Data preparation
- The data used below are all the following data
sensor_1,1547718199,35.8 sensor_6,1547718201,15.4 sensor_7,1547718202,6.7 sensor_10,1547718205,38.1 sensor_1,1547728199,25.8 sensor_6,1547712201,35.4 sensor_7,1547718102,16.7 sensor_10,1547712205,28.1
Basic conversion operators (Map, FlatMap, Filter)
Map
- map is to transform data from one form to another

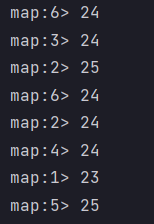
- Converts the string type to the length of the output string
SingleOutputStreamOperator<Integer> mapStream = inputStream.map(new MapFunction<String, Integer>() {
@Override
public Integer map(String s) throws Exception {
return s.length();
}
});
- The above is the complete writing method, and there is a simple writing method
SingleOutputStreamOperator<Integer> map = inputStream.map(str -> str.length());
- Result display
flatMap
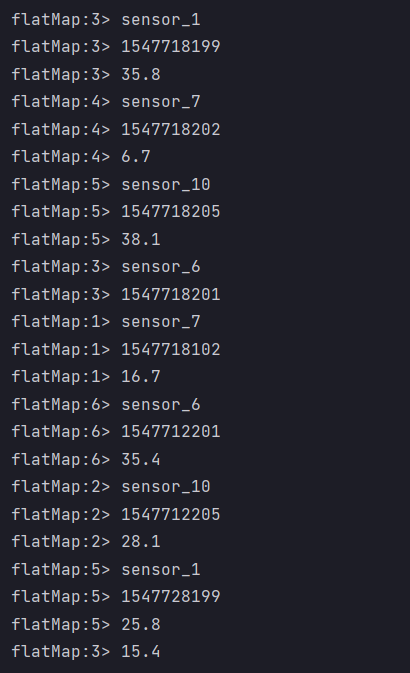
- flatMap is to split an array into groups
- Divide the data into commas
SingleOutputStreamOperator<String> flatMapStream = inputStream.flatMap(new FlatMapFunction<String, String>() {
@Override
public void flatMap(String s, Collector<String> collector) throws Exception {
String[] fields = s.split(",");
for (String field : fields) {
collector.collect(field);
}
}
});
- Result display
Filter
- Filter out the data you need
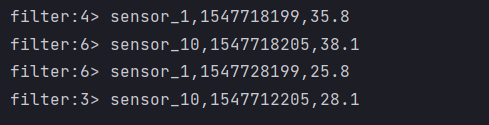
- Filter sensor_ Data beginning with 1
SingleOutputStreamOperator<String> filterStream = inputStream.filter(new FilterFunction<String>() {
@Override
public boolean filter(String s) throws Exception {
return s.equ("sensor_1");
}
});
- Result display
KeyBy
- DataStream → KeyedStream: logically split a stream into disjoint partitions. Each partition contains elements with the same key and is implemented internally in the form of hash.
- The rolling aggregation operator can aggregate each tributary of KeyedStream
- Code display
package transform;
import beans.SenSorReading;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.java.tuple.Tuple;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
public class KeyByAndRollAggregation {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//Read data from file
DataStreamSource<String> inputStream = env.readTextFile("src/main/resources/sensor.txt");
//Convert to custom type
// SingleOutputStreamOperator<SenSorReading> dataStream = inputStream.map(new MapFunction<String, SenSorReading>() {
// @Override
// public SenSorReading map(String s) throws Exception {
// String[] fileds = s.split(",");
// return new SenSorReading(fileds[0], new Long(fileds[1]), new Double(fileds[2]));
// }
// });
SingleOutputStreamOperator<SenSorReading> dataStream = inputStream.map(line -> {
String[] fields = line.split(",");
return new SenSorReading(fields[0], new Long(fields[1]), new Double(fields[2]));
});
/**
* key Two implementation methods of
* First: if the data type is Tuple, you can directly use the location of the partition
* The second is the field name, that is, the partition attribute name of the user-defined class
*/
KeyedStream<SenSorReading, Tuple> keyByStream = dataStream.keyBy("id");
// KeyedStream<SenSorReading, String> keyByStream02 = dataStream.keyBy(data -> data.getId());
//Rolling aggregation
/**
* What is rolling aggregation?
* It's just that different data are being updated. One piece of data will be updated
*/
SingleOutputStreamOperator<SenSorReading> resultStream = keyByStream.max("temperature");
/**
* maxBy And max?
* max The is to take the maximum value, but Zhu Hui pays attention to the element to be taken. The final output result is to ask for the maximum value of the element, but other elements do not necessarily match it
* maxBy The whole element is recorded
*/
SingleOutputStreamOperator<SenSorReading> maxByresultStream = keyByStream.maxBy("temperature");
maxByresultStream.print("maxBy");
resultStream.print("max");
env.execute();
}
}
-
What is the difference between max and maxBy?
max takes the maximum value, but Zhu Hui pays attention to the element to be taken. The final output result is to ask for the maximum value of the element, but other elements do not necessarily match it
maxBy records the entire element
-
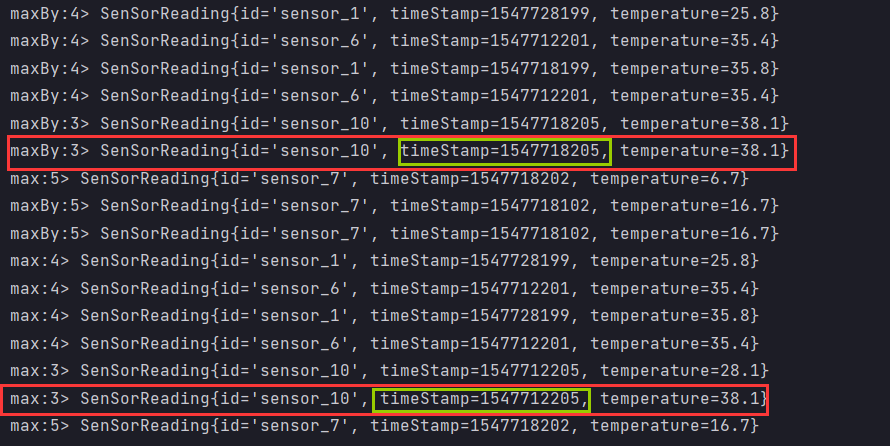
It can be seen from the original data that the largest piece of data should be sensor_ 101547718205,38.1, let's see the difference between the data obtained by max and maxBY
Customize reduce
-
KeyedStream → DataStream: an aggregation operation of grouped data stream, which combines the current element and the results of the last aggregation to generate a new value. The returned stream contains the results of each aggregation, rather than only the final results of the last aggregation.
-
Code display
package transform;
import beans.SenSorReading;
import org.apache.flink.api.common.functions.ReduceFunction;
import org.apache.flink.api.java.tuple.Tuple;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
public class reduceTest01 {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//Read data from file
DataStreamSource<String> inputStream = env.readTextFile("src/main/resources/sensor.txt");
SingleOutputStreamOperator<SenSorReading> dataStream = inputStream.map(line -> {
String[] fields = line.split(",");
return new SenSorReading(fields[0], new Long(fields[1]), new Double(fields[2]));
});
KeyedStream<SenSorReading, String> keyByStream = dataStream.keyBy(data -> data.getId());
//reduce gets the maximum temperature value and the latest timestamp
// SingleOutputStreamOperator<SenSorReading> reduceStream = keyByStream.reduce(new ReduceFunction<SenSorReading>() {
// /**
// * The first is the result data processed before
// * The second is waiting for data to be processed
// * @param senSorReading
// * @param t1
// * @return
// * @throws Exception
// */
// @Override
// public SenSorReading reduce(SenSorReading senSorReading, SenSorReading t1) throws Exception {
// return new SenSorReading(senSorReading.getId(), t1.getTimeStamp(), Math.max(senSorReading.getTemperature(), t1.getTemperature()));
// }
// });
SingleOutputStreamOperator<SenSorReading> reduceStream =keyByStream.reduce((curr, newData) -> new SenSorReading(curr.getId(), newData.getTimeStamp(), Math.max(curr.getTemperature(), newData.getTemperature())));
reduceStream.print();
env.execute();
}
}
-
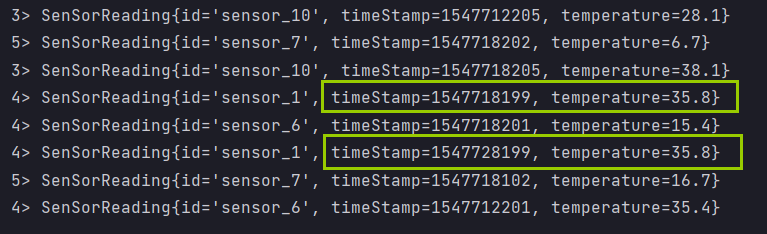
Result display
-
It can be seen that the timestamp is transformed to the latest
Split and combine
Split and Select
- Split: DataStream → SplitStream: split a DataStream into two or more datastreams according to some characteristics.
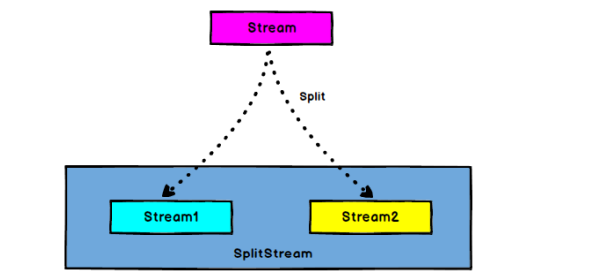
- Select: SplitStream → DataStream: obtain one or more datastreams from a SplitStream.
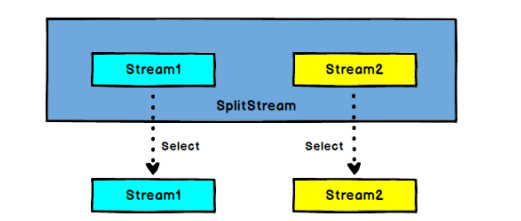
- Divide the data by temperature of 30 degrees
package transform;
import beans.SenSorReading;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.api.java.tuple.Tuple3;
import org.apache.flink.streaming.api.collector.selector.OutputSelector;
import org.apache.flink.streaming.api.datastream.*;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.co.CoMapFunction;
import java.util.Collections;
public class CollectAndColMap {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//Read data from file
DataStreamSource<String> inputStream = env.readTextFile("src/main/resources/sensor.txt");
SingleOutputStreamOperator<SenSorReading> mapStream = inputStream.map(line -> {
String[] fields = line.split(",");
return new SenSorReading(fields[0], new Long(fields[1]), new Double(fields[2]));
});
//Shunting: divide the data according to 30 degrees
SplitStream<SenSorReading> splitStream = mapStream.split(new OutputSelector<SenSorReading>() {
@Override
public Iterable<String> select(SenSorReading senSorReading) {
return (senSorReading.getTemperature() > 30 ? Collections.singletonList("high") : Collections.singletonList("low"));
}
});
DataStream<SenSorReading> highStream = splitStream.select("high");
DataStream<SenSorReading> lowStream = splitStream.select("low");
DataStream<SenSorReading> allStream = splitStream.select("high", "low");
highStream.print("high");
lowStream.print("low");
allStream.print("all");
env.execute();
}
}
- Result display
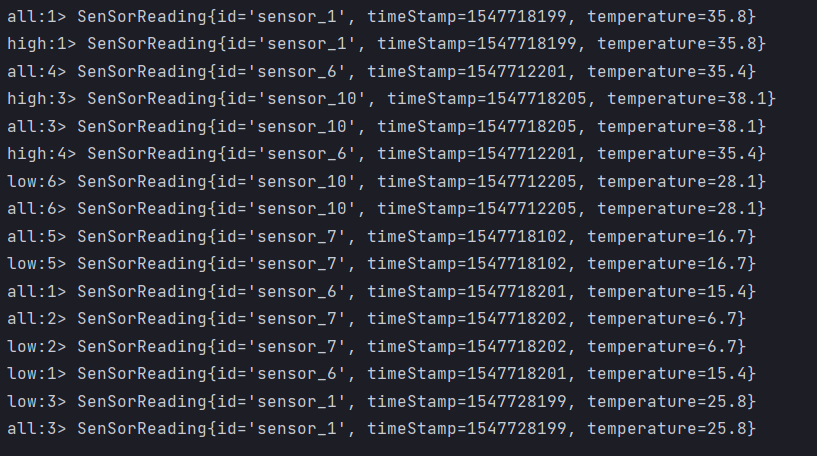
Connect and CoMap
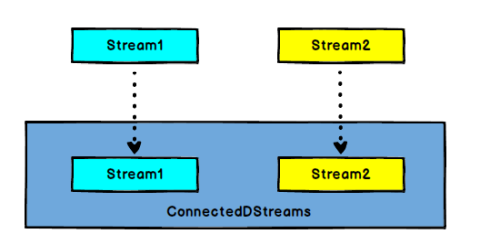
- Connect: DataStream,DataStream → ConnectedStreams: connect two data streams that maintain their types. After the two data streams are connected, they are only placed in the same stream. Their internal data and forms remain unchanged, and the two streams are independent of each other.
- CoMap: ConnectedStreams → DataStream: acts on ConnectedStreams. Its function is the same as that of map and flatMap. Map and flatMap are processed for each Stream in ConnectedStreams respectively.
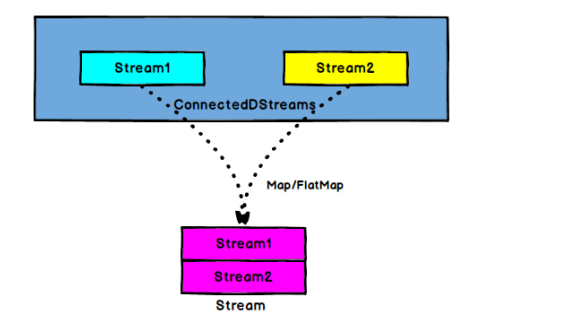
- Connect and CoMap can connect data of different data types. The following code demonstrates the connection of high and low data
package transform;
import beans.SenSorReading;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.api.java.tuple.Tuple3;
import org.apache.flink.streaming.api.collector.selector.OutputSelector;
import org.apache.flink.streaming.api.datastream.*;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.co.CoMapFunction;
import java.util.Collections;
public class CollectAndColMap {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//Read data from file
DataStreamSource<String> inputStream = env.readTextFile("src/main/resources/sensor.txt");
SingleOutputStreamOperator<SenSorReading> mapStream = inputStream.map(line -> {
String[] fields = line.split(",");
return new SenSorReading(fields[0], new Long(fields[1]), new Double(fields[2]));
});
//Shunting: divide the data according to 30 degrees
SplitStream<SenSorReading> splitStream = mapStream.split(new OutputSelector<SenSorReading>() {
@Override
public Iterable<String> select(SenSorReading senSorReading) {
return (senSorReading.getTemperature() > 30 ? Collections.singletonList("high") : Collections.singletonList("low"));
}
});
DataStream<SenSorReading> highStream = splitStream.select("high");
DataStream<SenSorReading> lowStream = splitStream.select("low");
DataStream<SenSorReading> allStream = splitStream.select("high", "low");
highStream.print("high");
lowStream.print("low");
allStream.print("all");
/**
* Confluence
* The high temperature is converted into a binary type, and the state information is output after the low temperature flow connection
*/
SingleOutputStreamOperator<Tuple2<String, Double>> highMapStream = highStream.map(new MapFunction<SenSorReading, Tuple2<String, Double>>() {
@Override
public Tuple2<String, Double> map(SenSorReading senSorReading) throws Exception {
return new Tuple2<>(senSorReading.getId(), senSorReading.getTemperature());
}
});
//connect
ConnectedStreams<Tuple2<String, Double>, SenSorReading> connectStream = highMapStream.connect(lowStream);
/**
* Three parameters of meaning
* The first two are the types of merged map s
* The third is the data type to be converted
*/
SingleOutputStreamOperator<Object> map = connectStream.map(new CoMapFunction<Tuple2<String, Double>, SenSorReading, Object>() {
@Override
public Object map1(Tuple2<String, Double> stringDoubleTuple2) throws Exception {
return new Tuple3<>(stringDoubleTuple2.f0,stringDoubleTuple2.f1,"high temp waring");
}
@Override
public Object map2(SenSorReading senSorReading) throws Exception {
return new Tuple2<>(senSorReading.getId(),"normal");
}
});
map.print();
}
}
- Result display
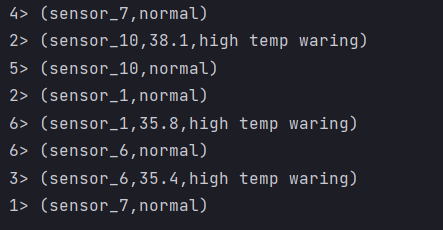
Union
- Is there a way to connect multiple streams? Yes, union is OK, but union can only connect streams with the same data type
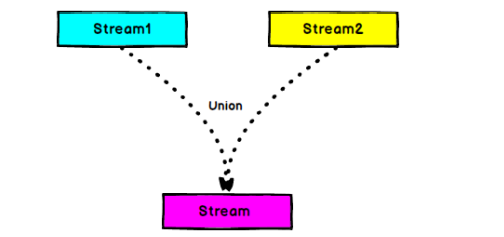
DataStream<SenSorReading> union = highStream.union(lowStream, allStream);
Rich Functions
-
"Rich function" is an interface of a function class provided by DataStream API. All Flink function classes have their rich versions. It is different from conventional functions in that it can obtain the context of the running environment and has some life-cycle methods, so it can realize more complex functions.
RichMapFunction
RichFlatMapFunction
RichFilterFunction
-
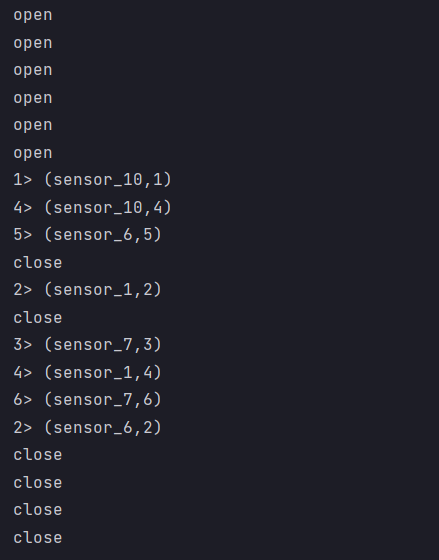
Rich Function has a concept of life cycle. Typical life cycle methods are:
The open() method is the initialization method of rich function. When an operator such as map or filter is called, open() will be called.
The close() method is the last method called in the life cycle to do some cleaning.
The getRuntimeContext() method provides some information about the RuntimeContext of the function, such as the parallelism of the function execution, the name of the task, and the state
-
The main function of the rich function is to obtain the information of the running environment and make some preparations before the program runs
package transform;
import beans.SenSorReading;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.common.functions.RichMapFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
public class RichFunctionTest {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//Read data from file
DataStreamSource<String> inputStream = env.readTextFile("src/main/resources/sensor.txt");
SingleOutputStreamOperator<SenSorReading> dataStream = inputStream.map(line -> {
String[] fields = line.split(",");
return new SenSorReading(fields[0], new Long(fields[1]), new Double(fields[2]));
});
DataStream<Tuple2<String, Integer>> res = dataStream.map(new MyMapper());
res.print();
env.execute();
}
public static class MyMapper01 implements MapFunction<SenSorReading, Tuple2<String, Integer>> {
@Override
public Tuple2<String, Integer> map(SenSorReading senSorReading) throws Exception {
return new Tuple2<>(senSorReading.getId(), senSorReading.getId().length());
}
}
/**
* The main function is to get a lot of current runtime information
*/
//Implement custom rich function classes
public static class MyMapper extends RichMapFunction<SenSorReading, Tuple2<String, Integer>> {
@Override
public Tuple2<String, Integer> map(SenSorReading senSorReading) throws Exception {
return new Tuple2<>(senSorReading.getId(), getRuntimeContext().getIndexOfThisSubtask()+1);
}
@Override
public void open(Configuration parameters) throws Exception {
/**
* Initialization is generally to define the working state or establish a database connection
*/
System.out.println("open");
}
@Override
public void close() throws Exception {
/**
* Release the cache and close the connection
*/
System.out.println("close");
}
}
}
- Result display
Jump top