
Data inconsistency will inevitably occur among multiple nodes in etcd cluster. However, whether synchronous replication, asynchronous replication or semi synchronous replication, there will be problems of availability or consistency. We usually use consensus algorithm to solve the problem of data consistency of multiple nodes. The common consensus algorithms are Paxos and Raft. ZooKeeper uses ZAB protocol and etcd uses Raft as the consensus algorithm.
Interface provided by etcd raft module
The main object in the raft module is the node.
You can use raft Startnode creates a new Node, or raft Restartnode creates a new Node from an initial state.
In raft / Node The Node interface is defined in go
// Node represents a node in a raft cluster.
type Node interface {
//Clock, trigger election or send heartbeat
Tick()
Campaign(ctx context.Context) error
//Submit an Op to raft StateMachine through channel, which is a message of local MsgProp type;
Propose(ctx context.Context, data []byte) error
ProposeConfChange(ctx context.Context, cc pb.ConfChangeI) error
//When the node receives the Msg sent by the Peer node, it will submit it to the raft state machine through this interface, and the Step interface will transfer the Msg to the raft state machine through recvc channel;
Step(ctx context.Context, msg pb.Message) error
//The interface will return a channel of type Ready, which represents the channel at the current time point. The application layer needs to pay attention to the channel. When changes occur, the data in it will also be operated accordingly
Ready() <-chan Ready
Advance()
ApplyConfChange(cc pb.ConfChangeI) *pb.ConfState
TransferLeadership(ctx context.Context, lead, transferee uint64)
ReadIndex(ctx context.Context, rctx []byte) error
Status() Status
ReportUnreachable(id uint64)
ReportSnapshot(id uint64, status SnapshotStatus)
Stop()
}The Node structure in the raft module implements the Node interface:
// node is the canonical implementation of the Node interface
type node struct {
propc chan msgWithResult
recvc chan pb.Message
confc chan pb.ConfChangeV2
confstatec chan pb.ConfState
readyc chan Ready
advancec chan struct{}
tickc chan struct{}
done chan struct{}
stop chan struct{}
status chan chan Status
rn *RawNode
}In raft / raft There are also two core data structures in go:
-
Config, which encapsulates the configuration parameters related to the raft algorithm and is exposed for external calls.
-
Raft, the concrete structure of the raft algorithm.
Node status
The state machine transformation of raft StateMachine is actually the transformation of various roles in raft algorithm. Each raft node may have one of the following three states:
-
Candidate: candidate status, which means that a new election will be held.
-
Follower: follower status, which means the election is over.
-
Leader: leader status, elected nodes, all data submission must be submitted to the leader first.
Each state has its corresponding state machine. Every time a submitted data is received, the message will be input into the state machine of different states according to its different states. At the same time, the processing function corresponding to each state is also different during the tick operation.
Therefore, in the raft structure, different states and their different processing functions are separated into several member variables:
-
State to save the current node state;
-
Tick function, the tick function corresponding to each state is different;
-
step, state machine function. Similarly, the state machine corresponding to each state is also different.
Etcd raft Statemachine is encapsulated in the raft mechanism, and its state transition is shown in the following figure:
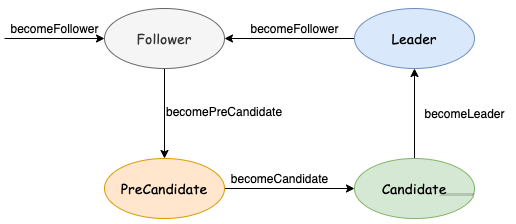
All interfaces for raft state transition are in raft In go, it is defined as follows:
func (r *raft) becomeFollower(term uint64, lead uint64) {
r.step = stepFollower
r.reset(term)
r.tick = r.tickElection
r.lead = lead
r.state = StateFollower
r.logger.Infof("%x became follower at term %d", r.id, r.Term)
}
func (r *raft) becomeCandidate() {
// TODO(xiangli) remove the panic when the raft implementation is stable
if r.state == StateLeader {
panic("invalid transition [leader -> candidate]")
}
r.step = stepCandidate
r.reset(r.Term + 1)
r.tick = r.tickElection
r.Vote = r.id
r.state = StateCandidate
r.logger.Infof("%x became candidate at term %d", r.id, r.Term)
}
func (r *raft) becomePreCandidate() {
// TODO(xiangli) remove the panic when the raft implementation is stable
if r.state == StateLeader {
panic("invalid transition [leader -> pre-candidate]")
}
// Becoming a pre-candidate changes our step functions and state,
// but doesn't change anything else. In particular it does not increase
// r.Term or change r.Vote.
r.step = stepCandidate
r.prs.ResetVotes()
r.tick = r.tickElection
r.lead = None
r.state = StatePreCandidate
r.logger.Infof("%x became pre-candidate at term %d", r.id, r.Term)
}
func (r *raft) becomeLeader() {
// TODO(xiangli) remove the panic when the raft implementation is stable
if r.state == StateFollower {
panic("invalid transition [follower -> leader]")
}
r.step = stepLeader
r.reset(r.Term)
r.tick = r.tickHeartbeat
r.lead = r.id
r.state = StateLeader
// Followers enter replicate mode when they've been successfully probed
// (perhaps after having received a snapshot as a result). The leader is
// trivially in this state. Note that r.reset() has initialized this
// progress with the last index already.
r.prs.Progress[r.id].BecomeReplicate()
// Conservatively set the pendingConfIndex to the last index in the
// log. There may or may not be a pending config change, but it's
// safe to delay any future proposals until we commit all our
// pending log entries, and scanning the entire tail of the log
// could be expensive.
r.pendingConfIndex = r.raftLog.lastIndex()
emptyEnt := pb.Entry{Data: nil}
if !r.appendEntry(emptyEnt) {
// This won't happen because we just called reset() above.
r.logger.Panic("empty entry was dropped")
}
// As a special case, don't count the initial empty entry towards the
// uncommitted log quota. This is because we want to preserve the
// behavior of allowing one entry larger than quota if the current
// usage is zero.
r.reduceUncommittedSize([]pb.Entry{emptyEnt})
r.logger.Infof("%x became leader at term %d", r.id, r.Term)
}How does the raft state machine run in different states? The answer is that etcd abstracts all the processing related to raft into Msg and processes it through the Step interface:
func (r *raft) Step(m pb.Message) error {``
r.step(r, m)
}step here is a callback function. According to different states, different callback functions will be set to drive raft. This callback function stepFunc is set in becomeXX() function:
type raft struct {
...
step stepFunc
}
The step callback function has the following values. Note that stepCandidate will handle two states: PreCandidate and Candidate:
func stepFollower(r *raft, m pb.Message) error func stepCandidate(r *raft, m pb.Message) error func stepLeader(r *raft, m pb.Message) error
raft message
Raft algorithm is essentially a large state machine. Any operation, such as election, data submission, etc., is finally encapsulated into a message structure and input into the state machine of raft algorithm library.
In raft / raft Pb / raft Proto file defines the structure of transmission Message in raft algorithm. The raft algorithm is actually composed of several protocols. Etcd raft defines it in the Message structure. The member uses of this structure are summarized below:
type Message struct {
Type MessageType `protobuf:"varint,1,opt,name=type,enum=raftpb.MessageType" json:"type"`
To uint64 `protobuf:"varint,2,opt,name=to" json:"to"`
From uint64 `protobuf:"varint,3,opt,name=from" json:"from"`
Term uint64 `protobuf:"varint,4,opt,name=term" json:"term"`
// logTerm is generally used for appending Raft logs to followers. For example,
// (type=MsgApp,index=100,logTerm=5) means leader appends entries starting at
// index=101, and the term of entry at index 100 is 5.
// (type=MsgAppResp,reject=true,index=100,logTerm=5) means follower rejects some
// entries from its leader as it already has an entry with term 5 at index 100.
LogTerm uint64 `protobuf:"varint,5,opt,name=logTerm" json:"logTerm"`
Index uint64 `protobuf:"varint,6,opt,name=index" json:"index"`
Entries []Entry `protobuf:"bytes,7,rep,name=entries" json:"entries"`
Commit uint64 `protobuf:"varint,8,opt,name=commit" json:"commit"`
Snapshot Snapshot `protobuf:"bytes,9,opt,name=snapshot" json:"snapshot"`
Reject bool `protobuf:"varint,10,opt,name=reject" json:"reject"`
RejectHint uint64 `protobuf:"varint,11,opt,name=rejectHint" json:"rejectHint"`
Context []byte `protobuf:"bytes,12,opt,name=context" json:"context,omitempty"`
}The data type related to the Message structure is MessageType. There are 19 types of messagetypes. Of course, not all Message types will use all the fields in the Message structure defined above, so some of them are optional.
Common message types:
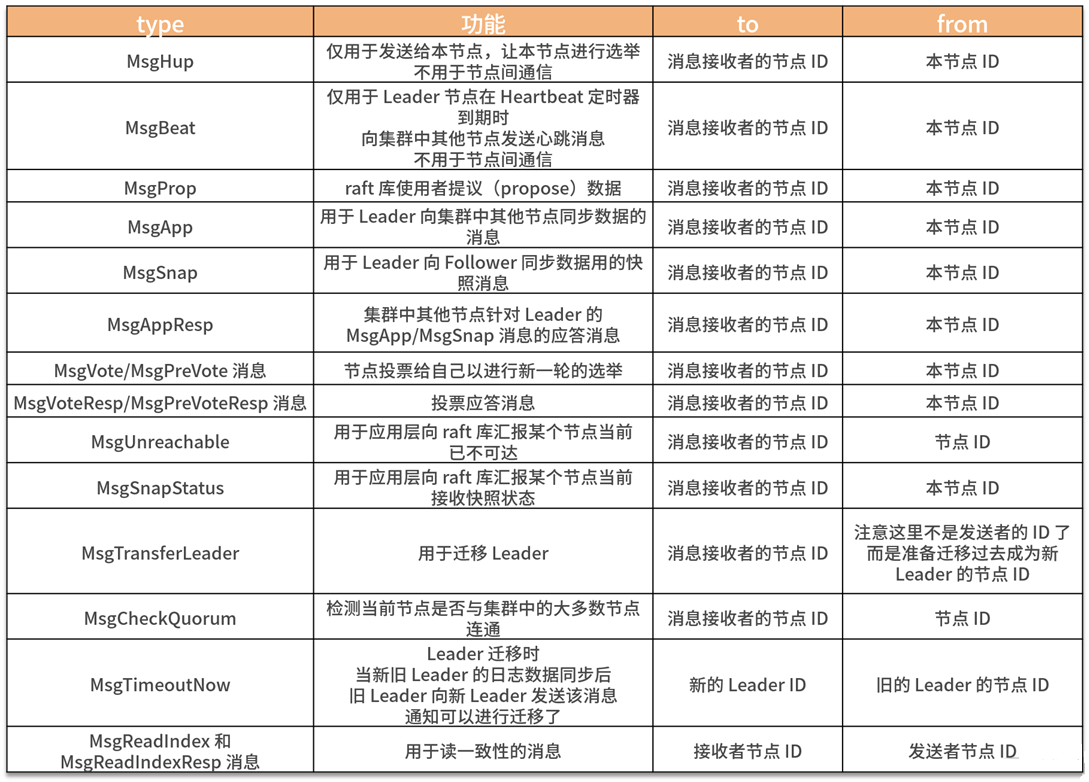
The above table lists the functions corresponding to the message type, the node ID of the message receiver and the node ID of the message sender. After receiving the message, retrieving this table according to the message type can help us understand the operation of the raft algorithm.
Election process
The key to the implementation of raft consistency algorithm are Leader election, log replication and security restrictions. After the Leader fails, the cluster can quickly select a new Leader. Only the Leader in the cluster can write the log. The Leader is responsible for copying the log to the Follower node and forcing the Follower node to remain the same as itself.
The first step of the raft algorithm is to elect a Leader. Even if the Leader fails, we need to quickly select a new Leader. Let's sort out the election process.
Launch an election
Initiating an election has restrictions on the status of nodes. Obviously, only nodes in Candidate or Follower status can initiate an election process, and the corresponding tick , function of nodes in these two states is , raft The tickelection function is used to initiate election and election timeout control. The process of initiating the election is as follows:
-
When nodes are started, they are started with Follower, and their own election timeout is randomly generated.
-
In the tickElection function of Follower, when the election times out, the node sends an MsgHup message to itself.
-
In the state machine function raft In the step function, after receiving the MsgHup message, the node first determines whether there is currently an apply configuration change message, and if so, ignores the message.
-
Otherwise, enter the campaign function for Election: first increase the Term number by 1, and then broadcast the election message to other nodes, with other fields, including the current last log Index of the node (Index field), the Term number corresponding to the last log (LogTerm field), the election Term number (Term field, that is, the Term number after + 1) Context field (the purpose is to inform whether it is a message that the Leader transfer class needs to be forced to vote this time).
-
If the node initiating the new election process gets more than half of the votes of the nodes within an election timeout period, the state will switch to the Leader state. When becoming a Leader, the Leader will send a dummy append message to submit the value on the node before this tenure.
In the above process, the reason why each node randomly selects its own timeout time is to avoid two nodes voting at the same time. At this time, no node will win more than half of the votes, resulting in the failure of this round of election and continue with the next round of election. In the third step, judge whether there is an apply configuration change message. The reason is that when there is a configuration update, the election operation cannot be carried out, that is to ensure that only one cluster member can be changed each time, and the status of multiple cluster members cannot be changed at the same time.
Participation in elections
When receiving a message whose tenure number is greater than the tenure number of the current node and the message type is an election message (type: prevote or vote), the node will make the following judgment.
-
First, judge whether the message is the type of mandatory election (the context is campaign transfer, which means Leader transfer).
-
Judge whether the current is within the lease term. The conditions met include: CheckQuota is true, the Leader saved by the current node is not empty, and there is no election timeout.
If the election is not mandatory and within the lease term, the election message will be ignored. This is to avoid those nodes that split the cluster and frequently initiate new election requests.
-
If the election message is not ignored, unless it is an election message of the prevote class, the node will switch to the Follower state when other messages are received.
-
At this time, you need to process other fields brought by the voting type, and meet the judgment of the log and the conditions for participating in the election.
Only when the above two conditions are met at the same time can the election of this node be agreed, otherwise it will be rejected. This method can ensure that the logs of the newly selected Leader nodes are up-to-date.
Log replication
After the Leader is elected, the Leader will copy the proposal to other followers when receiving the put proposal:
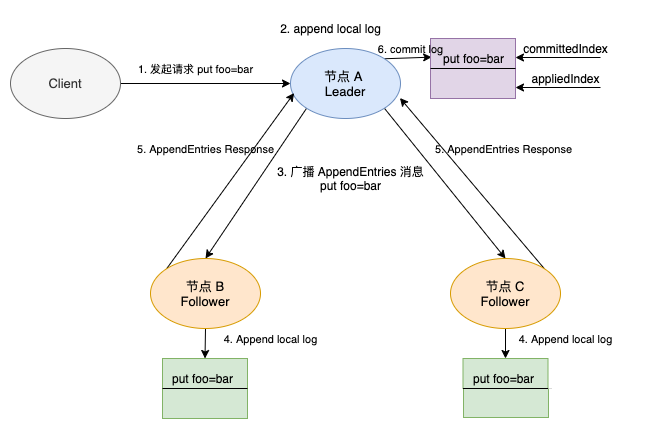
-
After receiving the client request, the KVServer module of etcd Server will submit a proposal message of MsgProp type to the raft module.
-
The Leader node adds a log locally, and its corresponding command is put foo bar. This step only adds a log and does not commit. The two index values also point to the previous log.
-
The Leader node broadcasts the AppendEntries message to other nodes in the cluster with the put command.
In the second step, the two index values are committedIndex and appliedIndex, which are identified in the figure. committedIndex stores the index of the last submitted log, while appliedIndex stores the index value of the last log applied to the state machine. The two values meet that committedIndex is greater than or equal to appliedIndex, because a log can be applied to the state machine only after it is submitted.
Next, let's see how the Leader copies the log data to the Follower node:
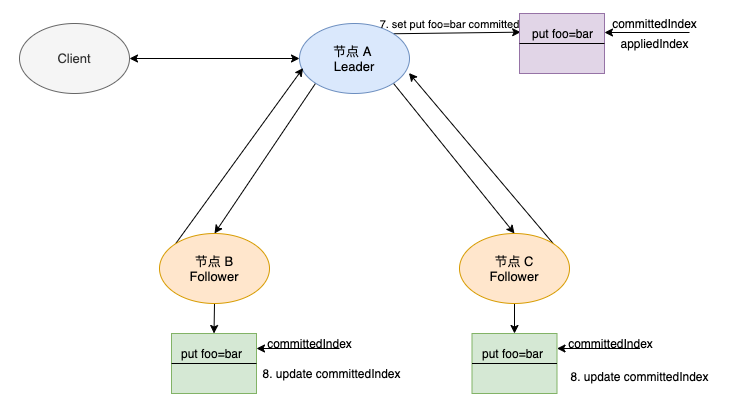
-
After receiving the AppendEntries request, the Follower node, like the Leader node, adds a new log locally, and the log is not submitted at this time.
-
After adding a successful log, the Follower node responds to the AppendEntries message to the Leader node.
-
The Leader node summarizes the responses of the Follower node. When the Leader node receives the response message of AppendEntries request from more than half of the nodes, it indicates that the put foo bar command is copied successfully and log submission can be carried out.
-
The Leader modifies the index of the local committed log and points to the latest log storing put foo bar. Because the command has not been applied to the state machine, the appliedIndex still maintains the last value.
After the command submission is completed, the command can be submitted to the application layer.
-
At this time, modify the value of appliedIndex to be equal to the value of committedIndex.
-
The Leader node will always bring the latest committedIndex index value in the subsequent AppendEntries requests sent to the Follower.
-
After receiving AppendEntries, Follower will modify the committedIndex index of the local log.