Introduction: use IK word splitter to segment words and generate word cloud.
This paper mainly introduces how to make word frequency statistics through IK word segmentation. Use the word splitter to count the word frequency of the article. The main purpose is to realize the word cloud function as shown in the figure below, and you can find the key words in the article. In the follow-up, it can also carry out part of speech tagging, entity recognition and emotional analysis of entities.

The specific modules of word frequency statistics service are as follows:
Data entry: text information
Data output: word frequency (TF-IDF, etc.) - part of speech, etc
Components used: word splitter, corpus, word cloud display component, etc
Function points: white list, blacklist, synonyms, etc
The existing Chinese word splitters include IK, HanLP, jieba and NLPIR. Different word splitters have their own characteristics. This paper uses IK to realize it, because ES generally uses the IK word splitter plug-in encapsulated by big guys such as medcl as the Chinese word splitter.
Because the IK word breaker plug-in of ES deeply combines es, it only uses the content of ES for text word segmentation, so the text adopts Shen Yanchao's version of IK.
1. IK word segmentation statistics code
The code of IK is relatively simple and there are few things. Split String into words and count the code as follows:
- Simple statistical word frequency:
/**
* Full text word frequency statistics
*
* @param content Text content
* @param useSmart Use smart
* @return Word frequency
* @throws IOException
*/
private static Map<String, Integer> countTermFrequency(String content, Boolean useSmart) throws IOException {
// Output result Map
Map<String, Integer> frequencies = new HashMap<>();
if (StringUtils.isBlank(content)) {
return frequencies;
}
DefaultConfig conf = new DefaultConfig();
conf.setUseSmart(useSmart);
// Initialize the text information and load the dictionary using IKSegmenter
IKSegmenter ikSegmenter = new IKSegmenter(new StringReader(content), conf);
Lexeme lexeme;
while ((lexeme = ikSegmenter.next()) != null) {
if (lexeme.getLexemeText().length() > 1) {// Filter single words and other contents, such as numbers and simple symbols
final String term = lexeme.getLexemeText();
// Map accumulation operation
frequencies.compute(term, (k, v) -> {
if (v == null) {
v = 1;
} else {
v += 1;
}
return v;
});
}
}
return frequencies;
}- Statistics of word frequency and document frequency:
/**
* Statistics of word frequency of text list and word document frequency
*
* @param docs Document list
* @param useSmart Whether to use only participle
* @return Word frequency list word - [word frequency, document frequency]
* @throws IOException
*/
private static Map<String, Integer[]> countTFDF(List<String> docs, boolean useSmart) throws IOException {
// Output result Map
Map<String, Integer[]> frequencies = new HashMap<>();
for (String doc : docs) {
if (StringUtils.isBlank(doc)) {
continue;
}
DefaultConfig conf = new DefaultConfig();
conf.setUseSmart(useSmart);
// Initialize the text information and load the dictionary using IKSegmenter
IKSegmenter ikSegmenter = new IKSegmenter(new StringReader(doc), conf);
Lexeme lexeme;
// Set for document frequency statistics
Set<String> terms = new HashSet<>();
while ((lexeme = ikSegmenter.next()) != null) {
if (lexeme.getLexemeText().length() > 1) {
final String text = lexeme.getLexemeText();
// Conduct word frequency statistics
frequencies.compute(text, (k, v) -> {
if (v == null) {
v = new Integer[]{1, 0};
} else {
v[0] += 1;
}
return v;
});
terms.add(text);
}
}
// Document frequency statistics: there is no need to initialize the Map. After word frequency statistics, there must be a record of the word in the Map
for (String term : terms) {
frequencies.get(term)[1] += 1;
}
}
return frequencies;
}2. Get TopN words in the word cloud
There are many sorting methods to obtain TopN words for word cloud display, which can be sorted directly according to word frequency, document frequency, TF-IDF and other algorithms. In this paper, TopN is obtained only according to word frequency.
There are the following algorithms for obtaining TopN from M numbers:
- M small N small: fast selection algorithm
- M large N small: small top pile
- M big N big: merge sort
This paper adopts the small top heap method, which corresponds to the priority queue data structure in JAVA:
/**
* The TopN is sorted from high to low according to the number of occurrences
*
* @param data Map corresponding to words and sorted numbers
* @param TopN TopN of word cloud display
* @return First N words and sort values
*/
private static List<Map.Entry<String, Integer>> order(Map<String, Integer> data, int topN) {
PriorityQueue<Map.Entry<String, Integer>> priorityQueue = new PriorityQueue<>(data.size(), new Comparator<Map.Entry<String, Integer>>() {
@Override
public int compare(Map.Entry<String, Integer> o1, Map.Entry<String, Integer> o2) {
return o2.getValue().compareTo(o1.getValue());
}
});
for (Map.Entry<String, Integer> entry : data.entrySet()) {
priorityQueue.add(entry);
}
//The processing method of TODO when the current 100 word frequency is the same (the probability is very low), if (list (0) value == list(99). value ){xxx}
List<Map.Entry<String, Integer>> list = new ArrayList<>();
//The statistics result queue size and topN values are listed as the smaller values
int size = priorityQueue.size() <= topN ? priorityQueue.size() : topN;
for (int i = 0; i < size; i++) {
list.add(priorityQueue.remove());
}
return list;
}3. Analysis of IK code
The core main class is ikkeeper, which needs to pay attention to the dic package, that is, the relevant contents of the dictionary and the identifyCharType() method of the character processing tool class CharacterUtil. The directory structure is as follows:
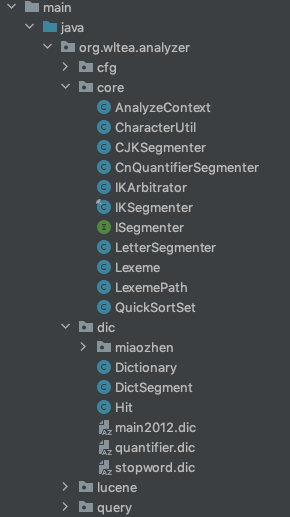
The structure of ikkeeper class is shown in the figure below, in which init() is a private method. The initialization loading dictionary adopts the non lazy loading mode. The dictionary will be called and loaded when the ikkeeper instance is initialized for the first time, and the code is located at the bottom of the structure diagram.
// Construction method of IKSegmenter class
public IKSegmenter(Reader input, Configuration cfg) {
this.input = input;
this.cfg = cfg;
this.init();
}
// IKSegmenter class initialization
private void init() {
//Initialize dictionary singleton
Dictionary.initial(this.cfg);
//Initialize word segmentation context
this.context = new AnalyzeContext(this.cfg);
//Load sub participle
this.segmenters = this.loadSegmenters();
//Load ambiguity arbiter
this.arbitrator = new IKArbitrator();
}
// Dictionary class initializes the dictionary
public static Dictionary initial(Configuration cfg) {
if (singleton == null) {
synchronized (Dictionary.class) {
if (singleton == null) {
singleton = new Dictionary(cfg);
return singleton;
}
}
}
return singleton;
}The dictionary private construction method Dictionary() will load IK's own dictionary and extended dictionary. We can also put our own online unchanged dictionary here, like ikanalyzer cfg. In XML, you only need to configure the dictionary that changes frequently.
private Dictionary(Configuration cfg) {
this.cfg = cfg;
this.loadMainDict();// Main dictionary and extended dictionary
this.loadmiaozhenDict();// Customize dictionary loading and follow other methods
this.loadStopWordDict();// Extended stop word dictionary
this.loadQuantifierDict();// Quantifier dictionary
}When the IKSegmenter class calls the next() method to get the next word element, it will call the identifyCharType() method in the CharacterUtil class to identify the character types. Here, we can also customize some character types to deal with emerging network languages, such as @, ## and so on:
static int identifyCharType(char input) {
if (input >= '0' && input <= '9') {
return CHAR_ARABIC;
} else if ((input >= 'a' && input <= 'z') || (input >= 'A' && input <= 'Z')) {
return CHAR_ENGLISH;
} else {
Character.UnicodeBlock ub = Character.UnicodeBlock.of(input);
//caster added # to Chinese characters
if (ub == Character.UnicodeBlock.CJK_UNIFIED_IDEOGRAPHS
|| ub == Character.UnicodeBlock.CJK_COMPATIBILITY_IDEOGRAPHS
|| ub == Character.UnicodeBlock.CJK_UNIFIED_IDEOGRAPHS_EXTENSION_A ||input=='#') {
//Currently known Chinese character UTF-8 set
return CHAR_CHINESE;
} else if (ub == Character.UnicodeBlock.HALFWIDTH_AND_FULLWIDTH_FORMS //Full angle numeric characters and Japanese and Korean characters
//Korean character set
|| ub == Character.UnicodeBlock.HANGUL_SYLLABLES
|| ub == Character.UnicodeBlock.HANGUL_JAMO
|| ub == Character.UnicodeBlock.HANGUL_COMPATIBILITY_JAMO
//Japanese character set
|| ub == Character.UnicodeBlock.HIRAGANA //Hiragana
|| ub == Character.UnicodeBlock.KATAKANA //Katakana
|| ub == Character.UnicodeBlock.KATAKANA_PHONETIC_EXTENSIONS) {
return CHAR_OTHER_CJK;
}
}
//Other unprocessed characters
return CHAR_USELESS;
}Since there is not much IK content, it is suggested that you can go through it from the beginning, including all self separators that implement the ISegmenter interface.
4. Word cloud display
Word cloud display can use Kibana's own word cloud Dashboard or the popular WordCloud. You can use online for your own test Micro word cloud Quickly and conveniently view the word cloud effect: import two columns of XLS files, and the left control bar can also configure and beautify the shape and font.
The display effect is shown in the figure below:
5. Summary
This paper mainly realizes the function of word frequency statistics through IK word splitter, which is used for the display of word cloud. It is not only applicable to ES, but also can be used for word frequency statistics in any data source document. However, the function is relatively basic. Interested students can realize the functions of word sorting mode change (tf/idf), part of speech tagging, entity recognition and emotion analysis; IK word segmentation is relatively limited and needs to be assisted by more advanced word segmentation such as hanlp (with part of speech tagging) and NLP related knowledge. You can also refer to Baidu AI's lexical analysis module.
This article is the original content of Alibaba cloud and cannot be reproduced without permission.