1, Introduce
The data generated in the application process is first stored in memory. If you want to save it permanently, it must exist in the hard disk. If the application wants to operate the hardware, it must pass through the operating system, and the file is the virtual concept that the operating system provides the application to operate the hard disk. The operation of the user or application to the file is to call the operating system, and then the operating system completes the specific operation of the hardware.
2, Basic process of file operation
2.1 basic process
# 1. Open the file, and the application program calls open(..) to the operating system, The operating system opens a file, corresponds to a piece of hard disk space, and returns a file object assigned to a variable f
f = open('a.txt',mode='r',encoding='utf-8') #The default on mode is r
# 2. Calling the read / write method of the file object will be converted into the operation of reading / writing the hard disk by the operating system
data= f.read()
#3. Send a request to the operating system to close the file and recycle the system resources
f.close()

2.2 resource recovery and context management
Opening a file contains two resources: application variables f and how the operating system is opened. When a file is operated, it must be recycled together with the two resources of the file. The recycling method is as follows:
1,f.close() #Reclaim file resources opened by the operating system 2,del f #Reclaim application level variables
Among them, del f must occur after f.close(), otherwise the file opened by the operating system cannot be closed and takes up resources in vain. However, Python's automatic garbage collection mechanism determines that we do not need to consider del F, which requires us to remember f.close() after operating the file. Although we emphasize so, But most readers can't help forgetting f.close (). Considering this, python provides the with keyword to help us manage the context
#1. After executing the subcode, with will automatically execute f.close()
with open('a.txt',mode='w') as f:
pass
#2. with can be used to open multiple files at the same time, separated by commas
with open('a.txt',mode='r') as read_f,open('b.txt',mode='w') as write_f:
data = read_f.read()
write_f.write(data)
2.3. Specify the character code of the operation text file
'''f = open(...) The file is opened by the operating system. If you open a text file, it will involve character coding. If it is not open Specifies encoding encoding operating system has the final say operating system will open the file with its default encoding. windows Next is gbk,stay linux Next is utf-8. If you want to ensure that there is no random code, you should open the file in whatever way you save it.'''
f = open('a.txt',mode='r',encoding = 'utf-8')
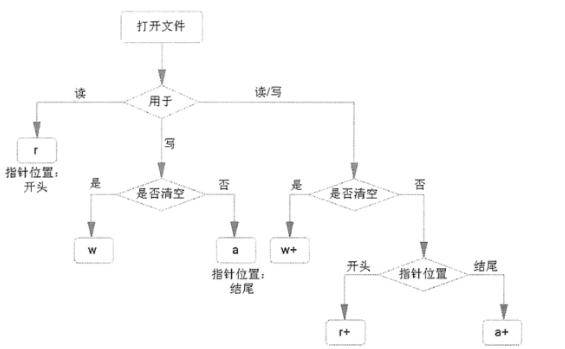
3, Operation mode of file
3.1. Control the mode of file reading and writing operation
r(default): read-only w: Write only a: Append write only
3.1.1 use of r mode
# r read only mode. If the file does not exist, an error is reported. If the file exists, the pointer in the file directly jumps to the beginning of the file
with open('a.txt',mode = 'r',encoding='utf-8') as f:
res=f.read()# The contents of the file will be read from the hard disk into the memory and assigned to res
3.1.2 use of w mode
# w write only mode creates an empty document when the file does not exist. If the file exists, the file will be emptied and the file pointer will run to the beginning of the file
with open('b.txt',mode='w',encoding = 'utf-8') as f:
f.write('Hello\n')
f.write('I'm fine\n')
f.write('hello everyone\n')
# Note: 1 When the file is not closed, it is written continuously, and the subsequent content must follow the signed content
2.If you re w If the file is opened in mode, the contents of the file will be emptied
3.1.3 use of mode a
#a append only write mode: an empty document will be created when the file does not exist, and the existence of the file will move the file pointer directly to the end of the file
with open('c.txt',mode = 'a',encoding = 'utf-8') as f:
f.write('sdsds\n')
f.write('sdsdssd\n')
# Note: similarities and differences between w mode and a mode
# 1. Similarities: when the file is opened and not closed, the newly written content will always follow the content written earlier
# 2. Difference: reopening the file in a mode will not empty the contents of the original file, but will move the file pointer directly to the end of the file, and the newly written contents will always be written at the end
3.2. Mode of controlling document reading and writing content
# Premise: T and B modes cannot be used alone, but must be combined with one of r, w and a t(default): Text mode 1.Read and write files are in string units 2.Only for text files 3.Must specify encoding parameter b: Binary mode: 1.Reading and writing are based on bytes/Binary unit 2.Can be for all files 3.Cannot specify encoding parameter
3.2.1 use of t mode
# t mode. If the file opening mode we specify is r/w/a, it defaults to rt/wt/at
with open('a.txt',mode='rt',encoding='utf-8') as f:
res=f.read()
print(type(res)) # The output result is: < class' STR '>
with open('a.txt',mode='wt',encoding='utf-8') as f:
s='abc'
f.write(s) # What is written must also be a string type
# Note: T mode can only be used to operate text files. No matter reading or writing, it should be in the unit of string. The essence of secondary access hard disk is binary. When t mode is specified, it internally helps us to encode and decode
3.2.2 use of mode b
#b: Reading and writing are in bytes
with open('1.jpg',mode = 'rb') as f:
data = f.read()
print(type(data)) # The output result is: < class' bytes' >
with open('a.txt',mode='wb') as f:
msg="Hello"
res=msg.encode('utf-8') # res is of type bytes
f.write(res) # In b mode, only bytes can be written to the file
# Comparison between mode b and mode t
#1. In the operation of plain text files, t mode helps us save the link of encoding and decoding, while b mode requires manual encoding and decoding, so t mode is more convenient at this time
#2. Only b mode can be used for non text files (such as pictures, videos, audio, etc.)
3.2.3 use of + mode
r +: after opening the file, you can either read the file content from the beginning or write new content to the file from the beginning. The written new content will overwrite the original content of the medium length of the file. And the operation file must exist
rb +: open the file in binary format in read-write mode. The pointer of the read-write file will be placed at the beginning of the file, usually for non text files (such as audio files). And the operation file must exist
w +: after opening the file, the original content will be cleared, and the modified file has read and write permission. (if the original file exists, its original contents will be emptied (overwritten); (otherwise, create a new file)
wb +: open the file in binary format and read-write mode. It is generally used for non text files. If the original file exists, it will be overwritten. If it does not exist, a new file will be created.
A +: open the file in read-write mode. If the file exists, the file pointer will be placed at the end of the file, and the newly written file will be located after the existing content; Otherwise, a new file is created.
ab +: open the file in binary mode and use the append mode to have read-write permission for the file. If the file exists, the file pointer is at the end of the file (the newly written file will be after the existing content); Otherwise, a new file is created.
4, Methods of operating files
# Read operation
f.read() # Read all contents. After this operation, the file pointer will move to the end of the file
f.readline()# Read one line and move the cursor to the head of the second line
f.readlines()# Read the contents of each line and store it in the list
#Note: both f.read() and f.readlines() read the content into the content at one time. If the content is too large, it will lead to memory overflow. If you want to read the content into the memory, you must read it multiple times. There are two implementation methods:
# Mode 1:
with open('a.txt',mode='rt',encoding='utf-8') as f:
for line in f:
print(line) # Read only one line of content into memory at the same time
# Mode 2
with open('1.mp4',mode='rb') as f:
while True:
data=f.read(1024) # Only 1024 Bytes are read into memory at the same time
if len(data) == 0:
break
print(data)
#Write operation
f.write('1111\n222\n') # For the writing of text mode, you need to write line breaks yourself
f.write('1111\n222\n'.encode('utf-8')) # For the writing of mode b, you need to write the line feed character yourself
f.writelines(['333\n','444\n']) # File mode
f.writelines([bytes('333\n',encoding='utf-8'),'444\n'.encode('utf-8')]) #b mode
#Other operations
f.readable() # Is the file readable
f.writable() # Is the file readable
f.closed # Close file
f.encoding # If the file open mode is b, this attribute is not available
f.flush() # Immediately swipe the contents of the file from memory to the hard disk
5, Active control of pointer movement in files
#Premise: the movement of pointers in the file is in bytes. The only exception is read (n) in t mode. N is in characters
with open('a.txt',mode='rt',encoding='utf-8') as f:
data=f.read(3) # Read 3 characters
with open('a.txt',mode='rb') as f:
data=f.read(3) # Read 3 Bytes
Previously, the movement of the pointer in the file was passively triggered by the read / write operation. If you want to read the data at a specific location of the file, you need to use the f.seek method to actively control the movement of the pointer in the file. The detailed usage is as follows:
Mode control
Create a.txt text file, the content is: abc Hello, the encoding method is utf-8 (abc each occupies one byte, and Chinese one word three bytes)
0 mode
# 0: the default mode, which represents the number of bytes moved by the pointer, and is referenced by the beginning of the file
#Use of 0 mode
with open('a.txt',mode='rt',ending='utf-8') as f:
f.seek(3,0) # The beginning of the reference file has been moved by three characters
print(f.tell()) # View the position of the current file pointer from the beginning of the file, and the output result is 3
print(f.read()) # From the position of the third byte to the end of the file, the output result is: Hello
#Note: since the read content will be automatically decoded in t mode, it must be ensured that the read content is a complete Chinese data, otherwise the decoding fails
with open('a.txt',mode='rb') as f:
f.seek(6,0)
print(f.read().decode('utf-8')) #The output result is: good
1 mode
# 1 use of mode
with open('a.txt',mode='rb') as f:
f.seek(3,1) # Move back 3 bytes from the current position, and the current position at this time is the beginning of the file
print(f.tell()) # The output result is: 3
f.seek(4,1) # Move back 4 bytes from the current position, while the current position is 3
print(f.tell()) # The output result is: 7
2 mode
# 2 use of mode
with open('a.txt',mode='rb') as f:
f.seek(0,2) # Move 0 bytes by referring to the end of the file, that is, jump directly to the end of the file
print(f.tell()) # The output result is: 9
f.seek(-3,2) # The end of the reference file is moved forward by 3 bytes
print(f.read().decode('utf-8')) # The output result is: good
6, Modification of documents
Note: the hard disk space cannot be modified. The data in the hard disk is updated by overwriting the old content with the new content. The data in memory can be modified.
The file corresponds to the hard disk space. If the hard disk cannot be modified, the nature of the file cannot be modified. Then we can see that the content of the file can be modified. How is it realized? The general idea is to read the contents of the files in the hard disk into the memory, and then overwrite them back to the hard disk after modification in the memory. The specific implementation methods are divided into two types:
6.1 modification method I of documents
# Implementation idea: read all the contents of the file into the memory at one time, and then overwrite and write back to the original file after modification in the memory
# Advantages: in the process of document modification, there is only one copy of the same data
# Disadvantages: it will occupy too much memory
with open('db.txt',mode='rt',encoding='utf-8') as f:
data=f.read()
with open('db.txt',mode='wt',encoding='utf-8') as f:
f.write(data.replace('kevin','svip'))
6.2 modification method II of documents
# Implementation idea: open the original file by reading, open a temporary file by writing, read the contents of the original file line by line, and write the temporary file after modification, Delete the original file and rename the temporary file to the original file name
# Advantages: it will not occupy too much memory
# Disadvantages: in the process of document modification, two copies of the same data are saved
import os
with open('db.txt',mode='rt',encoding='utf-8') as read_f,\
open('.db.txt.swap',mode='wt',encoding='utf-8') as wrife_f:
for line in read_f:
wrife_f.write(line.replace('SB','kevin'))
os.remove('db.txt')
os.rename('.db.txt.swap','db.txt')