Background introduction
This article will introduce how to import the data in MySQL into Kafka in the form of Binlog + Canal, and then be consumed by Flink.
In order to quickly verify the functionality of the whole process, all components are deployed in a single machine. If you have insufficient physical resources, you can build all the components in this article in a 4G 1U virtual machine environment.
If you need to deploy in a production environment, it is recommended to replace each component with a highly available cluster deployment scheme.
Among them, we have created a set of Zookeeper single node environment, which is shared by Flink, Kafka, Canal and other components.
For all components requiring JRE, such as Flink, Kafka, Canal and Zookeeper, considering that upgrading JRE may affect other applications, we choose each component to use its own JRE environment independently.
This paper is divided into two parts. The first seven sections mainly introduce the construction of the basic environment, and the last section introduces how the data flows in each component.
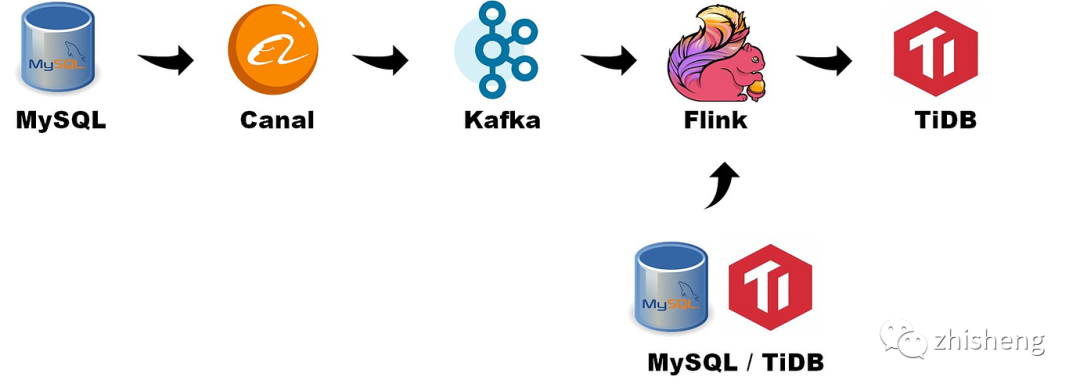
Data flows through the following components:
-
Generating Binlog from MySQL data source
-
The Canal reads the Binlog, generates the Canal json, and pushes it to the Topic specified by Kafka
-
Flink uses the Flink SQL connector Kafka API to consume data in the Kafka Topic
-
Flink writes data to TiDB through the Flink connector JDBC
The structure of TiDB + Flink supports the development and running of many different kinds of applications.
At present, the main features include:
-
Batch flow integration
-
Sophisticated state management
-
Event time support
-
Accurate primary state consistency guarantee
Flink can run on a variety of resource management frameworks including YARN, Mesos and Kubernetes. It also supports independent deployment on bare metal clusters. TiDB can be deployed on AWS, Kubernetes, GCP and gke. It also supports independent deployment on bare metal clusters using TiUP.
The common applications of TiDB + Flink structure are as follows:
-
Event driven applications
-
Anti fraud
-
anomaly detection
-
Rule based alarm
-
Business process monitoring
-
Data analysis application
-
Network quality monitoring
-
Product update and test evaluation analysis
-
Impromptu analysis of factual data
-
Large scale graph analysis
-
Data pipeline application
-
Construction of e-commerce real-time query index
-
E-commerce continuous ETL
Environment introduction
Operating system environment
[root@r20 topology]# cat /etc/redhat-release CentOS Stream release 8
software environment
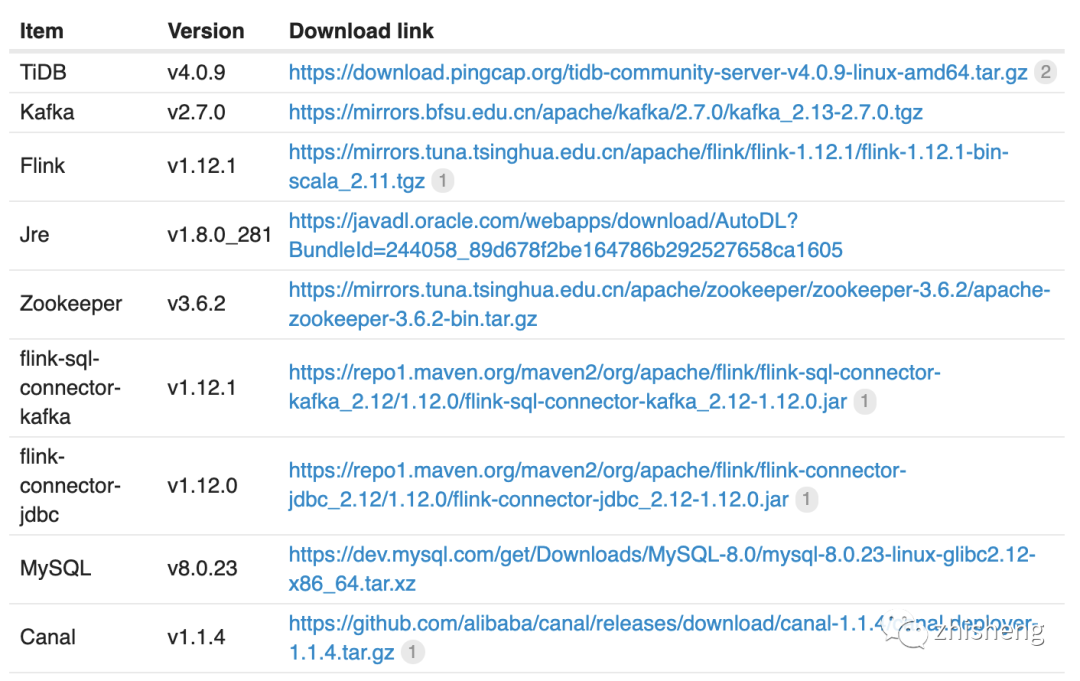
Machine allocation
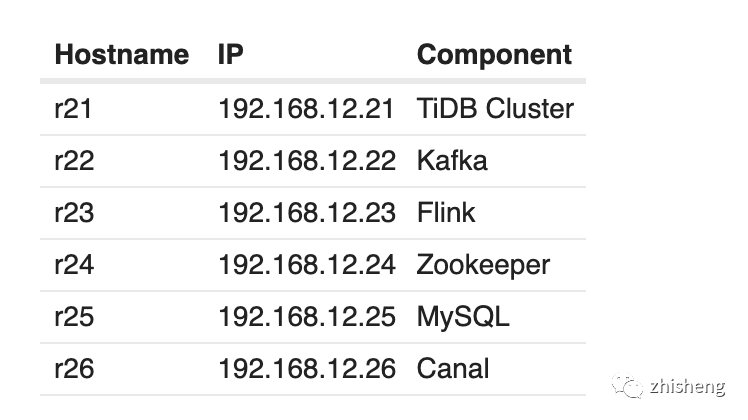
Deploy TiDB Cluster
Compared with the traditional stand-alone database, TiDB has the following advantages:
-
Pure distributed architecture, with good scalability and supporting elastic capacity expansion and contraction
-
It supports SQL, exposes the network protocol of MySQL, and is compatible with most MySQL syntax. It can directly replace MySQL in most scenarios
-
High availability is supported by default. When a few replicas fail, the database itself can automatically perform data repair and failover, which is transparent to the business
-
It supports ACID transactions and is friendly to some scenarios with strong consistent requirements, such as bank transfer
-
It has rich tool chain ecology, covering a variety of scenarios such as data migration, synchronization and backup
In terms of kernel design, TiDB distributed database divides the overall architecture into multiple modules, and each module communicates with each other to form a complete TiDB system. The corresponding architecture diagram is as follows:
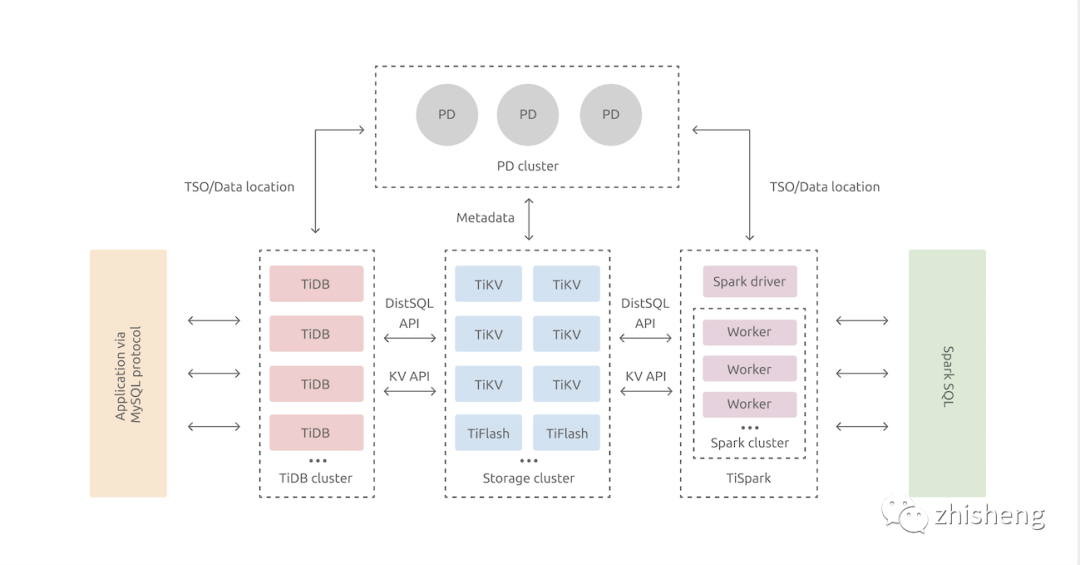
In this article, we only do the simplest function test, so we deploy a set of single node but replica TiDB, which involves the following three modules:
-
TiDB Server: SQL layer, which exposes the connection endpoint of MySQL protocol. It is responsible for accepting client connections, performing SQL parsing and optimization, and finally generating distributed execution plans.
-
PD (Placement Driver) Server: the meta information management module of the whole TiDB cluster, which is responsible for storing the real-time data distribution of each TiKV node and the overall topology of the cluster, providing the TiDB Dashboard control interface, and assigning transaction ID s to distributed transactions.
-
TiKV Server: it is responsible for storing data. Externally, TiKV is a distributed key value storage engine that provides transactions.
TiUP deployment template file
# # Global variables are applied to all deployments and used as the default value of
# # the deployments if a specific deployment value is missing.
global:
user: "tidb"
ssh_port: 22
deploy_dir: "/opt/tidb-c1/"
data_dir: "/opt/tidb-c1/data/"
# # Monitored variables are applied to all the machines.
#monitored:
# node_exporter_port: 19100
# blackbox_exporter_port: 39115
# deploy_dir: "/opt/tidb-c3/monitored"
# data_dir: "/opt/tidb-c3/data/monitored"
# log_dir: "/opt/tidb-c3/log/monitored"
# # Server configs are used to specify the runtime configuration of TiDB components.
# # All configuration items can be found in TiDB docs:
# # - TiDB: https://pingcap.com/docs/stable/reference/configuration/tidb-server/configuration-file/
# # - TiKV: https://pingcap.com/docs/stable/reference/configuration/tikv-server/configuration-file/
# # - PD: https://pingcap.com/docs/stable/reference/configuration/pd-server/configuration-file/
# # All configuration items use points to represent the hierarchy, e.g:
# # readpool.storage.use-unified-pool
# #
# # You can overwrite this configuration via the instance-level `config` field.
server_configs:
tidb:
log.slow-threshold: 300
binlog.enable: false
binlog.ignore-error: false
tikv-client.copr-cache.enable: true
tikv:
server.grpc-concurrency: 4
raftstore.apply-pool-size: 2
raftstore.store-pool-size: 2
rocksdb.max-sub-compactions: 1
storage.block-cache.capacity: "16GB"
readpool.unified.max-thread-count: 12
readpool.storage.use-unified-pool: false
readpool.coprocessor.use-unified-pool: true
raftdb.rate-bytes-per-sec: 0
pd:
schedule.leader-schedule-limit: 4
schedule.region-schedule-limit: 2048
schedule.replica-schedule-limit: 64
pd_servers:
- host: 192.168.12.21
ssh_port: 22
name: "pd-2"
client_port: 12379
peer_port: 12380
deploy_dir: "/opt/tidb-c1/pd-12379"
data_dir: "/opt/tidb-c1/data/pd-12379"
log_dir: "/opt/tidb-c1/log/pd-12379"
numa_node: "0"
# # The following configs are used to overwrite the `server_configs.pd` values.
config:
schedule.max-merge-region-size: 20
schedule.max-merge-region-keys: 200000
tidb_servers:
- host: 192.168.12.21
ssh_port: 22
port: 14000
status_port: 12080
deploy_dir: "/opt/tidb-c1/tidb-14000"
log_dir: "/opt/tidb-c1/log/tidb-14000"
numa_node: "0"
# # The following configs are used to overwrite the `server_configs.tidb` values.
config:
log.slow-query-file: tidb-slow-overwrited.log
tikv-client.copr-cache.enable: true
tikv_servers:
- host: 192.168.12.21
ssh_port: 22
port: 12160
status_port: 12180
deploy_dir: "/opt/tidb-c1/tikv-12160"
data_dir: "/opt/tidb-c1/data/tikv-12160"
log_dir: "/opt/tidb-c1/log/tikv-12160"
numa_node: "0"
# # The following configs are used to overwrite the `server_configs.tikv` values.
config:
server.grpc-concurrency: 4
#server.labels: { zone: "zone1", dc: "dc1", host: "host1" }
#monitoring_servers:
# - host: 192.168.12.21
# ssh_port: 22
# port: 19090
# deploy_dir: "/opt/tidb-c1/prometheus-19090"
# data_dir: "/opt/tidb-c1/data/prometheus-19090"
# log_dir: "/opt/tidb-c1/log/prometheus-19090"
#grafana_servers:
# - host: 192.168.12.21
# port: 13000
# deploy_dir: "/opt/tidb-c1/grafana-13000"
#alertmanager_servers:
# - host: 192.168.12.21
# ssh_port: 22
# web_port: 19093
# cluster_port: 19094
# deploy_dir: "/opt/tidb-c1/alertmanager-19093"
# data_dir: "/opt/tidb-c1/data/alertmanager-19093"
# log_dir: "/opt/tidb-c1/log/alertmanager-19093"
TiDB Cluster environment
The focus of this article is not to deploy TiDB Cluster. As a rapid experimental environment, TiDB Cluster cluster with a single copy is deployed on only one machine. There is no need to deploy the monitoring environment.
[root@r20 topology]# tiup cluster display tidb-c1-v409 Starting component `cluster`: /root/.tiup/components/cluster/v1.3.2/tiup-cluster display tidb-c1-v409 Cluster type: tidb Cluster name: tidb-c1-v409 Cluster version: v4.0.9 SSH type: builtin Dashboard URL: http://192.168.12.21:12379/dashboard ID Role Host Ports OS/Arch Status Data Dir Deploy Dir -- ---- ---- ----- ------- ------ -------- ---------- 192.168.12.21:12379 pd 192.168.12.21 12379/12380 linux/x86_64 Up|L|UI /opt/tidb-c1/data/pd-12379 /opt/tidb-c1/pd-12379 192.168.12.21:14000 tidb 192.168.12.21 14000/12080 linux/x86_64 Up - /opt/tidb-c1/tidb-14000 192.168.12.21:12160 tikv 192.168.12.21 12160/12180 linux/x86_64 Up /opt/tidb-c1/data/tikv-12160 /opt/tidb-c1/tikv-12160 Total nodes: 4
Create a table for testing
mysql> show create table t1; +-------+-------------------------------------------------------------------------------------------------------------------------------+ | Table | Create Table | +-------+-------------------------------------------------------------------------------------------------------------------------------+ | t1 | CREATE TABLE `t1` ( `id` int(11) NOT NULL, PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin | +-------+-------------------------------------------------------------------------------------------------------------------------------+ 1 row in set (0.00 sec)
Deploy Zookeeper environment
In this experiment, Zookeeper environment is configured separately to provide services for Kafka and Flink environments.
As an experimental demonstration scheme, only the stand-alone environment is deployed.
Unzip the Zookeeper package
[root@r24 soft]# tar vxzf apache-zookeeper-3.6.2-bin.tar.gz [root@r24 soft]# mv apache-zookeeper-3.6.2-bin /opt/zookeeper
Deploy jre for Zookeeper
[root@r24 soft]# tar vxzf jre1.8.0_281.tar.gz [root@r24 soft]# mv jre1.8.0_281 /opt/zookeeper/jre
Modify / opt/zookeeper/bin/zkEnv.sh file to add JAVA_HOME environment variable
## add bellowing env var in the head of zkEnv.sh JAVA_HOME=/opt/zookeeper/jre
Create a profile for Zookeeper
[root@r24 conf]# cat zoo.cfg | grep -v "#" tickTime=2000 initLimit=10 syncLimit=5 dataDir=/opt/zookeeper/data clientPort=2181
Start Zookeeper
[root@r24 bin]# /opt/zookeeper/bin/zkServer.sh start
Check the status of Zookeeper
## check zk status [root@r24 bin]# ./zkServer.sh status ZooKeeper JMX enabled by default Using config: /opt/zookeeper/bin/../conf/zoo.cfg Client port found: 2181. Client address: localhost. Client SSL: false. Mode: standalone ## check OS port status [root@r24 bin]# netstat -ntlp Active Internet connections (only servers) Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name tcp 0 0 0.0.0.0:22 0.0.0.0:* LISTEN 942/sshd tcp6 0 0 :::2181 :::* LISTEN 15062/java tcp6 0 0 :::8080 :::* LISTEN 15062/java tcp6 0 0 :::22 :::* LISTEN 942/sshd tcp6 0 0 :::44505 :::* LISTEN 15062/java ## use zkCli tool to check zk connection [root@r24 bin]# ./zkCli.sh -server 192.168.12.24:2181
Suggestions on Zookeeper
I personally have an immature suggestion about Zookeeper:
The Zookeeper cluster version must enable network monitoring.
In particular, pay attention to the network bandwidth in system metrics.
Deploy Kafka
Kafka is a distributed stream processing platform, which is mainly used in two types of applications:
-
A real-time stream data pipeline is constructed, which can reliably obtain data between systems or applications( Equivalent to message queue)
-
Build real-time streaming applications to transform or influence these streaming data( That is, flow processing, which changes internally between kafka stream topic and topic)
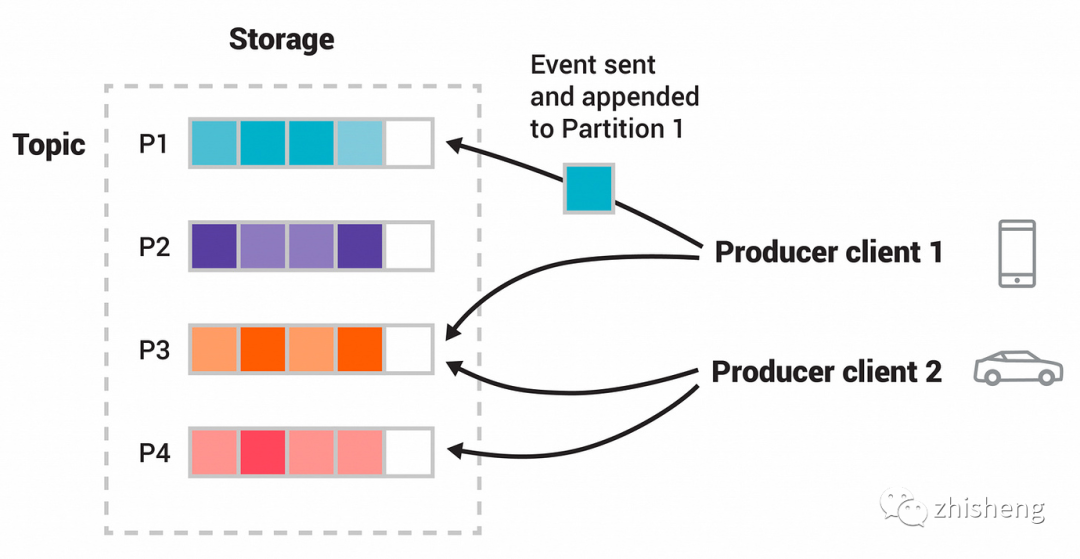
Kafka has four core API s:
-
The Producer API allows an application to publish a stream of data to one or more Kafka topic s.
-
The Consumer API allows an application to subscribe to one or more topic s and process the streaming data published to them.
-
The Streams API allows an application as a stream processor to consume input streams generated by one or more topics, and then produce an output stream to one or more topics for effective conversion in the input and output streams.
-
The Connector API allows to build and run reusable producers or consumers to connect Kafka topics to existing applications or data systems. For example, connect to a relational database and capture all changes to the table.
In this experiment, only functional verification is done, and only a stand-alone Kafka environment is built.
Download and unzip Kafka
[root@r22 soft]# tar vxzf kafka_2.13-2.7.0.tgz [root@r22 soft]# mv kafka_2.13-2.7.0 /opt/kafka
Deploy jre for Kafka
[root@r22 soft]# tar vxzf jre1.8.0_281.tar.gz [root@r22 soft]# mv jre1.8.0_281 /opt/kafka/jre
Modify Kafka's jre environment variable
[root@r22 bin]# vim /opt/kafka/bin/kafka-run-class.sh ## add bellowing line in the head of kafka-run-class.sh JAVA_HOME=/opt/kafka/jre
Modify Kafka profile
modify Kafka configuration file /opt/kafka/config/server.properties ## change bellowing variable in /opt/kafka/config/server.properties broker.id=0 listeners=PLAINTEXT://192.168.12.22:9092 log.dirs=/opt/kafka/logs zookeeper.connect=i192.168.12.24:2181
Start Kafka
[root@r22 bin]# /opt/kafka/bin/kafka-server-start.sh /opt/kafka/config/server.properties
View version information of Kafka
Kafka Not provided --version of optional To see Kafka Version information for. [root@r22 ~]# ll /opt/kafka/libs/ | grep kafka -rw-r--r-- 1 root root 4929521 Dec 16 09:02 kafka_2.13-2.7.0.jar -rw-r--r-- 1 root root 821 Dec 16 09:03 kafka_2.13-2.7.0.jar.asc -rw-r--r-- 1 root root 41793 Dec 16 09:02 kafka_2.13-2.7.0-javadoc.jar -rw-r--r-- 1 root root 821 Dec 16 09:03 kafka_2.13-2.7.0-javadoc.jar.asc -rw-r--r-- 1 root root 892036 Dec 16 09:02 kafka_2.13-2.7.0-sources.jar -rw-r--r-- 1 root root 821 Dec 16 09:03 kafka_2.13-2.7.0-sources.jar.asc ... ...
Where 2.13 is the version information of scale and 2.7.0 is the version information of Kafka.
Deploy Flink
Apache Flink is a framework and distributed processing engine for stateful computing on unbounded and bounded data streams. Flink can run in all common cluster environments and can calculate at memory speed and any size.
Apache Flink, a distributed processing framework supporting high throughput, low latency and high performance, is a framework and distributed processing engine for stateful computing of unbounded and bounded data streams. Flink is designed to run in all common cluster environments and perform calculations at memory execution speed and any size.
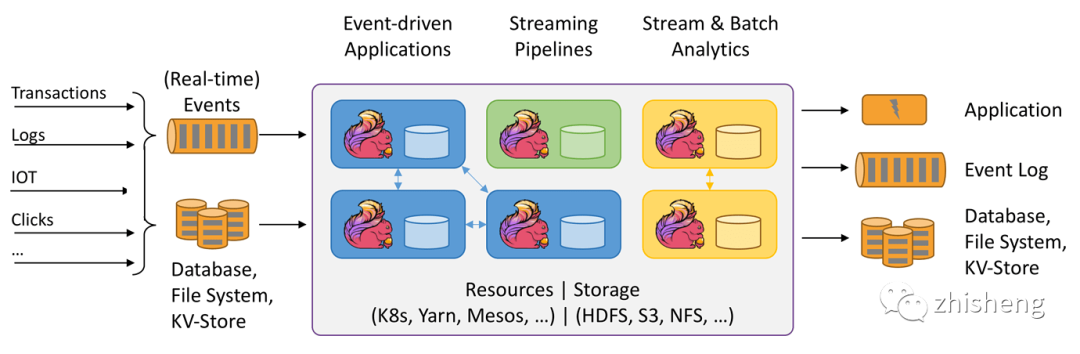
This experiment only does functional testing and only deploys the stand-alone Flink environment.
Download and distribute Flink
[root@r23 soft]# tar vxzf flink-1.12.1-bin-scala_2.11.tgz [root@r23 soft]# mv flink-1.12.1 /opt/flink
Deploy jre for Flink
[root@r23 soft]# tar vxzf jre1.8.0_281.tar.gz [root@r23 soft]# mv jre1.8.0_281 /opt/flink/jre
Add lib required by Flink
Flink consumption Kafka Data, required flink-sql-connector-kafka package Flink link MySQL/TiDB,need flink-connector-jdbc package [root@r23 soft]# mv flink-sql-connector-kafka_2.12-1.12.0.jar /opt/flink/lib/ [root@r23 soft]# mv flink-connector-jdbc_2.12-1.12.0.jar /opt/flink/lib/
Modify Flink profile
## add or modify bellowing lines in /opt/flink/conf/flink-conf.yaml jobmanager.rpc.address: 192.168.12.23 env.java.home: /opt/flink/jre
Launch Flink
[root@r23 ~]# /opt/flink/bin/start-cluster.sh Starting cluster. Starting standalonesession daemon on host r23. Starting taskexecutor daemon on host r23.
View Flink GUI
Deploy MySQL
Unzip MySQL package
[root@r25 soft]# tar vxf mysql-8.0.23-linux-glibc2.12-x86_64.tar.xz [root@r25 soft]# mv mysql-8.0.23-linux-glibc2.12-x86_64 /opt/mysql/
Create MySQL Service file
[root@r25 ~]# touch /opt/mysql/support-files/mysqld.service [root@r25 support-files]# cat mysqld.service [Unit] Description=MySQL 8.0 database server After=syslog.target After=network.target [Service] Type=simple User=mysql Group=mysql #ExecStartPre=/usr/libexec/mysql-check-socket #ExecStartPre=/usr/libexec/mysql-prepare-db-dir %n # Note: we set --basedir to prevent probes that might trigger SELinux alarms, # per bug #547485 ExecStart=/opt/mysql/bin/mysqld_safe #ExecStartPost=/opt/mysql/bin/mysql-check-upgrade #ExecStopPost=/opt/mysql/bin/mysql-wait-stop # Give a reasonable amount of time for the server to start up/shut down TimeoutSec=300 # Place temp files in a secure directory, not /tmp PrivateTmp=true Restart=on-failure RestartPreventExitStatus=1 # Sets open_files_limit LimitNOFILE = 10000 # Set enviroment variable MYSQLD_PARENT_PID. This is required for SQL restart command. Environment=MYSQLD_PARENT_PID=1 [Install] WantedBy=multi-user.target ## copy mysqld.service to /usr/lib/systemd/system/ [root@r25 support-files]# cp mysqld.service /usr/lib/systemd/system/
Create my.cnf file
[root@r34 opt]# cat /etc/my.cnf [mysqld] port=3306 basedir=/opt/mysql datadir=/opt/mysql/data socket=/opt/mysql/data/mysql.socket max_connections = 100 default-storage-engine = InnoDB character-set-server=utf8 log-error = /opt/mysql/log/error.log slow_query_log = 1 long-query-time = 30 slow_query_log_file = /opt/mysql/log/show.log min_examined_row_limit = 1000 log-slow-slave-statements log-queries-not-using-indexes #skip-grant-tables
Initialize and start MySQL
[root@r25 ~]# /opt/mysql/bin/mysqld --initialize --user=mysql --console [root@r25 ~]# chown -R mysql:mysql /opt/mysql [root@r25 ~]# systemctl start mysqld ## check mysql temp passord from /opt/mysql/log/error.log 2021-02-24T02:45:47.316406Z 6 [Note] [MY-010454] [Server] A temporary password is generated for root@localhost: I?nDjijxa3>-
Create a new MySQL user to connect to Canal
## change mysql temp password firstly mysql> alter user 'root'@'localhost' identified by 'mysql'; Query OK, 0 rows affected (0.00 sec) ## create a management user 'root'@'%' mysql> create user 'root'@'%' identified by 'mysql'; Query OK, 0 rows affected (0.01 sec) mysql> grant all privileges on *.* to 'root'@'%'; Query OK, 0 rows affected (0.00 sec) ## create a canal replication user 'canal'@'%' mysql> create user 'canal'@'%' identified by 'canal'; Query OK, 0 rows affected (0.01 sec) mysql> grant select, replication slave, replication client on *.* to 'canal'@'%'; Query OK, 0 rows affected (0.00 sec) mysql> flush privileges; Query OK, 0 rows affected (0.00 sec)
Create tables for testing in MySQL
mysql> show create table test.t2; +-------+----------------------------------------------------------------------------------+ | Table | Create Table | +-------+----------------------------------------------------------------------------------+ | t2 | CREATE TABLE `t2` ( `id` int DEFAULT NULL ) ENGINE=InnoDB DEFAULT CHARSET=utf8 | +-------+----------------------------------------------------------------------------------+ 1 row in set (0.00 sec)
Deploy Canal
The main purpose of Canal is to provide incremental data subscription and consumption based on MySQL database incremental log parsing
In the early days, Alibaba had the business requirement of cross machine room synchronization due to the deployment of dual machine rooms in Hangzhou and the United States. The implementation method was mainly to obtain incremental changes based on the business trigger.
Since 2010, the business has gradually tried to obtain incremental changes through database log parsing for synchronization, resulting in a large number of database incremental subscriptions and consumption services.
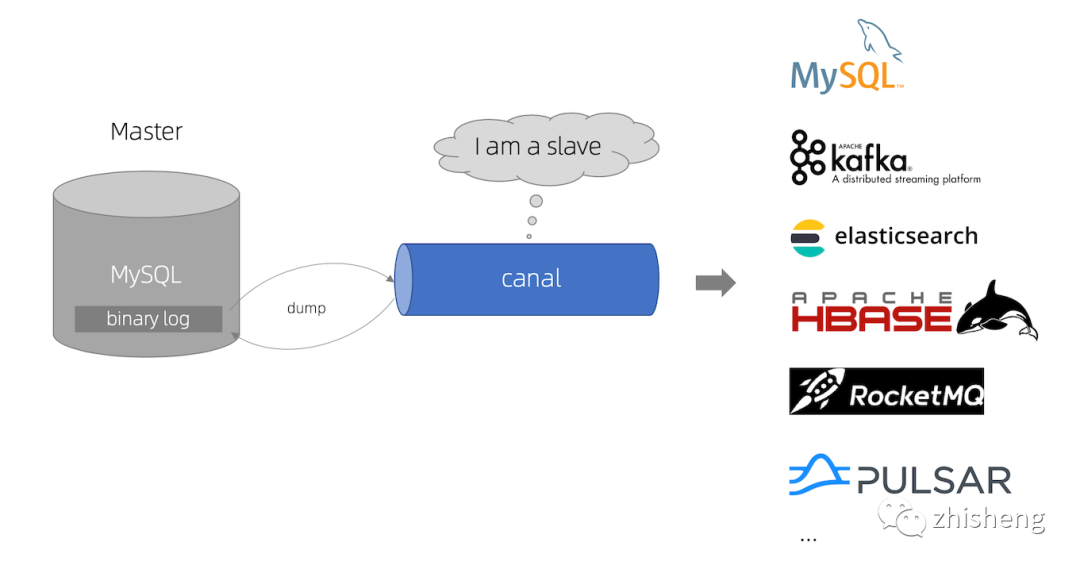
Businesses based on log incremental subscription and consumption include:
-
database mirroring
-
Real time database backup
-
Index construction and real-time maintenance (splitting heterogeneous indexes, inverted indexes, etc.)
-
Service cache refresh
-
Incremental data processing with business logic
Current canal supports source MySQL versions, including 5.1. X, 5.5. X, 5.6. X, 5.7. X, and 8.0. X
Unzip the Canal package
[root@r26 soft]# mkdir /opt/canal && tar vxzf canal.deployer-1.1.4.tar.gz -C /opt/canal
Deploy jre of Canal
[root@r26 soft]# tar vxzf jre1.8.0_281.tar.gz [root@r26 soft]# mv jre1.8.0_281 /opt/canal/jre ## configue jre, add bellowing line in the head of /opt/canal/bin/startup.sh JAVA=/opt/canal/jre/bin/java
Modify the configuration file of Canal
modify /opt/canal/conf/canal.properties configuration file ## modify bellowing configuration canal.zkServers =192.168.12.24:2181 canal.serverMode = kafka canal.destinations = example ## Need in / opt/canal/conf Create a directory example Folder for storing destination Configuration of canal.mq.servers = 192.168.12.22:9092 modify /opt/canal/conf/example/instance.properties configuration file ## modify bellowing configuration canal.instance.master.address=192.168.12.25:3306 canal.instance.dbUsername=canal canal.instance.dbPassword=canal canal.instance.filter.regex=.*\\..* ## Filter database tables canal.mq.topic=canal-kafka
Configure data flow
MySQL binlog - > canal - > Kafka channel
View MySQL Binlog information
Check the MySQL Binlog information to ensure that the Binlog is normal
mysql> show master status; +---------------+----------+--------------+------------------+-------------------+ | File | Position | Binlog_Do_DB | Binlog_Ignore_DB | Executed_Gtid_Set | +---------------+----------+--------------+------------------+-------------------+ | binlog.000001 | 2888 | | | | +---------------+----------+--------------+------------------+-------------------+ 1 row in set (0.00 sec)
Create a Topic in Kafka
Create a topic Canal Kafka in Kafka. The name of this topic should correspond to Canal. MQ. Topic = Canal Kafka in the Canal configuration file / opt/canal/conf/example/instance.properties:
[root@r22 kafka]# /opt/kafka/bin/kafka-topics.sh --create \
> --zookeeper 192.168.12.24:2181 \
> --config max.message.bytes=12800000 \
> --config flush.messages=1 \
> --replication-factor 1 \
> --partitions 1 \
> --topic canal-kafka
Created topic canal-kafka.
[2021-02-24 01:51:55,050] INFO [ReplicaFetcherManager on broker 0] Removed fetcher for partitions Set(canal-kafka-0) (kafka.server.ReplicaFetcherManager)
[2021-02-24 01:51:55,052] INFO [Log partition=canal-kafka-0, dir=/opt/kafka/logs] Loading producer state till offset 0 with message format version 2 (kafka.log.Log)
[2021-02-24 01:51:55,053] INFO Created log for partition canal-kafka-0 in /opt/kafka/logs/canal-kafka-0 with properties {compression.type -> producer, message.downconversion.enable -> true, min.insync.replicas -> 1, segment.jitter.ms -> 0, cleanup.policy -> [delete], flush.ms -> 9223372036854775807, segment.bytes -> 1073741824, retention.ms -> 604800000, flush.messages -> 1, message.format.version -> 2.7-IV2, file.delete.delay.ms -> 60000, max.compaction.lag.ms -> 9223372036854775807, max.message.bytes -> 12800000, min.compaction.lag.ms -> 0, message.timestamp.type -> CreateTime, preallocate -> false, min.cleanable.dirty.ratio -> 0.5, index.interval.bytes -> 4096, unclean.leader.election.enable -> false, retention.bytes -> -1, delete.retention.ms -> 86400000, segment.ms -> 604800000, message.timestamp.difference.max.ms -> 9223372036854775807, segment.index.bytes -> 10485760}. (kafka.log.LogManager)
[2021-02-24 01:51:55,053] INFO [Partition canal-kafka-0 broker=0] No checkpointed highwatermark is found for partition canal-kafka-0 (kafka.cluster.Partition)
[2021-02-24 01:51:55,053] INFO [Partition canal-kafka-0 broker=0] Log loaded for partition canal-kafka-0 with initial high watermark 0 (kafka.cluster.Partition)
View all topics in Kafka:
[root@r22 kafka]# /opt/kafka/bin/kafka-topics.sh --list --zookeeper 192.168.12.24:2181 __consumer_offsets canal-kafka ticdc-test
View the information of topic ticdc test in Kafka:
[root@r22 ~]# /opt/kafka/bin/kafka-topics.sh --describe --zookeeper 192.168.12.24:2181 --topic canal-kafka Topic: ticdc-test PartitionCount: 1 ReplicationFactor: 1 Configs: max.message.bytes=12800000,flush.messages=1 Topic: ticdc-test Partition: 0 Leader: 0 Replicas: 0 Isr: 0
8.1.3 start Canal
Before starting the Canal, you need to check the port on the Canal node:
## check MySQL 3306 port ## canal.instance.master.address=192.168.12.25:3306 [root@r26 bin]# telnet 192.168.12.25 3306 ## check Kafka 9092 port ## canal.mq.servers = 192.168.12.22:9092 [root@r26 bin]# telnet 192.168.12.22 9092 ## check zookeeper 2181 port ## canal.zkServers = 192.168.12.24:2181 [root@r26 bin]# telnet 192.168.12.24 2181
Start Canal:
[root@r26 bin]# /opt/canal/bin/startup.sh cd to /opt/canal/bin for workaround relative path LOG CONFIGURATION : /opt/canal/bin/../conf/logback.xml canal conf : /opt/canal/bin/../conf/canal.properties CLASSPATH :/opt/canal/bin/../conf:/opt/canal/bin/../lib/zookeeper-3.4.5.jar:/opt/canal/bin/../lib/zkclient-0.10.jar:/opt/canal/bin/../lib/spring-tx-3.2.18.RELEASE.jar:/opt/canal/bin/../lib/spring-orm-3.2.18.RELEASE.jar:/opt/canal/bin/../lib/spring-jdbc-3.2.18.RELEASE.jar:/opt/canal/bin/../lib/spring-expression-3.2.18.RELEASE.jar:/opt/canal/bin/../lib/spring-core-3.2.18.RELEASE.jar:/opt/canal/bin/../lib/spring-context-3.2.18.RELEASE.jar:/opt/canal/bin/../lib/spring-beans-3.2.18.RELEASE.jar:/opt/canal/bin/../lib/spring-aop-3.2.18.RELEASE.jar:/opt/canal/bin/../lib/snappy-java-1.1.7.1.jar:/opt/canal/bin/../lib/snakeyaml-1.19.jar:/opt/canal/bin/../lib/slf4j-api-1.7.12.jar:/opt/canal/bin/../lib/simpleclient_pushgateway-0.4.0.jar:/opt/canal/bin/../lib/simpleclient_httpserver-0.4.0.jar:/opt/canal/bin/../lib/simpleclient_hotspot-0.4.0.jar:/opt/canal/bin/../lib/simpleclient_common-0.4.0.jar:/opt/canal/bin/../lib/simpleclient-0.4.0.jar:/opt/canal/bin/../lib/scala-reflect-2.11.12.jar:/opt/canal/bin/../lib/scala-logging_2.11-3.8.0.jar:/opt/canal/bin/../lib/scala-library-2.11.12.jar:/opt/canal/bin/../lib/rocketmq-srvutil-4.5.2.jar:/opt/canal/bin/../lib/rocketmq-remoting-4.5.2.jar:/opt/canal/bin/../lib/rocketmq-logging-4.5.2.jar:/opt/canal/bin/../lib/rocketmq-common-4.5.2.jar:/opt/canal/bin/../lib/rocketmq-client-4.5.2.jar:/opt/canal/bin/../lib/rocketmq-acl-4.5.2.jar:/opt/canal/bin/../lib/protobuf-java-3.6.1.jar:/opt/canal/bin/../lib/oro-2.0.8.jar:/opt/canal/bin/../lib/netty-tcnative-boringssl-static-1.1.33.Fork26.jar:/opt/canal/bin/../lib/netty-all-4.1.6.Final.jar:/opt/canal/bin/../lib/netty-3.2.2.Final.jar:/opt/canal/bin/../lib/mysql-connector-java-5.1.47.jar:/opt/canal/bin/../lib/metrics-core-2.2.0.jar:/opt/canal/bin/../lib/lz4-java-1.4.1.jar:/opt/canal/bin/../lib/logback-core-1.1.3.jar:/opt/canal/bin/../lib/logback-classic-1.1.3.jar:/opt/canal/bin/../lib/kafka-clients-1.1.1.jar:/opt/canal/bin/../lib/kafka_2.11-1.1.1.jar:/opt/canal/bin/../lib/jsr305-3.0.2.jar:/opt/canal/bin/../lib/jopt-simple-5.0.4.jar:/opt/canal/bin/../lib/jctools-core-2.1.2.jar:/opt/canal/bin/../lib/jcl-over-slf4j-1.7.12.jar:/opt/canal/bin/../lib/javax.annotation-api-1.3.2.jar:/opt/canal/bin/../lib/jackson-databind-2.9.6.jar:/opt/canal/bin/../lib/jackson-core-2.9.6.jar:/opt/canal/bin/../lib/jackson-annotations-2.9.0.jar:/opt/canal/bin/../lib/ibatis-sqlmap-2.3.4.726.jar:/opt/canal/bin/../lib/httpcore-4.4.3.jar:/opt/canal/bin/../lib/httpclient-4.5.1.jar:/opt/canal/bin/../lib/h2-1.4.196.jar:/opt/canal/bin/../lib/guava-18.0.jar:/opt/canal/bin/../lib/fastsql-2.0.0_preview_973.jar:/opt/canal/bin/../lib/fastjson-1.2.58.jar:/opt/canal/bin/../lib/druid-1.1.9.jar:/opt/canal/bin/../lib/disruptor-3.4.2.jar:/opt/canal/bin/../lib/commons-logging-1.1.3.jar:/opt/canal/bin/../lib/commons-lang3-3.4.jar:/opt/canal/bin/../lib/commons-lang-2.6.jar:/opt/canal/bin/../lib/commons-io-2.4.jar:/opt/canal/bin/../lib/commons-compress-1.9.jar:/opt/canal/bin/../lib/commons-codec-1.9.jar:/opt/canal/bin/../lib/commons-cli-1.2.jar:/opt/canal/bin/../lib/commons-beanutils-1.8.2.jar:/opt/canal/bin/../lib/canal.store-1.1.4.jar:/opt/canal/bin/../lib/canal.sink-1.1.4.jar:/opt/canal/bin/../lib/canal.server-1.1.4.jar:/opt/canal/bin/../lib/canal.protocol-1.1.4.jar:/opt/canal/bin/../lib/canal.prometheus-1.1.4.jar:/opt/canal/bin/../lib/canal.parse.driver-1.1.4.jar:/opt/canal/bin/../lib/canal.parse.dbsync-1.1.4.jar:/opt/canal/bin/../lib/canal.parse-1.1.4.jar:/opt/canal/bin/../lib/canal.meta-1.1.4.jar:/opt/canal/bin/../lib/canal.instance.spring-1.1.4.jar:/opt/canal/bin/../lib/canal.instance.manager-1.1.4.jar:/opt/canal/bin/../lib/canal.instance.core-1.1.4.jar:/opt/canal/bin/../lib/canal.filter-1.1.4.jar:/opt/canal/bin/../lib/canal.deployer-1.1.4.jar:/opt/canal/bin/../lib/canal.common-1.1.4.jar:/opt/canal/bin/../lib/aviator-2.2.1.jar:/opt/canal/bin/../lib/aopalliance-1.0.jar: cd to /opt/canal/bin for continue
View Canal log
View / opt/canal/logs/example/example.log
2021-02-24 01:41:40.293 [destination = example , address = /192.168.12.25:3306 , EventParser] WARN c.a.o.c.p.inbound.mysql.rds.RdsBinlogEventParserProxy - ---> begin to find start position, it will be long time for reset or first position 2021-02-24 01:41:40.293 [destination = example , address = /192.168.12.25:3306 , EventParser] WARN c.a.o.c.p.inbound.mysql.rds.RdsBinlogEventParserProxy - prepare to find start position just show master status 2021-02-24 01:41:40.542 [destination = example , address = /192.168.12.25:3306 , EventParser] WARN c.a.o.c.p.inbound.mysql.rds.RdsBinlogEventParserProxy - ---> find start position successfully, EntryPosition[included=false,journalName=binlog.000001,position=4,serverId=1,gtid=<null>,timestamp=1614134832000] cost : 244ms , the next step is binlog dump
View consumer information in Kafka
Insert a test message into MySQL:
mysql> insert into t2 values(1); Query OK, 1 row affected (0.00 sec)
Check the information of the consumer, and you have the test data just inserted:
/opt/kafka/bin/kafka-console-consumer.sh --bootstrap-server 192.168.12.22:9092 --topic canal-kafka --from-beginning
{"data":null,"database":"test","es":1614151725000,"id":2,"isDdl":false,"mysqlType":null,"old":null,"pkNames":null,"sql":"create database test","sqlType":null,"table":"","ts":1614151725890,"type":"QUERY"}
{"data":null,"database":"test","es":1614151746000,"id":3,"isDdl":true,"mysqlType":null,"old":null,"pkNames":null,"sql":"create table t2(id int)","sqlType":null,"table":"t2","ts":1614151746141,"type":"CREATE"}
{"data":[{"id":"1"}],"database":"test","es":1614151941000,"id":4,"isDdl":false,"mysqlType":{"id":"int"},"old":null,"pkNames":null,"sql":"","sqlType":{"id":4},"table":"t2","ts":1614151941235,"type":"INSERT"}
Kafka - > Flink path
Create the t2 table in Flink, and the connector type is kafka
## create a test table t2 in Flink Flink SQL> create table t2(id int) > WITH ( > 'connector' = 'kafka', > 'topic' = 'canal-kafka', > 'properties.bootstrap.servers' = '192.168.12.22:9092', > 'properties.group.id' = 'canal-kafka-consumer-group', > 'format' = 'canal-json', > 'scan.startup.mode' = 'latest-offset' > ); Flink SQL> select * from t1;
Insert a test data in MySQL:
mysql> insert into test.t2 values(2); Query OK, 1 row affected (0.00 sec)
Sync data in real time from Flink:
Flink SQL> select * from t1; Refresh: 1 s Page: Last of 1 Updated: 02:49:27.366 id 2
Flink - > tidb path
Create a table for testing in the downstream TiDB
[root@r20 soft]# mysql -uroot -P14000 -hr21 mysql> create table t3 (id int); Query OK, 0 rows affected (0.31 sec)
Create a test table in Flink
Flink SQL> CREATE TABLE t3 ( > id int > ) with ( > 'connector' = 'jdbc', > 'url' = 'jdbc:mysql://192.168.12.21:14000/test', > 'table-name' = 't3', > 'username' = 'root', > 'password' = 'mysql' > ); Flink SQL> insert into t3 values(3); [INFO] Submitting SQL update statement to the cluster... [INFO] Table update statement has been successfully submitted to the cluster: Job ID: a0827487030db177ee7e5c8575ef714e
View the inserted data in the downstream TiDB
mysql> select * from test.t3; +------+ | id | +------+ | 3 | +------+ 1 row in set (0.00 sec)