Sometimes, when the system is running, there is a sudden crash, but we have to find out the cause. Although we can solve the current problem through the temporary protection mechanism watchdog, but to find the cause of the crash, we have to rely on the special tool Kdump for kernel analysis. Although I don't understand the Linux kernel, I can find out which stack is abnormal and causes the downtime through simple analysis.
Kdump
Kdump is a kernel crash capture mechanism based on kexec. It saves the memory image before kernel crash. The programmer analyzes the file to find out the cause of kernel crash, so as to improve the system.
The basic concept of Kdump
What is kexec?
Kexec is the key to realize kdump mechanism, which consists of two parts:
One is the kernel space system call kexec_load, which is responsible for loading the capture kernel (capture kernel or send kernel) to the specified address when the production kernel (production kernel or first kernel) is started.
The other is the user space tool kexec tools, which passes the address of the capture kernel to the production kernel, so that when the system crashes, it can find the address of the capture kernel and run it. No kdump without kexec.
First, kexec realizes that you can start another kernel in one kernel, which makes kdump useful. The original purpose of kexec is to save the time for kernel developers to restart the system. Who could have thought that this "lazy" technology gave birth to the most successful memory transfer mechanism?
What is kdump?
The concept of kdump appeared around 2005, which is the most reliable kernel transfer mechanism so far, and has been selected by major linux ™ manufacturers. Kdump is an advanced kernel crash dump mechanism based on kexec. When the system crashes, kdump uses kexec to start to the second kernel. The second kernel is usually called the capture kernel, which starts with a small amount of memory to capture the dump image. The first kernel keeps part of the memory for the second kernel to start. Because kdump uses kexec to start the capture kernel, bypassing the BIOS, the memory of the first kernel is preserved. This is the essence of kernel crash dump.
kdump requires two different purpose kernels, the production kernel and the capture kernel. The production kernel captures the image of the kernel service. The capture kernel will start when the production kernel crashes, and build a microenvironment with the corresponding ramdisk to collect and transfer the memory under the production kernel.
How to use kdump
There are two ways to build the system and dump capture kernel:
1) Build a separate custom dump capture kernel to capture the kernel dump;
2) Or take the system kernel itself as the dump capture kernel, which does not need to build a separate dump capture kernel.
Method (2) can only be used on architectures that support relocatable kernel; currently, i386, x86 ʄ, ppc64 and ia64 architectures support relocatable kernel. Building a relocatable kernel allows you to capture dumps without building a second kernel. But sometimes you may want to build a custom dump capture kernel to meet specific requirements.
How to access capture memory
All necessary information about the core image is encoded in ELF format and stored in the reserved memory area before the kernel crashes. The physical address of the elf header is passed as a command line parameter (fcorehdr =) to the newly started dump kernel.
On the i386 architecture, 640K of physical memory is required at startup, regardless of where the operating system kernel is reloaded. Therefore, the 640K area is backed up by kexec when the second kernel is restarted.
In the second kernel, the memory of the previous system can be accessed in two ways:
1. Through the device interface of / dev/oldmem.
A "capture" device can "read" the device file and write it out to the file using "raw" mode. This is a "raw" dump of memory, and these analysis / capture tools should be "smart" enough to know where to get the right information. ELF file headers (elfcorehdr passed through command line arguments) can be helpful.
2. Through / proc/vmcore.
This way is to output the dump to an ELF file, and use some file copy commands (such as cp, scp, etc.) to read out the information. At the same time, gdb can do some debugging (limited) on the dump file. This method ensures that all pages in memory are saved in the right way (note that 640K at the beginning of memory is remapped).
Advantages of kdump
high reliability
Crash dump data can be obtained from the context of a newly started kernel, rather than from the context of an already crashed kernel.
Multi version support
Lkcd (Linux kernel crash dump), netdump and diskdump have been included in LDPs (Linux documen station project) kernel. SUSE and RedHat both have technical support for kdump.
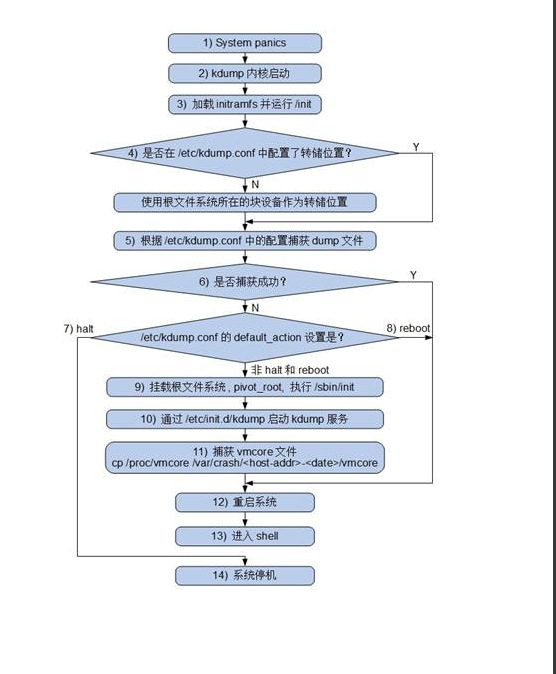
Kdump implementation process
RHEL6.2 execution process
Configure kdump
Install packages and utilities
The various tools used by kdump are in kexec tools. Kernel debuginfo is used to analyze vmcore files. Since rhel5, kexec tools has been installed in the distribution by default. novell also integrates kdump in the sles 10 release. So if you're using a release after rhel5 and sles10, you don't need to install kexec tools. If you need to debug the vmcore file generated by kdump, you need to install the kernel debuginfo package manually.
-
Check the operation of the installation package (note that the version of the installation package needs to be consistent with the kernel version number):
[root@localhost ~]# rpm -qa | grep kexec kexec-tools-2.0.7-50.el7.x86_64 [root@localhost ~]# uname -a Linux localhost.localdomain 3.10.0-514.el7.x86_64 #1 SMP Tue Nov 22 16:42:41 UTC 2016 x86_64 x86_64 x86_64 GNU/Linux [root@localhost ~]# rpm -qa 'kernel*debuginfo*' kernel-debuginfo-3.10.0-514.el7.x86_64 kernel-debuginfo-common-x86_64-3.10.0-514.el7.x86_64
The debuginfo package can be downloaded at http://debuginfo.centos.org/
Modify the kernel boot parameters to reserve memory for the boot capture kernel (after kexec tools is installed, the parameters will default)
Use the following method to configure the memory size used by kdump. Add the startup parameter "crashkernel=Y@X". Here, Y is the memory reserved for kdump to capture the kernel, and X is the starting position to reserve some memory.
For i386 and x86 ʄ, edit / etc/grub.conf and add "crashkernel=128M" at the end of the kernel line.
For ppc64, add "crashkernel=128M" at the end of / etc/yaboot.conf.
In ia64, edit / etc/elilo.conf and add "crashkernel=256M" to the kernel line.
kdump profile
The configuration file of kdump is / etc/kdump.conf (RHEL6.2); / etc/sysconfig/kdump(SLES11 sp2). Each file header has an option description, which can be set according to the use requirements.
Start kdump service
After setting the reserved memory, you need to restart the machine, otherwise kdump is not available. To start the kdump service:
[root@localhost ~]#systemctl restart kdump
Test whether the configuration is valid
You can load the kernel image through kexec, so that the system is ready to capture a vmcore generated in the event of a crash. You can force a system crash through sysrq.
[root@localhost~]# echo c > /proc/sysrq-trigger
This causes the kernel to crash. If the configuration is valid, the system will restart and enter the kdump kernel. When the system process enters the point where the kdump service is started, vmcore will be copied to the location you set in the kdump configuration file.
The default directory of RHEL is / var/crash; the default directory of SLES is / var/log/dump.
Then the system reboots into the normal kernel. Once you return to the normal kernel, you can find the vmcore file in the above directory, that is, the memory dump file.
You can use the crash tool in the previously installed kernel debuginfo for analysis (more detailed usage of crash will be covered later in this series).
[root@localhost~]# crash /usr/lib/debug/lib/modules/3.10.0-514.el7.x86_64/vmlinux/var/crash/127.0.0.1-2017-08-21-02\:31\:15/vmcore
crash
What is crash
As mentioned above, when the linux kernel crashes, you can collect the memory before the kernel crashes through kdump and other methods to generate a dump file vmcore. By analyzing the vmcore file, the kernel developer can diagnose the cause of kernel crash and improve the operating system code. So crash is a widely used kernel crash dump file analysis tool. Mastering the skills of crash plays an important role in locating problems.
Prerequisites for using crash
Because crash is used to debug the dump file of kernel crash, it depends on the following conditions:
1. The kernel image file vmlinux must specify the - g parameter when compiling, that is, with debugging information.
2. You need to have a memory crash dump file (such as vmcore), or real-time system memory that can be accessed through / dev/mem or / dev/crash. If the crash command line does not specify a dump file, crash uses real-time system memory by default, and root permission is required.
3. The platform processors supported by crash include: x86, x86_64, ia64, ppc64, arm, s390, s390x (some crash versions also support Alpha and 32-bit PowerPC, but the support of these two platforms does not guarantee long-term maintenance).
4.crash supports Linux kernel versions after 2.2.5-15 (included). With the update of Linux kernel, crash is also upgrading to adapt to the new kernel.
crash installation guide
To debug the kernel dump file using crash, you need to install crash tool and kernel debugging information package. The installation package names of different releases are slightly different. Here, only the installation package names corresponding to RHEL and SLES releases are listed as follows:
Table 1. crash tool and kernel debugging package
| System version | crash tool name | Kernel debugging information package |
|---|---|---|
| RHEL6.2 | crash | kernel-debuginfo-common kernel-debuginfo |
| SLES11SP2 | crash | kernel-default-debuginfo kernel-ppc64-debuginfo |
Taking RHEL as an example, the steps to install crash and kernel debugging information package are as follows:
[root@localhost ~]# rpm -ivh crash-7.1.5-2.el7.x86_64.rpm [root@localhost ~]# uname -a Linux localhost.localdomain 3.10.0-514.el7.x86_64 #1 SMP Tue Nov 22 16:42:41 UTC 2016 x86_64 x86_64 x86_64 GNU/Linux [root@localhost ~]# rpm -ivh kernel-debuginfo-common-x86_64-3.10.0-514.el7.x86_64.rpm [root@localhost ~]# rpm -ivh kernel-debuginfo-3.10.0-514.el7.x86_64.rpm
Start crash
Start parameter description
To debug a dump file using crash, you need to enter two parameters on the command line: debug kernel and dump file, where dump file is the name of the kernel dump file, and debug kernel is installed by the kernel debugging information package. The names of different distributions are slightly different. Take RHEL for example:
[root@localhost~]# crash /usr/lib/debug/lib/modules/3.10.0-514.el7.x86_64/vmlinux/var/crash/127.0.0.1-2017-08-21-02\:31\:15/vmcore
Using crash-h or man crash, you can view a series of options supported by crash. Here, just take the common options as an example:
-h: Print help
-d: Set debug level
-S: Use / boot/System.map as the default mapping file
-s: Do not display version, initial debugging information, etc., directly enter the command line
-ifile: automatically run the command in file after startup, and then accept user input
crash report analysis
After the crash command is started, an analysis report summary of the dump file will be generated, as shown in the following figure.
Listing 1. crash report
[root@hyhive ~]# crash /usr/lib/debug/lib/modules/3.10.0-514.el7.x86_64/vmlinux /var/crash/127.0.0.1-2017-07-21-17\:07\:17/vmcore crash 7.1.5-2.el7 Copyright (C) 2002-2016 Red Hat, Inc. Copyright (C) 2004, 2005, 2006, 2010 IBM Corporation Copyright (C) 1999-2006 Hewlett-Packard Co Copyright (C) 2005, 2006, 2011, 2012 Fujitsu Limited Copyright (C) 2006, 2007 VA Linux Systems Japan K.K. Copyright (C) 2005, 2011 NEC Corporation Copyright (C) 1999, 2002, 2007 Silicon Graphics, Inc. Copyright (C) 1999, 2000, 2001, 2002 Mission Critical Linux, Inc. This program is free software, covered by the GNU General Public License, and you are welcome to change it and/or distribute copies of it under certain conditions. Enter "help copying" to see the conditions. This program has absolutely no warranty. Enter "help warranty" for details. GNU gdb (GDB) 7.6 Copyright (C) 2013 Free Software Foundation, Inc. License GPLv3+: GNU GPL version 3 or later <http://gnu.org/licenses/gpl.html> This is free software: you are free to change and redistribute it. There is NO WARRANTY, to the extent permitted by law. Type "show copying" and "show warranty" for details. This GDB was configured as "x86_64-unknown-linux-gnu"... KERNEL: /usr/lib/debug/lib/modules/3.10.0-514.el7.x86_64/vmlinux DUMPFILE: /var/crash/127.0.0.1-2017-07-21-17:07:17/vmcore [PARTIAL DUMP] CPUS: 56 DATE: Fri Jul 21 17:07:00 2017 UPTIME: 8 days, 03:43:48 LOAD AVERAGE: 1.98, 1.73, 1.73 TASKS: 4444 NODENAME: hyhive RELEASE: 3.10.0-514.el7.x86_64 VERSION: #1 SMP Tue Nov 22 16:42:41 UTC 2016 MACHINE: x86_64 (2600 Mhz) MEMORY: 255.9 GB PANIC: "BUG: unable to handle kernel paging request at ffff8800fc14dfb0" PID: 21793 COMMAND: "sh" TASK: ffff883f97751f60 [THREAD_INFO: ffff8830e1b50000] CPU: 49 STATE: TASK_RUNNING (PANIC) crash>
kernel: the kernel file that runs when the system crashes
DUMPFILE: kernel dump file
CPUS: number of CPUS on the machine
DATE: time of system crash
TASKS: number of TASKS in memory at system crash
NODENAME: crashed system host name
RELEASE: and VERSION: kernel VERSION number
MACHINE:CPU architecture
MEMORY: physical MEMORY of crash host
PANIC: crash type. Common crash types include:
- SysRq(System Request): system crash caused by magic key combination, usually used for testing. With echo C > / proc / sysrq trigger, system crash can be triggered.
- Oops: it can be regarded as a kernel level Segmentation Fault. If the application program accesses the illegal memory or executes the illegal instruction, it will get Segfault signal. The general behavior is coredump. The application program can also intercept Segfault signal and process it by itself. If the kernel makes such a mistake, the oops message will pop up.
An introduction to crash built-in commands
After the crash command line is started, some built-in commands can be used to print the information before the system crashes.
bt -backtrace
bt command is used to view the stack information before system crash, which is a very common and easy command in system debugging.
crash> bt PID: 21793 TASK: ffff883f97751f60 CPU: 49 COMMAND: "sh" #0 [ffff8830e1b538e8] machine_kexec at ffffffff81059cdb #1 [ffff8830e1b53948] __crash_kexec at ffffffff81105182 #2 [ffff8830e1b53a18] crash_kexec at ffffffff81105270 #3 [ffff8830e1b53a30] oops_end at ffffffff8168ee88 #4 [ffff8830e1b53a58] no_context at ffffffff8167ea93 #5 [ffff8830e1b53aa8] __bad_area_nosemaphore at ffffffff8167eb29 #6 [ffff8830e1b53af0] bad_area_nosemaphore at ffffffff8167ec93 #7 [ffff8830e1b53b00] __do_page_fault at ffffffff81691c1e #8 [ffff8830e1b53b60] do_page_fault at ffffffff81691dc5 #9 [ffff8830e1b53b90] page_fault at ffffffff8168e088 [exception RIP: handle_mm_fault+319] RIP: ffffffff811b084f RSP: ffff8830e1b53c40 RFLAGS: 00010282 RAX: 00000000fc14d000 RBX: 00007ffefed4c150 RCX: 00003ffffffff000 RDX: ffff8800fc14dfb0 RSI: 000000000000000b RDI: 00000000fc14d000 RBP: ffff8830e1b53cc8 R8: ffff883f43635440 R9: 000000000000001d R10: 000000000000008f R11: 0000000000002941 R12: ffff883f43635440 R13: ffff8800fc14dfb0 R14: 0000000000000029 R15: ffff883ff7059f40 ORIG_RAX: ffffffffffffffff CS: 0010 SS: 0018 #10 [ffff8830e1b53cd0] __do_page_fault at ffffffff81691a94 #11 [ffff8830e1b53d30] do_page_fault at ffffffff81691dc5 #12 [ffff8830e1b53d60] page_fault at ffffffff8168e088 [exception RIP: __put_user_4+32] RIP: ffffffff81326b30 RSP: ffff8830e1b53e10 RFLAGS: 00050297 RAX: 0000000000000300 RBX: 00007fffffffeffd RCX: 00007ffefed4c150 RDX: ffff883ff73d3a80 RSI: 0000000000000300 RDI: ffff881185f95248 RBP: ffff8830e1b53e80 R8: ffff883f99e5f044 R9: 000000000000001d R10: 000000000000008f R11: 0000000000002941 R12: ffff883f8934edd0 R13: ffff8830e1b53ef8 R14: 0000000000005522 R15: 0000000000000000 ORIG_RAX: ffffffffffffffff CS: 0010 SS: 0018 #13 [ffff8830e1b53e10] wait_consider_task at ffffffff8108b102 #14 [ffff8830e1b53e88] do_wait at ffffffff8108b4c0 #15 [ffff8830e1b53ef0] sys_wait4 at ffffffff8108c6b0 #16 [ffff8830e1b53f80] system_call_fastpath at ffffffff816965c9 RIP: 00007f4210f9f27c RSP: 00007ffefed4bf30 RFLAGS: 00010246 RAX: 000000000000003d RBX: ffffffff816965c9 RCX: 0000ca6491781260 RDX: 0000000000000000 RSI: 00007ffefed4c150 RDI: ffffffffffffffff RBP: 0000000000e2e340 R8: 0000000000e2e340 R9: 0000000000000000 R10: 0000000000000000 R11: 0000000000000246 R12: 0000000000e2da90 R13: 0000000000000001 R14: 0000000000000000 R15: 0000000000000000 ORIG_RAX: 000000000000003d CS: 0033 SS: 002b
In the above output, the behavior call stack starting with "ා" is a series of functions that the kernel calls successively before the system crashes, through which we can quickly infer where the kernel crashes.
log -dump system message buffer
The log command prints the system message buffer, which may lead to a system crash.
crash> log [618639.865172] kvm [20669]: vcpu0 unhandled rdmsr: 0x611 [618639.865362] kvm [20669]: vcpu0 unhandled rdmsr: 0x639 [618639.865533] kvm [20669]: vcpu0 unhandled rdmsr: 0x641 [618639.865704] kvm [20669]: vcpu0 unhandled rdmsr: 0x619 [618639.868951] kvm [20669]: vcpu0 unhandled rdmsr: 0x60d [618698.976409] kvm: zapping shadow pages for mmio generation wraparound [618699.458405] kvm_get_msr_common: 6 callbacks suppressed [618699.458409] kvm [22064]: vcpu0 unhandled rdmsr: 0x1c9 [618699.458582] kvm [22064]: vcpu0 unhandled rdmsr: 0x1a6 [618699.458750] kvm [22064]: vcpu0 unhandled rdmsr: 0x1a7 [618699.458918] kvm [22064]: vcpu0 unhandled rdmsr: 0x3f6 [618699.525572] kvm [22064]: vcpu0 unhandled rdmsr: 0x606 [618700.003113] kvm [22064]: vcpu0 unhandled rdmsr: 0x611 [618700.003291] kvm [22064]: vcpu0 unhandled rdmsr: 0x639 [618700.003463] kvm [22064]: vcpu0 unhandled rdmsr: 0x641 [618700.003626] kvm [22064]: vcpu0 unhandled rdmsr: 0x619 [618700.005819] kvm [22064]: vcpu0 unhandled rdmsr: 0x60d [618759.027146] kvm: zapping shadow pages for mmio generation wraparound [618759.400453] kvm_get_msr_common: 6 callbacks suppressed
ps -display process status information
The ps command is used to display the status of the process (as shown in the figure) with the > mark to represent the active process.
crash> ps PID PPID CPU TASK ST %MEM VSZ RSS COMM > 0 0 0 ffffffff819c1460 RU 0.0 0 0 [swapper/0] > 0 0 1 ffff880173acaf10 RU 0.0 0 0 [swapper/1] > 0 0 2 ffff880173acbec0 RU 0.0 0 0 [swapper/2] > 0 0 3 ffff880173acce70 RU 0.0 0 0 [swapper/3] > 0 0 4 ffff880173acde20 RU 0.0 0 0 [swapper/4] > 0 0 5 ffff880173acedd0 RU 0.0 0 0 [swapper/5] > 0 0 6 ffff880173af0000 RU 0.0 0 0 [swapper/6] > 0 0 7 ffff880173af0fb0 RU 0.0 0 0 [swapper/7] > 0 0 8 ffff880173af1f60 RU 0.0 0 0 [swapper/8] > 0 0 9 ffff880173af2f10 RU 0.0 0 0 [swapper/9] > 0 0 10 ffff880173af3ec0 RU 0.0 0 0 [swapper/10] > 0 0 11 ffff880173af4e70 RU 0.0 0 0 [swapper/11] > 0 0 12 ffff880173af5e20 RU 0.0 0 0 [swapper/12] > 0 0 13 ffff880173af6dd0 RU 0.0 0 0 [swapper/13] > 0 0 14 ffff8820f3db0000 RU 0.0 0 0 [swapper/14] > 0 0 15 ffff8820f3db0fb0 RU 0.0 0 0 [swapper/15] > 0 0 16 ffff8820f3db1f60 RU 0.0 0 0 [swapper/16] > 0 0 17 ffff8820f3db2f10 RU 0.0 0 0 [swapper/17] > 0 0 18 ffff8820f3db3ec0 RU 0.0 0 0 [swapper/18] > 0 0 19 ffff8820f3db4e70 RU 0.0 0 0 [swapper/19] > 0 0 20 ffff8820f3db5e20 RU 0.0 0 0 [swapper/20] > 0 0 21 ffff8820f3db6dd0 RU 0.0 0 0 [swapper/21] > 0 0 22 ffff8820f3dd8000 RU 0.0 0 0 [swapper/22]
dis -disassembling instruction
The dis command is used to disassemble the contents of a given address.
crash> dis -l ffffffff8168e088 /usr/src/debug/kernel-3.10.0-514.el7/linux-3.10.0-514.el7.x86_64/arch/x86/kernel/entry_64.S: 1316 0xffffffff8168e088 <page_fault+40>: jmpq 0xffffffff8168e2c0 <error_exit>
struct– view data struct
The struct command is used to view the definition prototype of the data structure.
crash> struct -o vm_struct struct vm_struct { [0] struct vm_struct *next; [8] void *addr; [16] unsigned long size; [24] unsigned long flags; [32] struct page **pages; [40] unsigned int nr_pages; [48] phys_addr_t phys_addr; [56] const void *caller; } SIZE: 64
Case measurement
As mentioned above, when the linux kernel crashes, you can collect the memory before the kernel crashes through kdump and other methods to generate a dump file vmcore. By analyzing the vmcore file, the kernel developer can diagnose the cause of kernel crash and improve the operating system code. So crash is a widely used kernel crash dump file analysis tool. Mastering the skills of crash plays an important role in locating problems.
This paper uses the system crash problem found in the actual test work of CentOS system as a case to explain. The system has been configured with kdump enabled, so after the system crashes, a vmcore file is generated under the / var/crash / date / directory of the day. Let's analyze this file.
- Start crash first
[root@hyhive ~]# crash /usr/lib/debug/lib/modules/3.10.0-514.el7.x86_64/vmlinux /var/crash/127.0.0.1-2017-07-21-17\:07\:17/vmcore crash 7.1.5-2.el7 Copyright (C) 2002-2016 Red Hat, Inc. Copyright (C) 2004, 2005, 2006, 2010 IBM Corporation Copyright (C) 1999-2006 Hewlett-Packard Co Copyright (C) 2005, 2006, 2011, 2012 Fujitsu Limited Copyright (C) 2006, 2007 VA Linux Systems Japan K.K. Copyright (C) 2005, 2011 NEC Corporation Copyright (C) 1999, 2002, 2007 Silicon Graphics, Inc. Copyright (C) 1999, 2000, 2001, 2002 Mission Critical Linux, Inc. This program is free software, covered by the GNU General Public License, and you are welcome to change it and/or distribute copies of it under certain conditions. Enter "help copying" to see the conditions. This program has absolutely no warranty. Enter "help warranty" for details. GNU gdb (GDB) 7.6 Copyright (C) 2013 Free Software Foundation, Inc. License GPLv3+: GNU GPL version 3 or later <http://gnu.org/licenses/gpl.html> This is free software: you are free to change and redistribute it. There is NO WARRANTY, to the extent permitted by law. Type "show copying" and "show warranty" for details. This GDB was configured as "x86_64-unknown-linux-gnu"... KERNEL: /usr/lib/debug/lib/modules/3.10.0-514.el7.x86_64/vmlinux DUMPFILE: /var/crash/127.0.0.1-2017-07-21-17:07:17/vmcore [PARTIAL DUMP] CPUS: 56 DATE: Fri Jul 21 17:07:00 2017 UPTIME: 8 days, 03:43:48 LOAD AVERAGE: 1.98, 1.73, 1.73 TASKS: 4444 NODENAME: hyhive RELEASE: 3.10.0-514.el7.x86_64 VERSION: #1 SMP Tue Nov 22 16:42:41 UTC 2016 MACHINE: x86_64 (2600 Mhz) MEMORY: 255.9 GB PANIC: "BUG: unable to handle kernel paging request at ffff8800fc14dfb0" PID: 21793 COMMAND: "sh" TASK: ffff883f97751f60 [THREAD_INFO: ffff8830e1b50000] CPU: 49 STATE: TASK_RUNNING (PANIC) crash>
You can see that the kernel version is 3.10.0-514.el7.x86_, which is the development version of CentOS 7.3
- Look at the stack with the bt command
crash> bt PID: 21793 TASK: ffff883f97751f60 CPU: 49 COMMAND: "sh" #0 [ffff8830e1b538e8] machine_kexec at ffffffff81059cdb #1 [ffff8830e1b53948] __crash_kexec at ffffffff81105182 #2 [ffff8830e1b53a18] crash_kexec at ffffffff81105270 #3 [ffff8830e1b53a30] oops_end at ffffffff8168ee88 #4 [ffff8830e1b53a58] no_context at ffffffff8167ea93 #5 [ffff8830e1b53aa8] __bad_area_nosemaphore at ffffffff8167eb29 #6 [ffff8830e1b53af0] bad_area_nosemaphore at ffffffff8167ec93 #7 [ffff8830e1b53b00] __do_page_fault at ffffffff81691c1e #8 [ffff8830e1b53b60] do_page_fault at ffffffff81691dc5 #9 [ffff8830e1b53b90] page_fault at ffffffff8168e088 [exception RIP: handle_mm_fault+319] RIP: ffffffff811b084f RSP: ffff8830e1b53c40 RFLAGS: 00010282 RAX: 00000000fc14d000 RBX: 00007ffefed4c150 RCX: 00003ffffffff000 RDX: ffff8800fc14dfb0 RSI: 000000000000000b RDI: 00000000fc14d000 RBP: ffff8830e1b53cc8 R8: ffff883f43635440 R9: 000000000000001d R10: 000000000000008f R11: 0000000000002941 R12: ffff883f43635440 R13: ffff8800fc14dfb0 R14: 0000000000000029 R15: ffff883ff7059f40 ORIG_RAX: ffffffffffffffff CS: 0010 SS: 0018 #10 [ffff8830e1b53cd0] __do_page_fault at ffffffff81691a94 #11 [ffff8830e1b53d30] do_page_fault at ffffffff81691dc5 #12 [ffff8830e1b53d60] page_fault at ffffffff8168e088 [exception RIP: __put_user_4+32] RIP: ffffffff81326b30 RSP: ffff8830e1b53e10 RFLAGS: 00050297 RAX: 0000000000000300 RBX: 00007fffffffeffd RCX: 00007ffefed4c150 RDX: ffff883ff73d3a80 RSI: 0000000000000300 RDI: ffff881185f95248 RBP: ffff8830e1b53e80 R8: ffff883f99e5f044 R9: 000000000000001d R10: 000000000000008f R11: 0000000000002941 R12: ffff883f8934edd0 R13: ffff8830e1b53ef8 R14: 0000000000005522 R15: 0000000000000000 ORIG_RAX: ffffffffffffffff CS: 0010 SS: 0018 #13 [ffff8830e1b53e10] wait_consider_task at ffffffff8108b102 #14 [ffff8830e1b53e88] do_wait at ffffffff8108b4c0 #15 [ffff8830e1b53ef0] sys_wait4 at ffffffff8108c6b0 #16 [ffff8830e1b53f80] system_call_fastpath at ffffffff816965c9 RIP: 00007f4210f9f27c RSP: 00007ffefed4bf30 RFLAGS: 00010246 RAX: 000000000000003d RBX: ffffffff816965c9 RCX: 0000ca6491781260 RDX: 0000000000000000 RSI: 00007ffefed4c150 RDI: ffffffffffffffff RBP: 0000000000e2e340 R8: 0000000000e2e340 R9: 0000000000000000 R10: 0000000000000000 R11: 0000000000000246 R12: 0000000000e2da90 R13: 0000000000000001 R14: 0000000000000000 R15: 0000000000000000 ORIG_RAX: 000000000000003d CS: 0033 SS: 002b crash>
It can be seen that "[exception RIP: handle ﹐ mm ﹐ fault + 319]" appears after "﹐ 9 [ffff8830e1b53b90] page ﹐ fault at ffffff8168e088". At this time, there is a problem in the kernel. The ﹐ 9, ﹐ 0 to ﹐ 8 corresponding to the exception RIP are just routine operations after the system executes the code causing the panic, which is not helpful for understanding the panic.
RIP is the address of the currently executed instruction.
What you can see here is that: when the system calls handle mm fault() by executing the function of do page fault, panic occurs. The specific address is handle mm fault + 319
- Use the dis command to decompile the kernel function handle ﹣ mm ﹣ fault (the screenshot below)
crash> dis handle_mm_fault 0xffffffff811b0710 <handle_mm_fault>: nopl 0x0(%rax,%rax,1) [FTRACE NOP] 0xffffffff811b0715 <handle_mm_fault+5>: push %rbp 0xffffffff811b0716 <handle_mm_fault+6>: mov %rsp,%rbp 0xffffffff811b0719 <handle_mm_fault+9>: push %r15 0xffffffff811b071b <handle_mm_fault+11>: mov %rdi,%r15 0xffffffff811b071e <handle_mm_fault+14>: push %r14 0xffffffff811b0720 <handle_mm_fault+16>: mov %ecx,%r14d 0xffffffff811b0723 <handle_mm_fault+19>: push %r13 0xffffffff811b0725 <handle_mm_fault+21>: push %r12 0xffffffff811b0727 <handle_mm_fault+23>: mov %rsi,%r12 0xffffffff811b072a <handle_mm_fault+26>: push %rbx 0xffffffff811b072b <handle_mm_fault+27>: mov %rdx,%rbx 0xffffffff811b072e <handle_mm_fault+30>: sub $0x60,%rsp 0xffffffff811b0732 <handle_mm_fault+34>: mov %gs:0x28,%rax 0xffffffff811b073b <handle_mm_fault+43>: mov %rax,-0x30(%rbp) 0xffffffff811b073f <handle_mm_fault+47>: xor %eax,%eax 0xffffffff811b0741 <handle_mm_fault+49>: mov %gs:0xcdc0,%rax 0xffffffff811b074a <handle_mm_fault+58>: movq $0x0,(%rax) 0xffffffff811b0751 <handle_mm_fault+65>: mov 0x938c9d(%rip),%esi # 0xffffffff81ae93f4 <mem_cgroup_subsys+84> 0xffffffff811b0757 <handle_mm_fault+71>: incq %gs:0x11b78 0xffffffff811b0760 <handle_mm_fault+80>: test %esi,%esi 0xffffffff811b0762 <handle_mm_fault+82>: jne 0xffffffff811b076e <handle_mm_fault+94> 0xffffffff811b0764 <handle_mm_fault+84>: mov $0xb,%esi 0xffffffff811b0769 <handle_mm_fault+89>: callq 0xffffffff811eea80 <__mem_cgroup_count_vm_event> 0xffffffff811b076e <handle_mm_fault+94>: mov %gs:0xcdc0,%rax 0xffffffff811b0777 <handle_mm_fault+103>: mov 0x478(%rax),%edx 0xffffffff811b077d <handle_mm_fault+109>: lea 0x1(%rdx),%ecx 0xffffffff811b0780 <handle_mm_fault+112>: cmp $0x40,%edx 0xffffffff811b0783 <handle_mm_fault+115>: mov %ecx,0x478(%rax) 0xffffffff811b0789 <handle_mm_fault+121>: jg 0xffffffff811b14b7 <handle_mm_fault+3495> 0xffffffff811b078f <handle_mm_fault+127>: mov %r14d,%eax 0xffffffff811b0792 <handle_mm_fault+130>: and $0x80,%eax 0xffffffff811b0797 <handle_mm_fault+135>: mov %eax,-0x3c(%rbp) 0xffffffff811b079a <handle_mm_fault+138>: jne 0xffffffff811b0af0 <handle_mm_fault+992> 0xffffffff811b07a0 <handle_mm_fault+144>: testb $0x40,0x52(%r12) 0xffffffff811b07a6 <handle_mm_fault+150>: jne 0xffffffff811b149e <handle_mm_fault+3470> 0xffffffff811b07ac <handle_mm_fault+156>: mov %rbx,%r13 0xffffffff811b07af <handle_mm_fault+159>: shr $0x24,%r13 0xffffffff811b07b3 <handle_mm_fault+163>: and $0xff8,%r13d 0xffffffff811b07ba <handle_mm_fault+170>: add 0x58(%r15),%r13 0xffffffff811b07be <handle_mm_fault+174>: mov 0x0(%r13),%rdi 0xffffffff811b07c2 <handle_mm_fault+178>: test %rdi,%rdi 0xffffffff811b07c5 <handle_mm_fault+181>: je 0xffffffff811b14c8 <handle_mm_fault+3512> 0xffffffff811b07cb <handle_mm_fault+187>: mov %rdi,%rax 0xffffffff811b07ce <handle_mm_fault+190>: nopl 0x0(%rax) 0xffffffff811b07d2 <handle_mm_fault+194>: mov %rbx,%rdx 0xffffffff811b07d5 <handle_mm_fault+197>: movabs $0xffff880000000000,%rdi 0xffffffff811b07df <handle_mm_fault+207>: movabs $0x3ffffffff000,%rcx 0xffffffff811b07e9 <handle_mm_fault+217>: shr $0x1b,%rdx 0xffffffff811b07ed <handle_mm_fault+221>: and %rcx,%rax 0xffffffff811b07f0 <handle_mm_fault+224>: and $0xff8,%edx 0xffffffff811b07f6 <handle_mm_fault+230>: add %rdi,%rdx 0xffffffff811b07f9 <handle_mm_fault+233>: add %rax,%rdx 0xffffffff811b07fc <handle_mm_fault+236>: mov %rdx,%r13 0xffffffff811b07ff <handle_mm_fault+239>: je 0xffffffff811b0ae0 <handle_mm_fault+976> 0xffffffff811b0805 <handle_mm_fault+245>: mov (%rdx),%rdi 0xffffffff811b0808 <handle_mm_fault+248>: test $0xffffffffffffff9f,%rdi 0xffffffff811b080f <handle_mm_fault+255>: je 0xffffffff811b14e7 <handle_mm_fault+3543> 0xffffffff811b0815 <handle_mm_fault+261>: mov %rdi,%rax 0xffffffff811b0818 <handle_mm_fault+264>: nopl 0x0(%rax) 0xffffffff811b081c <handle_mm_fault+268>: mov %rbx,%rdx 0xffffffff811b081f <handle_mm_fault+271>: movabs $0xffff880000000000,%r13 0xffffffff811b0829 <handle_mm_fault+281>: movabs $0x3ffffffff000,%rcx 0xffffffff811b0833 <handle_mm_fault+291>: shr $0x12,%rdx 0xffffffff811b0837 <handle_mm_fault+295>: and %rcx,%rax 0xffffffff811b083a <handle_mm_fault+298>: and $0xff8,%edx 0xffffffff811b0840 <handle_mm_fault+304>: add %r13,%rdx 0xffffffff811b0843 <handle_mm_fault+307>: add %rax,%rdx 0xffffffff811b0846 <handle_mm_fault+310>: mov %rdx,%r13 0xffffffff811b084f <handle_mm_fault+319>: mov (%rdx),%rdi
You can see that mov% rdx and% r13 appear in + 319, which means that% rdx is assigned to% rdi, but you can see in + 310 that% rdx has been assigned to% r13, so it may be transferred to this line from another place, and% r13 may be invalid.
- corresponding
[exception RIP: handle_mm_fault+319] RIP: ffffffff811b084f RSP: ffff8830e1b53c40 RFLAGS: 00010282 RAX: 00000000fc14d000 RBX: 00007ffefed4c150 RCX: 00003ffffffff000 RDX: ffff8800fc14dfb0 RSI: 000000000000000b RDI: 00000000fc14d000 RBP: ffff8830e1b53cc8 R8: ffff883f43635440 R9: 000000000000001d R10: 000000000000008f R11: 0000000000002941 R12: ffff883f43635440 R13: ffff8800fc14dfb0 R14: 0000000000000029 R15: ffff883ff7059f40 ORIG_RAX: ffffffffffffffff CS: 0010 SS: 0018
You can see R13: ffff8800fc14dfb0, and check the contents of R13
crash> kmem ffff8800fc14dfb0 kmem: WARNING: cannot find mem_map page for address: ffff8800fc14dfb0
Or decompile with dis
crash> dis -l ffff8800fc14dfb0 dis: WARNING: ffff8800fc14dfb0: no associated kernel symbol found 0xffff8800fc14dfb0: dis: seek error: kernel virtual address: ffff8800fc14dfb0 type: "gdb_readmem_callback" Cannot access memory at address 0xffff8800fc14dfb0
The result shows that the value of the register cannot be queried in memory space. The specific reasons need to be further explored. The author's ability is limited. I will write here first, and then I will have ideas later.