Introduction: the pay as you go model of Serverless architecture can further reduce costs on the premise of ensuring the performance of online programming functions. This paper will take Alibaba cloud function computing as an example, implement an online programming function of Python language through Serverless architecture, and further optimize this function to make it closer to the local code execution experience.
With the development of computer science and technology, more and more people began to contact programming, and more and more online programming platforms were born. Taking the online programming platform of Python language as an example, it can be roughly divided into two categories:
- One is OJ type, that is, online evaluation programming platform. This kind of platform is characterized by blocking execution, that is, the user needs to submit the code and standard input content at one time, and the result will be returned at one time when the program execution is completed;
- The other is online programming platforms for learning and tools, such as Anycodes online programming and other websites. This kind of platform is characterized by non blocking execution, that is, users can see the results of code execution in real time and input content in real time.
However, no matter what type of online programming platform, the core module behind it ("code executor" or "question judging machine") is of great research value. On the one hand, such websites usually need a more strict "security mechanism", such as whether the program will have malicious code, dead cycle, damage the computer system, etc, Whether the program needs to be run in isolation, and whether the code submitted by others will be obtained during operation;
On the other hand, such platforms usually consume a lot of resources, especially when the game comes, they need to suddenly expand the capacity of relevant machines, and large-scale clusters are needed to deal with it when necessary. At the same time, such websites usually have a big feature, that is, trigger type, that is, there is no very close context relationship before and after the execution of each code.
With the continuous development of Serverless architecture, many people find that the request level isolation and extreme flexibility of Serverless architecture can solve the security problems and resource consumption problems encountered by traditional online programming platforms. The pay as you go mode of Serverless architecture can further reduce the cost on the premise of ensuring the performance of online programming functions. Therefore, the development of online programming function through Serverless architecture is gradually concerned and studied by more and more people. This paper will take Alibaba cloud function computing as an example, implement an online programming function of Python language through Serverless architecture, and further optimize this function to make it closer to the local code execution experience.
Online programming function development
A relatively simple and typical online programming function, the online execution module usually requires the following capabilities:
- Execute code online
- Users can enter content
- Can return results (standard output, standard error, etc.)
In addition to the functions required for online programming, the business logic required for online programming under the Serverless architecture can only be converged to the code execution module: obtain the program information sent by the client (including code, standard input, etc.), cache the code locally, execute the code, obtain the results, but give it to the client, The flow chart of the whole architecture is as follows:
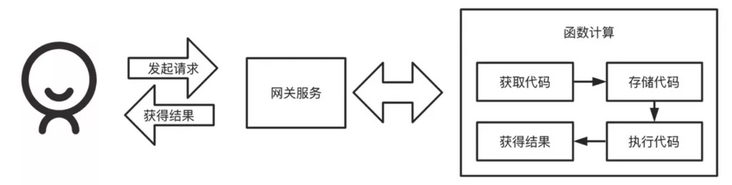
The code execution part can be implemented through the Popen() method in the subprocess dependency of Python language. When using the Popen() method, there are several important concepts that need to be clarified:
- subprocess.PIPE: a special value that can be used for Popen's stdin, stdout and stderr parameters, indicating that a new pipe needs to be created;
- subprocess.STDOUT: an output value that can be used for Popen's stderr parameter, indicating that the standard errors of the subroutine are merged into the standard output;
So when we want to achieve this, we can:
Carry out standard input (stdin), obtain standard output (stdout) and standard error (stderr)
The code can be simplified to:
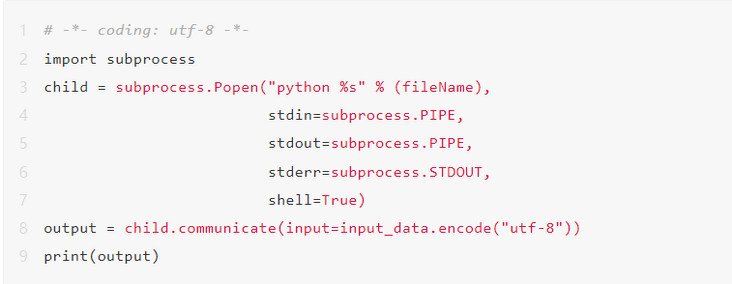
In addition to the code execution part, in the Serverless architecture, you need to pay extra attention to the read and write permissions of the directory in the function instance when you get the user code and store it in the procedure. Normally, in function calculation, only the / tmp / directory has write permission if the hard disk is not mounted. Therefore, in this project, when we temporarily store the code passed from the user to the server, we need to write it to the temporary directory / tmp /. When temporarily storing the code, we also need to consider the instance reuse. Therefore, at this time, we can provide a temporary file name for the temporary code, such as:
# -*- coding: utf-8 -*-
import randomrandom
Str = lambda num=5: "".join(random.sample('abcdefghijklmnopqrstuvwxyz', num))
path = "/tmp/%s"% randomStr(5)The complete code implementation is:
# -*- coding: utf-8 -*-
import json
import uuid
import random
import subprocess
# Random string
randomStr = lambda num=5: "".join(random.sample('abcdefghijklmnopqrstuvwxyz', num))
# Response
class Response:
def __init__(self, start_response, response, errorCode=None):
self.start = start_response
responseBody = {
'Error': {"Code": errorCode, "Message": response},
} if errorCode else {
'Response': response
}
# uuid is added by default to facilitate later positioning
responseBody['ResponseId'] = str(uuid.uuid1())
self.response = json.dumps(responseBody)
def __iter__(self):
status = '200'
response_headers = [('Content-type', 'application/json; charset=UTF-8')]
self.start(status, response_headers)
yield self.response.encode("utf-8")
def WriteCode(code, fileName):
try:
with open(fileName, "w") as f:
f.write(code)
return True
except Exception as e:
print(e)
return False
def RunCode(fileName, input_data=""):
child = subprocess.Popen("python %s" % (fileName),
stdin=subprocess.PIPE,
stdout=subprocess.PIPE,
stderr=subprocess.STDOUT,
shell=True)
output = child.communicate(input=input_data.encode("utf-8"))
return output[0].decode("utf-8")
def handler(environ, start_response):
try:
request_body_size = int(environ.get('CONTENT_LENGTH', 0))
except (ValueError):
request_body_size = 0
requestBody = json.loads(environ['wsgi.input'].read(request_body_size).decode("utf-8"))
code = requestBody.get("code", None)
inputData = requestBody.get("input", "")
fileName = "/tmp/" + randomStr(5)
responseData = RunCode(fileName, inputData) if code and WriteCode(code, fileName) else "Error"
return Response(start_response, {"result": responseData})After writing the core business logic, we can deploy the code to alicloud function computing. After deployment, we can get the temporary test address to the interface. Test the interface through PostMan. Take the output statement of Python language as an example:
print('HELLO WORLD')
It can be seen that when we initiate a request through the POST method with code as parameters, the response obtained is:
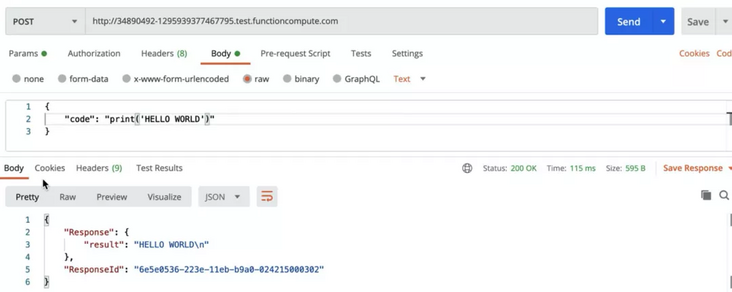
Through the response results, we can see that the system can normally output our expected results: "HELLO WORLD" so far, we have completed the test of standard output function. Next, we test the functions such as standard error. At this time, we destroy the output code just now:
print('HELLO WORLD)
Use the same method to execute the code again, and you can see the results:
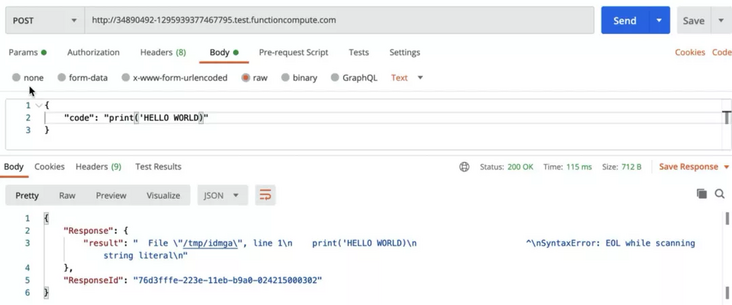
In the results, we can see that the error message of Python is in line with our expectations. So far, we have completed the test of the standard error function of the online programming function. Next, we test the standard input function because we use the subprocess Popen () method is a blocking method, so at this time, we need to put the code and standard input together on the server. The test code is:
tempInput = input('please input: ')
print('Output: ', tempInput)The standard input of the test is: "serverless devs".
When we use the same method to initiate a request, we can see:
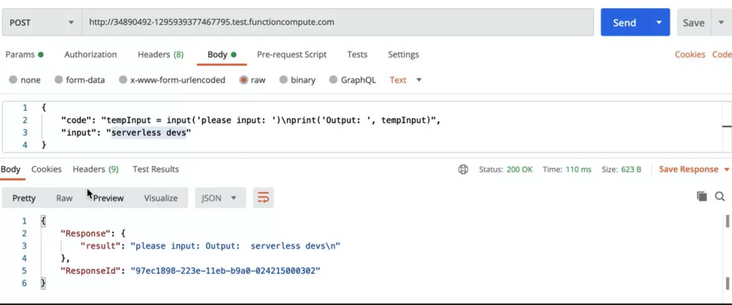
The system normally outputs the expected results. So far, we have completed a very simple online programming service interface. At present, this interface is only a preliminary version and is only used for learning. It has great optimization space:
- Processing of timeout
- Code execution is complete and can be cleaned up
Of course, we can also see such a problem through this interface: the code execution process is blocked. We can't make continuous input or real-time output. Even if we need to input content, we need to send the code and input content to the server together. This mode is very similar to the OJ mode commonly used in the market at present, but for simple online programming, it needs to further optimize the project so that it can realize code execution through non blocking method, and can continuously input and output content.
Closer to "local" code executors
Let's take a piece of code as an example:
import time
print("hello world")
time.sleep(10)
tempInput = input("please: ")
print("Input data: ", tempInput)When we execute this Python code locally, the actual performance of the overall user side is:
- System output hello world
- The system waits 10 seconds
- The system reminds us to please, and we can enter a string at this time
- The system outputs Input data and the string we just entered
However, if this code is applied to the traditional OJ or the online programming system we just implemented, the performance is very different:
- The code is passed to the simultaneous interpreting system.
- The system waits 10 seconds
- Output hello world, please, and finally Input data and what we input
It can be seen that there is a big gap between the online programming function of OJ mode and the local programming function, at least at the experience level. In order to reduce the problem of inconsistent experience, we can further upgrade the above architecture through asynchronous triggering of functions and pexpect. In Python language The spawn () method implements an online programming function closer to the local experience:

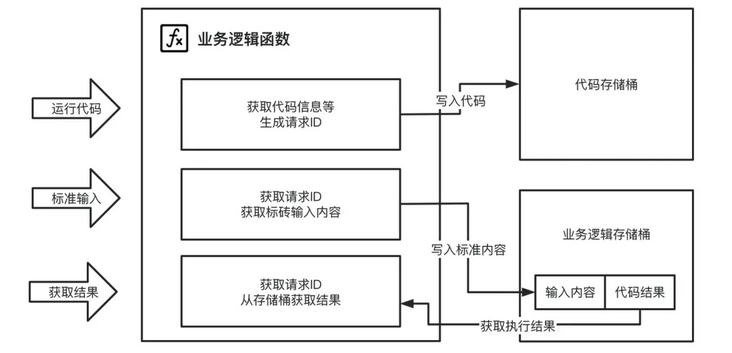
In the whole project, it includes two functions and two buckets:
- Business logic function: the main operation of this function is business logic, including creating tasks executed by code (asynchronous function execution through object storage trigger), obtaining function output results and performing relevant operations on the standard input of task function;
- Actuator function: the main function of this function is to execute the user's function code. This part is triggered by object storage, through downloading code, executing code, obtaining input and output results, etc; Code acquisition from the code storage bucket, output results and acquisition input from the service storage bucket;
- Code bucket: the bucket is used to store code. When a user initiates a request to run code, the business logic function will store the code in the bucket after receiving the user code, and then the bucket will punish the asynchronous task;
- Business bucket: this bucket is used for intermediate output, mainly including output content cache and input content cache; The life cycle of this part of data can be formulated through the characteristics of object storage;
In order to make the code execute online and closer to the local experience, the code of the scheme is divided into two functions for business logic processing and online programming.
The business logic processing functions mainly include:
- Obtain the user's code information, generate the code execution ID, save the code to the object storage, asynchronously trigger the execution of the online programming function, and return the generated code execution ID;
- Obtain the user's input information and code execution ID, and store the content in the corresponding object storage;
- Obtain the output result of the code, read the execution result from the object storage according to the code execution ID specified by the user, and return it to the user;
The overall business logic is:
The implementation code is:
# -*- coding: utf-8 -*-
import os
import oss2
import json
import uuid
import random
# Basic configuration information
AccessKey = {
"id": os.environ.get('AccessKeyId'),
"secret": os.environ.get('AccessKeySecret')
}
OSSCodeConf = {
'endPoint': os.environ.get('OSSConfEndPoint'),
'bucketName': os.environ.get('OSSConfBucketCodeName'),
'objectSignUrlTimeOut': int(os.environ.get('OSSConfObjectSignUrlTimeOut'))
}
OSSTargetConf = {
'endPoint': os.environ.get('OSSConfEndPoint'),
'bucketName': os.environ.get('OSSConfBucketTargetName'),
'objectSignUrlTimeOut': int(os.environ.get('OSSConfObjectSignUrlTimeOut'))
}
# Obtain / upload files to the temporary address of OSS
auth = oss2.Auth(AccessKey['id'], AccessKey['secret'])
codeBucket = oss2.Bucket(auth, OSSCodeConf['endPoint'], OSSCodeConf['bucketName'])
targetBucket = oss2.Bucket(auth, OSSTargetConf['endPoint'], OSSTargetConf['bucketName'])
# Random string
randomStr = lambda num=5: "".join(random.sample('abcdefghijklmnopqrstuvwxyz', num))
# Response
class Response:
def __init__(self, start_response, response, errorCode=None):
self.start = start_response
responseBody = {
'Error': {"Code": errorCode, "Message": response},
} if errorCode else {
'Response': response
}
# uuid is added by default to facilitate later positioning
responseBody['ResponseId'] = str(uuid.uuid1())
self.response = json.dumps(responseBody)
def __iter__(self):
status = '200'
response_headers = [('Content-type', 'application/json; charset=UTF-8')]
self.start(status, response_headers)
yield self.response.encode("utf-8")
def handler(environ, start_response):
try:
request_body_size = int(environ.get('CONTENT_LENGTH', 0))
except (ValueError):
request_body_size = 0
requestBody = json.loads(environ['wsgi.input'].read(request_body_size).decode("utf-8"))
reqType = requestBody.get("type", None)
if reqType == "run":
# Run code
code = requestBody.get("code", None)
runId = randomStr(10)
codeBucket.put_object(runId, code.encode("utf-8"))
responseData = runId
elif reqType == "input":
# Input content
inputData = requestBody.get("input", None)
runId = requestBody.get("id", None)
targetBucket.put_object(runId + "-input", inputData.encode("utf-8"))
responseData = 'ok'
elif reqType == "output":
# Get results
runId = requestBody.get("id", None)
targetBucket.get_object_to_file(runId + "-output", '/tmp/' + runId)
with open('/tmp/' + runId) as f:
responseData = f.read()
else:
responseData = "Error"
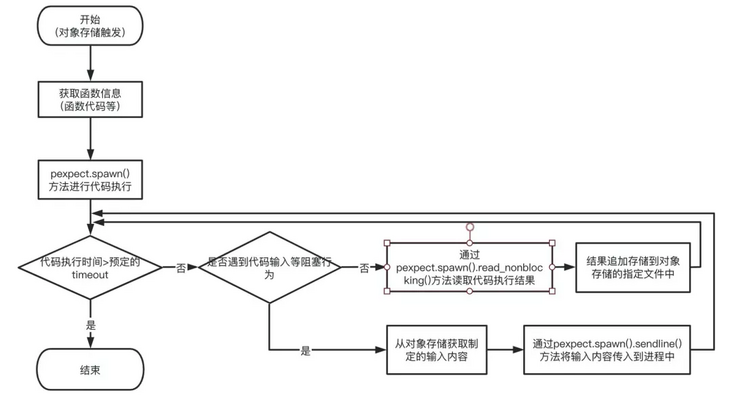
return Response(start_response, {"result": responseData})The executor function is mainly a module triggered by the code bucket to execute the code. This part mainly includes:
- Get the code from the bucket and use pexpect Spawn() for code execution;
- Through pexpect spawn(). read_ Nonblocking() obtains intermittent execution results and writes them to the object storage;
- Through pexpect spawn(). Sendline() for content input;
The overall process is:
The code implementation is:
# -*- coding: utf-8 -*-
import os
import re
import oss2
import json
import time
import pexpect
# Basic configuration information
AccessKey = {
"id": os.environ.get('AccessKeyId'),
"secret": os.environ.get('AccessKeySecret')
}
OSSCodeConf = {
'endPoint': os.environ.get('OSSConfEndPoint'),
'bucketName': os.environ.get('OSSConfBucketCodeName'),
'objectSignUrlTimeOut': int(os.environ.get('OSSConfObjectSignUrlTimeOut'))
}
OSSTargetConf = {
'endPoint': os.environ.get('OSSConfEndPoint'),
'bucketName': os.environ.get('OSSConfBucketTargetName'),
'objectSignUrlTimeOut': int(os.environ.get('OSSConfObjectSignUrlTimeOut'))
}
# Obtain / upload files to the temporary address of OSS
auth = oss2.Auth(AccessKey['id'], AccessKey['secret'])
codeBucket = oss2.Bucket(auth, OSSCodeConf['endPoint'], OSSCodeConf['bucketName'])
targetBucket = oss2.Bucket(auth, OSSTargetConf['endPoint'], OSSTargetConf['bucketName'])
def handler(event, context):
event = json.loads(event.decode("utf-8"))
for eveEvent in event["events"]:
# Get object
code = eveEvent["oss"]["object"]["key"]
localFileName = "/tmp/" + event["events"][0]["oss"]["object"]["eTag"]
# Download code
codeBucket.get_object_to_file(code, localFileName)
# Execute code
foo = pexpect.spawn('python %s' % localFileName)
outputData = ""
startTime = time.time()
# timeout can be identified by file name
try:
timeout = int(re.findall("timeout(.*?)s", code)[0])
except:
timeout = 60
while (time.time() - startTime) / 1000 <= timeout:
try:
tempOutput = foo.read_nonblocking(size=999999, timeout=0.01)
tempOutput = tempOutput.decode("utf-8", "ignore")
if len(str(tempOutput)) > 0:
outputData = outputData + tempOutput
# The output data is stored in oss
targetBucket.put_object(code + "-output", outputData.encode("utf-8"))
except Exception as e:
print("Error: ", e)
# Input request blocked
if str(e) == "Timeout exceeded.":
try:
# Reading data from oss
targetBucket.get_object_to_file(code + "-input", localFileName + "-input")
targetBucket.delete_object(code + "-input")
with open(localFileName + "-input") as f:
inputData = f.read()
if inputData:
foo.sendline(inputData)
except:
pass
# Program execution completion output
elif "End Of File (EOF)" in str(e):
targetBucket.put_object(code + "-output", outputData.encode("utf-8"))
return True
# The program threw an exception
else:
outputData = outputData + "\n\nException: %s" % str(e)
targetBucket.put_object(code + "-output", outputData.encode("utf-8"))
return FalseAfter we finish writing the core business logic, we can deploy the project online.
After the project deployment is completed, the interface is tested through PostMan, just like the test method above. At this time, we need to set a test code that can cover a wide range, including output printing, input, some sleep() methods:

After we initiate a request to execute this code through PostMan, we can see that the system returns the expected code execution ID for us:
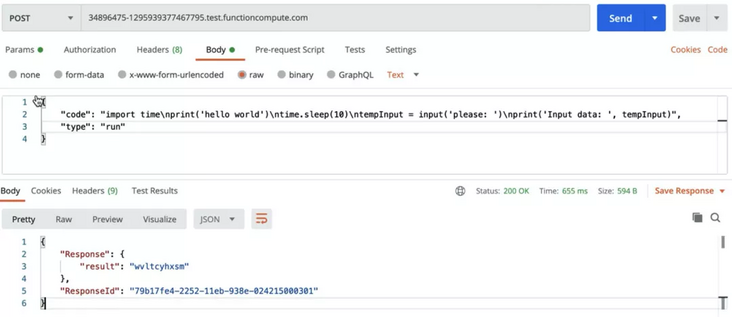
We can see that the system will return us a code execution ID, which will be used as the ID of our entire request task. At this time, we can obtain the results through the interface to obtain the output results:
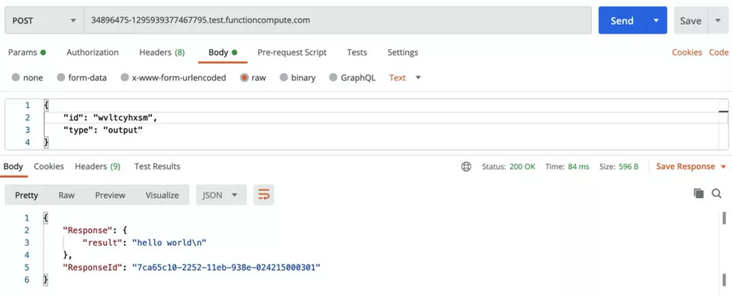
Because the code contains:
time.sleep(10)
Therefore, we can't see the output results of the second half when we get the results quickly. We can set a rotation training task and constantly refresh the interface through this ID:
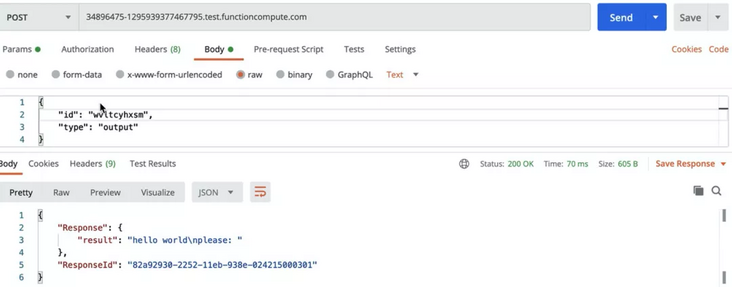
You can see that after 10 seconds, the code executes to the input part:
tempInput = input('please: ')
At this time, we can input through the input interface:
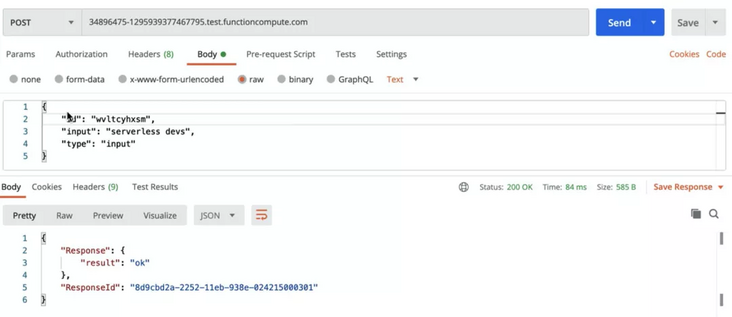
After completion, we can see the result of successful input (result: ok). At this time, we continue to refresh the previous request to obtain the result:
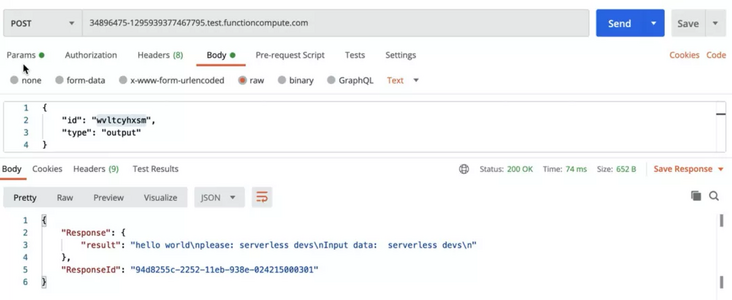
As you can see, we have obtained the output of all results.
Compared with the online programming function above, this "closer to the local code executor" becomes much more complex, but in the process of actual use, it can better simulate some phenomena of local code execution, such as code hibernation, blocking, content output, etc.
summary
Whether it's a simple online code executor or a more "local" code executor, this article has a relatively wide range of applications. Through this article, you can see:
- The basic usage of HTTP trigger; the basic user of object storage trigger;
- Basic usage of function calculation component and object storage component, and implementation method of dependency between components;
At the same time, through this article, you can also see a simple answer to such a common question from one side: I have a project. Do I have a function for each interface or reuse a function for multiple interfaces?
To solve this problem, the most important thing is to look at the demands of the business itself. If the meanings expressed by multiple interfaces are the same, or similar, and the resource consumption of multiple interfaces is similar, it is entirely possible to distinguish them through different paths in one function; If the resource consumption gap is large, or the function type, scale and category are too different, it is no problem to put multiple interfaces under multiple functions.
In fact, this article is to attract jade. Whether it is the "problem judging machine" part of OJ system or the "actuator part" of online programming tools, it can have an interesting combination with Serverless architecture. This combination point can not only solve the headache of traditional online programming (security problems, resource consumption problems, concurrency problems, traffic instability problems), but also bring the value of Serverless into play in a new field.
Original link
This article is the original content of Alibaba cloud and cannot be reproduced without permission.