In the big data era, Hadoop ecology is the most mainstream ecology, but the ecology formed by elasticsearch and ELKB forms a unique large data platform based on the search idea.
The construction of elasticsearch learning platform, refer to " Quick Start Details for the latest version of ElasticSearch This paper is based on entOS7. 6, the IP address is 192.168.10.51.
1. Docker support, see " CentOS 7 Install docker Environment >
yum install -y yum-utils device-mapper-persistent-data lvm2 #Add docker's software source address yum-config-manager --add-repo http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo yum makecache fast #Update yum cache #You can view all docker versions in all repositories and choose a specific version to install yum list docker-ce --showduplicates | sort -r #The latest version is installed yum install docker-ce Or specify a version sudo yum install docker-ce-17.12.1.ce #Start docker service systemctl start docker #Add startup entry systemctl enable docker #View docker version docker version
2. Docker way to set up Elasticsearch environment
#Search for ES mirrors available in the docker mirror library: docker search elasticsearch #stars ranked first in the official ES mirror and second in the bull's fused ES7.7 and Kibana7. Mirror of 7, using the second. docker pull nshou/elasticsearch-kibana #Start the mirror as a container and leave the port mapping unchanged. The container is named eskibana. docker run -d -p 9200:9200 -p 9300:9300 -p 5601:5601 --name eskibana nshou/elasticsearch-kibana
3. Tools, Elasticsearch-head
ElasticSearch Head, a graphical interface for ES, is used to debug and manage ES. There are several modes of operation, most notably the Chrome browser extension, which can be installed from the chrome online store.
If you do not have good access to the chrome store in China, you can use the offline packages (Note: generally you need to change the offline packages to zip/rar suffix decompression, from the chrome extender, choose the way to expand the decompressed packages, find the decompressed directory to install)
4. Verify ES installation
(1) Verify ES: http://192.168.10.51:9200/ , see the classic sentence: You Know, for Search:
(2) Verify Kibana:http://This paper is based on entOS7. 6, the IP address is 192.168.10.51:5601/, and then you will see the kibana interface, which provides a lot of simulation data. The most basic way to use Dev Tools is to use the wrench shape in the lower left corner during learning
5. Basic operations
ES is a RESTful style system with four keywords: PUT (modification), POST (add), DELETE (delete), GET (query). The boundaries between PUT and POST in ES are not very clear, and sometimes PUT is added as well.
Basic command actions can be performed in dev tool of Elastic (curl, postman, etc.) and the results can be viewed in Elastic head er.
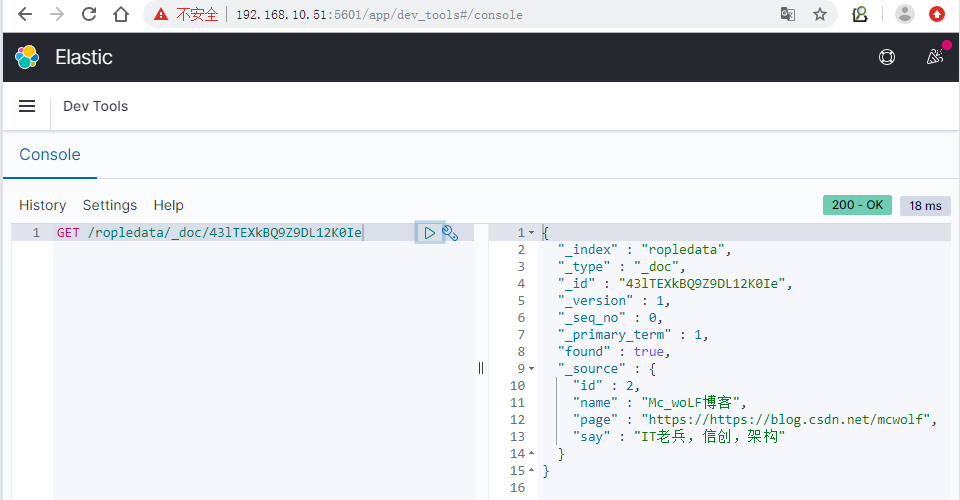 Enter commands in the Elasticsearch debugging console
Enter commands in the Elasticsearch debugging console
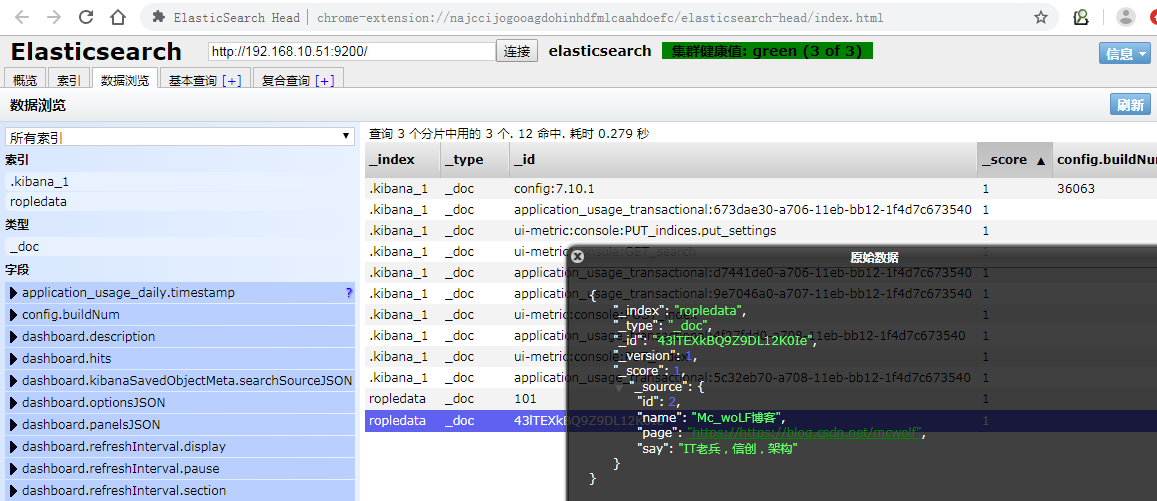 View index data in Elasticsearch-head er
View index data in Elasticsearch-head er
(1) Index base operation
Create an empty index, create a 0-copy 2-slice ropledata index, and refresh it in the Elasticsearch Head to see the information of the index:
PUT /ropledata
{
"settings": {
"number_of_shards": "2",
"number_of_replicas": "0"
}
}(2) Insert data, when inserting data, you can specify id, not ES will automatically generate for us. The code below is that we created a 101 document that you can see in the data browsing module of Elasticsearch Head once created successfully:
POST /ropledata/_doc/101
{
"id":1,
"name":"And listen_Wind Singing",
"page":"https://ropledata.blog.csdn.net",
"say":"Welcome to praise, collection, attention, study together"
}(3) To modify data, ES modifying data is essentially a document overwrite. ES's modifications to data are divided into global and local updates
#Global Update
PUT /ropledata/_doc/101
{
"id":1,
"name":"And listen_Wind Singing",
"page":"https://ropledata.blog.csdn.net",
"say":"Again, welcome to praise, collect, pay attention and learn together"
}
#Local update
POST /ropledata/_update/101
{
"doc":
{
"say":"Oliver"
}
}The _of this document after each global update Versions change. Update the code locally, and you'll find that except for the first execution, no matter how many executions follow, _ Versions never change!
- Global updates are essentially replacement operations, even if the content is the same;
- Local updates are essentially update operations. They are updated only when something new is encountered, and they are not updated without new changes.
- Local updates perform better than global updates, so local updates are recommended
(4) Query data: Data query knowledge points are very large and complex, the most basic basis is to search for data based on id:
GET /ropledata/_doc/101
6. ES Error [FORBIDDEN/12/index read-only / allow delete (api)] - Resolution of read only elastic search indices
The first time you insert data, the above prompt appears, and it was later discovered that Es is not allowed to use more than 95% of the disk space required.
In config/elasticsearch. In yml, the watermark is set to 99% during the flood stage, and you can set another percentage yourself, which is 95% by default.
cluster.routing.allocation.disk.watermark.flood_stage: 95%
es defaults to / usr/local, typically / partition, and df-h can be used for viewing space (it was later found that the Linux virtual machine under / var/lib took up some space), when space is freed up, execute
PUT ropledata/_settings
{
"index":{
"blocks":{
"read_only_allow_delete":"false"
}
}
}Official solution: curl-XPUT-H "Content-Type: application/json" http://127.0.0.1:9200/_all/_settings -d'{'index.blocks.read_only_allow_delete': null}'