catalogue
1. Introduction to streaming file writing
1.2. Bucket, SubTask and PartFile
3. Detailed explanation of streaming file writing configuration
3.1.2. Generation rules of partfile
3.1.3. PartFile naming settings
3.2. PartFile serialization encoding
3.3. Bucket allocation strategy
0. Links to related articles
1. Introduction to streaming file writing
Introduction to the official website: Apache Flink 1.12 Documentation: Streaming File Sink
Blog introduction: Flink1. Series 9 - StreamingFileSink vs BucketingSink_ Maple leaf's lonely blog - CSDN blog
1.1. Scene description
StreamingFileSink is flink1 The new features introduced in 7 are to solve the following problems:
In the big data business scenario, there is often a scenario: external data is sent to kafka, and flink consumes kafka data as a middleware for business processing; After processing, the data may need to be written to the database or file system, such as hdfs.
StreamingFileSink can be used to write partition files to the file system that supports the Flink # file system interface and supports the exactly once semantics.
The exact once of this sink implementation is guaranteed by the two-stage submission mode based on Flink checkpoint. It is mainly used in real-time data warehouse, topic splitting, hour based analysis and processing and other scenarios.
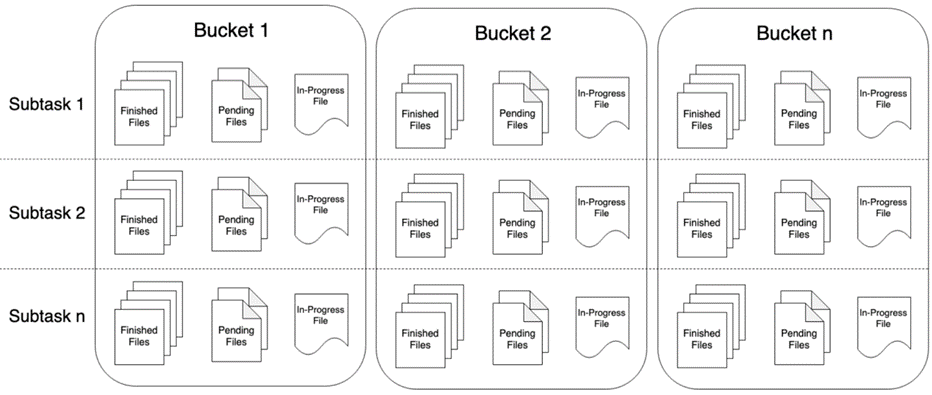
1.2. Bucket, SubTask and PartFile
- Bucket: StreamingFileSink can write partition files to the file system supported by the Flink file system abstraction (because it is streaming, the data is regarded as unbounded). The partition behavior is configurable. By default, one bucket is written every hour. The bucket includes several files, and the content is all record s received in the stream within this small time interval.
- PartFile: each Bucket is internally divided into multiple partfiles to store output data. Each subtask of sink that receives data in the Bucket life cycle has at least one PartFile. The additional file scrolling is determined by the configured scrolling strategy. The default strategy is to decide whether to scroll according to the file size and opening timeout (the maximum duration for which the file can be opened) and the maximum inactivity timeout of the file.
The relationship between Bucket, SubTask and PartFile is shown in the following figure:
2. Case display
2.1. demand
Write Flink program, receive the string data of socket, and then store the received data in hdfs in streaming mode
2.2. Development steps
- Initialize the flow computing environment
- Set Checkpoint (10s) to start periodically
- Specify a parallelism of 1
- Access socket data source to obtain data
- Specifies that the file encoding format is line encoding format
- Set bucket allocation policy
- Set file scrolling policy
- Specify file output configuration
- Add the streamingfilesink object to the environment
- Perform tasks
2.3. Implementation code
import org.apache.flink.api.common.serialization.SimpleStringEncoder;
import org.apache.flink.core.fs.Path;
import org.apache.flink.runtime.state.filesystem.FsStateBackend;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.sink.filesystem.OutputFileConfig;
import org.apache.flink.streaming.api.functions.sink.filesystem.StreamingFileSink;
import org.apache.flink.streaming.api.functions.sink.filesystem.bucketassigners.DateTimeBucketAssigner;
import org.apache.flink.streaming.api.functions.sink.filesystem.rollingpolicies.DefaultRollingPolicy;
import java.util.concurrent.TimeUnit;
public class StreamFileSinkDemo {
public static void main(String[] args) throws Exception {
//1.env
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.enableCheckpointing(TimeUnit.SECONDS.toMillis(10));
env.setStateBackend(new FsStateBackend("file:///D:/ckp"));
//2.source
DataStreamSource<String> lines = env.socketTextStream("node1", 9999);
//3.sink
//Set the prefix and suffix of sink
//File header and file extension
//prefix-xxx-.txt
OutputFileConfig config = OutputFileConfig
.builder()
.withPartPrefix("prefix")
.withPartSuffix(".txt")
.build();
//Set the path of sink
String outputPath = "hdfs://node1:8020/FlinkStreamFileSink/parquet";
//Create StreamingFileSink
final StreamingFileSink<String> sink = StreamingFileSink
.forRowFormat(
new Path(outputPath),
new SimpleStringEncoder<String>("UTF-8"))
/**
* Set bucket allocation policy
* DateTimeBucketAssigner --The default bucket allocation policy is the time-based distributor, which generates one bucket per hour. The format is yyyy MM DD -- HH
* BasePathBucketAssigner : Allocator (single global bucket) that stores all part file s in the base path
*/
.withBucketAssigner(new DateTimeBucketAssigner<>())
/**
* There are three rolling policies
* CheckpointRollingPolicy
* DefaultRollingPolicy
* OnCheckpointRollingPolicy
*/
.withRollingPolicy(
/**
* The scrolling strategy determines the state change process of the written file
* 1. In-progress : The current file is being written
* 2. Pending : When the file in the in progress state is closed, it changes to the Pending state
* 3. Finished : After a successful Checkpoint, the Pending state will change to the Finished state
*
* Observed phenomena
* 1.The bucket directory will be created first according to the local time and time zone
* 2.File name rule: part - < subtaskindex > - < partfileindex >
* 3.In macos, hidden files are not displayed by default. You need to display hidden files to see files in in in progress and Pending status, because files follow Named at the beginning
*
*/
DefaultRollingPolicy.builder()
.withRolloverInterval(TimeUnit.SECONDS.toMillis(2)) //Set scroll interval
.withInactivityInterval(TimeUnit.SECONDS.toMillis(1)) //Set inactivity interval
.withMaxPartSize(1024 * 1024 * 1024) // Maximum size
.build())
.withOutputFileConfig(config)
.build();
lines.addSink(sink).setParallelism(1);
env.execute();
}
}
3. Detailed explanation of streaming file writing configuration
3.1. PartFile
Each Bucket is divided into multiple partial files, and each subtask of the sink that receives data in the Bucket has at least one PartFile. Additional scrolling strategies are available.
About sequencing: for any given Flink subtask, the PartFile indexes are strictly increased (in the order of creation), but these indexes are not always sequential. When the job restarts, the next PartFile index of all subtasks will be max PartFile index + 1, where Max refers to the maximum value of all calculated indexes in all subtasks.
return new Path(bucketPath, outputFileConfig.getPartPrefix() + '-' + subtaskIndex + '-' + partCounter + outputFileConfig.getPartSuffix());
3.1.1. PartFile lifecycle
Naming rules and lifecycle of the output file. As can be seen from the above figure, part file s can be in one of the following three states:
- In progress: the current file is being written
- Pending: when the file in the in progress state is closed, it becomes pending
- Finished: after a successful Checkpoint, the Pending state will change to the finished state. The files in the finished state will not be modified and can be safely read by the downstream system.
Note: when using StreamingFileSink, you need to enable Checkpoint, and the writing is completed every time you do Checkpoint. If Checkpoint is disabled, part file s will always be in the 'in progress' or' pending 'state, and the downstream system cannot read them safely.
3.1.2. Generation rules of partfile
During each active Bucket, each Writer's subtask will only have a separate in progress partfile at any time, but there can be multiple pending and Finished status files.
An example of PartFile distribution of two subtasks of a Sink is as follows:
- In the initial state, two inprogress files are being written by two subtask s respectively
└── 2020-03-25--12
├── part-0-0.inprogress.bd053eb0-5ecf-4c85-8433-9eff486ac334
└── part-1-0.inprogress.ea65a428-a1d0-4a0b-bbc5-7a436a75e575
- When part-1-0 scrolls because the file size exceeds the threshold, it changes to Pending status and waits for completion, but it will not be renamed at this time. Note that Sink will create a new PartFile, part-1-1:
└── 2020-03-25--12
├── part-0-0.inprogress.bd053eb0-5ecf-4c85-8433-9eff486ac334
├── part-1-0.inprogress.ea65a428-a1d0-4a0b-bbc5-7a436a75e575
└── part-1-1.inprogress.bc279efe-b16f-47d8-b828-00ef6e2fbd11
- After the next checkpoint is successful, part-1-0 will change to Finished status and be renamed:
└── 2020-03-25--12
├── part-0-0.inprogress.bd053eb0-5ecf-4c85-8433-9eff486ac334
├── part-1-0
└── part-1-1.inprogress.bc279efe-b16f-47d8-b828-00ef6e2fbd11
- When the next Bucket cycle comes, creating a new Bucket directory will not affect the in-progress file in the previous Bucket. You still have to wait for the file RollingPolicy and checkpoint to change the status:
└── 2020-03-25--12
├── part-0-0.inprogress.bd053eb0-5ecf-4c85-8433-9eff486ac334
├── part-1-0
└── part-1-1.inprogress.bc279efe-b16f-47d8-b828-00ef6e2fbd11
└── 2020-03-25--13
└── part-0-2.inprogress.2b475fec-1482-4dea-9946-eb4353b475f1
3.1.3. PartFile naming settings
By default, PartFile naming rules are as follows:
- In-progress / Pending
part--.inprogress.uid - Finished
part--
For example, part-1-20 refers to document No. 20 for which sub task No. 1 has been completed.
You can use OutputFileConfig to change the prefix and suffix. The code example is as follows:
OutputFileConfig config = OutputFileConfig
.builder()
.withPartPrefix("prefix")
.withPartSuffix(".ext")
.build()
StreamingFileSink sink = StreamingFileSink
.forRowFormat(new Path(outputPath), new SimpleStringEncoder<String>("UTF-8"))
.withBucketAssigner(new KeyBucketAssigner())
.withRollingPolicy(OnCheckpointRollingPolicy.build())
.withOutputFileConfig(config)
.build()
The obtained PartFile example is as follows:
└── 2019-08-25--12
├── prefix-0-0.ext
├── prefix-0-1.ext.inprogress.bd053eb0-5ecf-4c85-8433-9eff486ac334
├── prefix-1-0.ext
└── prefix-1-1.ext.inprogress.bc279efe-b16f-47d8-b828-00ef6e2fbd11
3.2. PartFile serialization encoding
StreamingFileSink supports line encoding format and batch encoding format, such as Apache Parquet. These two variants can be created using the following static methods:
- Row-encoded sink:
StreamingFileSink.forRowFormat(basePath, rowEncoder)
//that 's ok
StreamingFileSink.forRowFormat(new Path(path), new SimpleStringEncoder<T>())
.withBucketAssigner(new PaulAssigner<>()) //Bucket strategy
.withRollingPolicy(new PaulRollingPolicy<>()) //Rolling strategy
.withBucketCheckInterval(CHECK_INTERVAL) //Inspection cycle
.build();
- Bulk-encoded sink:
StreamingFileSink.forBulkFormat(basePath, bulkWriterFactory)
//Column parquet
StreamingFileSink.forBulkFormat(new Path(path), ParquetAvroWriters.forReflectRecord(clazz))
.withBucketAssigner(new PaulBucketAssigner<>())
.withBucketCheckInterval(CHECK_INTERVAL)
.build();
When creating a row or batch coded Sink, we need to specify the basic path of the bucket and the code of the data
In addition to the different file formats, another important difference between the two write formats is the different rollback strategies:
1,forRowFormat Line writing can scroll based on file size, scrolling time and inactive time,
2,forBulkFormat Column write method can only be based on checkpoint Mechanism for file scrolling,
That is, in execution snapshotState Method to scroll the file. If you scroll the file based on size or time,
Then when the task fails to recover, it must be in in-processing The status of the file is as specified offset conduct truncate,
Because columnar storage is not available for files offset conduct truncate of
Therefore, every time checkpoint Scroll the file,
The rolling strategy used is OnCheckpointRollingPolicy.
forBulkFormat can only be used in combination with 'oncheckpoint rollingpolicy', which scrolls files every time you make a checkpoint.
3.2.1. Row Encoding
At this time, StreamingFileSink will encode and serialize each record.
Required configuration items:
- BasePath of output data
- Serialize each row of data and write it to the Encoder of PartFile
Use RowFormatBuilder optional configuration items:
- Customize RollingPolicy
DefaultRollingPolicy is used by default to scroll files, which can be customized
- bucketCheckInterval
The default is 1 minute. This value, in milliseconds, specifies the time interval between scrolling files by time
Examples are as follows:
import org.apache.flink.api.common.serialization.SimpleStringEncoder
import org.apache.flink.core.fs.Path
import org.apache.flink.streaming.api.functions.sink.filesystem.StreamingFileSink
// 1. Build DataStream
DataStream input = ...
// 2. Build StreamingFileSink and specify BasePath, Encoder and RollingPolicy
StreamingFileSink sink = StreamingFileSink
.forRowFormat(new Path(outputPath), new SimpleStringEncoder[String]("UTF-8"))
.withRollingPolicy(
DefaultRollingPolicy.builder()
.withRolloverInterval(TimeUnit.MINUTES.toMillis(15))
.withInactivityInterval(TimeUnit.MINUTES.toMillis(5))
.withMaxPartSize(1024 * 1024 * 1024)
.build())
.build()
// 3. Add Sink to inputdatastream
input.addSink(sink)
The above example builds a simple StreamingFileSink with default Bucket building behavior (inherited from the DateTimeBucketAssigner of BucketAssigner), builds a Bucket every hour, and internally uses the DefaultRollingPolicy inherited from RollingPolicy. In any of the following three cases, the PartFile will be scrolled:
- PartFile contains at least 15 minutes of data
- No new data has been received in the last 5 minutes
- After the last record is written, the file size has reached 1GB
In addition to using DefaultRollingPolicy, you can also implement the RollingPolicy interface to implement custom rolling policies.
3.2.2. Bulk Encoding
To use batch encoding, set streamingfilesink Forrowformat() is replaced by streamingfilesink Forbulkformat(), note that a BulkWriter must be specified at this time Factory instead of row mode Encoder. BulkWriter logically defines how to add, fllush new records, and finally determine the bulk of records for further coding.
It should be noted that when using Bulk Encoding, filnk1 Each time you scroll through the policy's version of rockpoint policy, you can only scroll through it.
Flink has three embedded bulkwriters:
- ParquetAvroWriters
There are some static methods to create ParquetWriterFactory.
- SequenceFileWriterFactory
- CompressWriterFactory
Flink has a built-in method to create a Parquet writer factory for Avro data.
To use ParquetBulkEncoder, you need to add the following Maven dependencies:
<!-- streaming File Sink Required jar package-->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-parquet_2.12</artifactId>
<version>1.12.0</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.avro/avro -->
<dependency>
<groupId>org.apache.avro</groupId>
<artifactId>avro</artifactId>
<version>1.12.0</version>
</dependency>
<dependency>
<groupId>org.apache.parquet</groupId>
<artifactId>parquet-avro</artifactId>
<version>1.12.0</version>
</dependency>
3.3. Bucket allocation strategy
The bucket allocation policy defines the subdirectories that write the structured data into the basic output directory. Both row format and batch format need to be used.
Specifically, StreamingFileSink uses BucketAssigner to determine which Bucket each input data should be put into. By default, DateTimeBucketAssigner creates a Bucket every hour based on the system default time zone. The format is as follows: yyyy MM DD -- HH. Date format (i.e. Bucket size) and time zone can be configured manually. We can call on the format builder With BucketAssigner (assigner) to customize the BucketAssigner.
Flink has two built-in bucket assignors:
- DateTimeBucketAssigner: the default time-based allocator
- BasePathBucketAssigner: allocator (single global bucket) that stores all part file s in the base path
3.3.1. DateTimeBucketAssigner
Both Row format and Bulk format codes use DateTimeBucketAssigner as the default BucketAssigner. By default, DateTimeBucketAssigner creates a Bucket in the format yyyy MM DD -- HH every hour based on the system default time zone. The Bucket path is / {basePath}/{dateTimePath} /.
- basePath refers to streamingfilesink Path when forrowformat (new path (outputpath)
- The date format and time zone in dateTimePath can be configured when initializing DateTimeBucketAssigner
public class DateTimeBucketAssigner<IN> implements BucketAssigner<IN, String> {
private static final long serialVersionUID = 1L;
// Default time format string
private static final String DEFAULT_FORMAT_STRING = "yyyy-MM-dd--HH";
// Time format string
private final String formatString;
// time zone
private final ZoneId zoneId;
// DateTimeFormatter is used to generate a time string from the current system time and DateTimeFormat
private transient DateTimeFormatter dateTimeFormatter;
/**
* Use the default 'yyyy MM DD -- HH' and system time zone to build DateTimeBucketAssigner
*/
public DateTimeBucketAssigner() {
this(DEFAULT_FORMAT_STRING);
}
/**
* Through the time string and system time zone that can be parsed by SimpleDateFormat
* To build DateTimeBucketAssigner
*/
public DateTimeBucketAssigner(String formatString) {
this(formatString, ZoneId.systemDefault());
}
/**
* Through the default 'yyyy MM DD -- HH' and the specified time zone
* To build DateTimeBucketAssigner
*/
public DateTimeBucketAssigner(ZoneId zoneId) {
this(DEFAULT_FORMAT_STRING, zoneId);
}
/**
* Through the time string that can be parsed by SimpleDateFormat and the specified time zone
* To build DateTimeBucketAssigner
*/
public DateTimeBucketAssigner(String formatString, ZoneId zoneId) {
this.formatString = Preconditions.checkNotNull(formatString);
this.zoneId = Preconditions.checkNotNull(zoneId);
}
/**
* Format the current ProcessingTime with the specified time format and time zone to obtain the BucketId
*/
@Override
public String getBucketId(IN element, BucketAssigner.Context context) {
if (dateTimeFormatter == null) {
dateTimeFormatter = DateTimeFormatter.ofPattern(formatString).withZone(zoneId);
}
return dateTimeFormatter.format(Instant.ofEpochMilli(context.currentProcessingTime()));
}
@Override
public SimpleVersionedSerializer<String> getSerializer() {
return SimpleVersionedStringSerializer.INSTANCE;
}
@Override
public String toString() {
return "DateTimeBucketAssigner{" +
"formatString='" + formatString + '\'' +
", zoneId=" + zoneId +
'}';
}
}
3.3.2. BasePathBucketAssigner
Store all partfiles in BasePath (there is only a single global Bucket at this time).
Let's take a look at the source code of BasePathBucketAssigner to continue learning DateTimeBucketAssigner:
@PublicEvolving
public class BasePathBucketAssigner<T> implements BucketAssigner<T, String> {
private static final long serialVersionUID = -6033643155550226022L;
/**
* BucketId Always be '', that is, the Bucket full path is the BasePath specified by the user
*/
@Override
public String getBucketId(T element, BucketAssigner.Context context) {
return "";
}
/**
* Serialize BucketId with SimpleVersionedStringSerializer
*/
@Override
public SimpleVersionedSerializer<String> getSerializer() {
// in the future this could be optimized as it is the empty string.
return SimpleVersionedStringSerializer.INSTANCE;
}
@Override
public String toString() {
return "BasePathBucketAssigner";
}
}
3.4. Rolling strategy
RollingPolicy defines when a specified file is closed and becomes Pending, and then becomes Finished. Files in Pending status will change to Finished status at the next Checkpoint. By setting the Checkpoint interval, you can control the speed, size and quantity of part file s available to downstream readers.
Flink has two built-in scrolling strategies:
- DefaultRollingPolicy
- OnCheckpointRollingPolicy
It should be noted that when using Bulk Encoding, you can only use the policy of oncheckpoint rollingpolicy for file scrolling, which scrolls part files every checkpoint.
Note: this blog is adapted from the 2020 New Year video of a horse - > Website of station B
Note: links to other related articles go here - > Flink article summary