Emotion classification with expression data
This is my classroom assignment. Refer to some online codes and articles for reference
Extract and classify text expressions
Get the expression parameter existing in a comment: Path: file path emotion_set: used to store the expression list: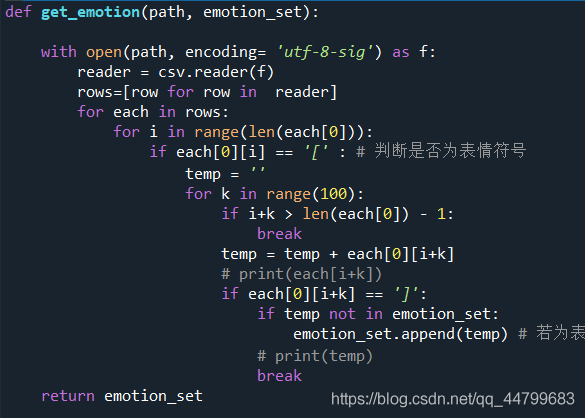 Integrate three file stars csv, hotspot csv and epidemic situation The expression obtained by csv is stored in emotion_result_sat and stored in save_ File under path
Integrate three file stars csv, hotspot csv and epidemic situation The expression obtained by csv is stored in emotion_result_sat and stored in save_ File under path
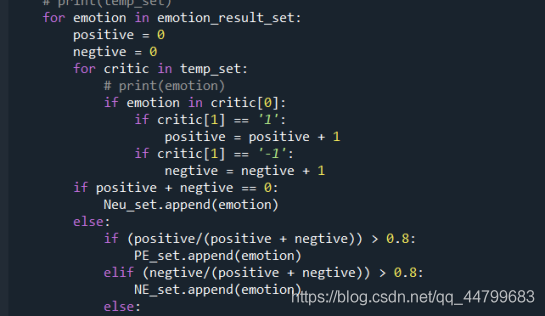
Judge whether the expression is positive or negative according to the number of comment tag 1 or - 1. When more than 80% of the file where an expression is located is positive, the expression represents positive. When more than 80% of the file where an expression is located is negative, the expression represents negative. If neither of them belongs, it is recorded as neutral and actively stored in PE_set, negative stored in NE_set, neutral in Neu_set:
 Comment feature processing
Comment feature processing
Traverse each comment word segmentation processing and de clutter (remove expression, remove @ content and remove stop words)
First, input three groups of initial parameter values x1, U1, X2, U2, X3 and U3 of chaotic sequence, and then save them in the list XL.
Using tfidf feature extraction, take the words with the highest tfidf in the top five feature dimensions for each comment. For comments with less than five, the features are filled with "blank", and the results are visually saved as a file for inspection:
Next, feature construction is carried out for three csv tables storing word segmentation:
 Forecast classification
Forecast classification
Extract characteristic values from a cvs table and add them to the data list:
Initialize the emotion type result list:
Select 30000 text data at intervals for naive Bayes training to generate the model, and the other 30000 use the generated model for prediction and classification to view the classification evaluation results:
On the basis of naive Bayesian prediction results, the expression is used for classification, the emotion represented by the expression is used for calculation, the classification results are predicted, and the evaluation effect is viewed:
Experimental results and analysis
Run the code and get the result:
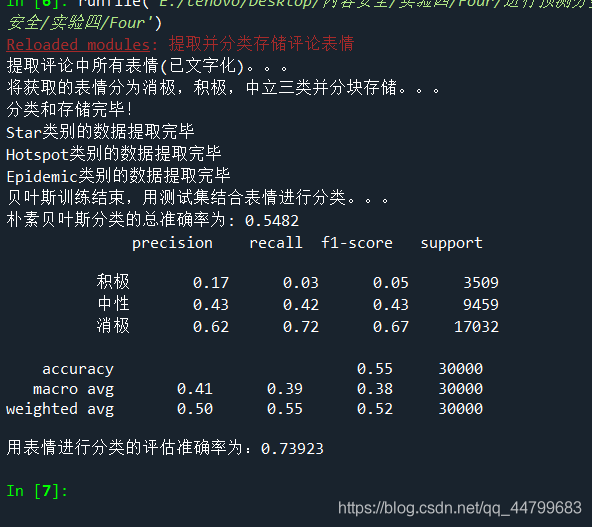 It can be seen that the effect of emotion analysis of text data classification assisted by expression is better than that of naive Bayesian classification alone.
It can be seen that the effect of emotion analysis of text data classification assisted by expression is better than that of naive Bayesian classification alone.
The reference code is pasted later:
Get dataset consolidation
import csv
# Get the expression parameter existing in a comment: Path: file path emotion_set: used to store the expression list
def get_emotion(path, emotion_set):
with open(path, encoding= 'utf-8-sig') as f:
reader = csv.reader(f)
rows=[row for row in reader]
for each in rows:
for i in range(len(each[0])):
if each[0][i] == '[' : # Determine whether it is an emoticon
temp = ''
for k in range(100):
if i+k > len(each[0]) - 1:
break
temp = temp + each[0][i+k]
# print(each[i+k])
if each[0][i+k] == ']':
if temp not in emotion_set:
emotion_set.append(temp) # If it is a emoticon, it is stored in the list so that each symbol appears only once
# print(temp)
break
return emotion_set
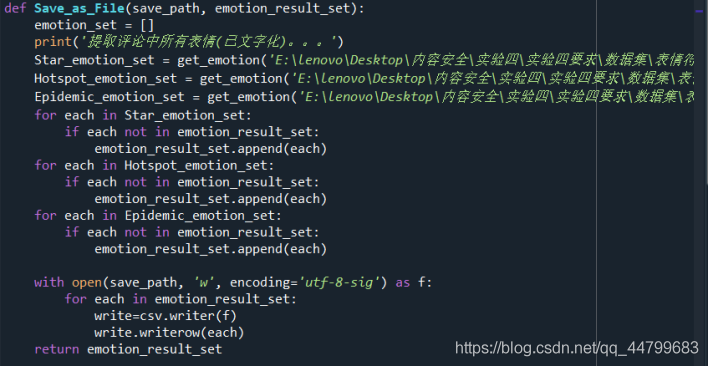
# The expression obtained by integrating three files is stored in emotion_result_sat and stored in save_ File under path
def Save_as_File(save_path, emotion_result_set):
emotion_set = []
print('Extract all expressions in comments(Written). . . ')
Star_emotion_set = get_emotion('Star.csv', emotion_set)
Hotspot_emotion_set = get_emotion('hotspot.csv', emotion_set)
Epidemic_emotion_set = get_emotion('epidemic situation.csv', emotion_set)
for each in Star_emotion_set:
if each not in emotion_result_set:
emotion_result_set.append(each)
for each in Hotspot_emotion_set:
if each not in emotion_result_set:
emotion_result_set.append(each)
for each in Epidemic_emotion_set:
if each not in emotion_result_set:
emotion_result_set.append(each)
with open(save_path, 'w', encoding='utf-8-sig') as f:
for each in emotion_result_set:
write=csv.writer(f)
write.writerow(each)
return emotion_result_set
# Judge whether the expression is positive or negative according to the number of comment tag 1 or - 1, and store the positive in PE_set, negative stored in NE_set
def creat_Respiratory(emotion_result_set):
print('The obtained expressions are divided into three categories: negative, positive and neutral, and stored in blocks...')
PE_set = []
NE_set = []
Neu_set = []
with open('Star.csv',encoding= 'utf-8-sig') as f1:
reader1 = csv.reader(f1)
rows1=[row for row in reader1]
with open('hotspot.csv',encoding= 'utf-8-sig') as f2:
reader2 = csv.reader(f2)
rows2=[row for row in reader2]
with open('epidemic situation.csv',encoding= 'utf-8-sig') as f3:
reader3 = csv.reader(f3)
rows3=[row for row in reader3]
temp_set = []
for a in rows1:
temp_set.append(a)
for b in rows2:
temp_set.append(b)
for c in rows3:
temp_set.append(c) #Store all comments in a list temp_ Within set
# print(temp_set)
for emotion in emotion_result_set:
positive = 0
negtive = 0
for critic in temp_set:
# print(emotion)
if emotion in critic[0]:
if critic[1] == '1':
positive = positive + 1
if critic[1] == '-1':
negtive = negtive + 1
if positive + negtive == 0:
Neu_set.append(emotion)
else:
if (positive/(positive + negtive)) > 0.8:
PE_set.append(emotion)
elif (negtive/(positive + negtive)) > 0.8:
NE_set.append(emotion)
else:
Neu_set.append(emotion)
with open('Positive_emotion.csv', 'w', encoding='utf-8-sig') as f:
for each in PE_set:
write=csv.writer(f)
write.writerow(each)
with open('Negtive_emotion.csv', 'w', encoding='utf-8-sig') as f:
for each in NE_set:
write=csv.writer(f)
write.writerow(each)
with open('Neu_emotion.csv', 'w', encoding='utf-8-sig') as f:
for each in Neu_set:
write=csv.writer(f)
write.writerow(each)
print('Classification and storage completed!')
return PE_set, NE_set, Neu_set
# emotion_result_set = []
# emotion_result_set = Save_as_File('.//emotion//All_emotion.csv', emotion_result_set)
# PE_set, NE_set = creat_Respiratory(emotion_result_set)
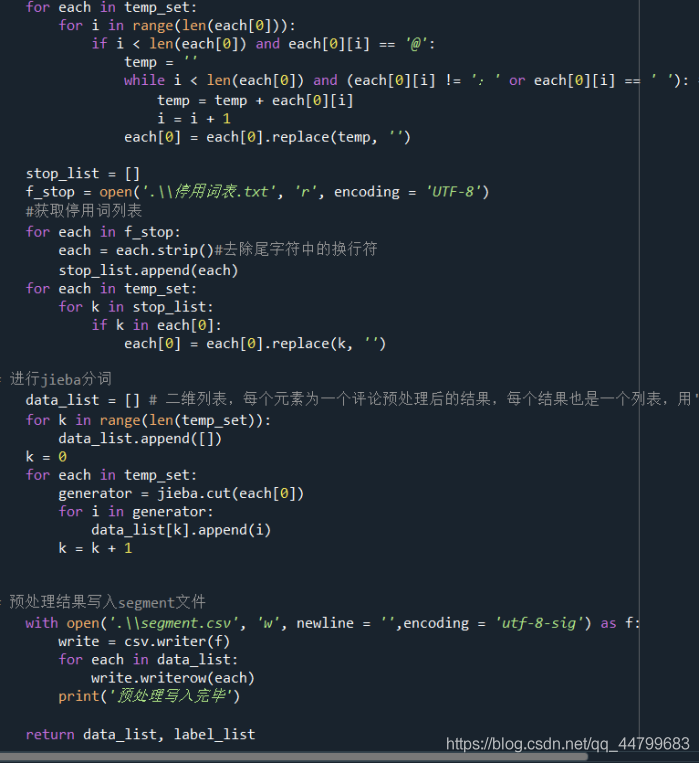
Comment feature processing:
import getdata
import jieba
import csv
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.feature_extraction.text import TfidfTransformer
# 3. tfidf feature extraction, take 5 feature dimensions for each comment, and use "blank fill" for less than 5 comments
# 4. The result visualization is saved as a file for inspection
def PLfenci(emotion_result_set, _class): #Traverse each comment word segmentation processing and de clutter (remove expression, remove @ content and remove stop words)
label_list = [] # One dimensional list, storing comment tags
with open('Star.csv',encoding= 'utf-8-sig') as f1:
reader1 = csv.reader(f1)
rows1=[row for row in reader1]
with open('hotspot.csv',encoding= 'utf-8-sig') as f2:
reader2 = csv.reader(f2)
rows2=[row for row in reader2]
with open('epidemic situation.csv',encoding= 'utf-8-sig') as f3:
reader3 = csv.reader(f3)
rows3=[row for row in reader3]
temp_set = []
for a in rows1:
if _class == 'Star' or _class == 'All':
temp_set.append(a)
label_list.append(a[1])
for b in rows2:
if _class == 'Hotspot' or _class == 'All':
temp_set.append(b)
label_list.append(b[1])
for c in rows3:
if _class == 'Epidemic' or _class == 'All':
temp_set.append(c) #Store comments in a list temp_ Within set
label_list.append(c[1])
if _class == 'All':
return temp_set, label_list
# Remove expressions, remove @ messages and stop words
for i in range(len(temp_set)):
for emotion in emotion_result_set:
if emotion in temp_set[i][0]:
temp_set[i][0] = temp_set[i][0].replace(emotion, '')
for each in temp_set:
for m in range(len(each[0])):
if (each[0][m] == '/') and (each[0][m+1] == '/') and (each[0][m+2] == '@'):
while m < len(each[0]):
each[0] = each[0].replace(each[0][m], '')
m+=1
break
for each in temp_set:
for i in range(len(each[0])):
if i < len(each[0]) and each[0][i] == '@':
temp = ''
while i < len(each[0]) and (each[0][i] != ': ' or each[0][i] == ' '): # Note to use Chinese ':'
temp = temp + each[0][i]
i = i + 1
each[0] = each[0].replace(temp, '')
stop_list = []
f_stop = open('.\\stop list .txt', 'r', encoding = 'UTF-8')
#Get a list of stop words
for each in f_stop:
each = each.strip()#Remove line breaks from trailing characters
stop_list.append(each)
for each in temp_set:
for k in stop_list:
if k in each[0]:
each[0] = each[0].replace(k, '')
# jieba word segmentation
data_list = [] # Two dimensional list, each element is the result of a comment preprocessing, and each result is also a list, separated by ','.
for k in range(len(temp_set)):
data_list.append([])
k = 0
for each in temp_set:
generator = jieba.cut(each[0])
for i in generator:
data_list[k].append(i)
k = k + 1
# The preprocessing result is written to the segment file
with open('.\\segment.csv', 'w', newline = '',encoding = 'utf-8-sig') as f:
write = csv.writer(f)
for each in data_list:
write.writerow(each)
print('Preprocessing write completed')
return data_list, label_list
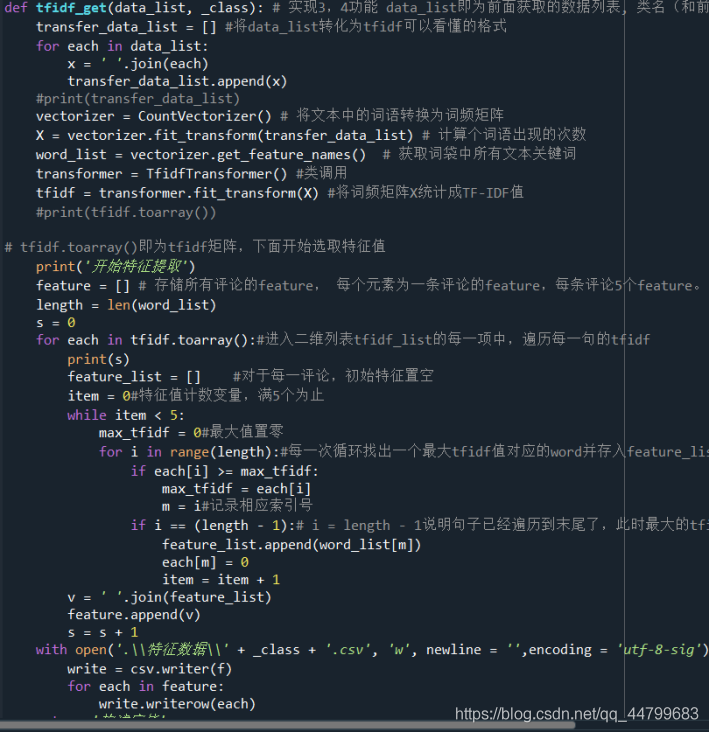
def tfidf_get(data_list, _class): # Realize 3 and 4 functions_ List is the data list obtained earlier, and the class name is the same as the previous function
transfer_data_list = [] #data_list into a format that tfidf can understand
for each in data_list:
x = ' '.join(each)
transfer_data_list.append(x)
#print(transfer_data_list)
vectorizer = CountVectorizer() # Convert words in text into word frequency matrix
X = vectorizer.fit_transform(transfer_data_list) # Count the number of occurrences of a word
word_list = vectorizer.get_feature_names() # Get all text keywords in the word bag
transformer = TfidfTransformer() #Class call
tfidf = transformer.fit_transform(X) #Count the word frequency matrix X into TF-IDF value
#print(tfidf.toarray())
# tfidf.toarray() is the TFIDF matrix. Let's start selecting eigenvalues
print('Start feature extraction')
feature = [] # Store the features of all comments. Each element is the feature of one comment, and each comment has 5 features.
length = len(word_list)
s = 0
for each in tfidf.toarray():#Enter the 2D list tfidf_ In each item of the list, traverse the tfidf of each sentence
print(s)
feature_list = [] #For each comment, the initial feature is left blank
item = 0#Eigenvalue count variables until 5 are full
while item < 5:
max_tfidf = 0#Set maximum to zero
for i in range(length):#Each cycle finds the word corresponding to a maximum tfidf value and stores it in the feature_list list, concatenate the tfidf = 0
if each[i] >= max_tfidf:
max_tfidf = each[i]
m = i#Record the corresponding index number
if i == (length - 1):# i = length - 1 indicates that the sentence has been traversed to the end, and the maximum tfidf value can be determined
feature_list.append(word_list[m])
each[m] = 0
item = item + 1
v = ' '.join(feature_list)
feature.append(v)
s = s + 1
with open('.\\Characteristic data\\' + _class + '.csv', 'w', newline = '',encoding = 'utf-8-sig') as f:
write = csv.writer(f)
for each in feature:
write.writerow(each)
return 'Build complete'
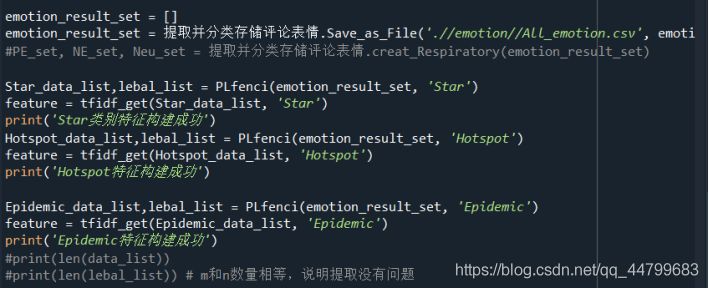
'''
emotion_result_set = []
emotion_result_set = Extract and classify comment expressions.Save_as_File('.//emotion//All_emotion.csv', emotion_result_set)
#PE_set, NE_set, Neu_set = extract and classify comment expressions creat_Respiratory(emotion_result_set)
Star_data_list,lebal_list = PLfenci(emotion_result_set, 'Star')
feature = tfidf_get(Star_data_list, 'Star')
print('Star Category feature successfully constructed')
Hotspot_data_list,lebal_list = PLfenci(emotion_result_set, 'Hotspot')
feature = tfidf_get(Hotspot_data_list, 'Hotspot')
print('Hotspot Feature construction succeeded')
Epidemic_data_list,lebal_list = PLfenci(emotion_result_set, 'Epidemic')
feature = tfidf_get(Epidemic_data_list, 'Epidemic')
print('Epidemic Feature construction succeeded')
#print(len(data_list))
#print(len(lebal_list)) # The number of m and n is equal, indicating that there is no problem with extraction
#print(data_list)
'''
Forecast classification:
import getdata
import csv
from sklearn.model_selection import train_test_split #Data set partition
from sklearn.naive_bayes import MultinomialNB # From sklean naive_ Introducing naive Bayesian model into Bayes
from sklearn.feature_extraction.text import CountVectorizer # From sklearn feature_ extraction. Import text feature vectorization module in text
from sklearn.metrics import classification_report
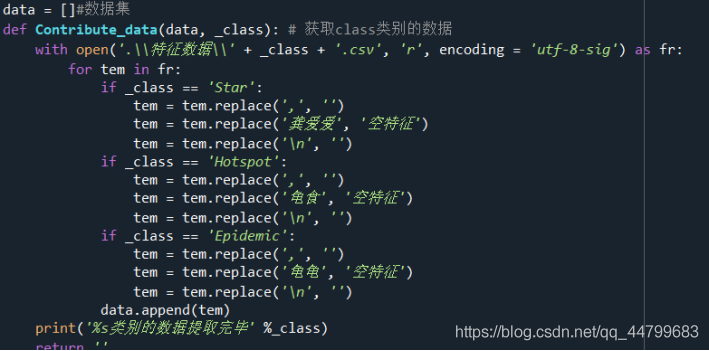
data = []#data set
def Contribute_data(data, _class): # Get data of class category
with open('\\Characteristic data\\' + _class + '.csv', 'r', encoding = 'utf-8-sig') as fr:
for tem in fr:
if _class == 'Star':
tem = tem.replace(',', '')
tem = tem.replace('Gong Aiai', 'Null feature')
tem = tem.replace('\n', '')
if _class == 'Hotspot':
tem = tem.replace(',', '')
tem = tem.replace('Turtle food', 'Null feature')
tem = tem.replace('\n', '')
if _class == 'Epidemic':
tem = tem.replace(',', '')
tem = tem.replace('Tortoise', 'Null feature')
tem = tem.replace('\n', '')
data.append(tem)
print('%s Category data extraction completed' %_class)
return ''
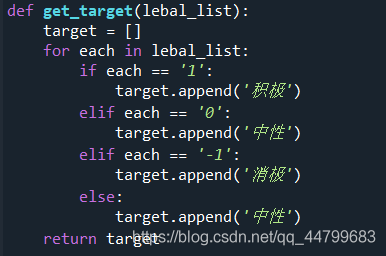
def get_target(lebal_list):
target = []
for each in lebal_list:
if each == '1':
target.append('positive')
elif each == '0':
target.append('neutral')
elif each == '-1':
target.append('negative')
else:
target.append('neutral')
return target
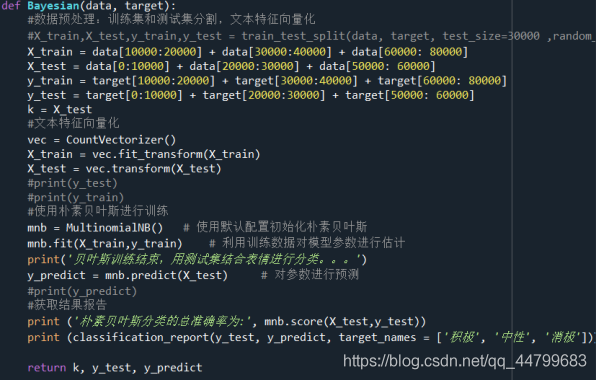
def Bayesian(data, target):
#Data preprocessing: training set and test set segmentation, text feature vectorization
#X_train,X_test,y_train,y_test = train_test_split(data, target, test_size=30000 ,random_state=4) # Randomly sampled data samples are used as test sets
X_train = data[10000:20000] + data[30000:40000] + data[60000: 80000]
X_test = data[0:10000] + data[20000:30000] + data[50000: 60000]
y_train = target[10000:20000] + target[30000:40000] + target[60000: 80000]
y_test = target[0:10000] + target[20000:30000] + target[50000: 60000]
k = X_test
#Text feature Vectorization
vec = CountVectorizer()
X_train = vec.fit_transform(X_train)
X_test = vec.transform(X_test)
#print(y_test)
#print(y_train)
#Training using naive Bayes
mnb = MultinomialNB() # Initialize naive Bayes with default configuration
mnb.fit(X_train,y_train) # The training data are used to estimate the model parameters
print('At the end of Bayesian training, use the test set combined with expression to classify...')
y_predict = mnb.predict(X_test) # Predict parameters
#print(y_predict)
#Get results report
print ('The total accuracy of naive Bayesian classification is:', mnb.score(X_test,y_test))
print (classification_report(y_test, y_predict, target_names = ['positive', 'neutral', 'negative']))
return k, y_test, y_predict
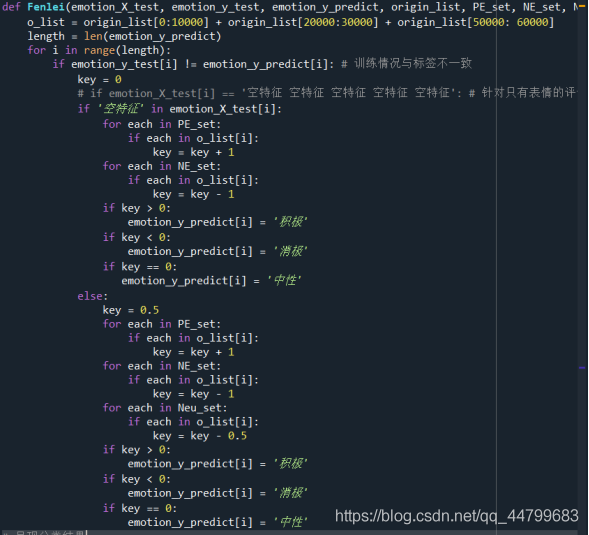
def Fenlei(emotion_X_test, emotion_y_test, emotion_y_predict, origin_list, PE_set, NE_set, Neu_set): # Using expression training
o_list = origin_list[0:10000] + origin_list[20000:30000] + origin_list[50000: 60000]
length = len(emotion_y_predict)
for i in range(length):
if emotion_y_test[i] != emotion_y_predict[i]: # The training is inconsistent with the label
key = 0
# if emotion_X_test[i] == 'Empty feature empty feature empty feature empty feature empty feature': # Comments on expressions only
if 'Null feature' in emotion_X_test[i]:
for each in PE_set:
if each in o_list[i]:
key = key + 1
for each in NE_set:
if each in o_list[i]:
key = key - 1
if key > 0:
emotion_y_predict[i] = 'positive'
if key < 0:
emotion_y_predict[i] = 'negative'
if key == 0:
emotion_y_predict[i] = 'neutral'
else:
key = 0.5
for each in PE_set:
if each in o_list[i]:
key = key + 1
for each in NE_set:
if each in o_list[i]:
key = key - 1
for each in Neu_set:
if each in o_list[i]:
key = key - 0.5
if key > 0:
emotion_y_predict[i] = 'positive'
if key < 0:
emotion_y_predict[i] = 'negative'
if key == 0:
emotion_y_predict[i] = 'neutral'
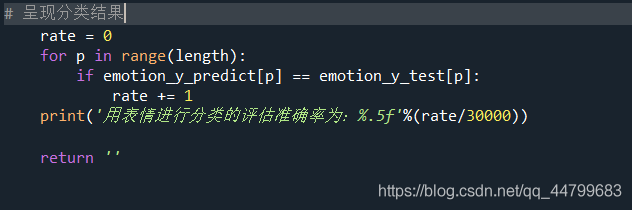
# Present classification results
rate = 0
for p in range(length):
if emotion_y_predict[p] == emotion_y_test[p]:
rate += 1
print('The evaluation accuracy of classification by expression is:%.5f'%(rate/30000))
return ''
emotion_result_set = []
emotion_result_set = Extract and classify comment expressions.Save_as_File('All_emotion.csv', emotion_result_set)
PE_set, NE_set, Neu_set = Extract and classify comment expressions.creat_Respiratory(emotion_result_set)
Star_data_list,lebal_list = Comment feature processing.PLfenci(emotion_result_set, 'Star')
feature = Comment feature processing.tfidf_get(Star_data_list, 'Star')
print('Star Category feature successfully constructed')
Hotspot_data_list,lebal_list = Comment feature processing.PLfenci(emotion_result_set, 'Hotspot')
feature = Comment feature processing.tfidf_get(Hotspot_data_list, 'Hotspot')
print('Hotspot Feature construction succeeded')
Epidemic_data_list,lebal_list = Comment feature processing.PLfenci(emotion_result_set, 'Epidemic')
feature = Comment feature processing.tfidf_get(Epidemic_data_list, 'Epidemic')
print('Epidemic Feature construction succeeded')
Contribute_data(data, 'Star')
Contribute_data(data, 'Hotspot')
Contribute_data(data, 'Epidemic')
origin_list, lebal_list = Comment feature processing.PLfenci(emotion_result_set, 'All')
target = get_target(lebal_list)
emotion_X_test, emotion_y_test, emotion_y_predict = Bayesian(data, target)
#print(len(emotion_y_test))
Fenlei(emotion_X_test, emotion_y_test, emotion_y_predict, origin_list, PE_set, NE_set, Neu_set)
'''accuracy: precision,The correct prediction is positive, accounting for the proportion of all predictions is positive, TP / (TP+FP)
Recall rate: recall,The proportion of correctly predicted positive in all actual positive, TP / (TP+FN)
F1-score: Harmonic average of accuracy and recall, 2 * precision*recall / (precision+recall)
support: The total number of samples in the test data for the category of the current row
At the same time, it also gives the overall micro average, macro average and weighted average.
accuracy: Calculation accuracy (TP+TN) / (TP+FP+FN+TN)
macro avg: Various precision,recall,f1 Add and average
weighted avg :For each category f1_score Carry out weighted average, and the weight is the number of each category y_true Proportion in
'''