Author: Hu Chengqing
Member of aikesheng DBA team, good at fault analysis and performance optimization, personal blog: https://www.jianshu.com/u/a95... , welcome to the discussion.
Source: original contribution
*It is produced by aikesheng open source community. The original content cannot be used without authorization. For reprint, please contact Xiaobian and indicate the source.
introduce
MySQL 8.0.16 introduces an experimental feature: explain format=tree, tree output execution process, estimated cost and estimated number of returned rows. On mysql8 0.18 also introduces EXPLAIN ANALYZE. On the basis of format=tree, it will execute SQL and output the actual information related to the iterator (it feels easier to understand with "operator" here), such as execution cost, number of returned lines, execution time and number of cycles.
Document link: https://dev.mysql.com/doc/ref...
Example:
mysql> explain format=tree SELECT * FROM t1 WHERE t1.a IN (SELECT t2.b FROM t2 WHERE id < 10);
*************************** 1. row ***************************
-> Nested loop inner join (cost=4.95 rows=9)
-> Filter: (`<subquery2>`.b is not null) (cost=2.83..1.80 rows=9)
-> Table scan on <subquery2> (cost=0.29..2.61 rows=9)
-> Materialize with deduplication (cost=3.25..5.58 rows=9)
-> Filter: (t2.b is not null) (cost=2.06 rows=9)
-> Filter: (t2.id < 10) (cost=2.06 rows=9)
-> Index range scan on t2 using PRIMARY (cost=2.06 rows=9)
-> Index lookup on t1 using a (a=`<subquery2>`.b) (cost=2.35 rows=1)
1 row in set (0.01 sec)
mysql> explain analyze SELECT * FROM t1 WHERE t1.a IN (SELECT t2.b FROM t2 WHERE id < 10)\G
*************************** 1. row ***************************
-> Nested loop inner join (cost=4.95 rows=9) (actual time=0.153..0.200 rows=9 loops=1)
-> Filter: (`<subquery2>`.b is not null) (cost=2.83..1.80 rows=9) (actual time=0.097..0.100 rows=9 loops=1)
-> Table scan on <subquery2> (cost=0.29..2.61 rows=9) (actual time=0.001..0.002 rows=9 loops=1)
-> Materialize with deduplication (cost=3.25..5.58 rows=9) (actual time=0.090..0.092 rows=9 loops=1)
-> Filter: (t2.b is not null) (cost=2.06 rows=9) (actual time=0.037..0.042 rows=9 loops=1)
-> Filter: (t2.id < 10) (cost=2.06 rows=9) (actual time=0.036..0.040 rows=9 loops=1)
-> Index range scan on t2 using PRIMARY (cost=2.06 rows=9) (actual time=0.035..0.038 rows=9 loops=1)
-> Index lookup on t1 using a (a=`<subquery2>`.b) (cost=2.35 rows=1) (actual time=0.010..0.010 rows=1 loops=9)
1 row in set (0.01 sec)It can be seen that explain format=tree shows a relatively clear execution process compared with the traditional execution plan. On this basis, explain analyze will output the actual execution time, the number of returned lines and the number of cycles.
Reading order
- From right to left: before parallel iterators are encountered, they are executed from the right;
- From top to bottom: when parallel iterators are encountered, the upper iterators start execution first
The reading sequence of the above examples is shown in the following figure (note that it is best not to output \ G, otherwise the indentation of the first line is inaccurate). The execution sequence of SQL is:
- Use Nested loop inner join algorithm;
- t2 first take the data (Index range scan), Filter and Materialize into a temporary table as the driving table;
- Bring the drive table data to t1 for query (Index lookup on t1), and execute the cycle 9 times.
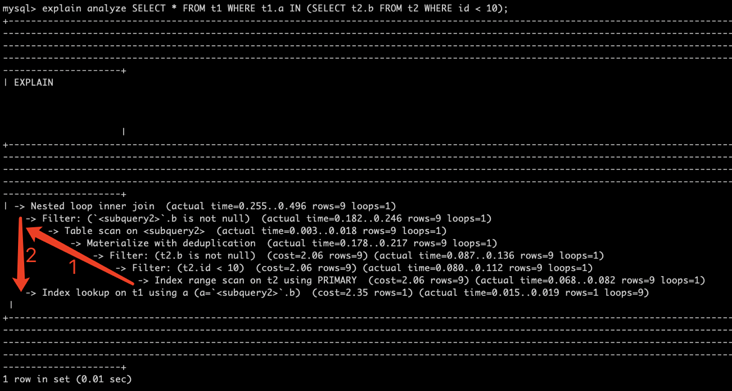
important information
Take the following as an example:
Index lookup on t1 using a (a=`<subquery2>`.b) (cost=2.35 rows=1) (actual time=0.015..0.017 rows=1 loops=9)
cost
The estimated cost information is complicated to calculate. If you want to know more, you can see: explain format=json
rows
The first row is the estimated value, and the second row is the actual number of rows returned.
actual time
"0.015.. 0.017". Note that there are two values here. The first value is to obtain the actual time of the first row, and the second value is to obtain the time of all rows. If the cycle is repeated for many times, it is the average time, in milliseconds.
loops
Because the Nested loop inner join algorithm is used here. According to the reading order, t2 is the driving table. First, the query is materialized into a temporary table; t1 table is the driven table, and the number of circular queries is 9, that is, loops=9.