1. Install Hadoop and Spark
Enter the Linux system and complete the installation of Hadoop pseudo distributed mode by referring to "Hadoop installation and use" in the "experimental guide" column of the official website of this tutorial. After installing Hadoop, install Spark (Local mode).
2. Common HDFS operations
Log in to the Linux system with the Hadoop user name, start Hadoop, refer to relevant Hadoop books or network materials, or refer to "common Shell commands for HDFS operation" in the "experimental guide" column of the official website of this tutorial,
Use the Shell command provided by Hadoop to complete the following operations:
(1) Start Hadoop and create the user directory "/ user/hadoop" in HDFS;
hadoop fs -mkdir /user/hadoop
(2) Create a new text file test. In the "/ home/hadoop" directory of the local file system of the Linux system Txt, and enter some content in the file, and then upload it to the "/ user/hadoop" directory of HDFS;
hdfs dfs -put /home/hadoop/test.txt /usr/hadoop
(3) hold Test. Under "/ user/hadoop" directory in HDFS Txt file, which is downloaded to the "/ home/hadoop / download" directory in the local file system of Linux system;
hdfs dfs -get /user/hadoop/test.txt /home/hadoop
(4) Put test. Under the "/ user/hadoop" directory in HDFS The contents of TXT file are output to the terminal for display;
hdfs dfs -cat /user/hadoop/test.txt
(5) Under the "/ user/hadoop" directory in HDFS, create a subdirectory input, and put the test under the "/ user/hadoop" directory in HDFS Txt file and copy it to the "/ user/hadoop/input" directory;
hadoop fs -mkdir /user/hadoop/input
hdfs dfs -cp /user/hadoop/test.txt /user/hadoop/input
(6) Delete test. Under "/ user/hadoop" directory in HDFS Txt file and delete the input in the "/ user/hadoop" directory in HDFS Subdirectories and all contents under them.
hdfs dfs -rm /user/hadoop/test.txt
hdfs dfs -rm -r /user/hadoop/input
3. Spark} reads data from the file system
(1) Read the local file "/ home/hadoop/test.txt" of Linux system in spark shell, and then count the number of lines of the file;
bin/spark-shell val textFile = sc.textFile("file:///home/hadoop/test1.txt") textFile.count()
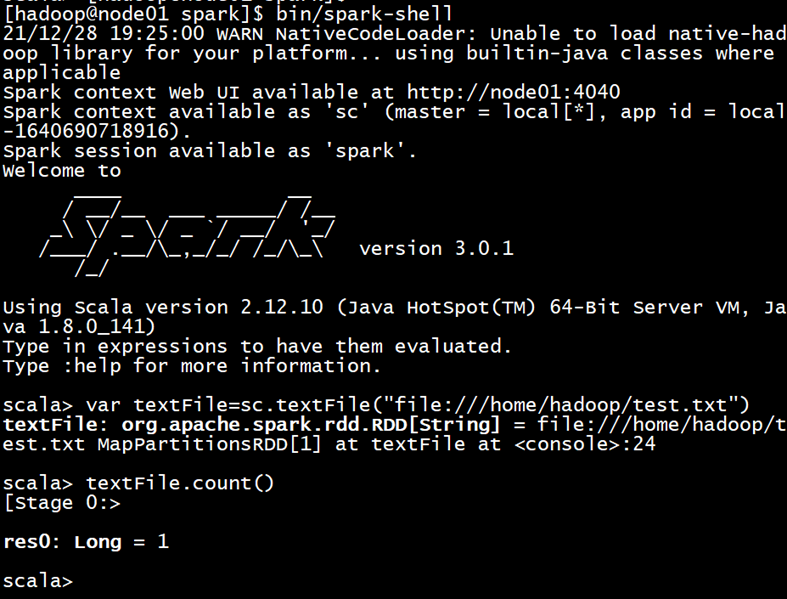
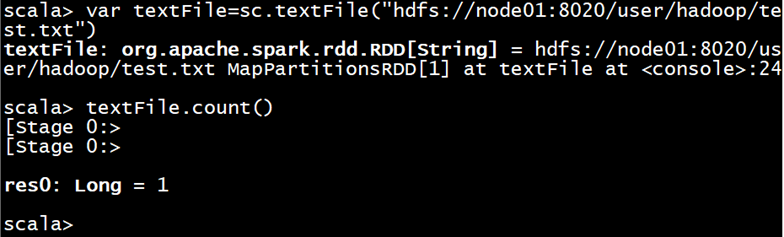
(2) Read the HDFS system file "/ user/hadoop/test.txt" in spark shell (if the file does not exist, please create it first), and then count the number of lines of the file;
val textFile = sc.textFile("hdfs://node01:8020/user/hadoop/test.txt")textFile.count()
(3) Write an independent application, read the HDFS system file "/ user/hadoop/test.txt" (if the file does not exist, please create it first), and then count the number of lines of the file; compile and package the whole application into JAR package through sbt tool, and submit the generated JAR package to Spark through Spark submit to run the command.
cd ~ # Enter user home folder mkdir ./sparkapp3 # Create application root directory mkdir -p ./sparkapp3/src/main/scala # Create the desired folder structure vim ./sparkapp3/src/main/scala/SimpleApp.scala ---------------------------------------------------------- /* SimpleApp.scala */ import org.apache.spark.SparkContext import org.apache.spark.SparkContext._ import org.apache.spark.SparkConf object SimpleApp { def main(args: Array[String]) { val logFile = "hdfs://localhost:9000/home/hadoop/test.csv" val conf = new SparkConf().setAppName("Simple Application") val sc = new SparkContext(conf) val logData = sc.textFile(logFile, 2) val num = logData.count() println("This file has %d that 's ok!".format(num)) } } ---------------------------------------------------------- vim ./sparkapp3/simple.sbt ---------------------------------------------------------- name := "Simple Project" version := "1.0" scalaVersion := "2.12.10" libraryDependencies += "org.apache.spark" %% "spark-core" % "3.0.0-preview2" ----------------------------------------------------------