What is feature engineering?
Feature engineering is a process that uses professional background knowledge and skills to process data, so that features can play a better role in machine learning algorithms.
- Significance: it will directly affect the effect of machine learning
Contents of Feature Engineering:
- feature extraction
- Feature preprocessing
- Feature dimensionality reduction
feature extraction
Machine learning algorithms – statistical methods – mathematical formulas
Text type - > numeric
Type ----- > value
Feature extraction of dictionary
sklearn.feature_extraction.DictVectorizer(sparse=True...)
vector Vector, vector Matrix: matrix Two dimensional array Vector: vector One dimensional array Parent class: converter class return sparse Matrix (sparse matrix) Application scenario: 1>There are many category features in the dataset * The characteristics of the dataset-----> Dictionary type * DictVectorizer transformation 2>The data obtained by itself is the dictionary type
supplement
Sparse matrix: represent non-zero values by position
Save memory and improve loading efficiency
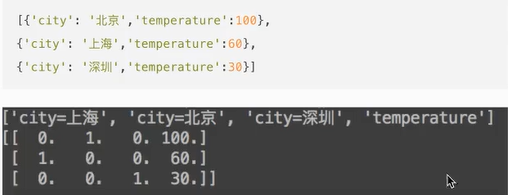
def dict_demo():
'''
Dictionary eigenvalue extraction
:return:
'''
data = [{'city':'Beijing','temperature':100},{'city':'Shanghai','temperature':60},
{'city':'Shenzhen','temperature':30}]
#1. Instantiate a converter class
transfer1 = DictVectorizer(sparse=True)
transfer2 = DictVectorizer(sparse=False)
#2. Call fit_transform()
data_new1 = transfer1.fit_transform(data)
data_new2 = transfer2.fit_transform(data)
print("data_new1:\n",data_new1)
print("data_new2:\n",data_new2)
if __name__ == "__main__":
# Use of sklearn() dataset
# datasets_demo()
#Extraction of dictionary eigenvalues
dict_demo()

Feature extraction of text
Words as features (sentences, phrases, words, letters...)
- Method 1: CountVectorizer
Count the number of feature words in each sample- be careful:
- Some parameters: stop_words stop words, words not included in feature words
- A Chinese sentence without spaces will be regarded as a feature word
- Single letter or Chinese is not included in the characteristic value
Key words: in a certain category of articles, there are many times, but there are few in other categories of articles
- be careful:
- Method 2: TfidfVectorizer
*TF-IDF – importance
*TF - word frequency
*IDF - reverse document frequency
*Return value: sparse matrix
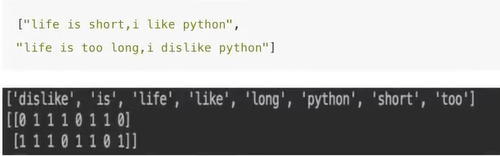
Method 1: CountVectorizer
def count_demo():
'''
Text feature extraction
:return:
'''
data = ["life is short,i like like python",
"life is too long,i dislike python"]
#1. Instantiate a converter class
transfer = CountVectorizer()
#2. Call fit_transform()
data_new = transfer.fit_transform(data)
print("data_new:\n", data_new.toarray())
# Word dictionary
print("\n",transfer.get_feature_names())
return None
if __name__ == "__main__":
#Extraction of text eigenvalues
count_demo()
#Note: single letters are not supported

def count_cn_demo():
'''
Text feature extraction
:return:
'''
data1 = ["I Love Beijing Tiananmen ",
"The sun rises on Tiananmen Square"]
data2 = ["I love Beijing Tiananmen Square",
"The sun rises on Tiananmen Square"]
#1. Instantiate a converter class
transfer = CountVectorizer()
#2. Call fit_transform()
data_new1 = transfer.fit_transform(data1)
print("data_new1:\n", data_new1.toarray())
# Word dictionary
print(transfer.get_feature_names())
print("~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~`")
data_new2 = transfer.fit_transform(data2)
print("data_new2:\n", data_new2.toarray())
# Word dictionary
print( transfer.get_feature_names())
return None
if __name__ == "__main__":
#Extraction of Chinese text eigenvalues
count_cn_demo()
#Note: single Chinese is not supported

Advanced
Automatic Chinese word segmentation
def cut_word(text):
'''
Chinese word segmentation:"I Love Beijing Tiananmen "---->"I love Beijing Tiananmen Square"
:param text:
:return:
'''
# a = " ".join(list(jieba.cut(text)))
# print(a)
return " ".join(list(jieba.cut(text)))
def count_cn_demo2():
'''
Chinese text, feature extraction, automatic word segmentation
:return:
'''
data = ["One or another, today is cruel, tomorrow is more cruel, and the day after tomorrow is beautiful, but most of them die tomorrow night, so everyone should not give up today.",
"The light we see from distant galaxies was emitted millions of years ago, so when we see the universe, we are looking at its past.",
"If you only know something in one way, you won't really know it. The secret of understanding the true meaning of things depends on how to connect them with what we know."]
data_new = []
for sentence in data:
data_new.append(cut_word(sentence))
# 1. Instantiate a converter class
transfer = CountVectorizer()
# 2. Call fit_transform()
data_final = transfer.fit_transform(data_new)
print("data_new:\n", data_final.toarray())
print("Feature Name:\n",transfer.get_feature_names())
return None
if __name__ == "__main__":
#test
# data = "I love Beijing Tiananmen Square"
# cut_word(data)
#Chinese text, feature extraction, automatic word segmentation
count_cn_demo2()

Method 2: TfidfVectorizer
def tfidf_demo():
'''
use TF-IDF Method for text feature extraction
:return:
'''
data = ["One or another, today is cruel, tomorrow is more cruel, and the day after tomorrow is beautiful, but most of them die tomorrow night, so everyone should not give up today.",
"The light we see from distant galaxies was emitted millions of years ago, so when we see the universe, we are looking at its past.",
"If you only know something in one way, you won't really know it. The secret of understanding the true meaning of things depends on how to connect them with what we know."]
data_new = []
for sentence in data:
data_new.append(cut_word(sentence))
# 1. Instantiate a converter class
transfer = TfidfVectorizer()
# 2. Call fit_transform()
data_final = transfer.fit_transform(data_new)
print("data_new:\n", data_final.toarray())
print("Feature Name:\n", transfer.get_feature_names())
return None
if __name__ == "__main__":
# Use of sklearn() dataset
# datasets_demo()
#Extraction of dictionary eigenvalues
# dict_demo()
#Extraction of text eigenvalues
# count_demo()
#Extraction of Chinese text eigenvalues
# count_cn_demo()
#test
# data = "I love Beijing Tiananmen Square"
# cut_word(data)
#Chinese text, feature extraction, automatic word segmentation
# count_cn_demo2()
# Text feature extraction using TF-IDF method
tfidf_demo()
Feature preprocessing
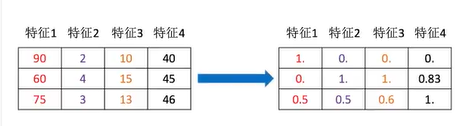
The process of converting feature data into feature data more suitable for the algorithm model through some conversion functions
Content included
- Unlimited tempering of numerical data:
- normalization
- Standardization
- Feature preprocessing API
sklearn.preprocessing
normalization
Outliers: maximum and minimum
When this happens, the result is obviously abnormal

For example:
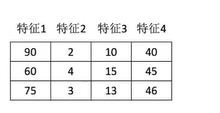
x' = (90-60)/(90-60) = 1 x'' = 1*1+0 = 1
def minmax_demo():
'''
normalization
:return:
'''
#1. Obtain data
data = pd.read_csv("dating.txt")
# print(data)
data = data.iloc[:,:3] #Only the first three columns of data are retrieved
#2. Instantiate a converter type
transfer = MinMaxScaler() #Default 0-1
#3. Call fit_transform
data_new = transfer.fit_transform(data)
print("data_new:\n",data_new)
return None
if __name__ == "__main__":
# normalization
minmax_demo()
Standardization
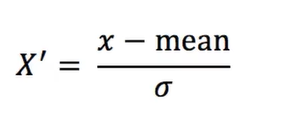
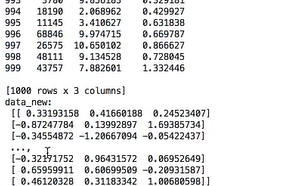
def stand_demo():
'''
Standardization
:return:
'''
# 1. Obtain data
data = pd.read_csv("dating.txt")
# print(data)
data = data.iloc[:, :3] # Only the first three columns of data are retrieved
# 2. Instantiate a converter type
transfer = StandardScaler() # Default 0-1
# 3. Call fit_transform
data_new = transfer.fit_transform(data)
print("data_new:\n", data_new)
return None
if __name__ == "__main__":
#Standardization
stand_demo()
Feature dimensionality reduction
Lowered objects: 2D arrays
Dimension reduction: reduce the number of features
Effect: features are not related to features
Two methods of dimensionality reduction
- feature selection
- principal component analysis
feature selection
The data contains redundant or related variables (or features, attributes, indicators, etc.) in order to find out the main features from the original features.
- Filter: it mainly explores the characteristics of the feature itself, the relationship between the feature and the feature and the target value.
*Variance selection method: low variance feature filtering
*Correlation coefficient: the degree of correlation between features - Embedded: the algorithm automatically selects features (the association between features and target values).
*Decision tree: information entropy and information gain
*Regularization
*Deep learning