1.Neo4j is a high-performance NOSQL graphical database written in Java and Scala
Download address of neo4j official website: https://neo4j.com/download-center/#enterprise
Neo4j Chinese community: http://neo4j.com.cn/
advantage:
- Fast query speed: when the relational database stores a large amount of data and there are many associated tables, the query efficiency will be reduced. neo4j starting from a node, according to its connection relationship, you can quickly and easily find its adjacent nodes without searching the whole database. This method of finding data is not affected by the amount of data, The query speed will not decrease due to the increase of data volume.
- Good flexibility: the unstructured data storage method can well adapt to the change of demand in the database design, because the nodes, relationships and attributes added with the change of demand will not affect the normal use of the original data.
- Transaction: fully support ACID's complete transaction management features (atomicity, consistency, isolation and persistence) rules
- Reliability: the database is safe and reliable. It can back up data in real time, which is very convenient to recover data
- Compared with other graph databases, Neo4j, as one of the earlier batch of graph databases, has many documents and various technical blogs, mature technology, many available success cases, and the data structure of graph is more intuitive
Disadvantages:
- The community version is free and open source, and the enterprise version is closed and expensive
- Importing a large amount of data is troublesome, and the performance of the official load csv mode is not ideal. The amount of node data slightly exceeds 10000, which is very slow, and the efficiency of inserting relational data is even slower. There are often problems of insufficient memory / overflow. Neo4j admin import is efficient, but it can only be used for database initialization, which is too limited
- If you want to improve performance and capacity, you can only deal with it in hardware. If you increase memory and hard disk, the hardware will always reach the bottleneck
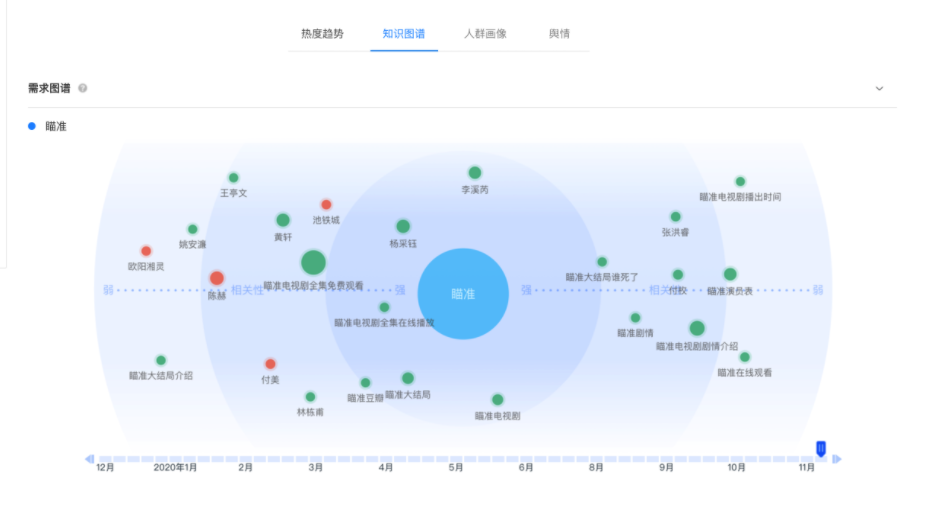
Applicable and use scenario: Knowledge Map
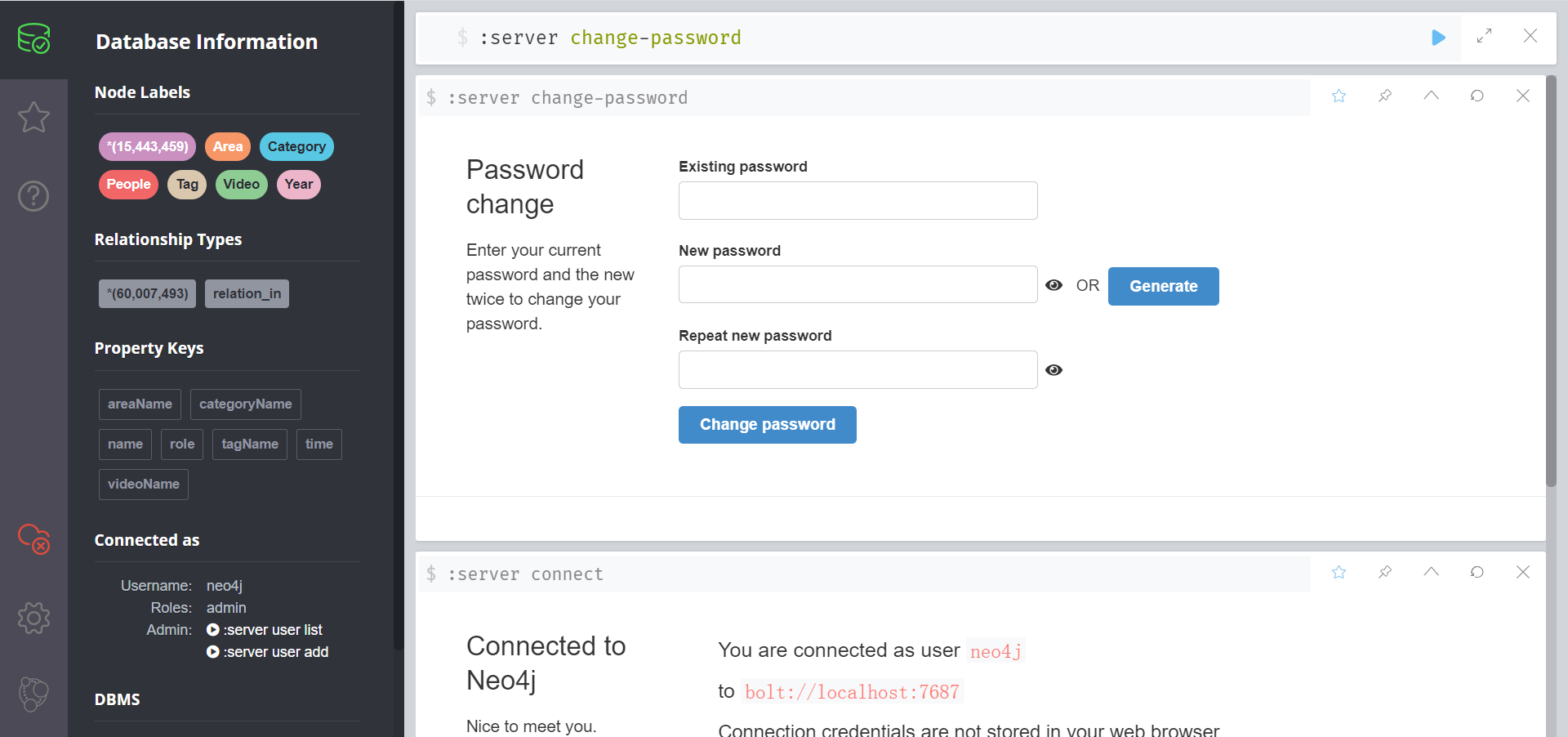
Download and unzip Windows and Linux. After startup, the browser outputs: http://localhost:7474/ You can log in.
You need to change the password for the first access. The default account password is neo4j. If you change the password later, you only need to enter: server change password on the console
Profile:
Enable remote access: (other remote computers can use the local IP or domain name followed by port 7474 to open the web interface, such as https://:7473)
Versions before 3.0: in / conf / neo4j. In the installation directory In the conf file, find and remove the comment # number and modify it.
#dbms.connector.https.address=localhost:7473
Change to
dbms.connector.https.address=0.0.0.0:7473
Version 3.1 and later: in / conf / neo4j In the conf file, find and remove the comment # number.
dbms.connectors.default_listen_address=0.0.0.0
Neo4j admin import or load csv import data memory overflow problem:
In the installation directory / conf / neo4j Conf file, find and modify the JVM initial heap memory and JVM maximum heap memory.
#Set JVM initial heap memory and JVM maximum heap memory
#The JVM's maximum heap memory given by the production environment should be as large as possible, but less than the physical memory of the machine
dbms.memory.heap.initial_size=5g
dbms.memory.heap.max_size=10g
Integrated springboot:
Version problem in integrated springboot!! (please correspond to the version number. Different versions may have different addresses.) https://neo4j.com/developer/neo4j-ogm/ ):
example:springboot 2.1.6 edition
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.1.6.RELEASE</version>
</parent>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-neo4j</artifactId>
</dependency>
<!-- Only add if you're using the Bolt driver Here I choose http agreement -->
<dependency>
<groupId>org.neo4j</groupId>
<artifactId>neo4j-ogm-http-driver</artifactId>
</dependency>
yml configuration:
data:
neo4j:
uri: http://127.0.0.1:7474
username: neo4j
password: "0123"If the password number starts with zero, remember that when configuring the number prefixed with 0 in the spring boot yml configuration file, it will be treated as an octal number, and a password error will be reported when logging in neo4j. For example: 0123, the solution is "0123"
Configure Neo4jConfiguration related configurations
neo4j config
import org.neo4j.ogm.session.SessionFactory;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.data.neo4j.repository.config.EnableNeo4jRepositories;
import org.springframework.data.neo4j.transaction.Neo4jTransactionManager;
import org.springframework.transaction.annotation.EnableTransactionManagement;
/**
* @author Eric.he
* @description neo4j Configuration class
*/
@Configuration
@EnableNeo4jRepositories("com.coocaa.fire.video.mediaresourceadmin.neo4j.repository")
@EnableTransactionManagement
public class MediaNeo4jConfiguration {
@Value("${spring.data.neo4j.uri}")
private String databaseUrl;
@Value("${spring.data.neo4j.username}")
private String userName;
@Value("${spring.data.neo4j.password}")
private String password;
@Bean
public SessionFactory sessionFactory() {
org.neo4j.ogm.config.Configuration configuration = new org.neo4j.ogm.config.Configuration.Builder()
.uri(databaseUrl)
.credentials(userName, password)
.build();
/**
* If the java bean path of node mapping is not specified, the following warning will be reported when saving, so that the node cannot be inserted into Neo4j
* ... is not a valid entity class. Please check the entity mapping.
*/
return new SessionFactory(configuration, "com.coocaa.fire.video.mediaresourceadmin.neo4j.node","com.coocaa.fire.video.mediaresourceadmin.neo4j.payload");
}
/**
* DefaultTransactionManager SessionFactory.openSession()
* Neo4jTransactionManager SessionFactory
*/
@Bean
public Neo4jTransactionManager transactionManager() {
return new Neo4jTransactionManager(sessionFactory());
}
}neo4j node
import com.coocaa.fire.video.mediaresourceadmin.neo4j.payload.NeoConsts;
import lombok.*;
import org.neo4j.ogm.annotation.GeneratedValue;
import org.neo4j.ogm.annotation.Id;
import org.neo4j.ogm.annotation.NodeEntity;
import org.neo4j.ogm.annotation.Relationship;
import java.util.Set;
@Data
@NoArgsConstructor
@RequiredArgsConstructor(staticName = "of")
@AllArgsConstructor
@Builder
@NodeEntity(label = "Video")
public class VideoNode {
@Id
@GeneratedValue
private Long nodeId;
@NonNull
private String videoName;
@Relationship(type = NeoConsts.RELATION_IN, direction = Relationship.INCOMING)
private Set<CategoryNode> categoryNodes;
@Relationship(type = NeoConsts.RELATION_IN, direction = Relationship.INCOMING)
private Set<AreaNode> areaNodes;
@Relationship(type = NeoConsts.RELATION_IN, direction = Relationship.INCOMING)
private Set<TagNode> tagNodes;
@Relationship(type = NeoConsts.RELATION_IN, direction = Relationship.INCOMING)
private Set<PeoPleNode> peoPleNodes;
@Relationship(type = NeoConsts.RELATION_IN, direction = Relationship.INCOMING)
private Set<YearNode> yearNodes;neo4j service
/**
* Query relevant node information according to the name (region, category, actor, label, album, year)
*
* @param targetName Region, category, actor, label, album, year
*/
public Map<String, Set<String>> findByTargetName(String targetName) {
Map<String, Set<String>> result = null;
if (0 != areaRepository.countByAreaName(targetName)) {
log.info(" By Region node region name[{}] ==>> Search for relevant data ", targetName);
List<VideoNode> res = areaRepository.findByAreaName(targetName);
result = getMapFun.apply(res);
}
if (0 != categoryRepository.countByCategoryName(targetName)) {
log.info(" Classification name according to classification node[{}] ==>> Search for relevant data ", targetName);
List<VideoNode> res = categoryRepository.findByCategoryName(targetName);
result = getMapFun.apply(res);
}
if (0 != peopleRepository.countByName(targetName)) {
log.info(" Node name according to person name[{}] ==>> Search for relevant data ", targetName);
List<VideoNode> res = peopleRepository.findByName(targetName);
result = getMapFun.apply(res);
}
if (0 != tagRepository.countByTagName(targetName)) {
log.info(" Label name according to label node[{}] ==>> Search for relevant data ", targetName);
List<VideoNode> res = tagRepository.findByTagName(targetName);
result = getMapFun.apply(res);
}
if (0 != videoRepository.countByVideoName(targetName)) {
log.info(" According to album node album name[{}] ==>> Search for relevant data ", targetName);
List<VideoNode> res = videoRepository.findByVideoName(targetName);
result = getMapFun.apply(res);
}
if (0 != yearRepository.countByTime(targetName)) {
log.info(" Release year and time according to year node[{}] ==>> Search for relevant data ", targetName);
List<VideoNode> res = yearRepository.findByTime(targetName);
result = getMapFun.apply(res);
}
Optional.ofNullable(result).
ifPresent(c ->
c.forEach((k, v) ->
log.info("[{}] Node association data is {}", k, JSONUtil.toJsonStr(v))
));
return result;
}
Function<List<VideoNode>, Map<String, Set<String>>> getMapFun = (list) -> {
Map<String, Set<String>> result = Maps.newHashMap();
List<String> areas = Lists.newArrayList();
List<String> categors = Lists.newArrayList();
List<String> peoples = Lists.newArrayList();
List<String> tags = Lists.newArrayList();
List<String> videos = list.stream().map(VideoNode::getVideoName).collect(Collectors.toList());
List<String> years = Lists.newArrayList();
list.forEach(c -> {
areas.addAll(
Optional.ofNullable(c.getAreaNodes())
.orElseGet(() -> {
return Collections.emptySet();
})
.stream()
.map(AreaNode::getAreaName)
.collect(Collectors.toList())
);
categors.addAll(
Optional.ofNullable(c.getCategoryNodes())
.orElseGet(() -> {
return Collections.emptySet();
})
.stream()
.map(CategoryNode::getCategoryName)
.collect(Collectors.toList())
);
peoples.addAll(
Optional.ofNullable(c.getPeoPleNodes())
.orElseGet(() -> {
return Collections.emptySet();
})
.stream()
.map(PeoPleNode::getName)
.collect(Collectors.toList())
);
tags.addAll(
Optional.ofNullable(c.getTagNodes())
.orElseGet(() -> {
return Collections.emptySet();
})
.stream()
.map(TagNode::getTagName)
.collect(Collectors.toList())
);
years.addAll(
Optional.ofNullable(c.getYearNodes())
.orElseGet(() -> {
return Collections.emptySet();
})
.stream()
.map(YearNode::getTime)
.collect(Collectors.toList())
);
});
result.put("area", Sets.newHashSet(areas));
result.put("categor", Sets.newHashSet(categors));
result.put("people", Sets.newHashSet(peoples));
result.put("tag", Sets.newHashSet(tags));
result.put("video", Sets.newHashSet(videos));
result.put("year", Sets.newHashSet(years));
return result;
};neo4j repository
public interface CategoryRepository extends Neo4jRepository<CategoryNode, Long> {
/**
* Query existence by category name
*
* @param categoryName Classification name
* @return Number of queries
*/
@Query("match (c:Category{categoryName:{categoryName}}) return count(c)")
Long countByCategoryName(@Param("categoryName") String categoryName);
/**
* Query associated data by category name
*
* @param categoryName Classification name
* @param *4 Depth 4
* @return Query results
*/
@Query("match data=(t:Category{categoryName:{categoryName}})-[*4]-(n) return data limit 50")
List<VideoNode> findByCategoryName(@Param("categoryName") String categoryName);
/**
* Query existence by category name
*
* @param categoryName Classification name
* @return Query results
*/
@Query("match (c:Category{categoryName:{categoryName}}) return c")
CategoryNode findDoesItExist(@Param("categoryName") String categoryName);
/**
* Query whether there is a relationship between the specified album name and category name
*
* @param videoName Album name
* @param categoryName Classification name
* @return Query results
*/
@Query("match data=(a:Video{videoName:{videoName}})-[r:relation_in]-(c:Category{categoryName:{categoryName}}) return count(data)")
Long findRelationshipByCategoryName(@Param("videoName") String videoName, @Param("categoryName") String categoryName);
@Query("match (a:Video{videoName:{videoName}})-[r:relation_in]-(c:Category{categoryName:{categoryName}}) WITH a, c, TAIL (COLLECT (r)) as rr WHERE size(rr)>0 FOREACH (r IN rr | DELETE r)")
void deleteRepeatRelationship(@Param("videoName") String videoName, @Param("categoryName") String categoryName);
@Query("match (from:Video{videoName:{videoName}}),(to:Category{categoryName:{categoryName}}) merge (from)<-[r:relation_in{roles:'classification'}]-(to)")
void addRelationship(@Param("videoName") String videoName, @Param("categoryName") String categoryName);Neo4J storage structure description
Node: represents an entity record, just like a record in a relational database. A node contains multiple attributes and labels.
Property: nodes and relationships can have multiple properties. Properties are composed of key value pairs, just like hashes in java
Relationship: relationship is used to associate and form a graph. Relationship is also called Edge of graph theory. ()<-[]->()
Label: a label indicates a group of nodes with the same attributes, but it is not mandatory. A node can have multiple labels.
CQL syntax: CQL stands for Cypher query language, and Neo4j uses CQL as the query language
CQL command keyword explanation:
CQL command} usage
CREATE creates nodes, relationships, and attributes
MATCH # retrieves data about nodes, relationships, and attributes
RETURN returns the query result
WHERE # provides conditional filtering to retrieve data
DELETE deletes nodes and relationships
REMOVE deletes the attributes of nodes and relationships
ORDER BY: sort and retrieve data
SET} add or update labels
Neo4J syntax common functions:
Predicate functions
ALL(identifier in collection WHERE predicate) determines whether an assertion satisfies all elements in the collection
ANY(identifier in collection WHERE predicate) determines whether an assertion satisfies at least one element in the collection
NONE(identifier in collection WHERE predicate) returns true if the elements in the collection do not satisfy the predicate
SINGLE(identifier in collection WHERE predicate) returns true if only one element in the collection satisfies the predicate
Scalar functions
Length (Collection) returns the number of elements in the collection
Type (relationship) returns the type of relationship
ID (property container) returns the ID of the node or relationship
Coalesce (expression [, expression] *) returns the first non empty value in the expressions list
Head (expression) returns the first element in a collection
Last (expression) returns the last element in a collection
Collection functions
Nodes (path) returns all nodes of a path
Relationships (path) returns all relationships of a path
Extract (identifier in collection: expression) returns a result set: the result obtained by performing the expression operation on all elements of the collection
Filter (identifier in collection: predicate) returns a collection of all elements in the collection that satisfy the predicate
Tail (expression) returns all elements in the collection except the first one
Range (start, end [, step]) returns all integer numbers with step (non-0) from start to end (closed interval)
Mathematical functions
ABS (expression) returns the absolute value of the value obtained by expression
Round (expression) rounding function: returns the largest integer less than or equal to the value obtained by expression (or the integer closest to the value obtained by expression)
Sqrt (expression) returns the square root of the value obtained by expression
Sign (expression) symbolic function: if the value obtained by expression is 0, it returns 0; If it is a negative number, - 1 is returned; A positive number returns 1
Aggregate functions
Count (expression) returns the number of results obtained by expression. Expression can also be "*"
Sum (expression) returns the sum of the results
AVG (expression) returns the average value of the result obtained by expression
Max (expression) returns the maximum value of the result obtained by expression
Min (expression) returns the minimum value of the result obtained by expression
Collect (expression) returns the result obtained by expression in the form of list
Common statements of CQL command:
# Before creating the index, the node data we insert may be duplicate. We need to clear the duplicate data first.
MATCH (n:Tag)
WITH n.tagName AS tagName, collect(n) AS nodes
WHERE size(nodes) > 1
FOREACH (n in tail(nodes) | DETACH DELETE n);
# View all indexes
:schema
# Create index
CREATE INDEX ON :Video(videoName);
# Delete index
DROP INDEX ON :Person(name)
# Create a node
CREATE (k:People{ name:'Eric',born:1777}) RETURN k
# Create multiple nodes at once
CREATE (:People{name:"Eric1",age:6}),(:People{name:"Eric2",age:4}),(:People{name:"Eric3",age:3}),(:People{name:"Eric4",age:1})
# Create node + relationship
CREATE data=(:People{name:"Eric"})-[:Year of birth]->(:Year{time:"1777"}) return data
# Query matching data paging return
MATCH (n:Video) RETURN n LIMIT 10
# Query objects according to the condition interval of attributes:
MATCH (n: People) WHERE n.age >= 3 AND n.age < 6 RETURN n
# modify attribute
MATCH (a:People{name:"Eric",age:6}) SET a.age=6666 return a
# Delete statement deletes the relationship node first
MATCH (n:People{name:"Eric"})-[r]-() DELETE r,n
# Use depth operator
match data=(v:Video{videoName:'Highlights of gun god'})<-[*2]-(t:Tag) return data
# Use the with keyword to query three-level relationship nodes as follows: with can use the previous query results as the subsequent query criteria
match (na:company)-[re]->(nb:company) where na.id = '12399145' WITH na,re,nb match (nb:company)-[re2]->(nc:company) return na,re,nb,re2,nc
# Match node delete relationship
match data=(a:Album{videoName:"2019 Billboard Music Award"})-[r]-(ac:Actor) delete r
# Query whether there is a relationship between nodes
match data=(a:Video{videoName:"Highlights of gun god"})-[r:relation_in]-(c:Tag{tagName:"2019"}) return count(data)
# Delete the relationship between duplicate nodes and keep one note: this syntax uses the two functions COLLECT and TAIL
match (a:Video{videoName:"Highlights of gun god"})-[r:relation_in]-(c:Area{areaName:"inland"}) WITH a, c, TAIL (COLLECT (r)) as rr WHERE size(rr)>0 FOREACH (r IN rr | DELETE r)
# Query and add relationships to existing nodes based on existing nodes
match (from:Video{videoName:"Highlights of gun god"}),(to:Category{categoryName:"Funny"}) merge (from)<-[r:relation_in{roles:'classification'}]-(to)Neo4J: batch import Neo4J admin import
- Applicable scenario: more than ten million nodes
- Speed: very fast (xw/s)
- Advantages: neo4j comes with tools and takes up less resources
- Disadvantages: need to convert to CSV; Must stop neo4j; Only new databases can be generated, and data cannot be inserted into existing databases. (the usage scenario has just been built, and there is a large amount of initialization data)
Note: data strings such as nodes, backslashes and internal quotation marks are not escaped or filtered in advance, which will cause import errors
For example:
"Love saint" fixed file "press conference"
End of time/
The CSV file to be imported needs to be prepared. The data needs to be converted into a CSV file and put into the import folder of the installation path of neo4j. Because neo4j is UTF-8 and CSV is ANSI by default, it needs to be saved as UTF-8 with Notepad. Save as "code selection UTF-8, neo4j admin import when importing CSV file, the first line of the read file must be the data field information, which is used to indicate the specific meaning of each column in the file:
- When the csv file is a node file, it is necessary to include the ID field (: ID) to represent the ID information of the node, (: LABEL) to identify the label of the node
- When the csv file is a relationship file, it must contain (: START_ID),(:END_ID), (: TYPE) to represent the start node ID, end node ID and relationship label of the relationship respectively
| videoName:ID | :LABEL |
| Guardian alliance 3D video 1 | Video |
| Fat cat wandering | Video |
| time:ID | :LABEL |
| 2012 | Year |
| 1920 | Year |
| :START_ID | role | :END_ID | :TYPE |
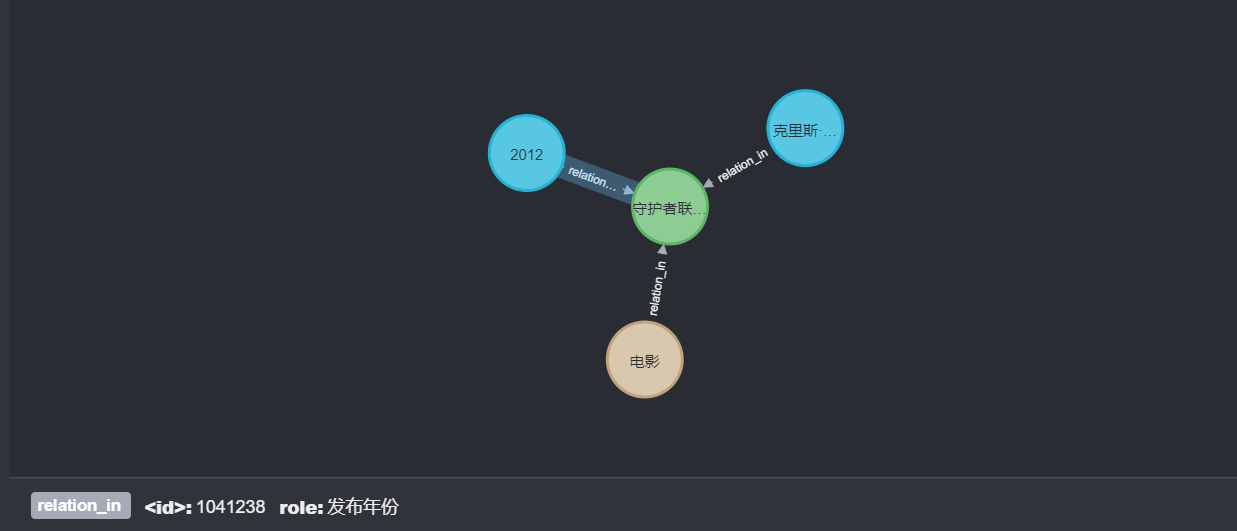
| 2012 | Year of issue | Guardian alliance 3D video 1 | relation_in |
| 2009 | Year of issue | Fat cat wandering | relation_in |
1. Stop Neo4J service
D:\Eric\neo4j-community-3.5.25\bin>neo4j status Neo4j is running D:\Eric\neo4j-community-3.5.25\bin>neo4j stop Neo4j service stopped D:\Eric\neo4j-community-3.5.25\bin>
2. Delete the graph DB file, or specify -- database = newgraph DB database name. After generation, overwrite the original database or modify the configuration file. Specify the default database as the new database name
3. Execute the Import command
Note: when the command reads csv files, if there are duplicate nodes or null values of invalid nodes, you need to add -- ignore duplicate nodes = true -- ignore missing nodes = true
D:\Eric\neo4j-community-3.5.25\bin>neo4j-admin import --database=graph.db --ignore-duplicate-nodes=true --ignore-missing-nodes=true --nodes "D:\Eric\neo4j-community-3.5.25\import\area.csv" --nodes "D:\Eric\neo4j-community-3.5.25\import\category.csv" --nodes "D:\Eric\neo4j-community-3.5.25\import\people.csv" --nodes "D:\Eric\neo4j-community-3.5.25\import\tag.csv" --nodes "D:\Eric\neo4j-community-3.5.25\import\year.csv" --nodes "D:\Eric\neo4j-community-3.5.25\import\video0.csv" --relationships "D:\Eric\neo4j-community-3.5.25\import\category0.csv" --relationships "D:\Eric\neo4j-community-3.5.25\import\area0.csv" --relationships "D:\Eric\neo4j-community-3.5.25\import\year0.csv" --relationships "D:\Eric\neo4j-community-3.5.25\import\tag0.csv" --relationships "D:\Eric\neo4j-community-3.5.25\import\mainActor0.csv" --multiline-fields=true
D:\Eric\neo4j-community-3.5.25\bin>neo4j-admin import --database=graph.db --ignore-duplicate-nodes=true --ignore-missing-nodes=true --nodes "D:\Eric\neo4j-community-3.5.25\import\area.csv" --nodes "D:\Eric\neo4j-community-3.5.25\import\category.csv" --nodes "D:\Eric\neo4j-community-3.5.25\import\people.csv" --nodes "D:\Eric\neo4j-community-3.5.25\import\tag.csv" --nodes "D:\Eric\neo4j-community-3.5.25\import\year.csv" --nodes "D:\Eric\neo4j-community-3.5.25\import\video0.csv" --relationships "D:\Eric\neo4j-community-3.5.25\import\category0.csv" --relationships "D:\Eric\neo4j-community-3.5.25\import\area0.csv" --relationships "D:\Eric\neo4j-community-3.5.25\import\year0.csv" --relationships "D:\Eric\neo4j-community-3.5.25\import\tag0.csv" --relationships "D:\Eric\neo4j-community-3.5.25\import\mainActor0.csv" --multiline-fields=true Neo4j version: 3.5.25 Importing the contents of these files into D:\Eric\neo4j-community-3.5.25\data\databases\graph.db: Nodes: D:\Eric\neo4j-community-3.5.25\import\area.csv D:\Eric\neo4j-community-3.5.25\import\category.csv D:\Eric\neo4j-community-3.5.25\import\people.csv D:\Eric\neo4j-community-3.5.25\import\tag.csv D:\Eric\neo4j-community-3.5.25\import\year.csv D:\Eric\neo4j-community-3.5.25\import\video0.csv Relationships: D:\Eric\neo4j-community-3.5.25\import\category0.csv D:\Eric\neo4j-community-3.5.25\import\area0.csv D:\Eric\neo4j-community-3.5.25\import\year0.csv D:\Eric\neo4j-community-3.5.25\import\tag0.csv D:\Eric\neo4j-community-3.5.25\import\mainActor0.csv Available resources: Total machine memory: 15.92 GB Free machine memory: 7.46 GB Max heap memory : 3.54 GB Processors: 12 Configured max memory: 11.14 GB High-IO: false Import starting 2021-06-24 14:36:44.028+0800 Estimated number of nodes: 3.33 M Estimated number of node properties: 3.32 M Estimated number of relationships: 8.25 M Estimated number of relationship properties: 8.25 M Estimated disk space usage: 1002.58 MB Estimated required memory usage: 1.04 GB InteractiveReporterInteractions command list (end with ENTER): c: Print more detailed information about current stage i: Print more detailed information (1/4) Node import 2021-06-24 14:36:44.112+0800 Estimated number of nodes: 3.33 M Estimated disk space usage: 412.41 MB Estimated required memory usage: 1.04 GB .......... .......... .......... .......... .......... 5% ?1s 244ms .......... .......... .......... .......... .......... 10% ?3s 216ms .......... .......... ....-..... .......... .......... 15% ?204ms .......... .......... .......... .......... .......... 20% ?202ms .......... .......... .......... .......... .......... 25% ?202ms .......... .......... .......... .......... .......... 30% ?1ms .......... .......... .......... .......... .......... 35% ?204ms .......... .......... .......... .......... .......... 40% ?215ms ...-...... .......... .......... .......... .......... 45% ?92ms .......... .......... .......... .......... .......... 50% ?2ms .......... .......... .......... .......... .......... 55% ?7ms .......... .......... .......... .......... .......... 60% ?1ms .......... .......... .......... .......... .......... 65% ?3ms .......... .......... .......... .......... .......... 70% ?3ms .......... .......... .......... .......... .......... 75% ?1ms .......... .......... .......... .......... .......... 80% ?3ms .......... .......... .......... .......... .......... 85% ?4ms .......... .......... .......... .......... .......... 90% ?1ms .......... .......... .......... .......... .......... 95% ?1ms .......... .......... .......... .......... .........(2/4) Relationship import 2021-06-24 14:36:51.459+0800 Estimated number of relationships: 8.25 M Estimated disk space usage: 590.17 MB Estimated required memory usage: 1.02 GB .......... .......... .......... .......... .......... 5% ?1s 381ms .......... .......... .......... .......... .......... 10% ?1s 7ms .......... .......... .......... .......... .......... 15% ?1s 205ms .......... .......... .......... .......... .......... 20% ?1s 8ms .......... .......... .......... .......... .......... 25% ?1s 208ms .......... .......... .......... .......... .......... 30% ?2s 11ms .......... .......... .......... .......... .......... 35% ?1s 610ms .......... .......... .......... .......... .......... 40% ?467ms .......... .......... .......... .......... .......... 45% ?2ms .......... .......... .......... .......... .......... 50% ?2ms .......... .......... .......... .......... .......... 55% ?1ms .......... .......... .......... .......... .......... 60% ?2ms .......... .......... .......... .......... .......... 65% ?3ms .......... .......... .......... .......... .......... 70% ?1ms .......... .......... .......... .......... .......... 75% ?3ms .......... .......... .......... .......... .......... 80% ?3ms .......... .......... .......... .......... .......... 85% ?1ms .......... .......... .......... .......... .......... 90% ?3ms .......... .......... .......... .......... .......... 95% ?2ms .......... .......... .......... .......... .......... 100% ?3ms (3/4) Relationship linking 2021-06-24 14:37:01.386+0800 Estimated required memory usage: 1.01 GB .......... .......... .......... .......... .......... 5% ?112ms .......... .......... .......... .......... .......... 10% ?1ms .......... .......... ..-....... .......... .......... 15% ?120ms .......... .......... .......... .......... .......... 20% ?2ms .......... .......... .......... .......... .......... 25% ?203ms .......... .......... .......... .......... .......... 30% ?2ms .......... .......... .......... .......... .......... 35% ?1ms .......... .......... .......... .......... .......... 40% ?2ms .......... .......... .......... .......... .......... 45% ?2ms -......... .......... .......... .......... .......... 50% ?97ms .......... .......... .......... .......... .......... 55% ?202ms .......... .......... .......... .......... .......... 60% ?1ms .......... .......... .......... .......... .......... 65% ?1ms .......... .......... .......... .......... .......... 70% ?187ms .......... .......... .......... .......... .......... 75% ?2ms .......... .......... .......... .......... .......... 80% ?2ms .......... .......... .......... .......... .......... 85% ?1ms .......... .......... .......... .......... .......... 90% ?1ms .......... .......... .......... .......... .......... 95% ?4ms .......... .......... .......... .......... .......... 100% ?2ms (4/4) Post processing 2021-06-24 14:37:02.723+0800 Estimated required memory usage: 1020.01 MB -......... .......... .......... .......... .......... 5% ?273ms .......... .......... .......... .......... .......... 10% ?1ms .......... .......... .......... .......... .......... 15% ?1ms .......... .......... .......... .......... .......... 20% ?1ms .......... .......... .......... .......... .......... 25% ?1ms .......... .......... .......... .......... .......... 30% ?1ms .......... .......... .......... .......... .......... 35% ?1ms .......... .......... .......... .......... .......... 40% ?5ms .......... .......... .......... .......... .......... 45% ?2ms .......... .......... .......... .......... .......... 50% ?0ms .......... .......... .......... .......... .......... 55% ?2ms .......... .......... .......... .......... .......... 60% ?1ms .......... .......... .......... .......... .......... 65% ?0ms .......... .......... .......... .......... .......... 70% ?6ms .......... .......... .......... .......... .......... 75% ?3ms .......... .......... .......... .......... .......... 80% ?2ms .......... .......... .......... .......... .......... 85% ?0ms .......... .......... .......... .......... .......... 90% ?7ms .......... .......... .......... .......... .......... 95% ?2ms .......... .......... .......... .......... .......... 100% ?1ms IMPORT DONE in 20s 629ms. Imported: 1214806 nodes 3019651 relationships 4234414 properties Peak memory usage: 1.04 GB There were bad entries which were skipped and logged into D:\Eric\neo4j-community-3.5.25\bin\import.report D:\Eric\neo4j-community-3.5.25\bin>
4. Start service
D:\Eric\neo4j-community-3.5.25\bin>neo4j start Neo4j service started
5. View data
Neo4J: batch import LOAD CSV
- You can import without closing neo4j the service, and the import method is simple
- It is not suitable for bulk import of large amount of data and large amount of relational data
The command reads the csv file information and inserts it without specifying the first line header information
LOAD CSV FROM "file:///mainActor.csv" AS line create (a:Actor{mainActorName:line[0]})
LOAD CSV FROM "file:///tag.csv" AS line create (a:Tag{tagName:line[0]})
LOAD CSV FROM "file:///categoryName.csv" AS line create (a:Category{categoryName:line[0]})
LOAD CSV FROM "file:///videoMainActor. CSV "as line match (from: album {videoname: line [0]}), (to: actor {mainactor Name: line [1]}) merge (from) - [R: actor_in {roles:" actor "}] - > (to) return R
LOAD CSV FROM "file:///videoTag. CSV "as line match (from: album {videoname: line [0]}), (to: tag {tagName: line [1]}) merge (from) - [R: tab_in {roles:" tag "}] - > (to) return R"
LOAD CSV FROM "file:///videoCategory. CSV "as line match (from: album {videoname: line [0]}), (to: category {category name: line [1]}) merge (from) - [R: category_in {roles:" category "}] - > (to) return R"Neo4J: batch import is based on APOC plug-in import (with the help of plug-in, the method is similar to LOAD CSV)
- Download the jar package corresponding to apoc https://github.com/neo4j-contrib/neo4j-apoc-procedures/releases
- Put the downloaded files into plugins in the neo4j folder
- Modify the configuration file DBMS security. procedures. unrestricted=apoc. export.*, apoc. import.*
apoc.export.file.enabled=true
apoc.import.file.enabled=true - Restart the neo4j server to complete the aopc plug-in installation
CALL apoc.periodic.iterate(
'CALL apoc.load.csv("file:///mainActor0.csv") yield map as row return row',
'MATCH (n:Video{videoName:row.line[0]}) with * MATCH (m:People{name:row.line[1]}) with * merge (n)-[r:relation{roles:"to star"}]->(m)'
,{batch:10000, iterateList:true, parallel:true})