Five data types and application scenarios of Redis
Redis has five data types, namely, string,list,hash,set,zset(sort set). I think this point should be clear to all partners who have a little knowledge of redis. Next, let's discuss the application scenarios of these five data types. [get notes]
string
This type is believed to be the most familiar, but don't underestimate it. It can do a lot of things and lead to a series of problems.
Let's start with the simplest:
localhost:6379> set coderbear hello OK localhost:6379> get codebear "hello"
I believe you all know these two commands. I won't explain them. Let's use the command strlen again:
localhost:6379> strlen codebear (integer) 5
Oh, I see. The strlen command can obtain the length of Value. The length of hello is 5, so the output is 5. Is this explanation right? Don't worry, let's look down slowly.
We use the append command to add something to the codebear key:
APPEND codebear China
What will be output if we use the strlen command again? Of course, it's 7. Although I'm not good at math, I still have no problem counting within 10. However, when we execute the strlen command again, you will find a strange phenomenon:
localhost:6379> strlen codebear (integer) 11
Nani, why 11? Is our opening method wrong and we don't want to try again? No, even if you try the third life, the output you see is still 11. Why? This involves binary security.
Binary security
The so-called binary security is that it will only access data in strict accordance with binary, and will not attempt to parse data in a special format. Redis is binary secure. It always accesses binary data, or byte arrays. [get notes]
Let's get codebear Kangkang:
get codebear "hello\xe4\xb8\xad\xe5\x9b\xbd"
You will find that the good "hello China" stored in Redis is actually like this, because our Xshell client uses UTF-8. Under UTF-8, a Chinese is usually three bytes, and two Chinese are six bytes, so "hello China" accounts for 5 + 6 = 11 bytes in Redis.
If you don't believe it, let's change the code of Xshell to GBK. In the world of GBK, a Chinese usually occupies two bytes, so:
localhost:6379> set codebeargbk China OK localhost:6379> get codebeargbk "\xd6\xd0\xb9\xfa" localhost:6379> strlen codebeargbk (integer) 4
So, wake up, boy, it's impossible to save Chinese in Redis. The reason why we can easily get Chinese in the program is just because the API decodes.
Unexpectedly, a String also involves the problem of binary security. It seems that you can't underestimate any knowledge point. This is often called search hell. When you find a question and find that there is another thing you don't understand in the answer to this question, you start to read that thing you don't understand, and then another concept you don't understand comes out, So... It's tears when you say too much.
We often use Redis as the cache. We use the set get commands. We can also use Redis as the second kill system. In most cases, we also use the String data type. Let's continue to look at the following:
localhost:6379> set codebearint 5 OK localhost:6379> incr codebearint (integer) 6
You may not have used the incr command, but you can guess what the incr command is from the result and command name. Yes, it is self increasing. Since there is self increasing, you can also do self decreasing:
localhost:6379> decr codebearint (integer) 5
It was 6 just now. After calling the decr command, it became 5 again.
Well, another question, String is a String. How can it do addition or subtraction?
Let's use the type command to check the type of codebeinter key:
localhost:6379> type codebearint string
Yes, it's a fake String type.
Let's look at another thing:
localhost:6379> object encoding codebear "raw" localhost:6379> object encoding codebearint "int"
Originally, a mark will be marked inside Redis to mark the type of this key (this type can be different from the five data types of Redis).
bitmap
There is a requirement: count the number of login days of a specified user in a year? It's not easy. I'll build a login form. Isn't it OK? Yes, it can, but is the price a little high? If there are 1 million users, how big is the login form. At this time, bitmap was born. It is an artifact to solve such problems. [get notes]
Let's take a look at what bitmap is. To put it bluntly, it's a binary array. Let's draw a diagram to illustrate:

This is the bitmap, which is composed of many small grids. Only 1 or 0 can be placed in the grid. To be professional, each small grid is bit by bit. String supports bitmap very well and provides a series of bitmap commands. Let's try:
setbit codebear 3 1 (integer) 0 localhost:6379> get codebear "\x10"
What does this mean? That is to say, there are 8 small grids. The fourth grid contains 1 (the index starts from 0), and the others are 0, like this:

Let's calculate the size, 1, 2, 4, 8, 16. Yes, it is 16 in decimal system, and the output of our get codebear is "\ x10", "\ x" represents hexadecimal, that is, hexadecimal 10, and hexadecimal 10 is decimal 16.
Let's use the strlen command again:
localhost:6379> strlen codebear (integer) 1
It seems to occupy only one byte. Let's continue:
localhost:6379> setbit codebear 5 1 (integer) 0
The bitmap looks like this:

The size in decimal is 20.
Let's continue with strlen: localhost: 6379 > strlen codeear (integer) 1
It still occupies only one byte. We have stored two data. Isn't it amazing.
Let's continue:
localhost:6379> setbit codebear 15 1 (integer) 0 localhost:6379> strlen codebear (integer) 2
It can be seen from here that bitmap can be extended. Now I put 1 in the 16th grid, so bitmap is extended. Now strlen is 2. So I want to know how many of the 16 grids are 1. What should I do? Use the bitcount command:
localhost:6379> bitcount codebear (integer) 3
At this point, is it suddenly clear that you can easily count the number of login days of a specified user in a year with bitmap. Let's assume that codebear logged in on the first day, the second day and the last day:
localhost:6379> setbit codebear 0 1 (integer) 0 localhost:6379> setbit codebear 1 1 (integer) 0 localhost:6379> setbit codebear 364 1 (integer) 0 localhost:6379> bitcount codebear (integer) 3
Continue to use strlen to see how many bytes are occupied in the login days of the whole year:
localhost:6379> strlen codebear (integer) 46
Only 46 bytes. Even if you log in every year, it only takes 46 bytes. I don't know how big such data should be in the database, but I think it's far more than 46 bytes. If there are 1 million users, it's less than 50M. Even if these 1 million users log in every day, they occupy these bytes.
Let's change the above requirements: count the number of days a specified user logs in in any time window?
The bitcount command can also be followed by two parameters, start and end:
localhost:6379> bitcount codebear 0 2 (integer) 2
We can also write the second parameter as - 1, representing up to the last bit, that is:
localhost:6379> bitcount codebear 0 -1 (integer) 3
bitmap is far more powerful than these. Let's come to Kangkang's second demand: Statistics on the login status of all users on any date:
- Count the users who have logged in in any day
- Count the users who have logged in in any few days
- Count the users who log in every day in any few days
Brain pain, is this something that people do? Don't worry, all this can be implemented with bitmap.
The first requirement is well implemented. Assuming that the userId of the user codebear is 5 and the userId of the user Xiaoqiang is 10, we can create a bitmap with the key as the date. The fourth and ninth cells are 1, which means that the user with userId 5 and userId 1 has logged in on this day, and then everything will be fine under bitcount, as shown below:
localhost:6379> setbit 20200301 4 1 (integer) 0 localhost:6379> setbit 20200301 9 1 (integer) 0 localhost:6379> bitcount 20200301 (integer) 2
To realize the following two requirements, you need to use new commands. Look at the results directly:
localhost:6379> setbit 20200229 9 1 (integer) 1 localhost:6379> bitop and andResult 20200301 20200229 (integer) 2 localhost:6379> bitcount andResult (integer) 1 localhost:6379> bitop or orResult 20200301 20200229 (integer) 2 localhost:6379> bitcount orResult (integer) 2
Let's explain below. First, a bitmap with key 20200229 is created, in which the 10th cell is 1, which means that the user with user Id 10 has logged in on 20200229. Next, the bitmap with key 20200301 and 20200229 is also a bitmap, and the result is put into the key andResult. The following is the familiar bitcount command, How many small cells are 1 in Kangkang, and the result is 1, that is, one user logs in every day these two days.
Since there is and operation, there is or operation. The following is the command of or operation. It is calculated that two users log in these two days.
In this way, the latter two requirements can be easily solved.
After looking at so many examples, have you found a problem? All operations are completed in Redis. In this case, there is a very tall noun: computing moves to data. In contrast, taking data from a certain place and then calculating it externally is called data moving to calculation. [get notes]
list
The bottom layer of Redis list is a two-way linked list. Let's start with Kangkang's commands:
localhost:6379> lpush codebear a b c d e (integer) 5 localhost:6379> lrange codebear 0 -1 1) "e" 2) "d" 3) "c" 4) "b" 5) "a"
Push, I understand. Push, but what does the front + l mean? The front l represents the left, and lpush is pushed on the left. In this way, the first push in is on the far right. lrange takes out the data within the specified index range from the left, and the back - 1 represents the last one.
Since you can push on the left, you must push on the right. We Kangkang:
localhost:6379> rpush codebear z (integer) 6 localhost:6379> lrange codebear 0 -1 1) "e" 2) "d" 3) "c" 4) "b" 5) "a" 6) "z"
Two pop-up commands are also commonly used. Let's use the following:
localhost:6379> lpop codebear "e" localhost:6379> lrange codebear 0 -1 1) "d" 2) "c" 3) "b" 4) "a" 5) "z" localhost:6379> rpop codebear "z" localhost:6379> lrange codebear 0 -1 1) "d" 2) "c" 3) "b" 4) "a"
lpop is the first element to pop up on the left, and rpop is the first element to pop up on the right.
If we use a combination of lpush, rpop or rpush, lpop, it is a first in, first out, or a queue; If we use a combination of lpush, lpop or rpush, rpop, it is first in and last out, which is the stack. Therefore, Redis can also be used as a message queue, using the data type of list.
I believe everyone must have played the forum. The posts posted at the back are usually in the front. For performance, we can put the post data in the list in Redis, but we can't throw data into the list indefinitely. Generally, more people will read the posts in the front pages, and few people will read the posts in the back. Therefore, we can put the post data in the front pages in the list, and then set a rule to delete the data in the list regularly, Can we use the ltrim of list? The command is:
localhost:6379> ltrim codebear 1 -1 OK localhost:6379> lrange codebear 0 -1 1) "c" 2) "b" 3) "a"
This ltrim is a little strange. It keeps the data within the index range and deletes the data outside the index range. Now the first parameter given is 1 and the second parameter is - 1, which is to retain the data from index 1 to the end, so the data with index 0 is deleted.
hash
Now there is a product details page, which contains a pile of information such as product introduction, price, warm tips, number of views, number of buyers, etc. of course, we can store the whole object in String, but there may be some places that only need product introduction. Even so, we still have to take out the whole object. Isn't it a little cost-effective? hash can solve such problems:
localhost:6379> hset codebear name codebear (integer) 1 localhost:6379> hset codebear age 18 (integer) 1 localhost:6379> hset codebear sex true (integer) 1 localhost:6379> hset codebear address suzhou (integer) 1 localhost:6379> hget codebear address "suzhou"
What if we store the whole object and want to modify the age now? To take out the whole object, then assign a value, and finally put it back, but now:
localhost:6379> hincrby codebear age 2 (integer) 20 localhost:6379> hget codebear age "20"
set
Set is an unordered and de duplicated data structure. We can use it to de duplicate. For example, if I want to store the IDs of all commodities, I can use set to implement it. What scenario needs to store the IDs of all commodities? To prevent cache penetration, of course, there are many implementation schemes to prevent cache penetration, and set scheme is only one of them. Let's Kangkang its basic usage: [get notes]
localhost:6379> sadd codebear 6 1 2 3 3 8 6 (integer) 5 localhost:6379> smembers codebear 1) "1" 2) "2" 3) "3" 4) "6" 5) "8"
We can clearly see that the data we have stored has been de duplicated and the data has been disrupted.
Let's see what the srandmember command does?
localhost:6379> srandmember codebear 2 1) "6" 2) "3" localhost:6379> srandmember codebear 2 1) "6" 2) "2" localhost:6379> srandmember codebear 2 1) "6" 2) "3" localhost:6379> srandmember codebear 2 1) "6" 2) "2" localhost:6379> srandmember codebear 2 1) "8" 2) "3"
srandmember can be followed by a parameter followed by 2, which means that two non repeating elements are taken out randomly. What if you want to take out two repeatable elements?
localhost:6379> srandmember codebear -2 1) "6" 2) "6"
If followed by a negative number, it means that the extracted element can be repeated.
What if the number followed is greater than the number of set elements?
localhost:6379> srandmember codebear 100 1) "1" 2) "2" 3) "3" 4) "6" 5) "8" localhost:6379> srandmember codebear -10 1) "8" 2) "1" 3) "1" 4) "1" 5) "6" 6) "1" 7) "1" 8) "2" 9) "6" 10) "8"
If it is a positive number, return all the elements in the set at most, because a positive number is not repeated. If you return one more, it will be repeated. If it is a negative number, it will not affect. If it is followed by a few, it will return how many elements.
We can use this command in the lottery system. If we can win the lottery repeatedly, it will be followed by a negative number. If we can't win the lottery repeatedly, it will be followed by a positive number.
Set can also calculate difference set, union set and intersection:
localhost:6379> sadd codebear1 a b c (integer) 3 localhost:6379> sadd codebear2 a z y (integer) 3 localhost:6379> sunion codebear1 codebear2 1) "a" 2) "c" 3) "b" 4) "y" 5) "z" localhost:6379> sdiff codebear1 codebear2 1) "b" 2) "c" localhost:6379> sinter codebear1 codebear2 1) "a"
The above command does not explain much. What's the use? We can use it to make a recommendation system of "financing fraud": who are your common friends, which games you are playing, and who you may know. [get notes]
zset
set is disordered, while zset is ordered. Each element has a concept of score. The smaller the score, the higher the ranking. Let's start with Kangkang's basic use:
localhost:6379> zadd codebear 1 hello 3 world 2 tree (integer) 3 localhost:6379> zrange codebear 0 -1 withscores 1) "hello" 2) "1" 3) "tree" 4) "2" 5) "world" 6) "3" localhost:6379> zrange codebear 0 -1 1) "hello" 2) "tree" 3) "world"
Now we create a zset whose key is codebear, and add three elements to it: hello, world, tree and score are 1, 3 and 2 respectively. Then we use zrange to take out the results. It is found that the order has been arranged according to the size of the score. If WithCores is followed, the score will be taken out together.
If we want to see where the tree ranks, we can use the zrank command:
localhost:6379> zrank codebear tree (integer) 1
Because it starts from 0, the result is 1.
If we want to query the score of the tree:
localhost:6379> zscore codebear tree "2"
What if we want to take out the first two from large to small:
localhost:6379> zrange codebear -2 -1 1) "tree" 2) "world"
However, this result is somewhat wrong. The first two elements from large to small are world. What should we do
localhost:6379> zrevrange codebear 0 1 1) "world" 2) "tree"
Such as leaderboard, hot data and delayed task queue can be implemented by zset. Delayed task queue has been introduced in my previous blog.
When it comes to szet, it may also lead to a question: what is the implementation of zset in Redis? Skip table.
We won't expand the hop table here. Why use the hop table? It's because of the characteristics of the hop table: read-write balance.
Why is Redis so fast
This is a classic interview question. When it comes to Redis in the interview, 80% will ask this question. Why is Redis so fast? The main reasons are as follows:
- Programming language: Redis is written in C language, which is closer to the bottom layer and can directly call os functions.
- Memory based: because Redis data is stored in memory, it is faster. If it is placed on the hard disk, the performance depends on two indicators: addressing (speed) and throughput. Addressing is at the millisecond level. Generally speaking, the throughput is about 500M. Even if the server performance is even better, there will be no throughput of a few G, but it is at the nanosecond level in memory.
- Single thread: because Redis is single thread, the consumption of thread switching is avoided and there is no competition, so it is faster.
- Network model: because Redis's network model is epoll, it is a multiplex network model. (epoll will be discussed later)
- Optimization of Redis data structure: Redis provides five data types, among which zset is optimized with hop table, and the whole Redis is actually optimized with hash, so that its time cost is O(1) and the search is faster.
- Redis6.0 introduces I/O Threads, so it's faster. (I/O Threads will be discussed later)
What are the disadvantages of Redis
This is an open-ended question. There are many answers, such as:
- Because Redis is single threaded, it cannot give full play to the advantages of multi-core CPU.
- Because Redis is single threaded, once a complex command is executed, all subsequent commands are blocked outside the door.
- It is impossible to add an expiration time to an item in the hash.
Why can Redis guarantee atomicity
Because Redis is single threaded, it can only process one read / write request at the same time, so it can ensure atomicity.
Redis is single threaded. How to explain it
We have always emphasized that redis is single threaded. Redis is single threaded. But is redis really single threaded? In fact, redis is single threaded, but the reading and writing of redis is single threaded, that is, there is only one work thread.
What is I/O Threads
I/O Threads is a new feature introduced by Redis 6.0. In the past, Redis received requests from the socket, processed them, and wrote the results to the socket in a serial manner, that is:

Redis6 0 introduced I/O Threads:
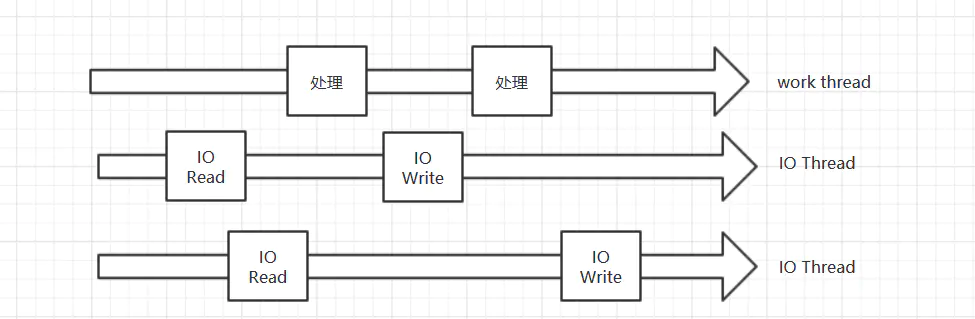
You can see that there are multiple I / O threads. I / O threads are responsible for reading and writing data from the socket to the socket. While the work thread processes the data, other I / O threads can read data from the socket. Get ready first. When the work thread is busy, it can process the next request immediately. But there is only one work thread, which should be kept in mind.
What is epol
Epoll is a multiplex IO model. Before talking about epoll, I have to talk about the traditional IO model. The traditional IO model is synchronous blocking. What does it mean? The socket established by the server will wait for the connection of the client. When the client is connected, it will wait for the write request of the client. A server can only serve one client. [get notes]
Later, programmers found that multithreading could be used to solve this problem:
- When the first client connects to the server, the server will start the first thread, and the interaction between the first client and the server will be carried out in the first thread.
- When the second client connects to the server, the server will start the second thread, and the interaction between the second client and the server will be carried out in the second thread.
- When the third client connects to the server, the server will start the third thread, and the interaction between the third client and the server will be carried out in the third thread.
It seems beautiful. A server can serve N clients, but it can't open threads indefinitely. In Java, threads have their own independent stack. A thread consumes at least 1M, and the CPU will not be affected by opening threads indefinitely.
Although it took several times before I came to the epoll era, as a curd boy, I didn't study api boy so deeply. Now let's cross the middle era and come directly to the epoll era. [get notes]
Let's first understand the epoll method. In linux, you can use man to look at the OS functions:
man epoll
There is a paragraph in the introduction:
* epoll_create(2) creates a new epoll instance and returns a file descriptor referring to that instance. (The more recent epoll_create1(2) extends
the functionality of epoll_create(2).)
* Interest in particular file descriptors is then registered via epoll_ctl(2). The set of file descriptors currently registered on an epoll
instance is sometimes called an epoll set.
* epoll_wait(2) waits for I/O events, blocking the calling thread if no events are currently available.
Although my English is really bad, I can barely understand it with the help of translation. The general meaning is:
- epoll_create creates an epoll example and returns a file descriptor.
- epoll_ctl is used to register events of interest.
- epoll_wait is used to wait for IO events. If there is no IO event of interest, it will be blocked. The implication is that if there is an event of interest, this method will return.
A demo is also given below. Let's try to see:
epollfd = epoll_create1(0);//Create an epoll instance and return an epoll file descriptor
if (epollfd == -1) {
perror("epoll_create1");
exit(EXIT_FAILURE);
}
ev.events = EPOLLIN;
ev.data.fd = listen_sock;
// Register events of interest
// The first parameter is the epoll file descriptor
// The second parameter is the action, and now it is time to add the event of interest
// The third parameter is the monitored file descriptor
// The fourth parameter tells the kernel what events to listen for
// The event being monitored is EPOLLIN, which indicates that there is readable data on the corresponding file descriptor
if (epoll_ctl(epollfd, EPOLL_CTL_ADD, listen_sock, &ev) == -1) {
perror("epoll_ctl: listen_sock");
exit(EXIT_FAILURE);
}
// A dead circle
for (;;) {
// Wait for the IO event to occur
// The first parameter is the epoll file descriptor
// The second parameter is the set of events that occur
// The third parameter is not important
// The fourth parameter is the waiting time, - 1 is always waiting
// The return value is the number of events that occurred
nfds = epoll_wait(epollfd, events, MAX_EVENTS, -1);
if (nfds == -1) {
perror("epoll_wait");
exit(EXIT_FAILURE);
}
// loop
for (n = 0; n < nfds; ++n) {
// If the event occurs, the corresponding file descriptor is listen_sock
if (events[n].data.fd == listen_sock) {
// Establish connection
conn_sock = accept(listen_sock,
(struct sockaddr *) &addr, &addrlen);
if (conn_sock == -1) {
perror("accept");
exit(EXIT_FAILURE);
}
setnonblocking(conn_sock);// Set non blocking
ev.events = EPOLLIN | EPOLLET;// Set events of interest
ev.data.fd = conn_sock;
// Add events of interest as epolin or EPOLLET
if (epoll_ctl(epollfd, EPOLL_CTL_ADD, conn_sock,
&ev) == -1) {
perror("epoll_ctl: conn_sock");
exit(EXIT_FAILURE);
}
} else {
do_use_fd(events[n].data.fd);
}
}
}
Since I haven't studied C language, please bear with me for some incorrect comments, but I think it probably means so.
If you have studied NIO in Java, you will find that this pattern is very similar to NIO in Java, because NIO in Java finally calls the epoll function of OS.
What the hell is epoll? To put it simply, tell the kernel what events I'm interested in, and the kernel will help you monitor. When events of interest occur, the kernel will take the initiative to notify you.
What are the advantages of this:
- Reduce the switching between user mode and kernel mode.
- Event ready notification mode: the kernel takes the initiative to notify you. If it is not secure, you have to bother to poll and judge.
- File descriptors have almost no upper limit: if you want to interact with several clients, you can interact with several clients. A thread can listen to N clients and complete the interaction.
Epoll function is based on OS. There is no epoll in windows.
Well, that's all for epoll. There are three new terms: user state, kernel state and file descriptor. I won't explain them first. Let's write NIO's blog later. At that time, epoll will be introduced in more detail.
Expiration policy of Redis
Generally speaking, there are three common expiration strategies:
- Scheduled deletion: you need to add a timer to each key to remove data as soon as it expires. The advantage is very accurate, but the disadvantage is large consumption.
- Regular deletion: every once in a while, a certain number of keys will be scanned. If expired keys are found, the data will be removed. The advantage is that the consumption is relatively small, but the disadvantage is that expired keys cannot be removed in time.
- Lazy delete: when using a key, first judge whether the key expires, and then delete it. The advantage is low consumption. The disadvantage is that expired keys cannot be removed in time. They will be removed only after they are used.
Redis uses the policy of regular deletion + lazy deletion.
The Conduit
If we have many commands to give to Redis, the first scheme is to send them one by one. The disadvantages are self-evident: each command needs to go through the network, and the performance is relatively low. The second scheme is to use the pipeline. Before introducing the pipeline, first demonstrate one thing: [get notes]
[root@localhost ~]# nc localhost 6379 set codebear hello +OK get codebear $5 hello
When sending commands to Redis, we don't have to use the Redis client. We just need to connect to the port of the Redis server. The meaning of $5 output after the get codeear command is not discussed here.
How to use the pipeline? With the above foundation, it is actually very simple:
[root@localhost ~]# echo -e "set codebear hello1234 \n incr inttest \n set haha haha" | nc localhost 6379 +OK :1 +OK
Divide the commands with \ n and send them to Redis through nc.
Let's see if Kangkang succeeded:
[root@localhost ~]# nc localhost 6379 get inttest $1 1 get codebear $9 hello1234 get haha $4 haha
It should be noted that although multiple commands are sent together, they are not atomic as a whole. Major Redis operating components also provide pipeline sending methods. If you need to send multiple commands in the project next time, you might as well try it.
Publish and subscribe
When we have a message that needs to be pushed to various systems in the form of broadcast, we can not only use message queue, but also publish and subscribe. Redis provides the function of publish and subscribe. Let's see how to use it [get notes]
First, we need to create a subscriber to subscribe to the channel named hello:
localhost:6379> subscribe hello Reading messages... (press Ctrl-C to quit) 1) "subscribe" 2) "hello" 3) (integer) 1
Then, to create a publisher, send a message to the channel named hello:
localhost:6379> publish hello goodmorning (integer) 1
Finally, go back to the subscriber and find that a message has been received:
1) "message" 2) "hello" 3) "goodmorning"
However, it should be noted that if you publish a message first and then subscribe to it, you will not receive historical messages.
Is it particularly simple? When I didn't know there was a ZooKeeper, I thought I could use Redis's publish and subscribe function as the configuration center.
Memory obsolescence
If Redis's memory is full and can no longer hold new data, Redis's memory elimination strategy will be triggered. In Redis Conf has a configuration, which is used to configure specific memory elimination strategies: [get notes]
maxmemory-policy volatile-lru
It has several configurations. Before talking about specific configurations, you should first say two nouns. If you don't understand these two nouns, you can only memorize the meaning of each configuration.
- LRU: minimum use elimination algorithm: if this key is rarely used, it will be eliminated
- LFU: the elimination algorithm has not been used recently: if this key has not been used recently, it will be eliminated
Here are the specific configurations. Let's look at them one by one:
- Volatile LRU: among the keys with expiration time set, remove the least recently used key
- All keys LRU: remove the least recently used key among all keys
- Volatile LFU: in the keys with expiration time set, remove the recently unused keys
- All keys LFU: among all keys, remove the keys that are not used recently
- Volatile random: randomly remove a key from the keys with expiration time set
- All keys random: randomly remove a key
- Volatile TTL: in the key space with expiration time set, keys with earlier expiration time are removed first
- noeviction: god horse doesn't do it, just throw an exception