It was a pleasant Saturday afternoon, and after adding hours of free work to the company, I suddenly wanted to see a movie, but as a junior engineer, how can I make as much money as those senior engineer s to go to the cinema and spend it?(Officer COS: Movies are reluctant to see. It's so grand, so special!)
First let's learn the English name of duplicate 4 Avengers: Endgame
Avengers: Avengers
Endgame: final stage, end
So from here on we'll call this movie AE.
AE is shown on XXX month xx day of XXX year, director XXX, I don't compile it anymore. Click on the link below to read it yourself.
https://movie.douban.com/subject/26100958/
Anyway, the names of those actors can't be remembered except Robert Downey Jr., because the Iron Man is said to be based on Tesla's founder XXX. Well, actually it's hard for me to remember the names of foreigners.
Well, here's where I officially start my movie journey with data.
The first step we need to collect data is to use a crawler to grab the data from the bean web.
Before crawling data, you need to look at what the data looks like on the website and estimate what data can be crawled into.
This screenshot above is from the previous introductory link, where the data in the red area is the data that must be crawled this time, and the data in the yellow area is Nice to have.
In addition to this basic introduction page, Douban has a special movie review page:
https://movie.douban.com/subject/26100958/reviews
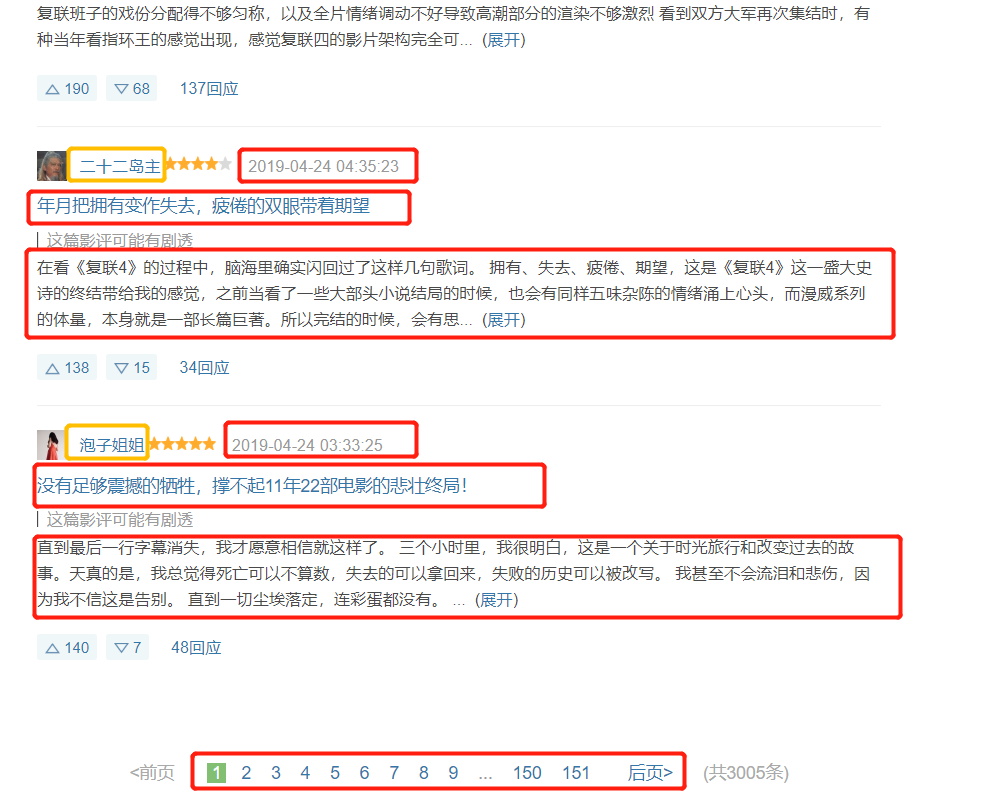
The data to be crawled is also shown in red and yellow boxes.
Okay, the goal for the first step here is set. Next, use the tool to look at the source of Douban Web page.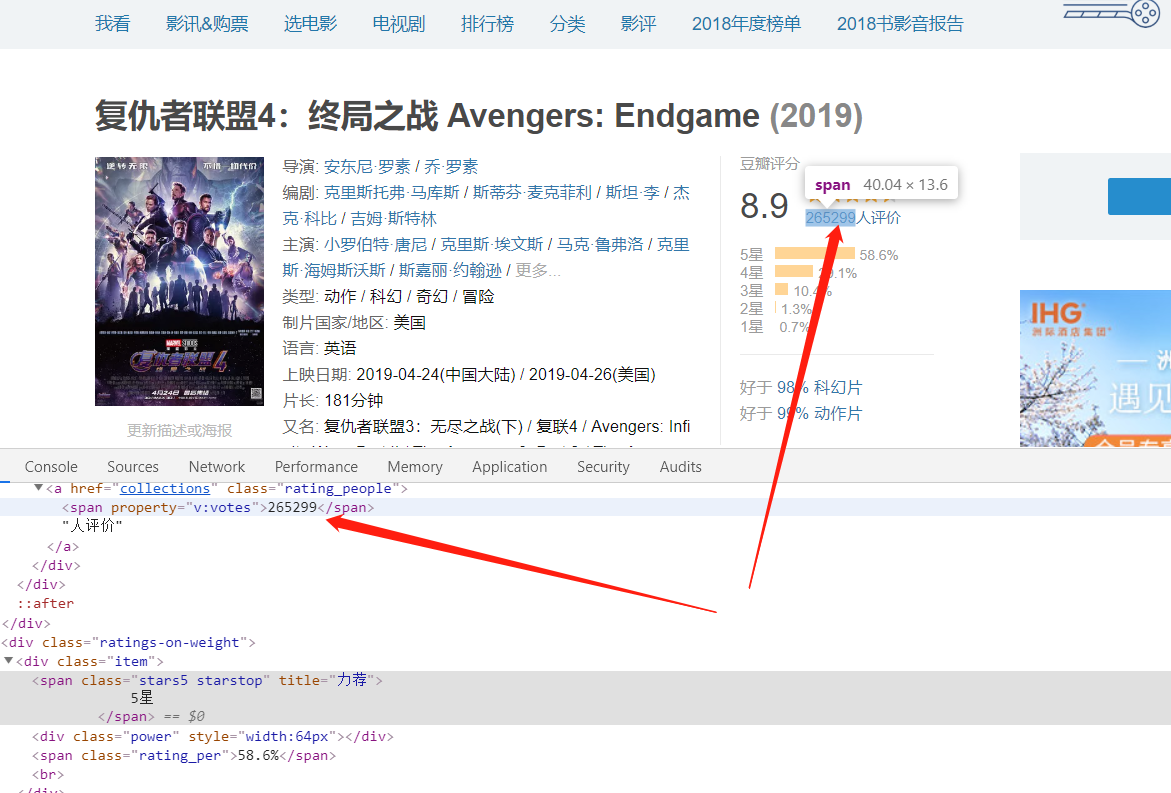
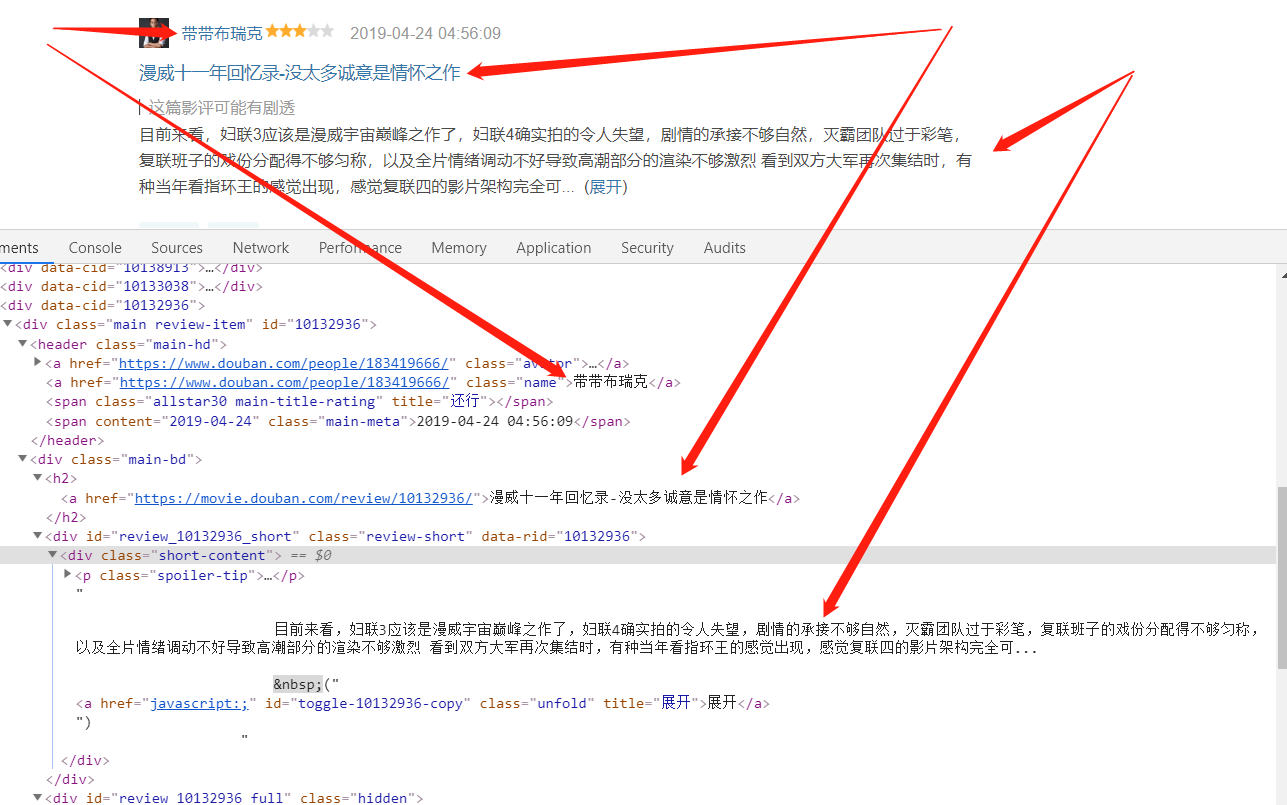
From the source code, basically set the target data can be crawled, except for the expansion function of the movie review, this crawl will not get all the movie reviews first.Of course, the current scenario does not take into account what Douban does in anti-crawling technology.(Non-technicians can skip this section with O() OHA~)
Let's not talk much about this, but start writing crawlers (I found out that the bean petals were anti-crawlers after writing, and I still don't think about how to solve them, but my little brother disagrees. This flag stands here first...
1. Get your own cookie s
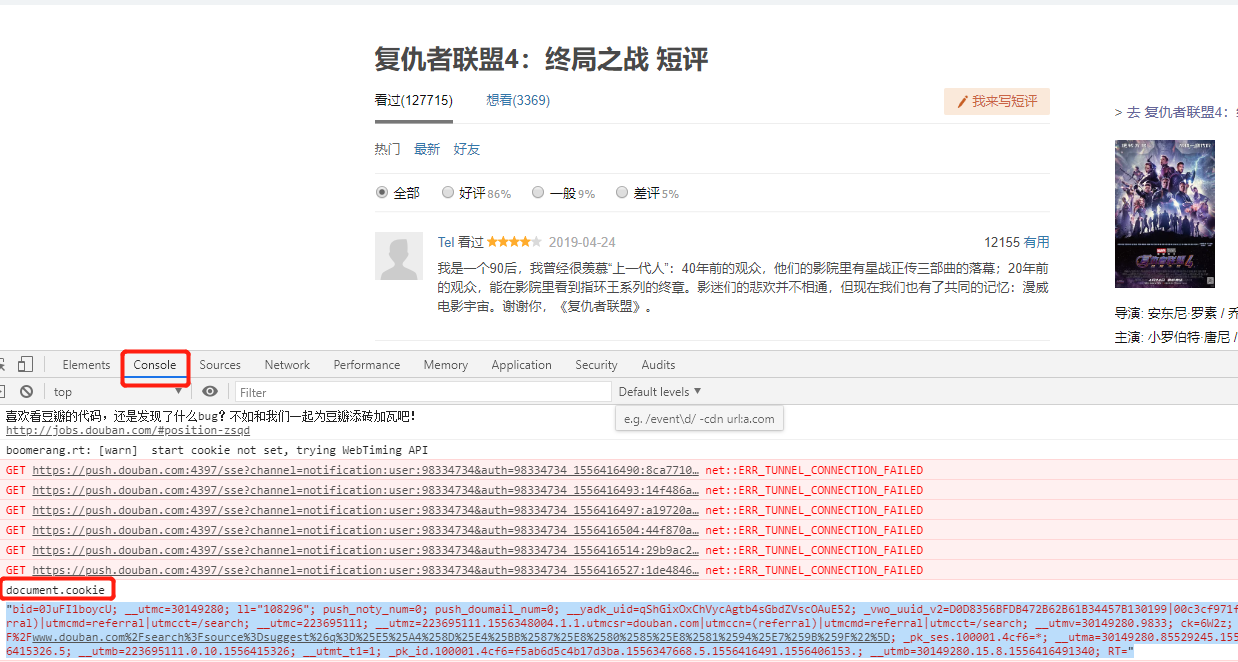
Open Chrome, find the developer tool or press F12, select the cookie tab, and enter document.cookie to get the cookie you access at this time. This cookie only lasts a few minutes and changes frequently, so grab it before running the program.
2. basic info crawling home page
First, right-click download this page so that you can see the source code locally and debug it yourself.
Codes for crawling data are pasted here, and other code can be downloaded from my GitHub.
# Get information about the home page
def get_home_info(url):
html = get_html(url)
doc = pq(html)
# movie_name = doc('#content h1 span').text()
movie = doc('#content h1 span').items()
movie_info = [x.text() for x in movie]
final_rate = doc('.ll.rating_num').text()
total_people = doc('.rating_people span').text()
rating = doc('.item span').items()
rating_info = [x.text() for x in rating]
res = [movie_info, final_rate, total_people, rating_info]
return res
3. Click the user, time, comments of the comments page
This page is slightly more complicated. In fact, the biggest problem is that only 12 pages are accessible. I hope you shrimps can give some guidance.
# return a dataframe
def parse_content(html):
doc = pq(html)
users = doc('.avatar a').items()
users_herf = doc('.avatar a').items()
comment_votes = doc('.comment-vote span').items()
comment_time = doc('.comment-time').items()
comment_content = doc('.comment-item p').items()
res_df = df(columns=['user_name', 'user_url', 'comment_votes', 'comment_time', 'comment_content'])
res_df['user_name'] = [u.attr('title') for u in users]
res_df['user_url'] = [h.attr('href') for h in users_herf]
res_df['comment_votes'] = [v.text() for v in comment_votes]
res_df['comment_time'] = [h.attr('title') for h in comment_time]
res_df['comment_content'] = [v.text() for v in comment_content]
return res_df
4. Crawl basic info on user home page
Based on the URL of the user Home page that was previously crawled, and then to crawl its basic information, only the user's registered address is crawled here.
# Get user's location
def get_user_info(url):
html = get_html(url)
doc = pq(html)
location = doc('.user-info a')
return location.text(), location.attr('href')
5. Crawling basic information for the home page
This step is actually a redundant operation, and I don't need a lot of information for the home page, just write it to death.
But do you think I'll only get hot in this movie?Oh o() o, young man!!!
def get_home_info(url):
html = get_html(url)
doc = pq(html)
# movie_name = doc('#content h1 span').text()
movie = doc('#content h1 span').items()
movie_info = [x.text() for x in movie]
final_rate = doc('.ll.rating_num').text()
total_people = doc('.rating_people span').text()
rating = doc('.item span').items()
rating_info = [x.text() for x in rating]
res = [movie_info, final_rate, total_people, rating_info]
return res
Part Two Data Analysis Stage