Background: Online migration of the current ES cluster to a new machine
Current:
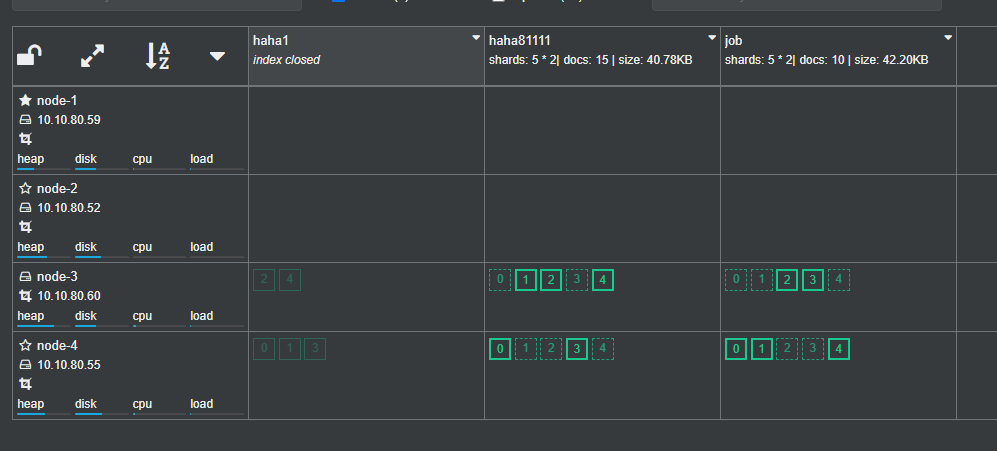
ES designs a load balancing mechanism for cluster fragmentation. When new nodes join or leave the cluster, the cluster will automatically balance the load distribution of fragmentation
Migration target: smooth migration
Migration strategy:
Turning off cluster auto balancing may bring network and IO pressure
Start the new node and the old node cluster to form a cluster
Manually migrate cluster data to new nodes
Switch to new peripheral access node
Close old node
Enable cluster auto balancing
Migration process:
1. Configure a new cluster
2. Turn off automatic cluster balancing
GET _cluster/settings

Can be updated dynamically:
#Disable cluster newly created index allocation. Disabling this option will prevent the allocation of the latest index
cluster.routing.allocation.enable:none
#Disable cluster auto balancing
cluster.routing.rebalance.enable:none
#Limit the distribution of indexes
"index.routing.allocation.include._ip": "multiple new cluster IPS"
KIBANA:
Turn off automatic slicing
PUT _cluster/settings
{
"transient": {
"cluster.routing.rebalance.enable":"none"
}
}
PUT _cluster/settings
{
"transient": {
"cluster.routing.allocation.enable":"none"
}
}
cluster. routing. allocation. When enable is set to none, it mainly affects that the newly created index in the cluster cannot be partitioned (allocate the partition to a node).
cluster. routing. rebalance. When enable is set to none, it mainly affects the fragmentation of existing indexes in the cluster and will not rebalance to other nodes
It can be excluded by ip or node name. When you operate exclude on an indexed node, the node will automatically migrate to other nodes in the cluster
When both exclude and include exist, exclude takes precedence
PUT _cluster/settings
{
"transient": {
"cluster.routing.allocation.exclude._ip": "10.10.80.59"
}
}
PUT _cluster/settings
{
"transient": {
"cluster.routing.allocation.include._ip": "10.10.80.55,10.10.80.60,10.10.80.52"
}
}
PUT _cluster/settings
{
"transient": {
"cluster.routing.allocation.exclude._name": "node-1,node-2"
}
}
PUT _cluster/settings
{
"transient": {
"cluster.routing.allocation.include._name": "node-4,node-3"
}
}
3. Start data node
The fragmentation will not be automatically balanced at this time because of cluster routing. allocation. If enable is set to none, the newly created index will not be allocated
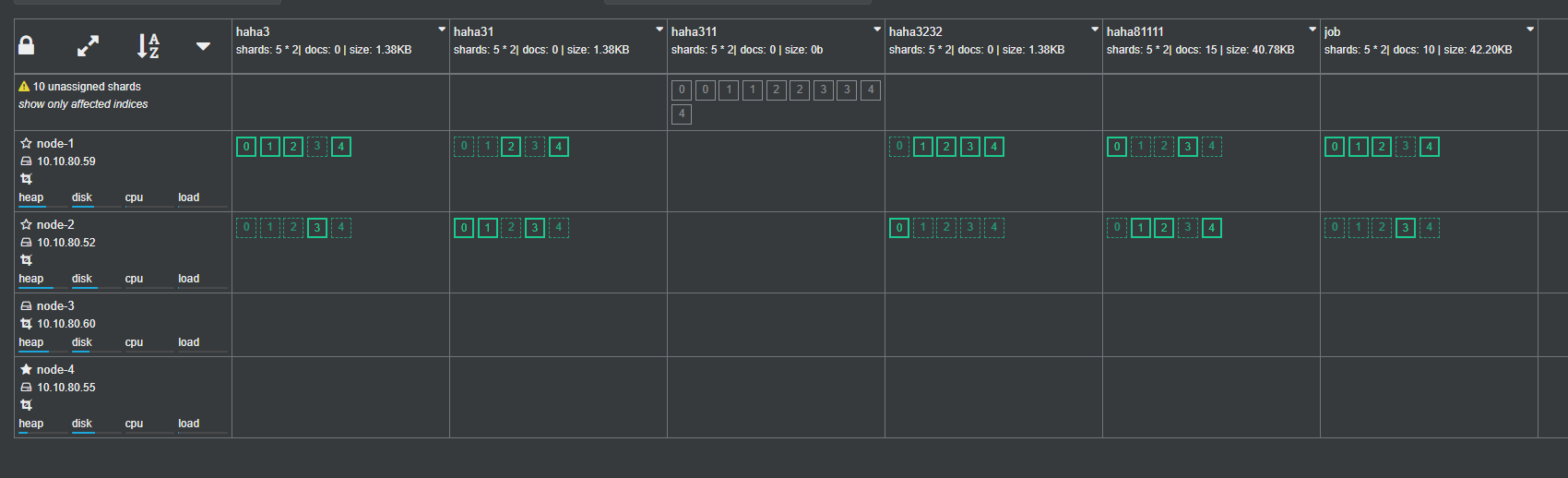
4. Switch external access and access ES through the IP of the new node
5. Modify the number of replicas and migrate data manually
Modify the number of index copies to 0 to speed up the migration
kibana: job is the index name,
PUT job/_settings
{
"number_of_replicas": 0
}
(if there are many indexes, you can also modify the number of copies through script)
curl -H "Content-Type: application/json" -XPUT 'http://10.10.80.55:9200/haha3/_settings' -d '{"index": {"number_of_replicas": "0"}}'
Manual migration:
1. Get all index names: refer to script 1 1es_prepare.sh
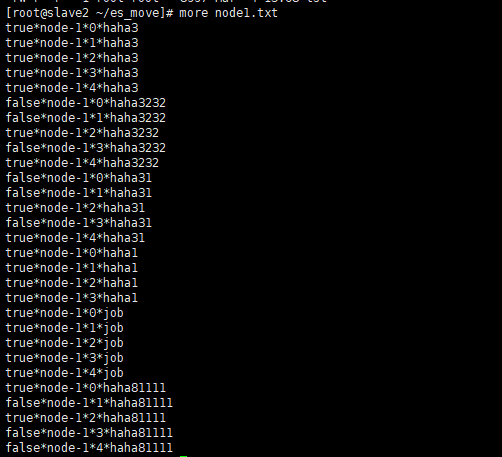
2. Generate migration statement: refer to script 2 to migrate each nodex by slice Txt needs to be generated
sh 2make.sh node1.txt
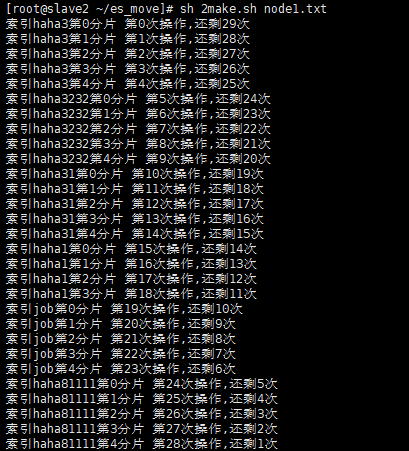
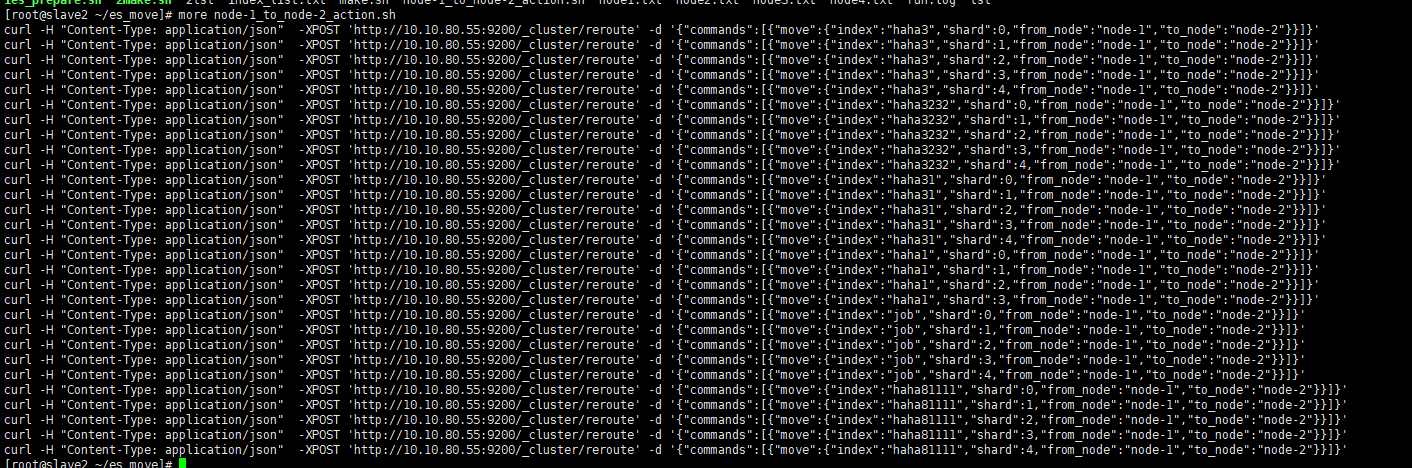
Execute the generated command to migrate one shard by one shard (in this example, node1 – > node3)
sh node-1_to_node-2_action.sh >run.log
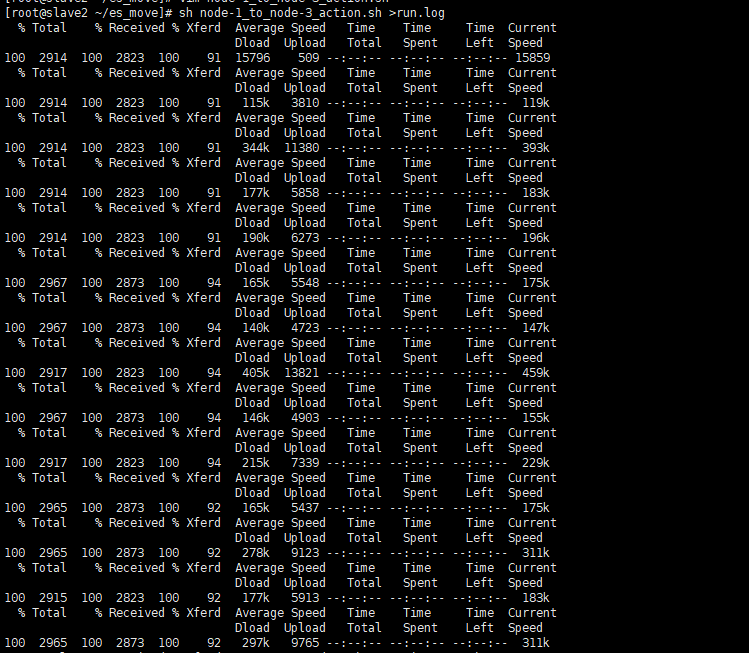
Before and after migration: comparison
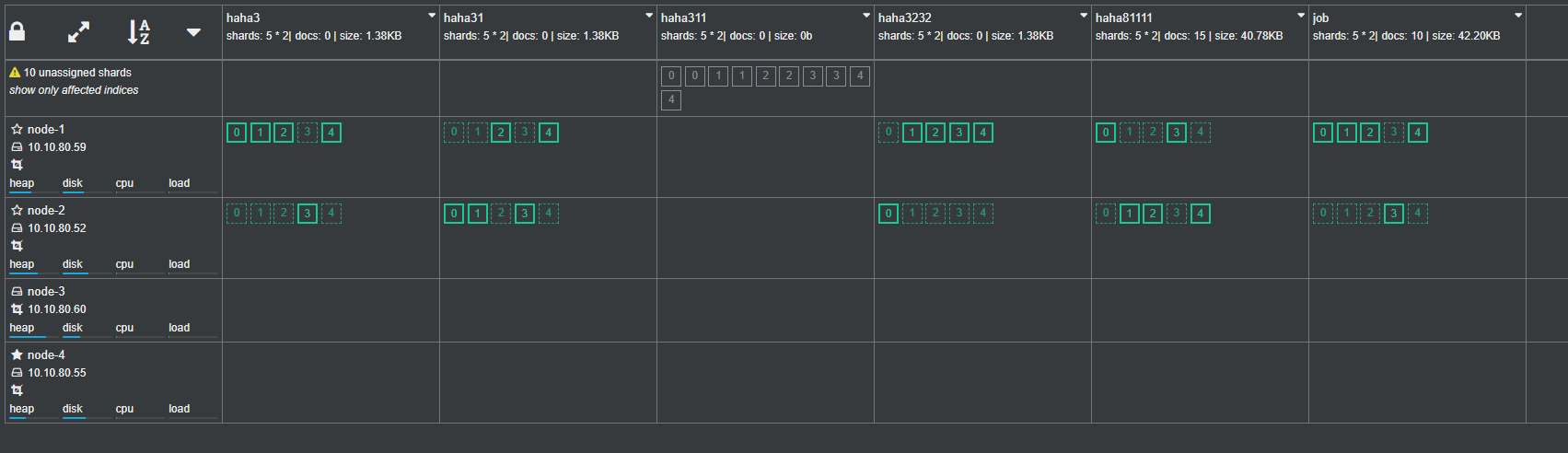
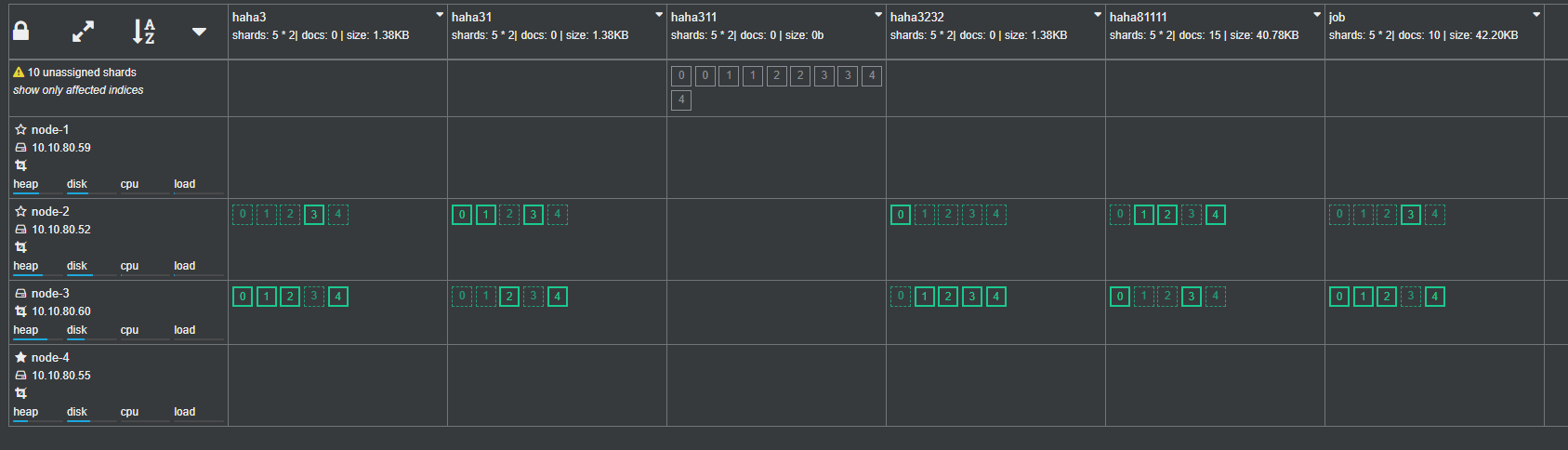
The process of migrating other node nodes in turn is the same as above
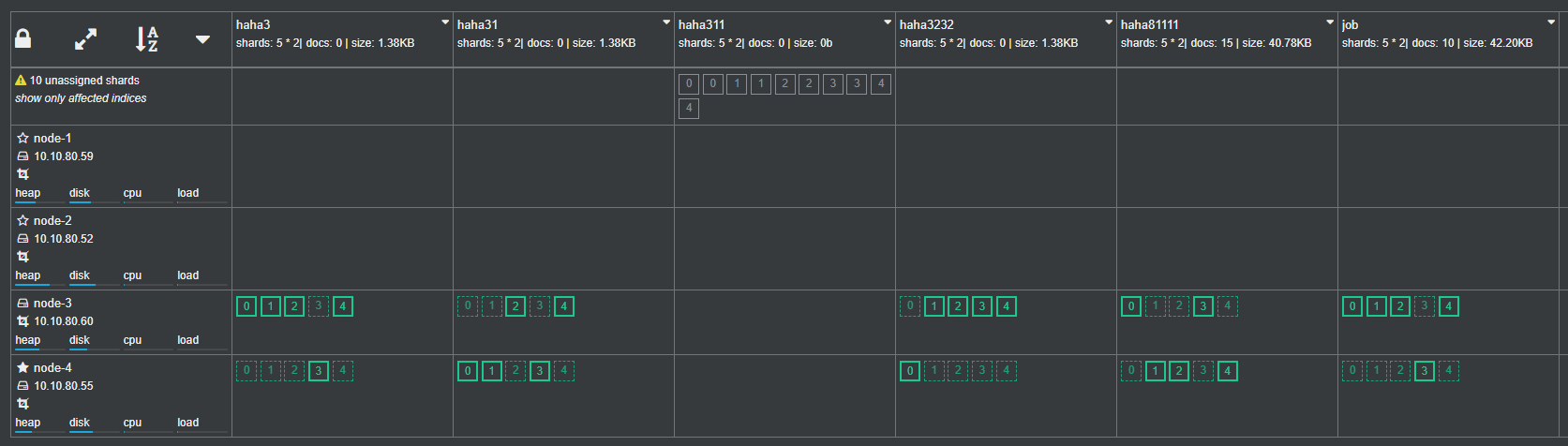
After all the nodes are migrated, exclude the old machine nodes and ensure that the old nodes have no index
6. Close the old data node
7. Gradually offline the old management node and start the new management node at the same time
First offline the old standby master node, add an equal number of new standby master nodes, and finally offline the master node in use
8. Restart cluster balancing
#Disable cluster newly created index allocation
cluster.routing.allocation.enable:true
#Disable cluster auto balancing
cluster.routing.rebalance.enable:true
When the number of replicas is added back, the migration ends
Script reference:
vim 1es_prepare.sh
#!/bin/bash
base_dir=/root/es_move
cd $base_dir
curl "10.10.80.55:9200/_cat/indices?pretty" | awk '{print $3}' | grep -v '^\.' > index_list.txt
#curl "10.10.80.55:9200/_cat/indices?pretty" | awk '{if($2 == "open") print $3}' | grep -v '^\.' #Exclude the system index, as long as the index in the open state
db_data1=`cat $base_dir/index_list.txt`
index=($db_data1)
num=${#index[@]}
i=0
1>tst
while (($num>0))
do
echo ${index[$i]}
curl -X GET "10.10.80.55:9200/${index[$i]}/_search_shards" |jq '.shards' |sed 's/\[//g' |sed 's/\]//g' >>tst
let i++
let num--
done
grep -v '^\s*$' tst >2tst #Remove blank lines
cat 2tst | paste -s > tst #Unify all rows into one row
#Replace the tab symbol with a space
#Remove the blanks
#Line feed processing
sed -i 's/\t/ /g;s/[ ]*//g;s/},{/\n},{/g;s/}{/\n/g;s/},{//g;s/}{//g' tst
#Manual modification is required here
cat tst |awk -F ',' '{print $2,":",$3,":",$5,":",$6}' |sed 's/ //g'|awk -F ':' '{print $2,"*",$4,"*",$6,"*",$8}' | sed 's/ //g;s/"//g' |sed 's/AvBEKEz5Q4iXafArWM7KXw/node-4/g;s/Spz57OmjRrCkub4l2Kg8og/node-3/g;s/5xP5tIzlRQW0uRFx61UTAg/node-2/g;s/5EouXEYlRxaCeKRaJqfwiA/node-1/g' | grep "node-1" >node1.txt
cat tst |awk -F ',' '{print $2,":",$3,":",$5,":",$6}' |sed 's/ //g'|awk -F ':' '{print $2,"*",$4,"*",$6,"*",$8}' | sed 's/ //g;s/"//g' |sed 's/AvBEKEz5Q4iXafArWM7KXw/node-4/g;s/Spz57OmjRrCkub4l2Kg8og/node-3/g;s/5xP5tIzlRQW0uRFx61UTAg/node-2/g;s/5EouXEYlRxaCeKRaJqfwiA/node-1/g' | grep "node-2" >node2.txt
cat tst |awk -F ',' '{print $2,":",$3,":",$5,":",$6}' |sed 's/ //g'|awk -F ':' '{print $2,"*",$4,"*",$6,"*",$8}' | sed 's/ //g;s/"//g' |sed 's/AvBEKEz5Q4iXafArWM7KXw/node-4/g;s/Spz57OmjRrCkub4l2Kg8og/node-3/g;s/5xP5tIzlRQW0uRFx61UTAg/node-2/g;s/5EouXEYlRxaCeKRaJqfwiA/node-1/g' | grep "node-3" >node3.txt
cat tst |awk -F ',' '{print $2,":",$3,":",$5,":",$6}' |sed 's/ //g'|awk -F ':' '{print $2,"*",$4,"*",$6,"*",$8}' | sed 's/ //g;s/"//g' |sed 's/AvBEKEz5Q4iXafArWM7KXw/node-4/g;s/Spz57OmjRrCkub4l2Kg8og/node-3/g;s/5xP5tIzlRQW0uRFx61UTAg/node-2/g;s/5EouXEYlRxaCeKRaJqfwiA/node-1/g' | grep "node-4" >node4.txt
vim 2make.sh
#!/bin/bash
basedir='/root/es_move'
cd $basedir
db_data1=`cat $basedir/$1 | awk -F '*' '{print $1}'`
db_data2=`cat $basedir/$1 | awk -F '*' '{print $2}'`
db_data3=`cat $basedir/$1 | awk -F '*' '{print $3}'`
db_data4=`cat $basedir/$1 | awk -F '*' '{print $4}'`
#host=($db_data1)
node=($db_data2)
shard=($db_data3)
index_name=($db_data4)
num=${#node[@]}
i=0
#Manually modify which node to migrate to, and migrate to node-3 this time
aim_node='node-3'
now_node=${node[$i]}
1>action.sh
while (($num>0))
do
echo 'Indexes'${index_name[$i]}'The first'${shard[$i]}'Slice section'$i'Secondary operation,Remaining'$num'second'
#Generate statement: $curl -XPOST 'http://localhost:9200/_cluster/reroute' -d '{"commands":[{"move":{"index":"filebeat-ali-hk-fd-tss1","shard":1,"from_node":"ali-hk-ops-elk1","to_node":"ali-hk-ops-elk2"}}]}'
# echo "curl -XPOST 'http://10.10.80.55:9200/_cluster/reroute' -d '"'{"commands":[{"move":{"index":"'${index_name[$i]}'","shard":'${shard[$i]}',"from_node":"'$now_node'","to_node":"'$aim_node'"}}]}'"'" >>action.sh
# -H "Content-Type: application/json"
echo "curl "'-H "Content-Type: application/json"' " -XPOST 'http://10.10.80.55:9200/_cluster/reroute' -d '"'{"commands":[{"move":{"index":"'${index_name[$i]}'","shard":'${shard[$i]}',"from_node":"'$now_node'","to_node":"'$aim_node'"}}]}'"'" >>action.sh
let i++
let num--
done
mv action.sh $now_node\_to_$aim_node\_action.sh
Index list generated from script_ list. Txt generate cancel copy script
vim replic.sh
#!/bin/bash
basedir='/root/es_move'
cd $basedir
db_data1=`cat $basedir/index_list.txt`
index_name=($db_data1)
num=${#index_name[@]}
i=0
1>rep.sh
while (($num>0))
do
echo 'Indexes'${index_name[$i]}'The first'${shard[$i]}'Slice section'$i'Secondary operation,Remaining'$num'second'
echo "curl "'-H "Content-Type: application/json"' " -XPUT 'http://10.10.80.55:9200/"${index_name[$i]}"/_settings' -d '"'{"index": {"number_of_replicas": "0"}}'"'" >>rep.sh
let i++
let num--
done
Import ES to mysql
Insert data:
PUT /haha657/_doc/5
{
"name":"xiao,""he",
"sex": "female",
"age":15
}
GET /haha657/_search?
{
"took" : 805,
"timed_out" : false,
"_shards" : {
"total" : 5,
"successful" : 5,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 4,
"relation" : "eq"
},
"max_score" : 1.0,
"hits" : [
{
"_index" : "haha657",
"_type" : "_doc",
"_id" : "3",
"_score" : 1.0,
"_source" : {
"name" : "xiao,hei",
"sex": "female",
"age" : 19
}
},
{
"_index" : "haha657",
"_type" : "_doc",
"_id" : "5",
"_score" : 1.0,
"_source" : {
"name" : """xiao,""he""",
"sex": "female",
"age" : 15
}
},
{
"_index" : "haha657",
"_type" : "_doc",
"_id" : "2",
"_score" : 1.0,
"_source" : {
"name" : "xiaohei",
"sex": "female",
"age" : 199
}
},
{
"_index" : "haha657",
"_type" : "_doc",
"_id" : "1",
"_score" : 1.0,
"_source" : {
"name" : "xiaohong",
"sex": "male",
"age" : 99
}
}
]
}
}
Configure logstash:
[root@slave1 /data/es/logstash-7.3.0/bin]# vim /tmp/convert_csv.conf
input{
elasticsearch {
hosts => ["10.10.80.33:9200"]
index => "haha657"
}
}
output{
csv {
fields => ["name","sex","age"]
path => "/tmp/csv.csv"
}
}
ES address: "10.10.80.33:9200"
Index name: "haha657"
Which columns to export: fields = > ["name", "sex", "age"]
Export location: path = > "/ tmp/csv.csv"
Perform export:
[root@slave1 /data/es/logstash-7.3.0/bin]# ./logstash -f /tmp/convert_csv.conf
Export results:
[root@slave1 /data/es/logstash-7.3.0/bin]# cat /tmp/csv.csv
xiaohong, male, 99
xiaohei, female, 199
"xiao", "he", female, 15
"xiao,hei", female, 19
mysql import uses csv format
MariaDB [test]> load data infile '/tmp/tmp/aa.csv' into table aa fields terminated by ',' optionally enclosed by '"' escaped by '"' ;
Query OK, 4 rows affected (0.00 sec)
Records: 4 Deleted: 0 Skipped: 0 Warnings: 0
MariaDB [test]> select * from aa;
±----------±-----±-----+
| name1 | sex | age |
±----------±-----±-----+
|xiaohong | male | 99|
|xiaohei | female 𞓜 199|
|Xiao, he | female | 15|
|xiao,hei | female | 19|
±----------±-----±-----+
4 rows in set (0.00 sec)