1, Experimental principle
The essence of audio compression coding is perceptual coding, which uses perceptual model to remove insensitive sound data and ensure that the sound quality will not decline significantly. It adopts subband coding technology, obtains the auditory masking threshold of different subbands according to the psychoacoustic model, and dynamically quantifies the sampling value of each subband.
1. Design idea of perceptual audio coding
1) Human auditory characteristics
critical band
The human auditory system is roughly equivalent to a filter bank composed of 25 overlapping band-pass filters in the frequency range of 0Hz to 20KHz. These 25 frequency bands are called critical frequency bands, and the human ear cannot distinguish different sounds occurring simultaneously in the same frequency band.
Masking effect
The phenomenon that the auditory perception of a weaker sound is affected by another stronger sound is called the auditory masking effect of human ear. The masking effect is related to the signal frequency and intensity. The masking effect does not change with the increase of bandwidth in a certain frequency range until it exceeds a certain frequency value.
Psychoacoustic model
There is an auditory threshold level in the auditory system. The sound signal below this level cannot be heard. The size of the auditory threshold changes with the change of sound frequency. Whether a person hears a sound depends on the frequency of the sound and whether the amplitude of the sound is higher than the auditory threshold at this frequency, that is, the auditory threshold level is adaptive and will change with the sound of different frequencies.
The use of psychoacoustic model can eliminate more redundant data, and the inaudible can not be encoded. The main sound components are represented by more bits. When the introduced quantization noise is lower than the auditory threshold, it will not affect the feeling of sound, so as to obtain greater compression efficiency.
2) Subband coding
Due to the different masking characteristics of different frequency bands, the original signal can be decomposed into several sub bands, which can be coded separately, and then synthesized into a full band signal at the receiver, so as to obtain a larger compression ratio. This method is called sub-band coding.
The signal decomposition method can be used to divide different subsequences, and the recursive decomposition method can be used to obtain subsequences, which is called analysis synthesis, and can be realized by digital filter.
2.MPEG-1AudioLayerII encoder
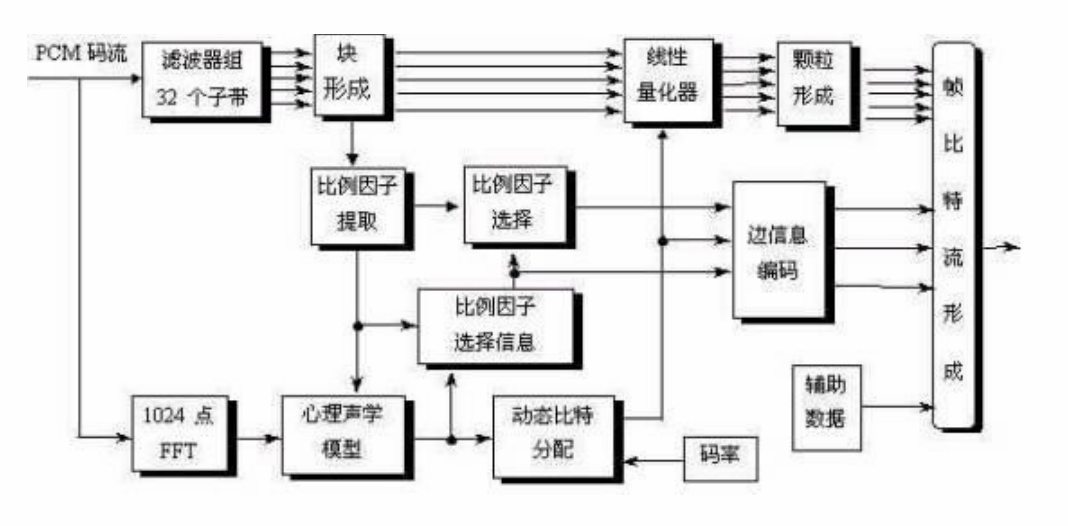
1. Sample transformation to frequency domain
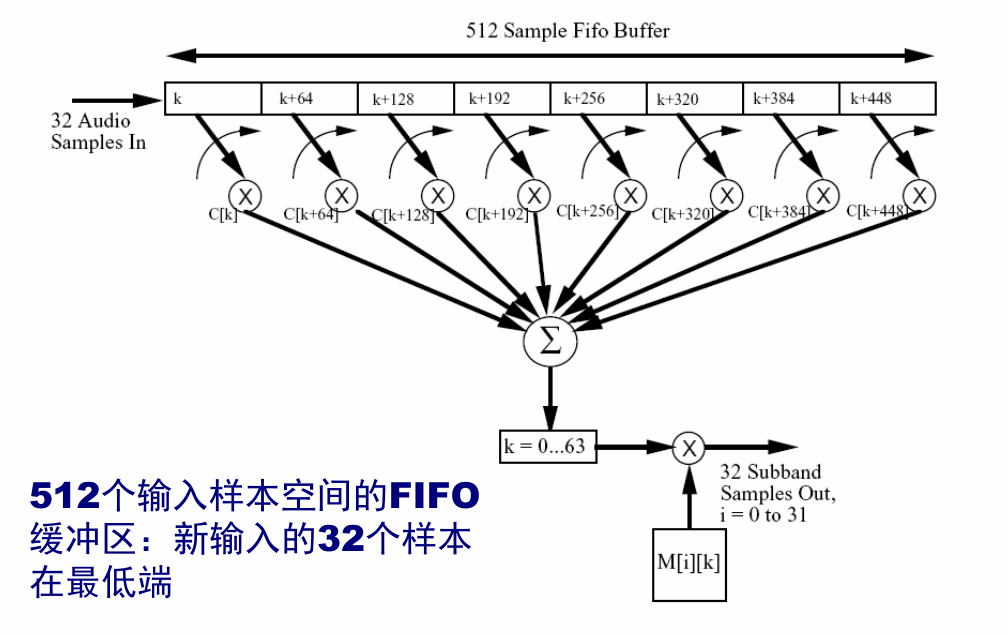
The polyphase filter bank divides the input signal into 32 subbands. The equal subbands of the signal can not accurately reflect the auditory characteristics of the human ear. The model needs finer frequency resolution, and the amplitude of each frequency is also required to calculate the masking threshold. Therefore, FFT is introduced to compensate for the lack of frequency resolution, so 1024 point FFT is adopted in LayerII.
Contradiction of time-frequency analysis: when filtering, the fewer samples you want to input, the better (the smaller the sample window size T0, the better). Through subband analysis, the filter bank can make the signal have high time resolution and ensure that the encoded sound signal has high enough quality in the case of short impact signal; During FFT transformation, the more input samples, the better (F0=fs/T0, the larger T0, the smaller F0), so that the signal has high frequency resolution through FFT operation, because the masking threshold is derived from the power spectral density. Therefore, Layer II adopts 1024 sample window, 1152 sample points per frame, 32 subbands, 3 groups of each subband and 1 group of 12 sample points.
2. Calculate masking threshold

Calculate the separate masking threshold: calculate the music and noise in a certain frequency band respectively. The noise is the concentration of all non music parts in the critical bandwidth
Calculate the global masking threshold: absolute threshold plus individual threshold

Calculate the subband masking threshold: select the minimum threshold in this subband as the subband threshold, which is incorrect for high frequencies, because the critical frequency band in the high frequency region is very wide and may span multiple subbands. When a subband is far away from the representative frequency in a very wide frequency band, it is impossible to obtain accurate non tonal masking value, but the amount of calculation is low
3. Rate allocation
The goal of rate allocation is to minimize the total noise masking ratio of the whole frame and each subband.
Before adjusting to a fixed code rate: first determine the number of effective bits that can be used for sample value coding, which depends on the scale factor, scale factor selection information, bit allocation information and the number of bits required for auxiliary data.
The scale factor is calculated every 12 samples in each subband. First determine the maximum absolute value of the 12 sample points. Look up the minimum value larger than the maximum value in the scale factor table as the scale factor. Represented by 6 bits. A frame of layer 2 corresponds to 36 subband samples, which is three times that of layer 1. In principle, three scale factors should be transmitted. In order to reduce the transmission rate of the scale factor, the three scale factors of each subband in each frame are considered together and divided into specific modes. It is expressed by the scale factor selection information (2 bits per subband). If there is only a small difference between one scale factor and the next, only the large one is transmitted. This situation often occurs for steady-state signals.
Bit allocation process
MNR (masking noise ratio) is calculated for each subband. MNR = SNR (signal-to-noise ratio) – SMR (signal masking ratio), where SMR = signal energy / masking threshold, which is calculated from FFT results by psychoacoustic model
Allocate bits to the subband with the lowest MNR to increase the quantization level of the subband with the greatest benefit by one level
Recalculate the MNR allocated with more bit subbands and cycle the previous step until no bits are available
2, Code implementation
m2nenc.c
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <time.h>
#include "common.h"
#include "encoder.h"
#include "musicin.h"
#include "options.h"
#include "audio_read.h"
#include "bitstream.h"
#include "mem.h"
#include "crc.h"
#include "psycho_n1.h"
#include "psycho_0.h"
#include "psycho_1.h"
#include "psycho_2.h"
#include "psycho_3.h"
#include "psycho_4.h"
#include "encode.h"
#include "availbits.h"
#include "subband.h"
#include "encode_new.h"
#include "m2aenc.h"
#include <assert.h>
FILE *musicin;
Bit_stream_struc bs;
char *programName;
char toolameversion[10] = "0.2l";
void global_init (void)
{
glopts.usepsy = TRUE;
glopts.usepadbit = TRUE;
glopts.quickmode = FALSE;
glopts.quickcount = 10;
glopts.downmix = FALSE;
glopts.byteswap = FALSE;
glopts.channelswap = FALSE;
glopts.vbr = FALSE;
glopts.vbrlevel = 0;
glopts.athlevel = 0;
glopts.verbosity = 2;
}
/************************************************************************
*
* main
*
* PURPOSE: MPEG II Encoder with
* psychoacoustic models 1 (MUSICAM) and 2 (AT&T)
*
* SEMANTICS: One overlapping frame of audio of up to 2 channels are
* processed at a time in the following order:
* (associated routines are in parentheses)
*
* 1. Filter sliding window of data to get 32 subband
* samples per channel.
* (window_subband,filter_subband)
*
* 2. If joint stereo mode, combine left and right channels
* for subbands above #jsbound#.
* (combine_LR)
*
* 3. Calculate scalefactors for the frame, and
* also calculate scalefactor select information.
* (*_scale_factor_calc)
*
* 4. Calculate psychoacoustic masking levels using selected
* psychoacoustic model.
* (psycho_i, psycho_ii)
*
* 5. Perform iterative bit allocation for subbands with low
* mask_to_noise ratios using masking levels from step 4.
* (*_main_bit_allocation)
*
* 6. If error protection flag is active, add redundancy for
* error protection.
* (*_CRC_calc)
*
* 7. Pack bit allocation, scalefactors, and scalefactor select
*headerrmation onto bitstream.
* (*_encode_bit_alloc,*_encode_scale,transmission_pattern)
*
* 8. Quantize subbands and pack them into bitstream
* (*_subband_quantization, *_sample_encoding)
*
************************************************************************/
int frameNum = 0;
int main (int argc, char **argv)
{
//#if TRACE
// tracefile = fopen(TRACE_FILE, "w");
//#endif
typedef double SBS[2][3][SCALE_BLOCK][SBLIMIT];
SBS *sb_sample;
typedef double JSBS[3][SCALE_BLOCK][SBLIMIT];
JSBS *j_sample;
typedef double IN[2][HAN_SIZE];
IN *win_que;
typedef unsigned int SUB[2][3][SCALE_BLOCK][SBLIMIT];
SUB *subband;
frame_info frame;//Including header information, bit allocation table, number of subbands and other information
frame_header header;//Include header information
char original_file_name[MAX_NAME_SIZE];//Enter file name
char encoded_file_name[MAX_NAME_SIZE];//Output file name
short **win_buf;
static short buffer[2][1152];
static unsigned int bit_alloc[2][SBLIMIT], scfsi[2][SBLIMIT];//Store the bit allocation table of each subband of two channels, SBLIMIT=32, that is, 32 subbands
static unsigned int scalar[2][3][SBLIMIT], j_scale[3][SBLIMIT];//Store the scale factor of 12 samples in each subband group
static double smr[2][SBLIMIT], lgmin[2][SBLIMIT], max_sc[2][SBLIMIT];
// FLOAT snr32[32];
short sam[2][1344]; /* was [1056]; */
int model, nch, error_protection;
static unsigned int crc;
int sb, ch, adb;
unsigned long frameBits, sentBits = 0;
unsigned long num_samples;
int lg_frame;
int i;
/* Used to keep the SNR values for the fast/quick psy models */
static FLOAT smrdef[2][32];
static int psycount = 0;
extern int minimum;
time_t start_time, end_time;
int total_time;
//Modified part
int gr;
FILE *out_txt=NULL;
unsigned char *outTXT=NULL;
out_txt=fopen("output.txt","w");
//end
sb_sample = (SBS *) mem_alloc (sizeof (SBS), "sb_sample");
j_sample = (JSBS *) mem_alloc (sizeof (JSBS), "j_sample");
win_que = (IN *) mem_alloc (sizeof (IN), "Win_que");
subband = (SUB *) mem_alloc (sizeof (SUB), "subband");
win_buf = (short **) mem_alloc (sizeof (short *) * 2, "win_buf");
/* clear buffers */
memset ((char *) buffer, 0, sizeof (buffer));
memset ((char *) bit_alloc, 0, sizeof (bit_alloc));
memset ((char *) scalar, 0, sizeof (scalar));
memset ((char *) j_scale, 0, sizeof (j_scale));
memset ((char *) scfsi, 0, sizeof (scfsi));
memset ((char *) smr, 0, sizeof (smr));
memset ((char *) lgmin, 0, sizeof (lgmin));
memset ((char *) max_sc, 0, sizeof (max_sc));
//memset ((char *) snr32, 0, sizeof (snr32));
memset ((char *) sam, 0, sizeof (sam));
global_init ();//initialization
header.extension = 0;
frame.header = &header;
frame.tab_num = -1; /* no table loaded */
frame.alloc = NULL;
header.version = MPEG_AUDIO_ID; /* Default: MPEG-1 */
total_time = 0;
time(&start_time);
programName = argv[0];
if (argc == 1) /* no command-line args */
short_usage ();
else
parse_args (argc, argv, &frame, &model, &num_samples, original_file_name,
encoded_file_name);
print_config (&frame, &model, original_file_name, encoded_file_name);
//Output configuration information, etc
/* this will load the alloc tables and do some other stuff */
hdr_to_frps (&frame);
nch = frame.nch;
error_protection = header.error_protection;
//Get audio from data stream
while (get_audio (musicin, buffer, num_samples, nch, &header) > 0) {
if (glopts.verbosity > 1)
if (++frameNum % 10 == 0)
fprintf (stderr, "[%4u]\r", frameNum);
fflush (stderr);
win_buf[0] = &buffer[0][0];
win_buf[1] = &buffer[1][0];
adb = available_bits (&header, &glopts);
lg_frame = adb / 8;
if (header.dab_extension) {
/* in 24 kHz we always have 4 bytes */
if (header.sampling_frequency == 1)
header.dab_extension = 4;
/* You must have one frame in memory if you are in DAB mode */
/* in conformity of the norme ETS 300 401 http://www.etsi.org */
/* see bitstream.c */
if (frameNum == 1)
minimum = lg_frame + MINIMUM;
adb -= header.dab_extension * 8 + header.dab_length * 8 + 16;
}
{
int gr, bl, ch;
/* New polyphase filter
Combines windowing and filtering. Ricardo Feb'03 */
for( gr = 0; gr < 3; gr++ )
for ( bl = 0; bl < 12; bl++ )
for ( ch = 0; ch < nch; ch++ )
WindowFilterSubband( &buffer[ch][gr * 12 * 32 + 32 * bl], ch,
&(*sb_sample)[ch][gr][bl][0] );
}
#ifdef REFERENCECODE
{
/* Old code. left here for reference */
int gr, bl, ch;
for (gr = 0; gr < 3; gr++)
for (bl = 0; bl < SCALE_BLOCK; bl++)
for (ch = 0; ch < nch; ch++) {
window_subband (&win_buf[ch], &(*win_que)[ch][0], ch);
filter_subband (&(*win_que)[ch][0], &(*sb_sample)[ch][gr][bl][0]);
}
}
#endif
#ifdef NEWENCODE
scalefactor_calc_new(*sb_sample, scalar, nch, frame.sblimit);
find_sf_max (scalar, &frame, max_sc);
if (frame.actual_mode == MPG_MD_JOINT_STEREO) {
/* this way we calculate more mono than we need */
/* but it is cheap */
combine_LR_new (*sb_sample, *j_sample, frame.sblimit);
scalefactor_calc_new (j_sample, &j_scale, 1, frame.sblimit);
}
#else
scale_factor_calc (*sb_sample, scalar, nch, frame.sblimit);
pick_scale (scalar, &frame, max_sc);
if (frame.actual_mode == MPG_MD_JOINT_STEREO) {
/* this way we calculate more mono than we need */
/* but it is cheap */
combine_LR (*sb_sample, *j_sample, frame.sblimit);
scale_factor_calc (j_sample, &j_scale, 1, frame.sblimit);
}
#endif
if ((glopts.quickmode == TRUE) && (++psycount % glopts.quickcount != 0)) {
/* We're using quick mode, so we're only calculating the model every
'quickcount' frames. Otherwise, just copy the old ones across */
for (ch = 0; ch < nch; ch++) {
for (sb = 0; sb < SBLIMIT; sb++)
smr[ch][sb] = smrdef[ch][sb];
}
} else {
/* calculate the psymodel */
switch (model) {
case -1:
psycho_n1 (smr, nch);
break;
case 0: /* Psy Model A */
psycho_0 (smr, nch, scalar, (FLOAT) s_freq[header.version][header.sampling_frequency] * 1000);
break;
case 1:
psycho_1 (buffer, max_sc, smr, &frame);
break;
case 2:
for (ch = 0; ch < nch; ch++) {
psycho_2 (&buffer[ch][0], &sam[ch][0], ch, &smr[ch][0], //snr32,
(FLOAT) s_freq[header.version][header.sampling_frequency] *
1000, &glopts);
}
break;
case 3:
/* Modified psy model 1 */
psycho_3 (buffer, max_sc, smr, &frame, &glopts);
break;
case 4:
/* Modified Psycho Model 2 */
for (ch = 0; ch < nch; ch++) {
psycho_4 (&buffer[ch][0], &sam[ch][0], ch, &smr[ch][0], // snr32,
(FLOAT) s_freq[header.version][header.sampling_frequency] *
1000, &glopts);
}
break;
case 5:
/* Model 5 comparse model 1 and 3 */
psycho_1 (buffer, max_sc, smr, &frame);
fprintf(stdout,"1 ");
smr_dump(smr,nch);
psycho_3 (buffer, max_sc, smr, &frame, &glopts);
fprintf(stdout,"3 ");
smr_dump(smr,nch);
break;
case 6:
/* Model 6 compares model 2 and 4 */
for (ch = 0; ch < nch; ch++)
psycho_2 (&buffer[ch][0], &sam[ch][0], ch, &smr[ch][0], //snr32,
(FLOAT) s_freq[header.version][header.sampling_frequency] *
1000, &glopts);
fprintf(stdout,"2 ");
smr_dump(smr,nch);
for (ch = 0; ch < nch; ch++)
psycho_4 (&buffer[ch][0], &sam[ch][0], ch, &smr[ch][0], // snr32,
(FLOAT) s_freq[header.version][header.sampling_frequency] *
1000, &glopts);
fprintf(stdout,"4 ");
smr_dump(smr,nch);
break;
case 7:
fprintf(stdout,"Frame: %i\n",frameNum);
/* Dump the SMRs for all models */
psycho_1 (buffer, max_sc, smr, &frame);
fprintf(stdout,"1");
smr_dump(smr, nch);
psycho_3 (buffer, max_sc, smr, &frame, &glopts);
fprintf(stdout,"3");
smr_dump(smr,nch);
for (ch = 0; ch < nch; ch++)
psycho_2 (&buffer[ch][0], &sam[ch][0], ch, &smr[ch][0], //snr32,
(FLOAT) s_freq[header.version][header.sampling_frequency] *
1000, &glopts);
fprintf(stdout,"2");
smr_dump(smr,nch);
for (ch = 0; ch < nch; ch++)
psycho_4 (&buffer[ch][0], &sam[ch][0], ch, &smr[ch][0], // snr32,
(FLOAT) s_freq[header.version][header.sampling_frequency] *
1000, &glopts);
fprintf(stdout,"4");
smr_dump(smr,nch);
break;
case 8:
/* Compare 0 and 4 */
psycho_n1 (smr, nch);
fprintf(stdout,"0");
smr_dump(smr,nch);
for (ch = 0; ch < nch; ch++)
psycho_4 (&buffer[ch][0], &sam[ch][0], ch, &smr[ch][0], // snr32,
(FLOAT) s_freq[header.version][header.sampling_frequency] *
1000, &glopts);
fprintf(stdout,"4");
smr_dump(smr,nch);
break;
default:
fprintf (stderr, "Invalid psy model specification: %i\n", model);
exit (0);
}
if (glopts.quickmode == TRUE)
/* copy the smr values and reuse them later */
for (ch = 0; ch < nch; ch++) {
for (sb = 0; sb < SBLIMIT; sb++)
smrdef[ch][sb] = smr[ch][sb];
}
if (glopts.verbosity > 4)
smr_dump(smr, nch);
}
#ifdef NEWENCODE
sf_transmission_pattern (scalar, scfsi, &frame);
main_bit_allocation_new (smr, scfsi, bit_alloc, &adb, &frame, &glopts);
//main_bit_allocation (smr, scfsi, bit_alloc, &adb, &frame, &glopts);
if (error_protection)
CRC_calc (&frame, bit_alloc, scfsi, &crc);
write_header (&frame, &bs);
//encode_info (&frame, &bs);
if (error_protection)
putbits (&bs, crc, 16);
write_bit_alloc (bit_alloc, &frame, &bs);
//encode_bit_alloc (bit_alloc, &frame, &bs);
write_scalefactors(bit_alloc, scfsi, scalar, &frame, &bs);
//encode_scale (bit_alloc, scfsi, scalar, &frame, &bs);
subband_quantization_new (scalar, *sb_sample, j_scale, *j_sample, bit_alloc,
*subband, &frame);
//subband_quantization (scalar, *sb_sample, j_scale, *j_sample, bit_alloc,
// *subband, &frame);
write_samples_new(*subband, bit_alloc, &frame, &bs);
//sample_encoding (*subband, bit_alloc, &frame, &bs);
#else
transmission_pattern (scalar, scfsi, &frame);
main_bit_allocation (smr, scfsi, bit_alloc, &adb, &frame, &glopts);
if (error_protection)
CRC_calc (&frame, bit_alloc, scfsi, &crc);
encode_info (&frame, &bs);
if (error_protection)
encode_CRC (crc, &bs);
encode_bit_alloc (bit_alloc, &frame, &bs);
encode_scale (bit_alloc, scfsi, scalar, &frame, &bs);
subband_quantization (scalar, *sb_sample, j_scale, *j_sample, bit_alloc,
*subband, &frame);
sample_encoding (*subband, bit_alloc, &frame, &bs);
#endif
/* If not all the bits were used, write out a stack of zeros */
for (i = 0; i < adb; i++)
put1bit (&bs, 0);
if (header.dab_extension) {
/* Reserve some bytes for X-PAD in DAB mode */
putbits (&bs, 0, header.dab_length * 8);
for (i = header.dab_extension - 1; i >= 0; i--) {
CRC_calcDAB (&frame, bit_alloc, scfsi, scalar, &crc, i);
/* this crc is for the previous frame in DAB mode */
if (bs.buf_byte_idx + lg_frame < bs.buf_size)
bs.buf[bs.buf_byte_idx + lg_frame] = crc;
/* reserved 2 bytes for F-PAD in DAB mode */
putbits (&bs, crc, 8);
}
putbits (&bs, 0, 16);
}
frameBits = sstell (&bs) - sentBits;
if (frameBits % 8) { /* a program failure */
fprintf (stderr, "Sent %ld bits = %ld slots plus %ld\n", frameBits,
frameBits / 8, frameBits % 8);
fprintf (stderr, "If you are reading this, the program is broken\n");
fprintf (stderr, "email [mfc at NOTplanckenerg.com] without the NOT\n");
fprintf (stderr, "with the command line arguments and other info\n");
exit (0);
}
sentBits += frameBits;
}
close_bit_stream_w (&bs);
if ((glopts.verbosity > 1) && (glopts.vbr == TRUE)) {
int i;
#ifdef NEWENCODE
extern int vbrstats_new[15];
#else
extern int vbrstats[15];
#endif
fprintf (stdout, "VBR stats:\n");
for (i = 1; i < 15; i++)
fprintf (stdout, "%4i ", bitrate[header.version][i]);
fprintf (stdout, "\n");
for (i = 1; i < 15; i++)
#ifdef NEWENCODE
fprintf (stdout,"%4i ",vbrstats_new[i]);
#else
fprintf (stdout, "%4i ", vbrstats[i]);
#endif
fprintf (stdout, "\n");
}
fprintf (stderr,
"Avg slots/frame = %.3f; b/smp = %.2f; bitrate = %.3f kbps\n",
(FLOAT) sentBits / (frameNum * 8),
(FLOAT) sentBits / (frameNum * 1152),
(FLOAT) sentBits / (frameNum * 1152) *
s_freq[header.version][header.sampling_frequency]);
if (fclose (musicin) != 0) {
fprintf (stderr, "Could not close \"%s\".\n", original_file_name);
exit (2);
}
fprintf (stderr, "\nDone\n");
//Modified part
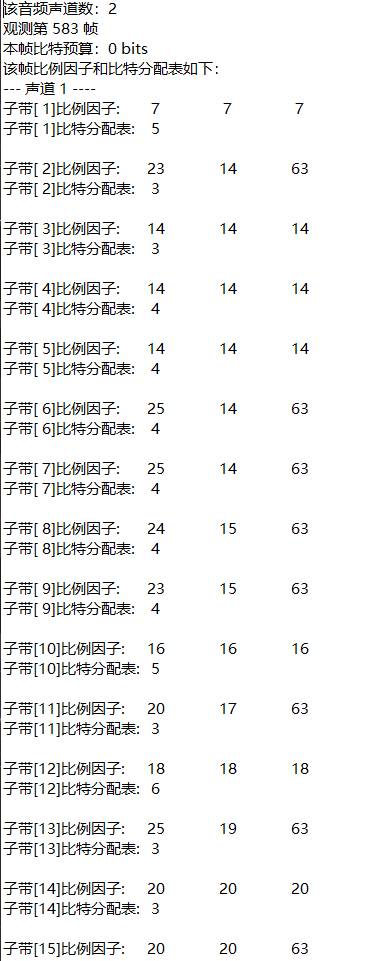
fprintf(out_txt, "The number of audio channels:%d\n", nch);
fprintf(out_txt, "Observation section %d frame\n", frameNum);
fprintf(out_txt, "Bit budget of this frame:%d bits\n", adb);
fprintf(out_txt, "The frame scale factor and bit allocation table are as follows:\n");
for (ch = 0; ch < nch; ch++) //Channel by channel output
{
fprintf(out_txt, "--- Vocal tract%2d ----\n", ch + 1);
for (sb = 0; sb < frame.sblimit; sb++) //Each subband
{
fprintf(out_txt, "Subband[%2d]Scale factor:\t", sb + 1);
for (gr = 0; gr < 3; gr++)
{
fprintf(out_txt, "%2d\t", scalar[ch][gr][sb]);
}
fprintf(out_txt, "\n");
fprintf(out_txt, "Subband[%2d]Bit allocation table:\t%2d\n", sb + 1, bit_alloc[ch][sb]);
fprintf(out_txt, "\n");
}
}
//end
time(&end_time);
total_time = end_time - start_time;
printf("total time is %d\n", total_time);
//Modified part
free(outTXT);
fclose(out_txt);
//end
system("pause");
exit (0);
}
/************************************************************************
*
* print_config
*
* PURPOSE: Prints the encoding parameters used
*
************************************************************************/
void print_config (frame_info * frame, int *psy, char *inPath,
char *outPath)
{
frame_header *header = frame->header;
if (glopts.verbosity == 0)
return;
fprintf (stderr, "--------------------------------------------\n");
fprintf (stderr, "Input File : '%s' %.1f kHz\n",
(strcmp (inPath, "-") ? inPath : "stdin"),
s_freq[header->version][header->sampling_frequency]);
fprintf (stderr, "Output File: '%s'\n",
(strcmp (outPath, "-") ? outPath : "stdout"));
fprintf (stderr, "%d kbps ", bitrate[header->version][header->bitrate_index]);
fprintf (stderr, "%s ", version_names[header->version]);
if (header->mode != MPG_MD_JOINT_STEREO)
fprintf (stderr, "Layer II %s Psycho model=%d (Mode_Extension=%d)\n",
mode_names[header->mode], *psy, header->mode_ext);
else
fprintf (stderr, "Layer II %s Psy model %d \n", mode_names[header->mode],
*psy);
fprintf (stderr, "[De-emph:%s\tCopyright:%s\tOriginal:%s\tCRC:%s]\n",
((header->emphasis) ? "On" : "Off"),
((header->copyright) ? "Yes" : "No"),
((header->original) ? "Yes" : "No"),
((header->error_protection) ? "On" : "Off"));
fprintf (stderr, "[Padding:%s\tByte-swap:%s\tChanswap:%s\tDAB:%s]\n",
((glopts.usepadbit) ? "Normal" : "Off"),
((glopts.byteswap) ? "On" : "Off"),
((glopts.channelswap) ? "On" : "Off"),
((glopts.dab) ? "On" : "Off"));
if (glopts.vbr == TRUE)
fprintf (stderr, "VBR Enabled. Using MNR boost of %f\n", glopts.vbrlevel);
fprintf(stderr,"ATH adjustment %f\n",glopts.athlevel);
fprintf (stderr, "--------------------------------------------\n");
}
/************************************************************************
*
* usage
*
* PURPOSE: Writes command line syntax to the file specified by #stderr#
*
************************************************************************/
void usage (void)
{ /* print syntax & exit */
/* FIXME: maybe have an option to display better definitions of help codes, and
long equivalents of the flags */
fprintf (stdout, "\ntooLAME version %s (http://toolame.sourceforge.net)\n",
toolameversion);
fprintf (stdout, "MPEG Audio Layer II encoder\n\n");
fprintf (stdout, "usage: \n");
fprintf (stdout, "\t%s [options] <input> <output>\n\n", programName);
fprintf (stdout, "Options:\n");
fprintf (stdout, "Input\n");
fprintf (stdout, "\t-s sfrq input smpl rate in kHz (dflt %4.1f)\n",
DFLT_SFQ);
fprintf (stdout, "\t-a downmix from stereo to mono\n");
fprintf (stdout, "\t-x force byte-swapping of input\n");
fprintf (stdout, "\t-g swap channels of input file\n");
fprintf (stdout, "Output\n");
fprintf (stdout, "\t-m mode channel mode : s/d/j/m (dflt %4c)\n",
DFLT_MOD);
fprintf (stdout, "\t-p psy psychoacoustic model 0/1/2/3 (dflt %4u)\n",
DFLT_PSY);
fprintf (stdout, "\t-b br total bitrate in kbps (dflt 192)\n");
fprintf (stdout, "\t-v lev vbr mode\n");
fprintf (stdout, "\t-l lev ATH level (dflt 0)\n");
fprintf (stdout, "Operation\n");
// fprintf (stdout, "\t-f fast mode (turns off psy model)\n");
// deprecate the -f switch. use "-p 0" instead.
fprintf (stdout,
"\t-q num quick mode. only calculate psy model every num frames\n");
fprintf (stdout, "Misc\n");
fprintf (stdout, "\t-d emp de-emphasis n/5/c (dflt %4c)\n",
DFLT_EMP);
fprintf (stdout, "\t-c mark as copyright\n");
fprintf (stdout, "\t-o mark as original\n");
fprintf (stdout, "\t-e add error protection\n");
fprintf (stdout, "\t-r force padding bit/frame off\n");
fprintf (stdout, "\t-D len add DAB extensions of length [len]\n");
fprintf (stdout, "\t-t talkativity 0=no messages (dflt 2)");
fprintf (stdout, "Files\n");
fprintf (stdout,
"\tinput input sound file. (WAV,AIFF,PCM or use '/dev/stdin')\n");
fprintf (stdout, "\toutput output bit stream of encoded audio\n");
fprintf (stdout,
"\n\tAllowable bitrates for 16, 22.05 and 24kHz sample input\n");
fprintf (stdout,
"\t8, 16, 24, 32, 40, 48, 56, 64, 80, 96, 112, 128, 144, 160\n");
fprintf (stdout,
"\n\tAllowable bitrates for 32, 44.1 and 48kHz sample input\n");
fprintf (stdout,
"\t32, 48, 56, 64, 80, 96, 112, 128, 160, 192, 224, 256, 320, 384\n");
exit (1);
}
/*********************************************
* void short_usage(void)
********************************************/
void short_usage (void)
{
/* print a bit of info about the program */
fprintf (stderr, "tooLAME version %s\n (http://toolame.sourceforge.net)\n",
toolameversion);
fprintf (stderr, "MPEG Audio Layer II encoder\n\n");
fprintf (stderr, "USAGE: %s [options] <infile> [outfile]\n\n", programName);
fprintf (stderr, "Try \"%s -h\" for more information.\n", programName);
exit (0);
}
/*********************************************
* void proginfo(void)
********************************************/
void proginfo (void)
{
/* print a bit of info about the program */
fprintf (stderr,
"\ntooLAME version 0.2g (http://toolame.sourceforge.net)\n");
fprintf (stderr, "MPEG Audio Layer II encoder\n\n");
}
/************************************************************************
*
* parse_args
*
* PURPOSE: Sets encoding parameters to the specifications of the
* command line. Default settings are used for parameters
* not specified in the command line.
*
* SEMANTICS: The command line is parsed according to the following
* syntax:
*
* -m is followed by the mode
* -p is followed by the psychoacoustic model number
* -s is followed by the sampling rate
* -b is followed by the total bitrate, irrespective of the mode
* -d is followed by the emphasis flag
* -c is followed by the copyright/no_copyright flag
* -o is followed by the original/not_original flag
* -e is followed by the error_protection on/off flag
* -f turns off psy model (fast mode)
* -q <i> only calculate psy model every ith frame
* -a downmix from stereo to mono
* -r turn off padding bits in frames.
* -x force byte swapping of input
* -g swap the channels on an input file
* -t talkativity. how verbose should the program be. 0 = no messages.
*
* If the input file is in AIFF format, the sampling frequency is read
* from the AIFF header.
*
* The input and output filenames are read into #inpath# and #outpath#.
*
************************************************************************/
void parse_args (int argc, char **argv, frame_info * frame, int *psy,
unsigned long *num_samples, char inPath[MAX_NAME_SIZE],
char outPath[MAX_NAME_SIZE])
{
FLOAT srate;
int brate;
frame_header *header = frame->header;
int err = 0, i = 0;
long samplerate;
/* preset defaults */
inPath[0] = '\0';
outPath[0] = '\0';
header->lay = DFLT_LAY;
switch (DFLT_MOD) {
case 's':
header->mode = MPG_MD_STEREO;
header->mode_ext = 0;
break;
case 'd':
header->mode = MPG_MD_DUAL_CHANNEL;
header->mode_ext = 0;
break;
/* in j-stereo mode, no default header->mode_ext was defined, gave error..
now default = 2 added by MFC 14 Dec 1999. */
case 'j':
header->mode = MPG_MD_JOINT_STEREO;
header->mode_ext = 2;
break;
case 'm':
header->mode = MPG_MD_MONO;
header->mode_ext = 0;
break;
default:
fprintf (stderr, "%s: Bad mode dflt %c\n", programName, DFLT_MOD);
abort ();
}
*psy = DFLT_PSY;
if ((header->sampling_frequency =
SmpFrqIndex ((long) (1000 * DFLT_SFQ), &header->version)) < 0) {
fprintf (stderr, "%s: bad sfrq default %.2f\n", programName, DFLT_SFQ);
abort ();
}
header->bitrate_index = 14;
brate = 0;
switch (DFLT_EMP) {
case 'n':
header->emphasis = 0;
break;
case '5':
header->emphasis = 1;
break;
case 'c':
header->emphasis = 3;
break;
default:
fprintf (stderr, "%s: Bad emph dflt %c\n", programName, DFLT_EMP);
abort ();
}
header->copyright = 0;
header->original = 0;
header->error_protection = FALSE;
header->dab_extension = 0;
/* process args */
while (++i < argc && err == 0) {
char c, *token, *arg, *nextArg;
int argUsed;
token = argv[i];
if (*token++ == '-') {
if (i + 1 < argc)
nextArg = argv[i + 1];
else
nextArg = "";
argUsed = 0;
if (!*token) {
/* The user wants to use stdin and/or stdout. */
if (inPath[0] == '\0')
strncpy (inPath, argv[i], MAX_NAME_SIZE);
else if (outPath[0] == '\0')
strncpy (outPath, argv[i], MAX_NAME_SIZE);
}
while ((c = *token++)) {
if (*token /* NumericQ(token) */ )
arg = token;
else
arg = nextArg;
switch (c) {
case 'm':
argUsed = 1;
if (*arg == 's') {
header->mode = MPG_MD_STEREO;
header->mode_ext = 0;
} else if (*arg == 'd') {
header->mode = MPG_MD_DUAL_CHANNEL;
header->mode_ext = 0;
} else if (*arg == 'j') {
header->mode = MPG_MD_JOINT_STEREO;
} else if (*arg == 'm') {
header->mode = MPG_MD_MONO;
header->mode_ext = 0;
} else {
fprintf (stderr, "%s: -m mode must be s/d/j/m not %s\n",
programName, arg);
err = 1;
}
break;
case 'p':
*psy = atoi (arg);
argUsed = 1;
break;
case 's':
argUsed = 1;
srate = atof (arg);
/* samplerate = rint( 1000.0 * srate ); $A */
samplerate = (long) ((1000.0 * srate) + 0.5);
if ((header->sampling_frequency =
SmpFrqIndex ((long) samplerate, &header->version)) < 0)
err = 1;
break;
case 'b':
argUsed = 1;
brate = atoi (arg);
break;
case 'd':
argUsed = 1;
if (*arg == 'n')
header->emphasis = 0;
else if (*arg == '5')
header->emphasis = 1;
else if (*arg == 'c')
header->emphasis = 3;
else {
fprintf (stderr, "%s: -d emp must be n/5/c not %s\n", programName,
arg);
err = 1;
}
break;
case 'D':
argUsed = 1;
header->dab_length = atoi (arg);
header->error_protection = TRUE;
header->dab_extension = 2;
glopts.dab = TRUE;
break;
case 'c':
header->copyright = 1;
break;
case 'o':
header->original = 1;
break;
case 'e':
header->error_protection = TRUE;
break;
case 'f':
*psy = 0;
/* this switch is deprecated? FIXME get rid of glopts.usepsy
instead us psymodel 0, i.e. "-p 0" */
glopts.usepsy = FALSE;
break;
case 'r':
glopts.usepadbit = FALSE;
header->padding = 0;
break;
case 'q':
argUsed = 1;
glopts.quickmode = TRUE;
glopts.usepsy = TRUE;
glopts.quickcount = atoi (arg);
if (glopts.quickcount == 0) {
/* just don't use psy model */
glopts.usepsy = FALSE;
glopts.quickcount = FALSE;
}
break;
case 'a':
glopts.downmix = TRUE;
header->mode = MPG_MD_MONO;
header->mode_ext = 0;
break;
case 'x':
glopts.byteswap = TRUE;
break;
case 'v':
argUsed = 1;
glopts.vbr = TRUE;
glopts.vbrlevel = atof (arg);
glopts.usepadbit = FALSE; /* don't use padding for VBR */
header->padding = 0;
/* MFC Feb 2003: in VBR mode, joint stereo doesn't make
any sense at the moment, as there are no noisy subbands
according to bits_for_nonoise in vbr mode */
header->mode = MPG_MD_STEREO; /* force stereo mode */
header->mode_ext = 0;
break;
case 'l':
argUsed = 1;
glopts.athlevel = atof(arg);
break;
case 'h':
usage ();
break;
case 'g':
glopts.channelswap = TRUE;
break;
case 't':
argUsed = 1;
glopts.verbosity = atoi (arg);
break;
default:
fprintf (stderr, "%s: unrec option %c\n", programName, c);
err = 1;
break;
}
if (argUsed) {
if (arg == token)
token = ""; /* no more from token */
else
++i; /* skip arg we used */
arg = "";
argUsed = 0;
}
}
} else {
if (inPath[0] == '\0')
strcpy (inPath, argv[i]);
else if (outPath[0] == '\0')
strcpy (outPath, argv[i]);
else {
fprintf (stderr, "%s: excess arg %s\n", programName, argv[i]);
err = 1;
}
}
}
if (header->dab_extension) {
/* in 48 kHz */
/* if the bit rate per channel is less then 56 kbit/s, we have 2 scf-crc */
/* else we have 4 scf-crc */
/* in 24 kHz, we have 4 scf-crc, see main loop */
if (brate / (header->mode == MPG_MD_MONO ? 1 : 2) >= 56)
header->dab_extension = 4;
}
if (err || inPath[0] == '\0')
usage (); /* If no infile defined, or err has occured, then call usage() */
if (outPath[0] == '\0') {
/* replace old extension with new one, 1992-08-19, 1995-06-12 shn */
new_ext (inPath, DFLT_EXT, outPath);
}
if (!strcmp (inPath, "-")) {
musicin = stdin; /* read from stdin */
*num_samples = MAX_U_32_NUM;
} else {
if ((musicin = fopen (inPath, "rb")) == NULL) {
fprintf (stderr, "Could not find \"%s\".\n", inPath);
exit (1);
}
parse_input_file (musicin, inPath, header, num_samples);
}
/* check for a valid bitrate */
if (brate == 0)
brate = bitrate[header->version][10];
/* Check to see we have a sane value for the bitrate for this version */
if ((header->bitrate_index = BitrateIndex (brate, header->version)) < 0)
err = 1;
/* All options are hunky dory, open the input audio file and
return to the main drag */
open_bit_stream_w (&bs, outPath, BUFFER_SIZE);
}
void smr_dump(double smr[2][SBLIMIT], int nch) {
int ch, sb;
fprintf(stdout,"SMR:");
for (ch = 0;ch<nch; ch++) {
if (ch==1)
fprintf(stdout," ");
for (sb=0;sb<SBLIMIT;sb++)
fprintf(stdout,"%3.0f ",smr[ch][sb]);
fprintf(stdout,"\n");
}
}
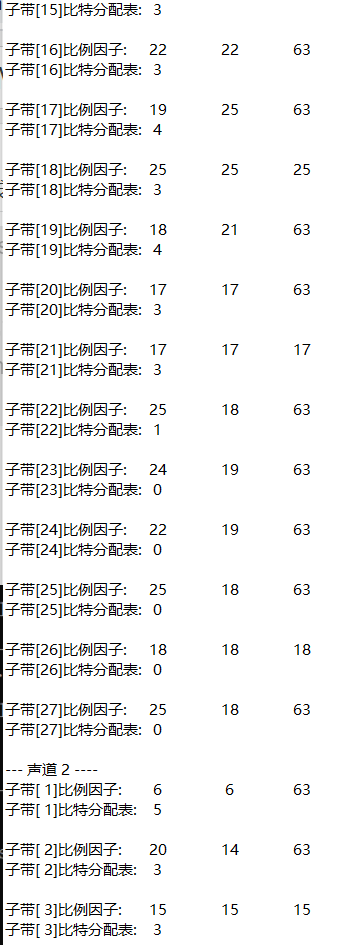
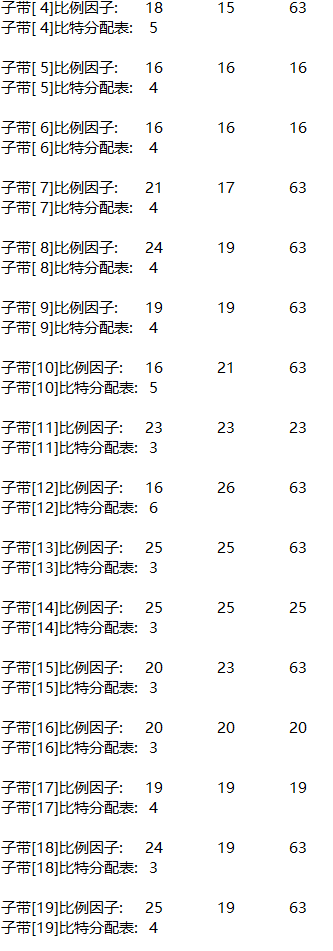
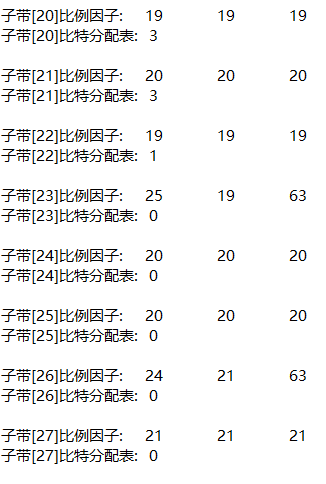
3, Experimental requirements

(1) Noise
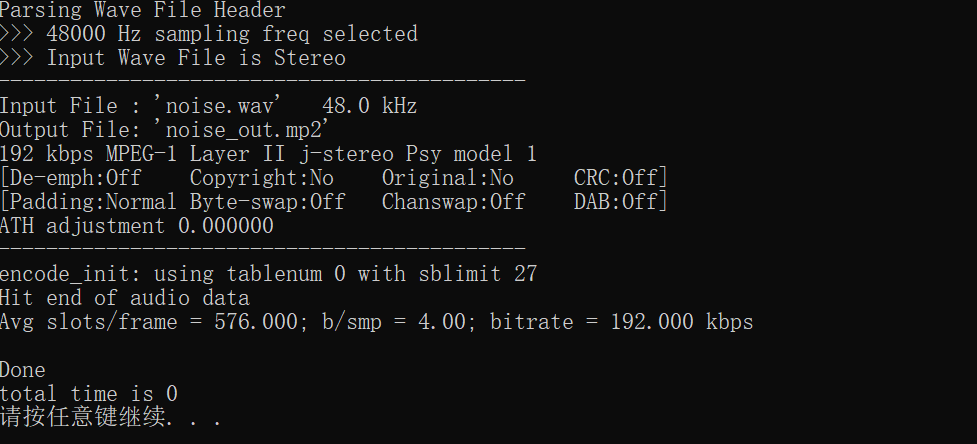
(2) Music
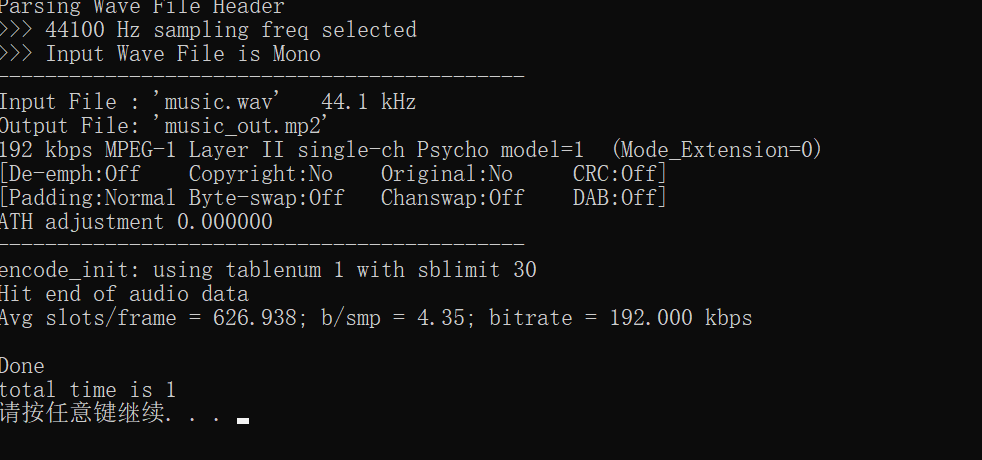
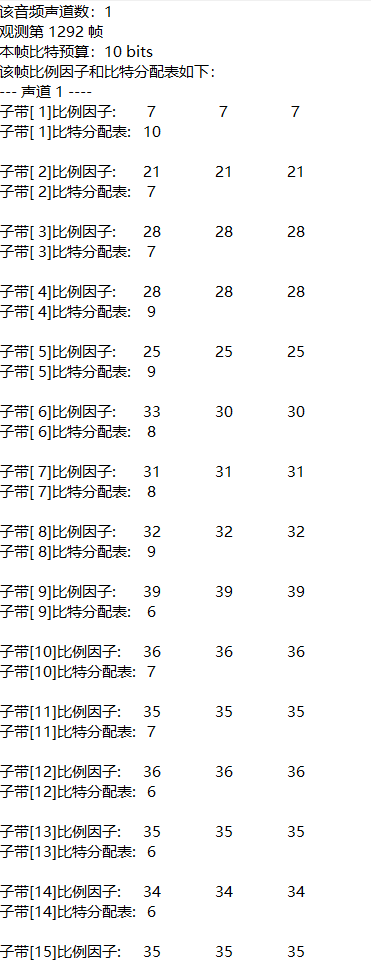
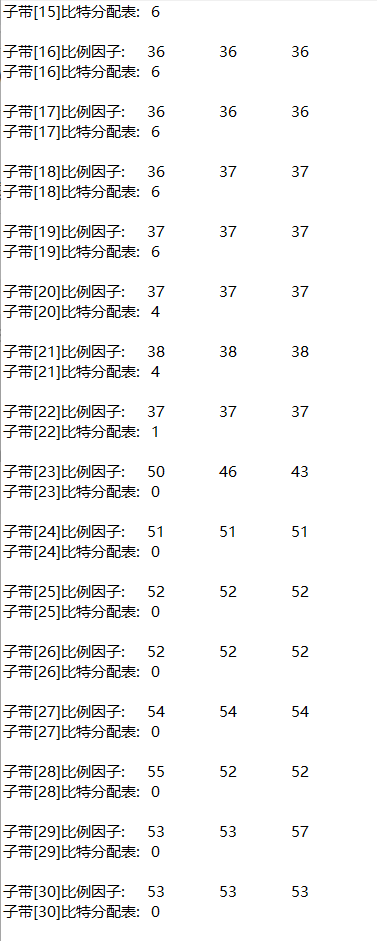
(3) Music plus noise
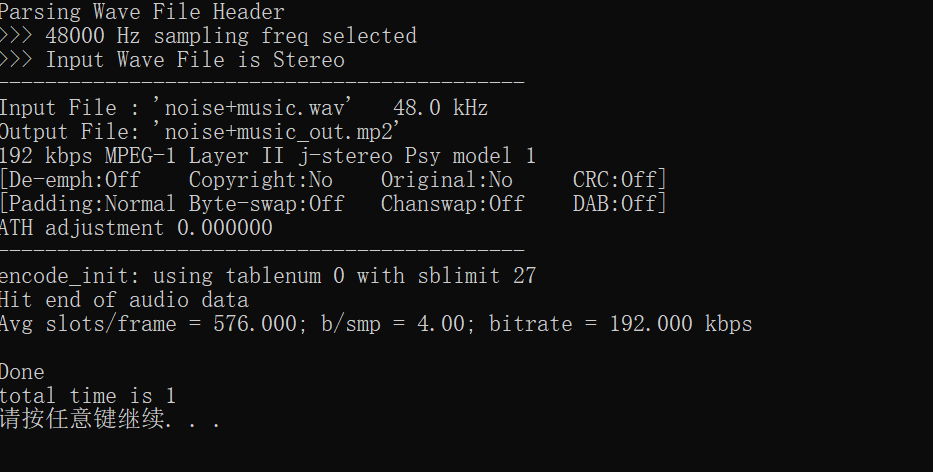
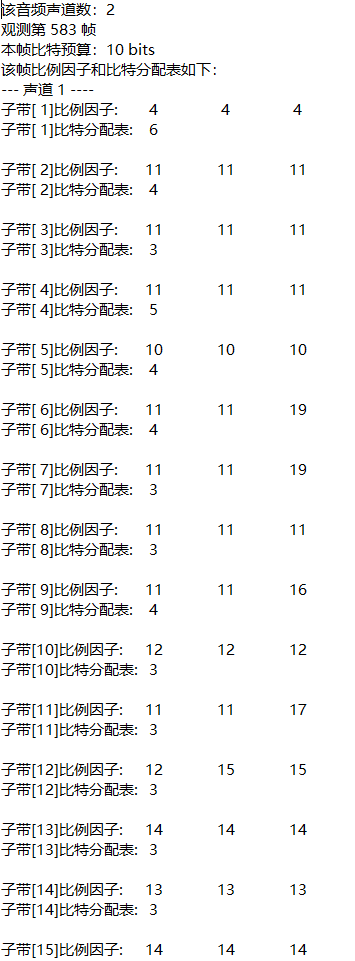
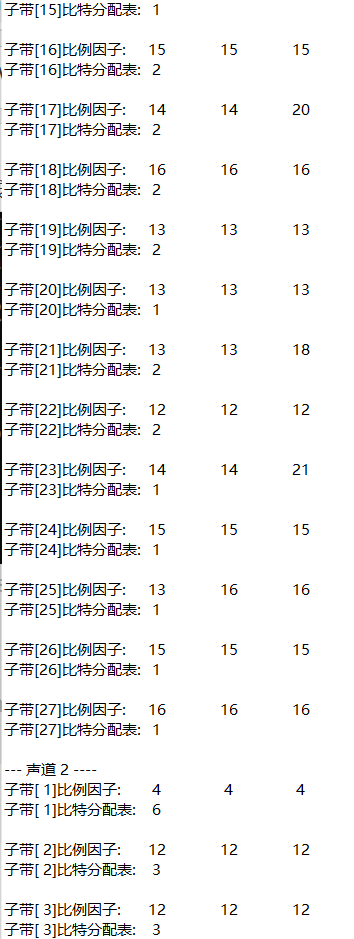
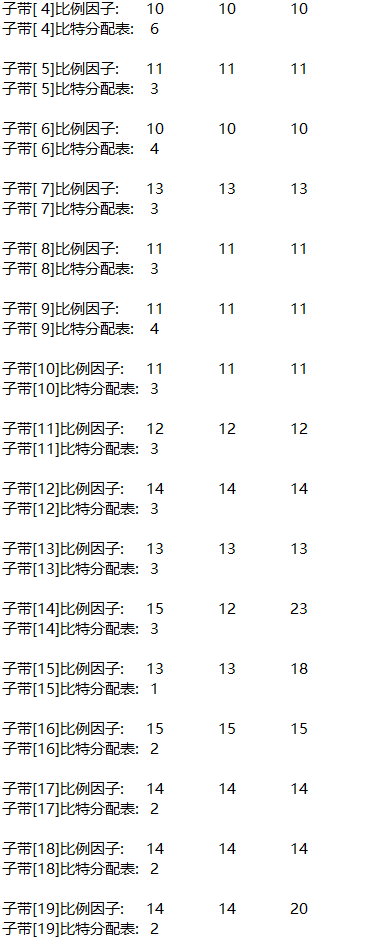
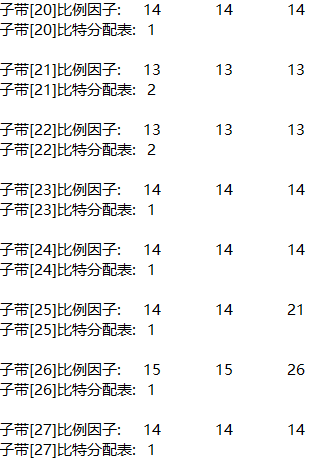
4, Experimental conclusion
From the bit allocation of each subband, the higher the frequency (the larger the subband number), the less bits are allocated. This is because in the low-frequency subband, in order to protect the structure of tone and formant, it is required to use smaller quantization order and more quantization stages, that is, allocate more bits to represent the sample value. The friction sound and noise like sound in speech usually appear in the high-frequency subband, and less bits are allocated to it.