Tip: after the article is written, the directory can be generated automatically. Please refer to the help document on the right for how to generate it
Overall topology of ELK and Kafuka
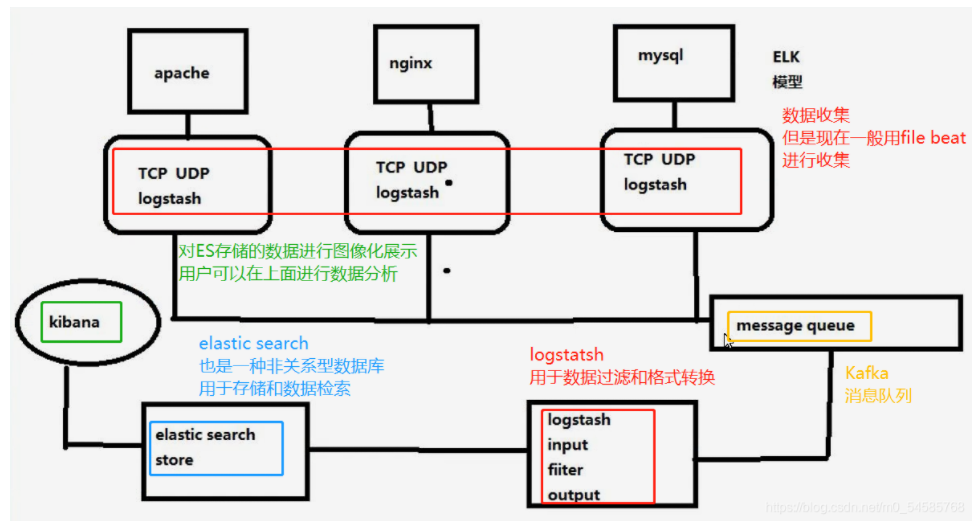
Kafka
Kafka is a distributed Message Queue (MQ) based on publish / subscribe mode, which is mainly used in the field of big data real-time processing.
Kafka was originally developed by Linkedin company. It is a distributed, partition supported, multi replica, Zookeeper coordinated distributed message middleware system. Its biggest feature is that it can process a large amount of data in real time to meet various demand scenarios, such as hadoop based batch processing system, low latency real-time system Spark/Flink streaming engine, nginx access log, message service, etc. are written in scala language. Linkedin contributed to the Apache foundation and became a top open source project in 2010.
characteristic
High throughput, low latency
Kafka can process hundreds of thousands of messages per second, and its latency is as low as a few milliseconds. Each topic can be divided into multiple partitions. The Consumer Group can consume partitions to improve load balancing and consumption capacity.
Scalability
kafka cluster supports hot expansion
Persistence and reliability
Messages are persisted to local disk, and data backup is supported to prevent data loss
Fault tolerance
Allow node failures in the cluster (in the case of multiple replicas, if the number of replicas is n, n-1 nodes are allowed to fail)
High concurrency
Support thousands of clients to read and write at the same time
Kafka system architecture
(1)Broker
A kafka server is a broker. A cluster consists of multiple brokers. A broker can accommodate multiple topic s.
(2)Topic
It can be understood as a queue, and both producers and consumers are oriented to one topic.
Similar to the database table name or ES index
Physically, messages of different topic s are stored separately
(3)Partition
In order to achieve scalability, a very large topic can be distributed to multiple broker s (i.e. servers). A topic can be divided into one or more partitions, and each partition is an ordered queue. Kafka only guarantees that the records in the partition are in order, not the order of different partitions in the topic.
Each topic has at least one partition. When the producer generates data, it will select the partition according to the allocation policy, and then append the message to the end of the queue of the specified partition.
Partation data routing rules:
1. If partition is specified, it can be used directly;
2. If you do not specify a partition but specify a key (equivalent to an attribute in the message), select a partition by hash ing the value of the key;
3. Neither the partition nor the key is specified. Use polling to select a partition.
Each message will have a self increasing number, which is used to identify the offset of the message. The identification sequence starts from 0.
The data in each partition is stored using multiple segment files.
If the topic has multiple partitions, the order of data cannot be guaranteed when consuming data. In the scenario of strictly ensuring the consumption order of messages (such as commodity spike and red envelope grabbing), the number of partitions needs to be set to 1.
Kafka deployed in Zookeeper cluster
cd /opt/ tar zxvf kafka_2.13-2.7.1.tgz mv kafka_2.13-2.7.1 /usr/local/kafka
//Modify profile
cd /usr/local/kafka/config/
cp server.properties{,.bak}
vim server.properties
broker.id=0 ●21 that 's ok, broker Globally unique number of each broker It cannot be repeated, so it should be configured on other machines broker.id=1,broker.id=2
listeners=PLAINTEXT://192.168.80.10:9092 line 31 specifies the IP and port to listen to. If the IP of each broker needs to be modified separately, the default configuration can be maintained without modification
num.network.threads=3 #Line 42, the number of threads that the broker processes network requests. Generally, it does not need to be modified
num.io.threads=8 #Line 45, the number of threads used to process disk IO. The value should be greater than the number of hard disks
socket.send.buffer.bytes=102400 #Line 48, buffer size of send socket
socket.receive.buffer.bytes=102400 #Line 51, buffer size of receive socket
socket.request.max.bytes=104857600 #Line 54, the buffer size of the request socket
log.dirs=/usr/local/kafka/logs #Line 60: the path where kafka operation logs are stored is also the path where data is stored
num.partitions=1 #In line 65, the default number of partitions of topic on the current broker will be overwritten by the specified parameters when topic is created
num.recovery.threads.per.data.dir=1 #69 lines, the number of threads used to recover and clean data
log.retention.hours=168 #In line 103, the maximum retention time of segment file (data file), in hours, defaults to 7 days, and the timeout will be deleted
log.segment.bytes=1073741824 #110 lines. The maximum size of a segment file is 1G by default. If it exceeds, a new segment file will be created
zookeeper.connect=192.168.121.10:2181,192.168.121.12:2181,192.168.121.14:2181 ●123 Rows, configuring connections Zookeeper Cluster address
//Modify environment variables
vim /etc/profile
export KAFKA_HOME=/usr/local/kafka
export PATH=$PATH:$KAFKA_HOME/bin
source /etc/profile
//Configure Zookeeper startup script
vim /etc/init.d/kafka
#!/bin/bash
#chkconfig:2345 22 88
#description:Kafka Service Control Script
KAFKA_HOME='/usr/local/kafka'
case $1 in
start)
echo "---------- Kafka start-up ------------"
${KAFKA_HOME}/bin/kafka-server-start.sh -daemon ${KAFKA_HOME}/config/server.properties
;;
stop)
echo "---------- Kafka stop it ------------"
${KAFKA_HOME}/bin/kafka-server-stop.sh
;;
restart)
$0 stop
$0 start
;;
status)
echo "---------- Kafka state ------------"
count=$(ps -ef | grep kafka | egrep -cv "grep|$$")
if [ "$count" -eq 0 ];then
echo "kafka is not running"
else
echo "kafka is running"
fi
;;
*)
echo "Usage: $0 {start|stop|restart|status}"
esac
//Set startup and self startup
chmod +x /etc/init.d/kafka
chkconfig --add kafka
//Start Kafka separately
service kafka start
3.Kafka command line operation
//Create topic kafka-topics.sh --create --zookeeper 192.168.121.10:2181,192.168.121.12:2181,192.168.121.14:2181 --replication-factor 2 --partitions 3 --topic test ------------------------------------------------------------------------------------- --zookeeper: definition zookeeper Cluster server address, if there are multiple IP Addresses are separated by commas, usually one IP that will do --replication-factor: Define the number of partition replicas. 1 represents a single replica, and 2 is recommended --partitions: Define number of partitions --topic: definition topic name ------------------------------------------------------------------------------------- //View all topic s in the current server kafka-topics.sh --list --zookeeper 192.168.121.10:2181,192.168.121.12:2181,192.168.121.14:2181 //View the details of a topic kafka-topics.sh --describe --zookeeper 192.168.121.10:2181,192.168.121.12:2181,192.168.121.14:2181 //Release news kafka-console-producer.sh --broker-list 192.168.121.10:9092,192.168.121.12:9092,192.168.121.14:9092 --topic test //Consumption news kafka-console-consumer.sh --bootstrap-server 192.168.121.10:9092,192.168.121.12:9092,192.168.121.14:9092 --topic test --from-beginning ------------------------------------------------------------------------------------- --from-beginning: All previous data in the topic will be read out ------------------------------------------------------------------------------------- //Modify the number of partitions kafka-topics.sh --zookeeper 192.168.80.10:2181,192.168.80.11:2181,192.168.80.12:2181 --alter --topic test --partitions 6 //Delete topic kafka-topics.sh --delete --zookeeper 192.168.80.10:2181,192.168.80.11:2181,192.168.80.12:2181 --topic test
Deploy Filebeat
cd /usr/local/filebeat
vim filebeat.yml
filebeat.prospectors:
- type: log
enabled: true
paths:
- /var/log/messages
- /var/log/*.log
......
#Add configuration output to Kafka
output.kafka:
enabled: true
hosts: ["192.168.80.10:9092","192.168.80.11:9092","192.168.80.12:9092"] #Specify Kafka cluster configuration
topic: "filebeat_test" #Specify topic for Kafka
#Start filebeat
./filebeat -e -c filebeat.yml
Deploy ELK
cd /etc/logstash/conf.d/
vim filebeat.conf
input {
kafka {
bootstrap_servers => "192.168.80.10:9092,192.168.80.11:9092,192.168.80.12:9092"
topics => "filebeat_test"
group_id => "test123"
auto_offset_reset => "earliest"
}
}
output {
elasticsearch {
hosts => ["192.168.80.30:9200"]
index => "filebeat-%{+YYYY.MM.dd}"
}
stdout {
codec => rubydebug
}
}
#Start logstash
logstash -f filebeat.conf