Excerpt from C + + actual combat notes
Pre school encouragement
- Anyone can write code that machines can understand, but only good programmers can write code that people can understand.
- There are two ways to write programs: one is to write the code so complex that "no obvious errors can be seen"; The other is to write the code so simple that "there is no obvious error".
- It's much easier to "change the correct code quickly" than to "change the fast code correctly".
Pay attention to the "development landing" of language and library, and basically do not talk about grammar details and internal implementation principles. Instead, use examples to urge you to apply more natural and intuitive thinking mode of "modern C + +".
an introduction to
Lifecycle and programming paradigm
life cycle
A C + + program goes through several stages from "birth" to "death": Coding, Pre-processing, Compiling and Running.
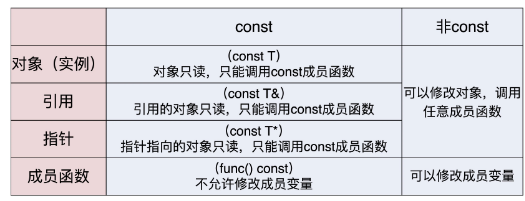
The coding stage is the starting point and the most important stage of the C + + program life cycle. It is the basis of the subsequent stages and directly determines the "quality of life" of the C + + program. Obviously, in the coding stage, we must follow some specifications instead of "writing blindly". The most basic requirement is to follow the language specifications and design documents. At a higher level, there are code specifications, annotation specifications, design patterns, programming idioms, and so on.
Preprocessing is a unique stage of C/C + + program, which is not available in other programming languages, which is also a feature of C/C + + language. At this stage, the pre processor plays a role. Its input is the source code file generated in the coding stage, and its output is the "preprocessed" source code file. The purpose of "preprocessing" is to replace words. We use various familiar preprocessing instructions, such as #include, #define, #if, to realize "preprocessing programming".
After preprocessing, the C + + program enters the compilation stage. More accurately, it should be "compilation" and "Linking". For simplicity, I uniformly call it "compilation".
- In the compilation stage, C + + programs - that is, the preprocessed source code - need to be "tempered" by the compiler and linker to generate binary machine code that can run on the computer. There is the most stress and complexity. The C + + compiler should segment words, parse syntax, generate object code, and optimize as much as possible.
- During compilation, the compiler will also check whether the syntax and semantics of the program are correct according to the C + + language rules. If an error is found, it will produce "compilation failure". This is the most basic C + + static check.
- When dealing with the source code, because the compiler checks the definitions of various types and functions according to C + + syntax, at this stage, we can program with the compiler as the goal and consciously control the behavior of the compiler. Here is a new term called "template meta programming". However, "template meta programming" is complex and difficult to understand. It belongs to a relatively advanced usage. I will talk about it briefly later.
- After the compilation stage, with the executable file, the C + + program can run and enter the running stage. At this time, the "static program" is loaded into memory and executed by the CPU one by one, forming a "dynamic process".
The operation phase is also the one we are most familiar with. At this stage, we often do GDB debugging, log tracking, performance analysis, etc., then collect dynamic data, adjust design ideas, and then return to the coding stage to revisit the "waterfall model" to realize the "spiral" development.
Programming paradigm
"Programming paradigm" is a kind of "methodology", which is some ideas, rules, habits, stereotypes and common words that guide you to write code.
Programming paradigms are different from programming languages. Some paradigms can only be used in a few specific languages, while others are suitable for most languages; Some languages may support only one paradigm, while others may support multiple paradigms.
Well, you must know or have heard that C + + is a multi paradigm programming language. Specifically, modern C + + (after 11 / 14) supports five main programming paradigms: "process oriented", "Object-Oriented", "generic", "template element" and "functional".
- Process oriented programming is the most basic programming paradigm in C + +. Its core idea is "command", which is usually the statement and subroutine (function) executed in sequence. The task is divided into several steps to execute, and finally achieve the goal. Procedure oriented is embodied in C + +, which is derived from its predecessor - the part of C language, such as variable declaration, expression, branch / loop / jump statement, and so on.
- Object oriented is another basic programming paradigm in C + +** Its core idea is "abstraction" and "encapsulation". It advocates decomposing the task into some highly cohesive and low coupling objects, which communicate and cooperate with each other to complete the task. It emphasizes the relationship and interface between objects, rather than the specific steps to complete the task** In C + +, object-oriented paradigm includes keywords related to classes such as class, public, private, virtual and this, as well as concepts such as constructor, destructor and friend function.
- Generic programming is a new paradigm that has gradually become popular since STL (Standard Template Library) was incorporated into C + + standard. The core idea of * * is "everything is type", or "parametric type" and "type erasure". The code is reused by using template rather than inheritance, so the operation efficiency is higher and the code is more concise** In C + +, the basis of generics is the template keyword, followed by a large and complex standard library, which contains various generic containers and algorithms, such as vector, map, sort, and so on.
- Similar to "generic programming" is template meta programming, which sounds very new. In fact, it has a history of more than ten years, but it is really "junior" compared with the first three paradigms** Its core idea is "type operation". The data of the operation is the "type" visible during compilation, so it is also special. The code can only be executed by the compiler, not by the CPU at run time** When talking about the compilation stage, I also said that template metaprogramming is an advanced and complex technology, and C + + language has less support for it. It is more used in the way of library, such as type_traits,enable_if et al.
- The last function, which is almost as old as "process oriented", has not entered the mainstream programming field until recent years** The so-called "functional formula" is not a subroutine written as a function in C + +, but a function in the mathematical sense without side effects. The core idea is "everything can be called", which realizes the processing of data through a series of continuous or nested function calls** There were a few attempts on functional expressions as early as C++98 (function objects such as bind1st/bind2nd), but it was not until the introduction of Lambda expression in C++11 that it really achieved the status of keeping pace with other paradigms.
Coding stage: Code Style
"Anyone can write code that machines can understand, but only good programmers can write code that people can understand."
- Write code like "writing poetry", using spaces and blank lines appropriately. Don't crowd many statements together in order to "save space" and "compact", but use spaces to separate variables and operators, and blank lines to separate code blocks, so as to maintain an appropriate reading rhythm.
- However, a generally accepted principle is that the length of variable / function name is directly proportional to its scope, that is, the local variable / function name can be shorter, while the global variable / function name should be longer.
- You may have noticed that I use English in the notes, because English (ASCII, or UTF-8) has the best "compatibility", which will not become unreadable garbled code due to operating system and coding problems, and can also exercise my English expression ability. However, writing notes in English also puts forward higher requirements for you. The most basic thing is not to make low-level grammar and spelling mistakes.
Preprocessing stage: macro definition and conditional compilation
The operation goal of programming in the preprocessing stage is "source code". Use various instructions to control the preprocessor and transform the source code into another form, just like pinching plasticine.
- First of all, preprocessing instructions begin with the symbol "#", which you should be familiar with. But at the same time, you should also realize that although it is all in one source file, it does not belong to C + + language. It takes the preprocessor and is not bound by C + + syntax rules. Therefore, preprocessing programming does not have to follow the style of C + + code.
- Generally speaking, preprocessing instructions should not be affected by the indentation level of C + + code. Whether in functions, classes, if, for and other statements, they are always written in the top grid.
- In addition, a single "#" is also a preprocessing instruction, called "empty instruction", which can be used as a special preprocessing empty line. There can also be spaces between "#" and subsequent instructions, so as to achieve indentation and facilitate typesetting.
General format of conditional compilation
# //Preprocessing blank lines #if __linux__ // Preprocessing checks whether the macro exists # define HAS_ Linux 1 / / macro definition with indentation #endif / / end of preprocessing condition statement # //Preprocessing blank lines
-
Include file (#include)
When writing header files, "Include Guard" is usually added to prevent code from being included repeatedly, that is, "#ifndef/#define/#endif" is used to protect the whole header file, as follows:
#ifndef _XXX_H_INCLUDED_ #define _XXX_H_INCLUDED_ ... // Header file content #endif // _XXX_H_INCLUDED_
You can also use the characteristics of "#include" to play some "tricks", write some code fragments, store them in "*. inc" files, and then load them selectively. If used well, you can realize "source level abstraction". For example, there is a large array for numerical calculation. There are hundreds of numbers in it. It takes up a lot of space in the file, which is particularly "eye-catching":
static uint32_t calc_table[] = { // A very large array with dozens of rows 0x00000000, 0x77073096, 0xee0e612c, 0x990951ba, 0x076dc419, 0x706af48f, 0xe963a535, 0x9e6495a3, 0x0edb8832, 0x79dcb8a4, 0xe0d5e91e, 0x97d2d988, 0x09b64c2b, 0x7eb17cbd, 0xe7b82d07, 0x90bf1d91, ... };At this time, you can pick it out separately, save it as a "*. inc" file, and then use "#include" to replace the original large number of numbers. This saves a lot of space and makes the code cleaner.
static uint32_t calc_table[] = { # include "calc_values.inc" / / a very large array with details hidden }; -
Macro definition (#define/#undef)
Note: be careful when using macros. Always remember to simplify the code and make it clear and easy to understand. Don't "abuse" to avoid confusion of the source code and reduce readability.
Advantages: the expansion and replacement of macros occur in the preprocessing stage, which does not involve function call, parameter transfer and pointer addressing, and there is no efficiency loss in the run-time. Therefore, for some small code fragments with frequent calls, the effect of encapsulation with macros is better than inline keyword, because it is really unconditional inlining at the source code level.
#define ngx_tolower(c) ((c >= 'A' && c <= 'Z') ? (c | 0x20) : c) #define ngx_toupper(c) ((c >= 'a' && c <= 'z') ? (c & ~0x20) : c) #define ngx_memzero(buf, n) (void) memset(buf, 0, n)
Secondly, you should know that macros have no scope concept and always take effect globally. Therefore, for some macros that are used to simplify code and play a temporary role, it is best to use "#undef" to cancel the definition as soon as possible after use, so as to avoid the risk of conflict. Like this:
#define CUBE(a) (a) * (a) * (a) / / define a simple cube macro cout << CUBE(10) << endl; // Simplify code with macros cout << CUBE(15) << endl; // Simplify code with macros #undef CUBE / / undefine immediately after use
-
Conditional compilation (#if/#else/#endif)
There are two key points in conditional compilation, one is the conditional instruction "#if", the other is the later "judgment basis", that is, all kinds of defined macros, and this "judgment basis" is the most critical part of conditional compilation.
Usually, the compilation environment will have some predefined macros, such as the special instruction set supported by the CPU, the version of the operating system / compiler / library, language features, etc. using them, you can make various optimizations in the preprocessing stage earlier than the running stage to produce the source code most suitable for the current system.
A macro you must know is "_cplusplus", which marks the version number of C + + language. It can be used to judge whether it is C or C + +, C++98 or C++11. You can see the following example
#ifdef __cplusplus / / defines this macro, which is compiled in C + + extern "C" { // Functions are handled in the way of C #endif void a_c_function(int a); #ifdef __cplusplus / / check whether it is compiled in C + + } // extern "C" end #endif #if __ Cplusplus > = 201402 / / check the version number of C + + standard cout << "c++14 or later" << endl; // 201402 is C++14 #elif __ Cplusplus > = 201103 / / check the version number of C + + standard cout << "c++11 or before" << endl; // 201103 is C++11 #else // __ Cplusplus < 201103 / / 199711 is C++98 # error "c++ is too old" / / if it is too low, the preprocessing will report an error #endif // __ Cplusplus > = 201402 / / end of preprocessing statementIn addition to "_ cplusplus", there are many other predefined macros in C + +, such as "FILE" "LINE" "DATE" of source FILE information, and some language feature test macros, such as "_ cpp_decltype" "_ cpp_decltype_auto" "_ cpp_lib_make_unique".
However, the underlying system information closely related to optimization is not defined in the C + + language standard, but the compiler usually provides it. For example, GCC can use a simple command to view:
g++ -E -dM - < /dev/null #define __GNUC__ 5 #define __unix__ 1 #define __x86_64__ 1 #define __UINT64_MAX__ 0xffffffffffffffffUL ...
Based on them, you can more finely change the source code according to the specific language, compiler and system characteristics. If there are, use new features; If not, it can be realized by means of modification:
#If defined (_cpp_decltype_auto) / / check whether decltype(auto) is supported cout << "decltype(auto) enable" << endl; #else cout << "decltype(auto) disable" << endl; #endif //__cpp_decltype_auto #if __GNUC__ <= 4 cout << "gcc is too old" << endl; #else // __GNUC__ > 4 cout << "gcc is good enough" << endl; #endif // __GNUC__ <= 4 #if defined(__SSE4_2__) && defined(__x86_64) cout << "we can do more optimization" << endl; #endif // defined(__SSE4_2__) && defined(__x86_64)
Compilation phase: attributes and static assertions
Compilation is the stage after preprocessing. Its input is (preprocessed) C + + source code and its output is binary executable file (or assembly file, dynamic library or static library). This processing action is executed by the compiler.
The particularity of the compilation stage is that it sees C + + syntax entities, such as typedef, using, template and struct/class, rather than run-time variables. Therefore, the programming thinking mode at this time is very different from that at ordinary times. We are familiar with CPU, memory and Socket, but it may be a little "difficult" to understand the operating mechanism of the compiler and know how to translate the source code into machine code.
Two easy to understand compilation stage skills
"Properties"
You can understand it as "labeling" variables, functions, classes, etc. at a compilation stage to facilitate the recognition and processing of the compiler. "Attribute" does not add new keywords, but in the form of two square brackets "[[...]]". In the middle of the square brackets is the attribute tag (looks like a square note).
The situation of C++14 is slightly better. A more practical attribute "deprecated" is added to mark variables, functions or classes that are not recommended, that is, they are "discarded". For example, you originally wrote a function old_func(), later felt that it was not good enough, so he rewritten a completely different new function. However, the old function has been released and used by many people. It is impossible to delete it immediately. What should I do? At this time, you can let the "attribute" exert its power. You can add a "deprecated" compile time label to the function and some descriptive text:
[[deprecated("deadline:2020-12-31")]] // C++14 or later
int old_func();
Therefore, any program that uses this function will see this label and give a warning when compiling:
warning: 'int old_func()' is deprecated: deadline:2020-12-31 [-Wdeprecated-declarations]
"Attribute" is like a "hint" and "notice" to the compiler. It cannot be calculated and is not programming. The next "static assertion" is a bit like writing a program at the compilation stage.
"Static assertion"
- static_assert is a "static assertion", which calculates constants and types at the compilation stage. If the assertion fails, it will lead to compilation errors. It is also the first step towards template metaprogramming.
- Like the "dynamic assertion" in the runtime, static_assert can define various preconditions in the compilation stage, make full use of the advantages of C + + static type language, and let the compiler perform various checks to avoid bringing hidden dangers to the running stage.
Object oriented programming: write a class
design idea
Although many languages have built-in syntax to support object-oriented programming, it is essentially a design idea and method, which has nothing to do with language details. The key points are Abstraction and Encapsulation.
The basic starting point of object-oriented programming is "simulation of the real world", which abstracts the entities in the problem and encapsulates them into classes and objects in the program, so as to establish a "virtual model" for real problems in the computer.
Then, based on this model, it continues to evolve, continue to abstract the relationship and communication between objects, and then use more objects to describe and simulate... Until finally, a system composed of many interrelated objects is formed. Designing and implementing this system with code is "Object-Oriented Programming".
However, because the real world is very complex, "Object-Oriented Programming" as an engineering method cannot be perfectly simulated. Pure object-oriented also has some defects, the most obvious of which is "inheritance".
The base class Bird has a Fly method, which should be inherited by all birds. But birds such as penguins and ostriches can't Fly. To realize them, they must rewrite the Fly method.
Various programming languages have added some "patches" for this. For example, C + + has "polymorphism", "virtual function" and "overloading". Although it solves the problem of "inheritance", it also complicates the code and distorts the original meaning of "Object-Oriented" to a certain extent.
Realization principle
The key points of "Object-Oriented Programming" are "abstraction" and "encapsulation", while "inheritance" and "polymorphism" are not the core and can only be regarded as additions. Therefore, I suggest you use inheritance and virtual functions as little as possible when designing classes.
In particular, if there is no inheritance relationship at all, the object can not bear the "burden of parents" (additional expenses such as parent members and virtual tables), and move forward with light weight, smaller and faster. No implicit reuse of code will also reduce the degree of coupling, making classes more independent and easier to understand.
If inheritance is necessary, I think we must control the level of inheritance and draw a schematic diagram of class system with UML to assist the inspection. If the inheritance depth exceeds three layers, it indicates that it is a little "over designed". We need to consider replacing the inheritance relationship with composite relationship, or using template and generic.
When designing the class interface, we should also make the class as simple as possible, "short and concise", and only be responsible for a single function. If many functions are mixed together and "universal class" and "spaghetti class" (sometimes called God Class) appear, it is necessary to apply the knowledge of design pattern and refactoring to split the large class into multiple sub classes with their respective responsibilities.
Coding criterion
C++11 adds a special identifier "final" (note that it is not a keyword). If it is used for class definition, inheritance can be explicitly disabled to prevent others from generating derived classes intentionally or unintentionally.
class DemoClass final // No one is allowed to inherit me
{ ... };
When inheritance must be used, it is recommended that you only use public inheritance and avoid using virtual and protected, because they will make the relationship between parent and child classes elusive and cause a lot of trouble. When reaching the bottom of the inheritance system, you should also use "final" in time to terminate the inheritance relationship
You must know the four functions of classes in C + +. They are constructor, destructor, copy constructor and copy assignment function. Because C++11 introduces Rvalue and Move, there are two more functions: transfer constructor and transfer assignment function.
Therefore, in modern C + +, a class always has six basic functions: three constructs, two assignments and one destructor. Fortunately, the C + + compiler will automatically generate the default implementation of these functions for us, saving us the time and energy of repeated writing. But I suggest that for more important constructors and destructors, we should use the form of "= Default" to clearly tell the compiler (and code readers): "this function should be implemented, but I don't want to write it myself." In this way, the compiler is given clear instructions and can be optimized better.
class DemoClass final
{
public:
DemoClass() = default; // Explicitly tell the compiler to use the default implementation
~DemoClass() = default; // Explicitly tell the compiler to use the default implementation
};
This "= default" is a new use of C++11 for the six basic functions. Similarly, there is a form of "= delete". It means that a function form is explicitly disabled, and it is not limited to construction / destruction. It can be used for any function (member function, free function). For example, if you want to prohibit object copying, you can use this syntax to explicitly assign "delete" to the copy structure and copy, so that the outside world cannot call it.
class DemoClass final
{
public:
DemoClass(const DemoClass&) = delete; // Prohibit copying construction
DemoClass& operator=(const DemoClass&) = delete; // Copy assignment prohibited
};
Because C + + has implicit construction and implicit transformation rules, if your class has a single parameter constructor or transformation operator function, in order to prevent accidental type conversion and ensure safety, you should use "explicit" to mark these functions as "explicit".
cclass DemoClass final
{
public:
explicit DemoClass(const string_type& str) // Explicit single parameter constructor
{ ... }
explicit operator bool() // Explicit transformation to bool
{ ... }
};
Common skills
The first is "delegating constructor".
In C++11, you can use the new feature of "delegate construction". One constructor directly calls another constructor to "delegate" the construction work, which is simple and efficient.
class DemoDelegating final
{
private:
int a; // Member variable
public:
DemoDelegating(int x) : a(x) // Basic constructor
{}
DemoDelegating() : // Parameterless constructor
DemoDelegating(0) // Give the default value and delegate to the first constructor
{}
DemoDelegating(const string& s) : // String parameter constructor
DemoDelegating(stoi(s)) // Convert to an integer and delegate to the first constructor
{}
};
The second is in class member initializer.
In C++11, you can assign a value to a variable while declaring it in a class to realize initialization, which is not only simple and clear, but also eliminates hidden dangers.
class DemoInit final // Class with many member variables
{
private:
int a = 0; // Integer member, assignment initialization
string s = "hello"; // String member, assignment initialization
vector<int> v{1, 2, 3}; // Container member, initialization list using curly braces
public:
DemoInit() = default; // Default constructor
~DemoInit() = default; // Default destructor
public:
DemoInit(int x) : a(x) {} // Members can be initialized separately, and others use default values
};
The third is Type Alias.
C++11 extends the usage of keyword using, increases the ability of typedef, and can define type aliases. Its format is just opposite to typedef. The alias is on the left and the original name is on the right. It is a standard assignment form, so it is easy to write and read.
using uint_t = unsigned int; // using alias typedef unsigned int uint_t; // Equivalent typedef
When writing classes, we often use many external types, such as string and vector in the standard library, as well as other third-party libraries and user-defined types. These names are usually very long (especially with namespace and template parameters), which is very inconvenient to write. At this time, we can alias them with using in the class, which not only simplifies the name, but also enhances readability.
class DemoClass final
{
public:
using this_type = DemoClass; // Give yourself an alias
using kafka_conf_type = KafkaConfig; // External class aliasing
public:
using string_type = std::string; // String type alias
using uint32_type = uint32_t; // Integer type alias
using set_type = std::set<int>; // Collection type alias
using vector_type = std::vector<std::string>;// Container type alias
private:
string_type m_name = "tom"; // Declare variables using type aliases
uint32_type m_age = 23; // Declare variables using type aliases
set_type m_books; // Declare variables using type aliases
private:
kafka_conf_type m_conf; // Declare variables using type aliases
};
Type alias can not only make the code standard and tidy, but also because of the introduction of this "syntax level macro definition", it can be changed to other types at will during maintenance in the future. For example, change the string to string_view (string read-only view in C++17), change the collection type to unordered_set, just change the alias definition, and the original code does not need to be changed.
Language characteristics
Automatic type derivation
- Because C + + is a statically strongly typed language, any variable must have a certain type, otherwise it cannot be used. Before the emergence of "automatic type derivation", we can only "manually deduce" when writing code, that is, when declaring variables, we must clearly give the type.
- It's OK to say this when variable types are simple, such as int and double, but in generic programming, trouble comes. Because there are many template parameters, some types and internal subtypes in generic programming, it immediately complicates the original concise type system of C + +, which forces us to "fight wits and courage" with the compiler. Only when we write the right type, the compiler will "release" (compile and pass).
auto
int i = 0; // Integer variable, the type is easy to know
double x = 1.0; // Floating point variable, the type is easy to know
std::string str = "hello"; // String variables, with a namespace, are a little troublesome
std::map<int, std::string> m = // Associative array, namespace plus template parameters, very troublesome
{{1,"a"}, {2,"b"}}; // Use the form of initialization list
std::map<int, std::string>::const_iterator // Internal subtype, super troublesome
iter = m.begin();
??? = bind1st(std::less<int>(), 2); // I can't write it at all
Although you can use typedef or using to simplify the type name and partially reduce the burden of typing, the key problem of "manual derivation" has not been solved. You still have to look at the type definition and find the correct declaration. At this time, the advantage of static strong type of C + + has become a disadvantage, which hinders the work of programmers and reduces the development efficiency.
But with "automatic type derivation", the problem is solved. This is like opening a small hole in the closed door of the compiler. When you tell it, it will hand over a small note. It doesn't matter what it is. What matters is that it contains the type we want.
This "small hole" is the keyword auto, which acts like a "placeholder" in the code. By writing it, you can let the compiler automatically "fill in" the correct type, which is both labor-saving and worry-saving.
auto i = 0; // Automatically deduce to int type
auto x = 1.0; // Automatically deduce to double type
auto str = "hello"; // Automatically deduce to const char [6] type
std::map<int, std::string> m = {{1,"a"}, {2,"b"}}; // It can't be deduced automatically
auto iter = m.begin(); // Automatically deduce to the iterator type inside the map
auto f = bind1st(std::less<int>(), 2); // Automatically deduce the type. I don't know what it is
In addition to simplifying the code, auto also avoids the "hard coding" of types, that is, variable types are not "dead", but can "automatically" adapt to the type of expression. For example, you change the map to unordered_map, then the following code doesn't need to be moved. This effect is a bit similar to the type alias (Lecture 5), but you don't need to write typedef or using. It's all "done by auto". In addition, you should also realize that "automatic type derivation" is actually the same as "attribute" (Lecture 4). It is a special instruction in the compilation stage, which instructs the compiler to calculate types. Therefore, it has more uses in generic programming and template metaprogramming, which I will talk about later.
There is a special case. When initializing class member variables (Lecture 5), the current C + + standard does not allow the use of auto derivation types (but I personally don't think it's necessary. Maybe I'll let it go in the future). Therefore, in the class, you still have to honestly "manually deduce types".
class X final
{
auto a = 10; // Error, auto derivation type cannot be used in class
};
- auto always deduces "value type", never "reference";
- auto can add type modifiers such as const, volatile, *, & to get a new type.
auto x = 10L; // auto is derived as long, and x is long auto& x1 = x; // auto is derived as long and x1 is long& auto* x2 = &x; // auto is derived as long and x2 is long* const auto& x3 = x; // auto is derived as long and x3 is const long& auto x4 = &x3; // auto is deduced as const long *, and x4 is const long **
decltype
"Automatic type derivation" requires that it must be derived from an expression. What should I do when there is no expression? In fact, the solution is also very simple, that is, "do it yourself, have plenty of food and clothing", and bring your own expression, so you won't be afraid to go anywhere.
decltype is in the form of a function. In the parentheses behind it is the expression that can be used to calculate the type (similar to sizeof). Other aspects are the same as auto. const, *, & can also be added to modify it. However, because it has its own expression, there is no need for an expression after the variable, that is, the variable can be declared directly
int x = 0; // Integer variable decltype(x) x1; // Derived as int, x1 is int decltype(x)& x2 = x; // The derivation is int, x2 is int &, and the reference must be assigned decltype(x)* x3; // Derived as int, x3 is int* decltype(&x) x4; // Derived as int *, x4 is int* decltype(&x)* x5; // Derived as int *, x5 is int** decltype(x2) x6 = x2; // The derivation is int&, x6 is int&, and the reference must be assigned
decltype can deduce not only the value type, but also the reference type, that is, the "original type" of the expression.
In the s amp le code, we can see that in addition to adding * and & modifiers, decltype can also directly deduce the reference type from the variable of a reference type, while auto will remove the reference and deduce the value type. Therefore, you can completely regard decltype as a real type name, which can be used where any type can appear, such as variable declaration, function parameter / return value, template parameter, etc., but this type is "calculated" by expression at the compilation stage.
using int_ptr = decltype(&x); // int * using int_ref = decltype(x)&; // int &
The form of "decltype(auto)" can not only accurately deduce the type, but also be as convenient as auto.
int x = 0; // Integer variable decltype(auto) x1 = (x); // Derived as int &, because (expr) is a reference type decltype(auto) x2 = &x; // Derived as int* decltype(auto) x3 = x1; // Derived as int&
Use auto/decltype
Another "best practice" of auto is "range based for", which can easily complete the traversal operation without caring about the container element type, iterator return value and head and end position. However, in order to ensure efficiency, it is best to use "const Auto &" or "auto &".
vector<int> v = {2,3,5,7,11}; // vector sequence container
for(const auto& i : v) { // Often access elements by reference to avoid the cost of copying
cout << i << ","; // Constant references do not change the value of an element
}
for(auto& i : v) { // Access elements by reference
i++; // You can change the value of an element
cout << i << ",";
}
const/volatile/mutable
const meaning
const int MAX_LEN = 1024; const std::string NAME = "metroid";
From the perspective of C + + program life cycle, we will find that it is essentially different from macro definition:
- const defined constants do not exist in the preprocessing phase, but do not appear until the run phase.
- Therefore, to be exact, it is actually a "variable" at runtime, but it is not allowed to be modified. It is "read only", which is more suitable to be called "read only variable".
- Since it is a "variable", it is also possible to use the pointer to obtain the address and then "force" writing. However, this practice destroys the "constancy" and is absolutely not advocated. Here, I'm just doing a demonstration experiment for you, and I need another keyword volatile.
// You need to add volatile decoration to see the effect at run time const volatile int MAX_LEN = 1024; auto ptr = (int*)(&MAX_LEN); *ptr = 2048; cout << MAX_LEN << endl; // Output 2048
reason:
-
const constant is not a "real constant", but in most cases, it can be regarded as a constant and will not change during operation.
-
When the compiler sees the const definition, it will take some optimization measures, such as replacing all the places where const constants appear with the original value.
-
Therefore, for const constants without volatile modification, although you change the value of the constant with a pointer, this value is not used at all in the run-time, because it is optimized in the compilation stage.
-
Role of volatile
Its meaning is "unstable" and "changeable". In C + +, the value of the variable may be modified in an "imperceptible" way (such as operating system signals and other external codes). Therefore, to prohibit the compiler from doing any form of optimization, the value must be taken "honestly" every time it is used.
MAX_ Although len is a "read-only variable", the volatile modification indicates that it is unstable and may change quietly. When generating binary machine code, the compiler will not do the optimization that may have side effects, but use Max in the most "conservative" way_ LEN.
In other words, the compiler will no longer put MAX_LEN is replaced with 1024, but the value is taken from memory (which has been forcibly modified through the pointer). Therefore, the final output of this code is 2048, not the original 1024.
Basic const usage:
-
Const & is called universal reference, that is, it can refer to any type, that is, whether it is a value, pointer, left reference or right reference, it can "collect all according to the order".
- It also adds const to the variable, so that the "variable" becomes a "constant", which can only be read and written. The compiler will help you check all writes to it and issue warnings to prevent intentional or unintentional modifications during the compilation phase.
- When designing a function, try to use it as an entry parameter to ensure efficiency and safety.
-
Const for pointers is a little more complicated. A common usage is that const is placed on the far left of the declaration, indicating a pointer to a constant. In fact, it is easy to understand that the pointer points to a "read-only variable", which cannot be modified:
string name = "uncharted"; const string* ps1 = &name; // Pointing constant *ps1 = "spiderman"; // Error, modification not allowed
Another "disgusting" usage is that const is on the right of "*", indicating that the pointer cannot be modified, and the pointed variable can be modified:
string* const ps2 = &name; // Points to a variable, but the pointer itself cannot be modified *ps2 = "spiderman"; // Correct, modification allowed
Class related const usage
-
const member function
class DemoClass final { private: const long MAX_SIZE = 256; // const member variable int m_value; // Member variable public: int get_value() const // const member function { return m_value; } };The use of const here is a little special. It is placed after the function, indicating that the function is a "constant". (if it is in the front, it means that the return value is const int)
Its real meaning is that the execution process of the function is const, and the state of the object (i.e. member variables) will not be modified. In other words, the member function is a "read-only operation".
-
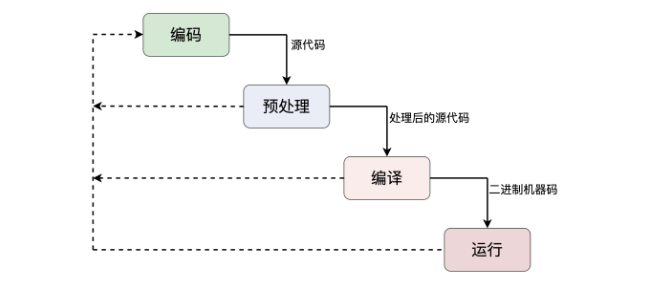
Usage rules for constant references, constant pointers and constant functions
Keyword mutable
-
The literal meaning of mutable and volatile is a bit similar, but the usage and effect are quite different. Volatile can be used to modify any variable, while mutable can only modify the member variables in the class, indicating that variables can be modified even in const objects.
-
mutable is like a "patch" made by C + + to const object to make it partially variable. Because the object is different from ordinary int and double, there will be many internal member variables to represent the state, but because of the "encapsulation" feature, the outside world can only see part of the state. Whether the object const should be determined by these externally observable state characteristics.
-
For these member variables with special functions, you can add mutable modification to them to remove the restriction of const, so that any member function can operate it.
class DemoClass final { private: mutable mutex_type m_mutex; // mutable member variable public: void save_data() const // const member function { // do someting with m_mutex } };
smart_pr smart pointer
-
In this way, when the object is invalid and destroyed, C + + will automatically call the destructor to complete the cleaning work such as memory release and resource recovery. Compared with Java and Go, this is a "micro" garbage collection mechanism, and the timing of recycling is completely "autonomous and controllable", which is very flexible. Of course, there is a price - you have to write the packaging code for each resource, which is tired and troublesome.
-
Smart pointer is to do these "dirty and tiring work" instead of you. As like as two peas, the RAII is completely wrapped up with bare pointer, and it is used as a new pointer to override the * and > operators. Moreover, it also comprehensively considers many real application scenarios, and can automatically adapt to various complex situations and prevent hidden dangers caused by misuse of pointers. It is very "smart", so it is called "smart pointer".
unique_ptr
unique_ptr is the simplest and easiest to use smart pointer. When declaring, you must specify the type with template parameters
unique_ptr<int> ptr1(new int(10)); // int smart pointer
assert(*ptr1 == 10); // You can use * to retrieve content
assert(ptr1 != nullptr); // You can determine whether it is a null pointer
unique_ptr<string> ptr2(new string("hello")); // string smart pointer
assert(*ptr2 == "hello"); // You can use * to retrieve content
assert(ptr2->size() == 5); // You can use - > to call member functions
-
unique_ptr is not actually a pointer, but an object. Therefore, do not attempt to call delete on it. It will automatically manage the pointer during initialization and destruct to free memory when leaving the scope.
-
It also does not define addition and subtraction operations, and cannot move the pointer address at will, which completely avoids dangerous operations such as pointer crossing, and makes the code safer:
ptr1++; // Cause compilation errors ptr2 += 2; // Cause compilation errors
-
To avoid this low-level error (directly manipulating null pointers and assigning values), you can call the factory function make_unique(), which forces initialization when creating a smart pointer. At the same time, you can also use auto of automatic type derivation (Lecture 6) to write less code:
auto ptr3 = make_unique<int>(42); // Factory functions create smart pointers assert(ptr3 && *ptr3 == 42); auto ptr4 = make_unique<string>("god of war"); // Factory functions create smart pointers assert(!ptr4->empty()); -
make_unique() requires C++14, but its principle is relatively simple. If you are using C++11, you can also implement a simplified version of make yourself_ Unique (), you can refer to the following code:
template<class T, class... Args> // Variable parameter template std::unique_ptr<T> // Return smart pointer my_make_unique(Args&&... args) // Entry parameters of variable parameter template { return std::unique_ptr<T>( // Construct smart pointer new T(std::forward<Args>(args)...)); // Perfect forwarding } -
unique_ Ownership of PTR
Just like its name, it means that the ownership of the pointer is "unique" and cannot be shared. Only one "person" can hold it at any time.
To achieve this, unique_ptr applies the "move" semantics of C + + and prohibits copy assignment. Therefore, it is transferring to another unique_ When assigning PTR, you should pay special attention to the fact that the ownership transfer must be explicitly declared with the std::move() function. After the assignment operation, the ownership of the pointer is transferred, and the original unique_ptr becomes null pointer, new unique_ptr takes over the management right and ensures the uniqueness of ownership:auto ptr1 = make_unique<int>(42); // Factory functions create smart pointers assert(ptr1 && *ptr1 == 42); // At this time, the smart pointer is valid auto ptr2 = std::move(ptr1); // Use move() to transfer ownership assert(!ptr1 && ptr2); // ptr1 becomes a null pointer
Try not to be unique_ It's good for PTR to perform the assignment operation. Let it "live and die" and fully automate the management.
shared_ptr
Than unique_ptr more "intelligent" smart pointer
-
Similarities: how to create and use
shared_ptr<int> ptr1(new int(10)); // int smart pointer assert(*ptr1 = 10); // You can use * to retrieve content shared_ptr<string> ptr2(new string("hello")); // string smart pointer assert(*ptr2 == "hello"); // You can use * to retrieve content auto ptr3 = make_shared<int>(42); // Factory functions create smart pointers assert(ptr3 && *ptr3 == 42); // You can determine whether it is a null pointer auto ptr4 = make_shared<string>("zelda"); // Factory functions create smart pointers assert(!ptr4->empty()); // You can use - > to call member functions -
difference
Its ownership can be safely shared, that is, it supports copy assignment and can be held by multiple "people" at the same time, just like the original pointer.auto ptr1 = make_shared<int>(42); // Factory functions create smart pointers assert(ptr1 && ptr1.unique() ); // At this time, the smart pointer is valid and unique auto ptr2 = ptr1; // Direct copy assignment, no need to use move() assert(ptr1 && ptr2); // At this time, both smart pointers are valid assert(ptr1 == ptr2); // shared_ptr can be compared directly // Both smart pointers are not unique and the reference count is 2 assert(!ptr1.unique() && ptr1.use_count() == 2); assert(!ptr2.unique() && ptr2.use_count() == 2);
-
shared_ptr sharing principle
- shared_ The secret of PTR supporting secure sharing lies in the internal use of "reference counting". The reference count starts with 1, which means there is only one holder.
- In case of copy assignment - that is, sharing, the reference count increases, and in case of destruction, the reference count decreases. Only when the reference count is reduced to 0, that is, no one uses this pointer, will it really call delete to free memory.
- Because shared_ptr has complete "value semantics" (that is, it can copy and assign values), so it can replace the original pointer in any situation without worrying about resource recovery, such as storing pointers in containers, safely returning dynamically created objects in functions, and so on.
-
shared_ Precautions for PTR:
-
shared_ptr is very "smart", but there is no free lunch in the world. It also comes at a price. The storage and management of reference counts are costs. This aspect is shared_ptr is not as unique as_ PTR. Overuse of shared_ptr will reduce the operation efficiency. But you don't have to worry too much, shared_ptr has good internal optimization. In non extreme cases, its overhead is very small.
-
You should be very careful about the destructor of the object, and do not have very complex and severely blocked operations. Once shared_ptr destructs and releases resources at an uncertain time point, which will block the whole process or thread, "and the whole world will stand still" (maybe students who have used Go will deeply experience it).
class DemoShared final // Dangerous category, irregular mine { public: DemoShared() = default; ~DemoShared() // Complex operations can lead to shared_ The world stands still during PTR deconstruction { // Stop The World ... } }; -
shared_ The reference count of PTR also leads to a new problem, which is "circular reference", which puts shared_ptr is most likely to appear when it is a class member. A typical example is the linked list node.
class Node final { public: using this_type = Node; using shared_type = std::shared_ptr<this_type>; public: shared_type next; // Use a smart pointer to point to the next node }; auto n1 = make_shared<Node>(); // Factory functions create smart pointers auto n2 = make_shared<Node>(); // Factory functions create smart pointers assert(n1.use_count() == 1); // Reference count is 1 assert(n2.use_count() == 1); n1->next = n2; // The two nodes refer to each other, forming a circular reference n2->next = n1; assert(n1.use_count() == 2); // The reference count is 2 assert(n2.use_count() == 2); // It cannot be reduced to 0 and cannot be destroyed, resulting in memory leakageHere, when two node pointers are first created, the reference count is 1, but after pointers refer to each other (i.e. copy assignment), the reference count becomes 2. At this time, shared_ptr is "stupid". It doesn't realize that this is a circular reference. It counts one more time. As a result, the reference count cannot be reduced to 0 and the destructor cannot be called to delete, resulting in memory leakage.
-
If you want to fundamentally eliminate circular references, just rely on shared_ptr doesn't work. We must use its "little helper": weak_ptr. weak_ptr, as its name suggests, is very "weak". It is specially designed to break the circular reference. It only observes the pointer and does not increase the reference count (weak reference). However, when necessary, you can call the member function lock() to get shared_ptr (strong reference). In the example just now, as long as you use weak instead_ PTR, the trouble of circular reference will disappear:
class Node final { public: using this_type = Node; // Note here that the alias is changed to weak_ptr using shared_type = std::weak_ptr<this_type>; public: shared_type next; // Because the alias is used, the code does not need to be changed }; auto n1 = make_shared<Node>(); // Factory functions create smart pointers auto n2 = make_shared<Node>(); // Factory functions create smart pointers n1->next = n2; // The two nodes refer to each other, forming a circular reference n2->next = n1; assert(n1.use_count() == 1); // Because of the use of weak_ptr, reference count is 1 assert(n2.use_count() == 1); // Breaking the circular reference will not lead to memory leakage if (!n1->next.expired()) { // Check whether the pointer is valid auto ptr = n1->next.lock(); // lock() get shared_ptr assert(ptr == n2); }I have another important suggestion: now that you understand smart pointers, try not to use bare pointers, new and delete to operate memory. If you strictly follow this advice, make good use of unique_ptr,shared_ptr, then, your program is unlikely to have memory leakage, you don't need to bother to study and use memory debugging tools such as valgrind, and life will be a little "better".
-
Use of exceptions
Exception, which can be understood as "different from normal", refers to some special situations and serious errors outside the normal process. Once such an error is encountered, the program will jump out of the normal process, and it is even difficult to continue to execute. In the final analysis, exceptions are only a solution proposed by C + + to deal with errors. Of course, they will not be the only one.
Before C + +, the basic means of handling exceptions was "error code". After the function is executed, check the return value or global errno to see if it is normal. If there is an error, execute another section of code to deal with the error:
int n = read_data(fd, ...); // Read data
if (n == 0) {
... // The return value is not correct. Handle it appropriately
}
if (errno == EAGAIN) {
... // Handle errors appropriately
}
- This approach is very intuitive, but there is also a problem, that is, the normal business logic code and error handling code are mixed together, which looks very messy. Your mind should jump back and forth in two unrelated processes.
- Error codes have another bigger problem: they can be ignored. In other words, you can not deal with errors, "pretend" that the program is running normally and continue to run the following code, which may lead to serious security risks.
"There is no harm without comparison". Now you should understand that as a new error handling method, exceptions are designed for the defects of error codes. It has three characteristics.
- The exception handling process is completely independent. After throw ing an exception, you can ignore it. The error handling code is concentrated in a special catch block. In this way, business logic and error logic are completely separated, which looks clearer.
- Exceptions must not be ignored and must be handled. If you intentionally or unintentionally do not write catch exceptions, it will propagate upward until you find a catch block that can be handled. If there is no, it will cause the program to stop running immediately, clearly prompt you that an error has occurred, and will not "insist on working with a disease".
- Exceptions can be used when error codes cannot be used, which is also a "personal reason" for C + +. Because it has more new features such as constructor / destructor and operator overloading than C language, some functions have no return value at all, or the return value cannot represent an error, and the global errno is really "too inelegant", which is inconsistent with the concept of C + +, so exceptions must also be used to report errors.
C + + has designed a supporting exception type system for handling exceptions, which is defined in the header file of the standard library.
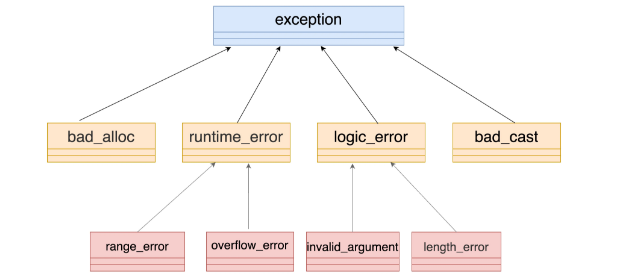
As I said in lesson 5, if the inheritance depth exceeds three layers, it means that it is a little "over designed". It is obvious that there is this trend now. Therefore, I suggest that you'd better choose a type of the first or second layer above as the base class, and don't deepen the level. For example, you can start from runtime_error derives its own exception class:
class my_exception : public std::runtime_error
{
public:
using this_type = my_exception; // Give yourself an alias
using super_type = std::runtime_error; // Alias the parent class as well
public:
my_exception(const char* msg): // Constructor
super_type(msg) // Aliases can also be used to construct
{}
my_exception() = default; // Default constructor
~my_exception() = default; // Default destructor
private:
int code = 0; // Other internal private data
};
When throwing an exception, I suggest you better not use the throw keyword directly, but encapsulate it into a function. This is similar to not using the new and delete keywords directly - you can get more readability, security and flexibility by introducing an "intermediate layer". The function throwing exceptions will not have a return value, so you should use the "properties" in lesson 4 for compilation stage optimization:
[[noreturn]] // Attribute label
int func(bool flag) // The function never returns any value
{
throw std::runtime_error("XXX");
}
Precautions for catch block:
C + + allows you to write multiple catch blocks, catch different exceptions, and then handle them separately. However, exceptions can only be matched in the order of catch blocks in the code, not the best match. This feature causes a bit of trouble in actual development, especially when the exception type system is complex, it may enter the catch block you didn't want to enter because of the wrong order.
Therefore, I suggest you use only one catch block to bypass this "pit". Writing a catch block is like writing a standard function, so the entry parameter should also be in the form of "const &" to avoid the cost of object copy:
try
{
raise("error occured"); // The function encapsulates throw and throws an exception
}
catch(const exception& e) // Const & to catch exceptions, you can use the base class
{
cout << e.what() << endl; // what() is the virtual function of exception
}
lambda: functional programming
Standard library
character string
string
-
String is not a "real type", but a template class basic_ The specialized form of string is a typedef:
using string = std::basic_string<char>; // string is actually a type alias
When it comes to characters and encoding, we can't help mentioning Unicode. Its goal is to use a unified encoding method to deal with human language and characters, and use 32 bits (4 bytes) to ensure that it can accommodate all the words in the past or in the future. But this conflicts with C + +. Because the string of C + + comes from C, and the characters in C are single byte char types, Unicode cannot be supported. In order to solve this problem, C + + adds several character types.
Therefore, I also suggest you only use string, and try not to use C + + when it comes to Unicode and encoding conversion. At present, it is not very good at doing this kind of work, and it may be better to use other languages. Next, I'll talk about how to use string well.
-
String is a string class with complete functions. It can extract substrings, compare sizes, check lengths, search characters... It basically meets the "imagination" of ordinary people on strings.
string str = "abc"; assert(str.length() == 3); assert(str < "xyz"); assert(str.substr(0, 1) == "a"); assert(str[1] == 'b'); assert(str.find("1") == string::npos); assert(str + "d" == "abcd"); -
Treat each string as an immutable entity, so that you can really make good use of strings in C + +. But sometimes, we do need containers for storing characters, such as byte sequences and data buffers. What should we do? At this time, I suggest you use vector instead. Its meaning is very "pure". It only stores characters without the unnecessary cost of string, so it is more flexible to use.
-
Literal suffix
To facilitate the use of strings, C++14 adds a literal suffix "s", which clearly indicates that it is a string string type, rather than a C string. Therefore, auto can be used for automatic type derivation. Moreover, in other places where strings are used, the trouble of specifying temporary string variables can also be saved and the efficiency will be higher:
using namespace std::literals::string_literals; //Namespace must be opened auto str = "std string"s; // Suffix s indicates that it is a standard string and is derived directly from the type assert("time"s.size() == 4); // The standard string can call member functions directlyIn order to avoid the conflict with the user-defined literal quantity, the suffix "s" cannot be used directly. You must open the namespace with using, which is a small disadvantage of it.
-
Original string
C++11 also adds a new representation of "Raw string literal" to the literal quantity, with an uppercase letter R and a pair of parentheses more than the original quotation marks, as follows:
auto str = R"(nier:automata)"; // Original string: nier:automata
Especially when using regular expression, because it also has escape, the two escape effects "multiply", it is easy to make mistakes. For example, if I want to express "$" in regular, I need to write "\ $", while in C + +, I need to escape "\" again, that is "\ \ $".
If the original string is used, there will be no such trouble. It will not escape the contents of the string and completely maintain the "original style", even if there are more special characters in itauto str1 = R"(char""'')"; // Output as is: char '' auto str2 = R"(\r\n\t\")"; // Output as is: \ r\n\t\“ auto str3 = R"(\\\$)"; // Output as is:\$ auto str4 = "\\\\\\$"; // Output after escape:\$
-
String conversion function
C++11 adds several new conversion functions:
- stoi(), stol(), stoll(), etc. convert strings into integers;
- stof(), stod(), etc. convert strings into floating-point numbers;
- to_string() converts integers and floating-point numbers into strings.
assert(stoi("42") == 42); // String to integer assert(stol("253") == 253L); // String to length integer assert(stod("2.0") == 2.0); // String to floating point number assert(to_string(1984) == "1984"); // Integer to string
regular expression
There are two main classes of C + + regular expressions.
- Regex: represents a regular expression, which is basic_ Specialized form of regex;
- smatch: indicates the matching result of regular expression. It is match_ Specialized form of results.
There are three algorithms for C + + regular matching. Note that they are "read-only" and will not change the original string.
- regex_match(): exactly match a string;
- regex_search(): find a regular match in the string;
- regex_replace(): regular search and replace.
auto make_regex = [](const auto& txt) // Production regular expression
{
return std::regex(txt);
};
auto make_match = []() // Production regular matching results
{
return std::smatch();
};
auto str = "neir:automata"s; // String to match
auto reg =
make_regex(R"(^(\w+)\:(\w+)$)"); // The original string defines a regular expression
auto what = make_match(); // Ready to get matching results
Here I first define two simple lambda expressions to produce regular objects, mainly to facilitate automatic type derivation with auto. Of course, it also hides the specific type information, which can be changed at any time in the future (which is also a bit like functional programming).
Then we can call regex_match() checks the string, and the function returns a bool value indicating whether it exactly matches the regular string. If the matching is successful, the result is stored in what and can be accessed like a container. Element 0 is the whole matching string, and others are sub expression matching strings:
assert(regex_match(str, what, reg)); // Regular matching
for(const auto& x : what) { // for traverses the matched subexpression
cout << x << ',';
}
regex_search(),regex_ The usage of replace () is similar. It's easy to understand. Just look at the code:
auto str = "god of war"s; // String to match
auto reg =
make_regex(R"((\w+)\s(\w+))"); // The original string defines a regular expression
auto what = make_match(); // Ready to get matching results
auto found = regex_search( // Regular search is similar to matching
str, what, reg);
assert(found); // Assertion found match
assert(!what.empty()); // Assertion has matching results
assert(what[1] == "god"); // Look at the first subexpression
assert(what[2] == "of"); // Look at the second subexpression
auto new_str = regex_replace( // Regular replacement, return new string
str, // The original string is unchanged
make_regex(R"(\w+$)"), // Generate regular expression objects in place
"peace" // Alternate text needs to be specified
);
cout << new_str << endl; // Output god of peace
container
Containers are data structures that can "hold" and "store" elements.
General characteristics of containers
You must know that all containers have a basic feature: it uses the "value" semantics to store elements, that is, the container stores copies and copies of elements, not references.
One solution is to try to implement the transfer construction and transfer assignment function for the element, and use std::move() to "transfer" when adding the container to reduce the cost of element replication:
Point p; // An object with high copy cost v.push_back(p); // Storage object, copy structure, high cost v.push_back(std::move(p)); // After defining the transfer structure, you can transfer storage and reduce costs
Specific characteristics of the container
One classification is divided into three categories: sequential containers, ordered containers and unordered containers according to the access mode of elements
-
Sequential container
Sequential containers are linear tables in data structures. There are five types: array, vector, deque, list and forward_list.
According to the storage structure, these five containers can be subdivided into two groups:- Continuously stored arrays: array, vector, and deque.
- Linked list of pointer structure: list and forward_list.
Array and vector directly correspond to the built-in array of C. the memory layout is fully compatible with C, so they are the containers with the lowest overhead and the fastest speed** The difference between them is whether the capacity can grow dynamically** Array is a static array. Its size is fixed at the time of initialization. It can't hold more elements. Vector is a dynamic array. Although the size is set during initialization, it can grow as needed to accommodate any number of elements.