Flink heavy
De duplication calculation should be a common indicator calculation in data analysis business, such as the number of users visiting the website in a day, the number of users clicking on advertisements, etc. offline calculation is a full and one-time calculation process, and the de duplication results can usually be obtained by distinct, while real-time calculation is an incremental and long-term calculation process. We are facing different scenarios, For example, different schemes can be used for the size of data and the accuracy requirements of calculation results. This article introduces how to achieve accurate de duplication through coding. Take an actual scenario as an example: calculate the number of users clicking on each advertisement per hour. The advertisement click log includes: advertisement slot ID, user device ID(idfa/imei/cookie) and click time.
Here are four ways of weight removal:
-
MapState de duplication
-
SQL de duplication
-
Hyperlog de duplication
-
bitmap exact de duplication
One MapState de duplication
1.1 analysis of implementation steps
- In order to reproduce the data of the day, the event time, that is, the advertising click time, is selected here as the window period division of each hour
- The data grouping uses the advertising space ID + the hour of the click event
- Select processFunction to implement it. One state is used to save data and the other state is used to save the corresponding amount of data
- Data cleaning after calculation is completed, and timer cleaning is registered according to the time schedule
1.2 realization
1.2.1 advertising data
case class AdData(id:Int,devId:String,time:Long)
1.2.2 grouping data
case class AdKey(id:Int,time:Long)
1.2.3 main process
val env=StreamExecutionEnvironment.getExecutionEnvironment
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
val kafkaConfig=new Properties()
kafkaConfig.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,"localhost:9092")
kafkaConfig.put(ConsumerConfig.GROUP_ID_CONFIG,"test1")
val consumer=new FlinkKafkaConsumer[String]("topic1",new SimpleStringSchema,kafkaConfig)
val ds=env.addSource(consumer)
.map(x=>{
val s=x.split(",")
AdData(s(0).toInt,s(1),s(2).toLong)
}).assignTimestampsAndWatermarks(new BoundedOutOfOrdernessTimestampExtractor[AdData](Time.minutes(1)) {
override def extractTimestamp(element: AdData): Long = element.time
})
.keyBy(x=>{
val endTime= TimeWindow.getWindowStartWithOffset(x.time, 0,
Time.hours(1).toMilliseconds) + Time.hours(1).toMilliseconds
AdKey(x.id,endTime)
})
Specify the time attribute. Set here to allow 1min delay, which can be adjusted according to the actual situation;
Select timewindow for time conversion The method of getwindowstartwithoffset Flink in processing the window is very convenient to use. The first parameter represents the data time, and the second parameter offset, which is 0 by default. The normal window division is in the whole point mode. For example, starting from 0, this offset is the offset relative to 0, and the third parameter represents the window size, The result is the start time of the window to which the data time belongs. Here, the window size is added, and the end time and advertising space ID are used as the grouping Key.
1.3 de duplication logic
The custom distinguish1processfunction inherits the KeyedProcessFunction. For convenience, the output type is Void. Here, you can directly use the print console to view the results. In practice, it can be output to the downstream for batch processing and then output;
Define two states: mapstate, where key represents devid, and value represents an arbitrary value for identification only. This state represents the device data of an advertising space in a certain hour. If we use rocksdb as statebackend, we will take the key in mapstate as part of the key in rocksdb, value in mapstate as the value in rocksdb, and the value in rocksdb has an upper limit, This method can reduce the size of rocksdb value; Another ValueState stores the data volume of the current mapstate because mapstate can only obtain the data volume through iteration. Each acquisition requires iteration, which can avoid each iteration.
class Distinct1ProcessFunction extends KeyedProcessFunction[AdKey, AdData, Void] {
var devIdState: MapState[String, Int] = _
var devIdStateDesc: MapStateDescriptor[String, Int] = _
var countState: ValueState[Long] = _
var countStateDesc: ValueStateDescriptor[Long] = _
override def open(parameters: Configuration): Unit = {
devIdStateDesc = new MapStateDescriptor[String, Int]("devIdState", TypeInformation.of(classOf[String]), TypeInformation.of(classOf[Int]))
devIdState = getRuntimeContext.getMapState(devIdStateDesc)
countStateDesc = new ValueStateDescriptor[Long]("countState", TypeInformation.of(classOf[Long]))
countState = getRuntimeContext.getState(countStateDesc)
}
override def processElement(value: AdData, ctx: KeyedProcessFunction[AdKey, AdData, Void]#Context, out: Collector[Void]): Unit = {
val currW=ctx.timerService().currentWatermark()
if(ctx.getCurrentKey.time+1<=currW) {
println("late data:" + value)
return
}
val devId = value.devId
devIdState.get(devId) match {
case 1 => {
//Indicates that it already exists
}
case _ => {
//Indicates that does not exist
devIdState.put(devId, 1)
val c = countState.value()
countState.update(c + 1)
//You also need to register a timer
ctx.timerService().registerEventTimeTimer(ctx.getCurrentKey.time + 1)
}
}
println(countState.value())
}
override def onTimer(timestamp: Long, ctx: KeyedProcessFunction[AdKey, AdData, Void]#OnTimerContext, out: Collector[Void]): Unit = {
println(timestamp + " exec clean~~~")
println(countState.value())
devIdState.clear()
countState.clear()
}
}
Data cleaning is done by registering timer CTX timerService(). Registereventtimer (CTX. Getcurrentkey. Time + 1) means that when the watermark is greater than the end time of the hour + 1, the cleanup action will be executed and the onTimer method will be called.
In the processing logic
val currW=ctx.timerService().currentWatermark()
if(ctx.getCurrentKey.time+1<=currW){
println("late data:" + value)
return
}
The main consideration is that the data that may lag is serious, which will affect the previous calculation results. A delay judgment similar to that in the window mechanism is made to filter out the delayed data. OutputTag can also be used for separate processing.
Secondary SQL de duplication
In MapState de duplication, it is introduced to use coding to complete de duplication, but this method has a long development cycle. We may need to implement different coding for different business logic. For business development, we also need to be familiar with Flink coding, which will also increase the corresponding cost, We hope to provide our own de duplication logic to business development in the form of sql. This article describes how to use sql to complete the de duplication.
In order to maintain the analysis semantics consistent with offline analysis, Flink SQL provides a distinct de duplication method, which is used as follows:
SELECT DISTINCT devId FROM pv
It means that the device ID is de duplicated and a detailed result is obtained. Then we usually use distinct to count the de duplicated results in two ways, still taking the daily website uv as an example.
2.1 the first method
SELECT datatime,count(DISTINCT devId) FROM pv group by datatime
This semantic means to calculate the daily uv quantity of web pages. Its internal core implementation mainly depends on the distinct accumulator and CountAccumulator. The distinct accumulator contains a map structure. key represents the field of distinct, value represents the repeated count, and CountAccumulator is the function of a counter, These two parts are used as the intermediate result accumulator of dynamically generating aggregate function. Through the analysis of aggregate function before, we can know that the intermediate result is stored in the state, that is, it is fault-tolerant and has consistent semantics
The processing flow is:
-
Adding devId to the corresponding distinguishaccumulator object will first determine whether the devId exists in the map. If it does not exist, it will be inserted into the map and the corresponding value will be marked as 1, and return True; If it exists, the corresponding value+1 is updated to the map, and False is returned
-
Only when it returns True will the CountAccumulator accumulate 1, so as to achieve the purpose of counting
2.2 the second method
select count(*),datatime from(select distinct devId,datatime from pv ) agroup by datatime
Internally, it is a distinct calculation of devid and DataTime. Internally, it will be converted into a stream grouped by devid and DataTime and aggregate. Internally, it will dynamically generate an aggregate function. The aggregate function createaggregates method generates an accumulator object of Row(0), and its aggregate method is an empty implementation, That is, the result returned by the aggregate function after each aggregation is Row(0). Through the previous analysis of the aggregate function in sql (see the source code of GroupAggProcessFunction function function), if the values obtained by the aggregate function before and after processing are the same, it may not send this result or send a withdrawal and a new result, However, the final effect will not affect the downstream calculation. Here, we simply understand that when processing the same devId,datatime will not send data to the downstream, that is, for each pair of devId,datatime will only send data to the downstream once;
The external is a simple counting calculation according to the time dimension. For each group of devids in the internal, datatime will only send data to the external once, so each devId of the external corresponding datatime dimension is a unique counting, and the result is the de counting result we need.
2.3 comparison of the two methods
- These two methods can eventually get the same results, but after analysis, there are still large differences in their internal implementation. The first is to select datatime in the grouping. Each datatime of the internal accumulator distinct accumulator will correspond to an object, and all device IDs in this dimension will be stored in the map of the accumulator object, The second option is to refine the grouping, use datatime + dev id to store separately, and then use the external time dimension to count. The simple summary is as follows:
First: DataTime - > value {devi1, devid2...}
The second type: DataTime + devid - > row (0)
The accumulator in the aggregate function is stored in the ValueState. The number of key s in the second method is much more than that in the first method, but the space occupied by the ValueState is much smaller. In practice, we usually choose the rocksdb method as the state backend. There is an upper limit on the value in rocksdb. The first method is easy to reach the upper limit, Then the second method will be more appropriate; - Both of these methods save the device data in full, which will consume a lot of storage space. However, our calculation usually has time attribute, so you can set the status ttl by configuring StreamQueryConfig.
III. hyperlog de duplication
HyperLogLog algorithm is the cardinality estimation statistical algorithm, which estimates the number of different data in a set, which is often referred to as de duplication statistics. There is also a HyperLogLog type structure in redis, which can use 12k memory and count 2 ^ 64 data with an allowable error of 0.81%. In this case, it can reduce the consumption of storage space, However, the premise is that certain errors are allowed. For the principle of hyperlog algorithm, please refer to this article: https://www.jianshu.com/p/55defda6dcd2 The algorithm is implemented in detail. Stream lib, an open source java streaming computing library, provides its specific implementation code. Because the code is relatively long, it will not be posted (you can reply to hll in the background and obtain the complete code of using hll to remove duplication in flink).
Test its use effect and prepare 97320 different data:
public static void main(String[] args) throws Exception{
String filePath = "000000_0";
BufferedReader br = new BufferedReader(new InputStreamReader(new FileInputStream(filePath)));
Set<String> values =new HashSet<>();
HyperLogLog logLog=new HyperLogLog(0.01); //Allowable error
String line = "";
while ((line = br.readLine()) != null) {
String[] s = line.split(",");
String uuid = s[0];
values.add(uuid);
logLog.offer(uuid);
}
long rs=logLog.cardinality();
}
When the error value is 0.01; rs = 98228, memory size required int[1366] / / internal data structure
When the error value is 0.001; rs is 97304, which requires memory size int[174763]
The smaller the error is, the closer it is to the real data, but the memory required in this process is also larger and larger. This choice can be determined according to the actual situation.
If you want to complete the development through sql, you can combine hll with udaf. The implementation code is as follows:
public class HLLDistinctFunction extends AggregateFunction<Long,HyperLogLog> {
@Override public HyperLogLog createAccumulator() {
return new HyperLogLog(0.001);
}
public void accumulate(HyperLogLog hll,String id){
hll.offer(id);
}
@Override public Long getValue(HyperLogLog accumulator) {
return accumulator.cardinality();
}
}
The defined return type is long, which is the result of de duplication. The accumulator is a hyperlog type structure.
Test:
case class AdData(id:Int,devId:String,datatime:Long)object Distinct1 { def main(args: Array[String]): Unit = {
val env=StreamExecutionEnvironment.getExecutionEnvironment
val tabEnv=StreamTableEnvironment.create(env)
tabEnv.registerFunction("hllDistinct",new HLLDistinctFunction)
val kafkaConfig=new Properties()
kafkaConfig.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,"localhost:9092")
kafkaConfig.put(ConsumerConfig.GROUP_ID_CONFIG,"test1")
val consumer=new FlinkKafkaConsumer[String]("topic1",new SimpleStringSchema,kafkaConfig)
consumer.setStartFromLatest()
val ds=env.addSource(consumer)
.map(x=>{
val s=x.split(",")
AdData(s(0).toInt,s(1),s(2).toLong)
})
tabEnv.registerDataStream("pv",ds)
val rs=tabEnv.sqlQuery( """ select hllDistinct(devId) ,datatime
from pv group by datatime
""".stripMargin)
rs.writeToSink(new PaulRetractStreamTableSink)
env.execute()
}
}
Prepare test data
1,devId1,1577808000000 1,devId2,1577808000000 1,devId1,1577808000000
Results obtained:
4> (true,1,1577808000000) 4> (false,1,1577808000000) 4> (true,2,1577808000000)
Its basic use is introduced here and will be further optimized later.
Four bitmap exact de duplication
All the precise de duplication schemes mentioned above will save a full amount of data, but this method is at the expense of storage. Although the hyperloglog method reduces storage but loses accuracy, how can we achieve accurate de duplication without consuming too much storage? This article mainly explains how to use bitmap for accurate de duplication.
ID-mapping
When using bitmap to remove the duplicate, we need to convert the ID of the duplicate into a string of numbers, but we usually remove a string containing characters, such as device ID. in the first step, we need to convert the string into numbers. First, we may think of hashing the string, but the hash will have probability conflict. Then we can use meituan's open source leaf distributed unique self increasing ID algorithm, You can also use Twitter's open source snowflake distributed unique ID snowflake algorithm. We chose to implement the relatively convenient snowflake algorithm (found online). The code is as follows:
public class SnowFlake {
/**
* Starting timestamp
*/
private final static long START_STMP = 1480166465631L;
/**
* Number of bits occupied by each part
*/
private final static long SEQUENCE_BIT = 12; //Number of digits occupied by serial number
private final static long MACHINE_BIT = 5; //Number of digits occupied by machine identification
private final static long DATACENTER_BIT = 5;//Number of bits occupied by data center
/**
* Maximum value of each part
*/
private final static long MAX_DATACENTER_NUM = -1L ^ (-1L << DATACENTER_BIT);
private final static long MAX_MACHINE_NUM = -1L ^ (-1L << MACHINE_BIT);
private final static long MAX_SEQUENCE = -1L ^ (-1L << SEQUENCE_BIT);
/**
* Displacement of each part to the left
*/
private final static long MACHINE_LEFT = SEQUENCE_BIT;
private final static long DATACENTER_LEFT = SEQUENCE_BIT + MACHINE_BIT;
private final static long TIMESTMP_LEFT = DATACENTER_LEFT + DATACENTER_BIT;
private long datacenterId; //Data center
private long machineId; //Machine identification
private long sequence = 0L; //serial number
private long lastStmp = -1L;//Last timestamp
public SnowFlake(long datacenterId, long machineId) {
if (datacenterId > MAX_DATACENTER_NUM || datacenterId < 0) {
throw new IllegalArgumentException("datacenterId can't be greater than MAX_DATACENTER_NUM or less than 0");
}
if (machineId > MAX_MACHINE_NUM || machineId < 0) {
throw new IllegalArgumentException("machineId can't be greater than MAX_MACHINE_NUM or less than 0");
}
this.datacenterId = datacenterId;
this.machineId = machineId;
}
/**
* Generate next ID
*
* @return
*/
public synchronized long nextId() {
long currStmp = getNewstmp();
if (currStmp < lastStmp) {
throw new RuntimeException("Clock moved backwards. Refusing to generate id");
}
if (currStmp == lastStmp) {
//Within the same milliseconds, the serial number increases automatically
sequence = (sequence + 1) & MAX_SEQUENCE;
//The number of sequences in the same millisecond has reached the maximum
if (sequence == 0L) {
currStmp = getNextMill();
}
} else {
//Within different milliseconds, the serial number is set to 0
sequence = 0L;
}
lastStmp = currStmp;
return (currStmp - START_STMP) << TIMESTMP_LEFT //Timestamp part
| datacenterId << DATACENTER_LEFT //Data center part
| machineId << MACHINE_LEFT //Machine identification part
| sequence; //Serial number part
}
private long getNextMill() {
long mill = getNewstmp();
while (mill <= lastStmp) {
mill = getNewstmp();
}
return mill;
}
private long getNewstmp() {
return System.currentTimeMillis();
}
}
The implementation of snowflake algorithm is related to machine code and time. In order to ensure its high availability, two different external services of machine code are provided. Then the whole conversion process is as follows:
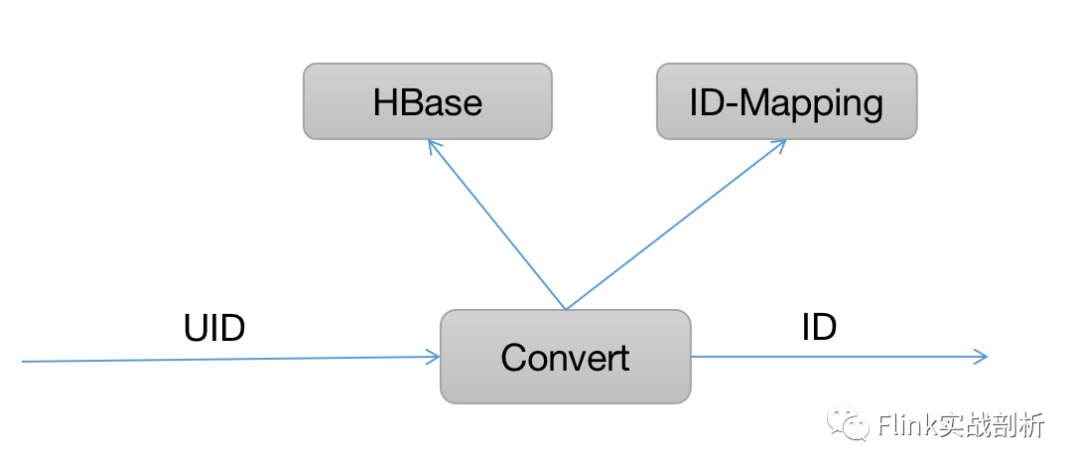
First, it will query whether there is an ID corresponding to the UID from the Hbase. If so, it will be obtained directly. If not, it will call the ID mapping service, then store its corresponding relationship in the Hbase, and finally return the ID to the downstream processing.
UDF
In order to facilitate the use of business providers, it also needs to be encapsulated into UDF. Since the snowflake algorithm obtains a long integer, Roaring64NavgabelMap is selected as the storage object. Since the de duplication is calculated according to the dimension, using UDAF, first define an accumulator:
public class PreciseAccumulator{
private Roaring64NavigableMap bitmap;
public PreciseAccumulator(){
bitmap=new Roaring64NavigableMap();
}
public void add(long id){
bitmap.addLong(id);
}
public long getCardinality(){
return bitmap.getLongCardinality();
}
}
udaf implementation
public class PreciseDistinct extends AggregateFunction<Long, PreciseAccumulator> {
@Override public PreciseAccumulator createAccumulator() {
return new PreciseAccumulator();
}
public void accumulate(PreciseAccumulator accumulator,long id){
accumulator.add(id);
}
@Override public Long getValue(PreciseAccumulator accumulator) {
return accumulator.getCardinality();
}
}
Then in actual use, you only need to register udaf.
reference resources: https://mp.weixin.qq.com/s/gnDvVPZh3JZArfmYii_trQ
https://mp.weixin.qq.com/s?__biz=MzI0NTIxNzE1Ng==&mid=2651218664&idx=1&sn=7babf9a45d44df2e7d7f36c3b9e98e60&chksm=f2a32003c5d4a9154a07be428d858df9c332457b44b779e8a0a2c061df3b222187ff95460e7a&mpshare=1&scene=1&srcid=0207smlUIuucD2KtY465Fvla&sharer_sharetime=1644202659963&sharer_shareid=8d60858916c3f82614fc6e0541627176#rd