1.ELK log analysis
1.1 advantages and disadvantages of log server
advantage
Improve security
Centralized storage of logs
shortcoming
Difficult analysis of logs
2. What is elk?
The management tool for simplified log analysis is composed of Elasticsearch(ES), Logstash and Kibana. The official website is: https://www.elastic.co/products
ES(nosql non relational database): storage function and index
Logstash (log collection): take the log from the application server and output it to es after format conversion
Collect / collect log s through the input function
filter: formatting data
Output: log output to es database
Kibana (display tool): display the data in es in the browser and display it through the UI interface (you can process the log according to your own needs for easy viewing and reading)
2.1 Logstash management includes four tools
Packetbeat (collect network traffic data)
Topbeat (collect CPU and memory usage data at system, process and file system levels)
Filebeat (collecting file data) is a lightweight tool compared with Logstash
Winlogbeat (collect Windows event log data)
2.2 log processing steps
Logstash collects logs generated by AppServer and centralizes log management
Format the log and store it in the ElasticSearch cluster
Index and store the formatted data (Elasticsearch)
Kibana queries the data from the Es cluster, generates charts, and then returns them to browsers
3. Basic and core concepts of elasticsearch
Relationship between relational database and Elasticsearch
mysql Elasticsearch database database index Indexes table surface type type row that 's ok document file column column attribute
1. Near real time (NRT)
Elastic search is a near real-time search platform, which means that there is a slight delay (usually 1 second) from indexing a document until the document can be searched
2. Cluster
The cluster has a unique identifier name, which is elasticsearch by default;
Cluster is organized by one or more nodes. They jointly hold the whole data and provide index and search functions together;
One of the nodes is the primary node, which can be elected and provides cross node joint index and search functions;
The cluster name is very important. Each node is added to its cluster based on the cluster name
3. Node
Node is a single server, which is a part of the cluster, stores data and participates in the index and search functions of the cluster;
Like clusters, nodes are also identified by name. By default, the character name is randomly assigned when the node is started, which can be defined by itself;
The name is used to identify the node corresponding to the server in the cluster.
4. Index
An index is a collection of documents with somewhat similar characteristics;
An index is identified by a name (which must be all lowercase letters), and we should use this name when we want to index, search, update and delete the documents corresponding to the index.
5. Type
In an index, you can define one or more types. A type is a logical classification / partition of your index; Typically, a type is defined for a document that has a common set of fields
6. document
Documents are represented in JSON (JavaScript object notation) format, which is a ubiquitous Internet data interaction format.
Although a document is physically located in an index, in fact, a document must be indexed and assigned a type within an index.
7. shards
That is why es as a search engine is fast:
In practice, the data stored in the index may exceed the hardware limit of a single node. For example, a 1 billion document requires 1TB of space, which may not be suitable for storage on the disk of a single node, or the search request from a single node is too slow. To solve this problem, elastic search provides the function of dividing the index into multiple slices. When creating an index, you can define the number of slices you want to slice. Each partition is a fully functional independent index, which can be located on any node in the cluster.
Benefits of fragmentation:
① : horizontally split and expand to increase the storage capacity
② : distributed parallel cross slice operation to improve performance and throughput
8. Replica
In order to prevent data loss caused by network problems and other problems, a failover mechanism is required. Therefore, elasticsearch allows us to copy one or more indexes into fragments, which is called fragmented copy or replica.
There are also two main reasons for replicas:
① : high availability to deal with fragmentation or node failure, which needs to be on different nodes
② : improve performance, increase throughput, and search can be performed on all replicas in parallel
In short, each index can be divided into multiple slices. An index can also be copied 0 times (meaning no copy) or more. Once replicated, each index has a primary shard (the original shard as the replication source) and a replication shard (a copy of the primary shard). The number of shards and replicas can be specified when the index is created. After the index is created, you can dynamically change the number of copies at any time, but you can't change the number of slices afterwards.
4.Logstash introduction
Logstash is written in JRuby language, based on the simple message based architecture, and runs on the Java virtual machine (JVM). Logstash can configure a single agent to combine with other open source software to realize different functions.
The concept of Logstash is very simple. It only does three things: Collect: data input, Enrich: data processing, 1 such as filtering, modification, etc., and Transport: data output (called by other modules)
1. Main components of logstash
① : shipper (log collector): responsible for monitoring the changes of local log files and collecting the latest contents of log files in time. Usually, the remote agent only needs to run this component;
② : indexer: responsible for receiving logs and writing them to local files.
③ : broker (log Hub): responsible for connecting multiple shippers and indexers
④ : search and storage: allows searching and storage of events;
⑥ : web interface: Web-based display interface
2. LogStash host classification
① : agent host: as the shipper of events, send various log data to the central host; Just run the Logstash agent
② : central host: it can run, including broker, indexer, Search and storage
Storage) and web interface to receive, process and store log data
5. Introduction to kibana
1. Introduction
Kibana is an open source analysis and visualization platform for Elasticsearch, which is used to search and view the data interactively stored in Elasticsearch index. With kibana, advanced data analysis and display can be carried out through various charts. It is easy to operate, and the browser based user interface can quickly create a dashboard to display the Elasticsearch query dynamics in real time. Setting up kibana is very simple. Kibana installation can be completed and Elasticsearch index monitoring can be started in a few minutes without writing code.
2. Main functions
① : seamless integration of Elasticsearch: kibana architecture is customized for Elasticsearch, and any structured and unstructured data can be added to Elasticsearch index; Kibana also makes full use of the powerful search and analysis capabilities of Elasticsearch.
② : integrate your data: Kibana can better handle massive data and create column charts, line charts, scatter charts, histograms, pie charts and maps.
③ : complex data analysis: Kibana improves the analysis ability of Elasticsearch, which can analyze data more intelligently, perform mathematical transformation, and cut and block data according to requirements.
④ : benefit more team members: the powerful database visualization interface enables all business posts to benefit from the data collection.
⑤ : flexible interface and easier sharing: Kibana can be used to create, save and share data more conveniently and exchange visual data quickly.
⑥ : simple configuration: kibana is very simple to configure and enable, and the user experience is very friendly. Kibana comes with its own Web server, which can start and run quickly.
⑦ : visual multi data sources: Kibana can easily integrate data from Logstash, ES Hadoop, Beats or third-party technologies into Elasticsearch. The supported third-party technologies include Apache Flume, fluent, etc.
⑧ : simple data export: Kibana can easily export the data of interest, quickly model and analyze after merging with other data sets, and find new results.
6. Configure ELK log analysis system
Configure and install ELK log analysis system, install cluster mode, two elasticsearch nodes, and monitor apache server logs
host operating system host name IP address Main software The server Centos7.4 node1 192.168.226.128 The server Centos7.4 node2 192.168.226.129 The server Centos7.4 apache 192.168.226.130
6.1. Installing elasticsearch cluster
6.1.1 configuring the elasticsearch environment
Change host name configuration domain name resolution view Java environment
hostnamectl set-hostname node1
hostnamectl set-hostname node2
hostnamectl set-hostname apache
vim /etc/hosts
192.168.35.40 node1
192.168.35.10 node2
upload jdk Compressed package to opt Directory
tar xzvf jdk-8u91-linux-x64.tar.gz -C /usr/local/
cd /usr/local/
mv jdk1.8.0_91 jdk
vim /etc/profile
export JAVA_HOME=/usr/local/jdk
export JRE_HOME=${JAVA_HOME}/jreexport CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH
source /etc/profile
java -version
6.1.2 deploying elasticsearch software
Upload the elasticsearch package to the opt directory
rpm -ivh elasticsearch-5.5.0.rpm systemctl daemon-reload ##Load system services systemctl enable elasticsearch ##Open service
Modify elasticsearch configuration file
cd /etc/elasticsearch/ cp elasticsearch.yml elasticsearch.yml.bak vim elasticsearch.yml 17 cluster.name: my-elk-cluster ##Change cluster name 23 node.name: node1 ##Change node name 33 path.data: /data/elk_data ##Change data storage path, elk_data needs to be created manually 37 path.logs: /var/log/elasticsearch ##Change file directory 43 bootstrap.memory_lock: false ##Lock the physical memory address to prevent es memory from being swapped out. Frequent swapping will lead to high IOPS (performance test: read and write times per second) 55 network.host: 0.0.0.0 ##Change to full network segment 59 http.port: 9200 ##Open port 68 discovery.zen.ping.unicast.hosts: ["node1", "node2"] ##Change node name grep -v '^#' /etc/elasticsearch/elasticsearch.yml
mkdir -p /data/elk_data ##Create data storage path chown elasticsearch:elasticsearch /data/elk_data/ ##Change primary group systemctl start elasticsearch ##Open service

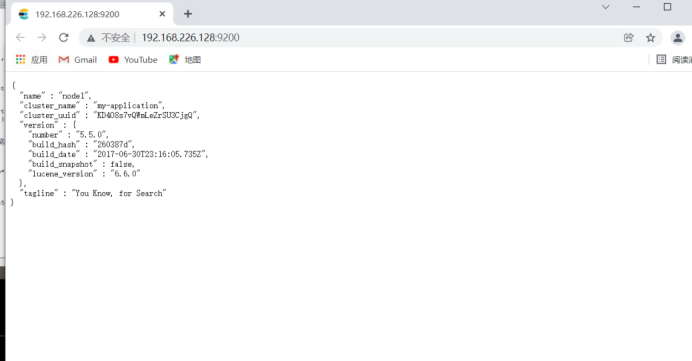
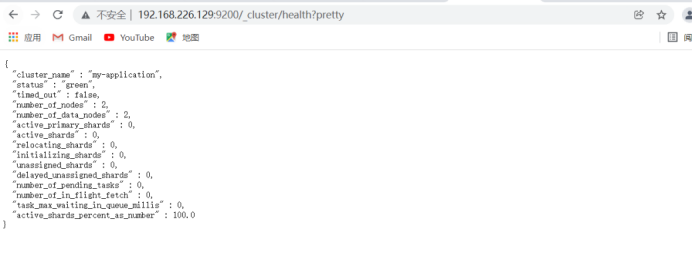
Open on real browser
192.168.226.128:9200/_cluster/health?pretty ##Check cluster health 192.168.226.129:9200/_cluster/state?pretty ##View cluster status
6.1.3 install elasticsearch head plug-in
The above way to view the cluster is inconvenient. We can manage the cluster by installing the elastic search head plug-in
Log in to the 192.168.226.128node1 host
upload node-v8.2.1.tar .gz reach/opt yum -y install gcc gcc-C++ make Compile and install node Component dependent packages take 47 minutes cd /opt tar -xzvf node-v8.2.1.tar.gz cd node-v8.2.1 ./configure make -j3 (This process requires 10 minutes-30 Minutes vary, depending on your computer configuration) make install
6.1.4 installing phantomjs front-end frame
Upload package to/usr/local/src/ cd /usr/local/src/ tar xjvf phantomjs-2.1.1-linux-x86_64.tar.bz2 cd phantomjs-2.1.1-linux-x86_64/bin cp phantomjs /usr/local/bin
6.1.5 install elasticsearch head data visualization tool
cd /usr/local/src/ tar xzvf elasticsearch-head.tar.gz cd elasticsearch-head/ npm install
The node2 server has the same configuration
vim /etc/elasticsearch/elasticsearch.yml ##Modify master profile Insert the following two lines at the end of the configuration file http.cors.enabled: true ##Enable cross domain access support. The default value is false http.cors.allow-origin: "*" ##Allowed domain names and addresses for cross domain access systemctl restart elasticsearch cd /usr/local/src/elasticsearch-head/ npm run start &start-up elasticsearch-head Start the server; Switch to background operation
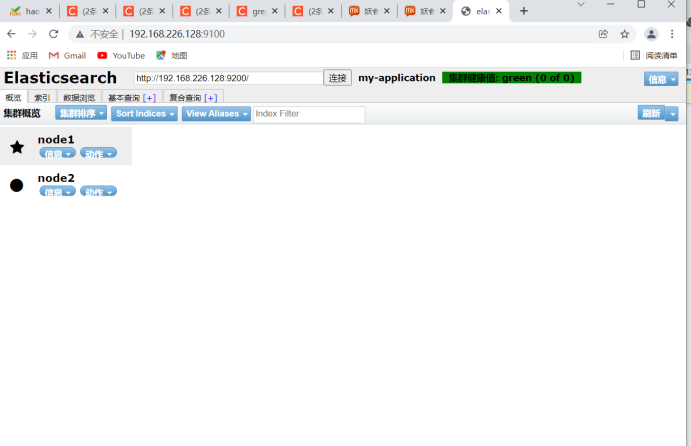
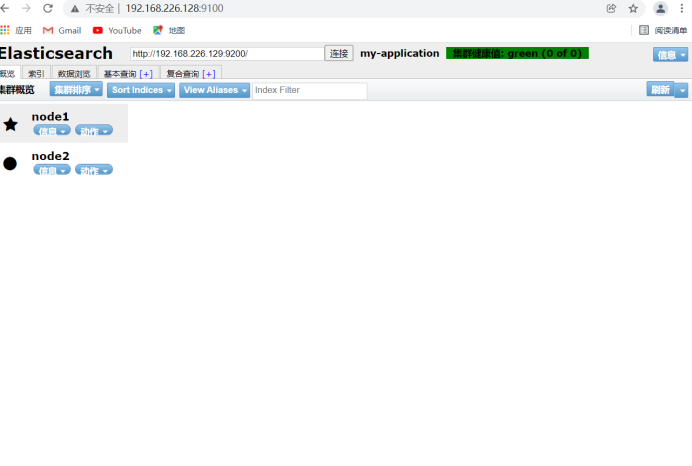
View 192.168.226.128:9100 and 192.168.226.129:9100 on native windows
Changing localhost to node ip will display node status information
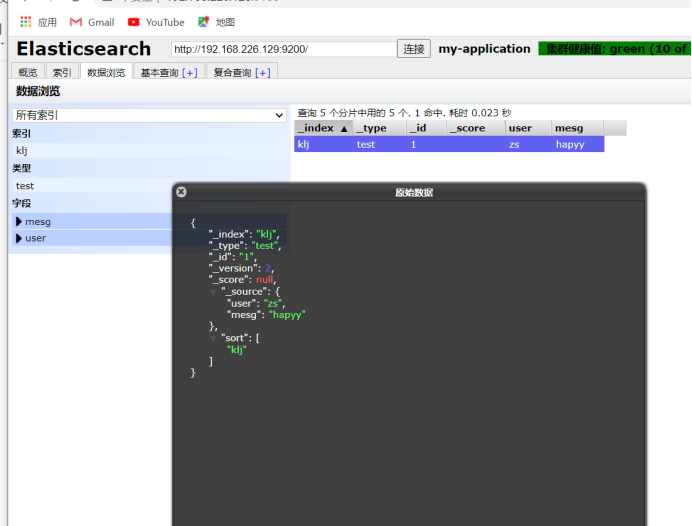
curl -XPUT 'localhost:9200/klj/test/1?pretty&pretty' -H 'conten-TYPE: application/json' -d '{"user":"zs","mesg":"hapyy"}' ##Insert an index called klj, the index type is test, the index content is zs, and the information is happy
6.2 installing logstash
Log in 192.168.35.10 on the Apache server; logstash does some log collection and outputs it to elastic search
6.2.1 change the host name and close the firewall and core protection
hostnamectl set-hostname logstash setenforce 0 systemctl stop firewalld
6.2.2 installing apache service and jdk environment
yum -y install httpd
systemctl start httpd
upload jdk Compressed package to opt Directory
tar xzvf jdk-8u91-linux-x64.tar.gz -C /usr/local/
cd /usr/local/
mv jdk1.8.0_91 jdk
vim /etc/profile
export JAVA_HOME=/usr/local/jdk
export JRE_HOME=${JAVA_HOME}/jreexport CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH
source /etc/profile
java -version
6.2.3 installing logstash
Upload the installation package to the opt directory
cd /opt rpm -ivh logstash-5.5.1.rpm systemctl start logstash.service ln -s /usr/share/logstash/bin/logstash /usr/local/bin/
6.2.4 docking test whether logstash (Apache) and elasticsearch (node) functions normally
Logstash This command tests the field description and interpretation: -f: This option allows you to specify logstash According to the configuration file logstash -e: Followed by a string that can be treated as logstash Configuration of(If yes "", It is used by default stdin As standard input stdout As standard output) -t: Test that the configuration file is correct and exit
6.2.5 standard input / output
logstash agent(agent)Plug in for
①input
②filter
③output
logstash -e 'input { stdin{} } output { stdout{} }'
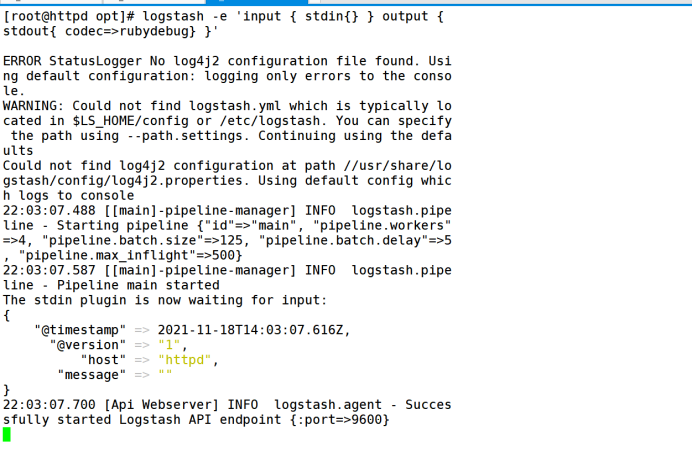
6.2.6 use rubydebug to display detailed output, and codec is a codec
logstash -e 'input { stdin{} } output { stdout{ codec=>rubydebug} }'
6.2.7 use logstash to write information into elastic search and view it
logstash -e 'input { stdin{} } output { elasticsearch { hosts=> ["192.168.35.40:9200"] } }' ##Input / output docking
Input docking without exiting. Access the data browsing of elasticsearch head plug-in in the local window
It can be seen that the overview is more than logstash-2021.8.14
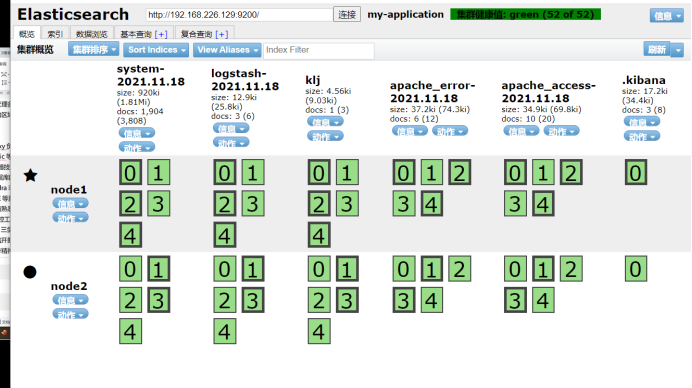
Click data browse to view the corresponding content
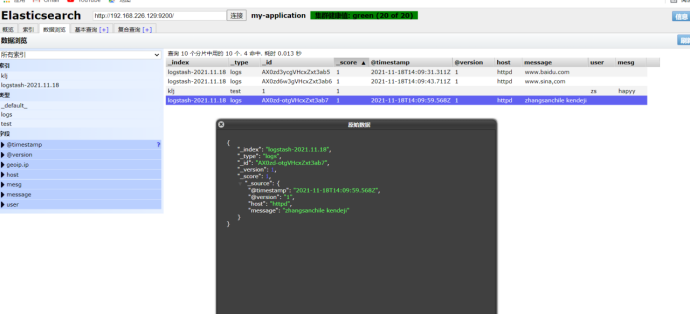
However, it is unrealistic to manually input thousands of data, and the platform needs to be used to collect logs
chmod o+r /var/log/messages ##Add a readable permission to other users
vim /etc/logstash/conf.d/system.conf ##Configuration file (collect system logs)
input {
file{
path => "/var/log/messages" //Path to collect data
type => "system" //type
start_position => "beginning" //Collect data from the beginning
}
}
output {
elasticsearch {
hosts => ["192.168.35.40:9200"] //Output to
index => "system-%{+YYYY.MM.dd}" //Indexes
}
}
systemctl restart logstash.service ##Restart service
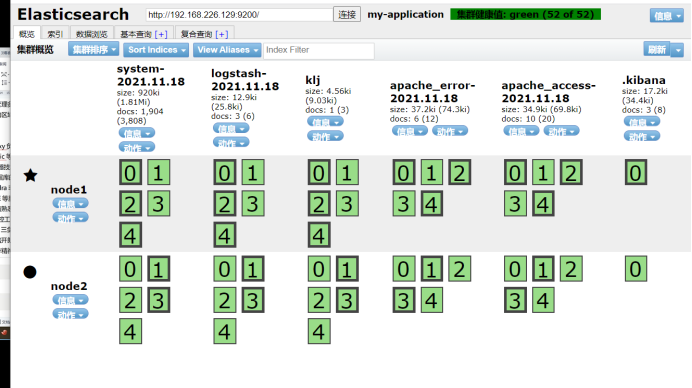
6.3 kibana installed on node1 host
upload kibana-5.5.1-x86_64.rpm reach/usr/local/src catalogue cd /usr/local/src rpm -ivh kibana-5.5.1-x86_64.rpm cd /etc/kibana/ cp kibana.yml kibana.yml.bak vim kibana.yml 2 server.port: 5601 ##kibana open port 7 server.host: "0.0.0.0" ##Address where kibana listens 21 elasticsearch.url: "http://192.168.35.40:9200" ## Contact elasticsearch 30 kibana.index: ".kibana" ##Add. kibana index in elasticsearch systemctl start kibana.service ##Start kibana service To access port 5601: http://192.168.35.40:5601/
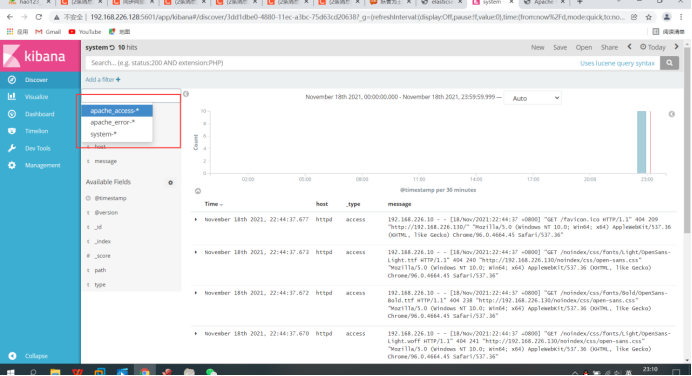
6.3.1 log of docking with apache (accessed and error)
cd /etc/logstash/conf.d/
vim apache_log.conf
input {
file{
path => "/etc/httpd/logs/access_log"
type => "access"
start_position => "beginning"
}
file{
path => "/etc/httpd/logs/error_log"
type => "error"
start_position => "beginning"
}
}
output {
if [type] == "access" {
elasticsearch {
hosts => ["192.168.35.40:9200"]
index => "apache_access-%{+YYYY.MM.dd}"
}
}
if [type] == "error" {
elasticsearch {
hosts => ["192.168.35.40:9200"]
index => "apache_error-%{+YYYY.MM.dd}"
}
}
}
logstash -f apache_log.conf ##Specifies the configuration file that uses apache_log.conf
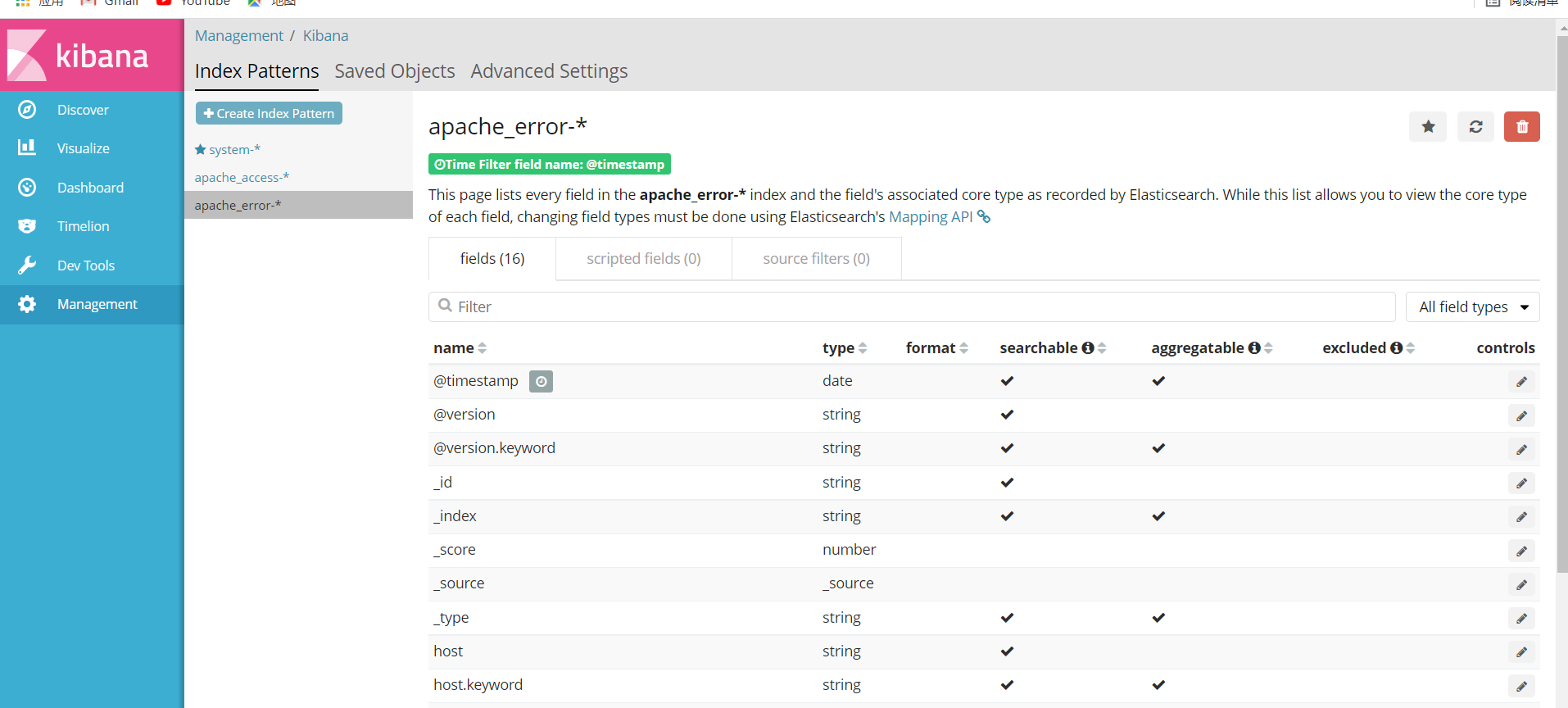
6.3.2 validation index
At this time, you can query Apache_access -, Apache_error -, and system by viewing kibana-*
6, Summary
1.ELK is a set of tools for collecting daily records
2. It is composed of es index database logstash log collection, filtering and output functions (functions in ELK Architecture) kibana (visual display + graphical display + filtering)
3.elk - "understand the architecture of ELK -" 1ogstash (collection, processing and output tools) selection (o logstash function split - filebeat o logstash where to collect)