1. What is flink?
Flink is a distributed open source computing framework for data stream processing and batch data processing, which supports both stream and batch applications. Because the SLAs (Service Level Agreement) provided by streaming and batching are completely different, streaming generally requires support for low latency, Exactly-once guarantees, and batching requires support for high throughput and efficient processing, two implementations are usually given separately when implementing. Or each of these solutions can be implemented through a separate open source framework. Typical open source solutions for batch processing are MapReduce and Spark. Storm is the open source solution for stream processing. Spark's Streaming is also essentially microbatch processing.
2. Steps for use
Flnk can use local files, hadoop's hdfs, kafka, and so on as data sources. Here I will use HDFS in Hadoop as data sources.
1. Install hadoop
I'm experimenting with a linux virtual machine in vmware. Here's how it works.
First create the Hadoop folder in the virtual machine, and download and unzip the jar package for hadoop.
cd /home mkdir hadoop cd hadoop wget http://archive.apache.org/dist/hadoop/common/hadoop-2.8.3/hadoop-2.8.3.tar.gz tar -xvf hadoop-2.8.3.tar.gz
2. Profile
The path to the configuration file is: /home/hadoop/hadoop-2.8.3/etc/hadoop
core-site.xml
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://192.168.1.11:9000</value>
</property>
</configuration>
hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
When mapred-site.xml is unzipped, there will be more template s, so delete them
<configuration>
<property>
<name>mapred.job.tracker</name>
<value>192.168.1.11:9001</value>
</property>
</configuration>
Now that the configuration is complete, format Hadoop's file system HDFS with the following commands
cd /home/hadoop/hadoop-2.8.3/bin ./hadoop namenode -format
Next, you can go to the sbin directory under hadoop, run the startup command, and run hadoop.
cd ../sbin ./start-all.sh
Having run successfully, you can access hadoop and HDFS through a few addresses.
http://192.168.1.11:8088 (MapReduce's Web page)
http://192.168.1.11:50070 (Web page for HDFS)
If it is not accessible, the port is not open.
At the same time, the network of the vmware virtual machine, it is best to choose the bridging mode, so that IP will not change frequently when the virtual machine is restarted.
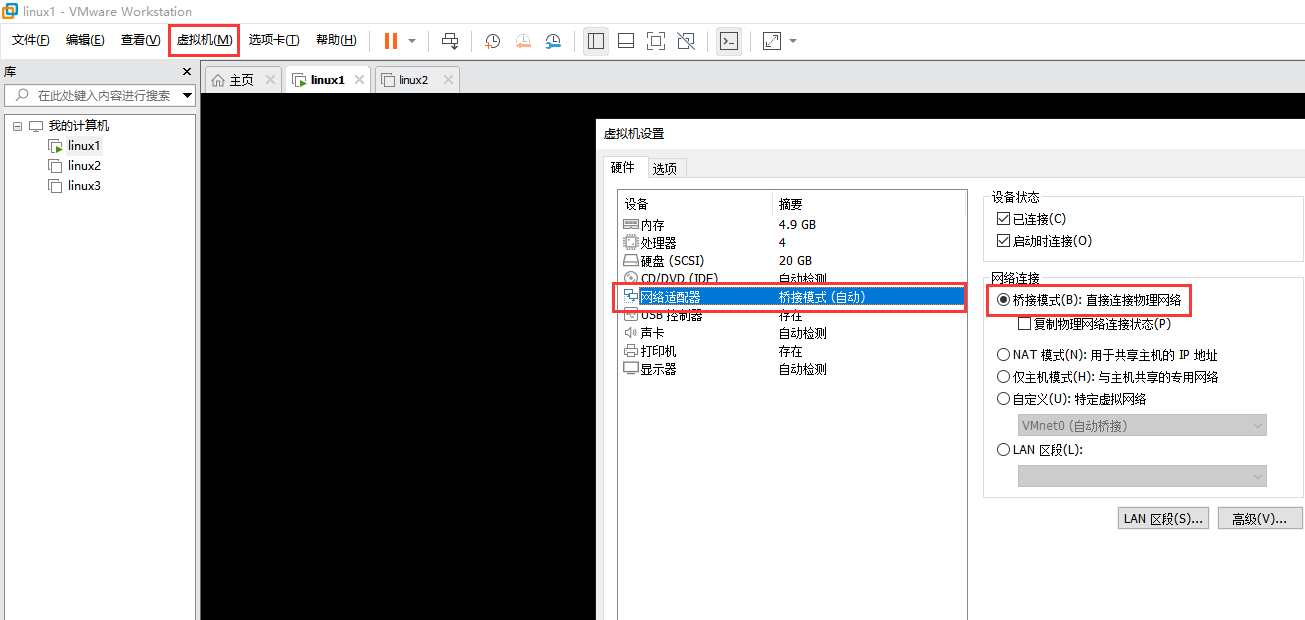
3. Create test files
Calculations have data sources, so you need to go to HDFS to create a file and open permissions.
cd ../bin hdfs dfs -touchz /wc.txt echo "hello word flink oh oh" | ./hdfs dfs -appendToFile - /wc.txt ./hdfs dfs -chmod -R 777 /
4. Implementation Code
This is written in scala language, about how IDEA integrates Scala with Baidu.
Import Dependency
<dependencies>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-scala_2.11</artifactId>
<version>1.9.1</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-scala_2.11</artifactId>
<version>1.9.1</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.7.2</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.7.2</version>
</dependency>
</dependencies>
<build>
<plugins> <!-- This plugin is used to add Scala Code compilation to class file -->
<plugin>
<groupId>net.alchim31.maven</groupId>
<artifactId>scala-maven-plugin</artifactId>
<version>3.4.6</version>
<executions>
<execution> <!-- Declare binding to maven Of compile stage -->
<goals>
<goal>testCompile</goal>
</goals>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-assembly-plugin</artifactId>
<version>3.0.0</version>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
create a file
Implementation Code
package source
import java.net.URL
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
object FileSource {
def main(args: Array[String]): Unit = {
//Initialization Context
val streamEnv: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment;
//Set parallelism (tasks can be spread over several slot s)
streamEnv.setParallelism(1);
//Sometimes the code cannot be prompted and can be imported into a function, it will prompt automatically
import org.apache.flink.streaming.api.scala._
//Reading data sources from hdfs
val stream: DataStream[String] = streamEnv.readTextFile("hdfs://zjj1:9000/wc.txt")
val result: DataStream[(String, Int)] = stream
.flatMap(_.split(" "))//The data read by flatMap is split into an array by spaces
.map((_, 1))//Each element in the array is split into a key-value pair whose key is its own value of 1
.keyBy(0)//Grouping 0 by key is key 1 is value
.sum(1)//Calculate the cumulative value with a subscript of 1
result.print();//Print results
//Execute task, stream calculation does not execute, no result
streamEnv.execute("readHdfs");
}
}
Contents in the file:
View the contents of the file through HDFS dfs-cat/wc.txt

Output results:
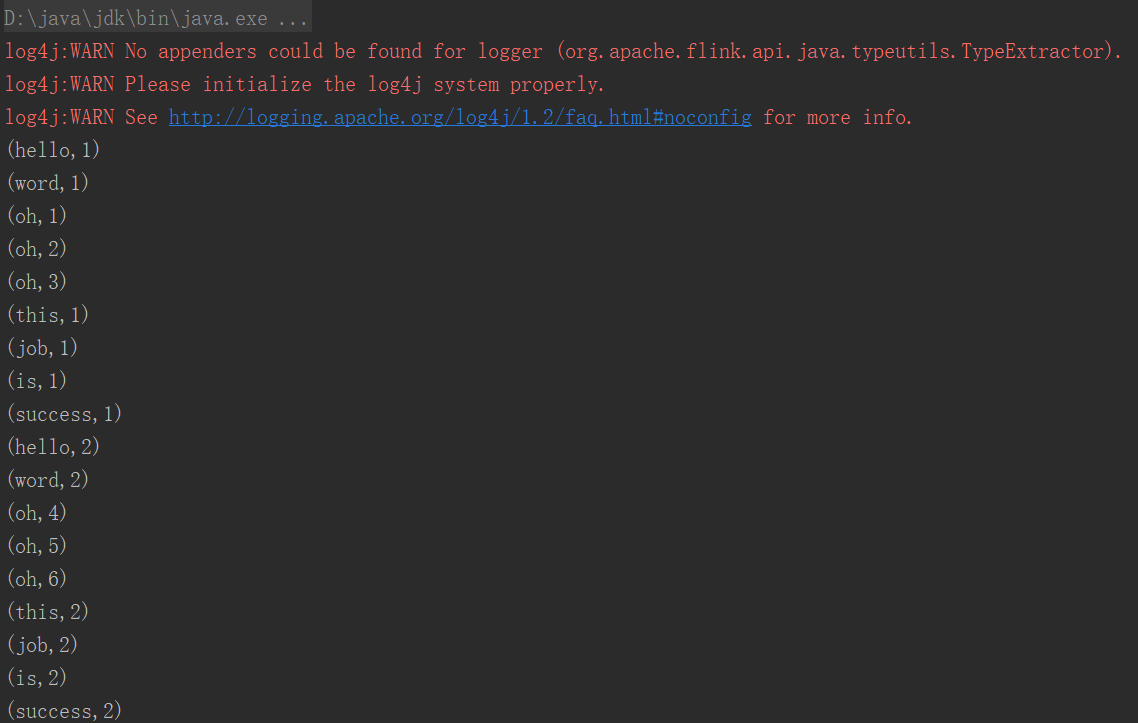
3. Conclusion
That's all for today's study. Go on!