Preface
- Article Java AQS Queue Synchronizer and ReentrantLock Application This paper introduces the implementation of AQS exclusive acquisition of synchronization state, and illustrates how ReentrantLock customizes synchronizer mutually exclusive lock.
- Article Java AQS Shared Obtain Synchronization Status and Semaphore Application Analysis Introduces the implementation of AQS shared synchronization state acquisition and how Semaphore customizes the synchronizer for simple current limiting
With the padding of these two articles, it's easy to understand ReadWriteLock, which is both exclusive and shared for synchronization.
ReadWriteLock
ReadWriteLock is translated literally as ReadWriteLock.In reality, business scenarios with more reads and fewer writes are common, such as applying caching
One thread writes data to the cache, while other threads can read data directly from the cache to improve data query efficiency
Mutexes mentioned earlier are exclusive locks, which means only one thread is allowed to access at a time. Mutexes are obviously an inefficient way to handle shared and readable business scenarios.To improve efficiency, a read-write lock model was created
Increasing efficiency is one aspect, but programming is more important to improve efficiency while ensuring accuracy
One write thread changed the value in the cache, and the other read threads must be "aware" of it, otherwise the value queried might be inaccurate
So the following three rules apply to the read-write lock model:
- Allow multiple threads to read shared variables simultaneously
- Allow only one thread to write shared variables
- If a write thread is performing a write operation, other read threads are prohibited from reading shared variables at this time
ReadWriteLock is an interface with only two methods:
public interface ReadWriteLock { // Return lock for reading Lock readLock(); // Returns the lock used for writing Lock writeLock(); }
So to understand the entire application of read/write locks, you need to start with its implementation class ReentrantReadWriteLock
ReentrantReadWriteLock class structure
Direct comparison of class structure between ReentrantReadWriteLock and ReentrantLock
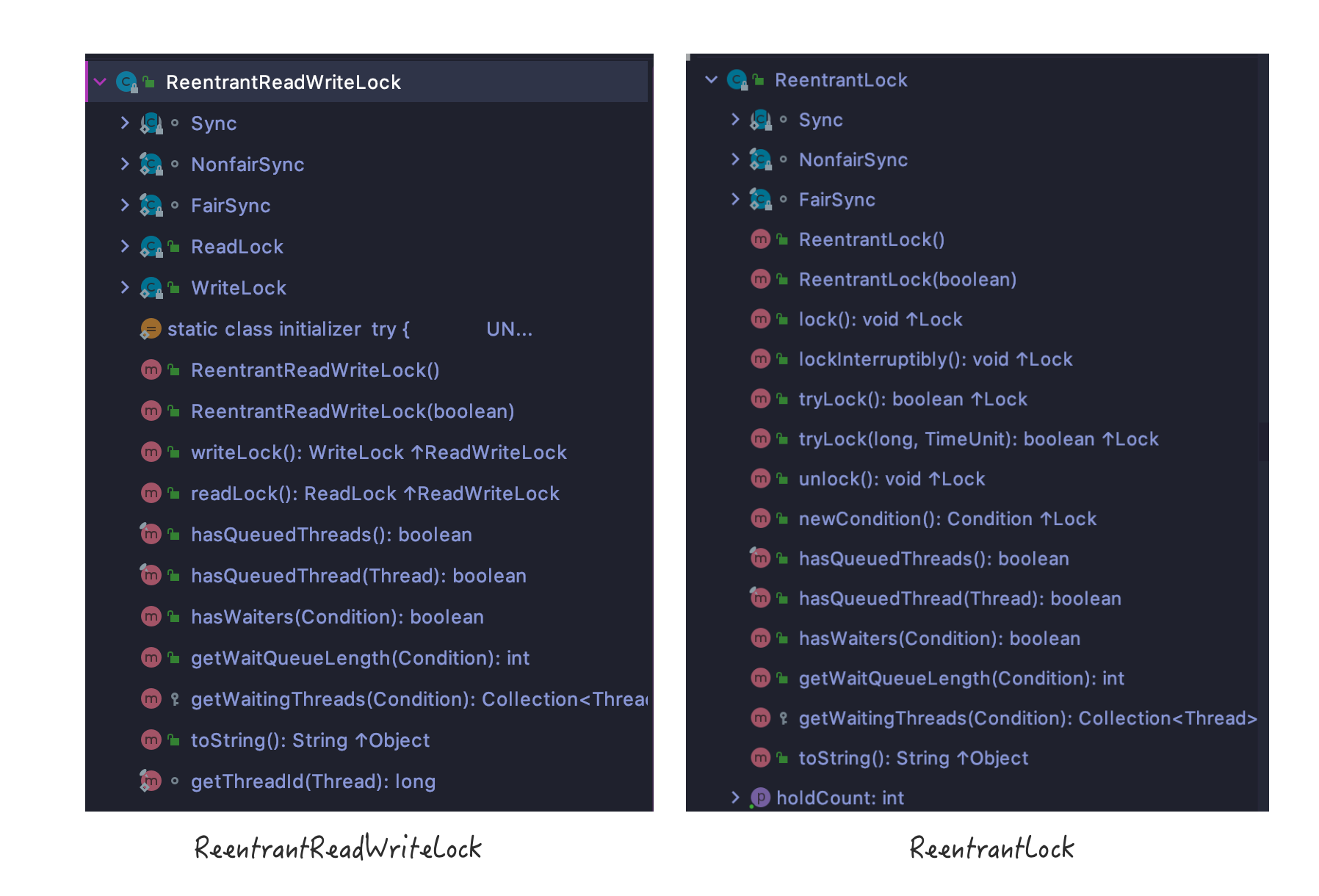
They are similar again, depending on the class name and class structure, you can also see the basic features of ReentrantReadWriteLock, as analyzed in the previous article:

The yellow-marked lock downgrade is not visible, so here's the first impression, which will be explained separately below
Also, I don't know if you remember, Java AQS Queue Synchronizer and ReentrantLock Application As mentioned, Lock and AQS synchronizers exist as a form of combination, since here are read/write locks, their combination modes are also divided into two types:
- Aggregation of read locks with custom Synchronizers
- Write Lock Aggregation with Custom Synchronizer
public ReentrantReadWriteLock(boolean fair) { sync = fair ? new FairSync() : new NonfairSync(); readerLock = new ReadLock(this); writerLock = new WriteLock(this); }
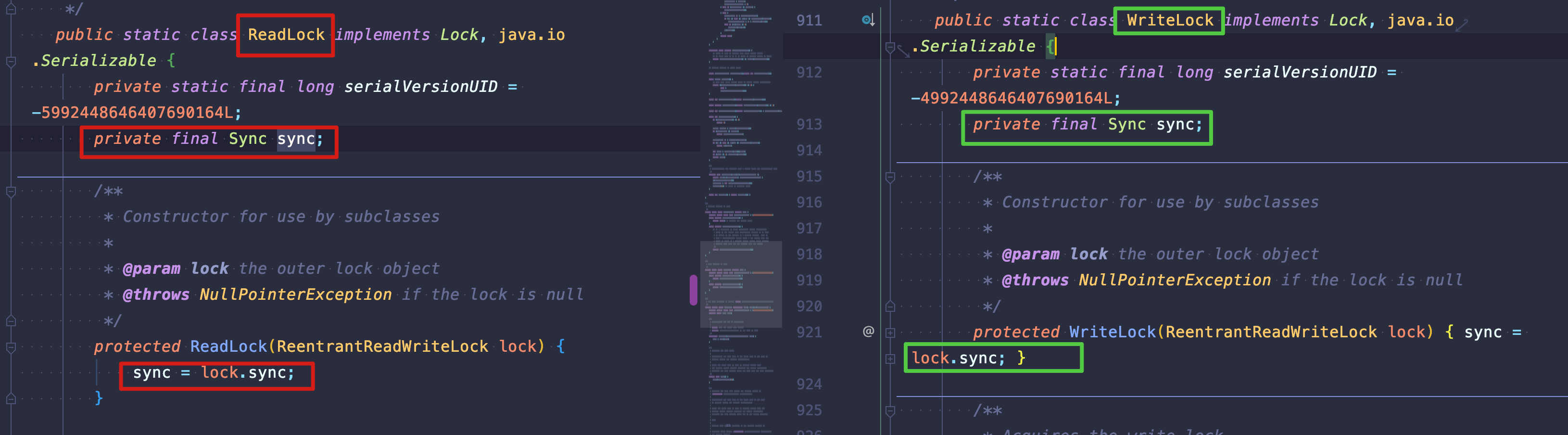
Here's just a reminder that the pattern hasn't changed. Don't be confused by read/write locks
Basic examples
So much said, if you forget the preamble, your overall understanding should be out of date, so let's start with an example (simulated use of caching) that gives you an intuitive impression of ReentrantReadWriteLock
public class ReentrantReadWriteLockCache { // Define a non-thread-safe HashMap for caching objects static Map<String, Object> map = new HashMap<String, Object>(); // Create Read-Write Lock Object static ReadWriteLock readWriteLock = new ReentrantReadWriteLock(); // Build Read Lock static Lock rl = readWriteLock.readLock(); // Build a write lock static Lock wl = readWriteLock.writeLock(); public static final Object get(String key) { rl.lock(); try{ return map.get(key); }finally { rl.unlock(); } } public static final Object put(String key, Object value){ wl.lock(); try{ return map.put(key, value); }finally { wl.unlock(); } } }
You see, it's so easy to use.But as you know, the core of AQS is the implementation of locks, which control the value of synchronization state. ReentrantReadWriteLock also uses AQS state to control synchronization state, so the problem is:
How can an int-type state control both read and write synchronization?
Clearly a little design is needed
Read-Write State Design
If you want to maintain multiple states on an int-type variable, you must split it.We know that int-type data takes up 32 bits, so we have the opportunity to cut states in bits.We cut it into two parts:
- High 16 Bit Representation Read
- Low 16 Bit Representation Write
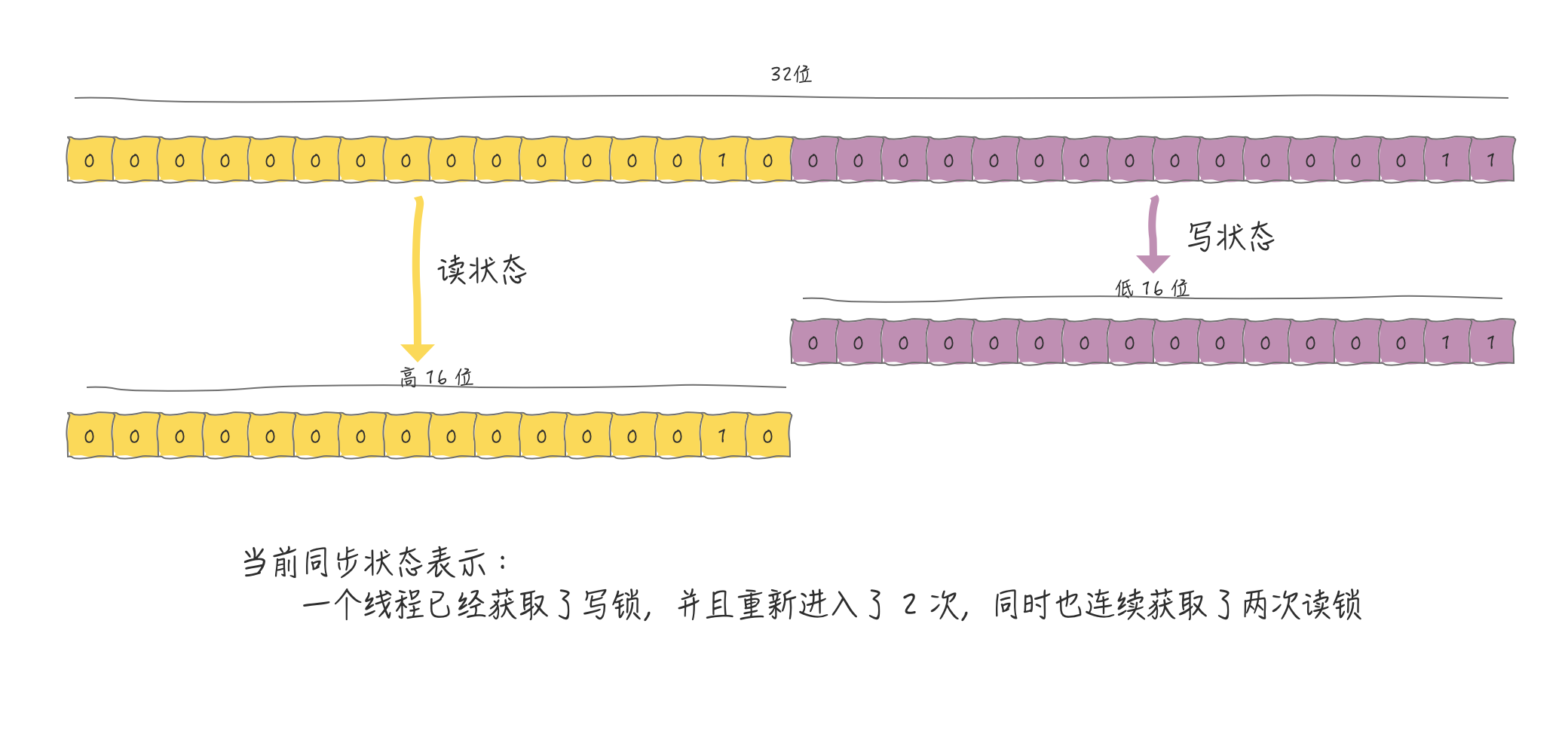
So if you want to accurately calculate the read/write status values, you must apply bit operations. The code below is JDK1.8, ReentrantReadWriteLock Custom Sync bit operations
abstract static class Sync extends AbstractQueuedSynchronizer { static final int SHARED_SHIFT = 16; static final int SHARED_UNIT = (1 << SHARED_SHIFT); static final int MAX_COUNT = (1 << SHARED_SHIFT) - 1; static final int EXCLUSIVE_MASK = (1 << SHARED_SHIFT) - 1; static int sharedCount(int c) { return c >>> SHARED_SHIFT; } static int exclusiveCount(int c) { return c & EXCLUSIVE_MASK; } }
At first glance, it's really complicated and terrible. Don't panic. Let's solve the whole bit operation with a few small math problems.

The entire ReentrantReadWriteLock calculation of the read/write state is to apply these math problems repeatedly, so before reading the following, I hope you understand this simple operation
Foundation padding is enough, let's go into source analysis
Source Code Analysis
Write Lock Analysis
Since the write lock is exclusive, it must be necessary to override the tryAcquire method in AQS
protected final boolean tryAcquire(int acquires) { Thread current = Thread.currentThread(); // Get the value of the state as a whole int c = getState(); // Get the value of the write state int w = exclusiveCount(c); if (c != 0) { // w=0: According to inference two, the overall state is not equal to zero, and the write state is equal to zero, so the read state is greater than 0, that is, there is a read lock // Or the current thread is not one that has acquired a write lock // Getting the write state fails if either of these conditions is true if (w == 0 || current != getExclusiveOwnerThread()) return false; if (w + exclusiveCount(acquires) > MAX_COUNT) throw new Error("Maximum lock count exceeded"); // Update Write Status Value according to inference 1 Article 1 setState(c + acquires); return true; } if (writerShouldBlock() || !compareAndSetState(c, c + acquires)) return false; setExclusiveOwnerThread(current); return true; }
The writerShouldBlock in line 19 above is not mysterious either, it's just a judgment of fair/unfair access to locks (whether there are any precursor nodes)
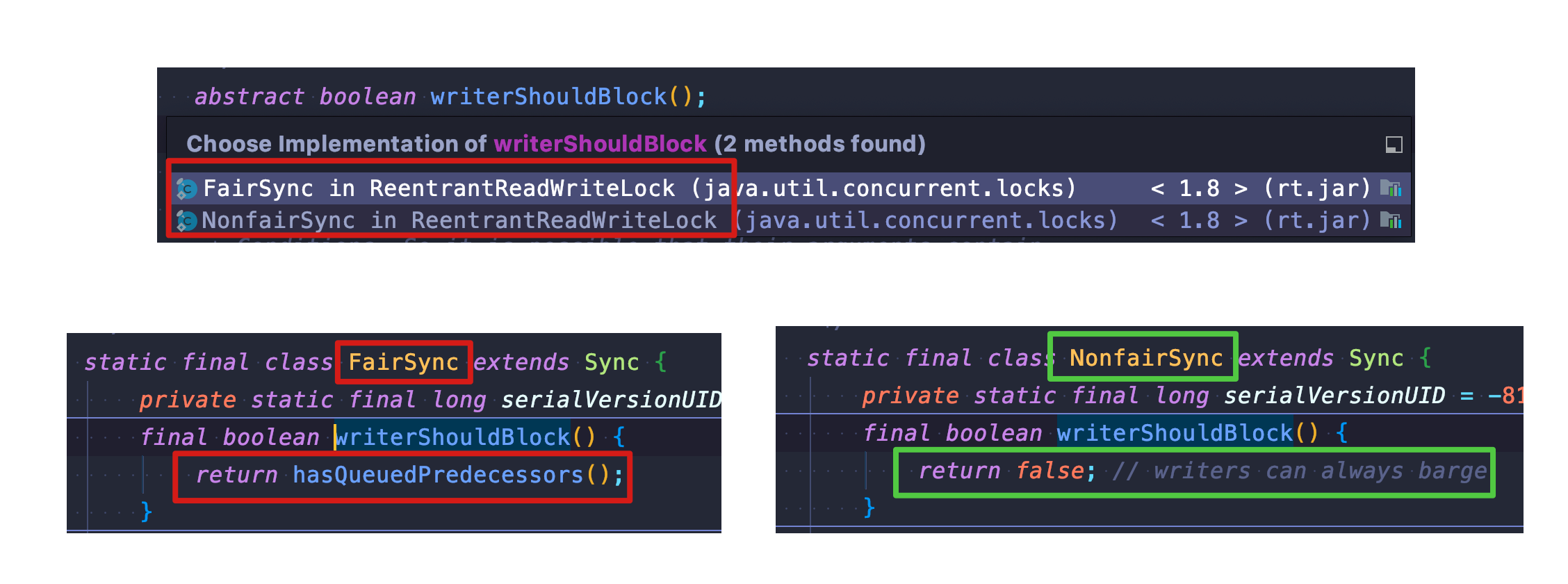
Look, it's so easy to get a write lock
Read Lock Analysis
Since the read lock is shared, you must override the tryAcquireShared method in AQS
protected final int tryAcquireShared(int unused) { Thread current = Thread.currentThread(); int c = getState(); // Write state is not equal to 0 and lock holder is not current thread, acquiring read lock fails according to contract 3 if (exclusiveCount(c) != 0 && getExclusiveOwnerThread() != current) return -1; // Get Read State Value int r = sharedCount(c); // This place is a bit different, let's explain it separately if (!readerShouldBlock() && r < MAX_COUNT && compareAndSetState(c, c + SHARED_UNIT)) { if (r == 0) { firstReader = current; firstReaderHoldCount = 1; } else if (firstReader == current) { firstReaderHoldCount++; } else { HoldCounter rh = cachedHoldCounter; if (rh == null || rh.tid != getThreadId(current)) cachedHoldCounter = rh = readHolds.get(); else if (rh.count == 0) readHolds.set(rh); rh.count++; } return 1; } // If acquiring a read lock fails, enter spin acquisition return fullTryAcquireShared(current); }
readerShouldBlock and writerShouldBlock both determine whether there are precursor nodes in the implementation of fair locks, but in the implementation of unfair locks, the former is as follows:
final boolean readerShouldBlock() { return apparentlyFirstQueuedIsExclusive(); } final boolean apparentlyFirstQueuedIsExclusive() { Node h, s; return (h = head) != null && // Waiting for the next node of the queue header node (s = h.next) != null && // If it is an exclusive node !s.isShared() && s.thread != null; }
Simply put, if the current thread requesting a read lock finds the head of the synchronization queueIf the next node of the node is an exclusive node, then there is a thread waiting to acquire a write lock (failed to contend for a write lock and put in a synchronization queue), then the thread requesting to read the lock will be blocked, because there are more reads and fewer writes. Write locks may occur if there is no such judgment mechanism yet.
These conditions are met and you enter lines 14 through 25 of the tryAcquireShared code, which is mainly to record the number of locks held by threads.Read locks are shared, and to record the number of read locks held by each thread, ThreadLocal is used, because it does not affect the value of the synchronization state state, so no analysis is done, just put the relationship here
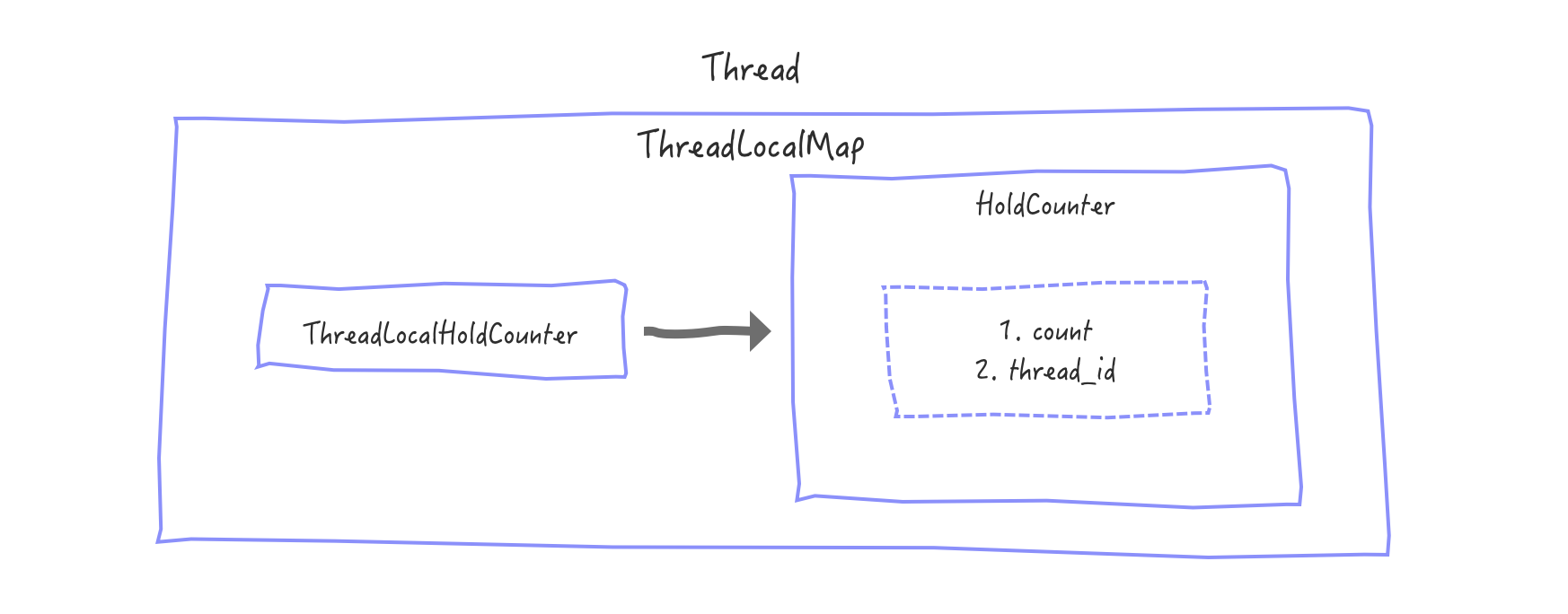
Now that the acquisition of the read lock is over, lost slightly more complex than the write lock, let's explain the upgrade/downgrade of the lock that might confuse you.
Upgrade and downgrade of read-write locks
**Personal understanding: ** Read locks can be shared by multiple threads, write locks are single-threaded exclusive, that is, write locks have a higher concurrency limit than read locks, so
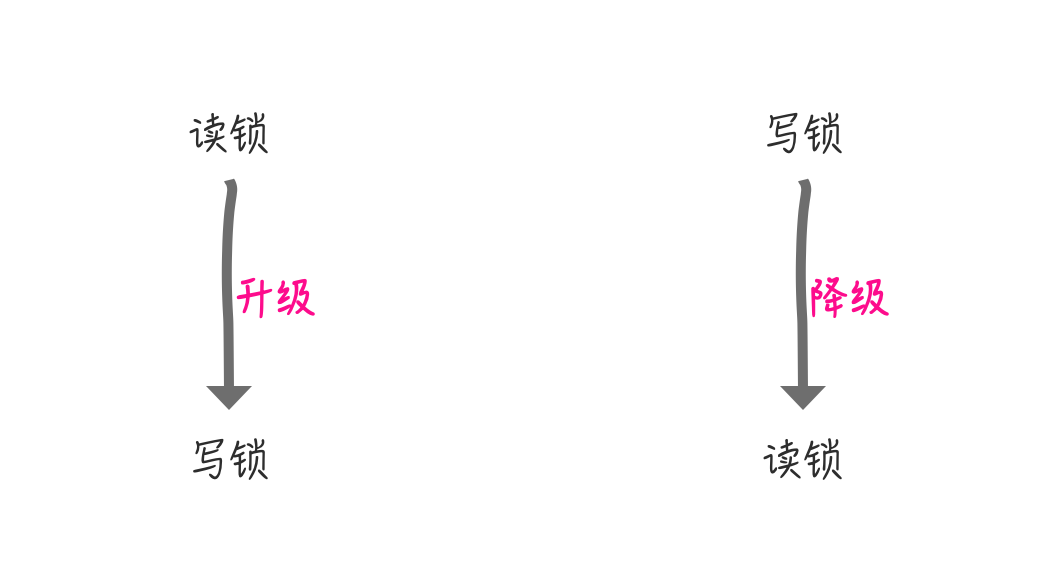
Before we can really understand the upgrade and downgrade of read-write locks, we need to refine the ReentrantReadWriteLock example at the beginning of this article
public static final Object get(String key) { Object obj = null; rl.lock(); try{ // Get the value in the cache obj = map.get(key); }finally { rl.unlock(); } // Cache median is not empty, returned directly if (obj!= null) { return obj; } // If the value in the cache is empty, the DB is queried by a write lock and written to the cache wl.lock(); try{ // Try again to get the value in the cache obj = map.get(key); // Get the cache median again or is it empty if (obj == null) { // Query DB obj = getDataFromDB(key); // Pseudocode: getDataFromDB // Put it in the cache map.put(key, obj); } }finally { wl.unlock(); } return obj; }
Children's shoes may be questionable
Inside the write lock, why does line 19 of the code need to retrieve the value from the cache again?Isn't that a redundant move?
In fact, it is necessary to try to get the value in the cache again here because there may be multiple threads executing the get method at the same time and the parameter key s are the same, up to line 16 of the codeWl.lock() For example:
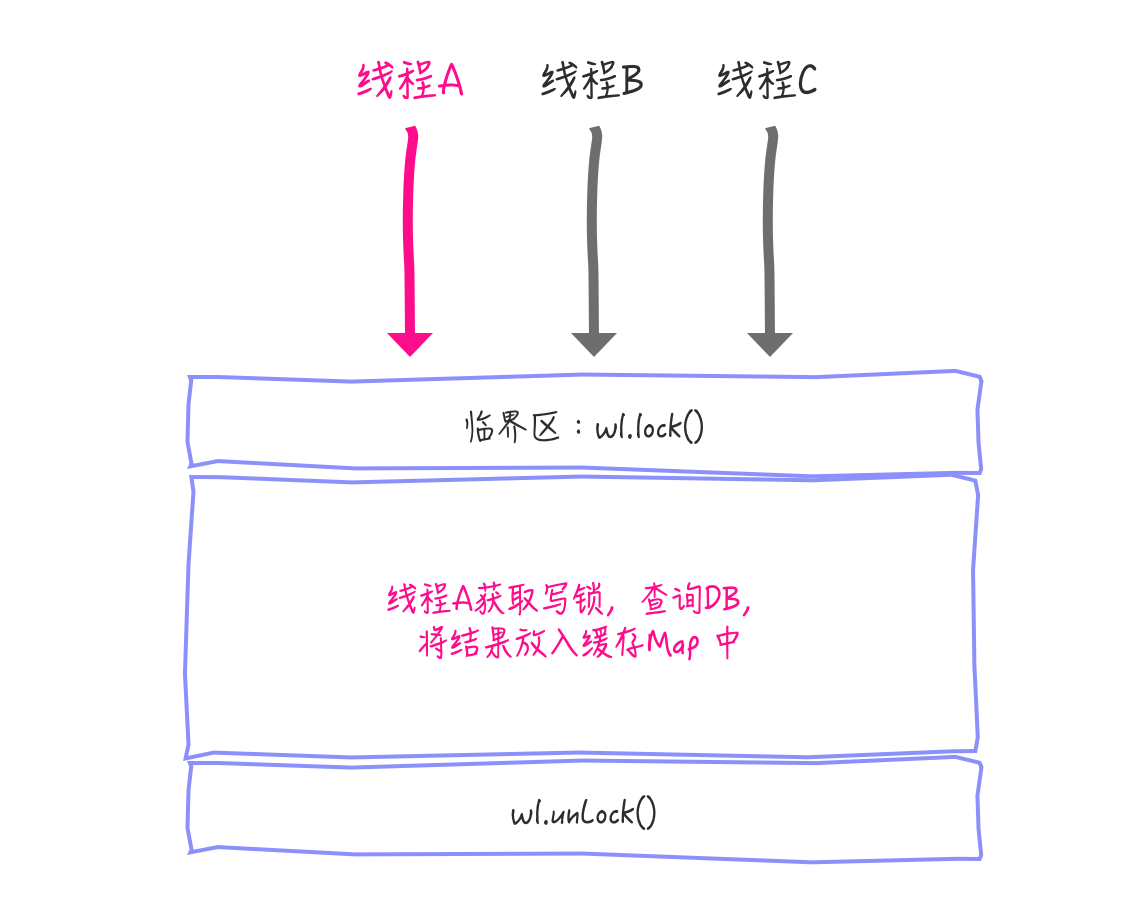
Threads A, B, C execute simultaneously to the critical zoneWl.lock(), only thread A acquires the write lock successfully, thread B, and C can only block until thread A releases the write lock.At this point, when thread B or C enters the critical zone again, thread A has updated the value to the cache, so thread B and C do not need to query DB again, but try to query the value in the cache again
Since it is necessary to retrieve the cache again, can I directly judge in the read lock that if there is no value in the cache, then retrieve the write lock again to query the DB is not OK, just like this:
public static final Object getLockUpgrade(String key) { Object obj = null; rl.lock(); try{ obj = map.get(key); if (obj == null){ wl.lock(); try{ obj = map.get(key); if (obj == null) { obj = getDataFromDB(key); // Pseudocode: getDataFromDB map.put(key, obj); } }finally { wl.unlock(); } } }finally { rl.unlock(); } return obj; }
This is really not possible because acquiring a write lock requires all the read locks to be released first. Deadlocks occur when two read locks attempt to acquire a write lock without releasing the read lock, so lock upgrade is not allowed here
Upgrading read and write locks is not possible, so what about downgrading locks?This is Example of Oracle Official Gateway on Lock Degradation I'll paste the code here and you'll be interested in clicking in to connect and see more
class CachedData { Object data; volatile boolean cacheValid; final ReentrantReadWriteLock rwl = new ReentrantReadWriteLock(); void processCachedData() { rwl.readLock().lock(); if (!cacheValid) { // Read locks must be released before a write lock can be acquired because lock upgrade is not allowed rwl.readLock().unlock(); rwl.writeLock().lock(); try { // Check again, possibly because another thread has updated the cache if (!cacheValid) { data = ... cacheValid = true; } //Demote to read lock before releasing write lock rwl.readLock().lock(); } finally { //Release the write lock, holding the read lock at this time rwl.writeLock().unlock(); } } try { use(data); } finally { rwl.readLock().unlock(); } } }
The code declares a cacheValid variable of volatile type to ensure its visibility.
- Get the read lock first, and release it if the cache is unavailable
- Then get the write lock
- Before changing the data, check the value of cacheValid again, then modify the data to set cacheValid to true
- Then acquire the read lock before releasing the write lock at this time
- Data in cache is available, data in cache is processed, and read locks are released
This process is a complete lock demotion process to ensure data visibility, which sounds reasonable, so here's the problem:
Why should the above code acquire a read lock before releasing the write lock?
If the current thread A releases the write lock instead of acquiring the read lock after modifying the data in the cache; assuming another thread B acquires the write lock and modifies the data at this time, thread A cannot perceive that the data has been modified, but thread A also applies the cached data, so data errors may occur
If thread A acquires a read lock before releasing the write lock following the lock demotion step, thread B will be blocked from acquiring the write lock until thread A completes the data processing and releases the read lock, thereby ensuring data visibility
Here comes the question again:
Do I have to downgrade when using write locks?
If you understand the above question, you believe it has already been answered.If Thread A has finished modifying the data,When you want to reuse the data after a time-consuming operation, you want to use your modified data instead of the modified data by other threads, which really requires a lock downgrade; if you only want to get the latest data when you last use the data, not necessarily the data you just modified, release the write lock, acquire the read lock, and make theUse data as well
Here I'd like to add an extra explanation of your possible misconceptions:
-
Upgrade to acquire a write lock without calling a lock if the read lock has been released
-
If a write lock has been released, acquiring a read lock does not degrade the lock
I'm sure you've come here to understand how locks are upgraded and downgraded, and why they're allowed or prohibited
summary
This paper mainly explains how ReentrantReadWriteLock uses state bitsplitting to achieve read/write synchronization. It also analyzes the process of acquiring read/write synchronization through source code. Finally, it understands the upgrade/downgrade mechanism of read/write locks. I believe you have a certain understanding of read/write locks here.If you find it difficult to understand what is in this article, I strongly recommend that you look back at the two articles at the beginning of this article, which are paved with a lot of content.Next let's look at CountDownLatch, the last concurrent tool class to use AQS
Soul Question
- Read locks do not modify data and allow shared access. Is it necessary to set up a read lock?
- How do you ensure consistency of cached data in a distributed environment?
- When you open the ReentrantReadWriteLock source code, you will find that Conditions can be used in WriteLock, but ReadLock uses Conditions and throws an UnsupportedOperationException. Why?
// WriteLock public Condition newCondition() { return sync.newCondition(); } // ReadLock public Condition newCondition() { throw new UnsupportedOperationException(); }
Original Qiang Rigong