1, Overview
About 100000 microblog comments are used as training data. Data 1 represents positive comments and 0 represents negative comments. pandas and jieba are used to pre process the data. TFIDF vectorizes the processed data, and then uses support vector machine and naive Bayes to train the processed data set. The algorithm is implemented and trained by using python's sklearn library, and the tool is implemented by juypter # notebook.
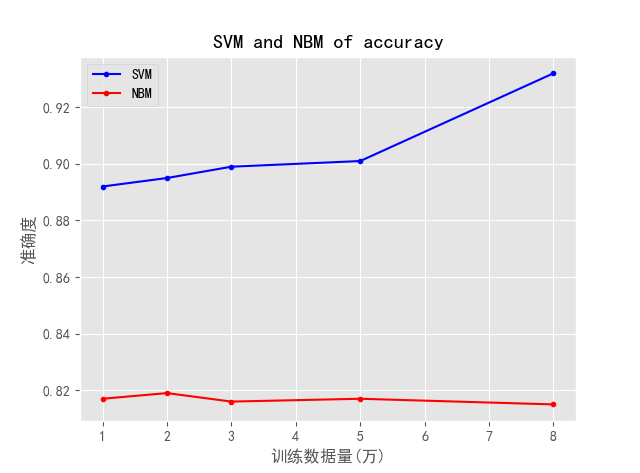
From the training results, it is obvious that the training results of support vector machine are better than those of naive Bayesian algorithm. The accuracy of SVM model will increase with the increase of the amount of data. However, in the actual use process, naive Bayesian model judges non original data more accurately, while support vector machine judges original data more accurately. It can be said that the adaptability of NBM is better than that of SVM. In terms of training time, the training speed of NBM in the same data set is much faster than that of SVM. Each has its own advantages and disadvantages. The following figure shows the judgment results of non original data sets using the trained model.

II. Implementation
Note: the implementation is implemented using juypter} notebook, so the following is also executed in order. Remember;
- data fetch
Use python's pandas to read the dataset data. The data format is shown in the figure below. The total data is more than 100000, which is divided into negative and positive datasets. The data source is microblog comment data.
#Read training dataset
import pandas as pd
test = pd.read_csv(".\\weibo_senti_100k.csv")
test_data = pd.DataFrame(test)
- Data processing
By observing the data set, we find that there are many special symbols, irrelevant people and other words in the data, so we need to remove the stop words. And disrupt the data set to prevent training over fitting.
####Disrupt data sets####
re_test_data = test_data.sample(frac=1).reset_index(drop=True)
####Remove special symbols and word segmentation####
import jieba_fast as jieba
import re
# Use jieba for word segmentation
def chinese_word_cut(mytext):
# Remove [@ user] to avoid affecting the later prediction accuracy
mytext = re.sub(r'@\w+','',mytext)
# Remove alphanumeric strings
mytext = re.sub(r'[a-zA-Z0-9]','',mytext)
return " ".join(jieba.cut(mytext))
# The method of apply is to process the data in rows
re_test_data['cut_review'] = re_test_data.review.apply(chinese_word_cut)
####Stop word processing####
import re
# Get a list of stop words
def get_custom_stopwords(stop_words_file):
with open(stop_words_file,encoding='utf-8') as f:
stopwords = f.read()
stopwords_list = stopwords.split('\n')
custom_stopwords_list = [i for i in stopwords_list]
return custom_stopwords_list
cachedStopWords = get_custom_stopwords(".\\stopwords.txt")
# Method of removing stop words
def remove_stropwords(mytext):
return " ".join([word for word in mytext.split() if word not in cachedStopWords])
re_test_data['remove_strop_word'] = re_test_data.cut_review.apply(remove_stropwords)- Data saving
Save the processed data
####Save data####
# Intercepted and processed comment data and Tags
re_data = re_test_data.loc[:,['remove_strop_word','label']]
# Save the data as a new csv
re_data.to_csv ("re_sentiment_data.csv" , encoding = "utf_8_sig'")- Data segmentation
The processed data is read and segmented. The segmentation method uses the sklearn method for random segmentation, which is divided into training data set X_train,y_train; Test data set x_test,y_test;
####Data segmentation#### X = re_test_data['remove_strop_word'] y = re_test_data.label from sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=11)
- Vectorization, training
In the code, I have written both SVM and NBM model training. What needs to be explained is that Pipeline is a module that connects multiple models.
####Training with NBM
%%time
# Loading model and saving model
from sklearn.externals import joblib
# Naive Bayes
from sklearn.naive_bayes import MultinomialNB
# TFIDF model
from sklearn.feature_extraction.text import TfidfVectorizer
# The pipeline model can connect the two algorithms
from sklearn.pipeline import Pipeline
# Connect TFIDF model with naive Bayesian algorithm
TFIDF_NB_Sentiment_Model = Pipeline([
('TFIDF', TfidfVectorizer()),
('NB', MultinomialNB())
])
# Take 30000 pieces of data for training
nbm = TFIDF_NB_Sentiment_Model.fit(X_train[:80000],y_train[:80000])
nb_train_score = TFIDF_NB_Sentiment_Model.score(X_test,y_test)
joblib.dump(TFIDF_NB_Sentiment_Model, 'tfidf_nb_sentiment.model')
print(nb_train_score)
####or
####use SVM Conduct training####
%%time
from sklearn.svm import SVC
TFIDF_SVM_Sentiment_Model = Pipeline([
('TFIDF', TfidfVectorizer()),
('SVM', SVC(C=0.95,kernel="linear",probability=True))
])
TFIDF_SVM_Sentiment_Model.fit(X_train[:30000],y_train[:30000])
svm_test_score = TFIDF_SVM_Sentiment_Model.score(X_test,y_test)
joblib.dump(TFIDF_SVM_Sentiment_Model, 'tfidf_svm1_sentiment.model')
print(svm_test_score)- forecast
After the trained model, we can predict
import re
from sklearn.externals import joblib
# Get a list of stop words
def get_custom_stopwords(stop_words_file):
with open(stop_words_file,encoding='utf-8') as f:
stopwords = f.read()
stopwords_list = stopwords.split('\n')
custom_stopwords_list = [i for i in stopwords_list]
return custom_stopwords_list
# Method of removing stop words
def remove_stropwords(mytext,cachedStopWords):
return " ".join([word for word in mytext.split() if word not in cachedStopWords])
# Dealing with negative sentences
def Jieba_Intensify(text):
word = re.search(r"no[\u4e00-\u9fa5 ]",text)
if word!=None:
text = re.sub(r"(no )|(no[\u4e00-\u9fa5]{1} )",word[0].strip(),text)
return text
# Judge whether the sentence is negative or positive
def IsPoOrNeg(text):
# Load the trained model
# model = joblib.load('tfidf_nb_sentiment.model')
model = joblib.load('tfidf_svm1_sentiment.model')
# Get a list of stop words
cachedStopWords = get_custom_stopwords(".\\stopwords.txt")
# Remove stop words
text = remove_stropwords(text,cachedStopWords)
# jieba participle
seg_list = jieba.cut(text, cut_all=False)
text = " ".join(seg_list)
# Negative non processing
text = Jieba_Intensify(text)
y_pre =model.predict([text])
proba = model.predict_proba([text])[0]
if y_pre[0]==1:
print(text,":This is most likely a positive emotion (Probability:)"+str(proba[1]))
else:
print(text,":This is most likely a negative emotion (Probability:)"+str(proba[0]))
IsPoOrNeg("I am so happy.")The prediction results are shown in the figure
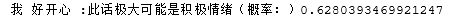
Need source code and data set, please + me Oh~

