I ES introduction
1.1 Lucene
Lucene is an open source, free, high-performance, full-text search engine written in pure Java. See for details Lucene study notes , no introduction here.
1.2 ElasticSearch
ElasticSearch is a distributed, scalable, near real-time, RESTful search and data analysis engine. ElasticSearch is written in Java. By further encapsulating Lucene, it shields the complexity of search. Developers only need a set of simple RESTful API s to operate full-text retrieval.
ElasticSearch performs well in distributed environment, which is one of the reasons why it is more popular. It supports PB level structured or unstructured massive data processing
On the whole, ElasticSearch has three functions:
- Data collection
- Data analysis
- data storage
ElasticSearch features:
- Distributed file storage.
- Distributed search engine for real-time analysis.
- High scalability.
- Pluggable plug-in support.
II ES installation
2.1 single node installation
get into ES official website , download the corresponding version of the compressed package according to the system
After downloading, directly decompress the compressed package. The meaning of the decompressed directory is as follows:
| catalogue | meaning |
|---|---|
| modules | Dependent module directory |
| lib | Third party dependency Library |
| logs | Output log directory |
| plugins | Plug in directory |
| bin | Executable directory |
| config | Profile directory |
| data | Data storage directory |
After entering the bin directory, directly execute elasticsearch Bat (Windows version)

Seeing started indicates successful startup.
The default listening port is 9200. The browser can directly enter localhost:9200 to view the node information.
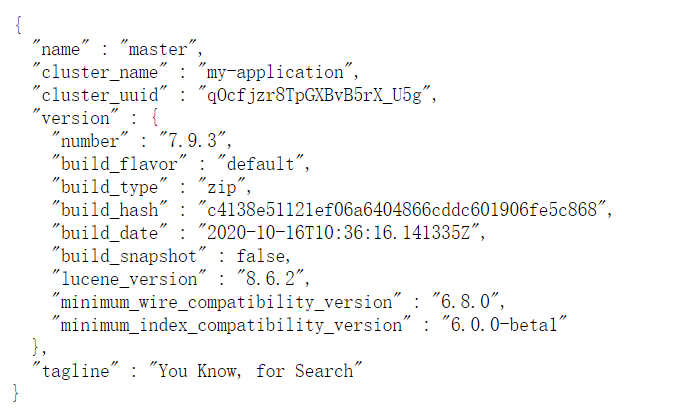
We can customize the name of the node and the name of the cluster (elasticsearch by default).
Open config / elasticsearch YML file, you can configure the cluster name and node name. The configuration method is as follows:
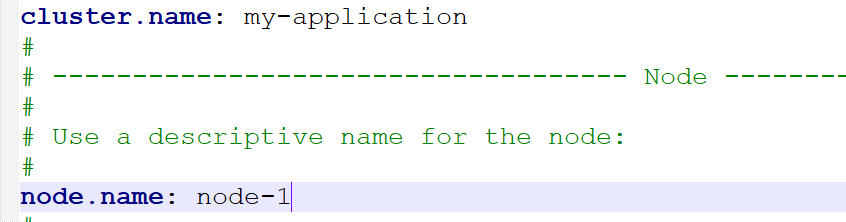
After configuration, save the configuration file and restart es. After successful restart, refresh the browser localhost:9200 page to see the latest information

Es supported version correspondence matrix: https://www.elastic.co/cn/support/matrix
2.2 installation of head plug-in
Elasticsearch head plug-in can view cluster information visually.
2.2.1 browser plug-in installation
Download address: https://download.csdn.net/download/zxc_123_789/19415225
After downloading, unzip it and drag it directly to Google browser to install it successfully
2.2.2 download Plug-in installation
GitHub address: https://github.com/mobz/elasticsearch-head
git clone git://github.com/mobz/elasticsearch-head.git cd elasticsearch-head npm install npm run start
After successful startup, the following steps are taken:

Note: if you install by downloading plug-ins, you may not be connected, and you can't see the cluster data at this time. The reason is that cluster data is requested through cross domain. By default, the cluster does not support cross domain, so cluster data cannot be seen here.
The solution is as follows: modify es config / elasticsearch YML configuration file, add the following content to make it support cross domain:
http.cors.enabled: true http.cors.allow-origin: "*"
After the configuration is completed, restart es, and there will be data on the head.
2.3 distributed cluster installation
Prepare one master and two slave mode here
The master port is 9200, and the slave port is 9201 and 9202 respectively
First, modify the config / elasticsearch.xml of the master YML profile:
node.name: master node.master: true network.host: 127.0.0.1
Decompress the compressed package of es into two copies, named slave01 and slave02 respectively, representing two slaves. And configure them respectively.
slave01/config/elasticsearch.yml:
cluster.name: my-application node.name: slave01 network.host: 127.0.0.1 http.port: 9201 discovery.zen.ping.unicast.hosts: ["127.0.0.1"]
slave02/config/elasticsearch.yml:
cluster.name: my-application node.name: slave02 network.host: 127.0.0.1 http.port: 9202 discovery.zen.ping.unicast.hosts: ["127.0.0.1"]
Then start slave01 and slave02 respectively. After startup, you can view the cluster information on the head plug-in.
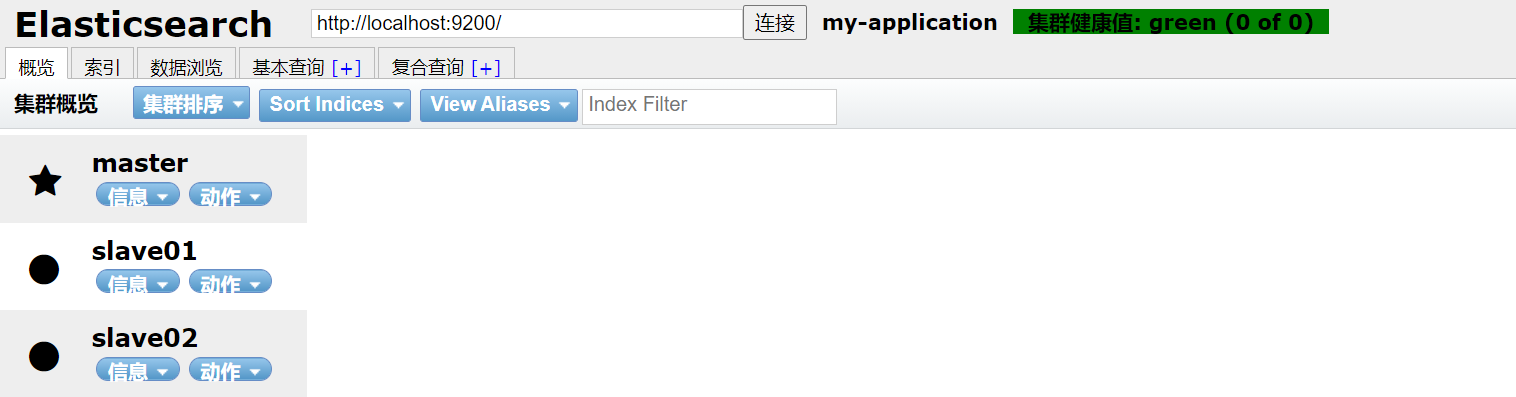
2.4 Kibana installation
Kibana is an analysis and data visualization platform for es launched by Elastic company, which can search and view the data stored in es.
Kibana official website download address: https://www.elastic.co/cn/downloads/kibana
After downloading and decompressing, directly enter the bin directory and start it
Configure the address information of ES (optional. If es is the default address and port, it can not be configured. The specific configuration file is config/kibana.yml)
After successful startup, visit localhost:5601
After Kibana is installed and opened for the first time, you can choose to initialize the test data provided by es or not use it.
Note: the installed version of es should be consistent with that of kibana as far as possible, otherwise kibana may start and report an error
III ES core concepts
3.1 Cluster
One or more servers installed with es nodes are organized together, which is a cluster. These nodes jointly hold data and provide search services.
A cluster has a name, which is the unique identifier of the cluster. The name becomes cluster name. The default cluster name is elasticsearch. Only nodes with the same name can form a cluster.
It can be found in config / elasticsearch Configure cluster name in YML file:
cluster.name: my-application
In the cluster, there are three node states: green, yellow and red:
- Green: the node operation status is healthy. All primary and replica partitions can work normally.
- Yellow: indicates that the operation status of the node is in the warning status. All primary partitions can run directly at present, but at least one replica partition cannot work normally.
- Red: indicates that the cluster is not working properly.
3.2 node
A server in the cluster is a node. The node will store data and participate in the index and search functions of the cluster. If a node wants to join a cluster, it only needs to configure the cluster name. By default, if we start multiple nodes and multiple nodes can discover each other, they will automatically form a cluster, which is provided by es by default. However, this method is not reliable and brain splitting may occur. Therefore, in actual use, it is recommended to manually configure the cluster information.
3.3 Index
Indexes can be understood from two aspects:
noun
A collection of documents with similar characteristics.
verb
Index data and index data.
3.4 Type
A type is a logical classification or partition on an index. Before es6, there can be multiple types in an index. From es7, there can only be one type in an index. In es6 X still maintains compatibility and supports multiple type structures with a single index, but this is not recommended.
3.5 Document
A unit of data that can be indexed. For example, a user's document, a product's document, and so on. All documents are in JSON format.
3.6 Shards
Indexes are stored on nodes, but the processing effect of a single node may not be ideal due to the space size and data processing capacity of the node. At this time, we can fragment the index. When we create an index, we need to specify the number of slices. Each partition itself is also a fully functional and independent index.
By default, an index automatically creates 1 shard and creates a copy for each shard.
3.7 Replicas
A replica is a backup, which is a backup of the primary partition.
3.8 Settings
The definition information of the index in the cluster, such as the number of slices and copies of the index.
3.9 Mapping
Mapping saves information such as the storage type, word segmentation method and whether to store the defined index fields.
3.10 Analyzer
Definition of field word segmentation method.
3.11 ElasticSearch Vs relational database
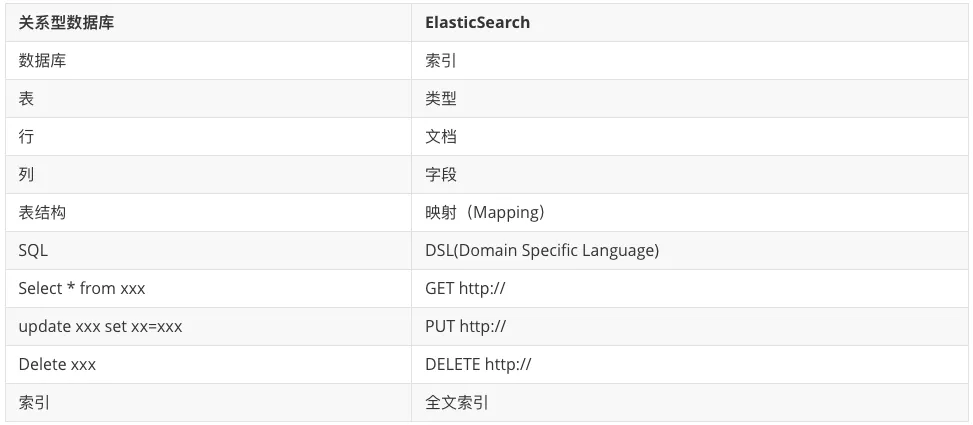
IV ES participle
4.1 ES built-in word splitter
The core function of ElasticSearch is data retrieval. First, the document is written into es through index. Query analysis is mainly divided into two steps:
- Entry: the word splitter converts the input text into a stream of entries one by one.
- Filtering: for example, the stop word filter will remove irrelevant terms (mood particles such as, uh, ah, NE) from the terms; In addition, there are synonym filters, lowercase filters, etc.
ElasticSearch has a variety of built-in word splitters for use.
Built in word splitter:
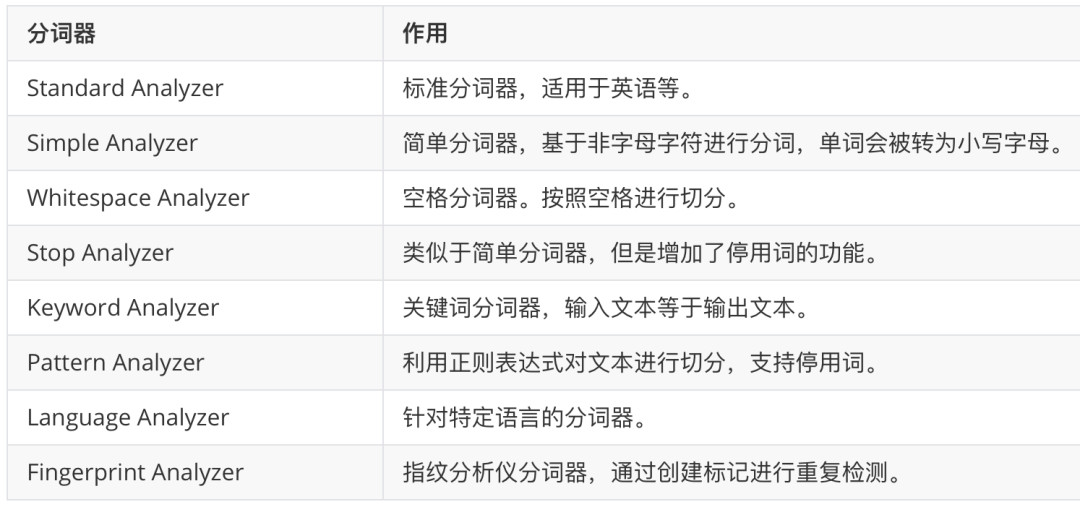
4.2 Chinese word splitter
In ES, elasticsearch analysis IK, a third-party plug-in of ES, is the most commonly used Chinese word splitter. The code is hosted on GitHub:
https://github.com/medcl/elasticsearch-analysis-ik
After opening, download the compressed package of the Chinese word splitter corresponding to the ES version, create a new ik directory in the es/plugins directory, and copy all the extracted files to the ik directory. Then restart es.
Test:
First create an index named test:

Next, perform word segmentation test in the index:
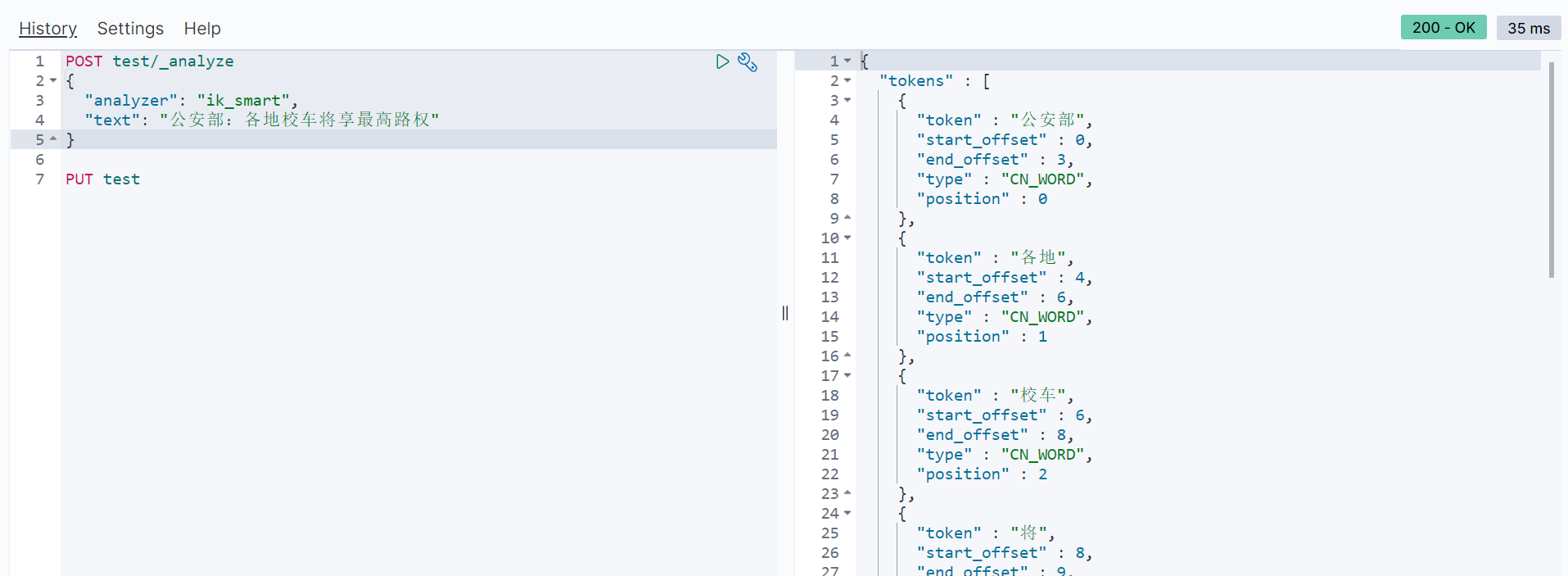
4.2.1 custom extended Thesaurus
-
Local customization
In the es/plugins/ik/config directory, create a new ext.dic file (any file name), in which you can configure a custom thesaurus.
Not for whom
If there are more than one word, write a new word on a new line.
Then in ES / plugins / IK / config / ikanalyzer cfg. Where to configure the extension dictionary in XML:
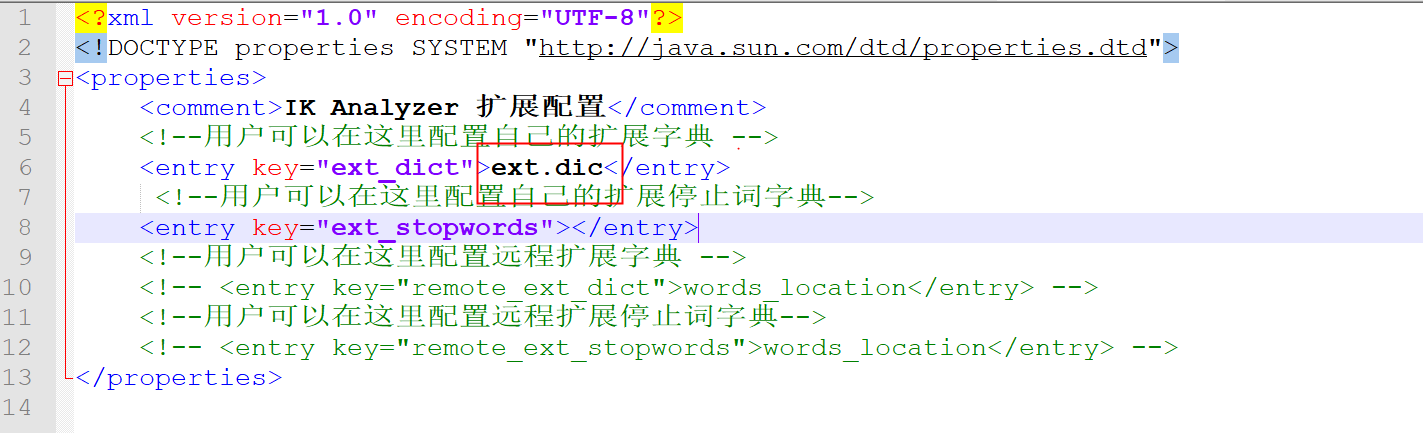
Test word segmentation results after restarting es
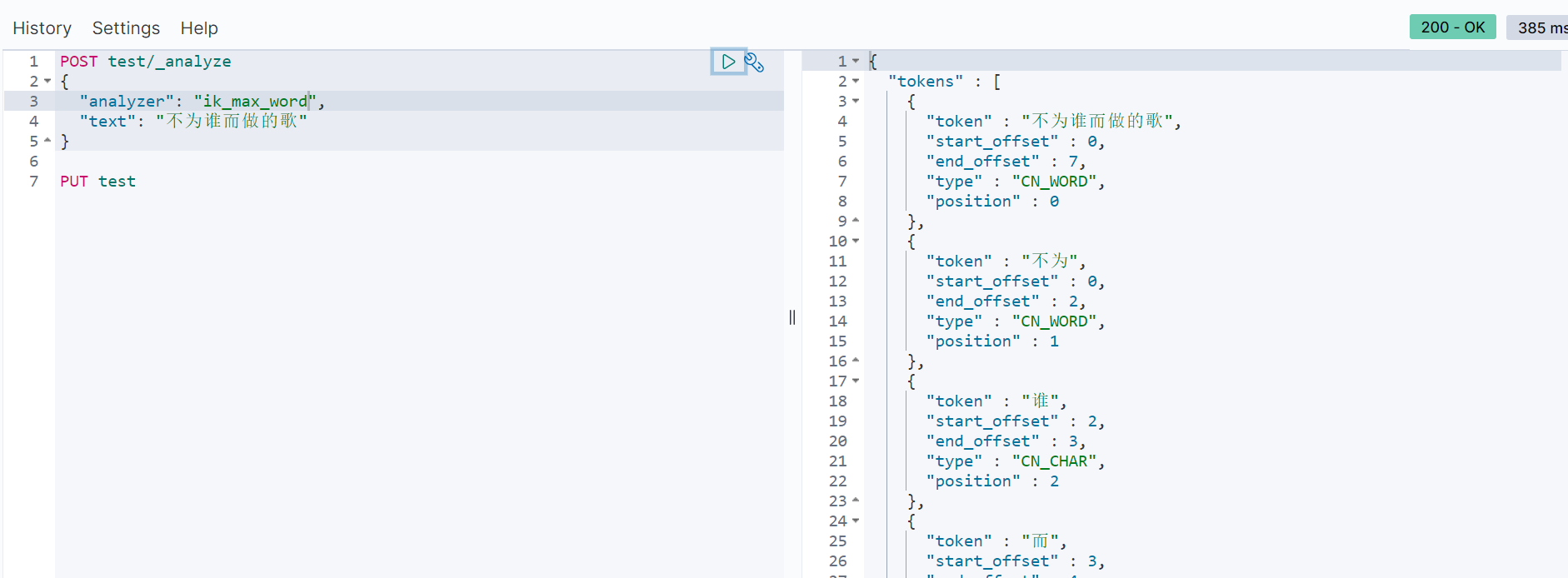
-
Remote Thesaurus
You can also configure the remote thesaurus. The remote thesaurus supports hot update (it can take effect without restarting es). Hot update only needs to provide an interface, and the interface can return extension words.
The hot words that need to be updated automatically can be placed in a UTF-8 encoding Txt file, in nginx or other simple http server, when When the txt file is modified, the http server will automatically return the corresponding last modified and ETag when the client requests the file. You can create another tool to extract relevant terms from the business system and update this Txt file. Here, we take nginx as an example. The nginx port number is mapped to 8080, and put ext.dic into the html directory of nginx

After configuration, restart es to take effect. There is no need to restart es after adding a new thesaurus
Hot update mainly means that if the last modified or ETag field of the response header changes, ik it will automatically reload the remote extension
V Basic operation of index
5.1 new index
In the head plug-in, select the index tab, and then click new index. When creating a new index, you need to fill in the index name, number of slices and number of copies. The default number of tiles is 5 and the number of copies is 1
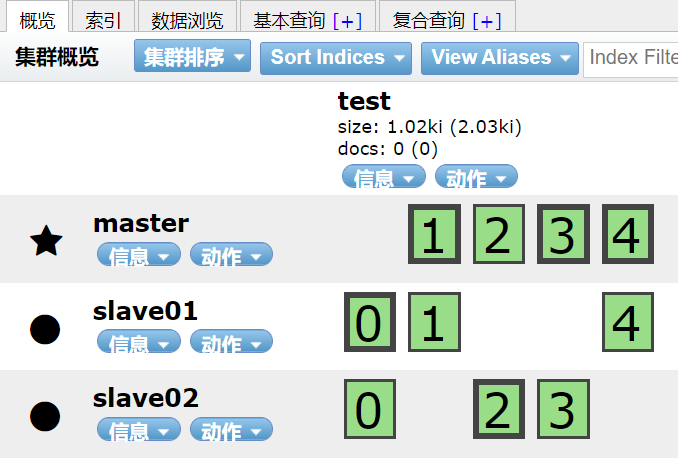
0, 1, 2, 3 and 4 respectively represent the five slices of the index, the thick box represents the primary slice, and the thin box represents the copy (click the box to view whether it is the primary slice or the copy through the primary attribute)
It can be created by sending a request through postman or kibana
PUT test1
After successful creation, you can view the index information through the head plug-in
When creating an index, you should pay attention to
- Index names cannot have uppercase letters
- The index name is unique and cannot be repeated. Repeated creation will cause errors
5.2 modify index
After the index is created, its properties can be modified.
5.2.1 modify index copy
For example, modify the number of copies to 2
PUT test/_settings
{
"number_of_replicas":2
}
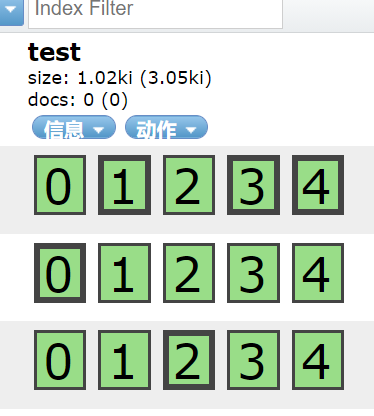
Updating other index parameters is similar
5.2.2 modify index read and write permissions
After the index is created successfully, you can write documents to the index:
PUT test/_doc/1
{
"title":"hello1"
}
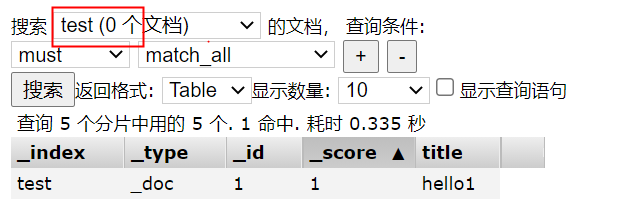
By default, the index has read-write permission. Of course, the read-write permission can be turned off.
For example, turn off write access to the index:
PUT test/_settings
{
"blocks.write": true
}
After closing, the document cannot be added. After closing the write permission, if you want to open it again, the method is as follows:
PUT book/_settings
{
"blocks.write": false
}
Other similar permissions include:
- blocks.write
- blocks.read
- blocks.read_only
5.3 view index
You can view it through the head plug-in
The request is viewed as follows:
You can view multiple index information at the same time, separated by commas

You can also view all index information:
GET _all/_settings
5.4 delete index
You can delete indexes through the head plug-in

It can also be deleted by request
DELETE test1
5.5 index on / off
POST .kibana/_close POST .kibana/_open
You can close / open multiple indexes, multiple index references, separate them, or use them directly_ All stands for all indexes.
5.6 copy index
POST _reindex
{
"source": {
"index": "test"
},
"dest": {
"index": "test_new"
}
}
Index replication will only copy data, not index configuration. When copying, you can add query criteria.
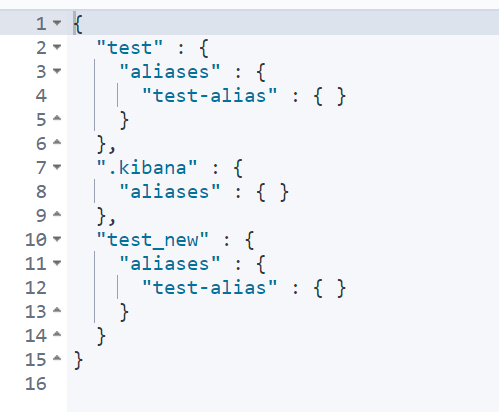
5.7 index alias
You can create an alias for the index. If the alias is unique, it can replace the index name.
POST _aliases
{
"actions": [
{
"add": {
"index": "test",
"alias": "test-alias"
}
}
]
}
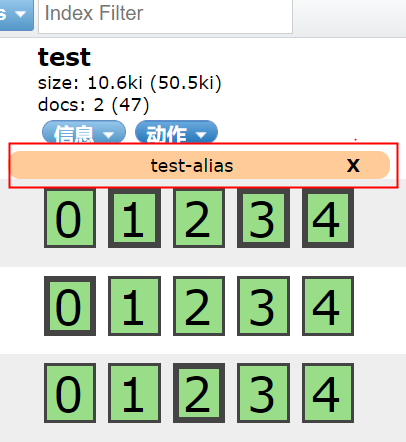
Delete alias
POST _aliases
{
"actions": [
{
"remove": {
"index": "test",
"alias": "test-alias"
}
}
]
}
5.8 viewing index aliases
GET test/_alias
View all index aliases
GET _alias
Vi Document operation
6.1 new document
Add a document to the index:
_ doc indicates the document type, and 1 indicates the ID of the added document
PUT test/_doc/1
{
"title": "es Document addition",
"content":"Document addition operation learning"
}
After adding successfully, the json of the response is as follows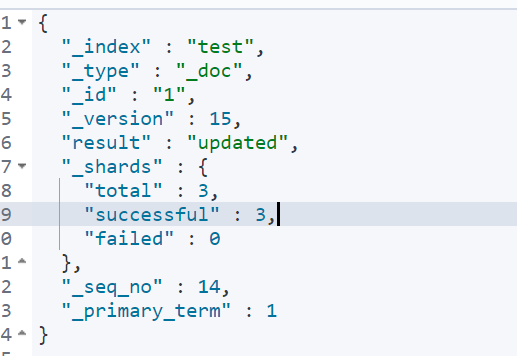
_ Index represents the document index.
_ Type indicates the type of document.
_ id represents the id of the document.
_ Version indicates the version of a document (when a document is updated, the version will be automatically increased by 1, which is specific to the version of a document).
Result indicates the execution result.
_ shards indicates fragment information.
_ seq_no and_ primary_term is also used for version control (for the current index).
Of course, when adding a document, you can also not specify an id. at this time, the system will give an id by default. If you do not specify an id, you need to use a POST request instead of a PUT request.
POST test/_doc
{
"title": "es Document addition",
"content":"post Document addition operation learning"
}
6.2 obtaining documents
Get document by document ID
GET test/_doc/t3RD5XkBJY9c7kUxehIr
Returns if this document does not exist
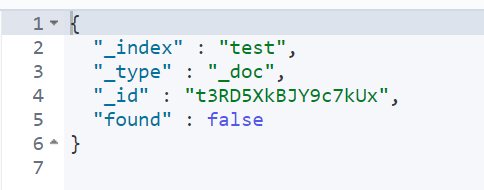
If you just want to detect whether a document exists, you can use the head request:
You can also get documents in batch
GET test/_mget
{
"ids":["t3RD5XkBJY9c7kUxehIr","1","2"]
}
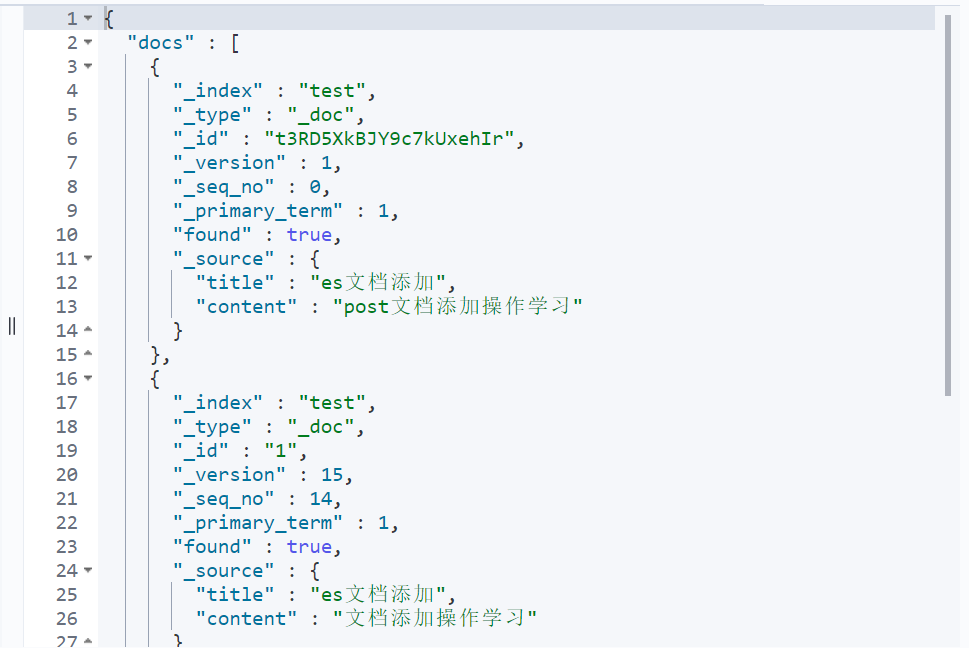
6.3 document update
6.3.1 general document update
Note that once the document is updated, the version will increase by 1.
In this way, the updated document will overwrite the original document.
PUT test/_doc/t3RD5XkBJY9c7kUxehIr
{
"title": "3"
}
If we just want to update the Department field of the document
POST test/_update/tHRD5XkBJY9c7kUxQBIJ
{
"script": {
"lang": "painless",
"source": "ctx._source.title=params.title",
"params":{
"title":"Single field modification es file"
}
}
}
In the script, lang represents the script language, and painless is a built-in script language of es. Source represents the script to be executed. ctx is a context object that can be accessed through ctx_ source,_ title, etc.
You can also add fields to the document:
POST test/_update/tHRD5XkBJY9c7kUxQBIJ
{
"script": {
"lang": "painless",
"source": "ctx._source.date=params.date",
"params":{
"date":["2021-06-07","2021-06-08"]
}
}
}
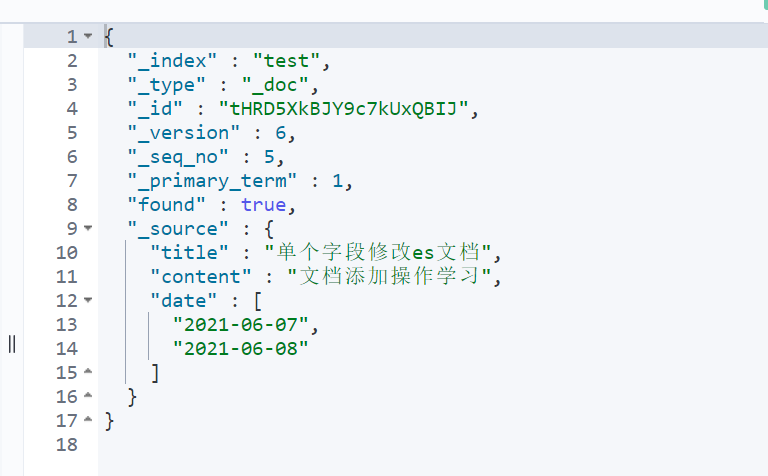
Through the scripting language, you can also modify the array. For example, add another date:
POST test/_update/tHRD5XkBJY9c7kUxQBIJ
{
"script": {
"lang": "painless",
"source": "ctx._source.date.add(\"2020-06-09\")"
}
}
You can also use if else to construct slightly more complex logic.
POST test/_update/tHRD5XkBJY9c7kUxQBIJ
{
"script": {
"lang": "painless",
"source": "if(ctx._source.title.contains(\"single\")){ctx.op=\"delete\"}else{ctx.op=\"none\"}"
}
}
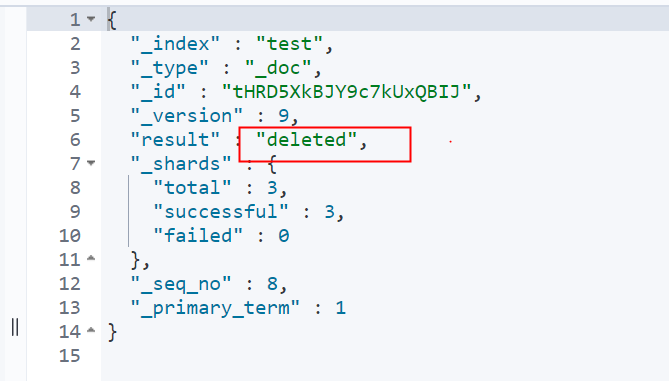
6.3.2 condition update
Find the document through conditional query, and then update it
For example, update the document containing 666 in the title
POST test/_update_by_query
{
"script": {
"lang": "painless",
"source": "ctx._source=params",
"params": {
"title":"777",
"content":"es Advanced road"
}
},
"query":{
"term": {
"title":"666"
}
}
}
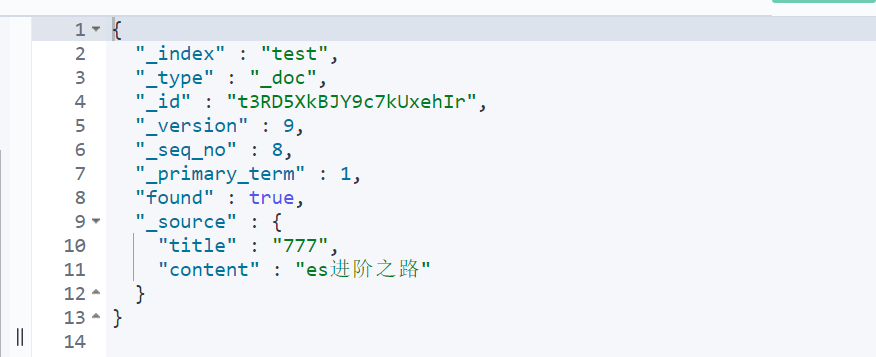
6.4 document deletion
6.4.1 delete by ID
Delete a document with ID t3RD5XkBJY9c7kUxehIr from the test index
DELETE test/_doc/t3RD5XkBJY9c7kUxehIr
If a route is specified when adding a document, you also need to specify a route when deleting a document, otherwise the deletion fails.
6.4.2 query deletion
If the document containing 777 in the title is deleted:
POST test/_delete_by_query
{
"query":{
"term":{
"title":"777"
}
}
}
Delete test_ All documents under the new index:
POST test_new/_delete_by_query
{
"query":{
"match_all":{}
}
}
6.5 batch operation
es can perform batch indexing, batch deletion, batch update and other operations through the Bulk API.
First, you need to write all batch operations into a JSON file, and then upload and execute the JSON file through POST request.
Create a new batch JSON file
{"index":{"_index":"java","_id":"5"}}
{"title":"es Batch operation"}
{"update":{"_index":"java","_id":"5"}}
{"doc":{"title":"es Modify operation"}}
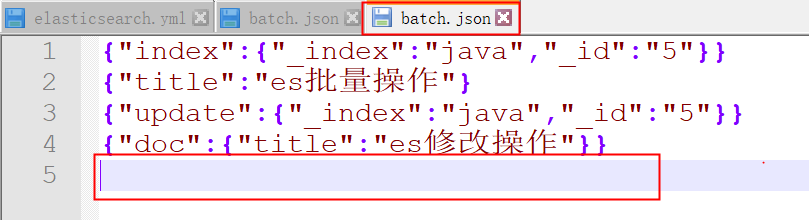
First, the first line: index indicates that an index operation is to be performed (this indicates an action, and other actions include create, delete and update)_ Index defines the index name, which means to create an index named java_ id indicates that the id of the new document is 666.
The second line is the parameters of the first line operation.
The update in the third line indicates that you want to update.
The fourth line is the parameter of the third line.
Note that you should leave a line at the end.
After the file is created successfully, execute the request command in this directory, as follows:
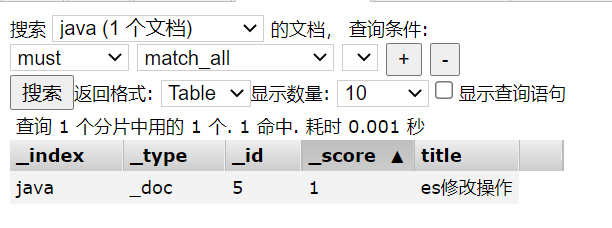
curl -XPOST "http://localhost:9200/java/_bulk" -H "content-type:application/json" --data-binary @batch.json
After execution, an index named java will be created, a record will be added to the index, and then the record will be modified. The final result is as follows
VII Document routing
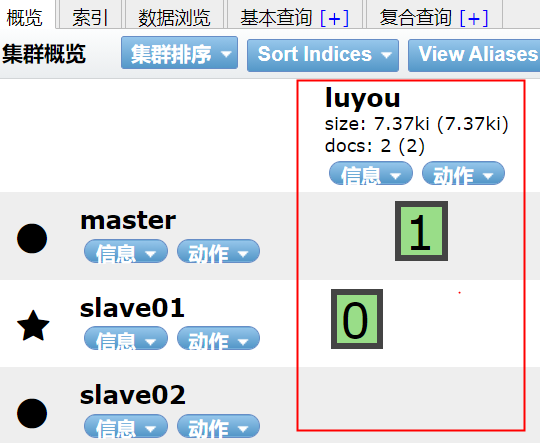
es is a distributed system. When we store a document on es, the document is actually stored on a master partition in the master node.
Create a new index with two slices and 0 copies
Save a document to the index
PUT luyou/_doc/a
{
"title":"15"
}
After the document is saved successfully, you can view the partition to which the document is saved:
GET _cat/shards/luyou?v

From this result, it can be seen that the document is saved in fragment 1.
7.1 routing rules
The routing mechanism in es is to put documents with the same hash value into a main partition through the hash algorithm. The partition location is calculated as follows:
shard=hash(routing) % number_of_primary_shards
Routing can be any string. By default, es takes the id of the document as the routing value, generates a number according to routing through the hash function, and then takes the remainder between the number and the number of fragments. The remainder result is the location of the fragments.
The biggest advantage of the default routing mode is load balancing, which can ensure that the data is evenly distributed in different slices. However, it has a big disadvantage that it cannot determine the location of the document during query. At this time, it will broadcast the request to all partitions for execution. On the other hand, using the default routing mode is inconvenient to modify the number of slices in the later stage.
Therefore, you can also customize the value of routing
PUT luyou/_doc/e?routing=userId
{
"title":"666"
}
If routing is specified when adding a document, it is also required to specify routing when querying, deleting and updating.
GET luyou/_doc/e?routing=userId
Custom routing may lead to load imbalance, which should be selected according to the actual situation.
Typical scenario:
For user data, we can use userid as routing, so as to ensure that the data of the same user is saved in the same partition. When retrieving, we also use userid as routing, so that we can accurately obtain data from a partition.
VIII Lock and version control
When we use es's API to update the document, it first reads the original document, then updates the original document, and then re indexes the whole document after the update. No matter how many updates you perform, the last updated document is saved in es. However, if two threads update at the same time, there may be problems.
To solve the problem is to lock.
8.1 lock
Pessimistic lock
Very pessimistic. Every time I read data, I think that others may modify the data, so I shield all operations that may damage data integrity. Pessimistic locks are often used in relational databases, such as row locks, table locks, and so on.
Optimistic lock
Very optimistic. Every time you read data, you think that others will not modify the data, so you don't lock the data. Only when you submit the data will you check the data integrity. This method can save the cost of locking and improve the throughput.
In es, the optimistic lock is actually used.
8.2 version control
es6. Before 7
In es6 Before 7, use version+version_type for optimistic concurrency control. According to the previous introduction, the version will be automatically incremented every time a document is modified. es through the version field, all operations can be carried out in an orderly manner.
Version is divided into internal version control and external version control.
8.2.1 build
Es maintains its own internal version. When creating a document, es will assign a value of 1 to the version of the document.
Whenever a user modifies a document, the version number will increase by 1.
If the build is used, the es requires that the value of the version parameter must be equal to the value of version in the es document before the operation can succeed.
8.2.2 external version
You can also maintain external versions.
When adding a document, specify the version number:
PUT luyou/_doc/2?version=666&version_type=external
{
"title":"12354"
}
When updating later, the version should be greater than the existing version number.
- vertion_type=external or verification_ type=external_ gt means that the version should be > the existing version number when updating in the future.
- vertion_type=external_gte means that when updating later, the version should be > = the existing version number.
8.2.3 latest scheme (after Es6.7)
Now use if_seq_no and if_primary_term two parameters for concurrency control.
seq_no does not belong to a document, it belongs to the entire index (version belongs to a document, and the versions of each document do not affect each other). Now when updating the document, use seq_no to do concurrency. Due to seq_no belongs to the whole index, so any document modification or addition, seq_no will increase by itself.
Now you can use seq_no and primary_term for optimistic concurrency control.
PUT luyou/_doc/2?if_seq_no=15&if_primary_term=1
{
"title":"12567"
}
IX Inverted index
9.1 "forward" index
The index we see in relational databases is the "forward index". When we search for articles by id or title, we can quickly find them.
However, if we search according to the keywords of the article content, we can only do character matching in the content. In order to improve query efficiency, we should consider using inverted index.
9.2 inverted index
Inverted index is to establish an index based on the keyword of the content, find the document id through the index, and then find the whole document.
Generally speaking, the inverted index is divided into two parts:
- Word dictionary (records all document word items and the association between word items and inverted list)
- Inverted list (records the relationship between words and their correspondence, which is composed of a series of inverted index items. Inverted index items refer to: document id, word frequency (TF) (the number of times words appear in the document and used in scoring), Position (the Position of word segmentation in the document), and offset (records the Position of the beginning and end of word items). When we index a document, The inverted index will be established. When searching, search directly according to the inverted index.
X Dynamic mapping and dynamic mapping
Mapping is mapping, which is used to define a document and how the fields contained in the document should be stored and indexed. Therefore, it is actually a bit similar to the definition of table fields in relational databases.
10.1 mapping classification
Dynamic mapping
As the name suggests, it is a map created automatically. es automatically analyzes the type and storage mode of fields in the document according to the stored document. This is dynamic mapping.
As a simple example, create a new index and insert a document
PUT luyou/_doc/2
{
"title":"Dynamic mapping",
"remark":"2020-06-11"
}
After the document is successfully added, Mappings will be automatically generated:
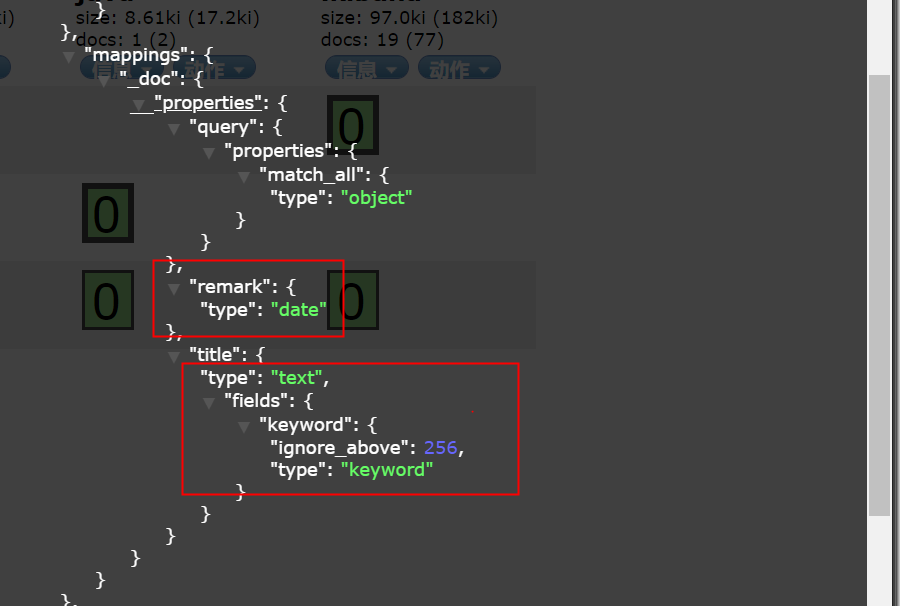
You can see that the type of remark field is date, and there are two types of title, text and keyword.
By default, if a field is added in the document, it will be automatically added in mappings.
Sometimes, if you want to add a field, you can throw an exception to remind the developer. This can be configured through the dynamic attribute in mappings.
- true, the default is this. Automatically add new fields.
- false to ignore the new field.
- Strict, strict mode. Exceptions will be thrown when new fields are found.
The specific configuration method is as follows: specify mappings when creating an index (this is actually static mapping):
PUT java
{
"mappings": {
"dynamic": "strict",
"properties": {
"title": {
"type": "text"
},
"id": {
"type": "long"
}
}
}
}
In the added document, there is an additional name field, which is not predefined, so the addition operation will report an error:
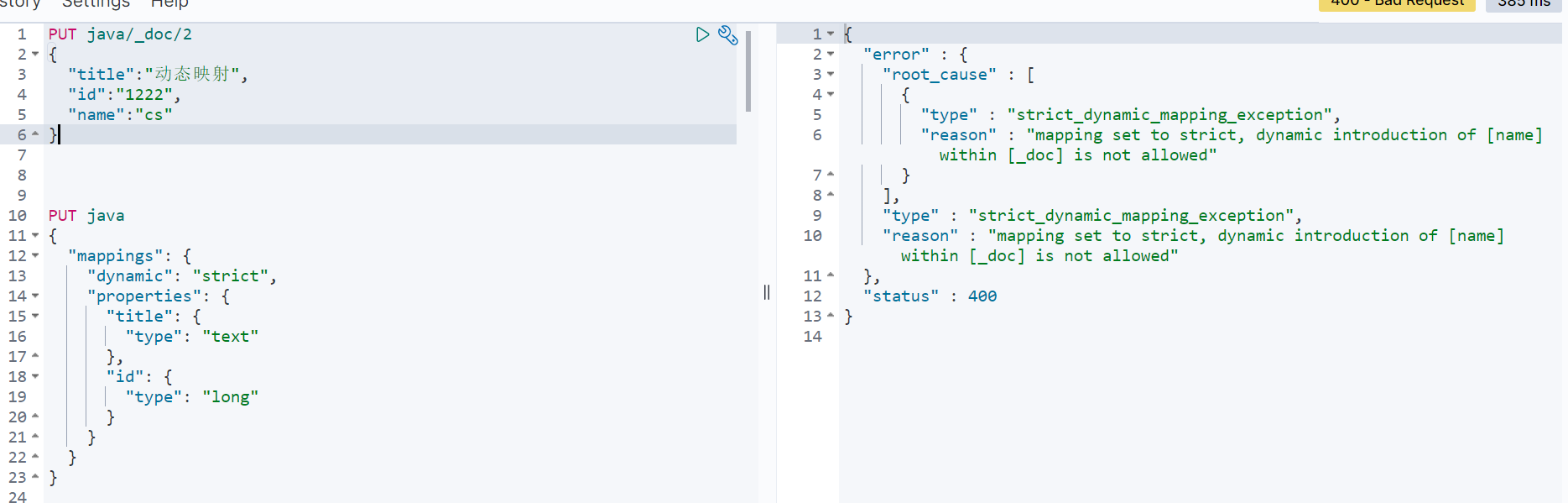
Dynamic mapping also has a problem of date detection.
For example, create a new index, and then add a document with a date, as follows:
PUT java/_doc/2
{
"title":"Dynamic mapping",
"remark":"2020-06-11"
}
After successful addition, the remark field will be inferred as a date type. At this point, the remark field cannot store other types.
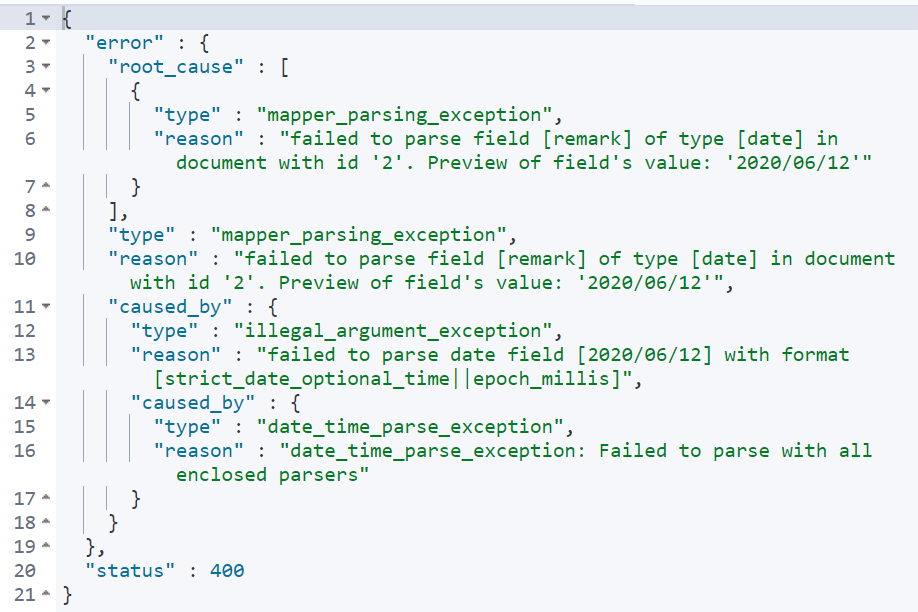
To solve this problem, you can use static mapping, that is, when defining the index, specify remark as text type. You can also turn off date detection.
PUT java
{
"mappings": {
"date_detection": false
}
}
At this time, the date type will be processed as a written document.
10.2 type inference
The inference method of dynamic mapping type in es is as follows:
| Stored data | Inferred type |
|---|---|
| null | No fields were added |
| true/false | boolean |
| Floating point number | float |
| number | long |
| JSON object | object |
| array | The first non null value in the array |
| string | text/keyword/date/double/long... Is possible |
Xi ES field type details
11.1 string type
- String: This is an expired string type. Before es5, this was used to describe strings, which has now been replaced by text and keyword.
- Text: if a field is to be retrieved in full text, such as blog content, news content and product description, text can be used. After using text, the field content will be analyzed. Before generating the inverted index, the string will be divided into word items by the word splitter. Fields of type text are not used for sorting and are rarely used for aggregation. This string is also called an analyzed field.
- keyword: this type is applicable to structured fields, such as tag, email address, mobile phone number, etc. this type of field can be used for filtering, sorting, aggregation, etc. This string is also called a not analyzed field.
11.2 digital type
| type | Value range |
|---|---|
| byte | -128~127 |
| short | -2^15 ~ -2^15-1 |
| integer | -2^31 ~ -2^31-1 |
| long | -2^63 ~ -2^63-1 |
| double | 64 bit double precision IEEE754 floating point type |
| float | 32-bit double precision IEEE754 floating point |
| half_float | 16 bit double precision IEEE754 floating point |
| scaled_float | Floating point type of scaling type |
- When the requirements are met, give priority to fields with small scope. The shorter the field length, the more efficient the index and search.
- Floating point number, scaled is preferred_ float
PUT subject
{
"mappings": {
"properties": {
"id":{
"type": "short"
},
"name":{
"type": "keyword"
},
"price":{
"type": "scaled_float",
"scaling_factor": 100
}
}
}
}
11.3 date type
Because there is no date type in JSON, the date types in es have various forms:
- 2020-11-11 or 2020-11-11 11:11
- A second or millisecond from zero on January 1, 1970 to the present.
- es internally converts the time to UTC, and then stores the time according to the long integer of millseconds since the epoch.
Custom date type:
PUT subject
{
"mappings": {
"properties": {
"id":{
"type": "short"
},
"name":{
"type": "keyword"
},
"price":{
"type": "scaled_float",
"scaling_factor": 100
},
"date":{
"type": "date"
}
}
}
}
PUT subject/_doc/1
{
"id":1,
"name":"java",
"price":19.99,
"date":"2021-06-15",
"remark":"java Programming thought"
}
PUT subject/_doc/2
{
"id":1,
"name":"java",
"price":19.99,
"date":"2021-06-15T12:19:29Z",
"remark":"java Programming thought"
}
PUT subject/_doc/3
{
"id":1,
"name":"java",
"price":19.99,
"date":"1623752415002",
"remark":"java Programming thought"
}

The dates in these three documents can be parsed, and the internal storage is a long integer number timed in milliseconds.
11.4 boolean type
"True", "false", "true" and "false" in JSON are OK.
11.5 binary type
Binary accepts base64 encoded strings, which are not stored or searchable by default.
11.6 scope and type
- integer_range
- float_range
- long_range
- double_range
- date_range
- ip_range
PUT subject
{
"mappings": {
"properties": {
"price":{
"type": "float_range"
}
}
}
}
PUT subject/_doc/1
{
"name":"subject",
"price": {
"gt": 10,
"lt": 20
}
}
When specifying a range, you can use gt, gte, lt, lte.
11.7 composite type
11.7.1 array type
There is no special array type in es. By default, any field can have one or more values. Note that the elements in the array must be of the same type.
When adding an array, the first element in the array determines the type of the entire array.
PUT subject/_doc/3
{
"name":["java","php"],
"ext_info":{
"remark":"object type"
}
}
11.7.2 object type
Because JSON itself has a hierarchical relationship, the document contains internal objects. Internal objects can also be included.
PUT subject/_doc/2
{
"name":"subject",
"ext_info":{
"remark":"object type"
}
}
11.7.3 nesting type
nested is a special case of object.
If the object type is used, suppose there is one of the following documents:
{
"user":[
{
"first":"Zhang",
"last":"san"
},
{
"first":"Li",
"last":"si"
}
]
}
Because Lucene does not have the concept of internal objects, es will flatten the object hierarchy and turn an object into a simple list composed of field names and values. The final storage form of the above document is as follows:
{
"user.first":["Zhang","Li"],
"user.last":["san","si"]
}
After flattening, the relationship between user names is gone. This will lead to a search for Zhang si.
In this case, the problem can be solved by using the nested object type, which can maintain the independence of each object in the array. Nested type indexes each object in the array as an independent hidden document, so that each nested object can be indexed independently.
{
{
"user.first":"Zhang",
"user.last":"san"
},{
"user.first":"Li",
"user.last":"si"
}
}
Advantages: documents are stored together with high reading performance.
Disadvantages: when updating parent or child documents, you need to update more documents.
11.8 geographical type
Usage scenario
- Find a geographic location within a range
- Documents are aggregated by geographic location or distance from the center point
- Sort documents by distance
11.8.1 geo_point
geo_point is a coordinate point, which is defined as follows:
PUT shape
{
"mappings": {
"properties": {
"location":{
"type": "geo_point"
}
}
}
}
Specify the field type during creation. There are four ways to store it:
PUT shape/_doc/2
{
"location":{
"lon":100,
"lat":33
}
}
PUT shape/_doc/1
{
"location":"33,100"
}
PUT shape/_doc/3
{
"location":"uzbrgzfxuzup"
}
PUT shape/_doc/4
{
"location":[100,33]
}
Note that using an array description, longitude first and then latitude.
Address location to geo_hash: http://www.csxgame.top/#/
11.8.2 geo_shape
| GeoJSON | ES | remarks |
|---|---|---|
| Point | point | A point described by latitude and longitude |
| LineString | linestring | A line consisting of any two or more points |
| Polygon | polygon | A closed polygon |
| MultiPoint | multipoint | A set of discontinuous points |
| MultiLineString | multilinestring | Multiple unrelated lines |
| MutliPolygon | mutlipolygon | Multiple polygons |
| GeometryCollection | geometrycollection | Collection of several objects |
| / | circle | circular |
| / | envelope | A rectangle defined by the upper left and lower right corners |
Specify geo when creating index_ Shape type:
PUT shape
{
"mappings": {
"properties": {
"location":{
"type": "geo_shape"
}
}
}
}
When adding a document, you need to specify a specific type:
PUT shape/_doc/1
{
"location":{
"type":"point",
"coordinates":[100,33]
}
}
PUT shape/_doc/2
{
"location":{
"type":"linestring",
"coordinates":[[100,33],[200,10]]
}
}
11.9 special types
11.9.1 IP
Store ip address, type ip:
PUT shape
{
"mappings": {
"properties": {
"address":{
"type": "ip"
}
}
}
}
Add document
PUT shape/_doc/1
{
"address":"192.168.1.1"
}
Search documents
GET shape/_search
{
"query": {
"term": {
"address": "192.168.0.0/16"
}
}
}
11.9.2 token_count
Used to count the number of word items after string word segmentation.
PUT shape
{
"mappings": {
"properties": {
"title": {
"type": "text",
"fields": {
"length": {
"type": "token_count",
"analyzer": "standard"
}
}
}
}
}
}
It is equivalent to adding a new title The length field is used to count the number of word items after word segmentation.
Add document:
PUT shape/_doc/1
{
"title":"li si"
}
There are two words after word segmentation, so you can use token_count to query:
GET shape/_search
{
"query": {
"term": {
"title.length": 2
}
}
}
11.10 analyzer
Defines the word breaker for the text field. The default is valid for both indexes and queries.
Assuming that there is no word splitter, let's take a look at the index results, create an index and add a document:
PUT news
PUT news/_doc/1
{
"title":"She may laugh at the blunt chat-up,Or maybe I think I have a crush on her"
}
View term vectors
GET news/_termvectors/1
{
"fields": ["title"]
}
The results are as follows:
{
"_index" : "news",
"_type" : "_doc",
"_id" : "1",
"_version" : 1,
"found" : true,
"took" : 0,
"term_vectors" : {
"title" : {
"field_statistics" : {
"sum_doc_freq" : 19,
"doc_count" : 1,
"sum_ttf" : 22
},
"terms" : {
"by" : {
"term_freq" : 1,
"tokens" : [
{
"position" : 15,
"start_offset" : 16,
"end_offset" : 17
}
]
},
"also" : {
"term_freq" : 1,
"tokens" : [
{
"position" : 11,
"start_offset" : 12,
"end_offset" : 13
}
]
},
"with" : {
"term_freq" : 1,
"tokens" : [
{
"position" : 14,
"start_offset" : 15,
"end_offset" : 16
}
]
},
"can" : {
"term_freq" : 2,
"tokens" : [
{
"position" : 1,
"start_offset" : 1,
"end_offset" : 2
},
{
"position" : 12,
"start_offset" : 13,
"end_offset" : 14
}
]
},
"she" : {
"term_freq" : 2,
"tokens" : [
{
"position" : 0,
"start_offset" : 0,
"end_offset" : 1
},
{
"position" : 18,
"start_offset" : 19,
"end_offset" : 20
}
]
},
"good" : {
"term_freq" : 1,
"tokens" : [
{
"position" : 20,
"start_offset" : 21,
"end_offset" : 22
}
]
},
"yes" : {
"term_freq" : 1,
"tokens" : [
{
"position" : 17,
"start_offset" : 18,
"end_offset" : 19
}
]
},
"sense" : {
"term_freq" : 1,
"tokens" : [
{
"position" : 21,
"start_offset" : 22,
"end_offset" : 23
}
]
},
"I" : {
"term_freq" : 1,
"tokens" : [
{
"position" : 16,
"start_offset" : 17,
"end_offset" : 18
}
]
},
"Take" : {
"term_freq" : 1,
"tokens" : [
{
"position" : 9,
"start_offset" : 9,
"end_offset" : 10
}
]
},
"have" : {
"term_freq" : 1,
"tokens" : [
{
"position" : 19,
"start_offset" : 20,
"end_offset" : 21
}
]
},
"living" : {
"term_freq" : 1,
"tokens" : [
{
"position" : 6,
"start_offset" : 6,
"end_offset" : 7
}
]
},
"of" : {
"term_freq" : 1,
"tokens" : [
{
"position" : 8,
"start_offset" : 8,
"end_offset" : 9
}
]
},
"hard" : {
"term_freq" : 1,
"tokens" : [
{
"position" : 7,
"start_offset" : 7,
"end_offset" : 8
}
]
},
"laugh" : {
"term_freq" : 1,
"tokens" : [
{
"position" : 3,
"start_offset" : 3,
"end_offset" : 4
}
]
},
"can" : {
"term_freq" : 2,
"tokens" : [
{
"position" : 2,
"start_offset" : 2,
"end_offset" : 3
},
{
"position" : 13,
"start_offset" : 14,
"end_offset" : 15
}
]
},
"Accost" : {
"term_freq" : 1,
"tokens" : [
{
"position" : 10,
"start_offset" : 10,
"end_offset" : 11
}
]
},
"word" : {
"term_freq" : 1,
"tokens" : [
{
"position" : 4,
"start_offset" : 4,
"end_offset" : 5
}
]
},
"this" : {
"term_freq" : 1,
"tokens" : [
{
"position" : 5,
"start_offset" : 5,
"end_offset" : 6
}
]
}
}
}
}
}
It can be seen that by default, Chinese is a word by word segmentation, which has no meaning. If the word is segmented in this way, the query can only be performed word by word, as follows:
GET news/_search
{
"query": {
"term": {
"title": {
"value": "can"
}
}
}
}
Therefore, we should configure an appropriate word splitter according to the actual situation.
Set a word breaker for the field:
PUT news
{
"mappings": {
"properties": {
"title":{
"type": "text",
"analyzer": "ik_max_word"
}
}
}
}
Store documents
PUT news/_doc/1
{
"title":"She may laugh at the blunt chat-up,Or maybe I think I have a crush on her"
}
View entries after word segmentation
{
"_index" : "news",
"_type" : "_doc",
"_id" : "1",
"_version" : 4,
"found" : true,
"took" : 2,
"term_vectors" : {
"title" : {
"field_statistics" : {
"sum_doc_freq" : 56,
"doc_count" : 4,
"sum_ttf" : 60
},
"terms" : {
"also" : {
"term_freq" : 1,
"tokens" : [
{
"position" : 7,
"start_offset" : 12,
"end_offset" : 13
}
]
},
"think" : {
"term_freq" : 1,
"tokens" : [
{
"position" : 10,
"start_offset" : 15,
"end_offset" : 17
}
]
},
"probably" : {
"term_freq" : 2,
"tokens" : [
{
"position" : 1,
"start_offset" : 1,
"end_offset" : 3
},
{
"position" : 8,
"start_offset" : 13,
"end_offset" : 15
}
]
},
"She can" : {
"term_freq" : 1,
"tokens" : [
{
"position" : 0,
"start_offset" : 0,
"end_offset" : 2
}
]
},
"She has" : {
"term_freq" : 1,
"tokens" : [
{
"position" : 13,
"start_offset" : 19,
"end_offset" : 21
}
]
},
"Favor" : {
"term_freq" : 1,
"tokens" : [
{
"position" : 14,
"start_offset" : 21,
"end_offset" : 23
}
]
},
"yes" : {
"term_freq" : 1,
"tokens" : [
{
"position" : 12,
"start_offset" : 18,
"end_offset" : 19
}
]
},
"I" : {
"term_freq" : 1,
"tokens" : [
{
"position" : 11,
"start_offset" : 17,
"end_offset" : 18
}
]
},
"Accost" : {
"term_freq" : 1,
"tokens" : [
{
"position" : 6,
"start_offset" : 9,
"end_offset" : 11
}
]
},
"Stiff" : {
"term_freq" : 1,
"tokens" : [
{
"position" : 4,
"start_offset" : 6,
"end_offset" : 8
}
]
},
"of" : {
"term_freq" : 1,
"tokens" : [
{
"position" : 5,
"start_offset" : 8,
"end_offset" : 9
}
]
},
"joke" : {
"term_freq" : 1,
"tokens" : [
{
"position" : 2,
"start_offset" : 3,
"end_offset" : 5
}
]
},
"Can take" : {
"term_freq" : 1,
"tokens" : [
{
"position" : 9,
"start_offset" : 14,
"end_offset" : 16
}
]
},
"this" : {
"term_freq" : 1,
"tokens" : [
{
"position" : 3,
"start_offset" : 5,
"end_offset" : 6
}
]
}
}
}
}
}
Then you can search through words
11.11 search_analyzer
A word splitter used in query. By default, if search is not configured_ Analyzer, when querying, first check whether there is a search_analyzer, if any, use search_analyzer is used for word segmentation. If not, it depends on whether there is an analyzer. If yes, it is used for word segmentation. Otherwise, the es default word splitter is used.
11.12 normalizer
The normalizer parameter is used to standardize the configuration before parsing (index or query).
For example, in es, for some strings we don't want to segment, we usually set them as keyword, and the whole word is used for search. If there is no data cleaning before indexing, resulting in inconsistent case, we can use normalizer to standardize documents before indexing and query.
Let's start with a counterexample
PUT subject
{
"mappings": {
"properties": {
"title":{
"type": "keyword"
}
}
}
}
PUT subject/_doc/1
{
"title":"english"
}
PUT subject/_doc/2
{
"title":"ENGLISH"
}
search
GET subject/_search
{
"query": {
"term": {
"title": {
"value": "english"
}
}
}
}
Upper case keywords can find upper case documents, and lower case keywords can find lower case documents.
If normalizer is used, the documents can be preprocessed respectively during indexing and query.
normalizer is defined as follows:
PUT subject
{
"settings": {
"analysis": {
"normalizer":{
"case_filtering":{
"type":"custom",
"filter":["lowercase"]
}
}
}
},
"mappings": {
"properties": {
"title":{
"type": "keyword",
"normalizer": "case_filtering"
}
}
}
}
Define normalizer in settings, and then refer to it in mappings.
The test method is the same as before. At this time, when querying, upper case keywords can also query lower case documents, because both indexes and queries will convert upper case to lower case.
11.13 boost
The boost parameter can set the weight of the field.
There are two ways to use boost. One is to use it when defining mappings and when specifying field types; The other is used in query.
The latter is recommended in actual development. The former has a problem: if the document is not re indexed, the weight cannot be modified.
Use boost in mapping (not recommended):
PUT subject
{
"mappings": {
"properties": {
"title": {
"type": "text",
"analyzer": "ik_max_word",
"boost": 3
}
}
}
}
Another way is to specify boost when querying
GET subject/_search
{
"query": {
"match": {
"title": {
"query":"Where",
"boost": 0.051977858
}
}
}
}
11.14 coerce
coerce is used to clear dirty data. The default value is true.
For example, when defining an index, the mapping type of a field is integer. By default, when inserting a number of string type, it can be inserted successfully
PUT subject
{
"mappings": {
"properties": {
"age":{
"type": "integer"
, "coerce": false
}
}
}
}
In this way, an error will be reported when inserting a number of string type
PUT subject/_doc/3
{
"age":"100.00"
}
When the coerce is changed to false, the number can only be a number, not a string, and an error will be reported when the string is passed in from this field.
11.15 copy_to
This attribute can copy the values of multiple fields to the same field.
The definition is as follows:
PUT subject
{
"mappings": {
"properties": {
"age":{
"type": "text",
"copy_to": "backup"
},
"name":{
"type": "text",
"copy_to": "backup"
},
"backup":{
"type": "text"
}
}
}
}
Insert document
PUT subject/_doc/1
{
"age":100,
"name":"student"
}
Query according to the backup field
GET subject/_search
{
"query": {
"term": {
"backup": {
"value": "100"
}
}
}
}
11.16 doc_values and fielddata
The search in es mainly uses inverted index, Doc_ The values parameter is generated to speed up sorting and aggregation operations. When an inverted index is established, an additional columnar storage mapping will be added.
doc_values is on by default. If you are sure that a field does not need sorting or aggregation, you can close doc_values.
Most fields will generate doc when indexing_ Values, except text. The text field will generate a fielddata data data structure during query, and fieldata will be generated when the field is aggregated and sorted for the first time.
PUT subject
{
"mappings": {
"properties": {
"age": {
"type": "integer"
}
}
}
}
PUT subject/_doc/1
{
"age":100
}
PUT subject/_doc/2
{
"age":99
}
PUT subject/_doc/4
{
"age":101
}
PUT subject/_doc/3
{
"age":98
}
Sort query
GET subject/_search
{
"query": {
"match_all": {}
},
"sort": [
{
"age": {
"order": "desc"
}
}
]
}
Query results
{
"took" : 29,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 4,
"relation" : "eq"
},
"max_score" : null,
"hits" : [
{
"_index" : "subject",
"_type" : "_doc",
"_id" : "4",
"_score" : null,
"_source" : {
"age" : 101
},
"sort" : [
101
]
},
{
"_index" : "subject",
"_type" : "_doc",
"_id" : "1",
"_score" : null,
"_source" : {
"age" : 100
},
"sort" : [
100
]
},
{
"_index" : "subject",
"_type" : "_doc",
"_id" : "2",
"_score" : null,
"_source" : {
"age" : 99
},
"sort" : [
99
]
},
{
"_index" : "subject",
"_type" : "_doc",
"_id" : "3",
"_score" : null,
"_source" : {
"age" : 98
},
"sort" : [
98
]
}
]
}
}
Due to doc_values is enabled by default, so you can directly use this field to sort. If you want to close doc_values, as follows:
PUT subject
{
"mappings": {
"properties": {
"age": {
"type": "integer",
"doc_values": false
}
}
}
}
Add doc_ When values is set to false, an error will be reported when sorting the query
{
"error" : {
"root_cause" : [
{
"type" : "illegal_argument_exception",
"reason" : "Can't load fielddata on [age] because fielddata is unsupported on fields of type [integer]. Use doc values instead."
}
],
"type" : "search_phase_execution_exception",
"reason" : "all shards failed",
"phase" : "query",
"grouped" : true,
"failed_shards" : [
{
"shard" : 0,
"index" : "subject",
"node" : "2C6CVJeaRAamI41ffmlvzg",
"reason" : {
"type" : "illegal_argument_exception",
"reason" : "Can't load fielddata on [age] because fielddata is unsupported on fields of type [integer]. Use doc values instead."
}
}
],
"caused_by" : {
"type" : "illegal_argument_exception",
"reason" : "Can't load fielddata on [age] because fielddata is unsupported on fields of type [integer]. Use doc values instead.",
"caused_by" : {
"type" : "illegal_argument_exception",
"reason" : "Can't load fielddata on [age] because fielddata is unsupported on fields of type [integer]. Use doc values instead."
}
}
},
"status" : 400
}
 doc_values is on by default and fielddata is off by default.
doc_values is on by default and fielddata is off by default.
11.17 dynamic
Sometimes, if you want to add a field, you can throw an exception to remind the developer. This can be configured through the dynamic attribute in mappings.
- true, the default is this. Automatically add new fields.
- false to ignore the new field.
- Strict, strict mode. Exceptions will be thrown when new fields are found.
11.18 enabled
es will index all fields by default, but some fields may only need to be stored without index. In this case, you can control through the enabled field:
PUT subject
{
"mappings": {
"properties": {
"age": {
"enabled":false
}
}
}
}
PUT subject/_doc/1
{
"age":100
}
GET subject/_search
{
"query": {
"term": {
"age": {
"value": "100"
}
}
}
}
At this point, you can't search with age
11.19 format
Date format. Format can standardize the date format, and multiple formats can be defined at a time.
PUT subject
{
"mappings": {
"properties": {
"date": {
"type": "date",
"format": "yyyy-MM-dd||yyyy/MM/dd||yyyy/MM/dd HH:mm:ss"
}
}
}
}
PUT subject/_doc/1
{
"date":"2021-06-18"
}
PUT subject/_doc/2
{
"date":"2021/06/18"
}
PUT subject/_doc/3
{
"date":"2021/06/18 16:20:30"
}
Multiple date formats are connected by the | symbol. Note that there are no spaces.
If the user does not specify a date format, the default date format is strict_date_optional_time||epoch_mills
See the official website for all date formats supported by es https://www.elastic.co/guide/en/elasticsearch/reference/current/mapping-date-format.html
11.20 ignore_above
igbore_above is used to specify the maximum length of word segmentation and index string. If the maximum length is exceeded, this field will not be indexed. This field is only applicable to keyword type.
PUT subject
{
"mappings": {
"properties": {
"name":{
"type": "keyword",
"ignore_above": 10
}
}
}
}
PUT subject/_doc/2
{
"name":"zhangsanzhangsan"
}
PUT subject/_doc/1
{
"name":"zhangsan"
}
GET subject/_search
{
"query": {
"term": {
"name": {
"value": "zhangsanzhangsan"
}
}
}
}
At this time, because the name length of the document with id 2 is greater than 10, the document cannot be queried according to the name field
11.21 ignore_malformed
ignore_malformed can ignore irregular data. This parameter is false by default.
PUT subject
{
"mappings": {
"properties": {
"age":{
"type": "integer",
"ignore_malformed": true
}
}
}
}
PUT subject/_doc/2
{
"age":"10"
}
PUT subject/_doc/1
{
"age":"zhangsan"
}
When defining an index rule, if the inserted document field type does not match the predefined, an error will be reported by default, but when this field is set to false, the insertion will succeed and the rule of this type will be ignored
11.22 index
PUT subject
{
"mappings": {
"properties": {
"age":{
"type": "integer",
"index": false
}
}
}
}
The index attribute specifies whether a field is indexed. If the attribute is true, it means that the field is indexed, and if false, it means that the field is not indexed. At this point, you cannot query the document through the age field
11.23 index_options
index_options controls which information is stored in the inverted index (used in the text field) during indexing. There are four values:
| index_options | remarks |
|---|---|
| docs | Only the document number is stored. This is the default |
| freqs | Store word item frequency based on docs |
| position | Store the word item offset position on the basis of freqs |
| offsets | Store the character positions of the beginning and end of the word item based on position |
11.24 norms
Normals is useful for field scoring. text enables normals by default. If it is not particularly necessary, do not enable normals.
11.25 null_value
PUT subject
{
"mappings": {
"properties": {
"age":{
"type": "integer",
"null_value": 0
}
}
}
}
PUT subject/_doc/2
{
"age":null,
"name":"java"
}
GET subject/_search
{
"query": {
"term": {
"age": {
"value": 0
}
}
}
}
In es, fields with null values are neither indexed nor searchable_ Value can make null fields explicitly indexable and searchable

11.26 position_increment_gap
The parsed text field will take the position of term into account in order to support approximate query and phrase query. When we index a text field with multiple values, an imaginary space will be added between the values to separate the values, so as to effectively avoid some meaningless phrase matching. The gap size is through position_increment_gap to control, the default is 100.
PUT subject
{
"mappings": {
"properties": {
"age":{
"type": "text"
}
}
}
}
PUT subject/_doc/2
{
"age":["ceshi","guanjianci"]
}
GET subject/_search
{
"query": {
"match_phrase": {
"age": {
"query": "ceshi guanjianci"
}
}
}
}
The gap size can be specified by slop.
GET subject/_search
{
"query": {
"match_phrase": {
"age": {
"query": "ceshi guanjianci",
"slop": 100
}
}
}
}
In this way, you can search, or specify the gap when defining the index:
PUT subject
{
"mappings": {
"properties": {
"age":{
"type": "text",
"position_increment_gap": 0
}
}
}
}
11.27 similarity
similarity specifies the scoring model of the document. There are three types by default:
| similarity | remarks |
|---|---|
| BM25 | es and lucene default evaluation model |
| classic | TF/IDF score |
| boolean | boolean model score |
11.28 store
By default, fields can be indexed or searched, but they will not be stored. Although they will not be stored, but_ There is a backup of a field in source. If you want to store fields, you can configure store.
11.29 fields
The fields parameter allows the same field to be indexed in many different ways. For example:
PUT subject
{
"mappings": {
"properties": {
"name":{
"type": "text",
"fields": {
"remark":{
"type":"keyword"
}
}
}
}
}
}
GET subject/_search
{
"query": {
"term": {
"name.remark": {
"value": "php"
}
}
}
}
XII ES document search
Import exercise data first Data file download
12.1 document index (import)
Create a new index and define index rules
PUT books
{
"mappings": {
"properties": {
"name":{
"type": "text",
"analyzer": "ik_max_word"
},
"publish":{
"type": "text",
"analyzer": "ik_max_word"
},
"type":{
"type": "text",
"analyzer": "ik_max_word"
},
"author":{
"type": "keyword"
},
"info":{
"type": "text",
"analyzer": "ik_max_word"
},
"price":{
"type": "double"
}
}
}
}
Batch import data
curl -XPOST "http://localhost:9200/books/_bulk?pretty" -H "content-type:application/json" --data-binary @bookdata.json
12.2 query all
Search is divided into two processes:
-
When you save a document to an index, by default, es saves two copies, one of which is_ The other is the inverted index file generated through a series of processes such as word segmentation and sorting. The inverted index saves the corresponding relationship between word items and documents.
-
During search, when es receives the search request from the user, it will query in the inverted index, find the document set corresponding to the keyword through the inverted record table maintained in the inverted index, score, sort and highlight the documents, and return to the document after processing
GET books/_search
{
"query": {
"match_all": {}
}
}
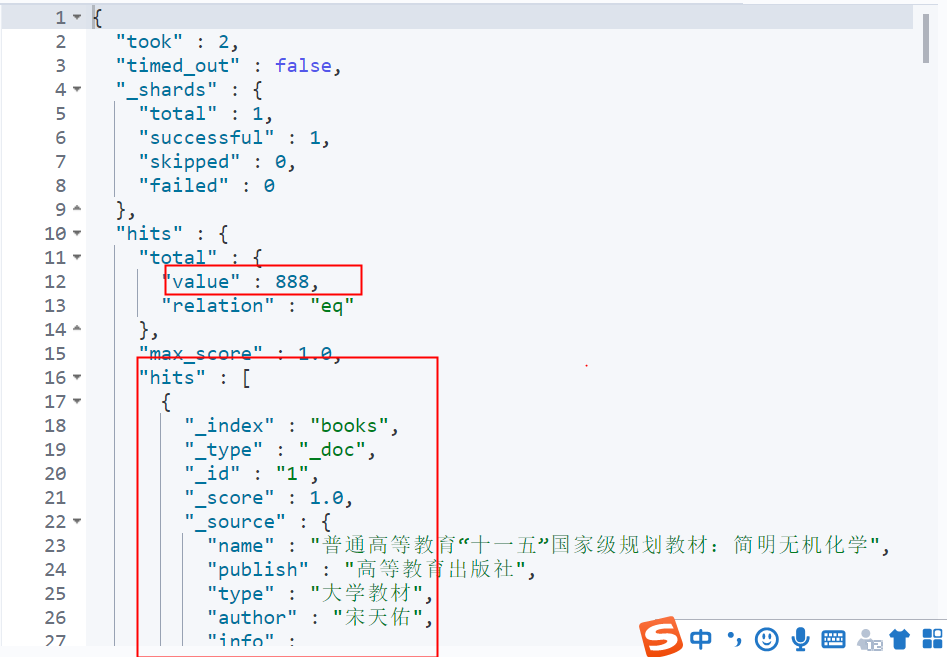
10 records are queried by default.
12.3 term query
12.3.1 term query
GET books/_search
{
"query": {
"term": {
"name": {
"value": "international"
}
}
},
"min_score":5.2,
"size":10,
"from":0,
"_source": ["name","price"],
"highlight": {
"fields": {
"name": {}
}
}
}
Term: query according to the word. Query the document containing the given word in the specified field. The term query is not parsed. The document will be returned only if the searched word exactly matches the word in the document. Application scenarios, such as person name, place name, etc.
size: paging query parameter, the number of items displayed per page
From: paging offset, starting from 0
_ source: returns the specified field
min_score: only documents with a score above the lowest score will be queried
highlight: query keyword highlighting

12.3.2 terms query
Term query, but you can give multiple keywords
GET books/_search
{
"query": {
"terms": {
"name":["country","java"]
}
}
}
12.3.3 range query
Range query: you can query by date range, number range, etc.
GET books/_search
{
"query": {
"range": {
"price": {
"gte": 10,
"lte": 20
}
}
},
"sort": [
{
"price": {
"order": "desc"
}
}
]
}
12.3.4 exists query
Returns a document with a non null field (an empty string is also non null)
GET books/_search
{
"query": {
"exists": {
"field": "author"
}
}
}
12.3.5 prefix query
Query the prefix of a given keyword:
GET books/_search
{
"query": {
"prefix": {
"author": {
"value": "Song Dynasty"
}
}
}
}
12.3.6 wildcard query
Wildcard query. Supports single character and multi character wildcards:
- ? Represents an arbitrary character.
- *Represents zero or more characters.
GET books/_search
{
"query": {
"wildcard": {
"author": {
"value": "Song Dynasty*"
}
}
}
}
12.3.7 regexp query
Regular expression queries are supported.
Check the books of all authors whose surname is Zhang and whose name is only two words:
GET books/_search
{
"query": {
"regexp": {
"author": {
"value": "Zhang."
}
}
}
}
12.3.8 fuzzy query
In the actual search, sometimes we may type wrong words, resulting in no search. In match query, fuzzy query can be realized through the fuzziness attribute.
fuzzy query returns documents similar to search keywords. What if it's similar? The distance edited by LevenShtein shall prevail. Editing distance refers to the number of character changes required to change one character into another. There are four main changes:
- Change character (javb – > java)
- Delete characters (javva – > java)
- Insert character (jaa – > java)
- Transpose character (ajva – > java)
In order to find similar words, fuzzy query will create a set of all possible changes or extensions of search keywords in the specified editing distance, and then search and match.
GET books/_search
{
"query": {
"fuzzy": {
"name": {
"value": "jvva"
}
}
}
}
12.3.9 ids query
You can batch query multiple ID collection documents
GET books/_search
{
"query": {
"ids": {
"values": [1,2,3]
}
}
}
12.4 full text query
12.4.1 match query
GET books/_search
{
"query": {
"match": {
"name": {
"query": "Computer application",
"operator": "and"
}
}
}
}
match query will segment the query statement. After word segmentation, if any word item in the query statement is matched, the document will be indexed.
This query will first segment the computer application, AND then query. As long as the document contains a word segmentation result, it will return to the document. In other words, the default relationship between terms is OR. If you want to modify it, you can also change it to AND. At this time, it is required that the document must contain both application AND computer.
12.4.2 match_phrase query
GET books/_search
{
"query": {
"match_phrase": {
"name": {
"query": "Application computer",
"slop": 10
}
}
}
}
Query is the keyword of the query, which will be decomposed by the word splitter, and then matched in the inverted index.
Slop refers to the minimum distance between keywords, but note that it is not the number of words between keys. After the fields in the document are parsed by the word splitter, the parsed word items contain a position field to represent the position of the word item. The interval between positions after query phrase word segmentation should meet the requirements of slop.
match_phrase query also performs word segmentation for query keywords, but it has two characteristics after word segmentation:
- The order of word items after word segmentation must be consistent with the order of word items in the document
- All words must appear in the document
12.4.3 match_phrase_prefix query
This is similar to match_phrase query, but there is a wildcard, match_phrase_prefix supports the prefix matching of the last word item, but because this matching method is inefficient, it is enough to understand.
GET books/_search
{
"query": {
"match_phrase_prefix": {
"name": {
"query": "meter",
"max_expansions": 10
}
}
}
}
In this query process, word matching will be performed automatically, and words starting with will be found automatically. The default number is 50. You can use max_expansions field control
match_phrase_prefix is a query at the slice level, assuming max_ If the expansions is 1, multiple documents may be returned, but there is only one word, which is our expected result. Sometimes the actual returned results are inconsistent with our expected results because the query is fragment level. Different fragments do return only one word, but the results may come from different fragments, so you will eventually see multiple words.
12.4.4 multi_match query
You can specify multiple query fields:
GET books/_search
{
"query": {
"multi_match": {
"query": "school",
"fields": ["name","info^3"]
}
}
}
In this query method, you can also specify the weight of the field ^ 3, which means that the weight appearing in info is three times that appearing in name
12.4.5 query_string query
query_string is a query method closely combined with Lucene. Some query syntax of Lucene can be used in a query statement:
GET books/_search
{
"query": {
"query_string": {
"query": "Calculation of the Eleventh Five Year Plan",
"default_field": "name",
"default_operator": "AND"
}
}
}
12.4.6 simple_query_string
GET books/_search
{
"query": {
"simple_query_string": {
"fields": ["name"],
"query": "Calculation of the Eleventh Five Year Plan",
"default_operator": "AND"
}
}
}
12.5 compound query
12.5.1 constant_score query
When we don't care about the influence of the frequency (TF) of search terms on the ranking of search results, we can use constant_score wraps query statements or filter statements.
GET books/_search
{
"query": {
"constant_score": {
"filter": {
"term": {
"name": "China"
}
}
}
}
}
12.5.2 bool query
bool query can assemble any number of simple queries. There are four keywords to choose from, and there can be one or more conditions described by the four keywords.
- Must: the document must match the query criteria under the must option.
- Should: the document can match or not match the query criteria under should.
- must_not: the document must not meet the requirement of must_ Query criteria under the not option.
- Filter: similar to must, but the filter does not score, just filters data.
GET books/_search
{
"query": {
"bool": {
"must": [
{
"term": {
"name": {
"value": "java"
}
}
}
],
"should": [
{"match": {
"info": "program"
}}
],
"must_not": [
{"range": {
"price": {
"gte": 0,
"lte": 36
}
}}
]
}
}
}
The query name attribute must contain java, and the book price is not within the [0,36] range. The info attribute can contain or not contain programming
12.5.3 minmum_should_match
GET books/_search
{
"query": {
"match": {
"info": {
"query": "Test Center Launch",
"minimum_should_match": 3
}
}
}
}
minmum_ should_ The match parameter is called the minimum matching degree on the es official website. That is, when the query info contains the word pushed by the examination center, the es word splitter will segment the word, for example, it is divided into three words pushed by the examination center, and then all documents containing any 2 words (the specified number of minimum_should_match) will be returned, that is, the minimum matching degree
12.5.4 function_score query
Scenario: for example, if you want to find a restaurant with high score nearby and flashback, the search keyword is restaurant, but the default scoring strategy can't take into account the restaurant score. Instead, you just consider the relevance of the search keyword. At this time, you can use function_score query.
First prepare the test data
PUT content
{
"mappings": {
"properties": {
"title":{
"type": "text",
"analyzer": "ik_max_word"
},
"votes":{
"type": "double"
}
}
}
}
PUT content/_doc/1
{
"title":"es From introduction to mastery es Study notes",
"votes":10.0
}
PUT content/_doc/2
{
"title":"es From introduction to mastery",
"votes":100.0
}
At this time, if you search by ES keyword, the document with id 1 will certainly appear at the top, because the document title contains two es, so the relevance is higher, and the expected result of votes 100 is at the top
The specific idea is to get a new score based on the old score and the value of votes.
There are several different calculation methods:
- Weight in_ score is multiplied by weight
- random_score will perform hash operation according to uid field to generate score, and random will be used_ A seed can be configured during score. If it is not configured, the current time is used by default.
- script_score can specify a custom scoring script.
- field_ value_ The function of factor is similar to script_score, but you don't have to write your own script.
For example, use new_score=old_score+votes
GET content/_search
{
"query": {
"function_score": {
"query": {
"match": {
"title": "es"
}
},
"functions": [
{
"script_score": {
"script": "_score + doc['votes'].value"
}
}
],
"boost_mode": "replace"
}
}
}

Via boost_mode parameter to set the final calculation method. There are other values for this parameter:
- Multiply: multiply fractions
- Sum: sum of fractions
- avg: Average
- max: maximum score
- min: min
- replace: do not perform secondary calculation
boost_mode this parameter indicates the calculation result new of the specified function in function_ Based on score and old_score returns after performing relevant operations
12.5.5 field_value_factor
This function is similar to script_score, but you don't have to write your own script.
GET content/_search
{
"query": {
"function_score": {
"query": {"match": {
"title": "es"
}},
"functions": [
{
"field_value_factor": {
"field": "votes"
}
}
]
}
}
}
The default score is old_score*votes.
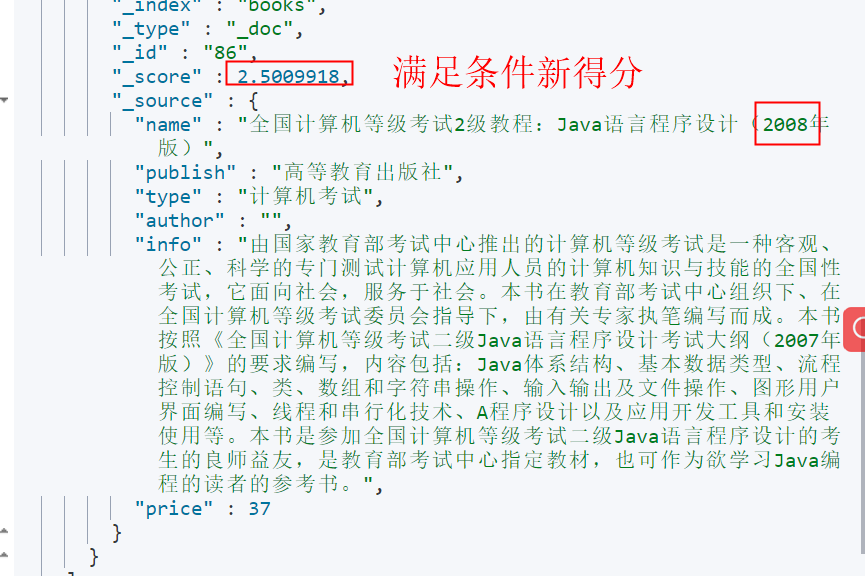
12.5.6 boosting query
Represents the query for the document containing java in the name field, and if the name field contains 2008, the name of the document will be included_ source multiplies the original basis by negative_ Value specified by boost
GET books/_search
{
"query": {
"boosting": {
"positive": {
"match": {
"name": "java"
}
},
"negative": {
"match": {
"name": "2008"
}
},
"negative_boost": 0.5
}
}
}
The boosting query contains three parts:
- positive: the score remains unchanged
- negative: reduce score
- negative_boost: reduced weight

12.6 joint query
12.6.1 nested document query
Prepare test data
PUT school
{
"mappings": {
"properties": {
"student": {
"type": "nested"
}
}
}
}
PUT school/_doc/1
{
"class":"Class one",
"student": [
{
"name": "zhang san",
"age": 18
},
{
"name": "li si",
"age": 20
}
]
}
query
GET school/_search
{
"query": {
"nested": {
"path": "student",
"query": {
"bool": {
"must": [
{
"match": {
"student.name": "li san"
}
},
{
"match": {
"student.age": "18"
}
}
]
}
}
}
}
}
It is found that even in this way, the search can be found, and the mapping relationship between object attributes is lost. Therefore, it is recommended to define parent-child relationship query
12.6.2 parent child documents
Compared with nested documents, parent-child documents have the following advantages:
- When the parent document is updated, the child document is not re indexed
- Creating, modifying, or deleting a parent-child document does not affect the parent document or other child documents.
- Subdocuments can be returned independently as search results.
For example, the relationship between students and classes:
PUT school
{
"mappings": {
"properties": {
"name": {
"type": "keyword"
},
"c_s": {
"type": "join",
"relations": {
"class": "student"
}
}
}
}
}
c_s represents the name of the parent-child document relationship, which can be customized. join indicates that this is a parent-child document. In relationships, the class position is parent and the student position is child.
Next, insert two parent documents:
PUT school/_doc/1
{
"name":"Class one",
"c_s":{
"name":"class"
}
}
PUT school/_doc/2
{
"name":"Class two",
"c_s":{
"name":"class"
}
}
Then add three sub documents:
PUT school/_doc/3?routing=1
{
"name":"Zhang San",
"c_s":{
"name":"student",
"parent":1
}
}
PUT school/_doc/4?routing=2
{
"name":"Li Si",
"c_s":{
"name":"student",
"parent":2
}
}
PUT school/_doc/5?routing=2
{
"name":"Wang Wu",
"c_s":{
"name":"student",
"parent":2
}
}
Sub documents are independent documents. What needs special attention is that the child document needs to be on the same partition as the parent document, so the value of the routing keyword is the id of the parent document. In addition, the value of the name attribute is the value of child in the index definition
Points to note when defining parent-child document indexes:
- Only one join file can be defined per index
- Parent and child documents need to be on the same partition (routing is required for query and modification)
- You can add a new relationship to an existing join file
12.6.3 has_child query
Query parent document through child document
GET school/_search
{
"query": {
"has_child": {
"type": "student",
"query": {
"match": {
"name": "Zhang San"
}
}
}
}
}
12.6.4 has_parent query
Query child documents through parent documents:
GET school/_search
{
"query": {
"has_parent": {
"parent_type": "class",
"query": {
"match": {
"name": "Class two"
}
}
}
}
}
You can also use parent_id query sub document:
GET school/_search
{
"query": {
"parent_id":{
"type":"student",
"id":2
}
}
}
Through the test, it is found that:
- If ordinary sub objects implement one to many, the boundary of sub documents will be lost, and the attribute relationship between sub objects will be lost.
- Nested can solve the problem of point 1, but nested has two disadvantages: when updating the main document, all of them should be updated. It does not support sub documents belonging to multiple main documents.
- The parent-child document solves the problems of 1 and 2 points, but it is mainly applicable to the scenario of writing more and reading less.
12.7 geographic location query
Prepare data
PUT geo
{
"mappings": {
"properties": {
"name":{
"type": "keyword"
},
"location":{
"type": "geo_point"
}
}
}
}
Prepare a Geo JSON file:
{"index":{"_index":"geo","_id":1}}
{"name":"Xi'an","location":"34.288991865037524,108.9404296875"}
{"index":{"_index":"geo","_id":2}}
{"name":"Beijing","location":"39.926588421909436,116.43310546875"}
{"index":{"_index":"geo","_id":3}}
{"name":"Shanghai","location":"31.240985378021307,121.53076171875"}
{"index":{"_index":"geo","_id":4}}
{"name":"Tianjin","location":"39.13006024213511,117.20214843749999"}
{"index":{"_index":"geo","_id":5}}
{"name":"Hangzhou","location":"30.259067203213018,120.21240234375001"}
{"index":{"_index":"geo","_id":6}}
{"name":"Wuhan","location":"30.581179257386985,114.3017578125"}
{"index":{"_index":"geo","_id":7}}
{"name":"Hefei","location":"31.840232667909365,117.20214843749999"}
{"index":{"_index":"geo","_id":8}}
{"name":"Chongqing","location":"29.592565403314087,106.5673828125"}
Execute the following command to batch import Geo JSON data:
curl -XPOST "http://localhost:9200/geo/_bulk?pretty" -H "content-type:application/json" --data-binary @geo.json
12.7.1 geo_distance query
Give a center point and query the documents within the specified range from the center point:
GET geo/_search
{
"query": {
"bool": {
"filter": [
{
"geo_distance": {
"distance": "700km",
"location": {
"lat": 34.288991865037524,
"lon": 108.9404296875
}
}
}
]
}
}
}
Query the cities 700km around Xi'an
{
"took" : 1,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 3,
"relation" : "eq"
},
"max_score" : 0.0,
"hits" : [
{
"_index" : "geo",
"_type" : "_doc",
"_id" : "1",
"_score" : 0.0,
"_source" : {
"name" : "Xi'an",
"location" : "34.288991865037524,108.9404296875"
}
},
{
"_index" : "geo",
"_type" : "_doc",
"_id" : "6",
"_score" : 0.0,
"_source" : {
"name" : "Wuhan",
"location" : "30.581179257386985,114.3017578125"
}
},
{
"_index" : "geo",
"_type" : "_doc",
"_id" : "8",
"_score" : 0.0,
"_source" : {
"name" : "Chongqing",
"location" : "29.592565403314087,106.5673828125"
}
}
]
}
}
12.7.2 geo_bounding_box query
A point within a rectangle that locks a rectangle through two points
GET geo/_search
{
"query": {
"bool": {
"filter": [
{
"geo_bounding_box": {
"location": {
"top_left": {
"lat": 40.84706035607122,
"lon": 111.62109375
},
"bottom_right": {
"lat": 39.30029918615029,
"lon": 119.53125
}
}
}
}
]
}
}
}
Taking [40.84706035607122111.62109375] longitude and latitude as the upper left corner of the rectangle and [39.30029918615029119.53125] longitude and latitude as the lower right corner of the rectangle, the constructed rectangle includes Shanghai and Hangzhou.
12.7.3 geo_polygon query
A query within a polygon.
GET geo/_search
{
"query": {
"bool": {
"filter": [
{
"geo_polygon": {
"location": {
"points": [
{
"lat":33.99802726234877,
"lon":108.45703125
},
{
"lat":33.99802726234877,
"lon": 109.3798828125
},
{
"lat":34.66935854524543,
"lon": 109.3798828125
},
{
"lat":34.66935854524543,
"lon": 108.45703125
}
]
}
}
}
]
}
}
}
Given multiple points, query the data in the polygon composed of multiple points.
12.7.4 geo_shape query
geo_shape is used to query graphics for geo_shape, the relationship between two figures is: intersection, inclusion and disjoint.
Prepare data
PUT geo_shape
{
"mappings": {
"properties": {
"name":{
"type": "keyword"
},
"location":{
"type": "geo_shape"
}
}
}
}
Then add a line:
PUT geo_shape/_doc/1
{
"name": "Baoji->Shangluo",
"location": {
"type": "linestring",
"coordinates": [
[
108.21533203125,
34.45221847282654
],
[
109.88525390624999,
34.03445260967645
]
]
}
}
Next, query whether a drawing intersects the line:
GET geo_shape/_search
{
"query": {
"bool": {
"filter": [
{
"geo_shape": {
"location": {
"shape": {
"type": "envelope",
"coordinates": [
[
109.7314453125,
35.11990857099681
],
[
108.369140625,
33.706062655101206
]
]
},
"relation": "intersects"
}
}
}
]
}
}
}
The relationship property represents the relationship between the two graphs:
- within contains
- intersects intersect
- Disjoint disjoint
12.8 special inquiry
12.8.1 more_like_this query
more_like_this query can realize content-based recommendation. Given an article, you can query the content similar to the article.
GET books/_search
{
"query": {
"more_like_this": {
"fields": [
"info"
],
"like": "country",
"min_term_freq": 1,
"max_query_terms": 12
}
}
}
- Fields: there can be multiple fields to match
- like: text to match
- min_term_freq: the lowest frequency of a word item. The default is 2. In particular, this refers to the frequency of the word item in the text to be matched, not in the es document
- max_query_terms: the maximum number of terms contained in the query
- min_doc_freq: the minimum document frequency, the search term, and the number of documents in which it appears at least. If it is less than the specified number, the word will be ignored
- max_doc_freq: maximum document frequency
- analyzer: word splitter, which uses the word splitter of the field by default
- stop_words: list of stop words
12.8.2 script query
Script query, such as querying all books with a price greater than 100:
GET books/_search
{
"query": {
"bool": {
"filter": [
{"script": {
"script": {
"lang": "painless",
"source": "if(doc['price'].size()>0){doc['price'].value>100}"
}
}}
]
}
}
}
12.8.3 percolate query
percolate query is translated into penetration query or reverse query.
- Normal operation: find the corresponding document according to the query statement query - > document
- Persistent query: returns the matching query statement according to the document, document - > query
Application scenario:
- Price monitoring
- Inventory alarm
- Stock warning
For example, for threshold alarm, if the specified field value is greater than the threshold, the alarm will be prompted.
percolate mapping definition:
PUT log
{
"mappings": {
"properties": {
"threshold":{
"type": "long"
},
"count":{
"type": "long"
},
"query":{
"type":"percolator"
}
}
}
}
The percolator type is equivalent to keyword, long, integer, and so on.
Insert document
PUT log/_doc/1
{
"threshold":10,
"query":{
"bool":{
"must":{
"range":{
"count":{
"gt":2
}
}
}
}
}
}
query
{
"query": {
"percolate": {
"field": "query",
"documents": [
{
"count":3
},
{
"count":6
},
{
"count":90
},
{
"count":12
},
{
"count":15
}
]
}
}
}
The query results are as follows
{
"took" : 16,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 1.0,
"hits" : [
{
"_index" : "log",
"_type" : "_doc",
"_id" : "1",
"_score" : 1.0,
"_source" : {
"threshold" : 10,
"query" : {
"bool" : {
"must" : {
"range" : {
"count" : {
"gt" : 2
}
}
}
}
}
},
"fields" : {
"_percolator_document_slot" : [
0,
1,
2,
3,
4
]
}
}
]
}
}
Documents with a count greater than 2 will be listed in the query results.
In query results_ percolator_ document_ The slot field represents the subscript of the document, counting from 0
12.9 search highlighting and sorting
12.9.1 highlight
By adding custom highlighted labels to search keywords:
GET books/_search
{
"query": {
"match": {
"name": "java"
}
},
"highlight": {
"require_field_match": "false",
"fields": {
"name": {
"pre_tags": ["<font color='red'>"],
"post_tags": ["</font>"]
},
"info": {
"pre_tags": ["<font color='red'>"],
"post_tags": ["</font>"]
}
}
}
}

12.9.2 sorting
es is sorted by the relevance of the query document by default, that is (_score field), match_all query only returns all documents without scoring. It is returned in the order of adding by default. You can use the_ doc field to sort them:
GET books/_search
{
"query": {
"match_all": {}
},
"sort": [
{
"_doc": {
"order": "desc"
}
}
]
}
es also supports multi field sorting:
GET books/_search
{
"query": {
"match": {
"name": "study"
}
},
"sort": [
{
"price": {
"order": "asc"
}
},
{
"_id": {
"order": "desc"
}
}
],
"size": 20
}
XIII ES index aggregation
13.1 Max Aggregation
Statistical maximum.
GET books/_search
{
"aggs": {
"max_price": {
"max": {
"field": "price"
}
}
}
}
give the result as follows

GET books/_search
{
"aggs": {
"max_price": {
"max": {
"field": "price",
"missing": 300
}
}
}
}
If the price field is missing in a document, set the value of the field to 300.
You can also query by script
GET books/_search
{
"aggs": {
"max_price": {
"max": {
"script": {
"source": "if(doc.price.size()!=0){doc.price.value}"
}
}
}
}
}
13.2 Min Aggregation
Statistical minimum
GET books/_search
{
"aggs": {
"min_price": {
"min": {
"field": "price"
}
}
}
}
13.3 Avg Aggregation
Statistical average:
GET books/_search
{
"aggs": {
"min_price": {
"avg": {
"field": "price"
}
}
}
}
13.4 Sum Aggregation
Summation:
GET books/_search
{
"aggs": {
"min_price": {
"avg": {
"field": "price"
}
}
}
}
13.5 Cardinality Aggregation
cardinality aggregation is used for cardinality statistics. Similar to distinct count(0) in SQL (de duplication first and then count the number):
Text type is an analytical type. Aggregation is not allowed by default. If aggregation is performed relative to text type, its fielddata property needs to be set to true. Although this method can enable text type to aggregate, it cannot meet accurate aggregation. If accurate aggregation is required, the field type can be set to keyword.
GET books/_search
{
"aggs": {
"publish_count": {
"cardinality": {
"field": "author"
}
}
}
}

13.6 Stats Aggregation
Basic statistics: count, max, min, avg, sum are returned at one time:
GET books/_search
{
"aggs": {
"agg_status": {
"stats": {
"field": "price"
}
}
}
}
13.7 Extends Stats Aggregation
Advanced statistics, more than stats: sum of squares, variance, standard deviation, mean plus minus two standard deviations:
GET books/_search
{
"aggs": {
"extends_status": {
"extended_stats": {
"field": "price"
}
}
}
}
13.8 Percentiles Aggregation
Percentile statistics. Count the percentage of the value of the price field in each stage
GET books/_search
{
"aggs": {
"per": {
"percentiles": {
"field": "price",
"percents": [
0,
25,
50,
75,
100
]
}
}
}
}
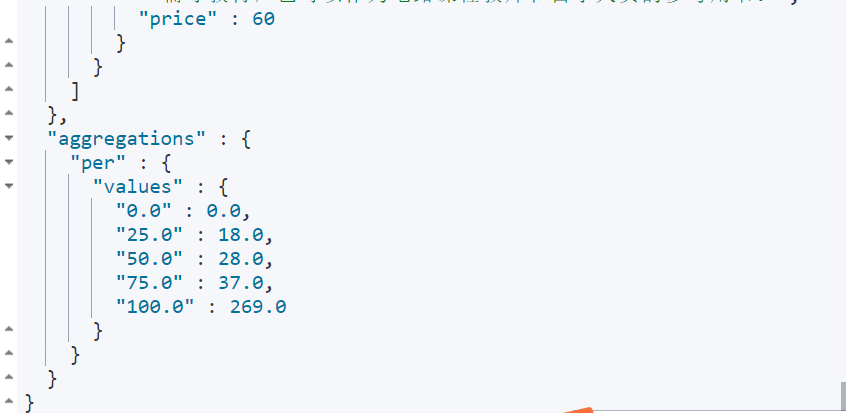
For example, documents with a price lower than 18 account for about 25% of the total number of documents, and the prices of all documents are lower than 269
13.9 Value Count Aggregation
You can count the number of documents by field (including the number of documents with the specified field):
GET books/_search
{
"aggs": {
"field_count": {
"value_count": {
"field": "price"
}
}
}
}
XIV ES barrel polymerization
14.1 Terms Aggregation
Terms Aggregation is used for grouping aggregation, for example, to count the total number of books published by each publishing house:
GET books/_search
{
"aggs": {
"publish_count": {
"terms": {
"field": "publish",
"size": 10
}
}
},
"size": 0
}

On the basis of terms bucket, you can also aggregate indicators for each bucket.
Statistics on the average price of books published by different publishing houses:
GET books/_search
{
"aggs": {
"publish_count": {
"terms": {
"field": "publish",
"size": 10
},
"aggs": {
"price_avg": {
"avg": {
"field": "price"
}
}
}
}
},
"size": 0
}
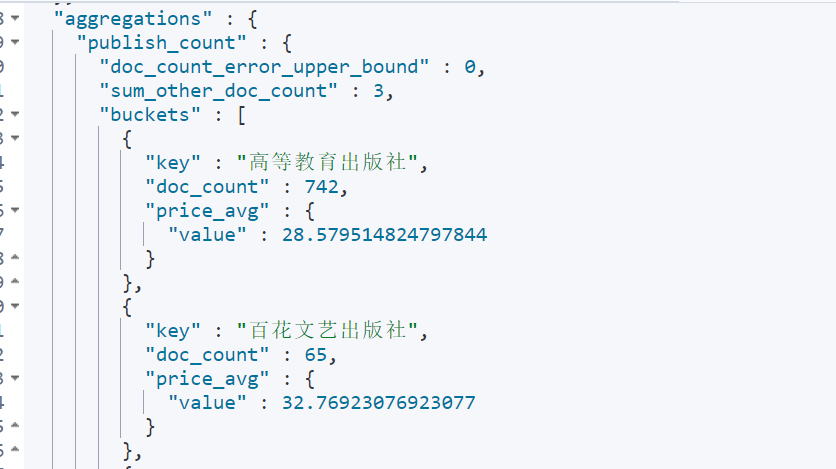
14.2 Filter Aggregation
Filter aggregation. Documents that meet the criteria in the filter can be divided into a bucket and then averaged.
For example, query the average price of books with java in the book title:
GET books/_search
{
"aggs": {
"java_count": {
"filter": {
"term": {
"name": "java"
}
},
"aggs": {
"avg_price": {
"avg": {
"field": "price"
}
}
}
}
},
"size": 0
}
14.3 Filters Aggregation
Multi filter aggregation. There can be multiple filter conditions.
For example, query the average price of books with java or international Titles:
GET books/_search
{
"aggs": {
"java_count": {
"filters": {
"filters": [
{
"term":{
"name":"java"
}
},
{
"term":{
"name":"international"
}
}
]
},
"aggs": {
"NAME": {
"avg": {
"field": "price"
}
}
}
}
},
"size": 0
}
14.4 Range Aggregation
The number of documents in a certain range is counted by range aggregation.
For example, count the number of books with book prices above 0-50, 50-100, 100-150 and 150:
GET books/_search
{ "size": 0,
"aggs": {
"NAME": {
"range": {
"field": "price",
"ranges": [
{
"from": 0,
"to": 50
},
{
"from": 50,
"to": 100
},
{
"from": 100,
"to": 150
},
{
"from": 150,
"to": 200
}
]
}
}
}
}
14.5 Date Range Aggregation
Prepare data
PUT clock/_doc/1
{
"name":"spring",
"date":"2018-02-11"
}
PUT clock/_doc/2
{
"name":"summer",
"date":"2019-03-11"
}
PUT clock/_doc/3
{
"name":"autumn",
"date":"2020-03-11"
}
PUT clock/_doc/4
{
"name":"winter",
"date":"2021-03-11"
}
Count the number from one year ago to now:
GET clock/_search
{
"size": 0,
"aggs": {
"NAME": {
"date_range": {
"field": "date",
"ranges": [
{
"from": "now-1y/y",
"to": "now"
}
]
}
}
}
}
- 12M/M means 12 months.
- 1y/y means 1 year.
- d stands for days
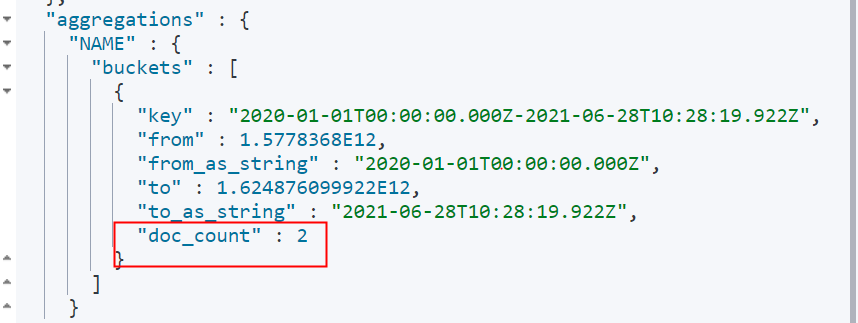
14.6 Date Histogram Aggregation
Time histogram aggregation.
For example, count the documents of each year
GET clock/_search
{
"size": 0,
"aggs": {
"NAME": {
"date_histogram": {
"field": "date",
"calendar_interval": "year"
}
}
}
}

14.7 Missing Aggregation
Null aggregation.
Count documents without price field:
GET books/_search
{
"size": 0,
"aggs": {
"NAME": {
"missing": {
"field": "price"
}
}
}
}

14.8 Children Aggregation
Buckets can be divided according to the parent-child document relationship.
Query the number of documents whose subtype is student:
GET school/_search
{
"size": 0,
"aggs": {
"NAME": {
"children": {
"type": "student"
}
}
}
}

14.9 Geo Distance Aggregation
Make statistics on geographical location data.
For example, query (34.288991865037524108.9404296875) the number of cities within 600KM and beyond 600KM-1000KM.
GET geo/_search
{"size": 0,
"aggs": {
"NAME": {
"geo_distance": {
"field": "location",
"origin": "34.288991865037524,108.9404296875",
"unit": "km",
"ranges": [
{
"from": 0,
"to": 600
},
{
"from": 600,
"to": 1000
}
]
}
}
}
}
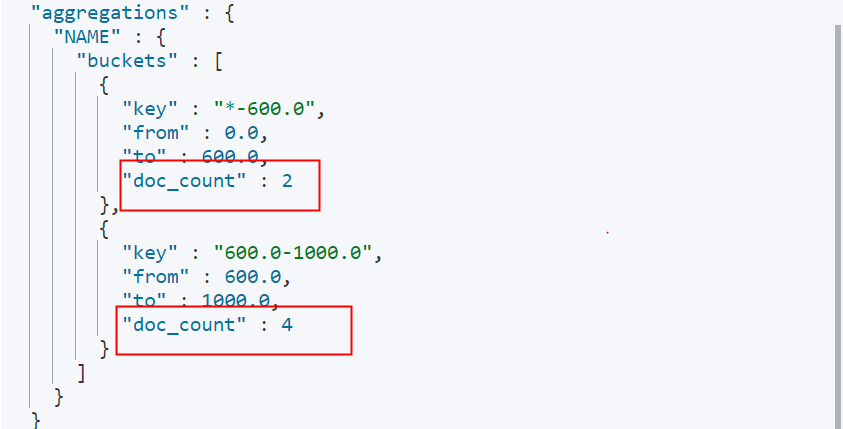
14.10 IP Range Aggregation
Query according to the IP address range (from - > to is the front closed and rear open interval)
GET address/_search
{
"aggs": {
"NAME": {
"ip_range": {
"field": "ip",
"ranges": [
{
"from": "127.0.0.1",
"to": "127.0.0.6"
}
]
}
}
}
}
XV Pipeline polymerization
Pipeline polymerization is equivalent to re polymerization on the basis of previous polymerization.
15.1 Avg Bucket Aggregation
Calculate the aggregate average. For example, count the average value of books published by each publishing house, and then count the average value of books published by all publishing houses:
GET books/_search
{
"size": 0,
"aggs": {
"avg_count": {
"terms": {
"field": "publish",
"size": 2
},
"aggs": {
"avg_price": {
"avg": {
"field": "price"
}
}
}
},
"avg_book":{
"avg_bucket": {
"buckets_path": "avg_count.avg_price"
}
}
}
}
15.2 Max Bucket Aggregation
Count the average value of the books published by each publishing house, and then count the maximum value in the average value:
GET books/_search
{
"size": 0,
"aggs": {
"avg_count": {
"terms": {
"field": "publish",
"size": 2
},
"aggs": {
"avg_price": {
"avg": {
"field": "price"
}
}
}
},
"avg_book":{
"max_bucket": {
"buckets_path": "avg_count.avg_price"
}
}
}
}
15.3 Min Bucket Aggregation
Count the average value of the books published by each publishing house, and then count the minimum value of the average value:
GET books/_search
{
"size": 0,
"aggs": {
"avg_count": {
"terms": {
"field": "publish",
"size": 2
},
"aggs": {
"avg_price": {
"avg": {
"field": "price"
}
}
}
},
"avg_book":{
"min_bucket": {
"buckets_path": "avg_count.avg_price"
}
}
}
}
15.4 Sum Bucket Aggregation
Count the average value of the books published by each publishing house, and then count the sum of the average values:
GET books/_search
{
"size": 0,
"aggs": {
"avg_count": {
"terms": {
"field": "publish",
"size": 2
},
"aggs": {
"avg_price": {
"avg": {
"field": "price"
}
}
}
},
"avg_book":{
"sum_bucket": {
"buckets_path": "avg_count.avg_price"
}
}
}
}
15.5 Stats Bucket Aggregation
Make statistics on the average value of books published by each publishing house, and then make statistics on various data of the average value:
GET books/_search
{
"size": 0,
"aggs": {
"avg_count": {
"terms": {
"field": "publish",
"size": 2
},
"aggs": {
"avg_price": {
"avg": {
"field": "price"
}
}
}
},
"avg_book":{
"stats_bucket": {
"buckets_path": "avg_count.avg_price"
}
}
}
}
15.6 Extended Stats Bucket Aggregation
15.7 Percentiles Bucket Aggregation
XVI Java operations ES
Scheme of Java operating Es:
-
Use HTTP requests directly
Directly use HTTP requests to operate Es. The HTTP request tool can use the HttpUrlConnection that comes with Java, or some HTTP request libraries, such as HttpClient, OKHttp, and RestTemplate in Spring.
One disadvantage of this method is to assemble the request parameters and parse the JSON of the response.
-
Low Level REST Client
The official low-level client for Es. This method allows communication with the Es cluster through HTTP, but the JSON parameters of the request and the response are handed over to the user for processing. The advantage of this method is that it is compatible with all Es versions. But data processing is troublesome.
-
High Level REST Client
The official advanced client of user Es. This method allows communication with the Es cluster through HTTP. It is based on the Low Level REST Client, but provides many API s. Developers do not need to assemble parameters or parse the response JSON by themselves. This method is more direct to use. However, it should be noted that in this way, the version of the dependent library used should correspond to Es.
-
TransportClient
TransportClient has been deprecated in Es7 and will be completely deleted in Es8.
16.1 send http request operation es
public class OriginalEsTest {
public static void main(String[] args) throws IOException {
URL url=new URL("http://localhost:9200/books/_search?pretty=true");
HttpURLConnection urlConnection = (HttpURLConnection) url.openConnection();
if (urlConnection.getResponseCode()==200){
BufferedReader reader = new BufferedReader(new InputStreamReader(urlConnection.getInputStream()));
String str=null;
while ((str=reader.readLine())!=null){
System.out.println(str);
}
reader.close();
}
}
}
16.2 Low Level REST Client
Add maven dependency
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-client</artifactId>
<version>7.9.3</version>
</dependency>
Request call
public class LowLevelEsTest {
public static void main(String[] args) throws IOException {
//1. Build a RestClient object
RestClientBuilder builder = RestClient.builder(
new HttpHost("localhost", 9200, "http")
);
//2. If you need to set authentication information in the request header, you can set it through builder
//builder.setDefaultHeaders(new Header[]{new BasicHeader("key","value")});
final RestClient restClient = builder.build();
//3. Build request
Request request = new Request("GET", "/books/_search");
//Add request parameters
request.addParameter("pretty","true");
//Add request body json parameter
request.setEntity(new NStringEntity("{\"size\": 10}", ContentType.APPLICATION_JSON));
//4. Initiate a request. There are two ways to initiate a request: synchronous and asynchronous
//restClient.performRequest(request);
//Asynchronous request
restClient.performRequestAsync(request, new ResponseListener() {
//Request successful callback
@Override
public void onSuccess(Response response) {
//5. Parse the response and obtain the response result
try {
BufferedReader br = new BufferedReader(new InputStreamReader(response.getEntity().getContent()));
String str = null;
while ((str = br.readLine()) != null) {
System.out.println(str);
}
br.close();
//Finally, remember to close RestClient
restClient.close();
} catch (IOException e) {
e.printStackTrace();
}
}
//Request failed callback
@Override
public void onFailure(Exception e) {
System.out.println(e.getMessage());
}
});
System.out.println("Main thread execution...");
}
}
16.3 High Level REST Client
Introduce dependency
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-high-level-client</artifactId>
<version>7.9.3</version>
</dependency>
Request call
public class HighLevelEsTest {
public static void main(String[] args) throws IOException {
RestHighLevelClient client = new RestHighLevelClient(RestClient.builder(new HttpHost("localhost", 9200, "http")));
//Delete existing indexes
DeleteIndexRequest deleteIndexRequest = new DeleteIndexRequest("user");
// client.indices().delete(deleteIndexRequest,RequestOptions.DEFAULT);
//New index
CreateIndexRequest request = new CreateIndexRequest("user");
//Configure settings, slice, copy and other information
request.settings(Settings.builder().put("index.number_of_shards", 2).put("index.number_of_replicas", 1));
//Configure the field type, which can be built by JSON string, Map and XContentBuilder
//1.json string mode
//request.mapping("{\"properties\":{\"name\":{\"type\":\"keyword\"},\"age\":{\"type\": \"integer\"}}}", XContentType.JSON);
//Execute request, create index
//2.map string mode
HashMap<String, Object> ageTypeMap = new HashMap<String, Object>();
ageTypeMap.put("type", "integer");
HashMap<String, Object> ageMap = new HashMap<String, Object>();
ageMap.put("age", ageTypeMap);
HashMap<String, Object> propertiesMap = new HashMap<String, Object>();
propertiesMap.put("properties", ageMap);
//3. Through XContentBuilder
XContentBuilder xContentBuilder = XContentFactory.jsonBuilder();
xContentBuilder.startObject();
xContentBuilder.startObject("properties");
xContentBuilder.startObject("age");
xContentBuilder.field("type","integer");
xContentBuilder.endObject();
xContentBuilder.endObject();
xContentBuilder.endObject();
//Index alias
request.alias(new Alias("user_alias"));
request.mapping(xContentBuilder);
client.indices().create(request, RequestOptions.DEFAULT);
//Close connection
client.close();
}
}
Directly encapsulate json parameters for calls
public class HighLevelEs2JsonTest {
public static void main(String[] args) throws IOException {
final RestHighLevelClient client = new RestHighLevelClient(RestClient.builder(new HttpHost("localhost", 9200, "http")));
//New index
CreateIndexRequest request = new CreateIndexRequest("user");
request.source(
"{\n" +
" \"settings\": {\n" +
" \"index.number_of_shards\":2,\n" +
" \"index.number_of_replicas\":1\n" +
" } ,\n" +
" \"mappings\": {\n" +
" \"properties\": {\n" +
" \"name\":{\n" +
" \"type\": \"keyword\"\n" +
" },\n" +
" \"age\":{\n" +
" \"type\": \"integer\"\n" +
" }\n" +
" }\n" +
" }\n" +
"}", XContentType.JSON);
//Synchronous calls block
//client.indices().create(request, RequestOptions.DEFAULT);
//Asynchronous call
client.indices().createAsync(request, RequestOptions.DEFAULT, new ActionListener<CreateIndexResponse>() {
@Override
public void onResponse(CreateIndexResponse createIndexResponse) {
//Close connection
try {
client.close();
} catch (IOException e) {
e.printStackTrace();
}
}
@Override
public void onFailure(Exception e) {
System.out.println(e.getMessage());
}
});
}
}
Index alias related operations
public class HighLevelEs2AliasTest {
public static void main(String[] args) throws IOException {
final RestHighLevelClient client = new RestHighLevelClient(RestClient.builder(new HttpHost("localhost", 9200, "http")));
//1. Check whether the index exists
GetIndexRequest getIndexRequest=new GetIndexRequest("user1");
boolean exists = client.indices().exists(getIndexRequest, RequestOptions.DEFAULT);
System.out.println("user1 Does the index exist = " + exists+"\r\n"+"---------------");
//2. Turn off the index
CloseIndexRequest closeIndexRequest=new CloseIndexRequest("user");
CloseIndexResponse close = client.indices().close(closeIndexRequest, RequestOptions.DEFAULT);
List<CloseIndexResponse.IndexResult> list = close.getIndices();
for (CloseIndexResponse.IndexResult result : list) {
System.out.println("Closed indexes are = "+result.getIndex()+"\r\n"+"---------------");
}
//3. Open index
OpenIndexRequest openIndexRequest=new OpenIndexRequest("user");
client.indices().open(openIndexRequest, RequestOptions.DEFAULT);
//4. Modify index
UpdateSettingsRequest settingsRequest=new UpdateSettingsRequest("user");
settingsRequest.settings(Settings.builder().put("index.blocks.write",true).build());
client.indices().putSettings(settingsRequest,RequestOptions.DEFAULT);
//5. Clone index the cloned index must be read-only, otherwise it cannot be cloned
//ResizeRequest resizeRequest=new ResizeRequest("user1","user");
//client.indices().clone(resizeRequest,RequestOptions.DEFAULT);
//6. View index information
GetSettingsRequest request = new GetSettingsRequest().indices("school");
//Set the specific parameters required. If not set, all parameters will be returned
request.names("index.uuid");
GetSettingsResponse response = client.indices().getSettings(request, RequestOptions.DEFAULT);
ImmutableOpenMap<String, Settings> indexToSettings = response.getIndexToSettings();
System.out.println(indexToSettings);
String s = response.getSetting("school", "index.uuid");
System.out.println(s);
//7. Add / remove alias
IndicesAliasesRequest indicesAliasesRequest = new IndicesAliasesRequest();
IndicesAliasesRequest.AliasActions aliasAction = new IndicesAliasesRequest.AliasActions(IndicesAliasesRequest.AliasActions.Type.ADD);
aliasAction.index("books").alias("books_alias");
//Add an alias after filtering data. When viewing this alias, you will see the filtered data, which is similar to the view in mysql
//aliasAction.index("books").alias("books_alias2").filter("{\"term\": {\"name\": \"java\"}}");
indicesAliasesRequest.addAliasAction(aliasAction);
client.indices().updateAliases(indicesAliasesRequest, RequestOptions.DEFAULT);
//8. Delete alias
DeleteAliasRequest deleteAliasRequest = new DeleteAliasRequest("books", "books_alias");
client.indices().deleteAlias(deleteAliasRequest, RequestOptions.DEFAULT);
//9. Get alias
GetAliasesRequest booksAlias = new GetAliasesRequest("books_alias2");
//Specify to view the alias of an index. If not specified, all aliases will be searched
//booksAlias.indices("books");
boolean b = client.indices().existsAlias(booksAlias, RequestOptions.DEFAULT);
System.out.println(b);
//View alias
GetAliasesResponse response1 = client.indices().getAlias(booksAlias, RequestOptions.DEFAULT);
Map<String, Set<AliasMetadata>> aliases = response1.getAliases();
System.out.println("aliases = " + aliases);
client.close();
}
}
Document related operations
public class HighLevelEs2DocTest {
public static void main(String[] args) throws IOException {
RestHighLevelClient client = new RestHighLevelClient(RestClient.builder(new HttpHost("localhost", 9200, "http")));
IndexRequest indexRequest = new IndexRequest("user");
indexRequest.source("{\"name\": \"Zhang San\",\"age\": 10}", XContentType.JSON).id("1");
//You can specify the add / update operation of the document. If you do not specify the default operation
//indexRequest.opType(DocWriteRequest.OpType.CREATE);
IndexResponse response = client.index(indexRequest, RequestOptions.DEFAULT);
System.out.println("Index is = " + response.getIndex());
System.out.println("file ID by:" + response.getId());
DocWriteResponse.Result result = response.getResult();
if (result.equals(DocWriteResponse.Result.CREATED)) {
System.out.println("The document was saved successfully");
}
//Judge whether the document is successfully updated (if the id already exists)
if (result.equals(DocWriteResponse.Result.UPDATED)) {
System.out.println("Document updated successfully");
}
//Judge whether the slicing operations are successful
ReplicationResponse.ShardInfo shardInfo = response.getShardInfo();
if (shardInfo.getTotal()!=shardInfo.getSuccessful()){
System.out.println("Some fragments were not saved successfully");
}
//There are failed fragments
if (shardInfo.getFailed()>0){
ReplicationResponse.ShardInfo.Failure[] failures = shardInfo.getFailures();
//Print error message
Arrays.stream(failures).forEach(x-> System.out.println(x.reason()));
}
//View document
GetRequest getRequest=new GetRequest("books","1");
GetResponse getResponse = client.get(getRequest, RequestOptions.DEFAULT);
//If the document exists
if (getResponse.isExists()){
System.out.println("getResponse.getId() = " + getResponse.getId());
System.out.println("getResponse.getIndex() = " + getResponse.getIndex());
System.out.println("getResponse.getVersion() = " + getResponse.getVersion());
System.out.println("getResponse.getSource() = " + getResponse.getSource());
}else {
System.out.println("Document does not exist");
}
//remove document
DeleteRequest deleteRequest=new DeleteRequest("books","1");
DeleteResponse deleteResponse = client.delete(deleteRequest, RequestOptions.DEFAULT);
if (deleteResponse.getResult().equals(DocWriteResponse.Result.DELETED)){
System.out.println("Delete succeeded");
System.out.println("deleteResponse.getResult() = " + deleteResponse.getResult().getLowercase());
}else {
System.out.println("Deletion failed");
}
//Update document
UpdateRequest updateRequest=new UpdateRequest("books","0");
//Update via json
updateRequest.docAsUpsert(true); //When true, insert the document if the document with id 0 is not found in the index
updateRequest.doc("{\"name\": \"Shuwen\",\"type\": \"primary school\"}",XContentType.JSON);
//Update via map
//updateRequest.doc(Collections.singletonMap("name", "math");
//If the update is not successful, insert the document
//updateRequest.upsert("{\"name \ ": \" Chinese \ ", \" type \ ": \" primary school \ "}", XContentType.JSON);
UpdateResponse update = client.update(updateRequest, RequestOptions.DEFAULT);
if (update.getResult().equals(DocWriteResponse.Result.UPDATED)){
System.out.println("update.getVersion() = " + update.getVersion());
System.out.println("update.getResult().getLowercase() = " + update.getResult().getLowercase());
}else if (update.getResult().equals(DocWriteResponse.Result.CREATED)){
System.out.println("Insert successful");
}else {
System.out.println("Update failed");
}
client.close();
}
}