preface
Purchase discount https://m.fenfaw.cn/Let's talk about a little thing first. Today I tried to make a motion map. It took me an hour to make a motion map, and it was ugly..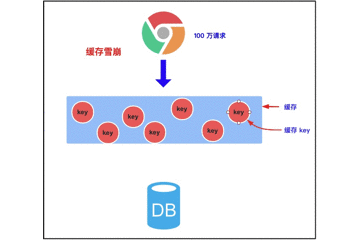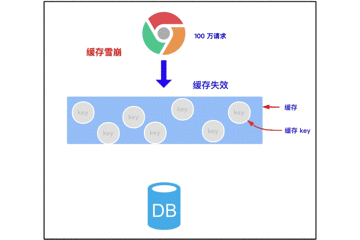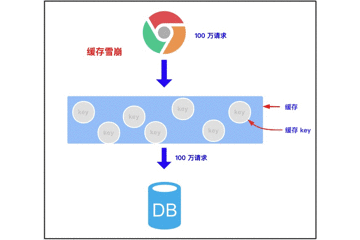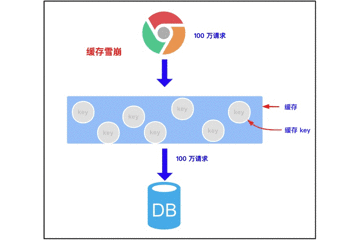
The main contents of this paper are as follows:
The previous article talked about how to do performance tuning, such as indexing tables, separating dynamic and static, and reducing unnecessary log printing. However, there is a powerful optimization method not mentioned, that is to add cache, such as querying the advertising space configuration of small programs, because no one will change it frequently. It is perfect to throw the advertising space configuration into the cache. Then let's add cache to PassJava, an open source Spring Cloud practical project, to improve performance.
I uploaded the back end, front end and small programs to the same warehouse. You can access them through github or code cloud. The address is as follows:
Github: https://github.com/Jackson0714/PassJava-Platform
Code cloud: https://gitee.com/jayh2018/PassJava-Platform
Supporting course: www.passjava.com cn
Before the actual combat, let's take a look at the principles and problems of using cache.
1, Cache
1.1 why cache
20 years ago, the common systems were stand-alone, such as ERP system, which did not require high performance, and it was not common to use cache. But now, it has entered the Internet era, and high concurrency, high availability and high performance have always been mentioned, which is the credit of the "three highs" neutrality.
We will put some data into the cache to improve the access speed, and then the database will undertake the work of storage.
So what data is suitable for caching?
-
Immediacy. For example, query the latest logistics status information.
-
Data consistency requirements are not high. For example, after the store information is modified, it has been changed in the database. It will be the latest in the cache after 5 minutes, but it will not affect the use of functions.
-
Large number of visits and low update frequency. For example, the advertising information and visits on the home page will not change often.
When we want to query data, the process of using cache is as follows:
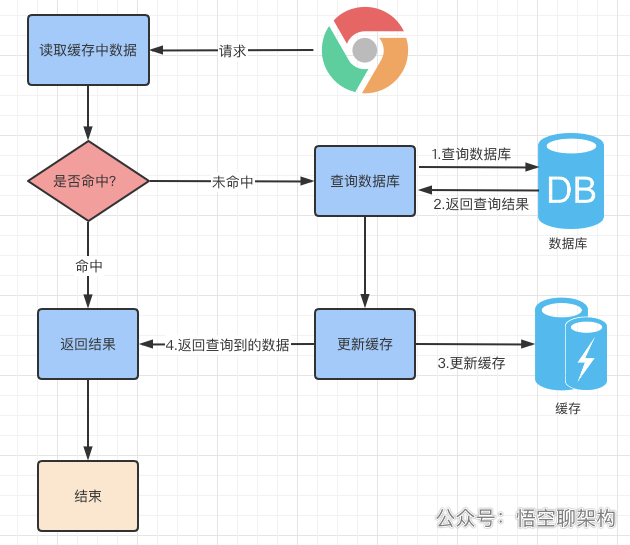
1.2 local cache
The simplest way to use cache is to use local cache.
For example, there is a requirement that the front-end applet needs to query the type of topic, and the topic type is placed on the front page of the applet. The traffic is very high, but it is not frequently changing data, so the topic type data can be put into the cache.

The simplest way to use cache is to use local cache, that is, to cache data in memory. You can use HashMap, array and other data structures to cache data.
1.2.1 do not use cache
Let's take a look at the situation without using cache: the request from the front end first passes through the gateway, then requests to the topic micro service, then queries the database and returns the query results.
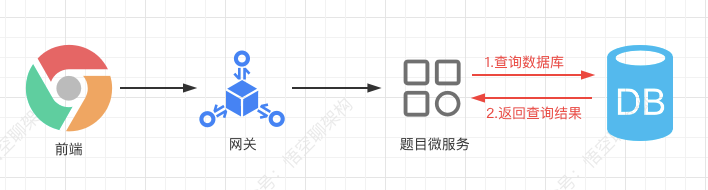
Let's look at the core code.
First customize a Rest API to query the list of topic types. The data is directly returned to the front end after being queried from the database.
@RequestMapping("/list")
public R list(){
// Query data from database
typeEntityList = ITypeService.list();
return R.ok().put("typeEntityList", typeEntityList);
}
1.2.2 using cache
Let's take a look at the use of cache: the front end first passes through the gateway, and then goes to the topic micro service. First judge whether there is data in the cache. If not, query the database, then update the cache, and finally return the query result.
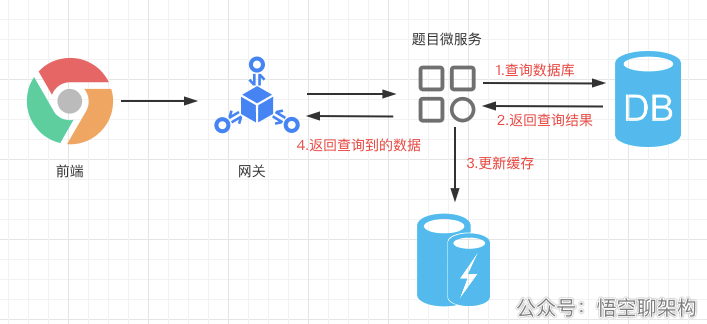
Now let's create a HashMap to cache the type list of topics:
private Map<String, Object> cache = new HashMap<>();
Get the list of cached types first
List<TypeEntity> typeEntityListCache = (List<TypeEntity>) cache.get("typeEntityList");
If not in the cache, get it from the database first. Of course, there must be no such data when querying the cache for the first time.
// If there is no data in the cache
if (typeEntityListCache == null) {
System.out.println("The cache is empty");
// Query data from database
List<TypeEntity> typeEntityList = ITypeService.list();
// Put data into cache
typeEntityListCache = typeEntityList;
cache.put("typeEntityList", typeEntityList);
}
return R.ok().put("typeEntityList", typeEntityListCache);
Let's use Postman tool to see the query results:
request URL: https://github.com/Jackson0714/PassJava-Platform
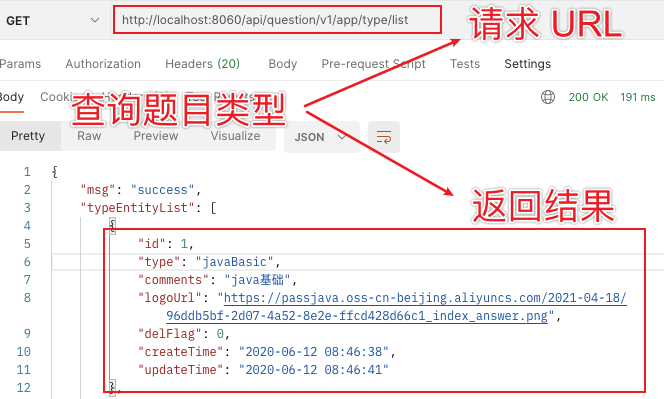
The list of topic types is returned, with 14 pieces of data in total.
When you query again in the future, because the data already exists in the cache, you can directly go to the cache and no longer query the data from the database.
From the above example, we can see what are the advantages of local caching?
- Reduce the interaction with the database and reduce the performance problems caused by disk I/O.
- Avoid database deadlock.
- Accelerate the corresponding speed.
Of course, there are some problems with local caching:
- Occupy local memory resources.
- After the machine is down and restarted, the cache is lost.
- There may be inconsistency between database data and cache data.
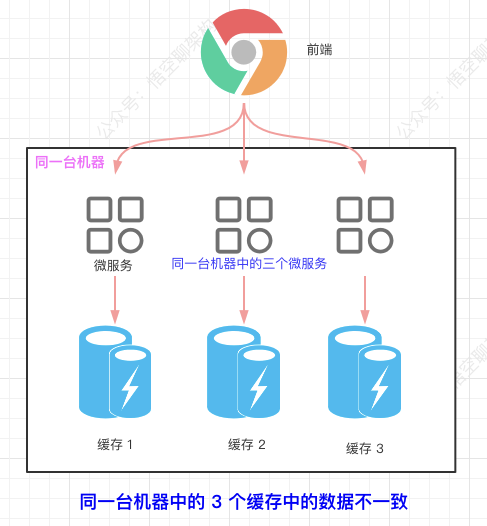
- The data cached by multiple microservices in the same machine is inconsistent.
- There is a problem of inconsistent cached data in the cluster environment.
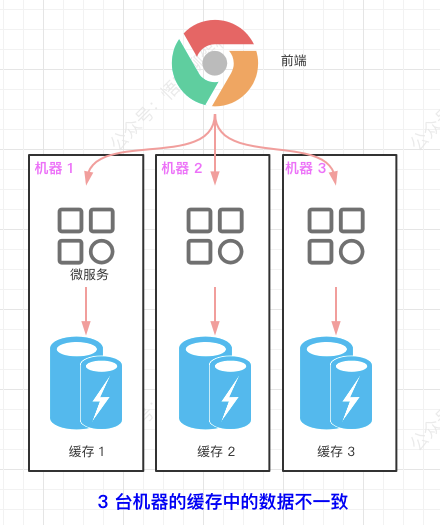
Based on the problem of local cache, we introduce distributed cache Redis to solve it.
2, Cache Redis
2.1 dock installation Redis
First, I need to install Redis. I install Redis through docker. In addition, I have installed the docker version of Redis on ubuntu and Mac M1. You can refer to these two articles for installation.
Installing redis on Docker for Ubuntu
M1 running Docker
2.2 introducing Redis components
I use the passjava question micro service, so it is the configuration file POM under the passjava question module redis component is introduced into XML.
File path: / passjava question / POM xml
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
2.3 testing Redis
We can write a test method to test whether the introduced redis can store data and whether it can find the stored data.
We all use the StringRedisTemplate library to operate Redis, so we can automatically load the StringRedisTemplate.
@Autowired StringRedisTemplate stringRedisTemplate;
Then in the test method, test the storage method: ops Set() and query method: ops get()
@Test
public void TestStringRedisTemplate() {
// Initialize redis component
ValueOperations<String, String> ops = stringRedisTemplate.opsForValue();
// Store data
ops.set("name of a fictitious monkey with supernatural powers", "Wukong chat architecture_" + UUID.randomUUID().toString());
// Query data
String wukong = ops.get("name of a fictitious monkey with supernatural powers");
System.out.println(wukong);
}
The first parameter of the set method is key, such as "Wukong" in the example.
The parameter of get method is also key.
Finally, the cached value of key = "Wukong" in redis is printed:
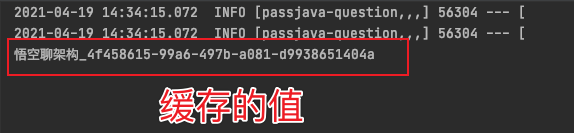
In addition, it can also be viewed through the client tool, as shown in the following figure:
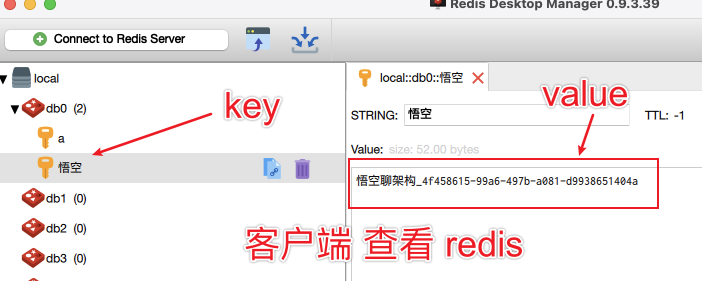
I downloaded this software: Redis Desktop Manager windows download address:
http://www.pc6.com/softview/SoftView_450180.html
2.4 transforming business logic with Redis
It's not difficult to replace hashmap with redis. Change hashmap to redis. In addition, it should be noted that:
The data queried from the database must be serialized into JSON strings before being stored in Redis. When querying data from Redis, you also need to deserialize the JSON strings into object instances.
public List<TypeEntity> getTypeEntityList() {
// 1. Initialize redis component
ValueOperations<String, String> ops = stringRedisTemplate.opsForValue();
// 2. Query data from cache
String typeEntityListCache = ops.get("typeEntityList");
// 3. If there is no data in the cache
if (StringUtils.isEmpty(typeEntityListCache)) {
System.out.println("The cache is empty");
// 4. Query data from database
List<TypeEntity> typeEntityListFromDb = this.list();
// 5. Serialize the data queried from the database into JSON strings
typeEntityListCache = JSON.toJSONString(typeEntityListFromDb);
// 6. Store the serialized data into the cache
ops.set("typeEntityList", typeEntityListCache);
return typeEntityListFromDb;
}
// 7. If there is data in the cache, take it out of the cache and deserialize it into an instance object
List<TypeEntity> typeEntityList = JSON.parseObject(typeEntityListCache, new TypeReference<List<TypeEntity>>(){});
return typeEntityList;
}
The whole process is as follows:
-
1. Initialize the redis component.
-
2. Query data from cache.
-
3. If there is no data in the cache, perform steps 4, 5 and 6.
-
4. Query data from database
-
5. Convert the data queried from the database into JSON string
-
6. Store the serialized data into the cache and return the data queried in the database.
-
7. If there is data in the cache, take it out of the cache and deserialize it into an instance object
2.5 test business logic
We still use the postman tool to test:
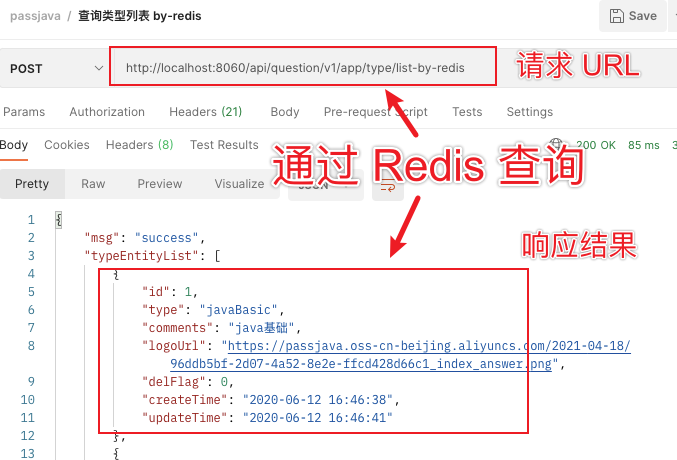
After many tests, the first request will be a little slower, and the next few times are very fast. This indicates that the performance is improved after using cache.
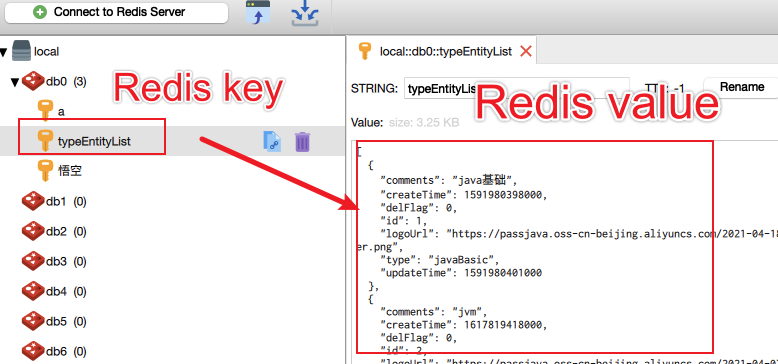
In addition, let's use Redis client to see the results:
Redis key = typeEntityList, Redis value is a JSON string, and the content in it is the subject classification list.
3, Cache penetration, avalanche, breakdown
Several problems caused by using cache in HPF: cache penetration, avalanche and breakdown.
3.1 cache penetration
3.1.1 concept of cache penetration
Cache penetration refers to a data that must not exist. If the cache misses this data, it will query the database. The database does not have this data, so the returned result is null. If every query goes to the database, the cache will lose its meaning, just like penetrating the cache.

3.1.2 risks
Attacking with nonexistent data increases the pressure on the database and eventually leads to system crash.
3.1.3 solutions
Cache the result null and add a short expiration time.
3.2 cache avalanche
3.2.1 concept of cache avalanche
Cache avalanche means that when we cache multiple pieces of data, we use the same expiration time, such as 00:00:00 expiration. If the cache fails at the same time, and a large number of requests come in, we query the database because the data is not cached. The pressure on the database increases, which will eventually lead to avalanche.
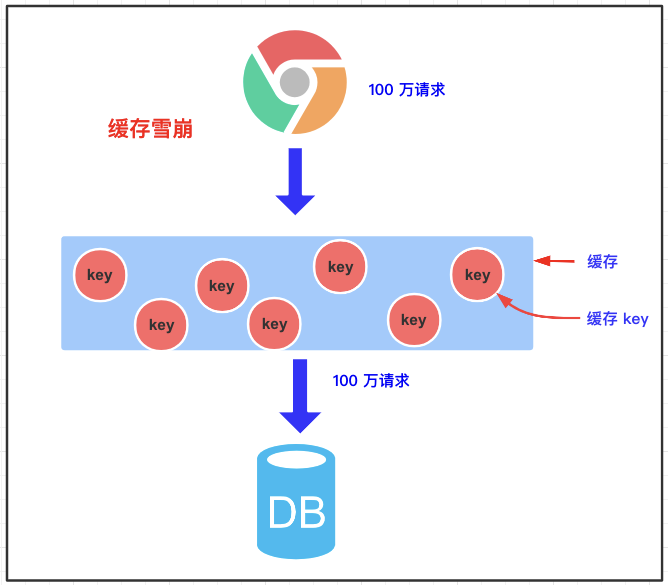
3.2.2 risks
Try to find the time when a large number of Keys expire at the same time. Carry out a large number of attacks at a certain time, increase the pressure on the database, and finally lead to the system crash.
3.2.3 solutions
On the basis of the original effective time, add a broken juice squeeze, such as 1-5 minutes random, to reduce the repetition rate of the cache expiration time and avoid the collective effect of the cache.
3.3 buffer breakdown
3.3.1 concept of buffer breakdown
A key has an expiration time set, but when it happens to expire, a large number of requests come in, resulting in requests being queried in the database.
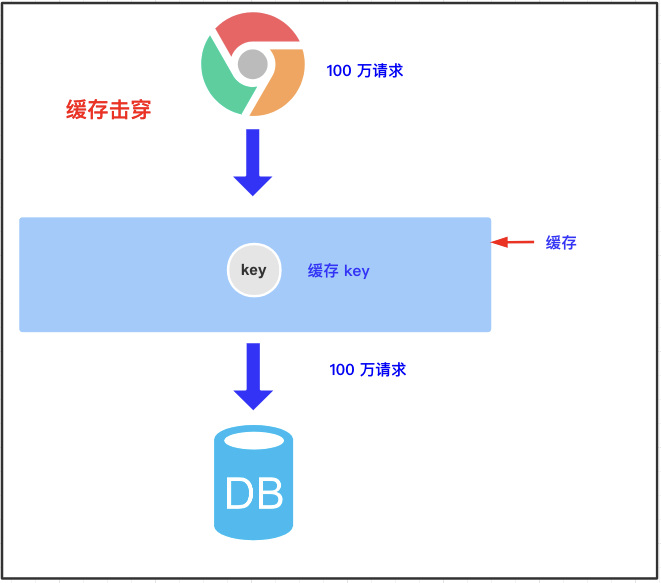
3.3.2 solutions
When there are a large number of concurrent requests, only one request can obtain the lock of the query database. Other requests need to wait and release the lock after finding it. After other requests obtain the lock, first check the cache. If there is data in the cache, you don't need to check the database.
4, Lock to solve cache breakdown
How to deal with cache penetration, avalanche and breakdown?
- Cache empty results to solve the cache penetration problem.
- Set the expiration time and add a random value for expiration offset to solve the cache avalanche problem.
- Lock to solve the problem of cache breakdown. In addition, it should be noted that locking will have an impact on performance.
Here, let's take a look at the code to demonstrate how to solve the cache breakdown problem.
We need to use synchronized to lock. Of course, this is the way of local locking. We will talk about distributed locking in the next article.
public List<TypeEntity> getTypeEntityListByLock() {
synchronized (this) {
// 1. Query data from cache
String typeEntityListCache = stringRedisTemplate.opsForValue().get("typeEntityList");
if (!StringUtils.isEmpty(typeEntityListCache)) {
// 2. If there is data in the cache, take it out of the cache, deserialize it into an instance object, and return the result
List<TypeEntity> typeEntityList = JSON.parseObject(typeEntityListCache, new TypeReference<List<TypeEntity>>(){});
return typeEntityList;
}
// 3. If there is no data in the cache, query the data from the database
System.out.println("The cache is empty");
List<TypeEntity> typeEntityListFromDb = this.list();
// 4. Serialize the data queried from the database into JSON strings
typeEntityListCache = JSON.toJSONString(typeEntityListFromDb);
// 5. Store the serialized data into the cache and return the database query results
stringRedisTemplate.opsForValue().set("typeEntityList", typeEntityListCache, 1, TimeUnit.DAYS);
return typeEntityListFromDb;
}
}
-
1. Query data from cache.
-
2. If there is data in the cache, take it out of the cache, deserialize it into an instance object, and return the result.
-
3. If there is no data in the database, query from the database.
-
4. Serialize the data queried from the database into JSON strings.
-
5. Store the serialized data into the cache and return the database query results.
5, Local lock problem
The local lock can only lock the thread of the current service. As shown in the figure below, multiple topic microservices are deployed, and each microservice is locked with a local lock.
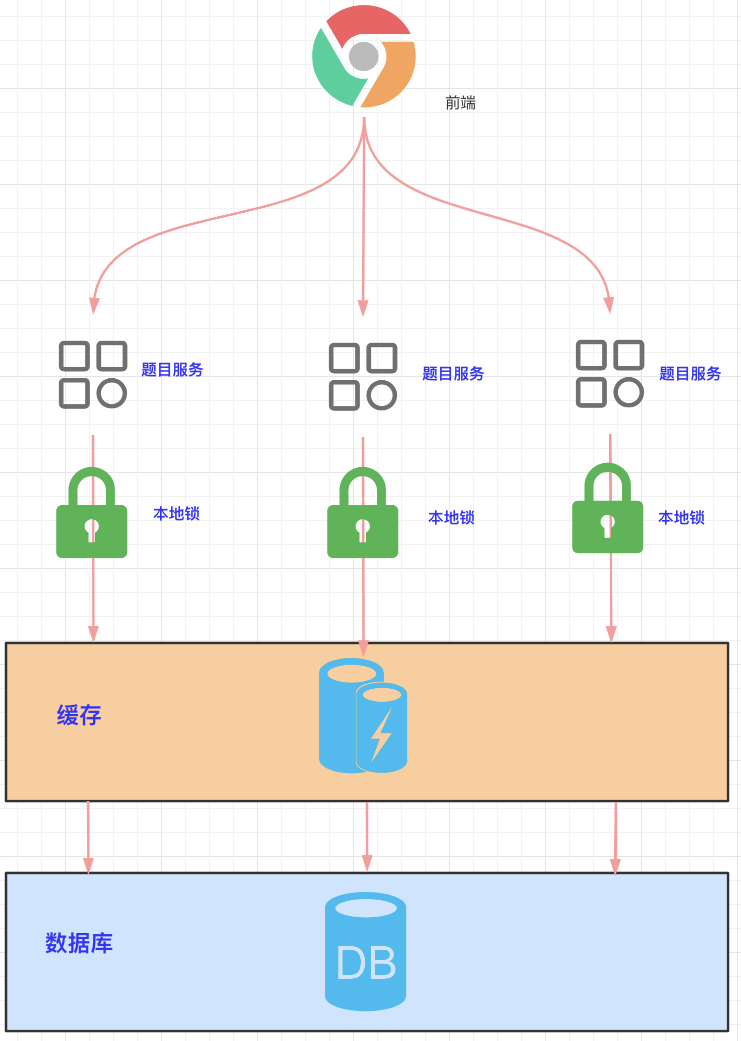
In general, there is no problem with local locks, but there is a problem when used to lock inventory:
-
1. The current total inventory is 100, which is cached in Redis.
-
2. After inventory micro service A reduces inventory by 1 with local latch, the total inventory is 99.
-
3. After inventory micro service B reduces inventory by 1 with local latch, the total inventory is 99.
-
4. After the inventory is deducted twice, it is still 99, and it is oversold by 1.
How to solve the problem of local locking?
Cache combat (Part 2): Combat distributed locks.