Feature extraction is simply to convert a series of data into digital features that can be used for machine learning. sklearn.feature_extraction is a module of scikit learn feature extraction
This paper summarizes the following contents:
- Onehot encoding
- DictVectorizer uses
- CountVectorizer use
- TfidfVectorizer uses
- HashingVectorizer uses
1.Onehot code
As mentioned above, the transformation of features into digital features of machine learning is actually transformed into Onehot coding.
Why convert to onehot coding? First look at the data below.
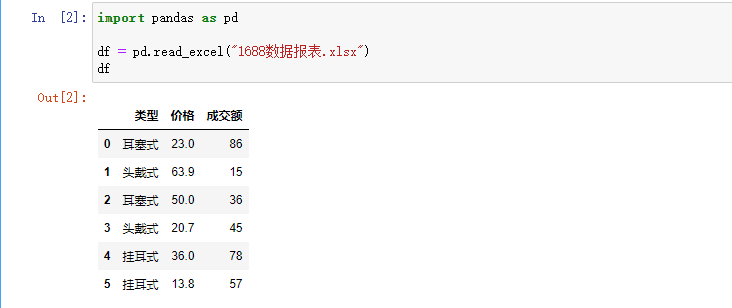
This is part of the Bluetooth headset data of the 1688 website. From the table above, the "type" column is a character type that the machine does not recognize, so it needs to be converted to a digital type.
What is Onehot coding like?
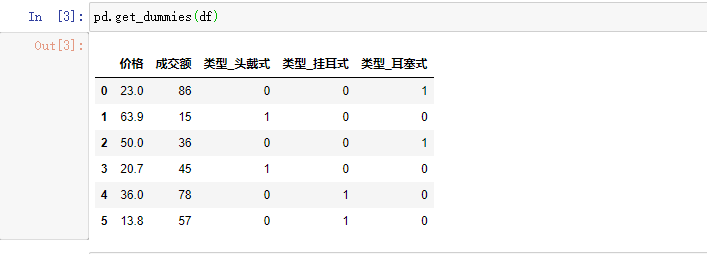
Call the pandas built-in function getdummies() to automatically convert to Onehot encoding. It can be seen from the above figure that the numerical data remains unchanged, and the number of columns can be created according to the number of "types". The values are represented by 1 and 0. For example, if the first row of data is earphone type, fill 1 in the "type earphone type" column, 0 for others, and so on.
Therefore, after Onehot coding, character data is also replaced by numerical data, and the machine can recognize it.
2.DictVectorizer
The DictVectorizer class is in sklearn feature_ extraction. Under DictVectorizer, it is used to convert the feature array in the form of standard Python dict object list into NumPy / SciPy form used by scikit learn estimator. example:
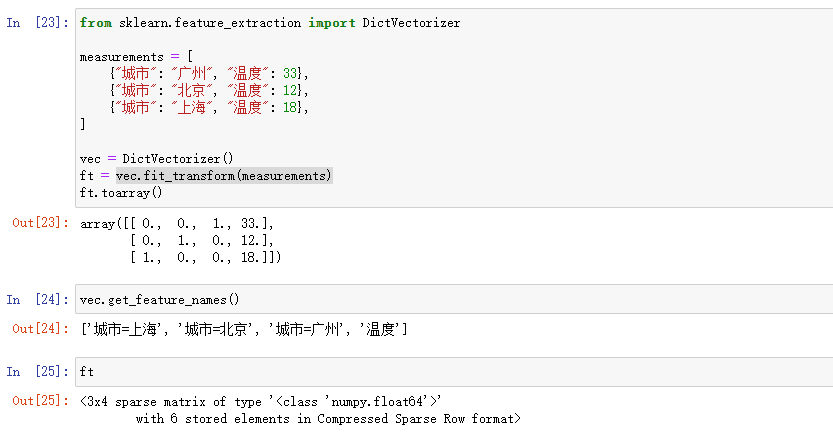
As can be seen from the above example, DictVectorizer automatically converts Python's Dict type data extraction into Onehot coding. It is similar to the result generated directly using the panads function getdummies().
It is worth noting that: VEC fit_ Transform (measurements) returns a 3x4 spark matrix, that is, a SciPy Sparse matrix.
Question: why convert SciPy Spark matrix?
In the above example, if hundreds of city data are added, many data columns will be generated after onehot coding, and many values are 0. In order to make the generated data structure suitable for memory, the DictVectorizer class uses SciPy by default Sparse matrix instead of numpy ndarray
2.CountVectorizer
The CountVectorizer class is in sklearn feature_ extraction. text. Under CountVectorizer, first look at the source code explanation of the CountVectorizer class.
Convert a collection of text documents to a matrix of token counts
This implementation produces a sparse representation of the counts using scipy.sparse.csr_matrix
It means to convert the text document set into a token count matrix, that is, to count the frequency of each word in some columns of documents.
But also into SciPy Sparse matrix. Because the word frequency is counted, and there are thousands of words in the article, avoid generating a wide list.
The use method of CountVectorizer is very simple, for example:
from sklearn.feature_extraction.text import CountVectorizer
corpus = [
'This is the first document.',
'This is the second second document.',
'And the third one.',
'Is this the first document?',
]
vec = CountVectorizer()
ft = vec.fit_transform(corpus)
print(vec.get_feature_names())
print(ft.toarray())
Output results:
['and', 'document', 'first', 'is', 'one', 'second', 'the', 'third', 'this']
[[0 1 1 1 0 0 1 0 1]
[0 1 0 1 0 2 1 0 1]
[1 0 0 0 1 0 1 1 0]
[0 1 1 1 0 0 1 0 1]]It can be seen from the example that CountVectorizer uses spaces for word segmentation by default, and counts the number of times of each word after segmentation.
Question: English words are separated by spaces. What about Chinese words?
Use jieba word segmentation library for word segmentation, and then use spaces for character connection.
import jieba
from sklearn.feature_extraction.text import CountVectorizer
sentences = []
#Original corpus
corpus = ["It's sunny now. Don't worry about going out",
"The weather is fine and the temperature is suitable",
"It will rain soon. Take an umbrella"]
#Use jieba to segment the corpus and put the results in sentences
for word in corpus:
lyrics = jieba.cut(word)
sentences.append(" ".join(lyrics))
vec = CountVectorizer()
ft = vec.fit_transform(sentences)
print(vec.get_feature_names())
print(ft.toarray())
Output results:
['rain', 'go out', 'weather', 'don 't worry', 'sunny', 'temperature', 'Now?', 'suitable', 'Umbrella', 'right off']
[[0 1 0 1 1 0 1 0 0 0]
[0 0 1 0 0 1 0 1 0 0]
[1 0 0 0 0 0 0 0 1 1]]In the above example, only the default parameters of CountVectorizer are used, but the following parameters should be noted:
preprocessor: a function used to preprocess text before tokenization. The default value is None.
tokenizer: used to split a string into a series of tag functions. The default value is None. Only applicable to analyzer == 'word'.
Question: in the above example, can you use other markers to segment words, such as /* Wait, can you change "rain" to "Snow"?
tokenizer can specify the segmentation method, and preprocessor can preprocess the corpus, such as deletion and replacement.
Slightly change the corpus, for example:
from sklearn.feature_extraction.text import CountVectorizer
# Original corpus
corpus = ["Now?/sunny/don 't worry/go out",
"weather/very good/temperature/suitable",
"right off/rain/give regards to/Umbrella"]
# Word segmentation with "/"
def my_tokenizer(s):
return s.split("/")
# Change all the words "rain" to "Snow"
def my_preprocessor(s):
return s.replace("rain", "snow")
vec = CountVectorizer(tokenizer=my_tokenizer, preprocessor=my_preprocessor)
ft = vec.fit_transform(corpus)
print(vec.get_feature_names())
print(ft.toarray())
Output results:
['snow', 'go out', 'weather', 'give regards to', 'very good', 'don 't worry', 'sunny', 'temperature', 'Now?', 'suitable', 'Umbrella', 'right off']
[[0 1 0 0 0 1 1 0 1 0 0 0]
[0 0 1 0 1 0 0 1 0 1 0 0]
[1 0 0 1 0 0 0 0 0 0 1 1]]stop_words: specifies a stop word. If "english" is passed in, the built-in english stop word list is used. If the list is passed in, it is assumed that the list contains stop words. All these words will be deleted from the result tag. The default is None, which is only applicable to analyzer = ='word '.
Question: what is the function of stop words?
In the prediction of article classification, it is often necessary to count the word frequency of each word in the article and calculate the weight of words for prediction and classification. However, some words are neutral and can not well reflect the type of article, such as "I, you, him, today, tomorrow, the day after tomorrow, now, right away" and so on. The function of stop words is to ignore these words, so as to screen important words.
from sklearn.feature_extraction.text import CountVectorizer
# Original corpus
corpus = ["Now?/sunny/don 't worry/go out",
"weather/very good/temperature/suitable",
"right off/rain/give regards to/Umbrella"]
# Word segmentation with "/"
def my_tokenizer(s):
return s.split("/")
# Change all the words "rain" to "Snow"
def my_preprocessor(s):
return s.replace("rain", "snow")
# Specify the list of stop words and delete the words "now" and "now"
stop_words=["Now?", "right off"]
vec = CountVectorizer(tokenizer=my_tokenizer, preprocessor=my_preprocessor, stop_words=stop_words)
ft = vec.fit_transform(corpus)
print(vec.get_feature_names())
print(ft.toarray())
Output results:
['snow', 'go out', 'weather', 'give regards to', 'very good', 'don 't worry', 'sunny', 'temperature', 'suitable', 'Umbrella']
[[0 1 0 0 0 1 1 0 0 0]
[0 0 1 0 1 0 0 1 1 0]
[1 0 0 1 0 0 0 0 0 1]]Stop words are not fixed and should be modified according to your business. Share a few Chinese common stop words list
3.TfidfVectorizer
In a large text corpus, some high-frequency words hardly carry any useful information related to the content of the document. If we provide statistics directly to the classifier, these high-frequency words will mask those words that we pay attention to but appear less frequently. Of course, it can be added to the stop phrase list, but this situation cannot be completely avoided according to different logical businesses. Then tf – idf transformation is needed to calculate the weight of word meaning, that is, the importance of words. Mathematical formula of tf – idf Transformation:
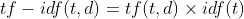
tf represents word frequency and idf represents inverse document frequency. The calculation formula is:
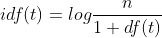
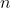 Represents the total number of documents in the document set,
Represents the total number of documents in the document set,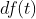 Indicates the number of documents containing the word in the document set. For example, a document library contains 100 documents, 10 of which contain the word "technology". Now there is a document prediction type, in which the document has 500 words, "technology" appears 20 times, and the "technology" tf – idf value is:
Indicates the number of documents containing the word in the document set. For example, a document library contains 100 documents, 10 of which contain the word "technology". Now there is a document prediction type, in which the document has 500 words, "technology" appears 20 times, and the "technology" tf – idf value is:
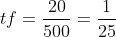
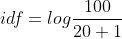
that
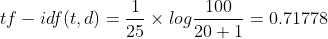
The TfidfVectorizer class is in sklearn feature_ extraction. text. tf – idf transformation is realized under TfidfVectorizer. Simple example:
from sklearn.feature_extraction.text import TfidfVectorizer
corpus = [
'first document.',
'second document.',
'second one.'
]
vec = TfidfVectorizer()
ft = vec.fit_transform(corpus)
print(vec.get_feature_names())
print(ft.toarray())
Output results:
['document', 'first', 'one', 'second']
[[0.60534851 0.79596054 0. 0. ]
[0.70710678 0. 0. 0.70710678]
[0. 0. 0.79596054 0.60534851]]The calculation method of TfidfVectorizer is somewhat different. Is the number of occurrences of words in a given document multiplied by idf. The calculation formula of idf is also a little different:
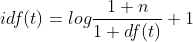
Then, the obtained TF IDF is normalized by Euclidean (L2) norm, and the calculation formula is:
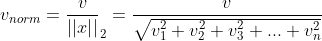
According to the formula, the above example tries to manually calculate the value of "document" of the first document. It can be seen from the corpus
"Document" appears once in the first document. There are three documents in total, and "document" appears in two documents,
"First" appears once in the first document. There are three documents in total, and "first" appears in one document,
"One" appears 0 times in the first document, there are 3 documents in total, and "one" appears in 1 document,
"Second" appears 0 times in the first document, there are 3 documents in total, and "second" appears in 2 documents,
Bring in the formula to obtain:
TF IDF of "document":
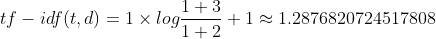
TF IDF of "first":
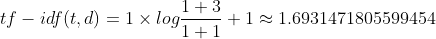
TF IDF of "one":
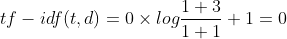
TF IDF of "second":
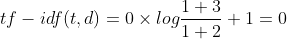
Then the Euclidean (L2) norm is normalized:
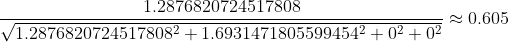
Other parameters can also be calculated in this way.
TfidfVectorizer parameter
Before talking about parameters, first explain the relationship between tfidfvector and countvecector. There is a class TfidfTransformer in scikit learn. In short:
TfidfVectorizer = CountVectorizer + TfidfTransformer
That is, the above example can achieve the same effect by using CountVectorizer and TfidfTransformer.
Therefore, the parameters described above for CountVectorizer and tfifvectorizer also have the same parameters, and their usage is the same.
Other parameters:
Norm: use L1 or L2 norm. The default value is L2. None does not use norms, such as
from sklearn.feature_extraction.text import TfidfVectorizer
corpus = [
'first document.',
'second document.',
'second one.'
]
vec = TfidfVectorizer(norm=None)
ft = vec.fit_transform(corpus)
print(vec.get_feature_names())
print(ft.toarray())
output
['document', 'first', 'one', 'second']
[[1.28768207 1.69314718 0. 0. ]
[1.28768207 0. 0. 1.28768207]
[0. 0. 1.69314718 1.28768207]]From the results, we can see that the data in the first row is the same as the value calculated manually above.
use_idf: whether to use idf weight. The default value is True. If False is set, it will not be multiplied by idf weight during calculation. Only L2 regularization after tf calculation will get the result.
smooth_idf: add 1 to smooth idf weight. The default value is True. If False is set, the formula of idf is:
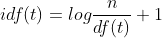
4.HashingVectorizer
HashingVectorizer class is in sklearn feature_ extraction. text. HashingVectorizer uses "hash technique" to extract features. Its memory is very low and is suitable for large data sets. example:
from sklearn.feature_extraction.text import HashingVectorizer
corpus = [
'This is the first document.',
'This is the second second document.',
'And the third one.',
'Is this the first document?',
]
vec = HashingVectorizer(n_features=2**5)
ft = vec.fit_transform(corpus)
print(ft)When memory is tight, FeatureHasher can also be used with CountVectorizer.
HashingVectorizer can replace tfidfvector for feature extraction, but HashingVectorizer does not provide IDF weighting and can be used with TfidfTransformer.
Intercept an example on the official website:
if opts.use_hashing:
# Using HashingVectorizer for feature extraction, according to opts use_ Is the IDF value IDF weighted
if opts.use_idf:
# IDF weighting using TfidfTransformer
# Perform IDF normalization on the output of HashingVectorizer
hasher = HashingVectorizer(n_features=opts.n_features,
stop_words='english', alternate_sign=False,
norm=None)
vectorizer = make_pipeline(hasher, TfidfTransformer())
else:
# No IDF weighting
vectorizer = HashingVectorizer(n_features=opts.n_features,
stop_words='english',
alternate_sign=False, norm='l2')
else:
# TfidfVectorizer is used for feature extraction according to opts use_ Is the IDF value IDF weighted
vectorizer = TfidfVectorizer(max_df=0.5, max_features=opts.n_features,
min_df=2, stop_words='english',
use_idf=opts.use_idf)Note: make_pipeline is the use of pipes to knead together various extractors.
This concludes the explanation of scikit learn feature extraction. The author's level is limited. You are welcome to make corrections.