Advances in flume learning
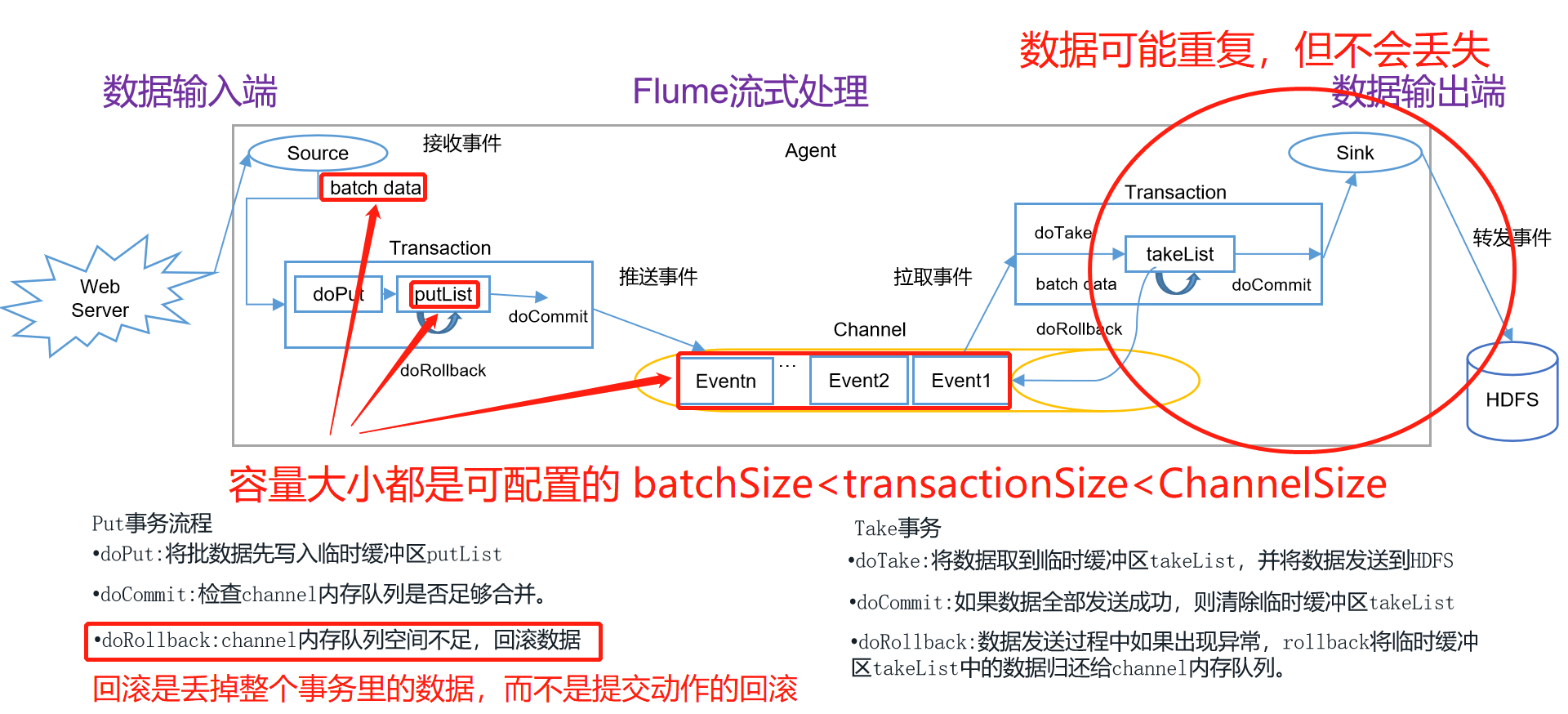
Flume Transactions
The primary purpose is to ensure data consistency, either with success or with failure.
Transaction schematics
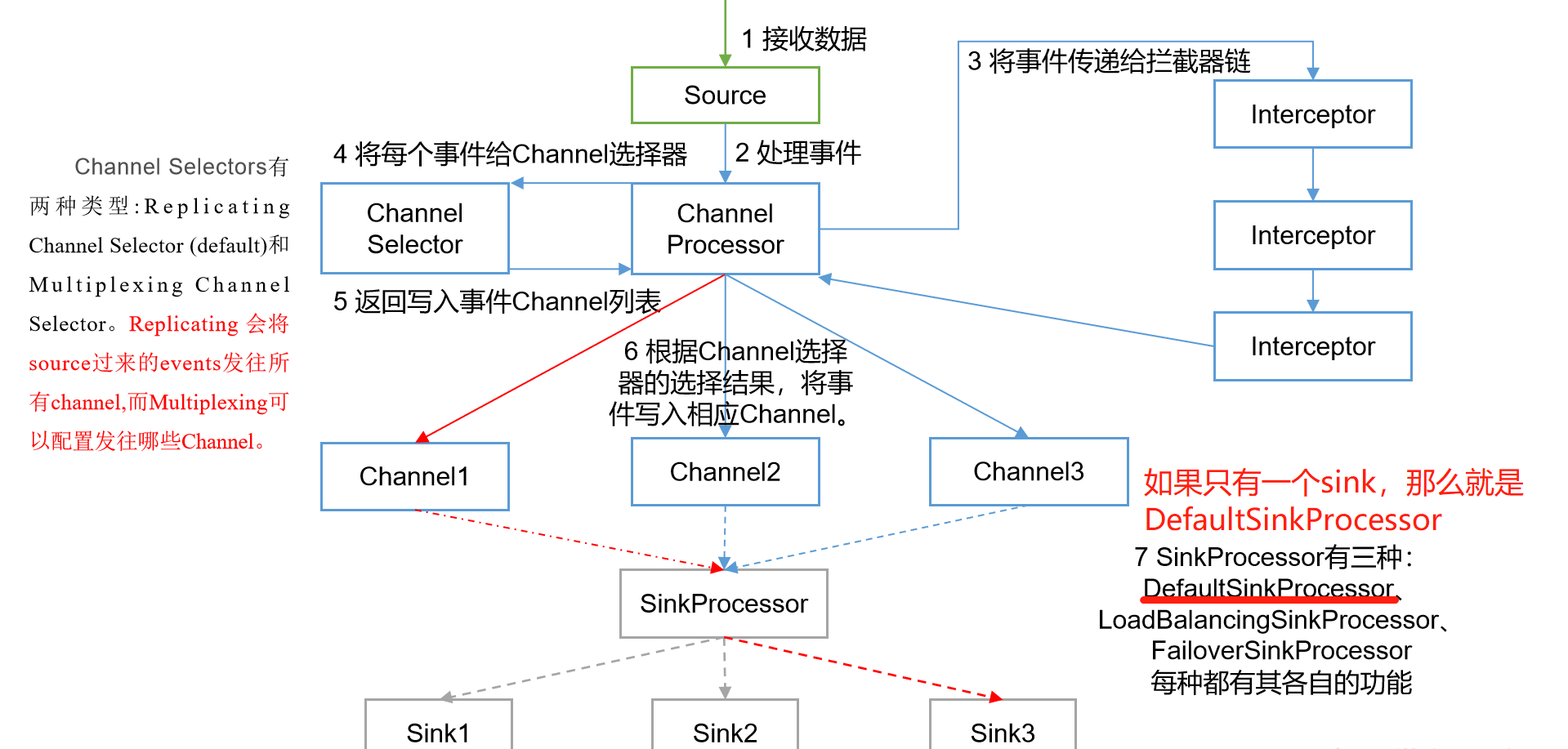
Flume Agent Internal Principles
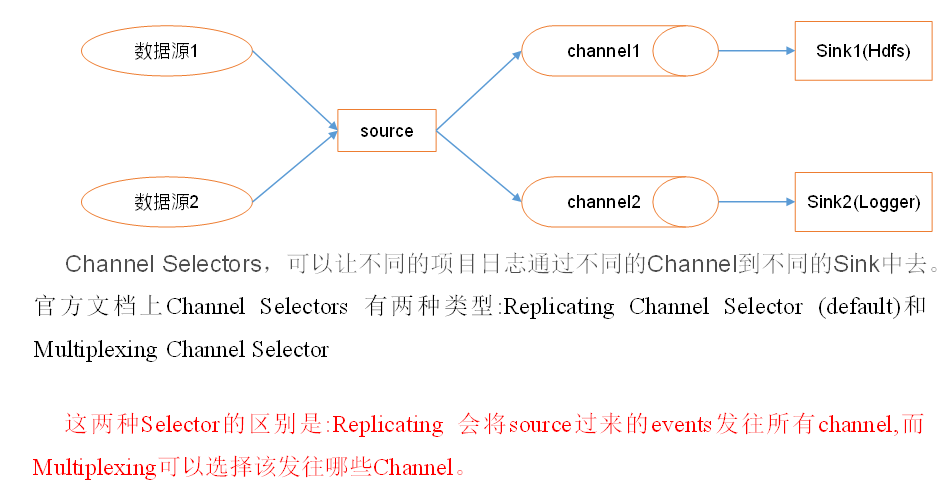
To summarize: That is to say Source Collected in event Not directly to channel Instead, a ChannelProcessor,this processor Will let us event Goes to take the interceptor chain, and then processor After passing through the interceptor chain event Send to ChannelSelector,selector There are two types: Replicating Channel Selector and Multiplexing Channel Selector,The former will event To each channel Send one copy in each, and the latter is to be configured to determine which to go to channel Sent in. Arrived channel After middle, another one will pass by SinkProcessor,sinkProcessor There are three types: defaultSinkProcessor, LoadBalancingSinkProcessor,FailoverSinkProcessor,The first is for only one channel In this case, the second is load balanced, which will vary according to an algorithm channel transmission event,The third is that failover is highly available.
Schematic diagram
Flume Topology
Use multiple flume s together
Simple series
In this series structure, A is required to be client, B is server, A sink is AVRO,B source is AVRO.
Start Server-side B at startup
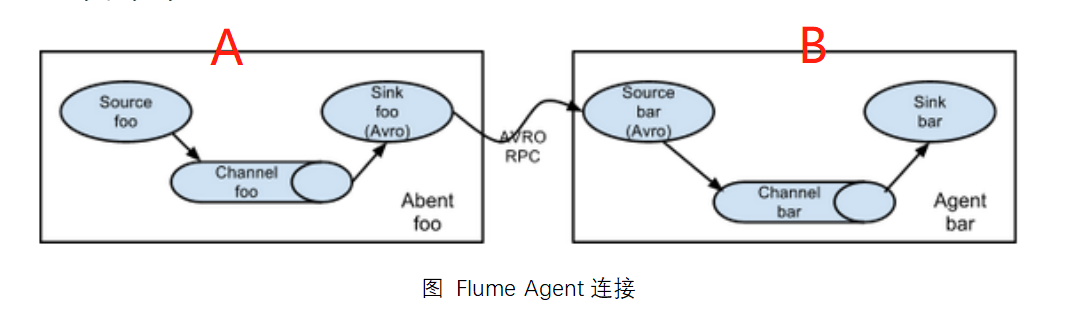
This mode connects multiple flumes sequentially, starting from the initial source to the destination storage system for the final sink transfer. This mode does not recommend bridging too many flumes. Too many flumes will not only affect the transfer rate, but will also affect the entire transmission system once a node flumes down during the transfer process.
Replication and multiplexing
Copy: A copy of the data is copied to a different channel and finally to hdfs,kafka, and other flume s.
Multiplexing: One piece of data is separated into unused channels, one part to hdfs, one part to kafka, etc. This can be achieved by multiplexing channel selector
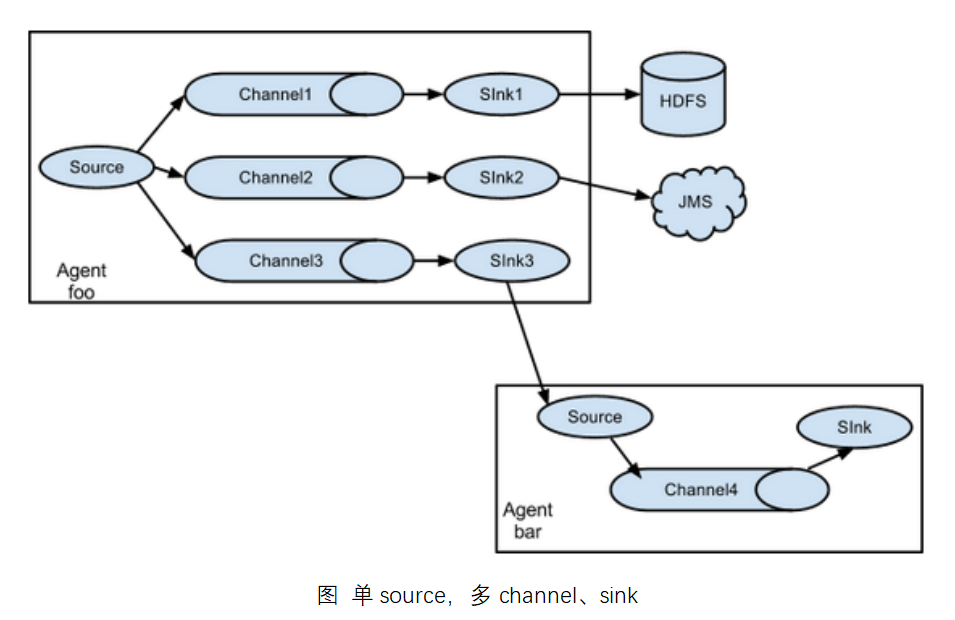
Flume supports the flow of events to one or more destinations. This mode allows you to copy the same data to multiple channels or distribute different data to different channels, and sink can choose to transfer to different destinations.
Load Balancing and Failover
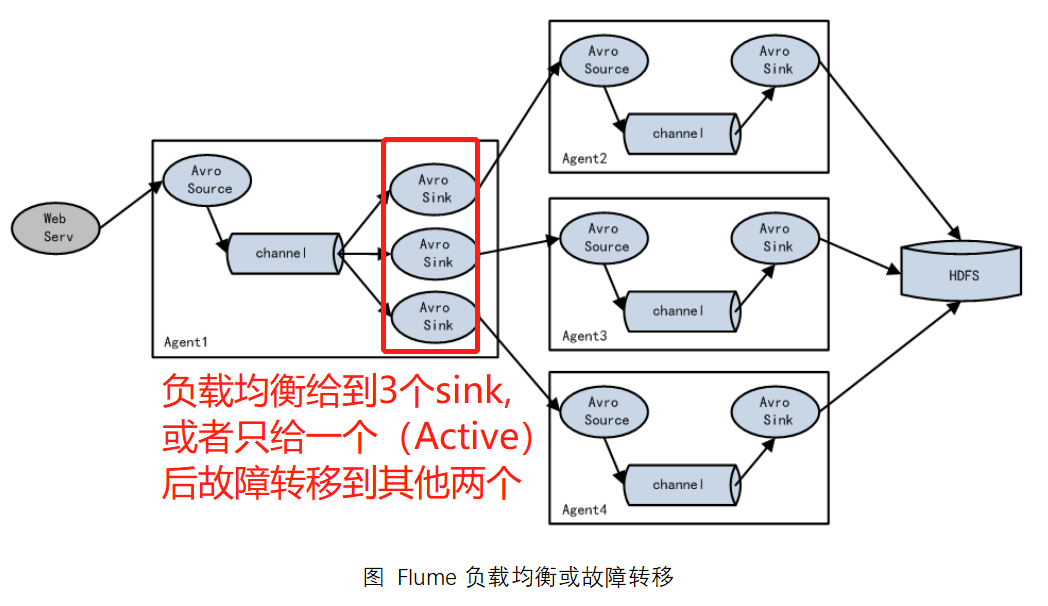
Flume supports the use of logically grouping multiple sinks into a single sink group that can work with different SinkProcessor s to achieve load balancing and error recovery.
polymerization
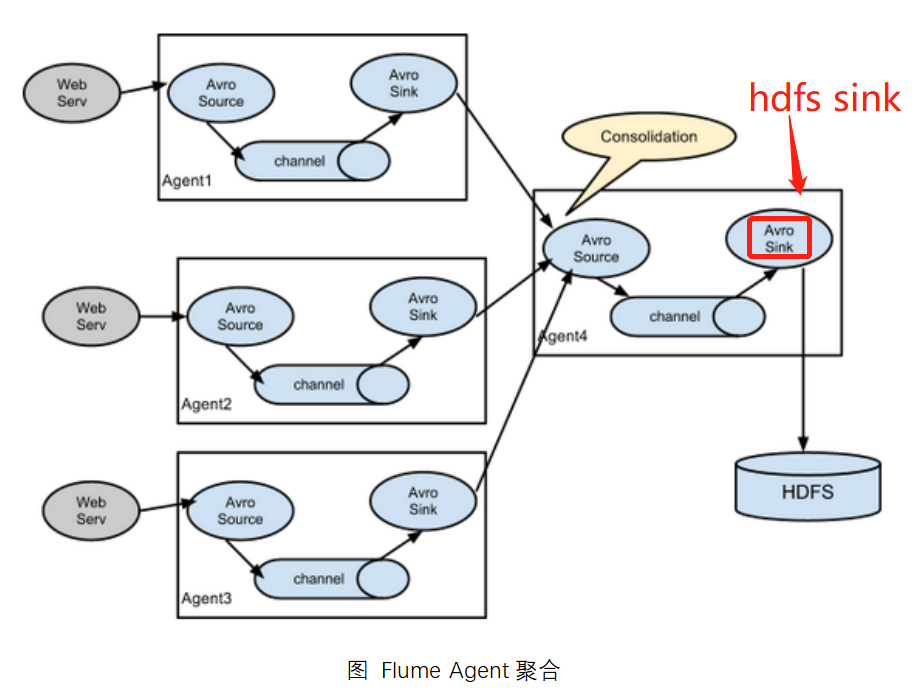
This is the most common and practical mode for us. Daily web applications are usually distributed over hundreds of servers, or even thousands or thousands of servers. The resulting logs can be very cumbersome to process. This combination of flumes can solve this problem very well. Each server deploys a flume to collect logs and send them to a flume that collects logs centrally.Flume is then uploaded to hdfs, hive, hbase, and so on for log analysis.
Flume Enterprise Development Case
Replication and multiplexing cases
copy
Requirements: Use Flume-1 to monitor file changes,
Flume-1 passes changes to Flume-2, which stores them in HDFS.
Flume-1 passes changes to Flume-3, which is responsible for output to the Local FileSystem.
Architecture diagram
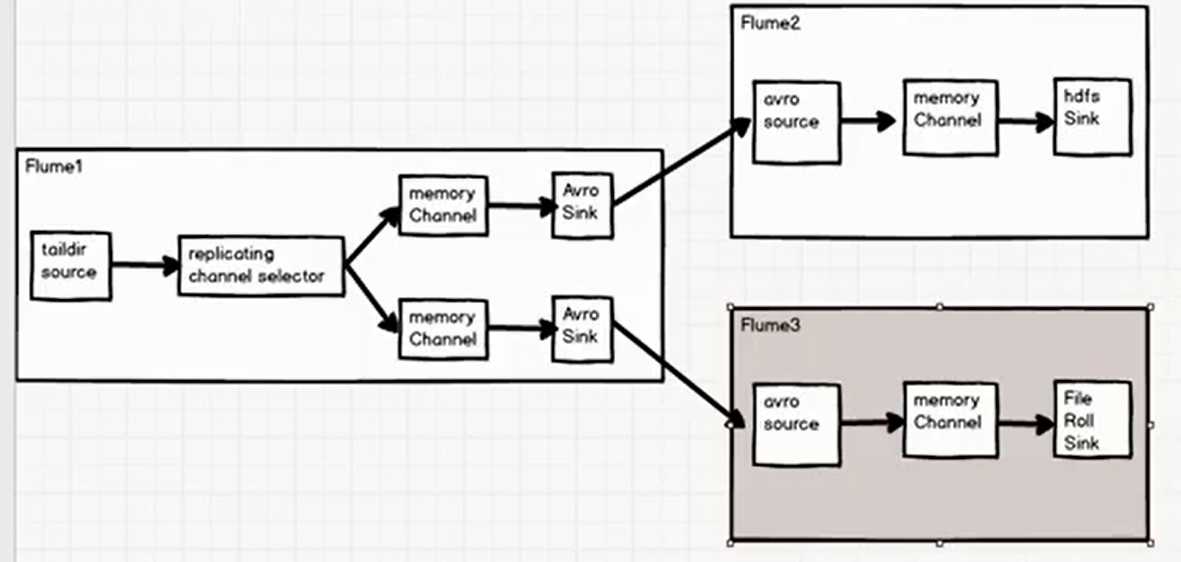
Dead work
# Create a replicating folder in the / opt/module/flume-1.9.0/jobs directory to store flume1,2,3 configurations [atguigu@hadoop102 jobs]$ pwd /opt/module/flume-1.9.0/jobs [atguigu@hadoop102 jobs]$ mkdir replicating [atguigu@hadoop102 jobs]$ cd replicating/ [atguigu@hadoop102 replicating]$ ls
Write flume3.conf configuration against structure
# Processing data, writing out to local file system # Name a3.sources = r1 a3.sinks = k1 a3.channels = c1 # source, need to dock with the last agent, use avro a3.sources.r1.type = avro a3.sources.r1.bind = localhost a3.sources.r1.port = 8888 # sink a3.sinks.k1.type = file_roll # Remember to create the fileroll folder a3.sinks.k1.sink.directory = /opt/module/flume-1.9.0/jobs/fileroll # channel a3.channels.c1.type = memory a3.channels.c1.capacity = 1000 a3.channels.c1.transactionCapacity = 100 # Bind a3.sources.r1.channels = c1 a3.sinks.k1.channel = c1
Write flume2.conf configuration against structure
# Processing data, writing out to hdfs # Name a2.sources = r1 a2.sinks = k1 a2.channels = c1 # source, need to dock with the last agent, use avro a2.sources.r1.type = avro a2.sources.r1.bind = localhost a2.sources.r1.port = 7777 # sink a2.sinks.k1.type = hdfs # Note that path here is the configuration of fs.defaultFS in core-site.xml of hdfs a2.sinks.k1.hdfs.path = hdfs://hadoop102:9820/flume/%Y%m%d/%H #Prefix for uploading files a2.sinks.k1.hdfs.filePrefix = logs- #Whether to scroll folders according to time a2.sinks.k1.hdfs.round = true #How much time unit to create a new folder a2.sinks.k1.hdfs.roundValue = 1 #Redefine time units a2.sinks.k1.hdfs.roundUnit = hour #Whether to use local timestamps a2.sinks.k1.hdfs.useLocalTimeStamp = true #How many Event s to flush to HDFS once a2.sinks.k1.hdfs.batchSize = 100 #Set file type to support compression a2.sinks.k1.hdfs.fileType = DataStream #How often to generate a new file in seconds a2.sinks.k1.hdfs.rollInterval = 60 #Set the scroll size of 128M for each file a2.sinks.k1.hdfs.rollSize = 134217700 #File scrolling is independent of the number of Event s a2.sinks.k1.hdfs.rollCount = 0 # channel a2.channels.c1.type = memory a2.channels.c1.capacity = 1000 a2.channels.c1.transactionCapacity = 100 # Bind a2.sources.r1.channels = c1 a2.sinks.k1.channel = c1
Write flume1.conf configuration against structure
# This is an upstream agent and needs to dock two downstream agents flume2, flume3 a1.sources = r1 a1.sinks = k1 k2 a1.channels = c1 c2 # Specify source configuration a1.sources.r1.type = TAILDIR # Multiple groups can be set a1.sources.r1.filegroups = f1 # Monitored Directory a1.sources.r1.filegroups.f1 = /opt/module/flume-1.9.0/jobs/taildir/.*\.txt # Breakpoint Continuation (json format) a1.sources.r1.positionFile = /opt/module/flume-1.9.0/jobs/position/position.json # channel Selector configuration a1.sources.r1.selector.type = replicating # Specify sink configuration (two sinks) a1.sinks.k1.type = avro a1.sinks.k1.hostname = localhost a1.sinks.k1.port = 7777 a1.sinks.k2.type = avro a1.sinks.k2.hostname = localhost a1.sinks.k2.port = 8888 # Specify channel configuration (two channels) a1.channels.c1.type = memory a1.channels.c1.capacity = 10000 a1.channels.c1.transactionCapacity = 100 a1.channels.c2.type = memory a1.channels.c2.capacity = 10000 a1.channels.c2.transactionCapacity = 100 # Specify the binding relationship between source,sink,channel a1.sources.r1.channels = c1 c2 a1.sinks.k1.channel = c1 a1.sinks.k2.channel = c2
Execute flume command
# flume3 flume-ng agent -c $FLUME_HOME/conf -f $FLUME_HOME/jobs/replicating/flume3.conf -n a3 -Dflume.root.logger=INFO,console # flume2 flume-ng agent -c $FLUME_HOME/conf -f $FLUME_HOME/jobs/replicating/flume2.conf -n a2 -Dflume.root.logger=INFO,console # flume1 flume-ng agent -c $FLUME_HOME/conf -f $FLUME_HOME/jobs/replicating/flume1.conf -n a1 -Dflume.root.logger=INFO,console
Append content to/opt/module/flume-1.9.0/jobs/taildir/.*.txt
[atguigu@hadoop102 taildir]$ pwd /opt/module/flume-1.9.0/jobs/taildir [atguigu@hadoop102 taildir]$ ll Total usage 16 -rw-rw-r--. 1 atguigu atguigu 12 10 January 1019:29 file1.txt -rw-rw-r--. 1 atguigu atguigu 13 10 January 1019:30 file2.txt [atguigu@hadoop102 taildir]$ echo hello >> file1.txt [atguigu@hadoop102 taildir]$ echo pihao >> file2.txt [atguigu@hadoop102 taildir]$
View content in hdfs
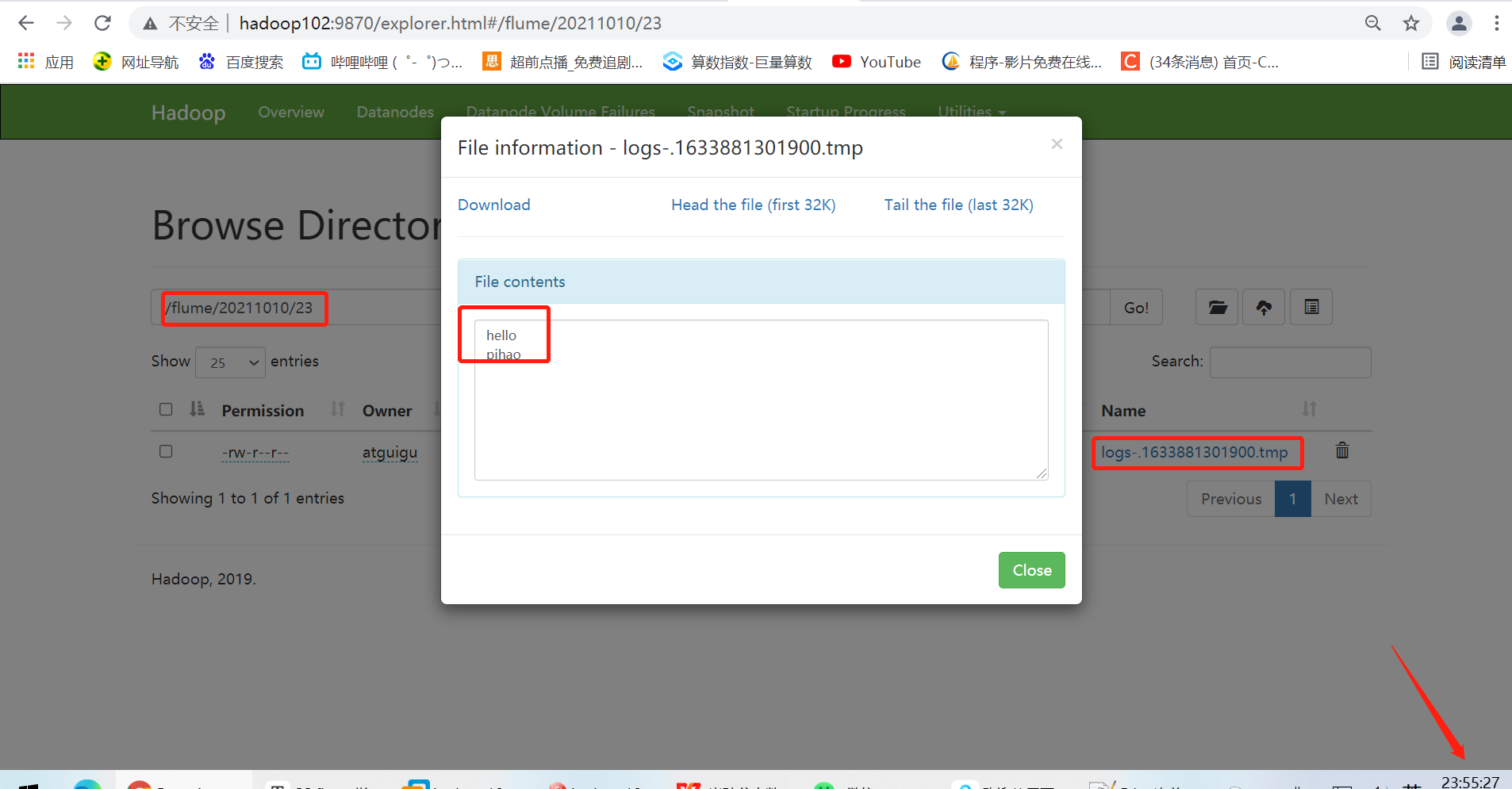
View local system content
[atguigu@hadoop102 fileroll]$ pwd /opt/module/flume-1.9.0/jobs/fileroll [atguigu@hadoop102 fileroll]$ [atguigu@hadoop102 fileroll]$ ll Total usage 8 # This locality is a bit odd. It generates a file every 30s, with or without new content -rw-rw-r--. 1 atguigu atguigu 0 10 January 1023:52 1633881154435-1 -rw-rw-r--. 1 atguigu atguigu 0 10 January 1023:53 1633881154435-2 -rw-rw-r--. 1 atguigu atguigu 6 10 January 1023:55 1633881154435-3 -rw-rw-r--. 1 atguigu atguigu 6 10 January 1023:55 1633881154435-4 [atguigu@hadoop102 fileroll]$ cat 1633881154435-3 hello [atguigu@hadoop102 fileroll]$ cat 1633881154435-4 pihao
The test is complete, now a copy of the data is transferred to a different destination, copy the test OK!
Load Balancing and Failover Cases
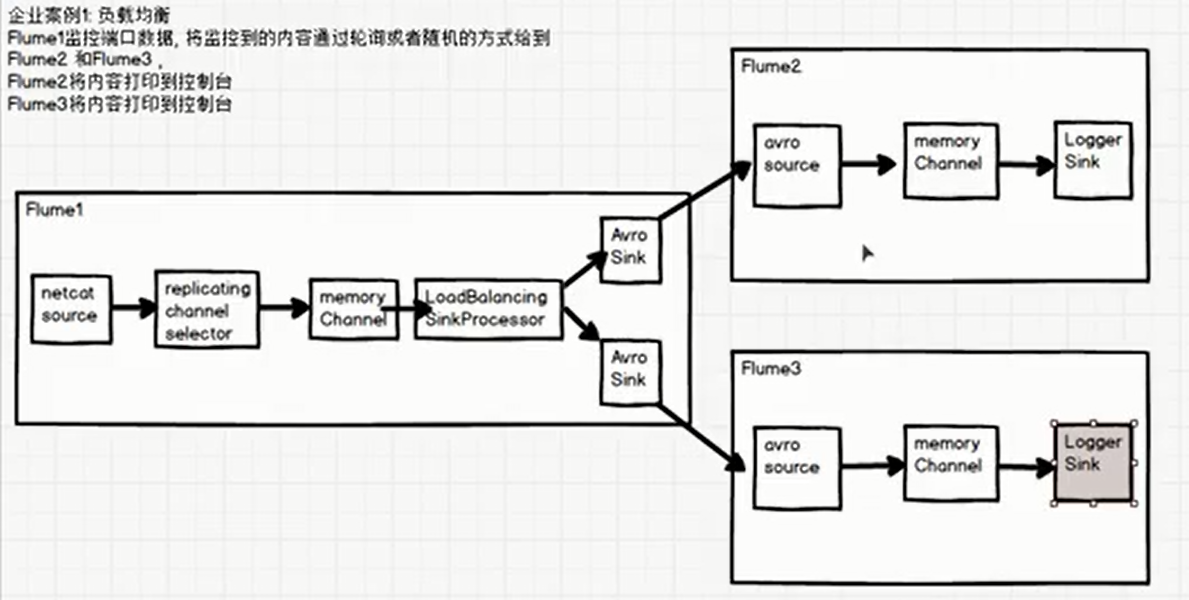
Requirements: Use Flume1 to monitor a port, sink in sink group is connected to Flume2 and Flume3 respectively, Failover SinkProcessor is used for failover function
Load Balancing First
Use Flume1 Monitor a port and send monitored content to it in a polling or random manner flume2 and flume3 flume2 Output data to console flume3 Output data to console
Architecture diagram
flume3.conf
# Processing data, writing out to local file system # Name a3.sources = r1 a3.sinks = k1 a3.channels = c1 # source, need to dock with the last agent, use avro a3.sources.r1.type = avro a3.sources.r1.bind = localhost a3.sources.r1.port = 8888 # sink a3.sinks.k1.type = logger # channel a3.channels.c1.type = memory a3.channels.c1.capacity = 1000 a3.channels.c1.transactionCapacity = 100 # Bind a3.sources.r1.channels = c1 a3.sinks.k1.channel = c1
flume2.conf
# Processing data, writing out to hdfs # Name a2.sources = r1 a2.sinks = k1 a2.channels = c1 # source, need to dock with the last agent, use avro a2.sources.r1.type = avro a2.sources.r1.bind = localhost a2.sources.r1.port = 7777 # sink a2.sinks.k1.type = logger # channel a2.channels.c1.type = memory a2.channels.c1.capacity = 1000 a2.channels.c1.transactionCapacity = 100 # Bind a2.sources.r1.channels = c1 a2.sinks.k1.channel = c1
flume1.conf
# This is an upstream agent and needs to dock two downstream agents flume2, flume3 a1.sources = r1 a1.sinks = k1 k2 a1.channels = c1 # Specify source configuration a1.sources.r1.type = netcat a1.sources.r1.bind = localhost a1.sources.r1.port = 6666 # channel Selector configuration a1.sources.r1.selector.type = replicating # Specify sink configuration (two sinks) a1.sinks.k1.type = avro a1.sinks.k1.hostname = localhost a1.sinks.k1.port = 7777 a1.sinks.k2.type = avro a1.sinks.k2.hostname = localhost a1.sinks.k2.port = 8888 # sink processor a1.sinkgroups = g1 a1.sinkgroups.g1.sinks = k1 k2 a1.sinkgroups.g1.processor.type = load_balance # Specify selector as polling or random round_robin/random a1.sinkgroups.g1.processor.selector = round_robin # Specify channel configuration (two channels) a1.channels.c1.type = memory a1.channels.c1.capacity = 10000 a1.channels.c1.transactionCapacity = 100 # Specify the binding relationship between source,sink,channel a1.sources.r1.channels = c1 a1.sinks.k1.channel = c1 a1.sinks.k2.channel = c1
Create the above profiles separately
[atguigu@hadoop102 jobs]$ pwd /opt/module/flume-1.9.0/jobs [atguigu@hadoop102 jobs]$ mkdir loadbalancing [atguigu@hadoop102 jobs]$ cd loadbalancing/ [atguigu@hadoop102 loadbalancing]$ vim flume1.conf [atguigu@hadoop102 loadbalancing]$ vim flume2.conf [atguigu@hadoop102 loadbalancing]$ vim flume3.conf [atguigu@hadoop102 loadbalancing]$ ll Total usage 12 -rw-rw-r--. 1 atguigu atguigu 992 10 November 120:32 flume1.conf -rw-rw-r--. 1 atguigu atguigu 430 10 November 120:32 flume2.conf -rw-rw-r--. 1 atguigu atguigu 443 10 November 120:32 flume3.conf [atguigu@hadoop102 loadbalancing]$
Execute flume command
# flume3 flume-ng agent -c $FLUME_HOME/conf -f $FLUME_HOME/jobs/loadbalancing/flume3.conf -n a3 -Dflume.root.logger=INFO,console # flume2 flume-ng agent -c $FLUME_HOME/conf -f $FLUME_HOME/jobs/loadbalancing/flume2.conf -n a2 -Dflume.root.logger=INFO,console # flume1 flume-ng agent -c $FLUME_HOME/conf -f $FLUME_HOME/jobs/loadbalancing/flume1.conf -n a1 -Dflume.root.logger=INFO,console
Test Send Data
[atguigu@hadoop102 loadbalancing]$ nc localhost 6666 hello OK pihao OK flume OK
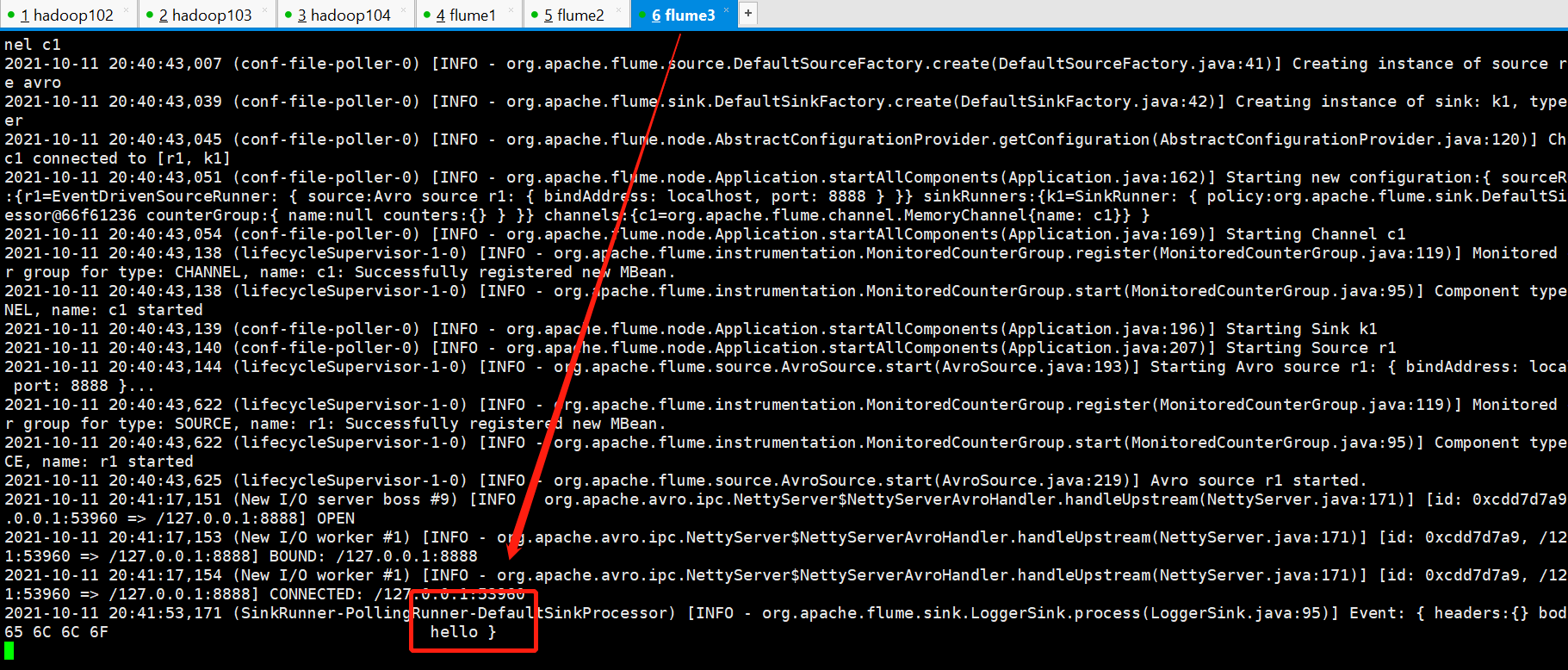
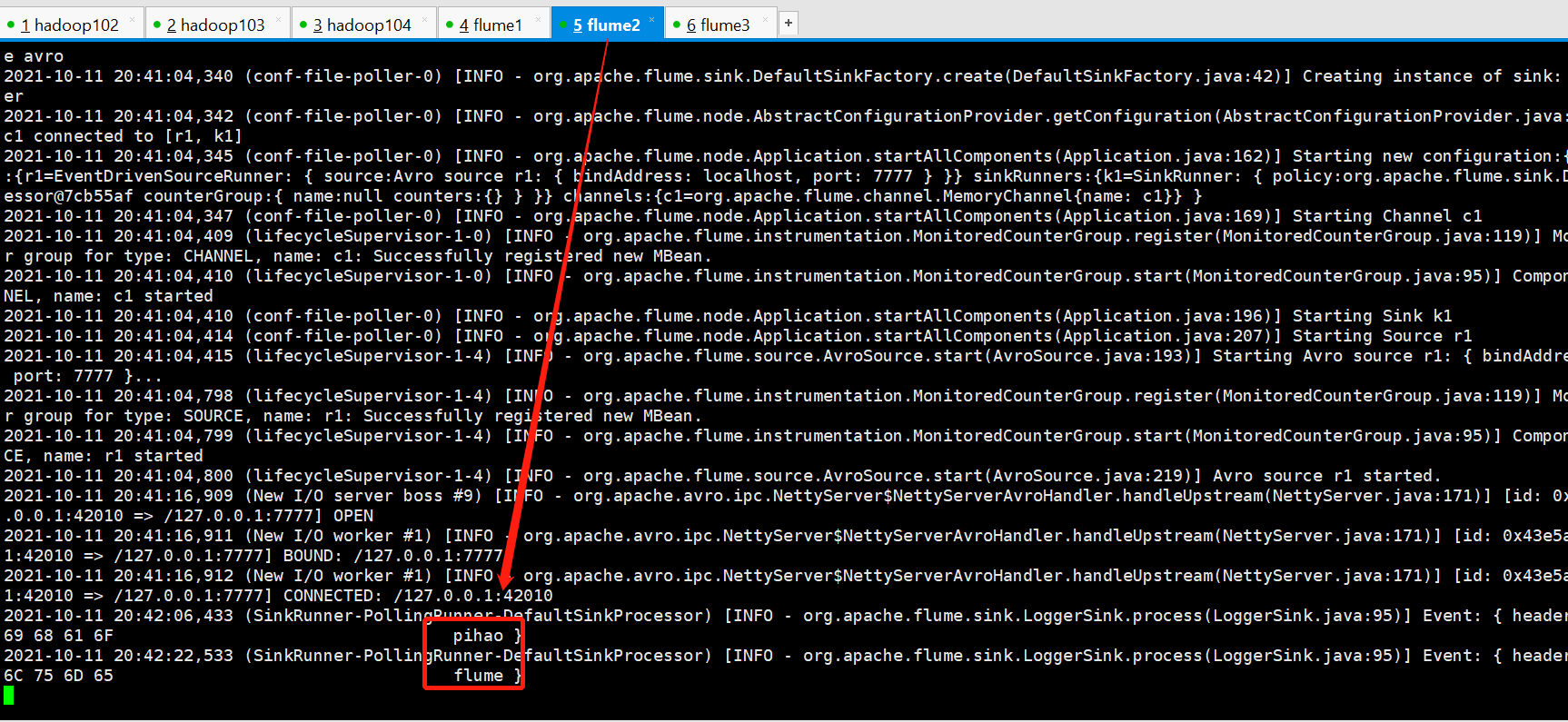
The test succeeded and found that only one sink was used to upload data at a time, and the polling was implemented. Note: The polling here does not refer to a single event's polling. Instead, it refers to that sink is polling to fetch data into channels. It is possible that this time flume2 gets data, then flume3 grabs it, and there is no data in channels. Next time, flume2 is getting data, there is data available, right
Test random
Simply change the sink processor in flume1.conf to:
a1.sinkgroups.g1.processor.selector = random
Test ok, load balancing polling and random mode testing is complete, then test failover
Failover Testing
flume1 monitors port data, sends monitored content to active's flume, and automatically transfers it to other flumes when the active's flume is down for high availability
Architecture diagram
This example is actually similar to the architecture of the load balancing example above. The only difference is the sink processor. The above example is the load_balancing sink processor, and this example is the failover sink processor
Configure flume1.conf
# This is an upstream agent and needs to dock two downstream agents flume2, flume3 a1.sources = r1 a1.sinks = k1 k2 a1.channels = c1 # Specify source configuration a1.sources.r1.type = netcat a1.sources.r1.bind = localhost a1.sources.r1.port = 6666 # channel Selector configuration a1.sources.r1.selector.type = replicating # Specify sink configuration (two sinks) a1.sinks.k1.type = avro a1.sinks.k1.hostname = localhost a1.sinks.k1.port = 7777 a1.sinks.k2.type = avro a1.sinks.k2.hostname = localhost a1.sinks.k2.port = 8888 # sink processor a1.sinkgroups = g1 a1.sinkgroups.g1.sinks = k1 k2 # Configure failover sink processor a1.sinkgroups.g1.processor.type = failover # Configure priority (see which sink becomes active) a1.sinkgroups.g1.processor.priority.k1 = 5 a1.sinkgroups.g1.processor.priority.k2 = 10 # Specify channel configuration (two channels) a1.channels.c1.type = memory a1.channels.c1.capacity = 10000 a1.channels.c1.transactionCapacity = 100 # Specify the binding relationship between source,sink,channel a1.sources.r1.channels = c1 a1.sinks.k1.channel = c1 a1.sinks.k2.channel = c1
Create flume profiles separately
[atguigu@hadoop102 jobs]$ pwd /opt/module/flume-1.9.0/jobs [atguigu@hadoop102 jobs]$ mkdir failover [atguigu@hadoop102 jobs]$ cd failover/ [atguigu@hadoop102 failover]$ vim flume1.conf [atguigu@hadoop102 failover]$ vim flume2.conf [atguigu@hadoop102 failover]$ vim flume3.conf [atguigu@hadoop102 failover]$ ll Total usage 12 -rw-rw-r--. 1 atguigu atguigu 1054 10 11 21 January:06 flume1.conf -rw-rw-r--. 1 atguigu atguigu 430 10 11 21 January:06 flume2.conf -rw-rw-r--. 1 atguigu atguigu 443 10 11 21 January:06 flume3.conf [atguigu@hadoop102 failover]$
Execute flume command
# flume3 flume-ng agent -c $FLUME_HOME/conf -f $FLUME_HOME/jobs/failover/flume3.conf -n a3 -Dflume.root.logger=INFO,console # flume2 flume-ng agent -c $FLUME_HOME/conf -f $FLUME_HOME/jobs/failover/flume2.conf -n a2 -Dflume.root.logger=INFO,console # flume1 flume-ng agent -c $FLUME_HOME/conf -f $FLUME_HOME/jobs/failover/flume1.conf -n a1 -Dflume.root.logger=INFO,console
Test Send Data
[atguigu@hadoop102 failover]$ nc localhost 6666 hello OK pihao OK nihoaya OK haha OK hhe OK
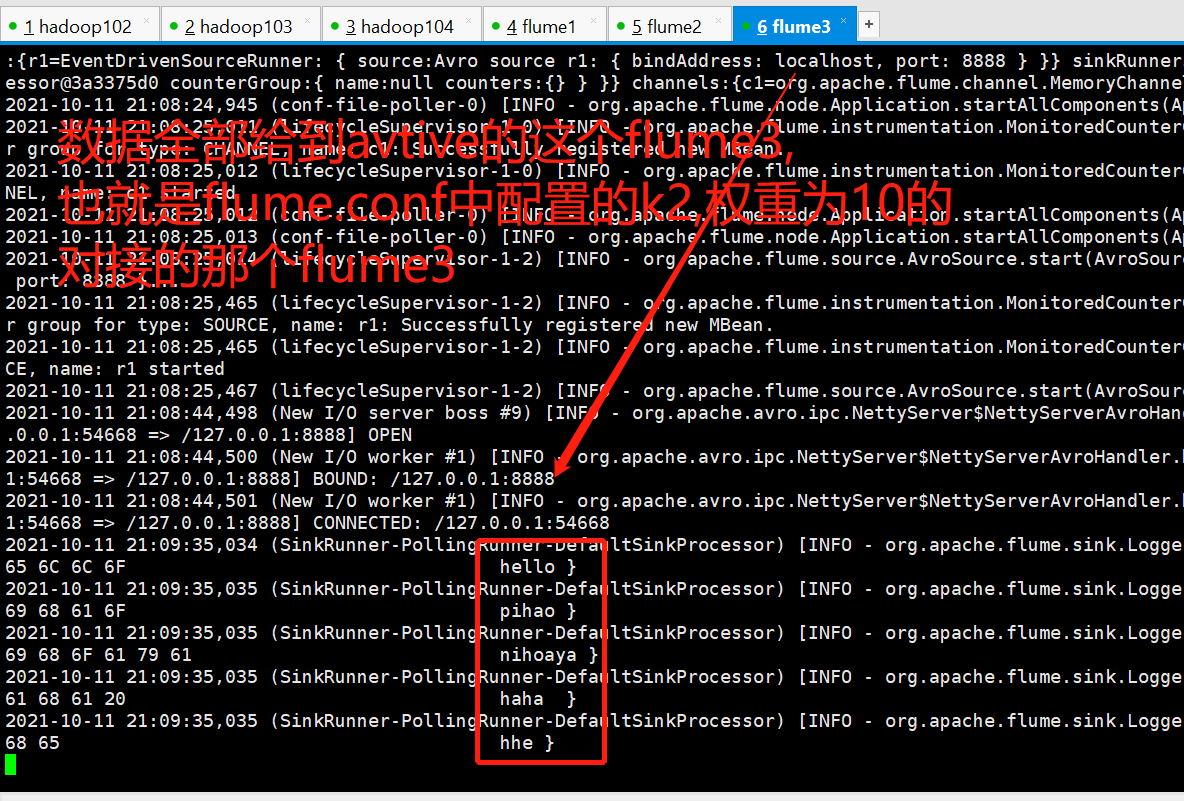
Now manually turn off flume3, then send the data again, and find that the data now goes to flume2 for failover.
Finally, I restarted flume3, sent the data again after successful connection, and found that the data is back to flume3
Aggregate Cases
Requirements:
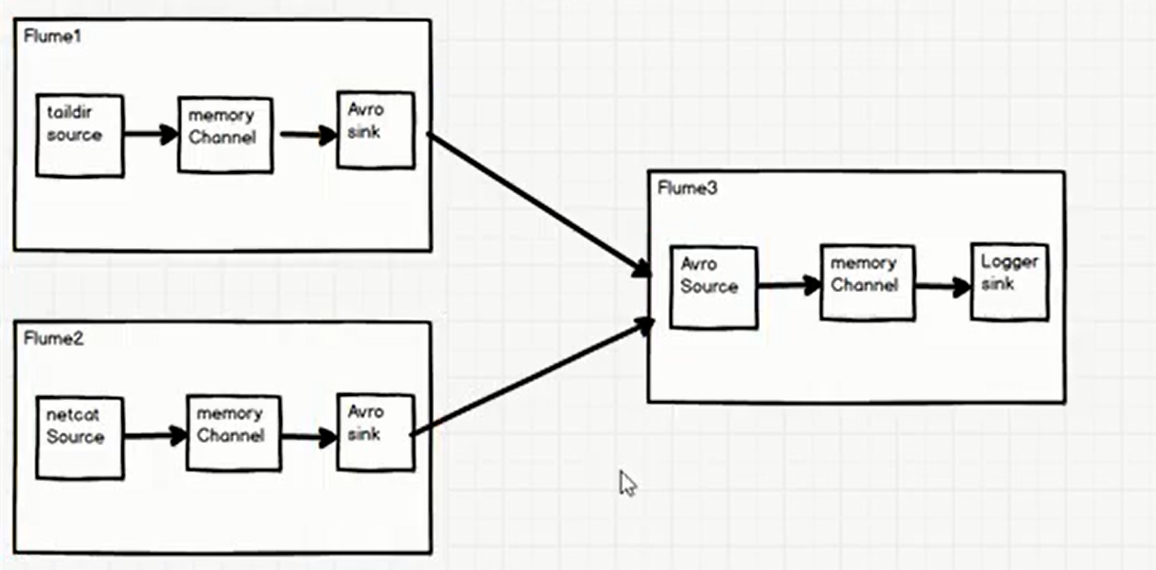
Flume1 monitoring file/opt/module/flume-1.9.0/jobs/taildir/.txt on hadoop102,
Flume2 on hadoop103 monitors the data flow on port 6666.
Flume-1 and Flume-2 send the data to Flume3 on hadoop104, and Flume3 prints the final data to the console.
Architecture diagram
Write flume1.conf configuration
#Named a1.sources = r1 a1.channels = c1 a1.sinks = k1 #Source a1.sources.r1.type = TAILDIR a1.sources.r1.filegroups = f1 a1.sources.r1.filegroups.f1 = /opt/module/flume-1.9.0/jobs/taildir/.*\.txt a1.sources.r1.positionFile = /opt/module/flume-1.9.0/jobs/position/position.json #Channel a1.channels.c1.type = memory a1.channels.c1.capacity = 10000 a1.channels.c1.transactionCapacity = 100 #Sink a1.sinks.k1.type = avro a1.sinks.k1.hostname = hadoop104 a1.sinks.k1.port = 8888 #Bind a1.sources.r1.channels = c1 a1.sinks.k1.channel = c1
Write flume2.conf configuration
a2.sources = r1 a2.channels = c1 a2.sinks = k1 #Source a2.sources.r1.type = netcat a2.sources.r1.bind = localhost a2.sources.r1.port = 6666 #Channel a2.channels.c1.type = memory a2.channels.c1.capacity = 10000 a2.channels.c1.transactionCapacity = 100 #Sink a2.sinks.k1.type = avro a2.sinks.k1.hostname = hadoop104 a2.sinks.k1.port = 8888 #Bind a2.sources.r1.channels = c1 a2.sinks.k1.channel = c1
Write flume3.conf configuration
#Named a3.sources = r1 a3.channels = c1 a3.sinks = k1 #Source a3.sources.r1.type = avro a3.sources.r1.bind = hadoop104 a3.sources.r1.port = 8888 #Channel a3.channels.c1.type = memory a3.channels.c1.capacity = 10000 a3.channels.c1.transactionCapacity = 100 #Sink a3.sinks.k1.type = logger #Bind a3.sources.r1.channels = c1 a3.sinks.k1.channel = c1
Create configuration files separately
[atguigu@hadoop102 jobs]$ pwd /opt/module/flume-1.9.0/jobs [atguigu@hadoop102 jobs]$ mkdir aggregate [atguigu@hadoop102 jobs]$ cd aggregate/ [atguigu@hadoop102 aggregate]$ vim flume1.conf [atguigu@hadoop102 aggregate]$ vim flume2.conf [atguigu@hadoop102 aggregate]$ vim flume3.conf [atguigu@hadoop102 aggregate]$ ll Total usage 12 -rw-rw-r--. 1 atguigu atguigu 538 10 11 21 January:35 flume1.conf -rw-rw-r--. 1 atguigu atguigu 404 10 11 21 January:35 flume2.conf -rw-rw-r--. 1 atguigu atguigu 354 10 11 21 January:35 flume3.conf [atguigu@hadoop102 aggregate]$
Note that the configuration file has now been created, but there is no flume on the hadoop103 and hadoop104 machines, and the configuration of environment variables for flume needs to be distributed as well.
#Execute in hadoop102 [atguigu@hadoop102 module]$ pwd /opt/module [atguigu@hadoop102 module]$ my_rsync.sh flume-1.9.0/ [atguigu@hadoop102 module]$ scp -r /etc/profile.d/my_env.sh root@hadoop103:/etc/profile.d/ [atguigu@hadoop102 module]$ scp -r /etc/profile.d/my_env.sh root@hadoop104:/etc/profile.d/ # Test whether environment variables are valid at 103,104, respectively
Execute flume command
# Start each machine in the following order # flume3 (104) Downstream Service Start First flume-ng agent -c $FLUME_HOME/conf -f $FLUME_HOME/jobs/aggregate/flume3.conf -n a3 -Dflume.root.logger=INFO,console # flume1 (102) flume-ng agent -c $FLUME_HOME/conf -f $FLUME_HOME/jobs/aggregate/flume1.conf -n a1 -Dflume.root.logger=INFO,console # flume2 (103) flume-ng agent -c $FLUME_HOME/conf -f $FLUME_HOME/jobs/aggregate/flume2.conf -n a2 -Dflume.root.logger=INFO,console
Three boots succeeded!
test
# Append to 102 test files [atguigu@hadoop102 taildir]$ pwd /opt/module/flume-1.9.0/jobs/taildir [atguigu@hadoop102 taildir]$ ll Total usage 16 -rw-rw-r--. 1 atguigu atguigu 18 10 January 1023:54 file1.txt -rw-rw-r--. 1 atguigu atguigu 19 10 January 1023:55 file2.txt -rw-rw-r--. 1 atguigu atguigu 11 10 January 1019:30 log1.log -rw-rw-r--. 1 atguigu atguigu 11 10 January 1019:30 log2.log [atguigu@hadoop102 taildir]$ echo hello >> file1.txt [atguigu@hadoop102 taildir]$ echo pihao >> file2.txt [atguigu@hadoop102 taildir]$ # Send content on test port 103 [atguigu@hadoop103 ~]$ nc localhost 6666 hello2 OK pihao2 OK # View output from 104 console
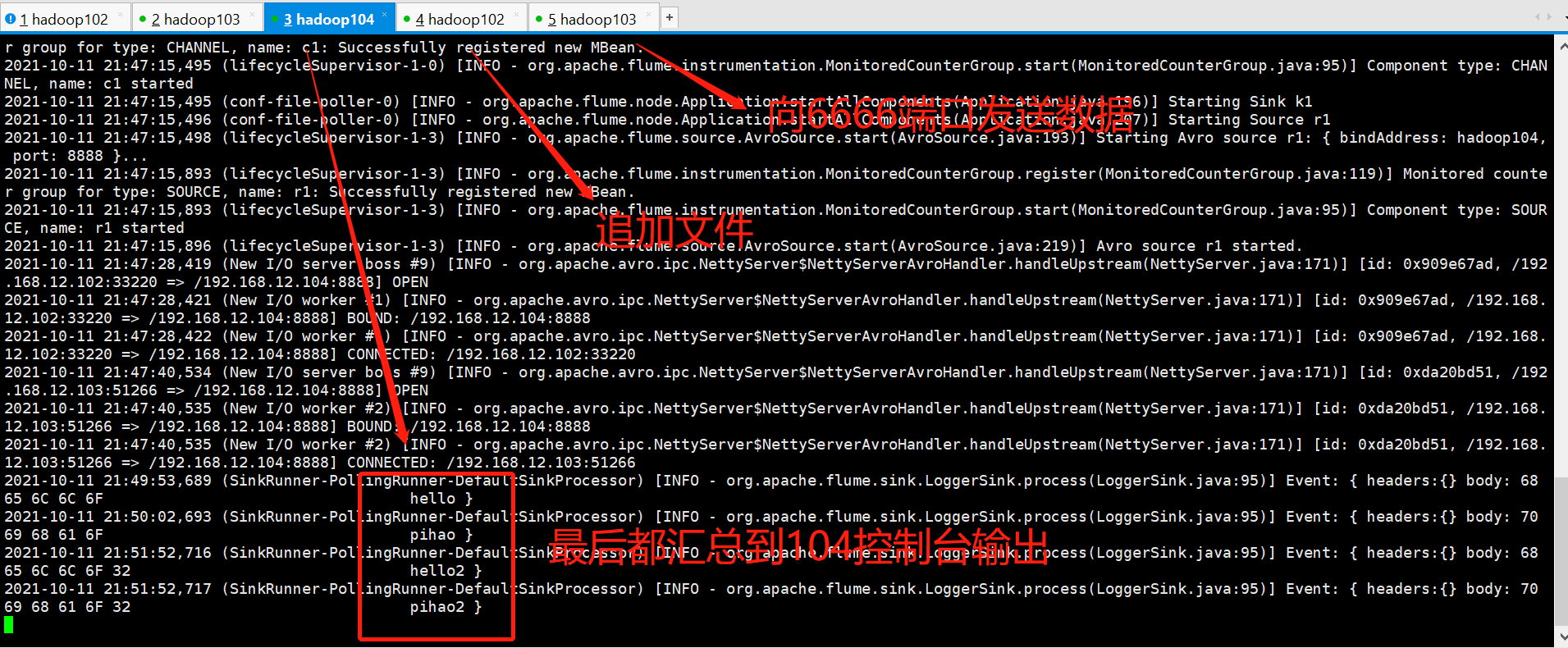
ok, aggregated case testing complete
Customize Interceptor
Requirements: Imagine a scenario where the data I collect contains a variety of information, including bigdata and java. Then I want to distribute the data containing bigdata and Java to different destinations. How can I do this?
Analysis
# You can use a multiplexer to send logs to the sink you want to specify. Take a look at the multiplexer configuration for your official network first: a1.sources = r1 a1.channels = c1 c2 c3 c4 a1.sources.r1.selector.type = multiplexing a1.sources.r1.selector.header = state a1.sources.r1.selector.mapping.CZ = c1 a1.sources.r1.selector.mapping.US = c2 c3 a1.sources.r1.selector.default = c4 # Roughly, this means getting the header from the event, then determining the value of the state field, and distributing it to the specified channel.Implementing a custom configuration channel Then think again about this event Enter this channel Before we do that, we need to event Set up header Head. Where to set it? That's in interceptor Interceptors can be set.
Write a java project
package com.pihao.flume.interceptor;
import com.nimbusds.jose.util.StandardCharset;
import org.apache.flume.Context;
import org.apache.flume.Event;
import org.apache.flume.interceptor.Interceptor;
import java.util.List;
import java.util.Map;
/**
* Custom flume interceptor
*/
public class EventHeaderInterceptor implements Interceptor {
@Override
public void initialize() {
}
@Override
public Event intercept(Event event) {
// Get header
Map<String, String> headers = event.getHeaders();
// Get body
String body = new String(event.getBody(), StandardCharset.UTF_8);
//Determine if a body contains bigdata,java
if(body.contains("bigdata")){
headers.put("whichChannel","bigdata");
}else if(body.contains("java")){
headers.put("whichChannel","java");
}else{
// headers.put("whichChannel","other");This is not writable and there is a default option in the multiplexer. This is the case
}
return event;
}
@Override
public List<Event> intercept(List<Event> events) {
for (Event event : events) {
intercept(event);
}
return events;
}
@Override
public void close() {
}
/**
* builder Internal class to instantiate the interceptor class above
*/
public static class MyBuilder implements Builder{
@Override
public Interceptor build() {
return new EventHeaderInterceptor();
}
@Override
public void configure(Context context) {
}
}
}
# Then pack it and send it to lib directory of cflume [atguigu@hadoop102 lib]$ ls|grep pihao pihao_event_interceptor.jar [atguigu@hadoop102 lib]$
Write a configuration file
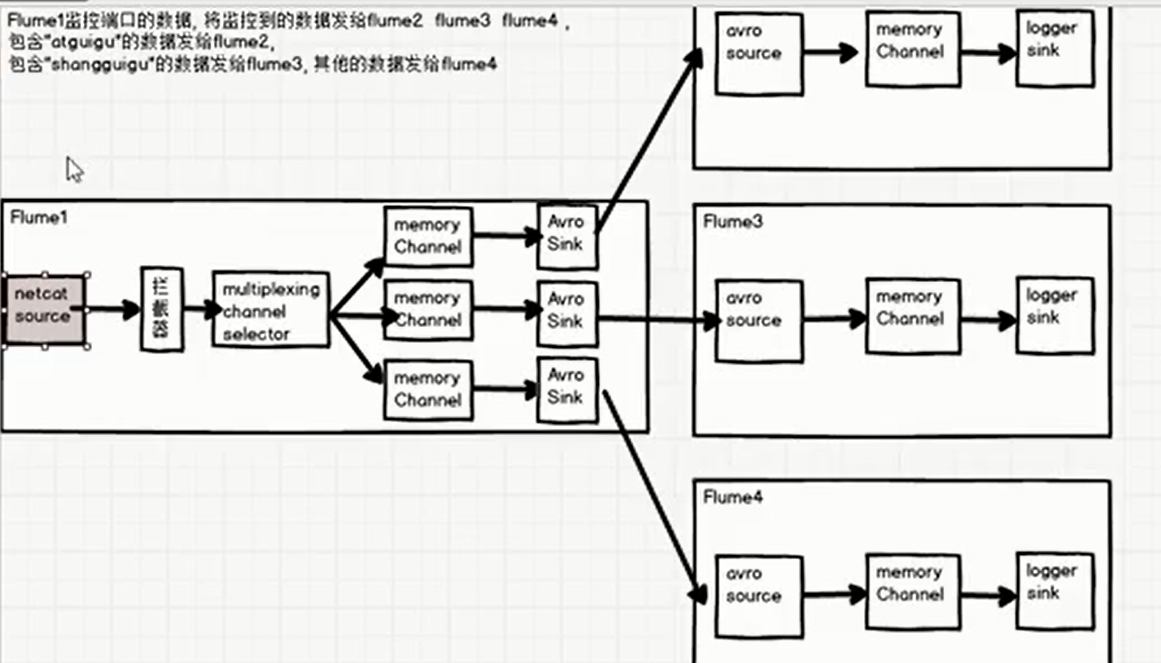
Multiplexer case flume1 Monitor port data, send monitored data to flume2,flume3,flume4.Contain bigdata,java,Other Issues flume4 flume2,flume3,flume4 Direct Output
Architecture diagram
Write a configuration file
#flume1.conf #Named a1.sources = r1 a1.channels = c1 c2 c3 a1.sinks = k1 k2 k3 #Source a1.sources.r1.type = netcat a1.sources.r1.bind = localhost a1.sources.r1.port = 5555 #channel selector a1.sources.r1.selector.type = multiplexing a1.sources.r1.selector.header = whichChannel a1.sources.r1.selector.mapping.bigdata = c1 a1.sources.r1.selector.mapping.java = c2 a1.sources.r1.selector.default = c3 # Interceptor a1.sources.r1.interceptors = i1 a1.sources.r1.interceptors.i1.type = com.pihao.flume.interceptor.EventHeaderInterceptor$MyBuilder #Channel a1.channels.c1.type = memory a1.channels.c1.capacity = 10000 a1.channels.c1.transactionCapacity = 100 a1.channels.c2.type = memory a1.channels.c2.capacity = 10000 a1.channels.c2.transactionCapacity = 100 a1.channels.c3.type = memory a1.channels.c3.capacity = 10000 a1.channels.c3.transactionCapacity = 100 #Sink a1.sinks.k1.type = avro a1.sinks.k1.hostname = localhost a1.sinks.k1.port = 6666 a1.sinks.k2.type = avro a1.sinks.k2.hostname = localhost a1.sinks.k2.port = 7777 a1.sinks.k3.type = avro a1.sinks.k3.hostname = localhost a1.sinks.k3.port = 8888 #Bind a1.sources.r1.channels = c1 c2 c3 a1.sinks.k1.channel = c1 a1.sinks.k2.channel = c2 a1.sinks.k3.channel = c3 #flume2.conf a2.sources = r1 a2.channels = c1 a2.sinks = k1 #Source a2.sources.r1.type = avro a2.sources.r1.bind = localhost a2.sources.r1.port = 6666 #Channel a2.channels.c1.type = memory a2.channels.c1.capacity = 10000 a2.channels.c1.transactionCapacity = 100 #Sink a2.sinks.k1.type = logger #Bind a2.sources.r1.channels = c1 a2.sinks.k1.channel = c1 #flume3.conf #Named a3.sources = r1 a3.channels = c1 a3.sinks = k1 #Source a3.sources.r1.type = avro a3.sources.r1.bind = localhost a3.sources.r1.port = 7777 #Channel a3.channels.c1.type = memory a3.channels.c1.capacity = 10000 a3.channels.c1.transactionCapacity = 100 #Sink a3.sinks.k1.type = logger #Bind a3.sources.r1.channels = c1 a3.sinks.k1.channel = c1 #flume4.conf #Named a4.sources = r1 a4.channels = c1 a4.sinks = k1 #Source a4.sources.r1.type = avro a4.sources.r1.bind = localhost a4.sources.r1.port = 8888 #Channel a4.channels.c1.type = memory a4.channels.c1.capacity = 10000 a4.channels.c1.transactionCapacity = 100 #Sink a4.sinks.k1.type = logger #Bind a4.sources.r1.channels = c1 a4.sinks.k1.channel = c1 start-up: flume-ng agent -c $FLUME_HOME/conf -f $FLUME_HOME/jobs/multi/flume4.conf -n a4 -Dflume.root.logger=INFO,console flume-ng agent -c $FLUME_HOME/conf -f $FLUME_HOME/jobs/multi/flume3.conf -n a3 -Dflume.root.logger=INFO,console flume-ng agent -c $FLUME_HOME/conf -f $FLUME_HOME/jobs/multi/flume2.conf -n a2 -Dflume.root.logger=INFO,console flume-ng agent -c $FLUME_HOME/conf -f $FLUME_HOME/jobs/multi/flume1.conf -n a1 -Dflume.root.logger=INFO,console
ok, boot successful, now start sending data to port 5555 to see if you can separate bigdata,java
[atguigu@hadoop102 multi]$ nc localhost 5555 bigdata # flume2 OK java # flume3 OK other # flume4 OK
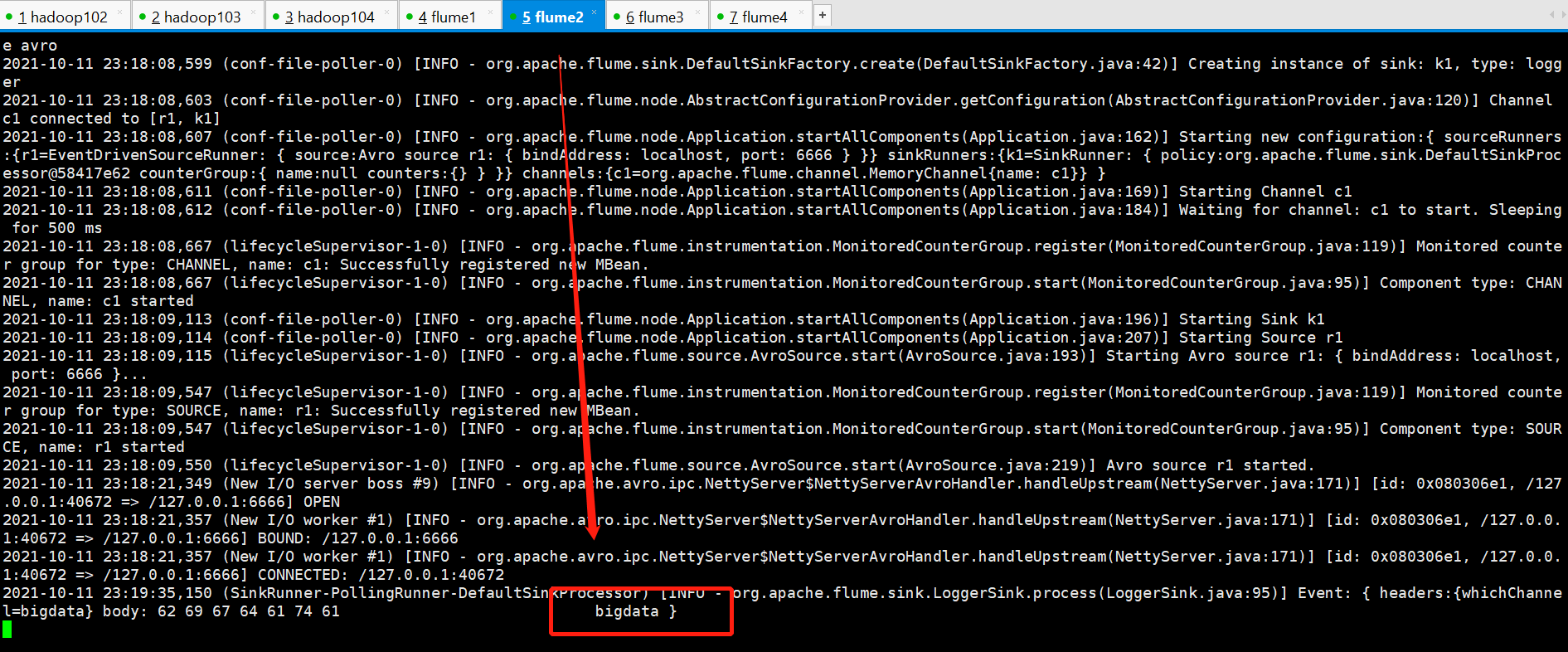
Multiple Case Test Successful
Customize Source, Customize Sink
Most Source s and Sink s are already defined on the official website, which is not important
Flume Data Flow Monitoring
Use Ganglia monitoring to learn about the installation yourself
Business Real Interview Questions
How do you do it Flume Data transfer monitoring? Use third-party framework Ganglia real time monitoring Flume. Flume Of Source,Sink,Channel Role? You Source What type? 1)Effect (1)Source Components are designed to collect data and can handle various types and formats of log data, including avro,thrift,exec,jms,spooling directory,netcat,sequence generator,syslog,http,legacy (2)Channel The component caches the collected data and can store it in Memory or File Medium. (3)Sink A component is a component used to send data to a destination that includes Hdfs,Logger,avro,thrift,ipc,file,Hbase,solr,Customize. 2)Our company uses Source The type is: (1)Monitor background logs: exec (2)Monitor the port of background log generation: netcat
Channel Selectors for Flume?
Flume Parameter tuning? 1)Source increase Source (Used) Tair Dir Source Can be increased FileGroups Number) can be increased Source For example, when a directory produces too many files, it is necessary to split the file directory into several file directories and configure many files at the same time. Source To ensure Source Enough capacity to obtain newly generated data. batchSize Parameter determination Source One-time bulk shipment to Channel Of event Number of bars, increasing this parameter appropriately can improve Source Carry Event reach Channel The performance at time. 2)Channel type Choice memory time Channel Best performance, but if Flume Data may be lost if the process hangs unexpectedly. type Choice file time Channel Better fault tolerance, but better performance than memory channel Poor. Use file Channel time dataDirs Configuring multiple directories under different disks can improve performance. Capacity Parameter determination Channel Maximum capacity event Number of bars. transactionCapacity Parameters determine each time Source to channel Maximum Written Inside event Number of bars and each time Sink from channel Maximum Read Inside event Number of bars. transactionCapacity Need to be greater than Source and Sink Of batchSize Parameters. 3)Sink increase Sink Number can be increased Sink consumption event Ability. Sink Nor is it that the more, the better, the more Sink Will occupy system resources, causing unnecessary waste of system resources. batchSize Parameter determination Sink One batch from Channel Read event Number of bars, increasing this parameter appropriately can improve Sink from Channel Remove event Performance.
Flume Transaction mechanism? Flume Transaction mechanism (similar to database transaction mechanism): Flume Using two separate transactions responsible for Soucrce reach Channel,And from Channel reach Sink Event delivery. For example spooling directory source Create an event for each line of the file once all events in the transaction are passed to Channel And submitted successfully, then Soucrce This file is marked as complete. Similarly, transactions are handled in a similar manner from Channel reach Sink If for some reason the event cannot be logged, the transaction will be rolled back. And all events will remain untouched Channel Medium, waiting for re-delivery.