catalogue
1. Data processing language of stream processing
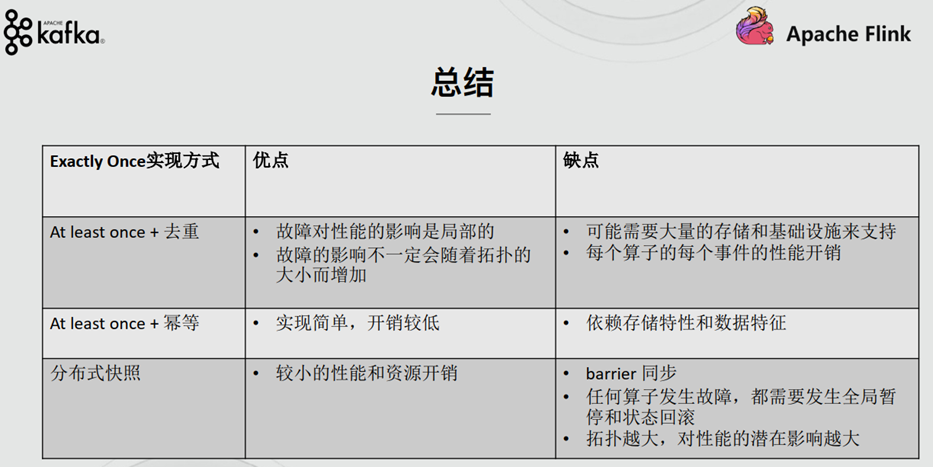
1.5. Accurate once & effective once
1.6. How does stream computing system support consistency semantics
2. Implementation of end to end exactly once
2.2.1. Distributed snapshot mechanism
2.2.3. Asynchronous and incremental
3. End to end exactly once of Flink + Kafka
3.3. Two stage submission - simple process
3.4. Two stage submission - detailed process
3.4.2. Pre submission - internal status
3.4.3. Pre submission - external status
4.1. Flink+Kafka implements end to end exactly once
4.2. Flink+MySQL implements end to end exactly once
0. Links to related articles
1. Data processing language of stream processing
For batch processing, fault tolerance is easy to do. Failure can be perfectly tolerated only by replay ing.
For stream processing, the data stream itself is dynamic, and there is no so-called start or end. Although part of the data in the buffer can be replayed, the fault tolerance will be much more complex.
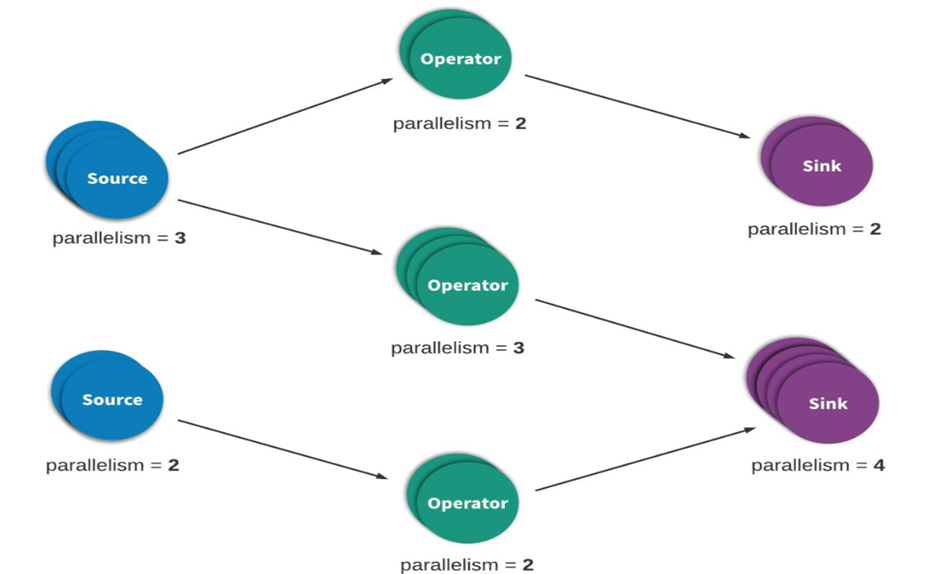
Stream processing (sometimes called event processing) can be simply described as continuous processing of unbounded data or events. Flow or event handling applications can be more or less described as directed graphs, and are often described as directed acyclic graphs (DAG s). In such a graph, each edge represents a flow of data or events, and each vertex represents an operator. The logic defined in the program will be used to process data or events from adjacent edges. There are two special types of vertices, commonly referred to as sources and sinks. Sources reads external data / events into the application, while sinks usually collects the results generated by the application. The following figure is an example of a streaming application. It has the following characteristics:
- In distributed case, it is composed of multiple source nodes, multiple operator nodes and multiple sink nodes
- The parallel number of each node can be different, and each node may fail
- The most important point for data correctness is how to fault tolerance and recovery in case of failure.
Stream processing engines usually provide three kinds of data processing semantics for applications: at most once, at least once, and exactly once.
The following is a loose definition of these different processing semantics (consistency from weak to strong): at most noce < at least once < exactly once < end to end exactly once
1.1. At most once
There may be data loss. This is essentially a simple recovery method, that is, directly start the recovery program from the next data at the failure, and ignore the previous failed data processing. Data or events can be guaranteed to be processed by all operators in the application at most once. This means that if the data is lost before it is fully processed by the streaming application, there will be no other retries or resending.

1.2. At least once
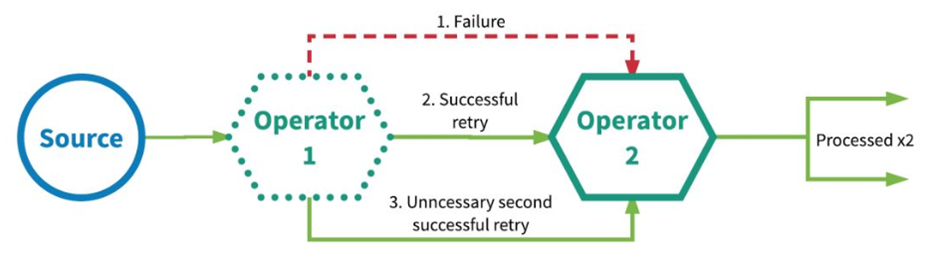
It is possible to process data repeatedly. All operators in the application ensure that data or events are processed at least once. This usually means that if an event is lost before the streaming application has fully processed it, the event will be replayed or retransmitted from the source. However, because events can be retransmitted, an event can sometimes be processed multiple times (at least once). As for whether there is duplicate data, we don't care. Therefore, this scenario requires manual intervention to process duplicate data by ourselves.
1.3. Exactly once
Exactly once is one of the core features of Flink, Spark and other stream processing systems. This semantics will ensure that each message is processed only once by the stream processing system. Even in the case of various faults, all operators in the flow application ensure that the event will only be processed "exactly once". (some articles translate exactly once as: completely once, exactly once).
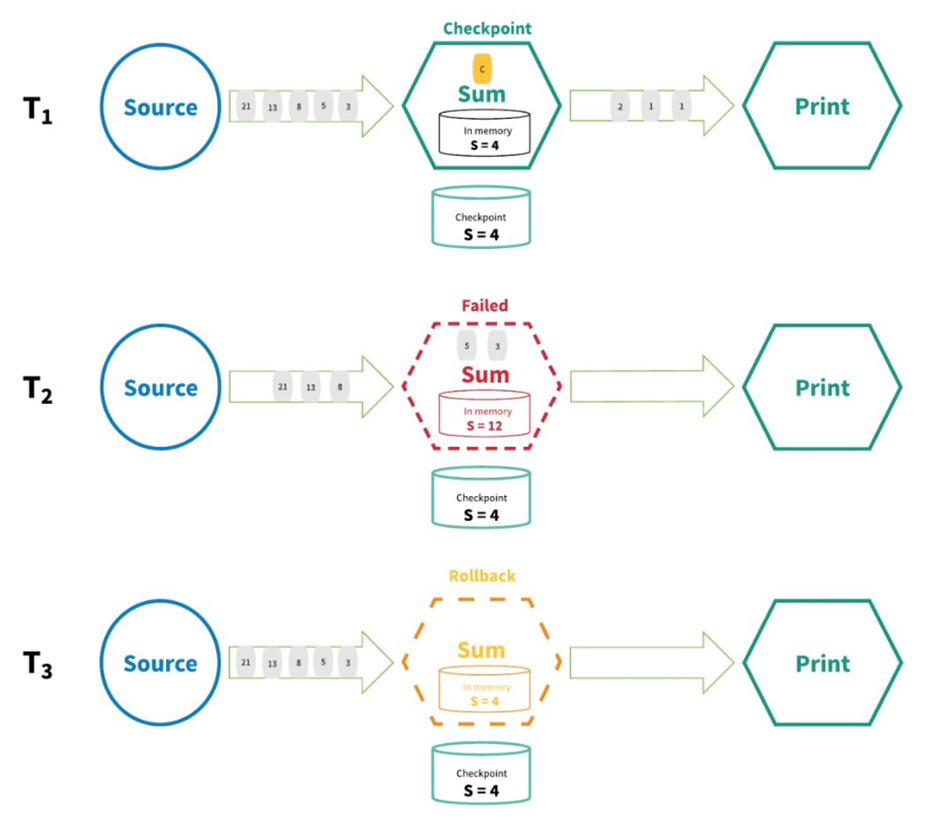
Flink's distributed snapshot / state checkpoint method of "accurate once" is inspired by chandy Lamport distributed snapshot algorithm. Through this mechanism, all States of each operator in the flow application will be checked regularly. If the failure occurs anywhere in the system, all States of each operator will be rolled back to the latest globally consistent checkpoint. During rollback, all processing is suspended. The source is also reset to the correct offset corresponding to the most recent checkpoint. The whole streaming application basically returns to the last consistent state, and then the program can be restarted from that state.
1.4. End to end exactly once
Flink introduces "exactly once" in version 1.4.0 and claims to support the "end-to-end exactly once" semantics of "end-to-end exactly once". It refers to the starting point and ending point that the Flink application must pass from the Source end to the Sink end.
The differences between "exactly once" and "end to end exactly once" are as follows:
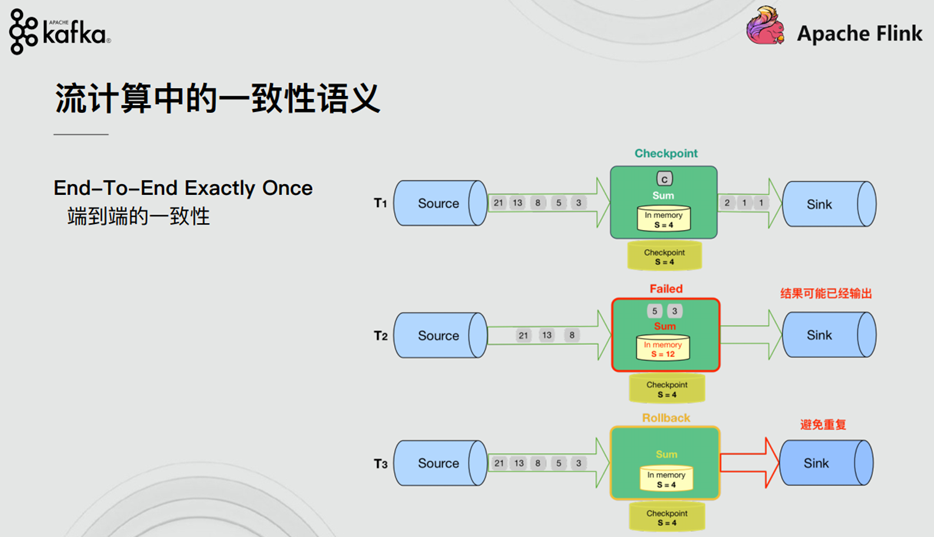

1.5. Accurate once & effective once
Some people may think that "accurate once" describes the guarantee of event processing, in which each event in the stream is processed only once. In fact, no engine can guarantee that it will be processed exactly once. In the face of any fault, it is impossible to ensure that the user-defined logic in each operator is executed only once in each event, because the possibility of partial execution of user code always exists.
So, when engines declare "exactly once" processing semantics, what can they guarantee? If the user logic cannot be guaranteed to be executed only once, what logic is executed only once? When the engine declares "exactly once" processing semantics, they are actually saying that they can ensure that the state updates managed by the engine are submitted to the persistent back-end storage only once.
Event processing can occur multiple times, but the effect of this processing is only reflected once in the persistent back-end state store. Therefore, we believe that the best term to effectively describe these processing semantics is "effectively once".
1.6. How does stream computing system support consistency semantics
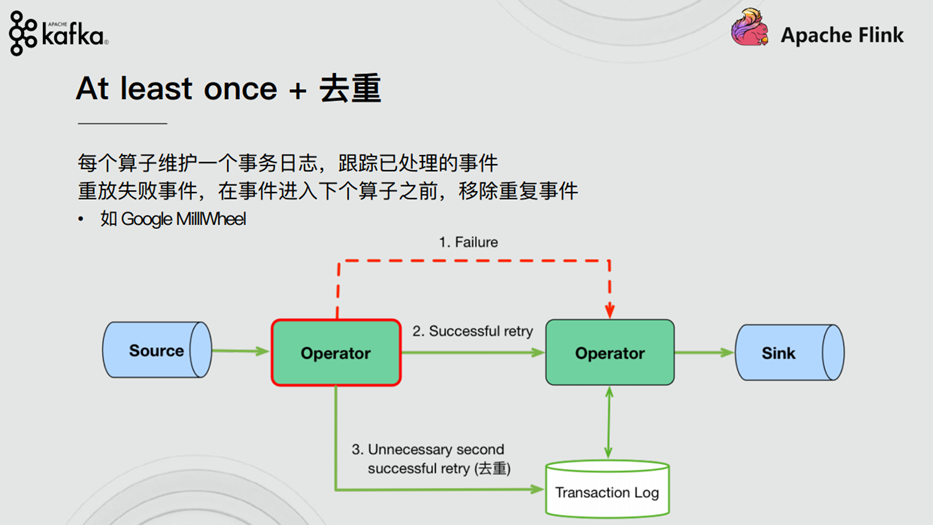
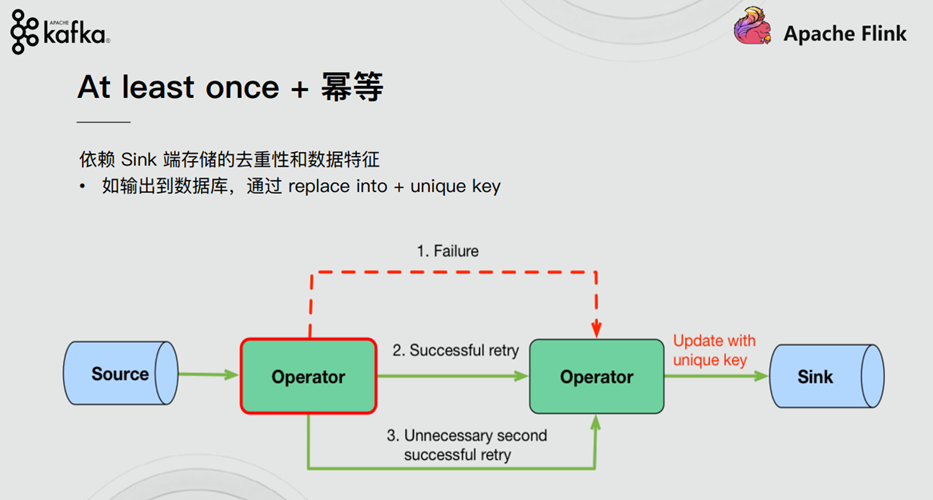
2. Implementation of end to end exactly once
With the help of distributed snapshot Checkpoint, Flink has realized the internal exactly once, but Flink itself cannot guarantee the "accurate once" semantics of other external systems. Therefore, if Flink wants to realize the requirement of "End to End accurate once", the external system must support the "accurate once" semantics; Then it can be achieved by some other means.
2.1. Source
In case of failure, it is necessary to support resetting the reading position of data. For example, Kafka can be realized through offset (for other systems without offset, we can realize accumulator counting by ourselves)
2.2. Transformation
That is, within Flink, it has been guaranteed through checkpoint that if there is a failure or error, the Flink application will recover from the latest successfully completed checkpoint after restarting - reset the application state and roll back the state to the correct position of the input stream in the checkpoint, and then start data processing, as if the failure or crash had never occurred.
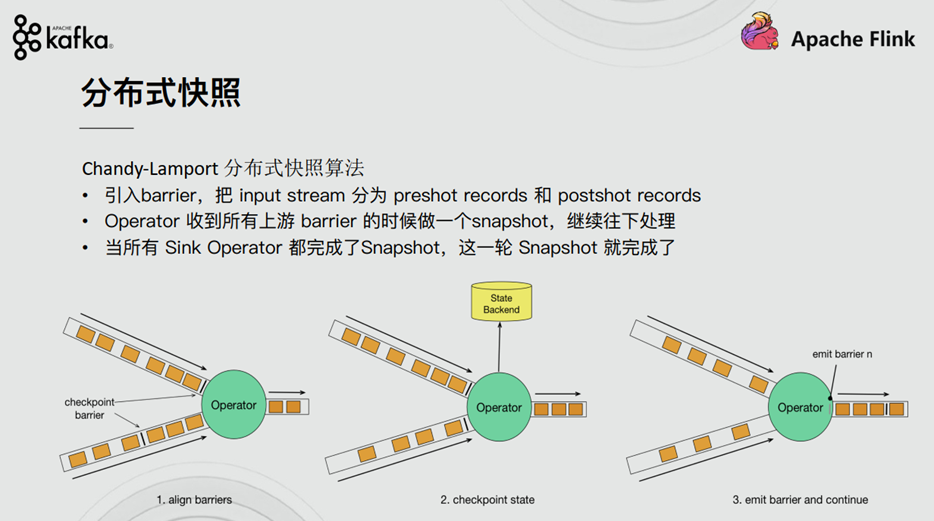
2.2.1. Distributed snapshot mechanism
We explained Flink's fault-tolerant mechanism in previous courses. Flink provides a fault-tolerant mechanism for failure recovery, and the core of this fault-tolerant mechanism is to continuously create snapshots of distributed data streams.
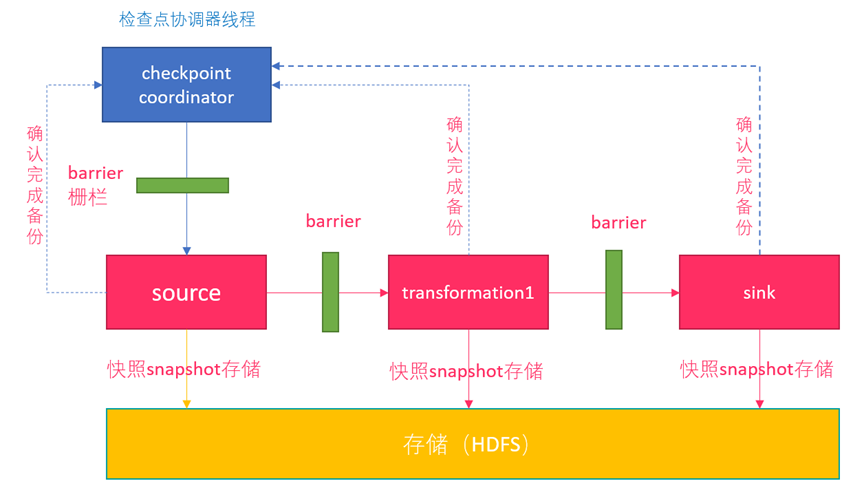
Compared with Spark, Spark is only a fault recovery Checkpoint for the Driver. The snapshot of Flink can be to the operator level, and the global data can also be snapshot. Flink's distributed snapshot is inspired by the chandy Lamport distributed snapshot algorithm and customized at the same time.
2.2.2. Barrier
One of the core elements of Flink distributed snapshot is Barrier (data fence). We can also simply understand Barrier as a tag, which is strictly ordered and flows down with the data flow. Each Barrier has its own ID. the Barrier is extremely lightweight and will not interfere with normal data processing.
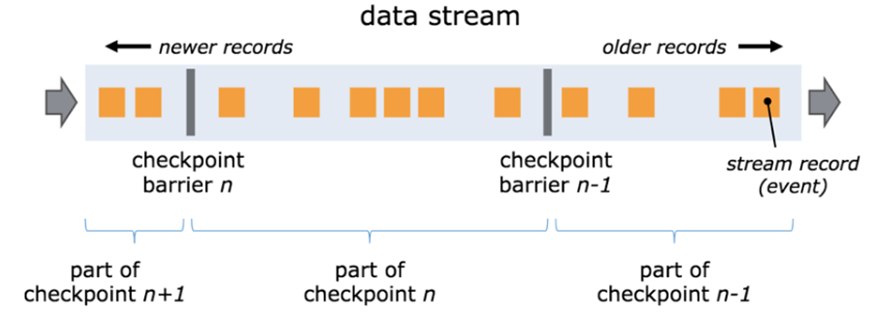
As shown in the figure above, if we have a data stream flowing from left to right, Flink will generate snapshot 1, snapshot 2 and snapshot 3 in turn... Flink has a special "coordinator" responsible for collecting the location information of each snapshot, and this "coordinator" is also highly available.
The Barrier will continue to flow down with the normal data. Whenever an operator is encountered, the operator will insert an identifier. The insertion time of this identifier is that all upstream input streams receive snapshot n. At the same time, when our sink operator receives the Barrier sent by all upstream streams, it indicates that this batch of data has been processed, and Flink will send a confirmation message to the "coordinator", indicating that the current snapshot n has been completed. When all sink operators confirm that this batch of data is processed successfully, the snapshot is marked as completed.
There will be a problem here. Because Flink runs in a distributed environment, there will be many streams upstream of an operator. What if the arrival time of barrier n of each stream is inconsistent? The measures taken by Flink here are: fast flow and slow flow.

Take the barrier n in the figure above as an example. One of them flows early and the other flows late. When the first barrier n arrives, the current operator will continue to wait for the barrier n of other streams. The operator will not send all data down until all barriers n arrive.
2.2.3. Asynchronous and incremental
According to the mechanism described above, every time the snapshot is stored in our state backend, if it is synchronized, it will block the normal task and introduce delay. Therefore, Flink can use asynchronous mode when storing snapshots.
In addition, because checkpoint is a global state, the state saved by users may be very large, most of which reach the level of G or T. In this case, the creation of checkpoint will be very slow, and the execution will occupy more resources. Therefore, Flink proposed the concept of incremental snapshot. In other words, the full amount of checkpoints is updated every time, which is based on the last update.
2.3. Sink
Idempotent write or transaction write is required (transaction support is required for Flink's two-phase commit)
2.3.1. Idempotent Writes
Idempotent write operation refers to writing data to a system any number of times, which only affects the result of the target system once.
For example, repeatedly insert the same key value binary pair into a HashMap. The HashMap changes during the first insertion, and subsequent insertion operations will not change the result of the HashMap. This is an idempotent write operation. KV databases such as HBase, Redis and Cassandra are often used as Sink to realize end-to-end exactly once.
It should be noted that a KV database does not support idempotent writing. Idempotent writing requires KV pairs, that is, the Key value must be deterministically calculated. If the Key we designed is: name + curTimestamp, each time we execute data retransmission, the generated Key is different, and multiple results will be generated. The whole operation is not idempotent. Therefore, in order to pursue end-to-end exactly once, we should try to use Deterministic computing logic and data model when designing business logic.
2.3.2. Transactional Writes
Flink draws lessons from the transaction processing technology in the database and combines its own Checkpoint mechanism to ensure that Sink only affects the external output once. The general process is as follows:
Flink saves the data to be output and does not submit it to the external system for the time being. When the Checkpoint ends and the data of all operators upstream and downstream of Flink are consistent, Flink commits all the previously saved data to the external system. In other words, only the data confirmed by Checkpoint can be written to the external system.
As shown in the following figure, if transaction writing is used, only the output before timestamp 3 is submitted to the external system, and the data after timestamp 3 (such as the data generated by timestamp 5 and 8) is temporarily saved and written to the external system at the next Checkpoint. This prevents the data of timestamp 5 from generating multiple results and writing to the external system multiple times.
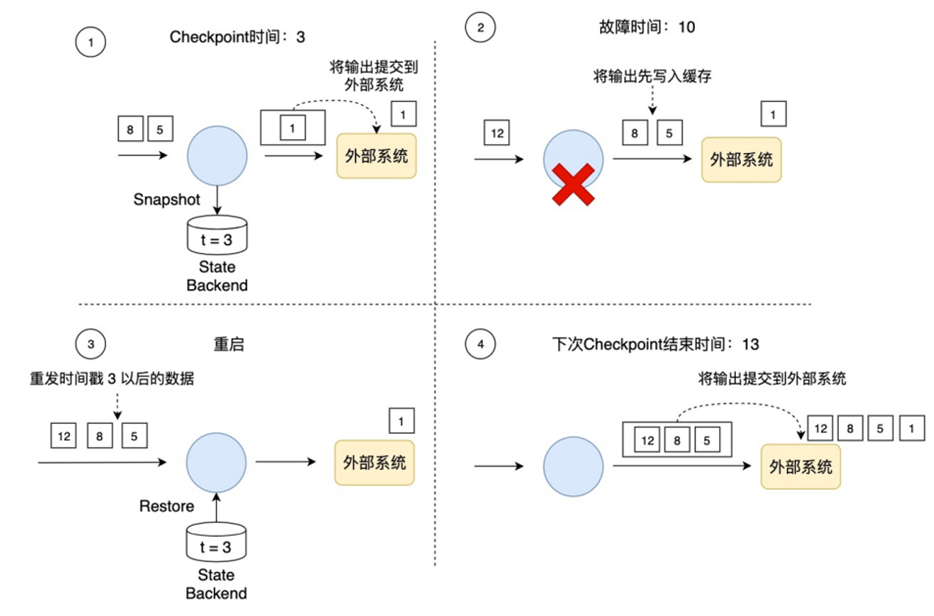
For the specific implementation of transaction writing, Flink currently provides two ways:
- Write ahead log (WAL)
- Two phase commit (2PC)
The main differences between the two methods are:
- The WAL mode is more versatile and suitable for almost all external systems, but it can not provide 100% end-to-end exactly once, because the WAL preview log will be written to memory first, and the memory is a volatile medium.
- If the external system itself supports transactions (such as MySQL and Kafka), 2PC mode can be used to provide 100% end-to-end exactly once.
Transaction writing can provide end-to-end exactly once consistency. Its cost is also very obvious, that is, it sacrifices latency. The output data is no longer written to the external system in real time, but submitted in batches. At present, there is no perfect fault recovery and exactly once guarantee mechanism. For developers, it is necessary to weigh between different requirements.
3. End to end exactly once of Flink + Kafka
3.1. Version Description
Before Flink version 1.4, it supports Exactly Once semantics, which is limited to the internal application.
After Flink version 1.4, it supports end to end exactly once through two-phase commit function, and requires Kafka 0.11 +.
Using TwoPhaseCommitSinkFunction is a general management scheme. As long as the corresponding interface is implemented and the Sink storage supports chaos submission, the end-to-end unified semantics can be realized.

3.2. Two phase commit API
The implementation method of Two-Phase-Commit-2PC two-phase submission in Flink is encapsulated in the abstract class of TwoPhaseCommitSinkFunction. The processing semantics of "exactly once" can be realized only by implementing the four methods of beginTransaction, preCommit, commit and abort. For example, FlinkKafkaProducer implements this class and implements these methods.
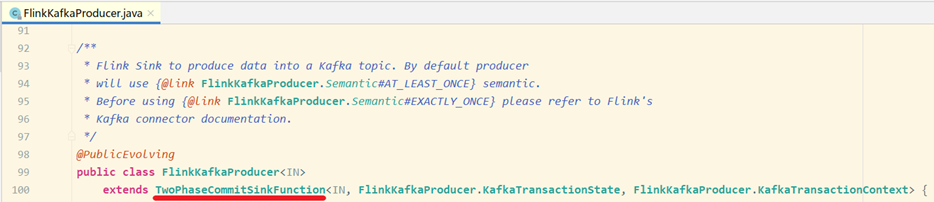
- Beginthransaction: before starting the transaction, we create a temporary file in the temporary directory of the target file system, and then write the data to this file when processing the data;
- preCommit: in the preCommit phase, flush the file, then close the file, and then it cannot be written to the file. We will also start a new transaction for any subsequent writes belonging to the next checkpoint;
- commit: in the submission phase, we move the atomicity of the pre submitted files to the real target directory. Please note that this will increase the delay of output data visibility;
- Abort, in the abort phase, we delete the temporary file.
3.3. Two stage submission - simple process
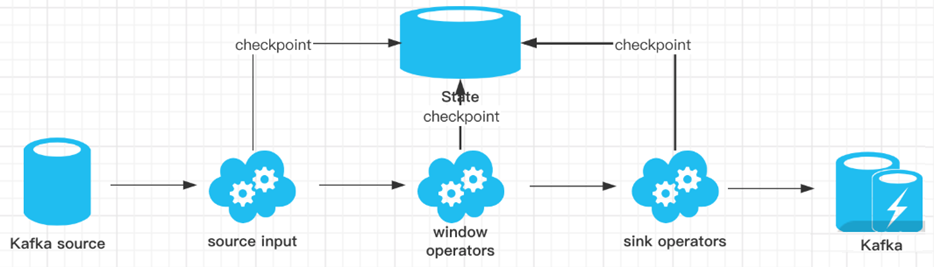
The whole process can be summarized into the following stages:
- Once Flink starts the checkpoint operation, it will enter the pre commit stage, and the Coordinator of JobManager will inject the Barrier into the data flow;
- The "pre commit" phase is completed when all barrier s are successfully delivered in the operator (i.e. Checkpoint is completed) and the snapshot is completed;
- When all operators complete the "pre submit", a "commit" action will be initiated. However, any "pre submit" failure will cause Flink to roll back to the nearest checkpoint;
3.4. Two stage submission - detailed process
3.4.1. demand
Next, we will introduce the two-phase commit protocol and how it implements the end-to-end exact once semantics in a flick program that reads and writes Kafka. Kafka is often used with Flink, and Kafka added transaction support in the latest version 0.11. This means that we now have the necessary support to read and write Kafaka through Flink and provide end-to-end exactly once semantics.
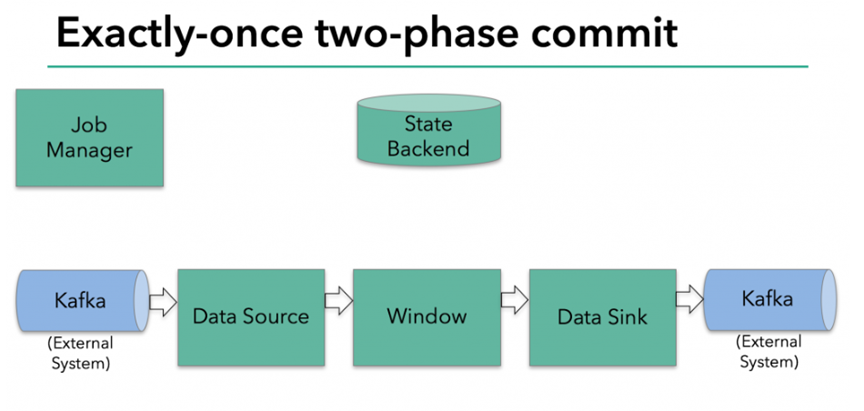
In the figure above, we have:
– data source read from Kafka (built-in KafkaConsumer in Flink)
– window aggregation
– write data back to Kafka's data output (the built-in Kafka producer in Flink)
In order for the data output to provide an exact once guarantee, it must submit all data to Kafka through a transaction. Submission bundles all data to be written between two checkpoint s. This ensures that written data can be rolled back in the event of a failure.
However, in distributed systems, there are usually multiple write tasks running concurrently. Simple commit or rollback is not enough, because all components must be "consistent" during commit or rollback to ensure consistent results.
Flink uses a two-phase commit protocol and a pre commit phase to solve this problem.
3.4.2. Pre submission - internal status
At the beginning of checkpoint, that is, the "pre submission" stage of the two-stage submission agreement. When the checkpoint starts, Flink's JobManager will inject the checkpoint barrier (which divides the records in the data stream into entering the current checkpoint and entering the next checkpoint) into the data stream.
brarrier is passed between operators. For each operator, it triggers the state snapshot of the operator to be written to the state backend.
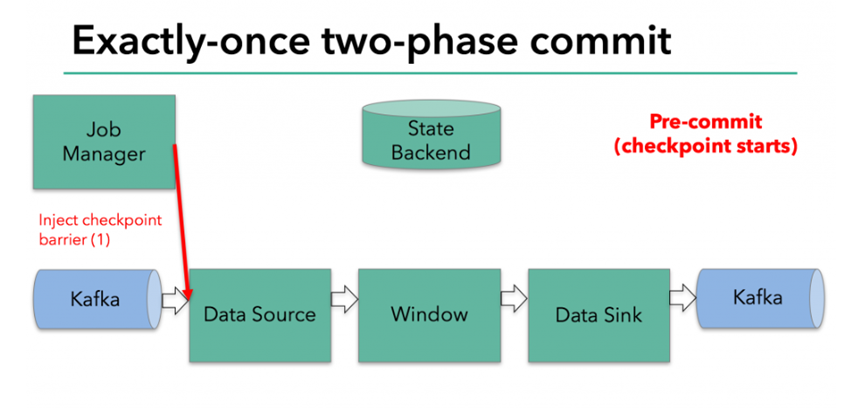
The data source saves the offset of consumption Kafka, and then passes the checkpoint barrier to the next operator.
This method is only applicable to the "internal" status of the operator. The so-called internal state refers to the sum value saved and managed by Flink state backend - for example, the sum value calculated by window aggregation in the second operator. When a process has its internal state, it does not need to perform any other operations in the pre commit phase except that the data changes need to be written to the state backend before the checkpoint. Flink is responsible for submitting these writes correctly if the checkpoint succeeds, or aborting them in case of failure.
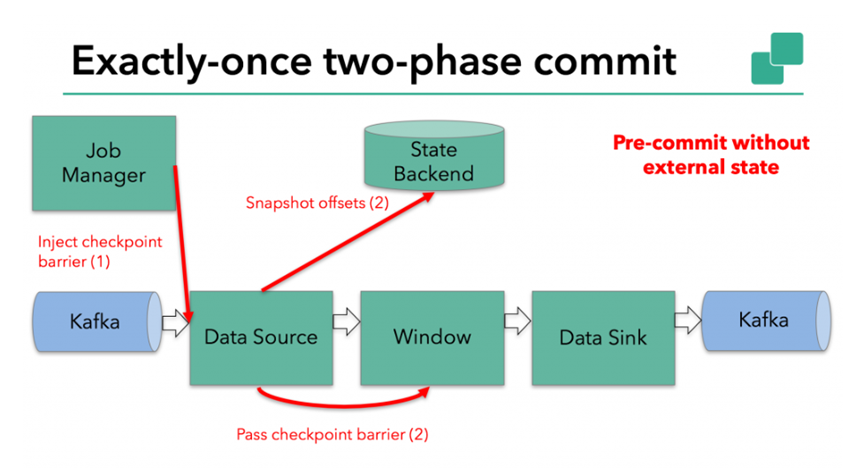
3.4.3. Pre submission - external status
However, when the process has an "external" state, some additional processing needs to be done. The external state usually appears in the form of writing to an external system (such as Kafka). In this case, in order to provide exactly once assurance, the external system must support transactions in order to integrate with the two-phase commit protocol.
In this example, the data needs to be written to Kafka, so the Data Sink has an external state. In this case, in the pre commit phase, in addition to writing its status to the state backend, the data output must also commit its external transactions in advance.
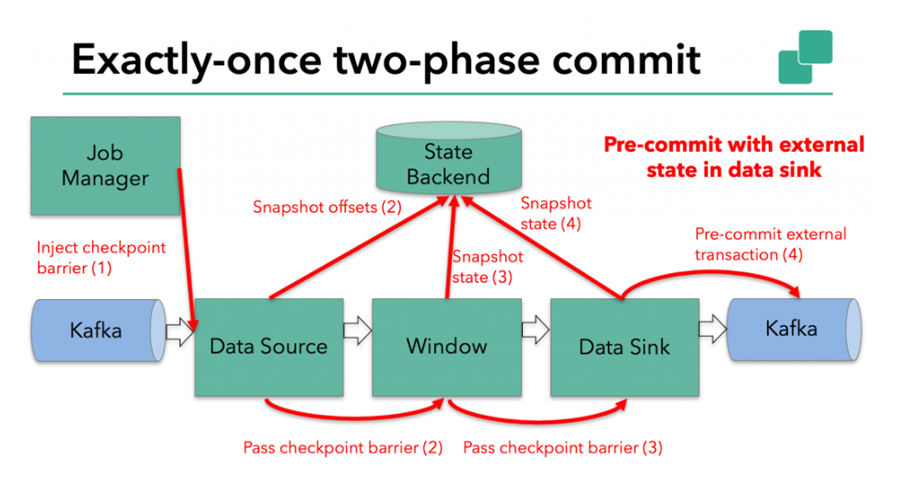
When the checkpoint barrier is passed through all operator s and the triggered checkpoint callback is successfully completed, the pre delivery phase ends. All triggered state snapshots are considered part of the checkpoint. A checkpoint is a snapshot of the state of the entire application, including pre submitted external states. If a failure occurs, we can roll back to the point in time when the snapshot was successfully completed last time.
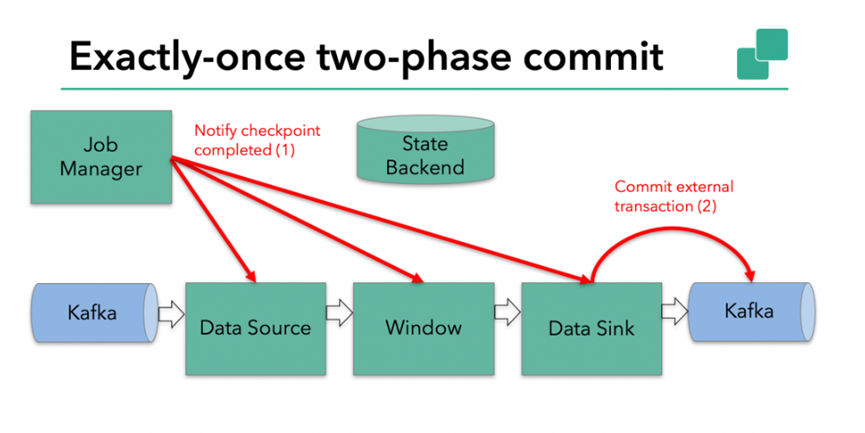
3.4.4. Submission phase
The next step is to inform all operators that the checkpoint has succeeded. This is the submission phase of the two-phase submission protocol. The JobManager issues a callback for each operator in the application that the checkpoint has completed.
Data sources and widnow operator s have no external state, so these operators do not have to perform any operations during the submission phase. However, the Data Sink has an external state, and the external transaction should be committed at this time.
3.4.5. summary
- Once all operator s have completed the pre commit, a commit is submitted.
- If only one pre commit fails, all other commits will be aborted and we will roll back to the last successfully completed checkpoint.
- After the pre submission is successful, the submitted commit needs to ensure the final success - both the operator and the external system need to ensure this. If the commit fails (for example, due to intermittent network problems), the entire Flink application will fail, the application will restart according to the user's restart policy, and will try to resubmit. This process is crucial because if the commit fails in the end, it will lead to data loss.
- The complete implementation of the two-phase commit protocol may be a little complex, which is why Flink extracts its general logic into the abstract class TwoPhaseCommitSinkFunction.
4. Code example
4.1. Flink+Kafka implements end to end exactly once
Official website example address: https://ververica.cn/developers/flink-kafka-end-to-end-exactly-once-analysis/
import org.apache.commons.lang3.SystemUtils;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.functions.RichMapFunction;
import org.apache.flink.api.common.restartstrategy.RestartStrategies;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.api.common.time.Time;
import org.apache.flink.api.java.tuple.Tuple;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.runtime.state.filesystem.FsStateBackend;
import org.apache.flink.streaming.api.CheckpointingMode;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.CheckpointConfig;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaProducer;
import org.apache.flink.streaming.connectors.kafka.internals.KeyedSerializationSchemaWrapper;
import org.apache.flink.util.Collector;
import java.util.Properties;
import java.util.Random;
import java.util.concurrent.TimeUnit;
/**
* Desc
* Kafka --> Flink-->Kafka End to end exactly once
* Direct use
* FlinkKafkaConsumer + Flink Checkpoint + flinkkafkaproducer
*/
public class Kafka_Flink_Kafka_EndToEnd_ExactlyOnce {
public static void main(String[] args) throws Exception {
//1.env
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//===========Checkpoint parameter setting====
//===========Type 1: required parameter=============
//Set the time interval of Checkpoint to 1000ms and do Checkpoint once / in fact, send Barrier every 1000ms!
env.enableCheckpointing(1000);
//Set State storage media
if (SystemUtils.IS_OS_WINDOWS) {
env.setStateBackend(new FsStateBackend("file:///D:/ckp"));
} else {
env.setStateBackend(new FsStateBackend("hdfs://node1:8020/flink-checkpoint/checkpoint"));
}
//===========Type 2: recommended parameters===========
//Set the minimum waiting time between two checkpoints. For example, set the minimum waiting time between checkpoints to be 500ms (in order to avoid that the previous time is too slow and the latter time overlaps when doing Checkpoint every 1000ms)
//For example, on the expressway, one vehicle is released at the gate every 1s, but the minimum distance between two vehicles is 500m
env.getCheckpointConfig().setMinPauseBetweenCheckpoints(500);//The default is 0
//Set whether to fail the overall task if an error occurs in the process of Checkpoint: true is false, not true
//env.getCheckpointConfig().setFailOnCheckpointingErrors(false);// The default is true
env.getCheckpointConfig().setTolerableCheckpointFailureNumber(10);//The default value is 0, which means that any checkpoint failure is not tolerated
//Set whether to clear checkpoints, indicating whether to keep the current Checkpoint when canceling. The default Checkpoint will be deleted when the job is cancelled
//ExternalizedCheckpointCleanup. DELETE_ ON_ Cancelation: true. When the job is cancelled, the external checkpoint is deleted (the default value)
//ExternalizedCheckpointCleanup. RETAIN_ ON_ Cancel: false. When the job is cancelled, the external checkpoint will be reserved
env.getCheckpointConfig().enableExternalizedCheckpoints(CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION);
//===========Type 3: just use the default===============
//Set the execution mode of checkpoint to actual_ Once (default)
env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE);
//Set the timeout time of the Checkpoint. If the Checkpoint has not been completed within 60s, it means that the Checkpoint fails, it will be discarded.
env.getCheckpointConfig().setCheckpointTimeout(60000);//Default 10 minutes
//Set how many checkpoint s can be executed at the same time
env.getCheckpointConfig().setMaxConcurrentCheckpoints(1);//The default is 1
//=============Restart strategy===========
env.setRestartStrategy(RestartStrategies.fixedDelayRestart(3, Time.of(10, TimeUnit.SECONDS)));
//2.Source
Properties props_source = new Properties();
props_source.setProperty("bootstrap.servers", "node1:9092");
props_source.setProperty("group.id", "flink");
props_source.setProperty("auto.offset.reset", "latest");
props_source.setProperty("flink.partition-discovery.interval-millis", "5000");//A background thread will be started to check the partition of Kafka every 5s
//props_source.setProperty("enable.auto.commit", "true");// When there is no Checkpoint, use the auto submit offset to the default theme:__ consumer_ In offsets
//props_source.setProperty("auto.commit.interval.ms", "2000");
//kafkaSource is KafkaConsumer
FlinkKafkaConsumer<String> kafkaSource = new FlinkKafkaConsumer<>("flink_kafka", new SimpleStringSchema(), props_source);
kafkaSource.setStartFromLatest();
//kafkaSource.setStartFromGroupOffsets();// Set to start consumption from the offset of the record. If there is no record, start from auto offset. Reset configuration starts consumption
//kafkaSource.setStartFromEarliest();// Set direct consumption from Earliest, and auto offset. Reset configuration independent
kafkaSource.setCommitOffsetsOnCheckpoints(true);//When executing Checkpoint, submit offset to Checkpoint (for Flink), and submit a copy to the default theme:__ consumer_ Offsets (it can also be obtained if other external systems want to use it)
DataStreamSource<String> kafkaDS = env.addSource(kafkaSource);
//3.Transformation
//3.1 cut out each word and write it down as 1
SingleOutputStreamOperator<Tuple2<String, Integer>> wordAndOneDS = kafkaDS.flatMap(new FlatMapFunction<String, Tuple2<String, Integer>>() {
@Override
public void flatMap(String value, Collector<Tuple2<String, Integer>> out) throws Exception {
//Each line is value
String[] words = value.split(" ");
for (String word : words) {
Random random = new Random();
int i = random.nextInt(5);
if (i > 3) {
System.out.println("Out bug Yes...");
throw new RuntimeException("Out bug Yes...");
}
out.collect(Tuple2.of(word, 1));
}
}
});
//3.2 grouping
//Note: the grouping of batch processing is groupBy and the grouping of stream processing is keyBy
KeyedStream<Tuple2<String, Integer>, Tuple> groupedDS = wordAndOneDS.keyBy(0);
//3.3 polymerization
SingleOutputStreamOperator<Tuple2<String, Integer>> aggResult = groupedDS.sum(1);
//3.4 convert the aggregation results to custom string format
SingleOutputStreamOperator<String> result = (SingleOutputStreamOperator<String>) aggResult.map(new RichMapFunction<Tuple2<String, Integer>, String>() {
@Override
public String map(Tuple2<String, Integer> value) throws Exception {
return value.f0 + ":::" + value.f1;
}
});
//4.sink
//result.print();
Properties props_sink = new Properties();
props_sink.setProperty("bootstrap.servers", "node1:9092");
props_sink.setProperty("transaction.timeout.ms", 1000 * 5 + "");//Set the transaction timeout, which can also be set in kafka configuration
/*FlinkKafkaProducer<String> kafkaSink0 = new FlinkKafkaProducer<>(
"flink_kafka",
new SimpleStringSchema(),
props_sink);*/
FlinkKafkaProducer<String> kafkaSink = new FlinkKafkaProducer<>(
"flink_kafka2",
new KeyedSerializationSchemaWrapper<String>(new SimpleStringSchema()),
props_sink,
FlinkKafkaProducer.Semantic.EXACTLY_ONCE
);
result.addSink(kafkaSink);
//5.execute
env.execute();
//Test:
//1. Create theme / export / server / Kafka / bin / Kafka topics sh --zookeeper node1:2181 --create --replication-factor 2 --partitions 3 --topic flink_ kafka2
//2. Open console producer / export / server / Kafka / bin / Kafka console producer sh --broker-list node1:9092 --topic flink_ kafka
//3. Open the console / export / server / Kafka / bin / Kafka console consumer sh --bootstrap-server node1:9092 --topic flink_ kafka2
}
}
4.2. Flink+MySQL implements end to end exactly once
Reference website: Flink implements Kafka to Mysql exactly once - simple book
Requirement Description:
1.checkpoint is performed every 10 seconds. At this time, FlinkKafkaConsumer is used to consume the messages in kafka in real time
2. After consuming and processing the message, conduct a pre submission database operation
3. If there is no problem with the pre submission, the real database insertion operation will be carried out after 10s. If the insertion is successful, a checkpoint will be carried out, and the offset of consumption will be automatically recorded by flink, and the data saved by checkpoint can be put into hdfs
4. If there is an error in the pre submission, such as an error in 5s, the Flink program will enter the process of continuous restart. The restart strategy can be set in the configuration. The offset recorded by the checkpoint is still the offset of the last successful consumption, because the data consumed this time was successfully consumed during the checkpoint, but failed in the pre submission process
5. Note that the data is not actually inserted at this time, because the pre commit fails, and the commit process will not occur. After handling the abnormal data, restart the Flink program, which will automatically continue to consume data from the last successful checkpoint, so as to achieve the exact once from Kafka to Mysql.
Code 1:
import org.apache.flink.api.common.ExecutionConfig;
import org.apache.flink.api.common.typeutils.base.VoidSerializer;
import org.apache.flink.api.java.typeutils.runtime.kryo.KryoSerializer;
import org.apache.flink.runtime.state.filesystem.FsStateBackend;
import org.apache.flink.shaded.jackson2.com.fasterxml.jackson.databind.node.ObjectNode;
import org.apache.flink.streaming.api.CheckpointingMode;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.sink.TwoPhaseCommitSinkFunction;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;
import org.apache.flink.streaming.util.serialization.JSONKeyValueDeserializationSchema;
import org.apache.kafka.clients.CommonClientConfigs;
import java.sql.*;
import java.text.SimpleDateFormat;
import java.util.Date;
import java.util.Properties;
public class Kafka_Flink_MySQL_EndToEnd_ExactlyOnce {
public static void main(String[] args) throws Exception {
//1.env
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);//Convenient test
env.enableCheckpointing(10000);
env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE);
env.getCheckpointConfig().setMinPauseBetweenCheckpoints(1000);
//env.getCheckpointConfig().enableExternalizedCheckpoints(CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION);
env.setStateBackend(new FsStateBackend("file:///D:/ckp"));
//2.Source
String topic = "flink_kafka";
Properties props = new Properties();
props.setProperty(CommonClientConfigs.BOOTSTRAP_SERVERS_CONFIG,"node1:9092");
props.setProperty("group.id","flink");
props.setProperty("auto.offset.reset","latest");//If there is a recorded offset, it will be consumed from the recorded position. If not, it will be consumed from the latest data
props.setProperty("flink.partition-discovery.interval-millis","5000");//Start a background thread to check the partition status of Kafka every 5s
FlinkKafkaConsumer<ObjectNode> kafkaSource = new FlinkKafkaConsumer<>("topic_in", new JSONKeyValueDeserializationSchema(true), props);
kafkaSource.setStartFromGroupOffsets();//Start consumption from the location of the group offset record. If the kafka broker does not have the group information, it will decide where to start consumption according to the setting of "auto.offset.reset"
kafkaSource.setCommitOffsetsOnCheckpoints(true);//When Flink executes Checkpoint, submit the offset (one in Checkpoint and one in Kafka's default theme _comsumer_offsets)
DataStreamSource<ObjectNode> kafkaDS = env.addSource(kafkaSource);
//3.transformation
//4.Sink
kafkaDS.addSink(new MySqlTwoPhaseCommitSink()).name("MySqlTwoPhaseCommitSink");
//5.execute
env.execute();
}
}
/**
Customize kafka to mysql, inherit TwoPhaseCommitSinkFunction, and realize two-stage submission.
Function: ensure that kafak to mysql is exactly once
CREATE TABLE `t_test` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`value` varchar(255) DEFAULT NULL,
`insert_time` datetime DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4
*/
class MySqlTwoPhaseCommitSink extends TwoPhaseCommitSinkFunction<ObjectNode, Connection, Void> {
public MySqlTwoPhaseCommitSink() {
super(new KryoSerializer<>(Connection.class, new ExecutionConfig()), VoidSerializer.INSTANCE);
}
/**
* Perform data warehousing
*/
@Override
protected void invoke(Connection connection, ObjectNode objectNode, Context context) throws Exception {
System.err.println("start invoke.......");
String date = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss").format(new Date());
System.err.println("===>date:" + date + " " + objectNode);
String value = objectNode.get("value").toString();
String sql = "insert into `t_test` (`value`,`insert_time`) values (?,?)";
PreparedStatement ps = connection.prepareStatement(sql);
ps.setString(1, value);
ps.setTimestamp(2, new Timestamp(System.currentTimeMillis()));
//Execute insert statement
ps.execute();
//Manual manufacturing exception
if(Integer.parseInt(value) == 15) System.out.println(1/0);
}
/**
* Get the connection and start the manual transaction submission (in the getConnection method)
*/
@Override
protected Connection beginTransaction() throws Exception {
String url = "jdbc:mysql://localhost:3306/bigdata?useUnicode=true&characterEncoding=UTF-8&zeroDateTimeBehavior=convertToNull&useSSL=false&autoReconnect=true";
Connection connection = DBConnectUtil.getConnection(url, "root", "root");
System.err.println("start beginTransaction......."+connection);
return connection;
}
/**
* Pre commit, where the pre commit logic is in the invoke method
*/
@Override
protected void preCommit(Connection connection) throws Exception {
System.err.println("start preCommit......."+connection);
}
/**
* If invoke executes normally, commit the transaction
*/
@Override
protected void commit(Connection connection) {
System.err.println("start commit......."+connection);
DBConnectUtil.commit(connection);
}
@Override
protected void recoverAndCommit(Connection connection) {
System.err.println("start recoverAndCommit......."+connection);
}
@Override
protected void recoverAndAbort(Connection connection) {
System.err.println("start abort recoverAndAbort......."+connection);
}
/**
* If invoke executes abnormally, the transaction will be rolled back and the next checkpoint operation will not be executed
*/
@Override
protected void abort(Connection connection) {
System.err.println("start abort rollback......."+connection);
DBConnectUtil.rollback(connection);
}
}
class DBConnectUtil {
/**
* Get connection
*/
public static Connection getConnection(String url, String user, String password) throws SQLException {
Connection conn = null;
conn = DriverManager.getConnection(url, user, password);
//Set manual submission
conn.setAutoCommit(false);
return conn;
}
/**
* Commit transaction
*/
public static void commit(Connection conn) {
if (conn != null) {
try {
conn.commit();
} catch (SQLException e) {
e.printStackTrace();
} finally {
close(conn);
}
}
}
/**
* Transaction rollback
*/
public static void rollback(Connection conn) {
if (conn != null) {
try {
conn.rollback();
} catch (SQLException e) {
e.printStackTrace();
} finally {
close(conn);
}
}
}
/**
* Close connection
*/
public static void close(Connection conn) {
if (conn != null) {
try {
conn.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
}
}
Code 2:
import com.alibaba.fastjson.JSON;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import org.apache.kafka.clients.producer.Producer;
import org.apache.kafka.clients.producer.ProducerRecord;
import java.util.Properties;
public class DataProducer {
public static void main(String[] args) throws InterruptedException {
Properties props = new Properties();
props.put("bootstrap.servers", "node1:9092");
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
Producer<String, String> producer = new org.apache.kafka.clients.producer.KafkaProducer<>(props);
try {
for (int i = 1; i <= 20; i++) {
DataBean data = new DataBean(String.valueOf(i));
ProducerRecord record = new ProducerRecord<String, String>("flink_kafka", null, null, JSON.toJSONString(data));
producer.send(record);
System.out.println("send data: " + JSON.toJSONString(data));
Thread.sleep(1000);
}
}catch (Exception e){
System.out.println(e);
}
producer.flush();
}
}
@Data
@NoArgsConstructor
@AllArgsConstructor
class DataBean {
private String value;
}
Note: this blog is adapted from the 2020 New Year video of a horse - > Website of station B
Note: links to other related articles go here - > Flink article summary