Flink (I): introduction to Flink installation and running architecture
What is flink?
Apache Flink is a memory stream based computing engine born in December 2014.
Apache Flink is a framework and distributed processing engine for stateful computing on unbounded and bounded data streams. Flink is designed to run in all common cluster environments and perform calculations at memory speed and any size.
Flink features
- Can handle bounded and unbounded data streams.
- It can be transported anywhere. (third party resource managers, such as yarn, k8s, and self-contained resource managers)
- Run applications at any size
- Deploy applications anywhere
- Command execution
- Remote deployment
- Graphical interface (commonly used)
- Make full use of memory performance
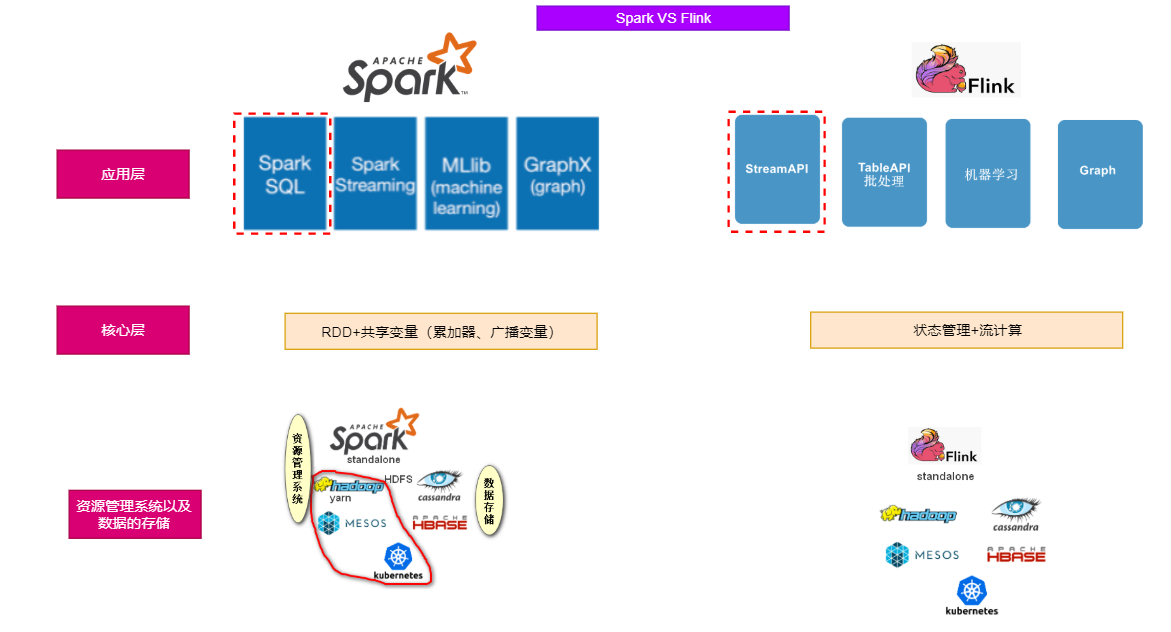
Flink vs Spark
- Spark underlying computing is a batch model, which simulates the flow on the basis of batch processing, resulting in low real-time performance of flow computing (micro batch processing)
- Flink underlying computing is a continuous flow computing model. Simulating batch processing on flow computing can not only ensure the real-time performance of flow, but also realize batch processing
Installation and getting started
install
quick get start

- Import dependency
<!-- https://mvnrepository.com/artifact/org.apache.flink/flink-streaming-scala --> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-streaming-scala_2.11</artifactId> <version>1.10.0</version> </dependency>
- Introducing plug-ins
Portal - Getting started with WordCount
package com.baizhi.flink
import org.apache.flink.streaming.api.scala._
object FlinkQuickStart {
def main(args: Array[String]): Unit = {
//1. Create execution environment
val environment = StreamExecutionEnvironment.getExecutionEnvironment
//Set parallelism
//environment.setParallelism(2)
//Local operating environment
//val environment = StreamExecutionEnvironment.createLocalEnvironment(3)
//2. Create DataStream
val text = environment.socketTextStream("hadoop10", 9999)
//3. General conversion of text data
val result = text.flatMap(line=>line.split("\\s+"))
.map(word=>(word,1))
//keyBy is to group the above data according to element 0. That is, group according to the input words
.keyBy(0) //Similar to reducebykey in spark; groupbykey
.keyBy(0)
.sum(1);
//4. Console print results
result.print();
//5. Perform flow calculation tasks
environment.execute("myDataStreamJobTask")
}
}
Program deployment
-
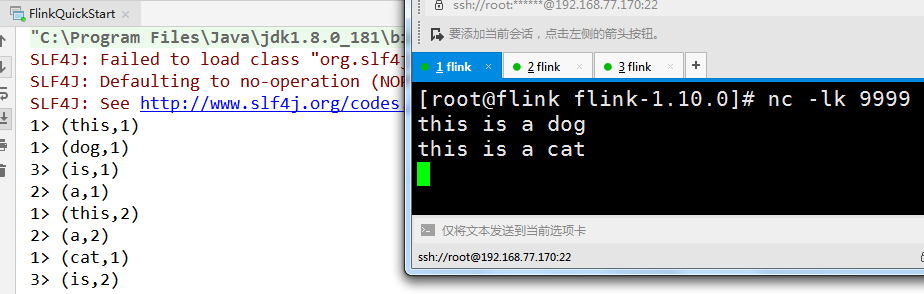
Execute locally (run the code directly in the idea development tool)
-
Listen for port number 9999 through nc command
nc -lk 9999
Note: you must ensure that nc has been installed
-
The client program is modified to the local running environment
You can also directly use streamexecutionenvironment getExecutionEnvironment
val environment = StreamExecutionEnvironment.createLocalEnvironment(3)
-
Run program: execute main method
-
Input the content in the nc interface of Linux and view the output results on the console of the development tool
-
-
Remote script deployment
-
The client program is modified to automatically identify the running environment
val environment = StreamExecutionEnvironment.getExecutionEnvironment
-
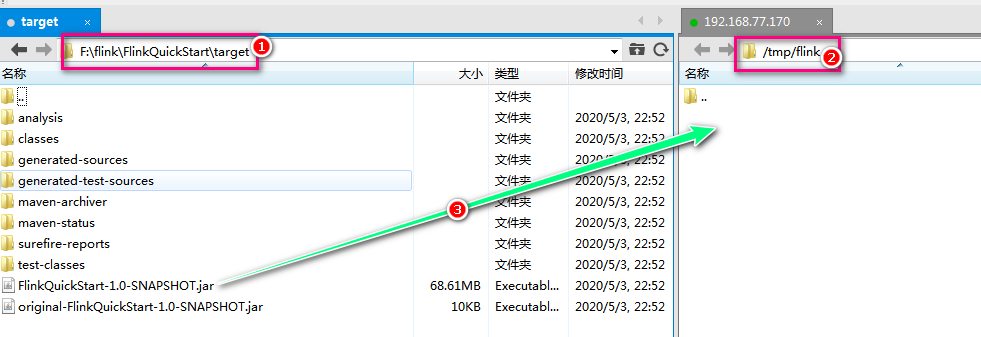
Generate jar package through mvn package
-
Transfer the generated jar to the / tmp/flink directory of the Linux system
-
By executing flink_ run action of the flink file in the home / bin directory and submit the job

explain
-c,--class <classname> Class with the program entry point ("main()" method). Only needed if the JAR file does not specify the class in its manifest. Specify startup class -d,--detached If present, runs the job in detached mode Background submission -p,--parallelism <parallelism> The parallelism with which to run the program. Optional flag to override the default value specified in the configuration. Specify parallelism -m,--jobmanager <arg> Address of the JobManager (master) to which to connect. Use this flag to connect to a different JobManager than the one specified in the configuration. Submit target hostYou must ensure that you are listening for the 9999 port number
All action/option/args do not need to be memorized. Pass/ Flick -- help view help documents
It can also be passed/ Flick -- help view the help document of the corresponding action. Where the location can be run/list/info/cancel
View running job s

[root@flink bin]# ./flink list --running --jobmanager flink.baizhiedu.com:8081
View all job s
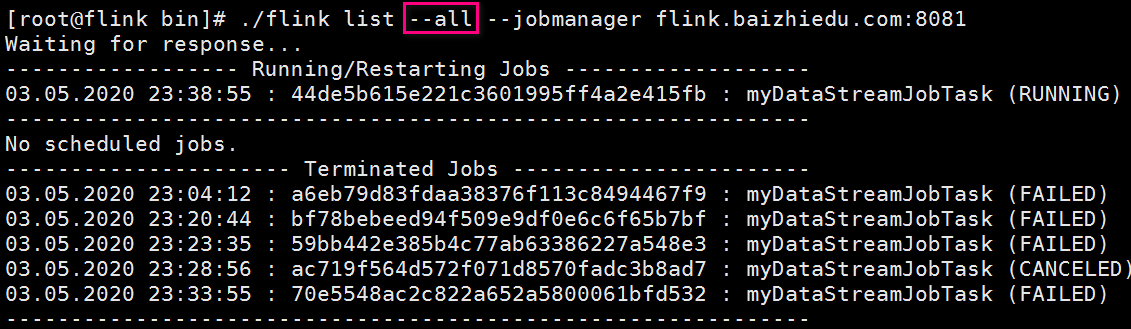
[root@flink bin]# ./flink list --all --jobmanager flink.baizhiedu.com:8081
Unassigned job

View program execution plan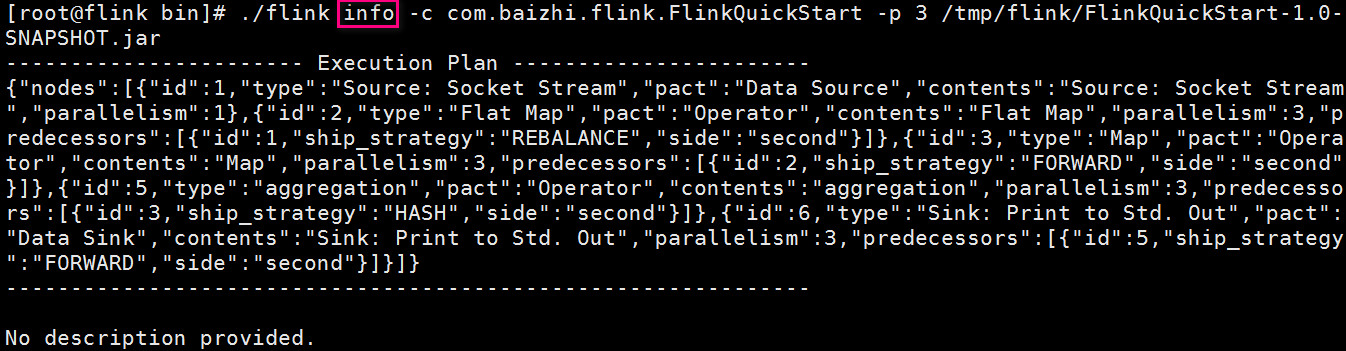
[root@flink bin]# ./flink info -c com.baizhi.flink.FlinkQuickStart -p 3 /tmp/flink/FlinkQuickStart-1.0-SNAPSHOT.jar
visit https://flink.apache.org/visualizer /, copy the json after the above command is executed to view the program execution plan
[
-
-
Web UI deployment
By accessing the web interface of flink, submit a job to complete the deployment
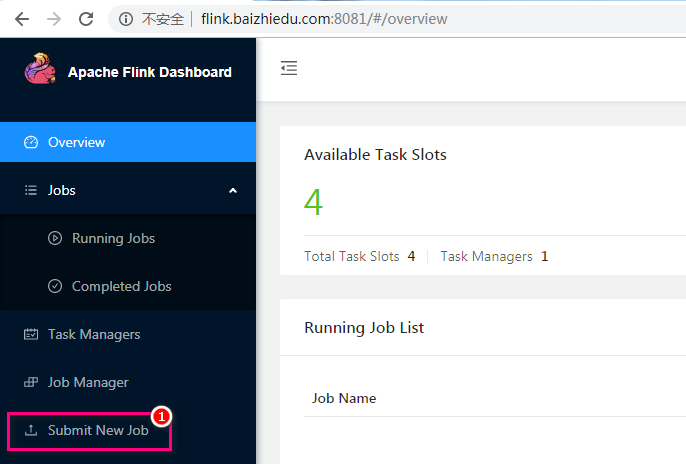
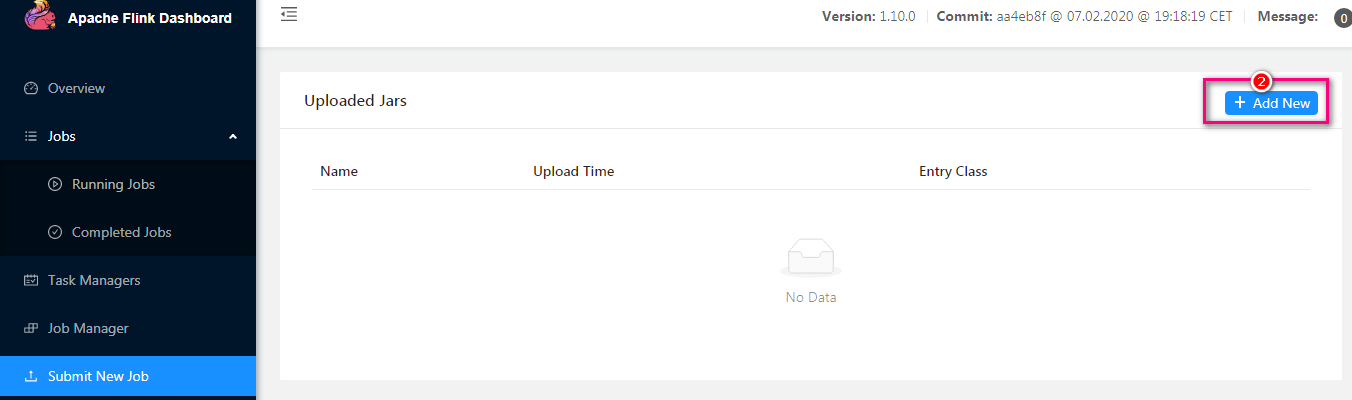
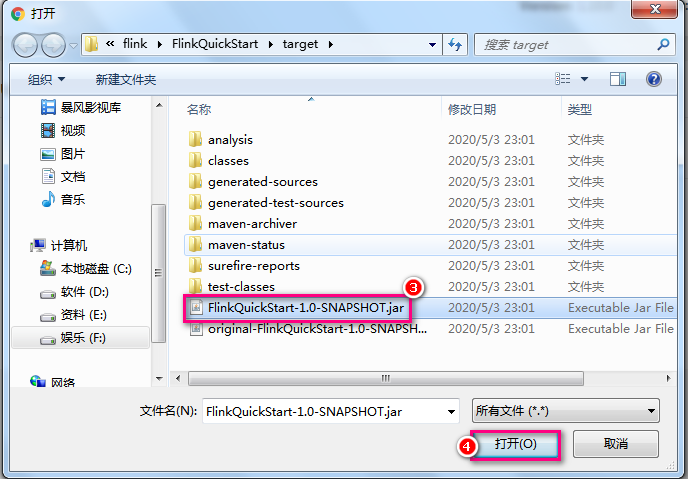

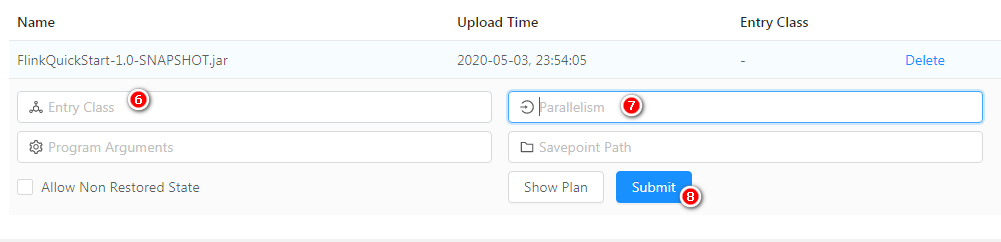
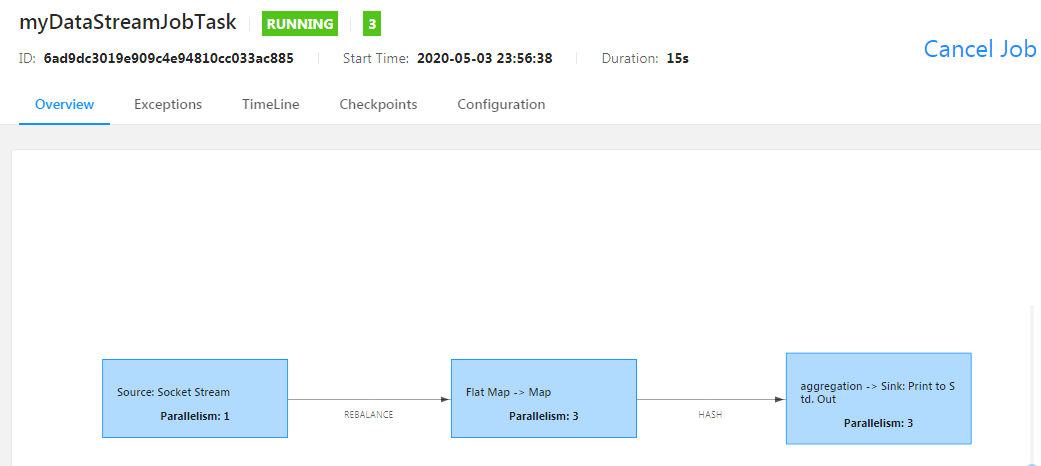
-
Cross platform deployment
- Modify the running environment code of the program and specify the parallelism
val jar = "F:\\flink\\FlinkQuickStart\\target\\FlinkQuickStart-1.0-SNAPSHOT.jar"; val environment = StreamExecutionEnvironment.createRemoteEnvironment("flink.baizhiedu.com",8081,jar); //Set parallelism environment.setParallelism(3);- Package the program through mvn package
- Run the main method to complete the deployment
Running architecture
Tasks and Operator Chains
In flink,
A main method represents a job,
A job contains many operators,
These operators are connected by some rule (operator chain),
Many operators are connected together to form a concept - task, [similar to spark's stage],
There are several subtask s according to the parallelism of a task.
subtask is the smallest unit in which a flick program runs.
The difference between Spark and Spark is that Spark realizes Stage division through RDD dependency, while Flink realizes task splitting through the concept of Operator Chain. In this way, multiple operators are merged into one task, so as to optimize the calculation and reduce the communication cost of thread to thread.
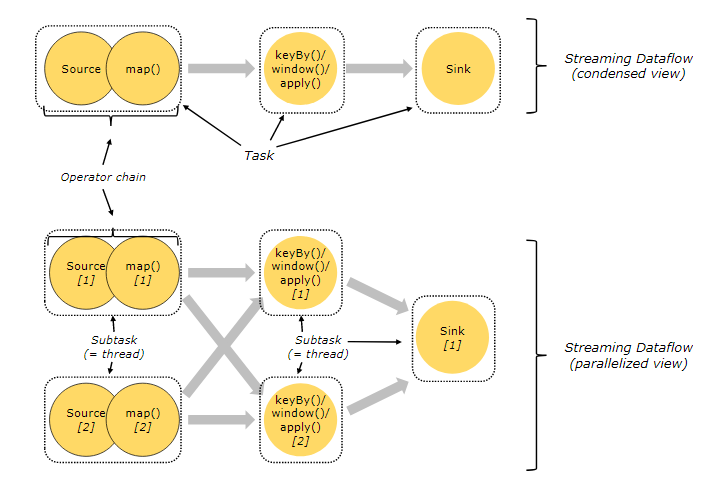
- Task - equivalent to the Stage in spark. Each task has a Subtask
- Subtask - equivalent to a thread, is a subtask in a Task
- Operator Chain - a mechanism for merging multiple operators into one Task. The merging principle is similar to the width dependency of SparkRDD
Job Managers, Task Managers, Clients
Flink is composed of two types of processes during its operation
-
Job Manager - (also known as master) is responsible for coordinating distributed execution. It is responsible for task scheduling, coordinating checkpoints, coordinating fault recovery, etc. it is equivalent to the function of Master+Driver in Spark. Usually, there is at least one Active JobManager in a cluster. If the others are in StandBy state in HA mode.
-
Task Manager - (also known as Worker) is really responsible for the task execution computing node, and needs to report its status information and workload to JobManager. There are usually several task managers in a cluster, but at least one must be.
-
Client - the client in Flink is not a part of cluster computing. The client only prepares and submits dataflow to JobManager. After completing the submission, you can exit directly, or you can also maintain connections to receive execution progress, so Client is not responsible for scheduling during the execution of tasks. The client can be run as part of a Java/Scala program that triggers execution, or in a command line window.
It is similar to the Driver in Spark, but it is particularly different because Spark Driver is responsible for task scheduling and recovery
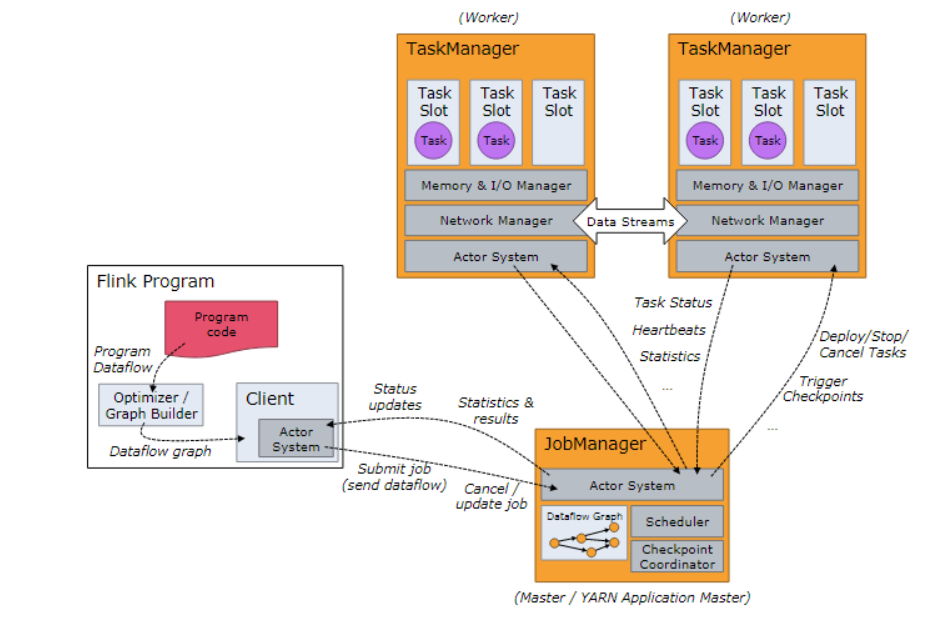
task slot [task slot]
Task slots represent the computing power of a taskmanager. All task slot s will share the resources of the taskmanager equally,
The maximum parallelism of tasks in the job determines the minimum task slots required for the task execution. Subtasks of different tasks in the same job share task slots
, the parallelism of a task cannot be greater than the number of task slot s, otherwise the task fails to start.
If slot s cannot be shared among subtasks of different tasks under the same Job, non intensive subtasks will be blocked and memory will be wasted.
Note:
- Non intensive tasks: source()/map(). The operation occupies a small amount of memory
- Intensive tasks: keyBy()/window()/apply(). shuffle is involved in the operation, which will occupy a lot of memory
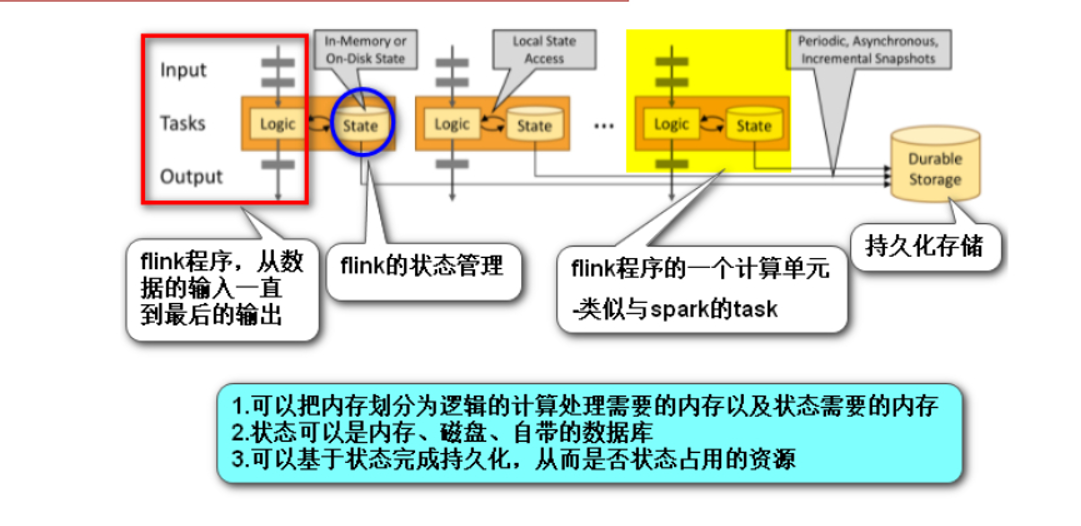
Checkpoint/Savepoint
- Checkpoint is set in the flink program. The flink server will automatically execute it regularly to persist the data in the state to the corresponding storage medium. After the new checkpoint is executed, the old checkpoint will be discarded.
- savepoint is a manual version of checkpoint, which needs to be manually executed by programmers. However, when the new checkpoint is completed, it will not expire automatically and needs to be cleaned manually.
State Backends
It is up to him to decide where to persist the data in the checkpoint.
- The MemoryStateBackend: the memory of jobmanager
- The FsStateBackend: file system, such as hdfs
- The RocksDBStateBackend: DB – the built-in database of flink, which stores data in a k-v structure based on memory + disk