Traditional databases are difficult to deal with complex multi hop relational operations. A relational computing database that supports massive, complex and flexible structure is needed, and graph database came into being.
Related concepts
brief introduction
The graph database consists of vertices and edges;
It is mainly used for adding, deleting, modifying and querying graph data;
At present, the commonly used graph databases include Neo4j, JanuxGraph, etc
Usage scenario
- Commonly used in social networking, e-commerce, finance, retail, Internet of things and other industries
- Used for relation query
- Used to traverse complex relationships
- It is used to implement complex rules, such as subgraph comparison, recommendation, etc
- For structured data, relational database can often be used; If there are many relationships and the data is not regular, use the graph database
classification
- Attribute graph database
- Composition: vertex, edge, vertex attribute, edge attribute
- RDF graph database (it doesn't support attributes. It's old and doesn't work much anymore)
- For text semantic scene generation
- Triplet: subject - > predict - > object
Native graph database
- Native graph database: the graph model is used for data storage, which can be optimized for graph data to bring better performance, such as Neo4j.
- Non native graph database: the underlying storage uses the non graph model, encapsulating the semantics of the graph on the storage, which is suitable for cooperation with other data applications. For example, Titan and JanusGraph use the KV storage non graph model on the underlying.
Technology stack
- Technical architecture
- Interface layer, computing layer (graph algorithm), storage layer
- Mainstream query language
- Cypher (CQL, SQL like), Neo4j uses this query
- Gremlin (Scala like)
- SPARQL (for RDF framework) is applicable to semantic scenarios
- Figure calculation of data
- Graph traversal (local query: depth first, breadth first)
- Path discovery (shortest path between two points)
- Graph processing engine
- For analyzing complex graphs
- Common engines: GraphX, GraphLab, Giraph
Neo4j
Neo4j is a commonly used graph database.
Basic concepts
It includes the following four concepts:
- Label: the category of a node. A node can have more than one label
- Nodes: solid objects
- Relationship between entities
- Attribute: both nodes and relationships can have attributes, which are described in the form of key:value
install
$ docker search neo4j # View all Neo4j related images $ docker pull neo4j # Download the latest version
The latest version is about 500 M
function
$ sudo adduser neo4j $ docker run -d --name neo4j -p 7474:7474 -p 7687:7687 -v /home/neo4j/data:/data -v /home/neo4j/logs:/logs -v /home/neo4j/conf:/var/lib/neo4j/conf -v /home/neo4j/import:/var/lib/neo4j/import --env NEO4J_AUTH=neo4j/password neo4j
Browser open
http://localhost:7474
Enter user name: neo4j, password: password (set through NEO4J_AUTH when starting docker)
The syntax is very simple. Click the button to view help in the left column, which is similar to VSCode and Obsidian.
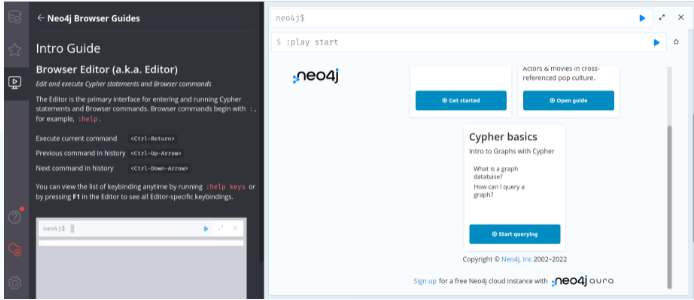
image.png
Processing data using CQL
Click the "Star" icon on the left to view the sample code and try to establish a relationship between two nodes:
CREATE (database:Database {name:"Neo4j"})-[r:SAYS]->(message:Message {name:"Hello World!"}) RETURN database, message, r
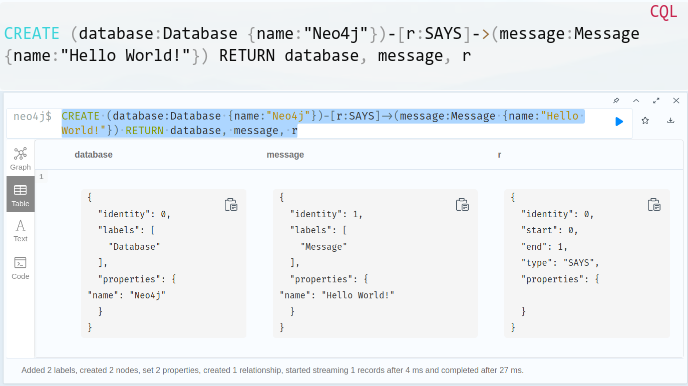
After the structure is established, you can view the data through the Database Infomation on the left.
Accessing the graph database using Python
install
$ pip install py2neo
code
# coding:utf-8
from py2neo import Graph, Node, Relationship
# Enter the user name, password and database connection 4nej
graph = Graph("http://192.168.1.106:7474", name="neo4j")
graph.delete_all()
# Create node
test_node_1 = Node('ru_yi_zhuan', name='emperor') # Modified part
test_node_2 = Node('ru_yi_zhuan', name='queen') # Modified part
test_node_3 = Node('ru_yi_zhuan', name='princess') # Modified part
graph.create(test_node_1)
graph.create(test_node_2)
graph.create(test_node_3)
# Create relationship
# Test is established respectively_ node_ 1 points to test_node_2 and test_node_2 points to test_node_1 there are two relationships. The relationship type is husband and wife. Both relationships have the attribute count and the value is 1.
node_1_zhangfu_node_1 = Relationship(test_node_1, 'husband', test_node_2)
node_1_zhangfu_node_1['count'] = 1
node_2_qizi_node_1 = Relationship(test_node_2, 'wife', test_node_1)
node_2_munv_node_1 = Relationship(test_node_2, 'mother and daughter', test_node_3)
node_2_qizi_node_1['count'] = 1
graph.create(node_1_zhangfu_node_1)
graph.create(node_2_qizi_node_1)
graph.create(node_2_munv_node_1)
print(graph)
print(test_node_1)
print(test_node_2)
print(node_1_zhangfu_node_1)
print(node_2_qizi_node_1)
print(node_2_munv_node_1)
At this point, you can see the newly created data in the interface:
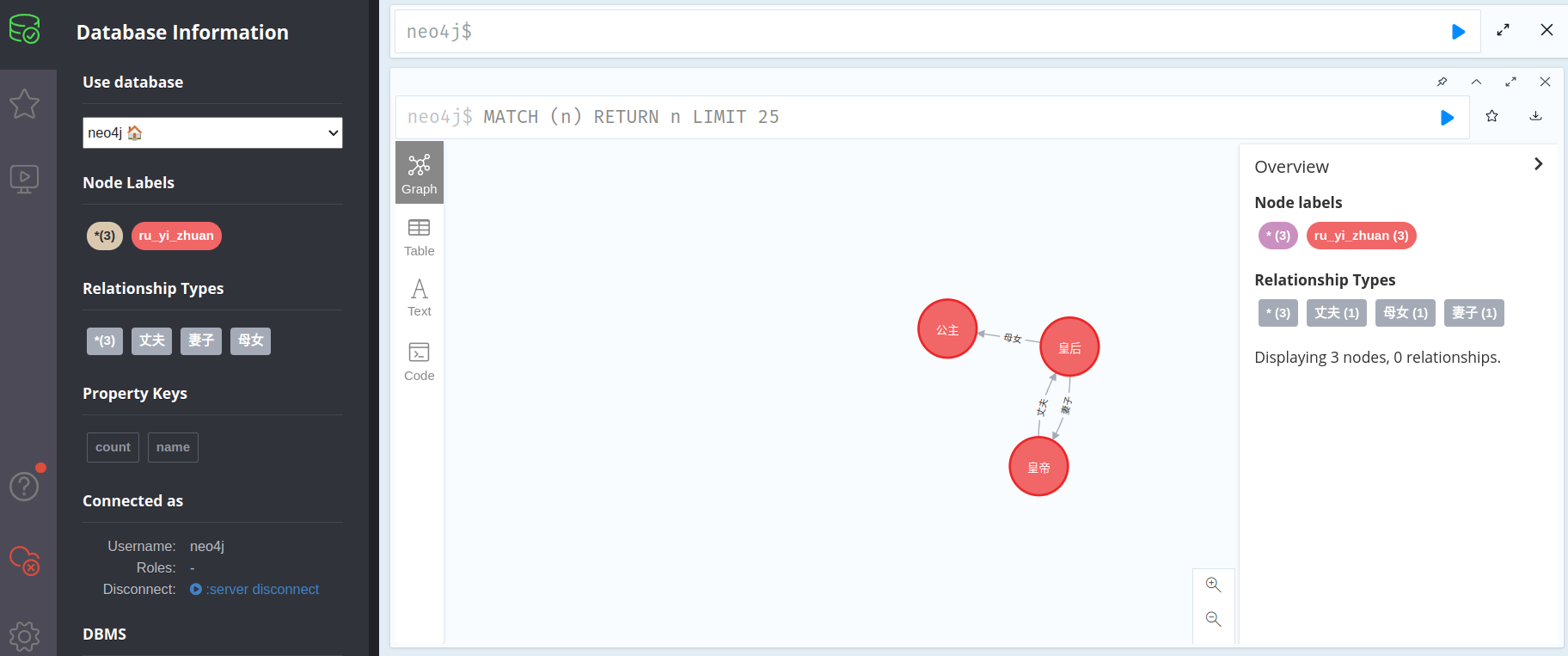
reference resources
docker installation and deployment neo4j
Neo4j basic introduction
python operation neo4j