "lte": "2021-09-01 23:59:59" } } } } } }After implementation, the recall result was 40599, which met the conditions. Of course, if there is only the "should" statement in your "bool" statement, the recalled documents must meet one of them before they can be recalled.
In order to understand the condition of , should , timeliness, I tried the following syntax to query, that is, put the , filter , statement and , should , statement in , bool , and put them in the context of , filter ,,
The result is 40599
POST /form/_search { "query": { "constant_score": { "filter": { "bool": { "filter": { "range": { "gmtCreate": { "gte": "2021-09-01 00:00:00", "lte": "2021-09-01 23:59:59" } } }, "should": [ { "term": { "complaintZoneCode": "000195" } }, { "term": { "toComplaintZoneCode1": "000195" } }, { "term": { "toComplaintZoneCode2": "000195" } }, { "term": { "toComplaintZoneCode3": "000195" } } ] } } } } }The result is correct, but there are the following tips:
#! Deprecation: Should clauses in the filter context will no longer automatically set the minimum should match to 1 in the next major version. You should group them in a [filter] clause or explicitly set [minimum_should_match] to 1 to restore this behavior in the next major version.
In fact, when we use it this way, es automatically helps us join the} minimum_should_match condition. Underlying source code:
final String minimumShouldMatch; if (context.isFilter() && this.minimumShouldMatch == null && shouldClauses.size() > 0) { if (mustClauses.size() > 0 || mustNotClauses.size() > 0 || filterClauses.size() > 0) { deprecationLogger.deprecatedAndMaybeLog("filter_context_min_should_match", "Should clauses in the filter context will no longer automatically set the minimum should " + "match to 1 in the next major version. You should group them in a [filter] clause or explicitly set " + "[minimum_should_match] to 1 to restore this behavior in the next major version." ); } minimumShouldMatch = "1"; } else { minimumShouldMatch = this.minimumShouldMatch; }For more detailed analysis, please refer to This article,
Write more clearly
Range query
This part is relatively simple, for example
Query data with status greater than or equal to 1 and less than or equal to 2
POST /claim_form/_search { "query": { "bool": { "filter": { "range": { "status": { "gte": 1, "lte": 2 } } } } } }Query the data whose creation date is greater than or equal to September 1, 2021
POST /claim_form/_search { "query": { "bool": { "filter": { "range": { "gmtCreate": { "gte": "2021-09-01 00:00:00" } } } } } } -
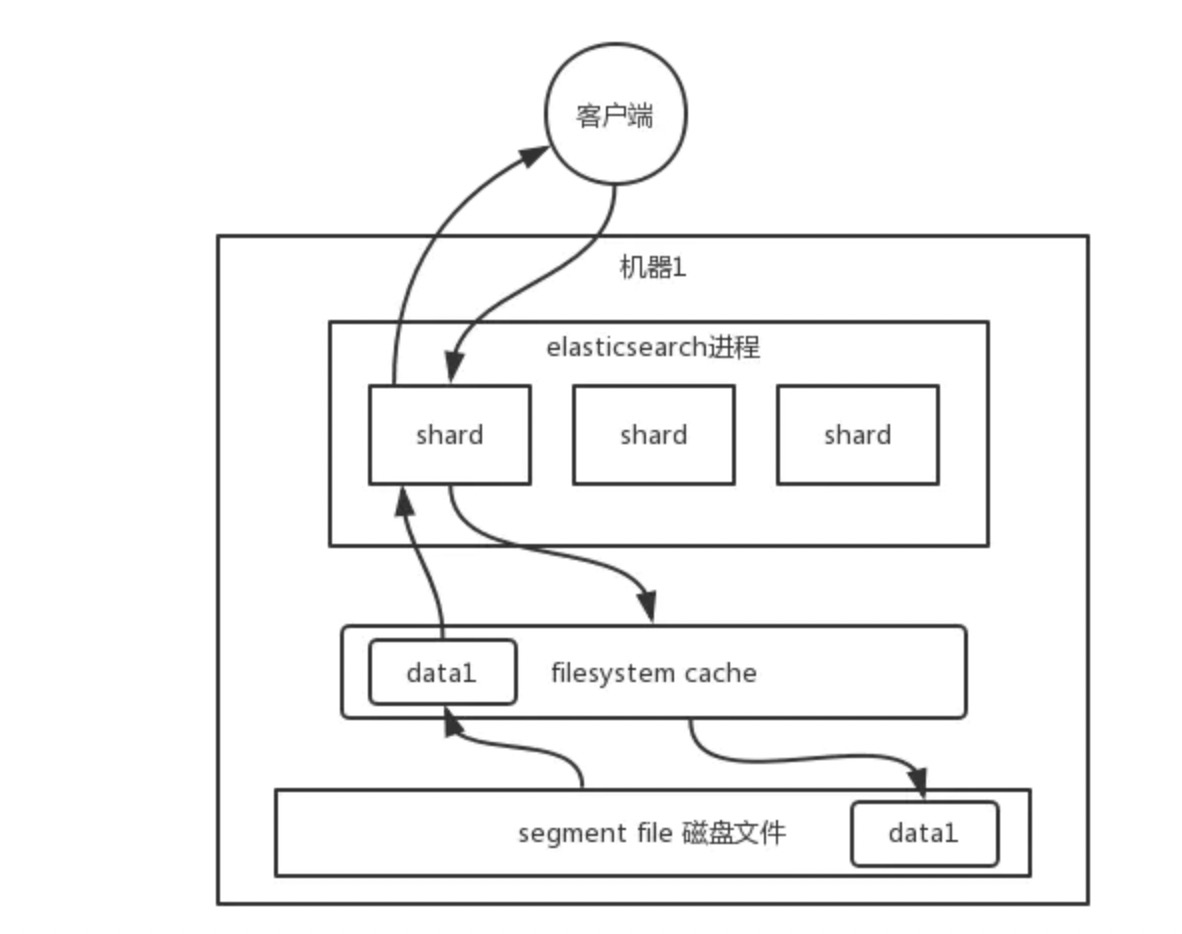
ES storage structure
The search engine of es , relies heavily on the underlying , filesystem , cache. If you give more memory to , filesystem , cache and try to make the memory accommodate all , idx , segment , file index data files, then you basically use memory when searching, and the performance will be very high.
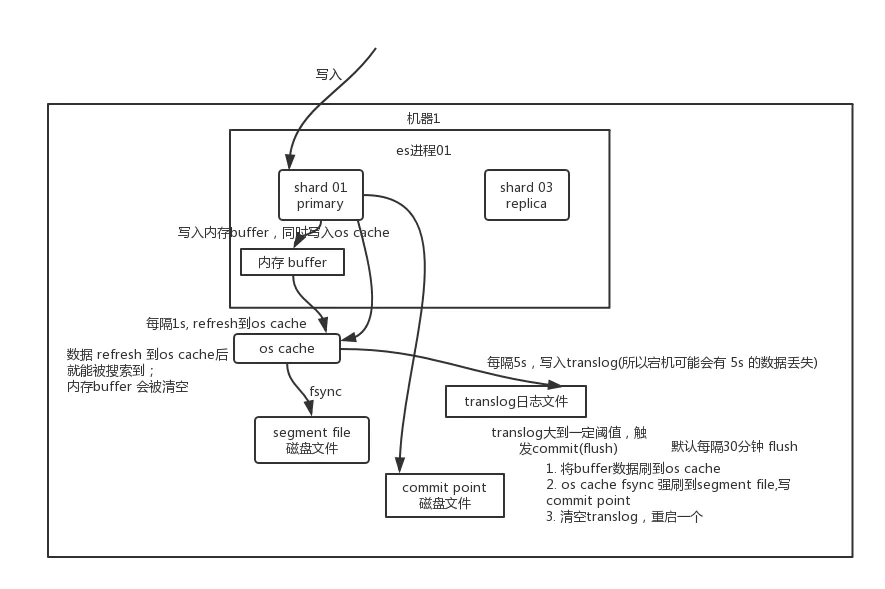
The data is written into the memory buffer first, and then the data is refreshed into the system cache every {1s. The data in the system cache can be searched, that is, es} can be searched from writing to, with a delay of {1s}. Write the data to the # translog # file every # 5s (in this way, if the machine goes down and there is no memory data, there will be # 5s # data loss at most). When the translog # is large to a certain extent, or every # 30mins by default, the # commit # operation will be triggered to refresh the buffer data to the # segment # file # disk file.
optimization
-
Data preheating
-
Regularly search hot data to ensure that the data is in the file system cache, which can enable users to search faster
-
Question: if the hot data is normal, it should always be in the cache. Why do you need to keep searching to keep it in the cache?
-
In the actual usage scenario, there are many users viewing a microblog of big v, but users do not query at the same time, so at an interval of 1 minute, for example, hot data may have been crowded out by non hot data, so keeping it in the cache can enable more users to search faster.
-
Cold heat separation
-
For a large number of data with little access and low frequency, write a separate index, and then write a separate index for the hot data with frequent access. It is better to write the cold data into one index and then the hot data into another index, so as to ensure that after the hot data is preheated, try to keep them in the "file system" os "cache so that the cold data is not washed away.
-
Document design
-
For some data association operations, use code to write the relevant association data before writing to the document. Do not rely on its own es Association and other complex operations for query. The efficiency of these operations is low
-
Paging optimization
-
The paging of es ^ slows down as the page turns back. The more data to query on each partition, the more total data, and the more data to sort
-
optimization
-
Deep paging is not supported
-
Using the page turning mode, scroll # will generate a snapshot of all the data at one time, and then turn back the page every time you slide through the cursor scroll_id moves and gets the next page. The performance is basically in milliseconds. However, page skipping is not supported.
-
-
search_after , search_ The idea of after is to use the results of the previous page to help retrieve the data of the next page, and you are not allowed to turn the page at will. When initializing, you need to use a field with a unique value as the {sort} field.
quote:
Detailed explanation of ES # Mapping and Field type