
etcd Server startup overview
The startup of etcd server includes two parts:
-
The main process of etcdServer, which directly or indirectly includes many core components such as raftNode, WAL and snapshot, can be understood as a container;
-
The other is raftNode, which encapsulates the implementation of the internal Raft protocol and exposes a simple interface to ensure the cluster consistency of write transactions.
Etcd can be divided into Client layer, API network interface layer, etcd Raft algorithm layer, logic layer and etcd storage layer. As shown in the figure below:
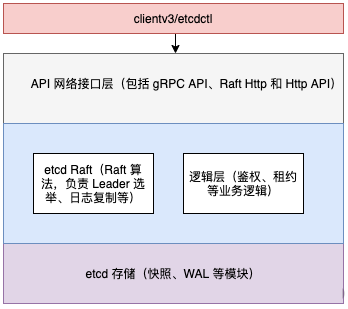
The etcd server abstracts the structure of EtcdServer, which contains the attribute of Raft node, which represents a node in the Raft cluster.
etcd server entry:
//etcdmain/main.go:25
func Main(args []string) {
checkSupportArch()
if len(args) > 1 {
cmd := args[1]
switch cmd {
case "gateway", "grpc-proxy":
if err := rootCmd.Execute(); err != nil {
fmt.Fprint(os.Stderr, err)
os.Exit(1)
}
return
}
}
startEtcdOrProxyV2(args)
}// At etcdmain / etcd go:52
func startEtcdOrProxyV2() {
grpc.EnableTracing = false
cfg := newConfig()
defaultInitialCluster := cfg.ec.InitialCluster
// Exception log processing
defaultHost, dhErr := (&cfg.ec).UpdateDefaultClusterFromName(defaultInitialCluster)
var stopped <-chan struct{}
var errc <-chan error
// identifyDataDirOrDie returns the type of the data directory
which := identifyDataDirOrDie(cfg.ec.GetLogger(), cfg.ec.Dir)
if which != dirEmpty {
switch which {
// In what mode does etcd start
case dirMember:
stopped, errc, err = startEtcd(&cfg.ec)
case dirProxy:
err = startProxy(cfg)
default:
lg.Panic(..)
}
} else {
shouldProxy := cfg.isProxy()
if !shouldProxy {
stopped, errc, err = startEtcd(&cfg.ec)
if derr, ok := err.(*etcdserver.DiscoveryError); ok && derr.Err == v2discovery.ErrFullCluster {
if cfg.shouldFallbackToProxy() {
shouldProxy = true
}
}
}
if shouldProxy {
err = startProxy(cfg)
}
}
if err != nil {
// ... With Ellipsis
// Exception logging
}
osutil.HandleInterrupts(lg)
notifySystemd(lg)
select {
case lerr := <-errc:
lg.Fatal("listener failed", zap.Error(lerr))
case <-stopped:
}
osutil.Exit(0)
}According to the above implementation, we can draw the following flow chart of startEtcdOrProxyV2 call:
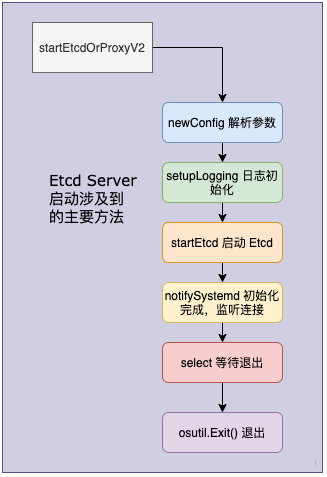
Let's explain each step in the figure above.
-
CFG: = newconfig() is used to initialize the configuration, CFG Parse (OS. Args [1:]), and then parse the command line input parameters from the second parameter.
-
setupLogging() is used to initialize log configuration.
-
identifyDataDirOrDie: judge the type of data directory, including dirMember, dirProxy and dirEmpty, corresponding to etcd directory, proxy directory and empty directory respectively. Etcd first determines whether to start etcd or start agent according to the type of data directory. If it is dirEmpty, it is determined according to whether the proxy mode is specified in the command line parameters.
-
startEtcd, the core method, is used to start etcd. We will explain this part below.
-
osutil.HandleInterrupts(lg) registration signals, including SIGINT and SIGTERM, are used to terminate the program and clean up the system.
-
Notifysystem D (LG). After initialization, listen for external connections.
-
select(), monitor the data flow on the channel, catch exceptions and wait for exit.
-
osutil.Exit(), received an exception or exit command.
Through the above process, we can see that the focus of startEtcdOrProxyV2 is startEtcd. Now let's specifically analyze the startup process.
startEtcd start etcd service
// startEtcd runs StartEtcd in addition to hooks needed for standalone etcd.
func startEtcd(cfg *embed.Config) (<-chan struct{}, <-chan error, error) {
e, err := embed.StartEtcd(cfg)
if err != nil {
return nil, nil, err
}
osutil.RegisterInterruptHandler(e.Close)
select {
case <-e.Server.ReadyNotify(): // wait for e.Server to join the cluster
case <-e.Server.StopNotify(): // publish aborted from 'ErrStopped'
}
return e.Server.StopNotify(), e.Err(), nil
}Startetcd starts the etcd service mainly by calling the startetcd method. The implementation of this method is located in the embed ded package, which is used to start the etcd server and HTTP handler for client / server communication.
// Located in embedded / etcd go:92
func StartEtcd(inCfg *Config) (e *Etcd, err error) {
// Verify etcd configuration
if err = inCfg.Validate(); err != nil {
return nil, err
}
serving := false
// Create an etcd instance according to the legal configuration
e = &Etcd{cfg: *inCfg, stopc: make(chan struct{})}
cfg := &e.cfg
// Create a peerListener(rafthttp.NewListener) for each peer to receive messages from the peer
if e.Peers, err = configurePeerListeners(cfg); err != nil {
return e, err
}
// Create a map of the client's listener(transport.NewKeepAliveListener) contexts for the server to process the client's requests
if e.sctxs, err = configureClientListeners(cfg); err != nil {
return e, err
}
for _, sctx := range e.sctxs {
e.Clients = append(e.Clients, sctx.l)
}
// Create etcdServer
if e.Server, err = etcdserver.NewServer(srvcfg); err != nil {
return e, err
}
e.Server.Start()
// After raft HTTP starts, configure peer Handler
if err = e.servePeers(); err != nil {
return e, err
}
// ... With deletion
return e, nil
}According to the above code, we can summarize the following call steps:
-
inCfg.Validate() check whether the configuration is correct;
-
Create an instance (CFCD: {etmake)};
-
Configure peerlisteners creates a peerListener(rafthttp.NewListener) for each peer to receive messages from the peer;
-
configureClientListeners creates the client's listener(transport.NewKeepAliveListener) for the server to process the client's request;
-
etcdserver.NewServer(srvcfg) creates an etcdServer instance;
-
Start etcdserver Start();
-
Configure peer handler.
etcdServer NewServer (srvcfg) and etcdServer Start() is used to create an etcdServer instance and start etcd respectively. We will introduce these two steps respectively below.
Server initialization
The initialization of the server involves many business operations, including the creation of etcdServer, starting backend, starting raftNode, etc. we will introduce these operations in detail below.
Create instance of NewServer
The NewServer method is used to create an etcdServer instance. We can create a new etcdServer according to the passed configuration. During the lifetime of etcdServer, the configuration is considered static.
Let's summarize the main methods involved in etcd Server initialization, as follows:
NewServer()
|-v2store.New() // Create a store and create the initial directory according to the given namespace
|-wal.Exist() // Determine whether the wal file exists
|-fileutil.TouchDirAll // create folder
|-openBackend // Use the current etcd db to return a backend
|-restartNode() // The most common scenario is the existing WAL, which is launched directly from SnapShot
|-startNode() // Create a new node without WAL
|-tr.Start // Start rafthttp
|-time.NewTicker() By creating &EtcdServer{} Create new structure tick ClockIt should be noted that we need to restore the lease term before the reconstruction of kv key value pairs. When restoring mvcc When kv, rebind the key to the lease. If you restore mvcc kv, it is possible to bind the key to the wrong lease before recovery.
Another is the final cleanup logic. Closing the backend without closing kv first may lead to the compression failure of recovery and TX error.
Start backend
After creating the etcdServer instance, another important operation is to start the backend. Backend is the storage support of etcd. openBackend calls the current db to return a backend. The specific implementation of openBackend method is as follows:
// Located at etcdserver / backend go:68
func openBackend(cfg ServerConfig) backend.Backend {
// Path to db storage
fn := cfg.backendPath()
now, beOpened := time.Now(), make(chan backend.Backend)
go func() {
// Start the backend separately
beOpened <- newBackend(cfg)
}()
// Blocking, waiting for the backend to start, or 10s timeout
select {
case be := <-beOpened:
return be
case <-time.After(10 * time.Second):
// Timeout, db file occupied
)
}
return <-beOpened
}
As you can see, in the implementation of openBackend, we first create a backend Back end type chan, and start the back end with a separate co process. Set the start timeout to 10s. Beopened < - newbackend (CFG) is mainly used to configure backend startup parameters. The specific implementation is in the backend package.
The underlying storage of etcd is based on boltdb. The parameters needed to build boltdb using newBackend method are bolt Open (bcfg. Path, 0600, bopts) creates and opens the database under the given path. The second parameter is the permission to open the file. If the file does not exist, it will be created automatically. Passing the nil parameter causes boltdb to open a database connection using the default options.
Start Raft
In the implementation of NewServer, we can judge the starting mode of Raft based on conditional statements. The specific implementation is as follows:
switch {
case !haveWAL && !cfg.NewCluster:
// startNode
case !haveWAL && cfg.NewCluster:
// startNode
case haveWAL:
// restartAsStandaloneNode
// restartNode
default:
return nil, fmt.Errorf("unsupported Bootstrap config")
}
The expression corresponding to the haveWAL variable is WAL Exist (CFG. Waldir()), used to judge whether there is WAL, CFG Newcluster corresponds to -- initial cluster state when etcd is started, which identifies the node initialization method. This configuration defaults to new and the value of the corresponding variable haveWAL is true. New indicates that no cluster exists. All members start in static mode or DNS mode to create a new cluster; existing indicates that the cluster exists and the node will try to join the cluster.
Under three different conditions, raft corresponds to three startup modes: startNode, restartAsStandaloneNode and restartNode. Next, we will introduce these three startup methods in combination with judgment conditions.
startNode
Under the following two conditions, raft will call the startNode method in raft.
- !haveWAL && cfg.NewCluster - !haveWAL && !cfg.NewCluster - startNode(cfg, cl, cl.MemberIDs()) - startNode(cfg, cl, nil) // Definition of startNode func startNode(cfg ServerConfig, cl *membership.RaftCluster, ids []types.ID) (id types.ID, n raft.Node, s *raft.MemoryStorage, w *wal.WAL) ;
You can see that the startNode method will be called under both conditions, but the parameters are different. In the scenario where there is no WAL log and the node is newly configured, it is necessary to pass in the cluster member ids. If you join an existing cluster, it is not necessary.
We use one of the case s to analyze specifically:
case !haveWAL && !cfg.NewCluster:
// Check the initial configuration when joining an existing cluster, and return an error if there is a problem
if err = cfg.VerifyJoinExisting(); err != nil {
return nil, err
}
// Create a new cluster using the address provided by raft
cl, err = membership.NewClusterFromURLsMap(cfg.Logger, cfg.InitialClusterToken, cfg.InitialPeerURLsMap)
if err != nil {
return nil, err
}
// GetClusterFromRemotePeers takes a set of URLs representing etcd peer s and tries to construct a cluster by accessing the member endpoint on one of the URLs
existingCluster, gerr := GetClusterFromRemotePeers(cfg.Logger, getRemotePeerURLs(cl, cfg.Name), prt)
if gerr != nil {
return nil, fmt.Errorf("cannot fetch cluster info from peer urls: %v", gerr)
}
if err = membership.ValidateClusterAndAssignIDs(cfg.Logger, cl, existingCluster); err != nil {
return nil, fmt.Errorf("error validating peerURLs %s: %v", existingCluster, err)
}
// Verify compatibility
if !isCompatibleWithCluster(cfg.Logger, cl, cl.MemberByName(cfg.Name).ID, prt) {
return nil, fmt.Errorf("incompatible with current running cluster")
}
remotes = existingCluster.Members()
cl.SetID(types.ID(0), existingCluster.ID())
cl.SetStore(st)
cl.SetBackend(be)
// Start raft Node
id, n, s, w = startNode(cfg, cl, nil)
cl.SetID(id, existingCluster.ID())From the above mainstream process, first verify the configuration, then create a new raft cluster using the provided address mapping, verify the compatibility of joining the cluster, and finally start the raft Node.
StartNode returns a new node based on the given configuration and raft member list, which appends the ConfChangeAddNode entry of each given peer to the initial log. The length of the called restars method cannot be zero if it is zero.
RestartNode is similar to StartNode, but does not contain the peers list. The current membership of the cluster will be restored from the storage. If the caller has a state machine, pass in the latest log index value applied to the state machine; Otherwise, use zero as the parameter directly.
Restart the raft Node
When the WAL file already exists, first check the read-write permission of the response folder when starting the raft Node (the discovery token will not take effect after the cluster is initialized); The snapshot file will then be loaded and the backend storage will be restored from the snapshot.
cfg.ForceNewCluster corresponds to -- force new cluster in etcd configuration. If it is true, a new single member cluster will be forced to be created; Otherwise, restart the raft Node.
restartAsStandaloneNode
When -- force new cluster is configured as true, restartAsStandaloneNode will be called, that is, a new single member cluster will be forced to be created. This node will submit configuration updates, forcibly delete all members in the cluster, and add itself as a node of the cluster. At the same time, we need to restore its backup settings.
In the implementation of restartAsStandaloneNode, first read the WAL file and discard the local uncommitted entries. createConfigChangeEnts creates a series of Raft entries (i.e. EntryConfChange) to delete a given set of IDs from the cluster. If the current node self appears in the entry, it will not be deleted; If self is not within the given ID, it will create a Raft entry to add the given self default member, and then force the newly submitted entries to be appended to the existing data store.
Finally, set some states, construct the configuration of the raft Node, and restart the raft Node.
restartNode
In the case of existing WAL data, in addition to the restart astandalonenode scenario, when -- force new cluster is false by default, restart raftNode directly. This operation is relatively simple, reducing the steps of discarding local uncommitted entries and forcing the addition of newly submitted entries. The next step is to restart the raftNode directly, restore the status of the previous cluster node, read the WAL and snapshot data, and finally start and update the raftStatus.
Raft HTTP start
After analyzing the startup of raft Node, let's look at the startup of raft http. Transport implements the Transporter interface, which provides the function of sending and receiving raft messages from peers. We need to call the Handler method to get the Handler to process the request received from peers. Users need to call Start before calling other functions, and call Stop when they Stop using transport.
In the process of starting raft HTTP, first build transport, assign m.peers to Remote and Peer in transport, and then SRV r. Transport points to the built transport.
Start etcd server
Next is the real start of etcd. Let's look at the main call steps:
// Located in embedded / etcd go:220
e.Server.Start()
// Receive peer message
if err = e.servePeers(); err != nil {
return e, err
}
// Receive client requests
if err = e.serveClients(); err != nil {
return e, err
}
// Provide export metrics
if err = e.serveMetrics(); err != nil {
return e, err
}
serving = true
Starting etcd Server includes three main steps: first, e.Server Start initializes the necessary information for Server startup; Then realize the internal communication of the cluster; Finally, start receiving requests from peer and client, including range, put and other requests.
e.Server.Start
Before processing the request, the Start method initializes the necessary information of Server. It needs to be called before Do and Process, and must be non blocking. Any time consuming function must be run in a separate association. In the implementation of the start method, several goroutine s are also started, which are used for asynchronous operations such as electing clock settings and registering their own information to the server.
Cluster internal communication
The communication within the cluster is mainly by etcd Servepeers is implemented in rafthttp After transport starts, configure the processors of cluster members. First generate http Handler to handle the requests of etcd cluster members and do some configuration verification. goroutine reads the gRPC request and then calls srv.. Handler handles these requests. srv.Serve always returns a non empty error. When Shutdown or Close, the error returned is ErrServerClosed. Finally, SRV Serve starts listening to cluster members in an independent collaboration.
Processing client requests
Etcd.serveClients are mainly used to handle client requests, such as our common range, put and other requests. Etcd processes the requests of clients. Each client's request corresponds to a goroutine protocol, which is also the support of etcd's high performance. etcd Server starts a client service protocol for each monitored address and processes it differently according to v2 and v3 versions. In serveClients, gRPC properties are also set, including GRPCKeepAliveMinTime, GRPCKeepAliveInterval and GRPCKeepAliveTimeout.